By Adrien Payong and Shaoni Mukherjee

Introduction
The advent of powerful AI large language models requires orchestration beyond simple API calls when developing real-world applications. LangChain is an open-source Python framework aiming to simplify every step of the LLM app lifecycle. It provides standard interfaces for chat models, embeddings, vector stores, and integrations across hundreds of providers.
In this article, we will cover why AI applications need frameworks like LangChain. We will explain how LangChain works, its key building blocks, and common use cases. We’ll also compare LangChain to other similar tools (such as LlamaIndex and Haystack) and finish with a simple Python demo.
Key Takeaways
- LangChain is a modular, open-source Python framework to simplify the building of advanced LLM applications. It provides standardized interfaces for models, embeddings, vector stores, tools, and memory.
- It abstracts away the complexity of integrations, enabling developers to connect any LLM (e.g., OpenAI, Anthropic, Hugging Face) with external data sources, APIs, and custom tools with minimal code changes.
- LangChain offers reusable building blocks like chains, agents, memory, tools, and indexes. This allows developers to build complex, multi-step AI workflows, chatbots, RAG pipelines, and autonomous agents.
- LangChain features easy installation and concise Python APIs for fast prototyping and deployment of real-world AI applications and experimental work.
- The framework supports seamless switching and orchestration between model providers and backends. It can also be used in combination with alternatives like LlamaIndex (retrieval) and Haystack (search pipelines) for hybrid solutions.
What is LangChain?
LangChain is a generic interface to any LLM. It is a central hub for LLM-driven app development. The project was launched in late 2022 by Harrison Chase and Ankush Gola and quickly became one of the most popular open-source AI projects.
In simple terms, LangChain makes it easy to build generative AI applications (chatbots, virtual assistants, custom question-answering systems, etc.) by providing pre-built modules and APIs for the most common LLM tasks (prompt templates, model calls, vector embedding, etc.). This allows developers to avoid “reinventing the wheel” each time. LangChain is designed around a simple idea: LLMs must be connected to the right data and tools. After all, they are just pre-trained statistical models and often lack up-to-date facts or domain knowledge. LangChain can help you connect an LLM (such as GPT-4) to external sources( databases, documents, web APIs, or even your code). As a result, the AI model can answer questions with real-time, contextual information.
For example, when a user asks a question, a LangChain-powered chatbot might retrieve company documents or call a weather API to get current data before responding.
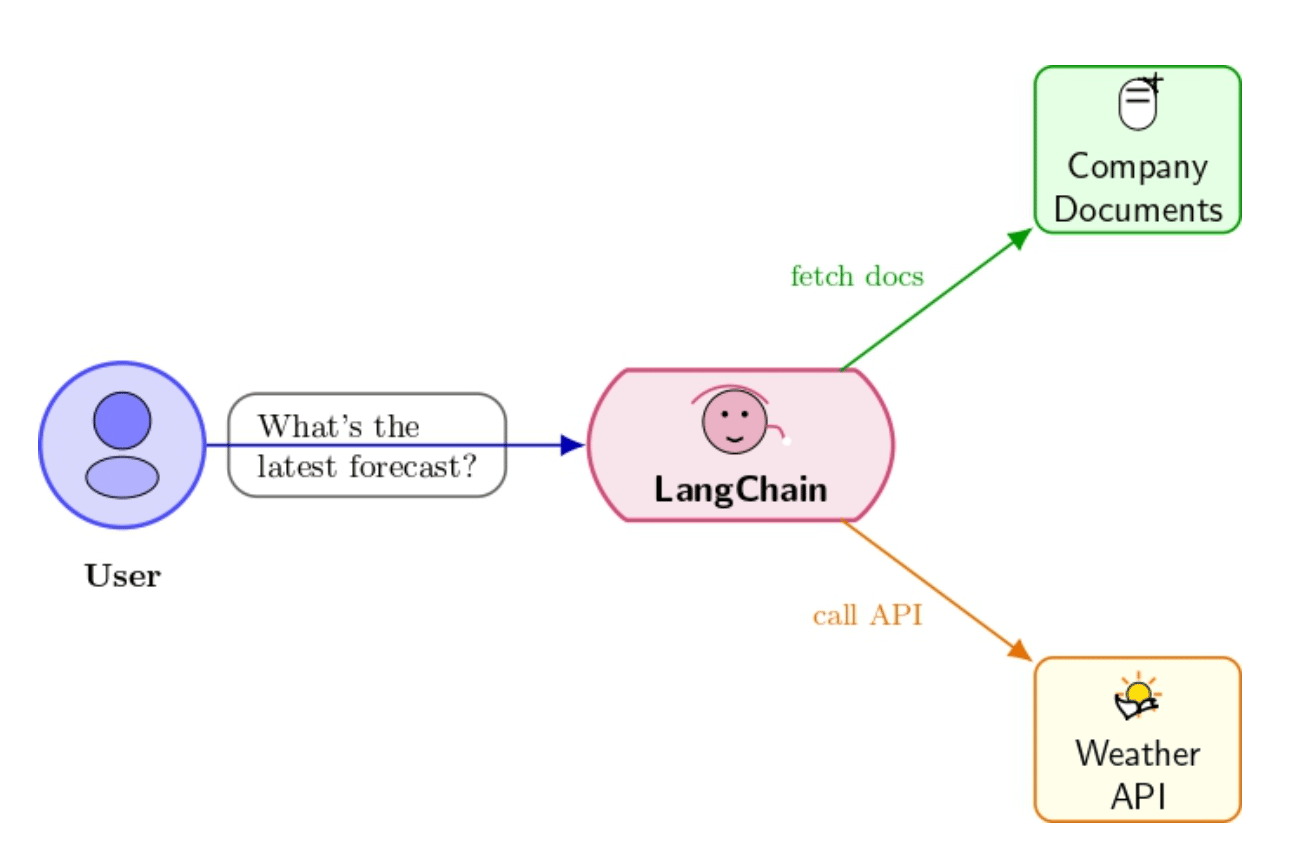
Without a framework, you would develop the integration code for each feature from scratch. LangChain’s architecture abstracts away such details by providing a standard interface for calling any LLM along with the integration of data retrieval and action tools. This makes it far easier to play around with different models or combine multiple models in a single application.
Key Components: Chains, Agents, Memory, Tools, Indexes
LangChain offers several building blocks for LLM applications. These components are used together to build complex AI workflows:
Chains
A chain is a series of steps (each step can be an LLM call, a data retrieval, or other action) that feeds its output to the next step in the chain. LangChain offers a powerful framework for building and executing such chains in Python (or JavaScript). LangChain includes several built-in chain types:
- LLMChain (Deprecated but not yet removed): The original “simplest” type of chain that wraps a single prompt and LLM call (i.e., ask a question and get the answer back). LLMChain is deprecated in favor of more flexible programming patterns such as RunnableSequence and the LangChain Expression Language (LCEL).
- SimpleSequentialChain: A chain that takes the LLM output from one step and directly passes it as input to the next step.
- SequentialChain: A superset of SimpleSequentialChain that can have branches, or more than one input/output - useful for more complex workflows.
- RouterChain: A chain that can dynamically choose which sub-chain to run based on the input (basically an if/else or switch statement for chains).
You can build a chain that translates text to French and then summarizes it. You could also imagine a chain that extracts essential information from user input, creates a database quer, and then uses the result to respond to the user. By breaking tasks into a series of smaller LLM calls, chains can perform step-by-step reasoning.
Agents
An agent is an LLM-based program that can autonomously decide what steps to take next. It observes the conversation or user query, and reasons (by one or more calls to an LLM), and decides which actions or tools to execute in the sequence. Tools can be a calculator, a search engine, a code interpreter, a custom API, etc.
LangChain includes the following types of agents:
- ZeroShotAgent: An agent that uses the React framework (Reflection + Action) to figure out what action to take, without example-based actions.
- ConversationalAgent: A chatbot-like agent that keeps track of the conversation history and uses tools conversationally (e.g., answer the user’s questions with the help of search).
- Plan-and-Execute Agents: A newer, more robust approach to agent building. Rather than a single large chain, the agent first plans out a sequence of steps (using an LLM) and then executes them one by one. This can be more robust, especially for complex tasks that involve multi-step research or reasoning.
Note: Agent types such as ZeroShotAgent and ConversationalAgent have been deprecated since version 0.1.0. For new projects, we recommend using LangGraph for agent orchestration. LangGraph is more flexible, supports stateful execution, and has more advanced orchestration capabilities.
For example, a LangChain agent might interpret a user’s request, determine that it needs to search Wikipedia, execute an API call to retrieve results, and format a response.
Here’s a Python-style LangChain agent example (simplified, with key logic) using the modern LangChain API. This example demonstrates an agent that decides which tool to use, gets the answe, and drafts a reply.
Note: You must install langchain, langchain-openai, langchain-community, and openai. Ensure to get your OpenAI API key. The Wikipedia tool, DuckDuckGo Search, and Requests tool come from langchain_community.tools.
# Install required packages (run this in your terminal, not in the script)
# pip install langchain langchain-openai langchain-community openai
import os
from langchain_openai import OpenAI
from langchain.agents import initialize_agent, AgentType
from langchain_community.tools import WikipediaQueryRun, DuckDuckGoSearchRun, RequestsGetTool
from langchain_community.utilities import WikipediaAPIWrapper
# 0. Set your OpenAI API key (recommended: set as environment variable)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key-here" # Replace with #your actual OpenAI API key
# 1. Set up the LLM and tools
llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0)
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper()) # No API key needed for Wikipedia
web_search = DuckDuckGoSearchRun()
api_tool = RequestsGetTool()
# 2. Add all tools to the agent
tools = [wikipedia, web_search, api_tool]
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # ReAct-style agent
verbose=True
)
# 3. User input
user_query = "What's the latest news about NASA on Wikipedia and the web? Also, fetch the NASA API homepage."
# 4. Agent workflow: will pick the right tool for each part of the request
response = agent.run(user_query)
print(response)
The agent will parse the user’s complex query, decide which tool(s) to use (Wikipedia for encyclopedic information, DuckDuckGo for up-to-date news, RequestsGetTool for API fetches), and combine the results in its response.
AgentType.ZERO_SHOT_REACT_DESCRIPTION defines how to build a ReAct-style agent that can reason over which tool to use for each part of a user query.
Memory
In contrast to a single LLM call, many applications (such as chatbots) must maintain context from previous interactions. LangChain’s memory modules store conversation history, summaries, or other states. For each new prompt to the LLM, the relevant past information is retrieved from memory and included as context.
The most commonly used memories include:
- ConversationBufferMemory: The entire conversation history is stored in a single sequential buffer (all messages).
- ConversationBufferWindowMemory: Only the last N messages are stored. This “window” of recent exchanges slides over a conversation and can be used when a full history is too long (exceeding a context length limit).
- ConversationSummaryMemory: It is similar to ConversationBufferMemory, but rather than storing all messages directly, it maintains a running summary of past interactions. This is useful for distilling the salient information from a long conversation.
- VectorStore-backed Memory: Facts or embeddings are stored in a vector database, enabling long-term memory and semantic search capabilities beyond recent text.
Other memories include ConversationSummaryBufferMemory (a hybrid of buffer and summary memory) and EntityStoreMemory (tracks entities). However, if you are starting a new project, it is ideal to use the latest memory management patterns, such as RunnableWithMessageHistory, for more flexibility and control.
For instance, a chatbot chain can retrieve previous dialogue turns to maintain coherence in conversation. This enables applications to maintain context over long-form chats, which is critical for coherent multi-turn responses.
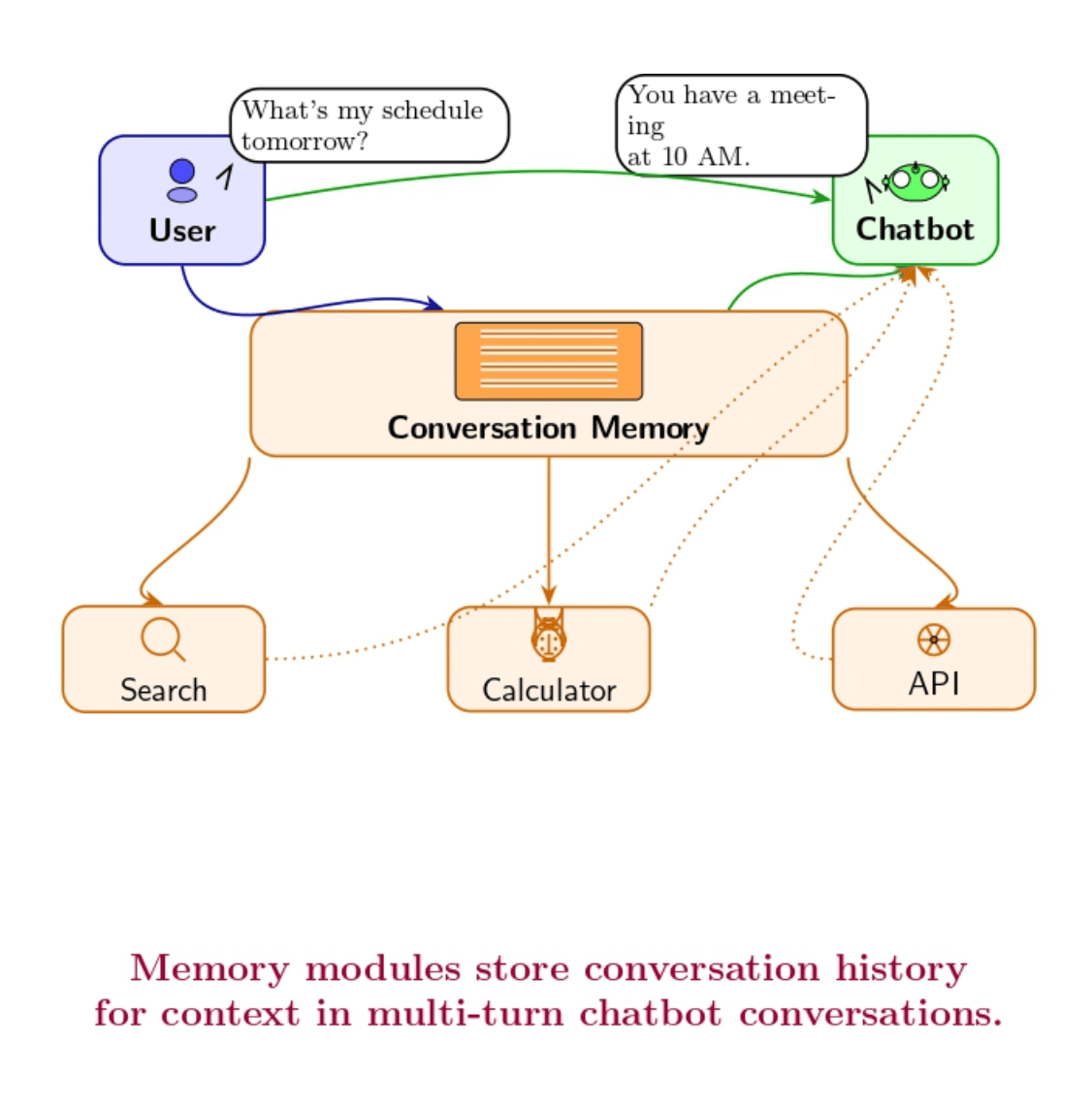
Key Notes:
- The user sends a message, which is added to the memory.
- The chatbot accesses the memory to maintain continuity and coherence.
- If necessary, the chatbot uses external tools to gather information before responding.
Tools
In LangChain, a tool represents any external function or API that an agent can call
LangChain has a large number of built-in tools, including:
- Web search API (SerpAPI) – the LLM can ask it to search the internet.
- Python REPL – run Python code (useful for math, data manipulation, etc).
- Database query tools – e.g., connect to an SQL database and query it.
- Browser or Scraper – navigate webpages (often used via Playwright or similar wrappers).
- Calculator – a simple math evaluator.
- …and many more, but you can also create your own tools (any Python function can be a tool).
Tools enable the LLM to fetch data or otherwise perform actions beyond its training data and capabilities. When running an agent, the LLM may output an “action” that tells which tool to run and with what input. This allows us to prevent hallucinations and ground the AI’s output to real data.
Indexes (Vector Stores)
Most LangChain apps use retrieval-augmented generation, where the LLM’s answers are grounded in a corpus of documents. To enable RAG, LangChain supports integration with vector databases (also known as vector stores), which index documents using embeddings. A vector store allows you to add_documents(…) and then perform a similarity search given a query embedding.
In practice, this means you can load PDFs/web pages/etc into a LangChain-compatible vector store, and when the LLM requests relevant facts, LangChain retrieves the most similar documents. These “indexes” provide fast semantic search over large corpora of text. LangChain supports multiple vector database backends (such as Pinecone, Weaviate, Chroma, etc) all through a common interface.
LangChain Architecture
LangChain provides a modular, layered architecture. There are distinct layers, each with a specific role. This design enables developers to build, scale, and customize LLM-powered applications. The ecosystem is organized as follows:
- langchain-core: This library contains essential abstractions such as LLMs, prompts, messages, and the underlying Runnable interface. This package defines the standard building blocks upon which the LangChain feature is built.
- Integration Packages: For each supported LLM provider or external tool (OpenAI, Google, Redis, etc. ), there is an integration package (langchain-openai, langchain-google, langchain-redis, etc.) that includes lightweight adapters. These adapters wrap the provider’s API and expose them as LangChain components.
- langchain (Meta-Package): This meta-package includes prebuilt chains, agents, and retrieval chains. Installing Langchain provides you with the core framework along with the most popular features for LLM workflow orchestration.
- langchain-community: It contains connectors and integrations developed by the community. It is a collaborative space for the community to build out support for new databases, APIs, and third-party tools to extend LangChain’s integrations.
- LangGraph: LangGraph features a flexible orchestration layer for more advanced scenarios. Developers can build stateful, streaming, production-ready LLM applications by orchestrating multiple chains and agents, with persistence and strong state management. While it is closely integrated with LangChain, you can also use it to manage more complex workflows and orchestration needs.
Practically, you would install Langchain and then import the required components. Chains, for example, are classes found in langchain.chains, Agents are in langchain.agents and there are subpackages for Models, Embeddings, Memory, etc. Using LangChain, you can abstract away the differences between model providers. This way, your code can easily switch between OpenAI, Anthropic, Azure, Hugging Face, etc., by changing the model specification.
Let’s look at the basic Python code example below. You can see how easy it is to switch between LLM providers:
# Install: pip install langchain langchain-openai langchain-anthropic
import os
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
# 1. Set your API key(s)
# For OpenAI:
os.environ["OPENAI_API_KEY"] = "your-openai-api-key-here" # Replace with #your OpenAI API key
# For Anthropic (if you want to use Claude):
os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-api-key-here" # Replace #with your Anthropic API key
# 2. Choose a model provider (swap between OpenAI and Anthropic)
# Uncomment one of the following lines depending on the provider you want to #use:
llm = ChatOpenAI(model="gpt-3.5-turbo")
# llm = ChatAnthropic(model="claude-3-opus")
# 3. Create a prompt template
prompt = ChatPromptTemplate.from_template("Tell me a fun fact about {topic}.")
# 4. Compose the chain using the chaining operator
chain = prompt | llm
# 5. Run the chain with user input
response = chain.invoke({"topic": "space"})
print(response.content)
Key Notes:
- For OpenAI: ChatOpenAI (from langchain_openai)
- For Anthropic: ChatAnthropic (from langchain_anthropic)
- Use chain.invoke() for synchronous calls.
- You can swap llm = ChatOpenAI(…) with llm = ChatAnthropic(…) in one line.
- You must set the API keys ( for example, OPENAI_API_KEY, ANTHROPIC_API_KEY) as environment variables or pass them to the model constructor.
Popular Use Cases
LangChain is designed to help developers and technical leaders build fast, efficient LLM-powered applications to solve various real-world challenges. LangChain supports a set of use cases described in the following table:
| Use Case | Overview | LangChain Features | Benefits |
|---|---|---|---|
| Retrieval‑Augmented QA (RAG) | Build Q&A systems grounded in your data, reducing hallucinations and ensuring up‑to‑date responses. | Document loaders, text splitters → embeddings → vector store retrievers → RetrievalQA chain; supports Pinecone, FAISS, etc | Accurate, verifiable answers with dynamic updates—no need to retrain models. |
| Chatbots & Conversational Agents | Create stateful chatbots with full history, memory, and streaming/persona support. | RunnableWithMessageHistoy Memory modules & prompt templates | Context-rich dialogue and coherent, persona-driven conversation management. |
| Autonomous Agents | Agents that plan and execute multi-step workflows autonomously, maintaining the memory of previous steps. | Plan‑and‑Execute agents, ReAct agents, agent loop frameworks, memory | Enables planning, tool execution, and runtime adaptation in autonomous workflows. |
| Data Q&A & Summarization | Natural-language querying or summarizing PDFs, spreadsheets, articles, etc. Supports step‑by‑step reasoning over documents. | Document loaders, text splitters, embeddings, chain-of-thought prompts | Efficient processing of lengthy texts with hierarchical summarization and Q&A. |
In summary, if your LLM app requires chaining multiple steps together, integrating external data, or maintaining context, LangChain has components to assist you. The list above is far from exhaustive—developers are building entirely new types of applications by uniquely combining LangChain building blocks.
LangChain vs Alternatives
Find below a comparison between LangChain and two of its most widely used alternatives, LlamaIndex and Haystack, to help you make an informed decision about which tool best suits your project:
| Framework | Key Features & Comparison |
|---|---|
| LlamaIndex (formerly GPT Index) | Purpose-built for RAG: Provides simple APIs to load data, build vector indexes, and query them efficiently. Strength: Lightning-fast document retrieval and search with minimal configuration. LangChain vs LlamaIndex: While LangChain excels at agentic, multi-step workflows and LLM orchestration (think chatbots, assistants, pipelines), LlamaIndex is streamlined for retrieval and semantic search. LlamaIndex is adding more workflow and agent support, but LangChain remains the more flexible option for complex, multi-component applications. |
| Haystack | Robust Python framework for NLP and RAG: Started as an extractive QA tool, now supports pipelines for search, retrieval, and generation. Strength: High-level interface, great for search-centric or production-grade retrieval systems. LangChain vs Haystack: LangChain offers deeper agent tooling, composability, and custom agent design. Haystack’s recent “Haystack Agents” add multi-step reasoning, but LangChain still offers more flexibility for highly customized agentic systems. Hybrid Approach: Many teams combine LangChain’s agent orchestration with Haystack’s retrievers or pipelines, leveraging the best of both ecosystems. |
| Other Tools | Includes Microsoft Semantic Kernel, OpenAI Function Calling, and more. Most are focused on specific scenarios such as search or dialogue orchestration. LangChain advantage: The largest collection of reusable agents, chains, and orchestration primitives, supporting true end-to-end LLM applications and rapid prototyping for complex workflows. |
It’s important to note that each tool has its strengths. Often, development teams can use them together to benefit from advanced retrieval functionality and flexible orchestration. Weigh up your project’s complexity and goals when choosing a framework (and don’t be afraid to try a hybrid approach if necessary).
Getting Started with LangChain in Python
Here’s a step-by-step guide to getting started with LangChain in Python, from installation to running your first demo.
1. Prerequisites
Before you begin, make sure you have the following in your environment:
- Python 3.8 or higher
- pip (Python package manager)
- (Optional, but recommended) Use a virtual environment to manage dependencies
2. Installation
Open your terminal or command prompt and run the following command to install the core LangChain package:
pip install langchain
To work with OpenAI models and other popular providers, you’ll need to install the corresponding integration packages. For OpenAI, run:
pip install langchain-openai
LangChain’s modular approach allows you to install only the integrations you need.
3. Setting Up Your API Key
Option 1: Set as an environment variable.
- On macOS/Linux:
export OPENAI_API_KEY=“your_openai_api_key_here”
- On Windows:
set OPENAI_API_KEY=“your_openai_api_key_here”
Option 2: Use a .env file (recommended for local development):
- Install python-dotenv:
pip install python-dotenv
- Create a .env file in your project directory:
OPENAI_API_KEY=your_openai_api_key_here
- At the top of your Python script, add:
from dotenv import load_dotenv
load_dotenv()
4. Running a Simple LangChain Demo
Let’s consider the simple code example using OpenAI’s GPT-3.5 Turbo Instruct model:
# If using a .env file, load environment variables
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
# Create a prompt template
prompt = PromptTemplate.from_template("Answer concisely: {query}")
# Initialize the OpenAI LLM
llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0)
# Compose the chain
chain = prompt | llm
# Run the chain with a sample query
answer = chain.invoke({"query": "What is LangChain used for?"})
print(answer)
Key Points:
- Imports: Import langchain_openai for OpenAI models, and langchain_core.prompts for prompt templates.
- PromptTemplate: Defines your prompt’s structure with placeholders.
- Chaining: The | operator pipes the prompt into the model.
- Invocation: Call chain.invoke() with your input to get a response.
LangChain manages all the API calls and formatting under the hood. You don’t have to write your own HTTP requests or manage conversation tokens manually. As you build out your app, you might incorporate additional chains, tool-supported agents, or a memory component. However, even this basic demo illustrates how concise the LangChain code can be.
Conclusion
LangChain is a flexible, modular framework that simplifies building advanced LLM-powered applications. Its component-based architecture, extensive building blocks, and integration capabilities allow you to easily connect your language models to external data, tools, and workflows.
Whether you’re building a chatbot, a RAG-powered assistant, or a complex multi-agent system, LangChain provides the foundation and flexibility to launch your AI projects. As the ecosystem evolves, it can also be combined with other tools, such as LlamaIndex, Haystack, etc., to enhance your application’s capabilities.
If you have intensive LLM workloads (large models, long contexts), you’ll want to take advantage of a GPU-backed environment. Cloud providers like DigitalOcean’s GPU droplets are cost-effective and can be used to launch GPU instances that are optimized for running LangChain models at scale.
To get started, follow the setup instructions provided above. You can also check LangChain’s official documentation and the growing community resources.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
