
Introduction
When deciding which server architecture to use for your environment, there are many factors to consider, such as performance, scalability, availability, reliability, cost, and management.
In this tutorial, you will learn about commonly used server setups, with a short description of each, including the pros and cons. Keep in mind that all of the concepts covered here can be used in various combinations with one another and that every environment has different requirements, so there is no single correct configuration.
Setting Up Everything On One Server
One server setup is when an entire environment resides on a single server. For a typical web application, this includes the web server, application server, and database server. A common variation of this setup is a LAMP stack, which stands for Linux, Apache, MySQL, and PHP, on a single server. An example use case for this is when you want to set up an application quickly. A basic setup like this can be used to test an idea or get a simple web page up and running.
Unfortunately, this offers little in the way of scalability and component isolation. Additionally, the application and the database contend for the same server resources such as CPU, Memory, I/O, and more. As a result, this can possibly cause poor performance and make it difficult to determine the root cause. Using one server is also not readily horizontally scalable. You can learn more about horizontal scaling in our tutorial on Understanding Database Sharding. Learn more about LAMP stack as well in our tutorial on How To Install LAMP on Ubuntu 22.04. The following is a visual representation of using a single server:
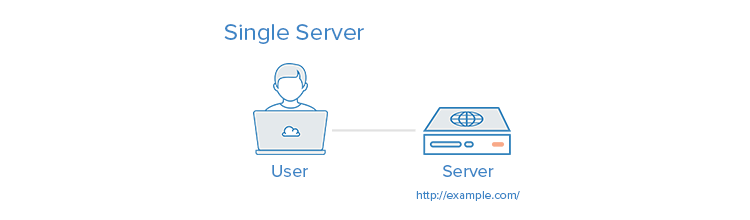
Setting Up a Separate Database Server
The database management system (DBMS) can be separated from the rest of the environment to eliminate the resource contention between the application and the database, and to increase security by removing the database from the DMZ, or public internet.
An example use case is that this can get your application set up quickly and prevents the application and database from fighting over the same system resources. You can also vertically scale each application and database tier separately. This is possible by adding more resources to whichever server needs increased capacity. Depending on your setup, this may also increase security by removing your database from the DMZ.
This setup is slightly more complex than a single server. Performance issues, like high latency, can arise if the network connection between the two servers is geographically distant from each other. There can also be performance issues if the bandwidth is too low for the amount of data being transferred. You can read more on How To Set Up a Remote Database to Optimize Site Performance with MySQL. The following is a visual representation of using a separate database server:
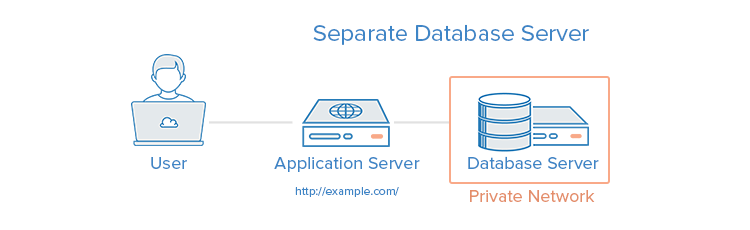
Setting Up a Load Balancer (Reverse Proxy)
Load balancers can be added to a server environment to improve performance and reliability by distributing the workload across multiple servers. If one of the load balanced servers fails, the other servers will handle the incoming traffic until the failed server becomes healthy again. It can also be used to serve multiple applications through the same domain and port, by using a layer 7 application layer reverse proxy. A few types of software capable of reverse proxy load balancing are HAProxy, Nginx, and Varnish.
An example use case is in an environment that requires scaling by adding more servers, also known as horizontal scaling. When you set up a load balancer, it enables an environment capacity that can be scaled by adding more servers to it. It can also protect against DDOS attacks by limiting client connections to a sensible amount and frequency.
Setting up a load balancer can introduce a performance bottleneck if the load balancer does not have enough resources, or if it is configured poorly. It can also present complexities that require additional consideration, such as where to perform SSL termination and how to handle applications that require sticky sessions. Additionally, the load balancer is a single point of failure, this means that if it goes down, your whole service can go down. A high availability (HA) setup is an infrastructure without a single point of failure. To learn how to implement an HA setup, you can read our documentation on Reserved IPs. You can read more in our guide on An Introduction to HAProxy and Load Balancing Concepts as well. The following is a visual representation of setting up a load balancer:
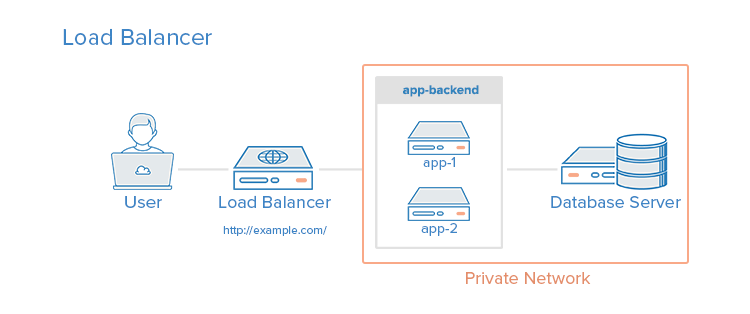
Setting Up an HTTP Accelerator (Caching Reverse Proxy)
An HTTP accelerator, or caching HTTP reverse proxy, can be used to reduce the time it takes to serve content to a user through a variety of techniques. The main technique employed with an HTTP accelerator is caching responses from a web or application server in memory, so future requests for the same content can be served quickly, with less unnecessary interaction with the web or application servers. A few examples of software capable of HTTP acceleration are Varnish, Squid, Nginx. An example use case is in an environment with content-heavy dynamic web applications or many commonly accessed files.
HTTP acceleration can increase site performance by reducing CPU load on a web server, through caching and compression, thereby increasing user capacity. It can also be used as a reverse proxy load balance, and some caching software can even protect against DDOS attacks. Unfortunately, it can reduce performance if the cache-hit rate is low, and requires tuning to get the best performance out of it. The following is a visual representation of setting up an HTTP Accelerator:
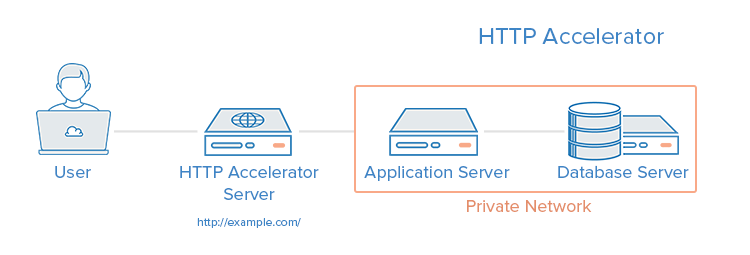
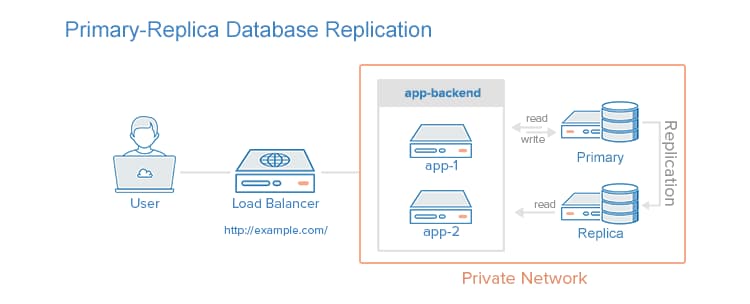
Setting up Primary-replica Database Replication
One way to improve performance for a database system that performs many reads compared to writes, such as a CMS, is to use primary-replica database replication. Replication requires one primary node and one or more replica nodes. In this setup, all updates are sent to the primary node and reads can be distributed across all nodes. An example use case is increasing the read performance of the database tier of an application. Setting up a primary-replica database replication improves database read performance by spreading reads across replicas, and improves write performance by using exclusively for updates, with no time spent on serving read requests.
Some of the cons for primary-replica database replication are that the application accessing the database must have a mechanism to determine which database nodes it should send update and read requests to. Also, if the primary fails, no updates can be performed on the database until the issue is corrected. It also does not have built-in failover in a case of failure of primary node. The following is a visual representation of a primary-replica replication setup, with a single replica node:
Combining the Concepts
It is possible to load balance the caching servers, in addition to the application servers, and use database replication in a single environment. The purpose of combining these techniques is to reap the benefits of each without introducing too many issues or complexity. Here is an example diagram of this type of server environment set up:
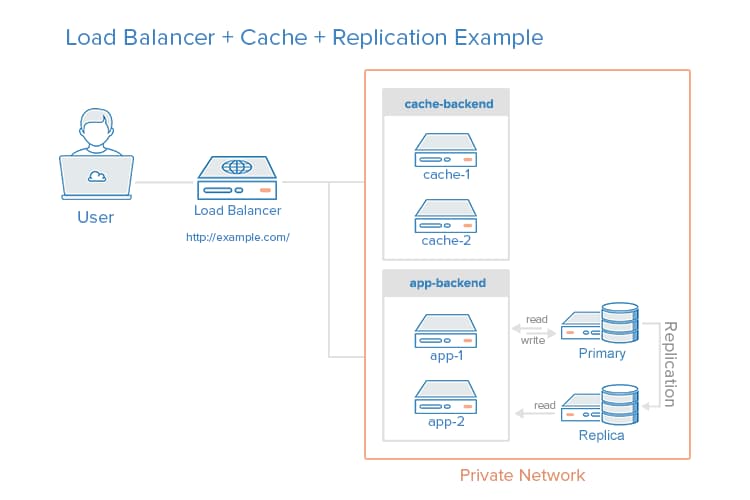
For example, imagine a scenario where the load balancer is configured to recognize static requests (like images, CSS, JavaScript, etc.) and send those requests directly to the caching servers, and send other requests to the application servers.
Here is a breakdown of the process when a user sends a request for dynamic content:
- The user requests dynamic content from http://example.com/ (load balancer)
- The load balancer sends the request to the app-backend
- The app-backend reads from the database and returns requested content to load balancer
- The load balancer returns requested data to the user
When a user requests static content, the following process applies:
- The load balancer checks the cache-backend to confirm if the requested content is cached (cache-hit) or not (cache-miss)
- If the content is cache-hit this means it will return the requested content to the load balancer and jump to the final step in the process and return the data to the user. If the content is cache-miss, the cache server forwards the request to the app-backend through the load balancer
- The load balancer forwards the request through to app-backend
- The app-backend reads from the database and returns requested content to the load balancer
- The load balancer forwards the response to cache-backend
- The cache-backend caches the content and returns it to the load balancer
- The load balancer returns requested data to the user
This environment still has two single points of failure, the load balancer and the primary database server, but it provides all of the other reliability and performance benefits that were described in previous sections.
Conclusion
Now that you are familiar with some basic server setups, you should have a good idea of what kind of setup you would use for your own application(s). If you are working on improving your own environment, remember that an iterative process is best to avoid introducing too many complexities too quickly.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Software Engineer @ DigitalOcean. Former Señor Technical Writer (I no longer update articles or respond to comments). Expertise in areas including Ubuntu, PostgreSQL, MySQL, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
And Google App Engine gives all of that for free, plus
- Master-master replication, which gives you almost infinite horizontal scaling.
- Automatically replicates your data over datacenters/continents, so even whole datacenter failure won’t make your unavaliable.
- Serves static content (HTML, CSS, JS, images) without even touching your server, from Google’s distributed Content Delivery Network.
- Secures HTTPS requests automatically, no need to obtain/install/manage SSL certificates.
- Many more.
And all of that automatically, you don’t worry how it works inside.
Awesome article, can you write another one that includes Snort level security threat detection? ;)
@dlazerka whilst we’re at it, why don’t we suck all of the fun out of the web development as well, and just go for a prebuilt system? Recommending people use something out of the tin rather than learning how it works is setting them up for failure. Live a little, learn a little.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
