By Adrien Payong and Shaoni Mukherjee

Introduction
Modern data-driven companies all rely on data pipelines that fetch, transform, enrich, and move information from one location to another. These data pipelines might involve many steps (extracting the raw data, cleaning it, training machine‑learning models, building dashboards, etc. ). Additionally, they must run in a very specific order. Workflow orchestration tools such as Apache Airflow help ensure that all these steps run at the right time and in the right order. They also make pipelines easy to monitor and manage.
Airflow was built at Airbnb in 2014 and has become one of the most popular open‑source workflow orchestration platforms. It is used by thousands of organisations to automate and monitor batch pipelines. In this article, we explain Apache Airflow from the ground up. Topics we’ll cover include:
- What Airflow is, what it does, and why data teams use it.
- The core concepts and components of Airflow, and how they fit together.
- How pipelines are defined as Directed Acyclic Graphs (DAGs) and a walkthrough of a simple DAG in action.
- Common use cases such as ETL/ELT, MLOps, and more.
We hope this will be a practical, example‑driven introduction to Apache Airflow for engineers, students, and teams who are getting started with workflow orchestration.
Key Takeaways
- Apache Airflow is a Python-based workflow orchestration platform that manages, schedules, and monitors complex data pipelines using DAGs (Directed Acyclic Graphs).
- DAGs define tasks and their dependencies, allowing Airflow to execute each step in the correct order with built-in retries, logging, and observability.
- Airflow’s architecture (Scheduler, Executor, Worker, Metadata DB, Web UI) enables scalable, distributed execution and real-time monitoring of pipelines.
- Airflow excels in batch workflows such as ETL/ELT jobs, ML training pipelines, data quality checks, and scheduled analytics — but is not ideal for real-time or ultra-high-frequency workloads.
- Alternatives like Prefect, Dagster, Luigi, Argo Workflows, and Mage AI may be better suited depending on needs such as event-driven workflows, Kubernetes-native execution, or modern developer-friendly interfaces.
What Is Apache Airflow?
Apache Airflow is an open-source system for authoring, scheduling, and monitoring workflows. An Airflow workflow is a DAG (a directed acyclic graph), which is a series of tasks with clearly defined relationships (dependencies) and without any cycles (a task can’t repeat itself upstream). Airflow’s core philosophy is “configuration as code,” so instead of using a UI with a drag-and-drop interface, you author Python scripts to represent workflows. This approach provides significant flexibility for engineers: you can connect to almost any technology via Airflow’s operators and Python libraries. You can also apply software engineering best practices (version control, testing, etc) to your pipeline definitions.
Why does workflow orchestration matter?
The key point is that often you have multiple steps in any data workflow that must be executed in sequence. A simple example is the ETL (Extract/Transform/Load) pipeline. Pipelines can quickly become more complex as you add more tasks, dependencies, branching, and so on, and also need to run on a regular cadence. Manual intervention or simple scheduler tools often become inadequate in these cases. Airflow solves this by acting as a central orchestrator. It has a directed acyclic graph (DAG) of tasks (nodes) with dependencies (edges). It knows when to execute which task (waiting for upstream dependencies to complete before running), including scheduling (periodic interval execution), error handling (automatic retries, alerts), and logging.
If we consider the entire data pipeline to be a recipe, then each individual task is a sub-step (chopping, boiling, plating, etc.). Airflow is like the kitchen manager who knows the recipes and keeps an eye on all the different sub-steps happening in each kitchen, making sure that everything happens in the correct order and at the right time.
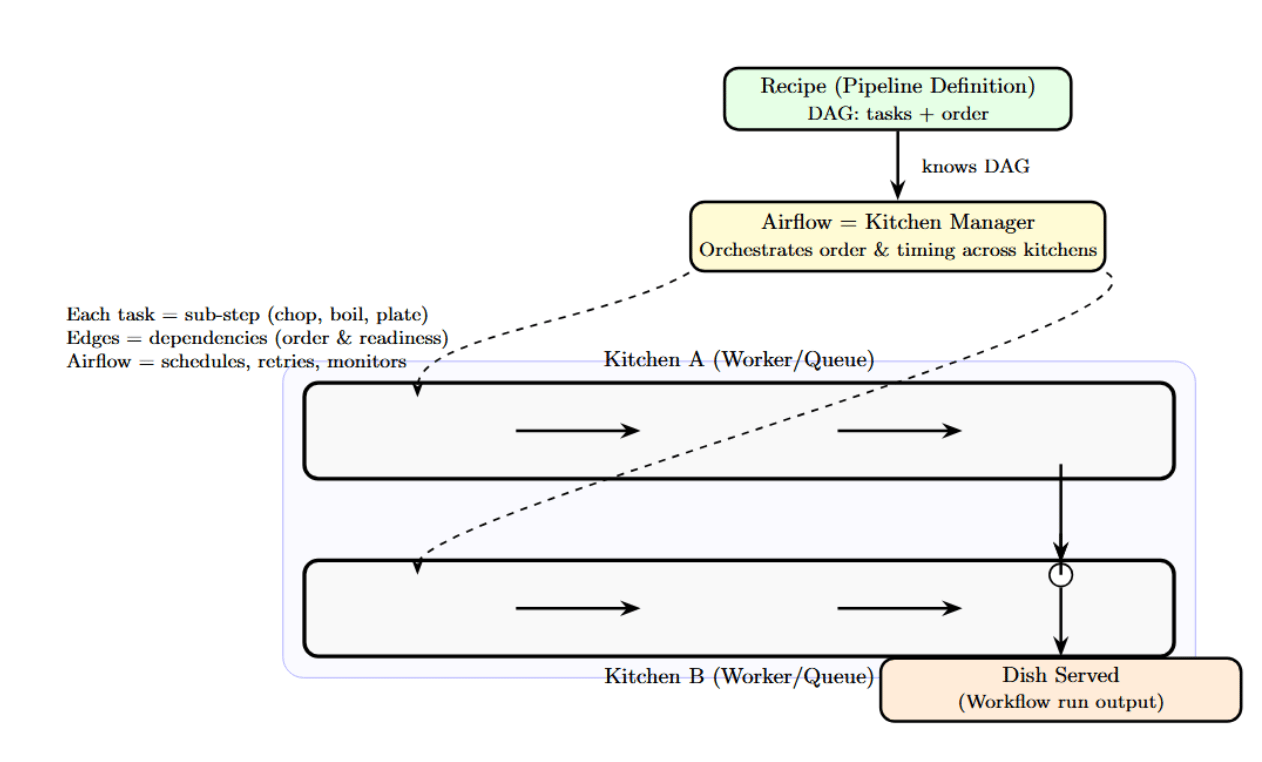
Without workflow orchestration, you may have all the chefs and ingredients, but they are not coordinated. Airflow provides that coordination, allowing for the production of the desired “dish” (workflow run).
Why Do Data Teams Use Airflow?
Airflow has become popular among data engineers, ML engineers, and DevOps teams because it addresses many needs of complex data pipelines. Here are a few big reasons why teams choose Airflow:
- Orchestrating Complex Workflows & Dependencies: Airflow was designed for workflows with a large number of interdependent steps. Airflow makes it easy to declare upstream and downstream requirements, ensuring that tasks execute in proper order. If task C depends on tasks A and B, the Airflow scheduler is aware of these relationships and will ensure that A and B run (potentially in parallel) before running C. Airflow can deal with complex dependencies, branching logic, etc.
- Centralized Scheduling (Cron on Steroids): It provides a scheduler that allows you to execute tasks on a certain schedule. You could define dozens or hundreds of pipelines that trigger tasks at different times (hourly, daily, monthly) using Airflow’s scheduler. Airflow understands task relationships. It can intelligently schedule and trigger tasks to run. The central scheduler frees you from having to write different scripts on different servers.
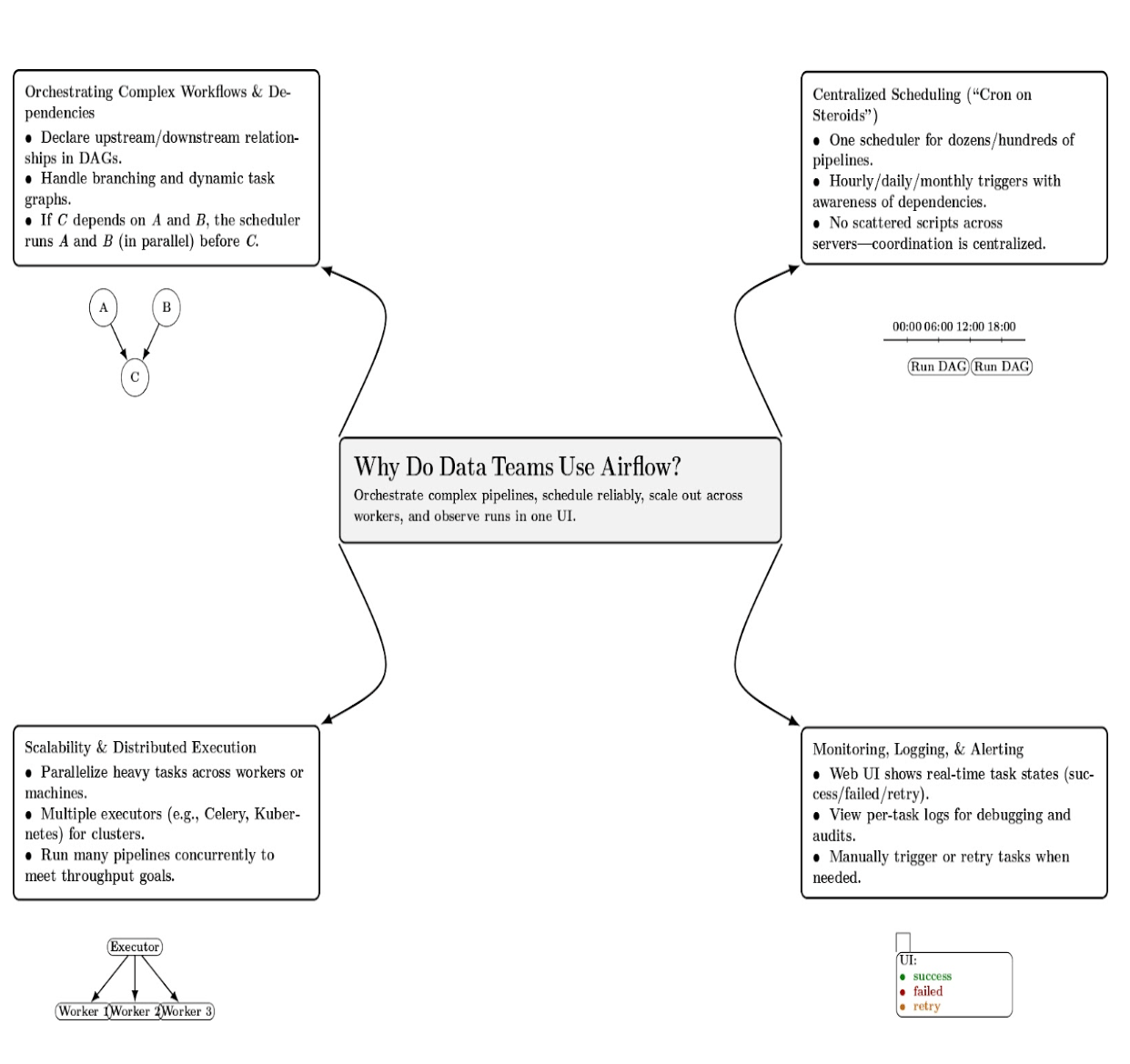
- Scalability and Distributed Execution: Airflow can also scale with your workflows. It can be configured to execute tasks in parallel across multiple worker processes or machines. It also provides multiple executors (discussed later in this article) that can run tasks on distributed systems such as Celery or Kubernetes across a cluster of nodes. This means you can parallelize heavy tasks ( big data processing) and have multiple pipelines running concurrently.
- Monitoring, Logging, and Alerting: It ships with a rich web UI that provides real-time visibility into your workflows. You can see which tasks have succeeded and which have failed, and view the log output for each task. You can even manually trigger and/or retry tasks via the web interface.
Key Components of Airflow
Below is a brief overview of Apache Airflow’s core building blocks. Use this table as a quick reference to understand what each component is and what it does.
| Component | What it is | Core responsibilities |
|---|---|---|
| DAGs (Directed Acyclic Graphs) | The workflow blueprint is written in Python; a graph of tasks with dependencies and no cycles. | Defines which tasks run and in what order; encodes schedule and metadata; enables visualization in the UI. |
| Tasks | The smallest unit of work (node in the DAG graph) is instantiated from operators or TaskFlow functions. | Executes a specific action (e.g., run SQL, call Python, trigger API, move files); reports success/failure. |
| Scheduler | A persistent service that evaluates DAGs and task states continuously. | Determines when each task should run based on schedules and dependencies; creates task instances; manages retries and backfills. |
| Executor (and Workers) | The execution backend and processes that actually run tasks. | Launches task instances on the chosen backend (local process/thread, Celery workers, Kubernetes pods); returns results to the Scheduler. |
| Web Server (Web UI) | The operational user interface served by Airflow’s webserver. | Observability and control: view DAGs, trigger/clear tasks, inspect logs, pause DAGs, manage connections/variables. |
| Metadata Database | The persistent system of record (PostgreSQL/MySQL typically). | Stores DAG runs, task instances, and states, configurations, logs metadata, and operational history. |
How Airflow Works (Architecture)
Here’s a step-by-step overview of how Airflow processes a workflow (DAG):
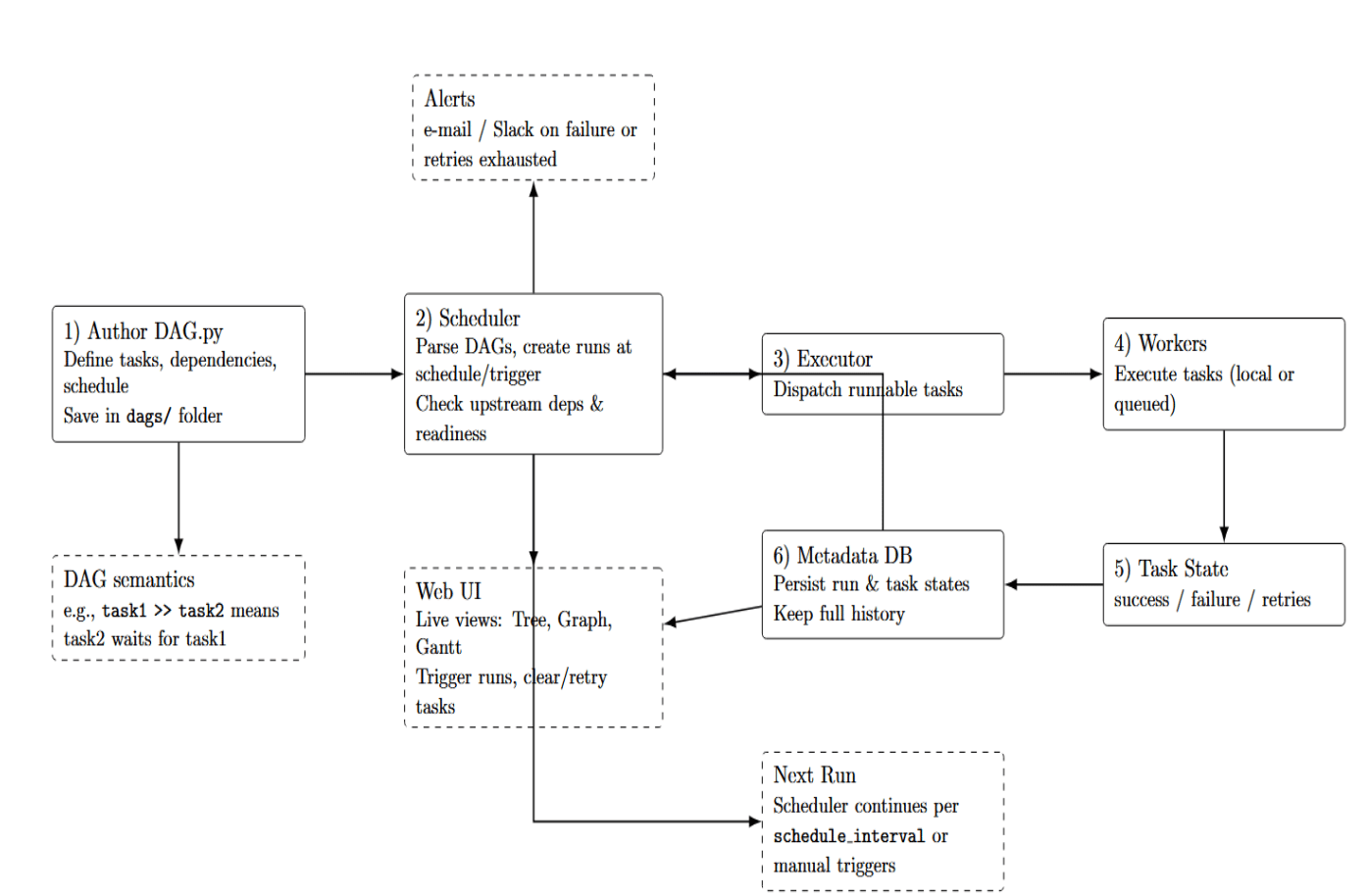
- Authoring the DAG: The DAG author writes a Python script that defines a DAG. This script includes things such as the schedule (e.g., “run daily at 9 AM”) or trigger manual settings. It also contains the definitions of the tasks (via operators or @task functions), as well as the task dependencies (e.g., task1 >> task2(task2 waits for task1 to finish)). The Python file is saved in Airflow’s DAGs folder to be found by Airflow. Airflow will read (parse) this file periodically to load the DAG definition.
- Scheduling and DAG Parsing: Airflow Scheduler is a process that runs continuously in the background. It checks if each DAG should be run based on its schedule or triggers. For example, a DAG with a schedule of “daily” can be picked up by the scheduler, and notice that a new run must be scheduled at midnight. Airflow Scheduler also checks if tasks within DAGs are ready to run – meaning that all their upstream dependencies are complete and their scheduled time (logical date) has arrived.
- Executing Tasks: Each task to be executed is handed over to the Executor from the Scheduler. The executor decides where and how to run the task. It could be executed locally or sent to a worker queue. For a distributed architecture, the task will be added to a queue and then selected by Worker processes that execute tasks.
- Updating State & Error Handling: Each task instance reports its status (success, failure, etc.) back to the scheduler as it completes, and the scheduler updates its metadata database with the task state.
State tracking is what allows the scheduler to know what to do next – for example, if Task A has completed successfully, it knows that it can schedule Task B now, or if Task A has failed with retries left, it schedules a retry, or if it failed with no retries remaining, it marks the DAG run as failed. If a task fails, Airflow has logic to automatically retry the task if configured for retries. If it continues to fail after retries, Airflow can alert on failures (send an email or Slack message, etc. ). All of these are configurable as part of the DAG or task parameters (for example, number of retries, retry delay, email to send on alert). - Monitoring and Intervention: Airflow Web UI provides a live interface of the above process. You can see a DAG run show up (for example, a new line in the Tree view for a run of today), and watch task statuses change as they progress. The Graph view visualises the DAG’s tasks, and shows which ones have completed or errored.
- Cleanup and Next Run: When a DAG run is completed (all tasks have succeeded or have been skipped/failed), Airflow moves on to the next scheduled run. All metadata about past runs is still kept in the database, and you can always check the history. The scheduler will continue to trigger new runs according to the schedule or manual triggering. This process is repeated until the Airflow process is killed.
Understanding DAGs in Airflow
A DAG in Airflow defines the schedule, and the tasks and dependencies required to execute a workflow. A DAG doesn’t have to know what’s inside each task; it just needs to define when and in what order they should run.
Tasks, operators, and sensors
Tasks are the basic units of work in Airflow. In Airflow, tasks are instances of operators, which are templates for predefined actions. Airflow comes with a variety of core operators. The BashOperator lets you run shell commands, and the PythonOperator lets you call Python functions. Airflow also provides a @task decorator, which allows you to turn a regular Python function into a task.
In addition to operators, Airflow provides sensors. Sensors are tasks that wait for a condition or event to be met before they succeed. They can be used for things such as waiting for a file to appear or a table to be populated.
Task dependencies
To declare dependencies between tasks, you use >> and << operators (recommended) or methods like set_upstream and set_downstream. It’s also possible to chain tasks, create cross‑downstream dependencies, and even dynamically build lists of tasks. A DAG without any dependencies would just be an independent set of tasks.
Best practices for DAG design
The table below presents a few guidelines to keep in mind when designing DAGs.
| Best Practice | Description | Practical Tips / Examples |
|---|---|---|
| Ensure DAGs are truly acyclic | DAGs must not contain cycles. In complex workflows, it is easy to introduce indirect loops (e.g., A → B → C → A). Airflow automatically detects cycles and refuses to run such DAGs. | Review dependencies regularly. Use Graph View to visually confirm the DAG has no loops. Refactor complex DAGs to avoid accidental cycles. |
| Keep tasks idempotent and small | Each task should perform a single logical step and be safe to rerun without corrupting data. Idempotent tasks ensure retries do not produce inconsistent results. | Use “insert or replace” patterns. Write to temp files before committing results. Split large scripts into multiple tasks. |
| Use descriptive IDs and documentation | Clear naming and documentation improve readability and maintainability in both code and the Airflow UI. | Use meaningful DAG IDs and task IDs. Add documentation using dag.doc_md or task.doc_md. Align names with business logic. |
| Leverage Airflow features | Use built-in Airflow capabilities for communication, credential handling, and pipeline coordination instead of custom logic. | Use XComs for small data sharing. Use Variables and Connections for config and secrets. Use built-in operators and hooks whenever possible. |
| Test and version control the DAG code | DAGs are code and should be maintained using proper software engineering practices: version control, testing, and CI/CD. | Store DAGs in Git. Write tests for custom operators and logic. Use local/test environments before deploying to production. |
| Avoid overloading the scheduler | Huge numbers of DAGs or heavy computations inside DAG files can slow down the scheduler. DAGs should be lightweight to parse. | Monitor scheduler performance. Split massive DAGs into smaller ones. Avoid API calls or heavy computation during DAG import. |
| Define a clear failure handling strategy | Plan how failures should be handled. Not all errors should be retried, and long-running tasks may need SLAs or alerts. | Use retries only for transient failures. Use Sensors and triggers for event-based dependencies. Set SLAs for long or critical tasks. |
Example: A Simple Airflow DAG
Nothing solidifies concepts better than an example. Let’s walk through a simple Airflow DAG code and explain its parts. This example will create a small workflow with two tasks in sequence:
from datetime import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
# Define the DAG and its schedule
with DAG(
dag_id="example_dag",
description="A simple example DAG",
start_date=datetime(2025, 1, 1),
schedule_interval="@daily", # runs daily
catchup=False
) as dag:
# Task 1: Print current date
task1 = BashOperator(
task_id="print_date",
bash_command="date"
)
# Task 2: Echo a message
task2 = BashOperator(
task_id="echo_hello",
bash_command="echo 'Hello, Airflow!'"
)
# Define dependency: task1 must run before task2
task1 >> task2
Let’s break down what’s happening here:
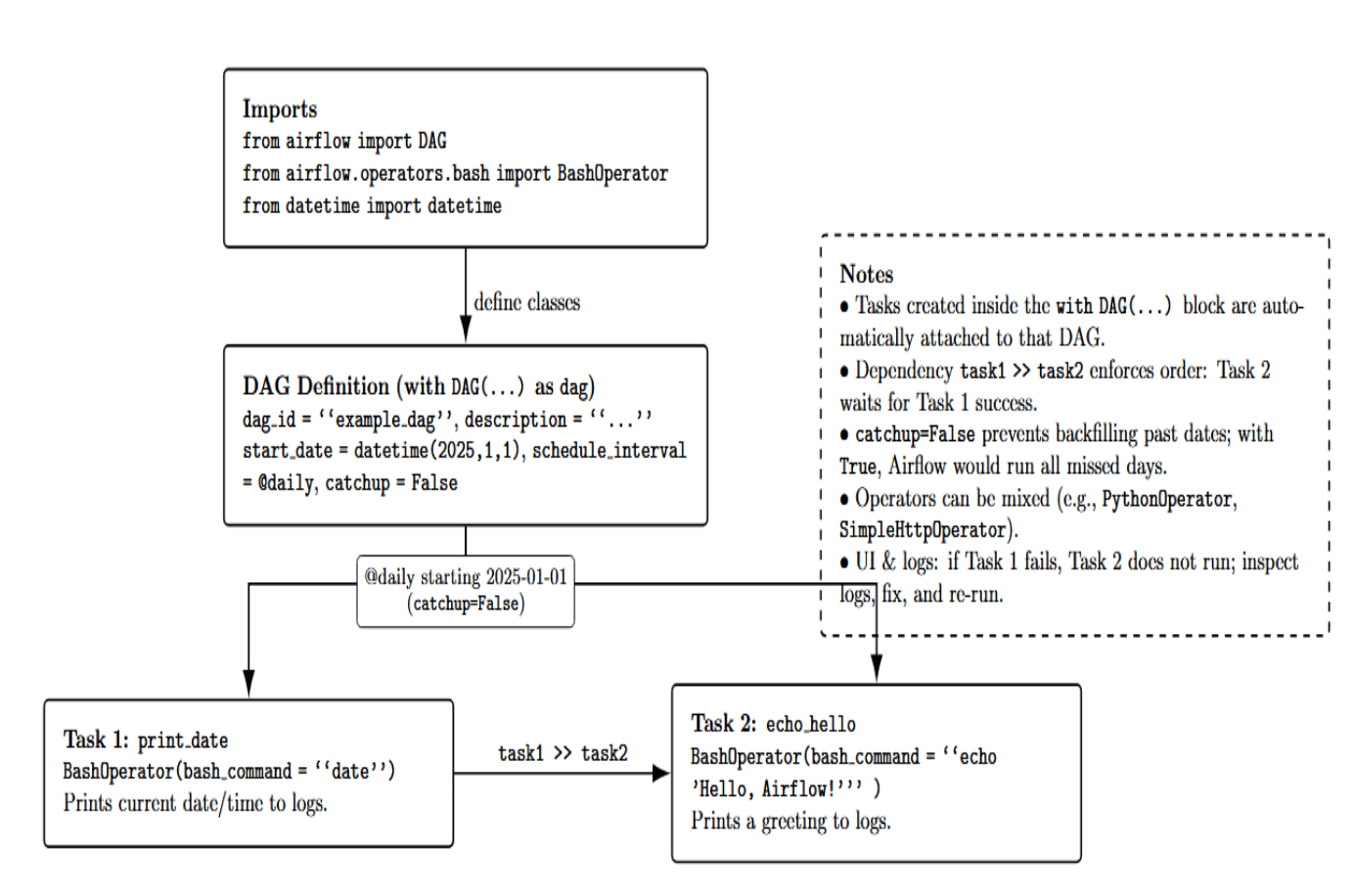
- import the required classes DAG (to define the DAG), and BashOperator (to run shell/bash commands in tasks). We also import datetime for specifying the start date of the DAG.
- We create a DAG object with a context manager (with DAG(…) as dag:). Provide the DAG with a unique ID “example_dag” (must be unique in an Airflow environment), a description(optional, to help humans read), a start_date, and a schedule_interval. Here, we set a built-in schedule_interval preset (@daily), and start_date=datetime(2025,1,1). We have also set catchup=False to prevent backfilling of any missing runs between the start_date and today (we only want it to run from now onward daily). This entire block creates a DAG that Airflow will be made aware of to run daily at the beginning of the day.
- We then define two tasks in the DAG context:
- task1 is defined using BashOperator to execute a bash command (date). task_id is “print_date” and will be used to identify this task in the UI and in logs. When it runs, this task will simply print the current date/time (to the task’s log).
- task2 also uses a BashOperator with task_id=“echo_hello”, and command=echo ‘Hello, Airflow!’. This will print a nice message.These tasks right now are just defined, not yet linked.
- The last line (task1 >> task2) specifies a dependency (flow) : task1 flows into task2. This means task 1 will run and complete successfully before task 2 can be considered for scheduling to run. Graphically, in the DAG graph, there will be an arrow pointing from task1 to task2.
A few things to note in this example:
- We only used BashOperator for simplicity, but we could have used a DAG with mixed types of operators. We could have a PythonOperator to call a Python function, or a SimpleHttpOperator to ping an API, and so on.
- The with DAG(…) as dag: context pattern is a common idiom for creating a DAG instance. All tasks that are created inside of it are automatically associated with that DAG.
- catchup=False is a parameter that is used in a lot of DAGs with a start_date in the past, when you don’t want it to run for all past dates. If we left catchup=True (the default) and today was Jan 10, 2025, Airflow would try to run the DAG for Jan 1, 2, 3, … all the way up to Jan 10, catching up on those missed days in a backlog. We turned it off here for simplicity.
- This example uses the relative import path for BashOperator. In Airflow 2, many of the operators were moved under airflow.providers. This example is written under the assumption that those providers are installed (BashOperator is in the core Airflow itself).
This simple example can be easily expanded on – you might add additional tasks (maybe make an API call, then load results to a database, then send a notification). You can also add more complex logic (like branching – Airflow supports if/else style branching using the BranchOperator, for example).
As your DAGs get bigger, Airflow’s UI and logging become invaluable for figuring out what is going on. In this example, the log for print_date would contain the system date that was printed, and the log for echo_hello would contain “Hello, Airflow!”. If print_date failed (maybe it couldn’t find the date command, in a hypothetical scenario), then echo_hello would never be executed (due to the dependency), and the DAG run would be marked as failed. You could then inspect the log, fix the problem, and re-run that task or the entire DAG.
Common Use Cases for Airflow
Below is a structured summary of common Apache Airflow use cases. The table highlights what each use case involves and how Airflow adds value in that context.
| Use Case | Description (What It Involves & Typical Steps) | How Airflow Helps / Benefits |
|---|---|---|
| ETL/ELT Data Pipelines | Moving data from multiple sources into a data warehouse or data lake using ETL (Extract–Transform–Load) or ELT patterns. | DAGs orchestrate extraction → transformation → load in the correct order. Airflow integrates with many databases and storage systems. If a step fails (e.g., API down), downstream tasks are stopped, and alerts can be triggered, improving reliability for batch and incremental syncs. |
| Data Warehousing & BI Reporting | Preparing and refreshing analytics data used in dashboards and reports. | Schedules daily or periodic jobs so reports always run against fresh data. Coordinates SQL workloads, quality checks, and reporting steps. Provides monitoring and notifications so failures (e.g., broken aggregations) are visible instead of silently corrupting BI outputs. |
| Machine Learning Pipelines | Automating end-to-end ML workflows from data preparation to deployment. | Represents each ML stage as a task in a DAG and enforces the correct ordering. Can persist artifacts between steps (preprocessed data, model binaries). Integrates with ML frameworks and Kubernetes operators and enables scheduled retraining and experiment orchestration during off-peak hours. |
| Data Quality Checks & Validation | Running automated checks to ensure data is complete, consistent, and trustworthy. | Schedules recurring data quality DAGs (daily/weekly). Coordinates checks across databases and QA scripts, alerts teams on anomalies, and can trigger downstream correction tasks as part of data reliability engineering. |
| Transactional DB Maintenance & Backups | Automating routine operational tasks for production databases and infrastructure. | Centralizes scheduling and monitoring of maintenance tasks. Ensures backups and housekeeping run consistently at defined times, reduces manual effort and human error, and provides logs/history so teams can confirm that critical maintenance jobs are completed successfully. |
| Integration / Workflow Automation | Orchestrating business or system workflows that span multiple services and APIs. | Acts as a flexible “glue” layer that connects services. DAGs encode complex branching and conditional logic. Operators and Python tasks enable custom integrations. Provides a central place to manage, monitor, and retry business process steps instead of scattering automation logic across ad-hoc scripts and tools. |
When NOT to Use Airflow
Although Airflow is powerful, it isn’t the right tool for every situation. Understanding its limitations helps you choose the correct orchestration approach:
- Real-Time or Streaming Workloads: Airflow is batch-oriented with a well-defined start and end. It’s not for long-running, event-driven, or streaming workloads. If you’re ingesting continuous streams of events (user clicks, IoT sensors, etc.) and need to process those with very low latency in real-time, Airflow isn’t the best fit.
- High-Frequency or Many Short Tasks: This is another case where Airflow may not work, or at least not efficiently. Airflow tasks have some overhead (in the database tracking, etc. ), so if you need to trigger something every few seconds or have thousands of tiny tasks, Airflow may not scale well.
- Purely Event-Driven Workflows: This is similar to the streaming use case, but for something that should be triggered by an event. “Whenever an event X happens, do Y” is a perfectly valid use case for Airflow, but if the only thing that should trigger that is an event (e.g., “whenever a file arrives in an S3 bucket, do X”), then Airflow is not the most lightweight solution here. Airflow generally uses sensors (S3KeySensor, for example) to “sense” the presence of files/events. Sensors have downsides as they rely on polling. Issues with sensors include triggering on existing files and not necessarily being responsive to events (e.g., they poll at intervals).
In short, Airflow is suitable for workflows that are periodic, batch-oriented, or complex to define and manage. It might not be a good fit if your use case requires real-time or continuous processing, ultra-frequent jobs, or very simple workflows that don’t need Airflow’s overhead. If so, you may want to explore other options or simplify your solution.
Alternatives to Airflow
The workflow orchestration space has exploded in recent years, and while Airflow is a leader, there are several alternative tools worth knowing:
| Tool / Service | Summary | Reference |
|---|---|---|
| Luigi | Open-source Python workflow scheduler created by Spotify. Good for building batch pipelines with tasks and dependencies in code. Simpler architecture and lighter-weight than Airflow, but with a smaller ecosystem and fewer built-in integrations. | Luigi documentation |
| Prefect | Python-native orchestration framework positioned as a more modern, developer-friendly alternative to Airflow. Uses Flows and Tasks, offers scheduling, retries, and observability. Can run fully open-source or with Prefect Cloud for hosted UI and control plane. | Perfect website Prefect docs |
| Dagster | Data orchestrator focused on software-defined assets and data-aware pipelines. Emphasizes type safety, testing, and development workflows. Strong fit for teams that care about data lineage, quality, and modern engineering practices. | Dagster website Dagster docs |
| Kedro | Python framework for structuring reproducible, maintainable data and ML pipelines. Focuses on project scaffolding, modular pipelines, and best practices. Often used alongside an orchestrator like Airflow rather than replacing it. | Kedro website Kedro docs |
| Argo Workflows | Kubernetes-native workflow engine implemented as a CRD. Each step runs in a container, making it ideal for cloud-native batch jobs, CI/CD, and ML pipelines in Kubernetes-heavy environments. | Argo Workflows website |
| Mage AI | Modern data pipeline tool for building, running, and managing ETL, streaming, and ML pipelines with a notebook-style, visual interface. Focuses on developer experience and fast iteration. | Mage AI website |
| Kestra | Open-source, event-driven orchestration platform using declarative YAML-based workflows. Designed for scalable, scheduled, and event-driven data and process orchestration with a strong plugin ecosystem. | Kestra website Kestra docs |
Airflow is not the only option out there, and the best choice is dependent on your use case. Luigi, Prefect, and Dagster are commonly listed as the main other open-source options in the same space (Python-based workflow orchestrators). If you find Airflow’s dated UI or other limitations cumbersome, you should consider evaluating these. Prefect attempts to be a “better” or “simpler” Airflow, Dagster tries to be a more “structured” orchestrator with an emphasis on data assets, and Luigi is a simpler predecessor to Airflow. On the other hand, if your use case diverges significantly (real-time streaming or fully cloud-native, for instance), you might not use Airflow at all and may directly consider streaming platforms or managed orchestration services.
Final Thoughts
Apache Airflow is an open-source platform to orchestrate complex computational workflows and data processing pipelines. Originally developed at Airbnb, it has gained significant popularity in the data engineering and machine learning communities. Airflow’s components include a scheduler, an executor, workers, a metadata database, and a web-based UI. This allows teams to easily run and maintain production-ready ETL, MLOps, and infrastructure pipelines. Airflow’s DAG (Directed Acyclic Graph) abstraction enables keeping workflows explicit, testable, and maintainable over time. The platform’s ecosystem of community-built operators and providers also simplifies the workflow orchestration that depends on any technology or tool.
It is not a one-size-fits-all solution, though. It works best with batch or micro‑batch pipelines, and users must be comfortable with Python. For streaming or high‑frequency workflows, there are other solutions more suitable than Airflow. For data scientists or teams preferring to write declarative pipelines, alternative tools to Airflow might be worth considering.
Airflow is still actively developed, and new features are being added over time, such as event‑driven scheduling, datasets, and assets. The concepts and best practices introduced in this guide should help you, regardless of your background, to understand how workflow orchestration works and when Airflow should be used (or not). Hopefully, this will serve as a stepping stone to further explore this rich universe.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
