By Savic, Kathryn Hancox and Fernando Pimenta

O autor escolheu o Free and Open Source Fund para receber uma doação como parte do programa Write for DOnations.
Introdução
O monitoramento de banco de dados é o processo contínuo de rastrear sistematicamente várias métricas que mostram como o banco de dados está se comportando. Ao observar os dados de desempenho, você pode obter informações valiosas e identificar possíveis gargalos, além de encontrar maneiras adicionais de melhorar o desempenho do banco de dados. Esses sistemas geralmente implementam alertas que notificam os administradores quando as coisas dão errado. As estatísticas coletadas podem ser usadas não apenas para melhorar a configuração e o fluxo de trabalho do banco de dados, mas também para os aplicativos clientes.
Os benefícios da utilização do Elastic Stack (ELK stack) para monitorar seu banco de dados gerenciado, é seu excelente suporte para pesquisa e a capacidade de ingerir novos dados muito rapidamente. Ele não se destaca na atualização dos dados, mas esse trade-off é aceitável para fins de monitoramento e logs, onde dados passados quase nunca são alterados. O Elasticsearch oferece meios poderosos de consultar os dados, que você pode usar através do Kibana para entender melhor como o banco de dados se sai em diferentes períodos de tempo. Isso permitirá que você correlacione a carga do banco de dados com eventos da vida real para obter informações sobre como o banco de dados está sendo usado.
Neste tutorial, você importará métricas de banco de dados geradas pelo coletor de estatísticas do PostgreSQL no Elasticsearch via Logstash. Isso implica em configurar o Logstash para extrair dados do banco de dados usando o conector JDBC do PostgreSQL para enviá-los ao Elasticsearch para indexação imediatamente após. Os dados importados podem ser analisados e visualizados posteriormente no Kibana. Então, se seu banco de dados for novo, você usará o pgbench, uma ferramenta de benchmarking do PostgreSQL, para criar visualizações mais interessantes. No final, você terá um sistema automatizado buscando as estatísticas do PostgreSQL para análise posterior.
Pré-requisitos
-
Um servidor Ubuntu 18.04 com pelo menos 4 GB de RAM, privilégios de root, e uma conta secundária não-root. Você pode configurar isso seguindo este guia de Configuração Inicial de servidor com Ubuntu 18.04. Para este tutorial o usuário não-root é o
sammy. -
Java 8 instalado em seu servidor. Para instruções de instalação, visite Como Instalar o Java com
aptno Ubuntu 18.04. -
Nginx instalado em seu servidor. Para um guia sobre como fazer isso, consulte Como Instalar o Nginx no Ubuntu 18.04.
-
Elasticsearch e Kibana instalados em seu servidor. Conclua os dois primeiros passos do tutorial Como Instalar Elasticsearch, Logstash e Kibana (Elastic Stack) no Ubuntu 18.04
-
Um banco de dados PostgreSQL gerenciado provisionado a partir da DigitalOcean com informações de conexão disponíveis. Verifique se o endereço IP do seu servidor está na lista permitida ou whitelist. Para saber mais sobre os bancos de dados gerenciados da DigitalOcean, visite a documentação de produto.
Passo 1 — Configurando o Logstash e o Driver JDBC para PostgreSQL
Nesta seção, você instalará o Logstash e fará o download do driver JDBC para PostgreSQL para que o Logstash possa se conectar ao seu banco de dados gerenciado.
Comece instalando o Logstash com o seguinte comando:
- sudo apt install logstash -y
Depois que o Logstash estiver instalado, habilite o serviço para iniciar automaticamente na inicialização:
- sudo systemctl enable logstash
O Logstash é escrito em Java, portanto, para conectar-se ao PostgreSQL, é necessário que a biblioteca JDBC (Java Database Connectivity) do PostgreSQL esteja disponível no sistema em que está sendo executado. Por causa de uma limitação interna, o Logstash carregará adequadamente a biblioteca apenas se for encontrada no diretório /usr/share/logstash/logstash-core/lib/jars, onde armazena bibliotecas de terceiros que ele utiliza.
Vá para a página de download da biblioteca JDBC e copie o link para a versão mais recente. Em seguida, faça o download usando curl executando o seguinte comando:
- sudo curl https://jdbc.postgresql.org/download/postgresql-42.2.6.jar -o /usr/share/logstash/logstash-core/lib/jars/postgresql-jdbc.jar
No momento da escrita deste tutorial, a versão mais recente da biblioteca era a 42.2.6, com o Java 8 como a versão runtime suportada. Certifique-se de baixar a versão mais recente; emparelhando-a com a versão Java correta que tanto o JDBC quanto o Logstash suportam.
O Logstash armazena seus arquivos de configuração em /etc/logstash/conf.d e armazena a si próprio em /usr/share/logstash/bin. Antes de criar uma configuração que coletará estatísticas do seu banco de dados, será necessário ativar o plug-in JDBC no Logstash executando o seguinte comando:
- sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-jdbc
Você instalou o Logstash usando o apt e baixou a biblioteca JDBC do PostgreSQL para que o Logstash possa usá-la para conectar-se ao seu banco de dados gerenciado. Na próximo passo, você configurará o Logstash para coletar dados estatísticos dele.
Passo 2 — Configurando o Logstash Para Coletar Estatísticas
Nesta seção, você configurará o Logstash para coletar métricas do seu banco de dados PostgreSQL gerenciado.
Você configurará o Logstash para monitorar três bancos de dados de sistema no PostgreSQL, a saber:
pg_stat_database: fornece estatísticas sobre cada banco de dados, incluindo seu nome, número de conexões, transações, rollbacks, linhas retornadas ao consultar o banco de dados, deadlocks e assim por diante. Possui um campostats_reset, que especifica quando as estatísticas foram zeradas pela última vez.pg_stat_user_tables: fornece estatísticas sobre cada tabela criada pelo usuário, como o número de linhas inseridas, excluídas e atualizadas.pg_stat_user_indexes: coleta dados sobre todos os índices em tabelas criadas pelo usuário, como o número de vezes que um índice específico foi consultado.
Você armazenará a configuração para indexar as estatísticas do PostgreSQL no Elasticsearch em um arquivo chamado postgresql.conf no diretório /etc/logstash/conf.d, onde o Logstash armazena arquivos de configuração. Quando iniciado como um serviço, ele será executado automaticamente em segundo plano.
Crie o postgresql.conf usando seu editor de textos favorito (por exemplo, o nano):
- sudo nano /etc/logstash/conf.d/postgresql.conf
Adicione as seguintes linhas:
input {
# pg_stat_database
jdbc {
jdbc_driver_library => ""
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
jdbc_user => "username"
jdbc_password => "password"
statement => "SELECT * FROM pg_stat_database"
schedule => "* * * * *"
type => "pg_stat_database"
}
# pg_stat_user_tables
jdbc {
jdbc_driver_library => ""
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
jdbc_user => "username"
jdbc_password => "password"
statement => "SELECT * FROM pg_stat_user_tables"
schedule => "* * * * *"
type => "pg_stat_user_tables"
}
# pg_stat_user_indexes
jdbc {
jdbc_driver_library => ""
jdbc_driver_class => "org.postgresql.Driver"
jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
jdbc_user => "username"
jdbc_password => "password"
statement => "SELECT * FROM pg_stat_user_indexes"
schedule => "* * * * *"
type => "pg_stat_user_indexes"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
Lembre-se de substituir host pelo seu endereço de host, port pela porta à qual você pode se conectar ao seu banco de dados, username pelo nome de usuário do banco de dados e password pela sua senha. Todos esses valores podem ser encontrados no Painel de Controle do seu banco de dados gerenciado.
Nesta configuração, você define três entradas JDBC e uma saída Elasticsearch. As três entradas extraem dados dos bancos de dados pg_stat_database, pg_stat_user_tables e pg_stat_user_indexes, respectivamente. Todos eles definem o parâmetro jdbc_driver_library como uma string vazia, porque a biblioteca JDBC do PostgreSQL está em uma pasta que o Logstash carrega automaticamente.
Em seguida, eles definem o jdbc_driver_class, cujo valor é específico da biblioteca JDBC, e fornecem uma jdbc_connection_string, que detalha como se conectar ao banco de dados. A parte jdbc: significa que é uma conexão JDBC, enquanto postgres:// indica que o banco de dados de destino é o PostgreSQL. Em seguida, vem o host e a porta do banco de dados e, após a barra, você também especifica um banco de dados ao qual se conectar; isso ocorre porque o PostgreSQL exige que você esteja conectado a um banco de dados para poder emitir quaisquer consultas. Aqui, ele está definido como o banco de dados padrão que sempre existe e não pode ser excluído, apropriadamente denominado de defaultdb.
Em seguida, eles definem um nome de usuário e a senha do usuário através do qual o banco de dados será acessado. O parâmetro statement contém uma consulta SQL que deve retornar os dados que você deseja processar — nessa configuração, ele seleciona todas as linhas do banco de dados apropriado.
O parâmetro schedule aceita uma string na sintaxe do cron que define quando o Logstash deve executar esta entrada; omiti-lo completamente fará com que o Logstash a execute apenas uma vez. Especificando * * * * *, como você fez aqui, dirá ao Logstash para executá-la a cada minuto. Você pode especificar sua própria string do cron se desejar coletar dados em diferentes intervalos.
Há apenas uma saída, que aceita dados de três entradas. Todas elas enviam dados para o Elasticsearch, que está sendo executado localmente e pode ser acessado em http://localhost:9200. O parâmetro index define para qual índice do Elasticsearch ele enviará os dados e seu valor é passado no campo type da entrada.
Quando você terminar de editar, salve e feche o arquivo.
Você configurou o Logstash para reunir dados de várias tabelas estatísticas do PostgreSQL e enviá-los ao Elasticsearch para armazenamento e indexação. Em seguida, você executará o Logstash para testar a configuração.
Passo 3 — Testando a Configuração do Logstash
Nesta seção, você testará a configuração executando o Logstash para verificar se ele extrairá os dados corretamente. Em seguida, você executará essa configuração em segundo plano, configurando-a como um pipeline do Logstash.
O Logstash suporta a execução de uma configuração específica, passando seu caminho de arquivo para o parâmetro -f. Execute o seguinte comando para testar sua nova configuração da último passo:
- sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/postgresql.conf
Pode levar algum tempo até que ele mostre qualquer saída, que será semelhante a esta:
OutputThread.exclusive is deprecated, use Thread::Mutex
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[WARN ] 2019-08-02 18:29:15.123 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2019-08-02 18:29:15.154 [LogStash::Runner] runner - Starting Logstash {"logstash.version"=>"7.3.0"}
[INFO ] 2019-08-02 18:29:18.209 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 19 keys and 39 values
[INFO ] 2019-08-02 18:29:20.195 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2019-08-02 18:29:20.667 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2019-08-02 18:29:21.221 [[main]-pipeline-manager] elasticsearch - ES Output version determined {:es_version=>7}
[WARN ] 2019-08-02 18:29:21.230 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[INFO ] 2019-08-02 18:29:21.274 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2019-08-02 18:29:21.337 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2019-08-02 18:29:21.369 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2019-08-02 18:29:21.386 [[main]-pipeline-manager] elasticsearch - ES Output version determined {:es_version=>7}
[WARN ] 2019-08-02 18:29:21.386 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[INFO ] 2019-08-02 18:29:21.409 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2019-08-02 18:29:21.430 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2019-08-02 18:29:21.444 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2019-08-02 18:29:21.465 [[main]-pipeline-manager] elasticsearch - ES Output version determined {:es_version=>7}
[WARN ] 2019-08-02 18:29:21.466 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[INFO ] 2019-08-02 18:29:21.468 [Ruby-0-Thread-7: :1] elasticsearch - Using default mapping template
[INFO ] 2019-08-02 18:29:21.538 [Ruby-0-Thread-5: :1] elasticsearch - Using default mapping template
[INFO ] 2019-08-02 18:29:21.545 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2019-08-02 18:29:21.589 [Ruby-0-Thread-9: :1] elasticsearch - Using default mapping template
[INFO ] 2019-08-02 18:29:21.696 [Ruby-0-Thread-5: :1] elasticsearch - Attempting to install template {:manage_template=>{"index_patterns"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s", "number_of_shards"=>1}, "mappings"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}
[INFO ] 2019-08-02 18:29:21.769 [Ruby-0-Thread-7: :1] elasticsearch - Attempting to install template {:manage_template=>{"index_patterns"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s", "number_of_shards"=>1}, "mappings"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}
[INFO ] 2019-08-02 18:29:21.771 [Ruby-0-Thread-9: :1] elasticsearch - Attempting to install template {:manage_template=>{"index_patterns"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s", "number_of_shards"=>1}, "mappings"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}
[WARN ] 2019-08-02 18:29:21.871 [[main]-pipeline-manager] LazyDelegatingGauge - A gauge metric of an unknown type (org.jruby.specialized.RubyArrayOneObject) has been create for key: cluster_uuids. This may result in invalid serialization. It is recommended to log an issue to the responsible developer/development team.
[INFO ] 2019-08-02 18:29:21.878 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>1, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>125, :thread=>"#<Thread:0x470bf1ca run>"}
[INFO ] 2019-08-02 18:29:22.351 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2019-08-02 18:29:22.721 [Ruby-0-Thread-1: /usr/share/logstash/lib/bootstrap/environment.rb:6] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[INFO ] 2019-08-02 18:29:23.798 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600}
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/cronline.rb:77: warning: constant ::Fixnum is deprecated
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/cronline.rb:77: warning: constant ::Fixnum is deprecated
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/cronline.rb:77: warning: constant ::Fixnum is deprecated
[INFO ] 2019-08-02 18:30:02.333 [Ruby-0-Thread-22: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/jobs.rb:284] jdbc - (0.042932s) SELECT * FROM pg_stat_user_indexes
[INFO ] 2019-08-02 18:30:02.340 [Ruby-0-Thread-23: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/jobs.rb:331] jdbc - (0.043178s) SELECT * FROM pg_stat_user_tables
[INFO ] 2019-08-02 18:30:02.340 [Ruby-0-Thread-24: :1] jdbc - (0.036469s) SELECT * FROM pg_stat_database
...
Se o Logstash não mostrar nenhum erro e registrar com êxito as linhas Selecionadas (SELECT) dos três bancos de dados, suas métricas serão enviadas ao Elasticsearch. Se você obtiver um erro, verifique todos os valores no arquivo de configuração para garantir que a máquina na qual você está executando o Logstash possa se conectar ao banco de dados gerenciado.
O Logstash continuará importando os dados em horários especificados. Você pode pará-lo com segurança pressionando CTRL+C.
Como mencionado anteriormente, quando iniciado como um serviço, o Logstash executa automaticamente todos os arquivos de configuração encontrados em /etc/logstash/conf.d em segundo plano. Execute o seguinte comando para iniciá-lo como um serviço:
- sudo systemctl start logstash
Neste passo, você executou o Logstash para verificar se ele pode se conectar ao seu banco de dados e coletar dados. Em seguida, você visualizará e explorará alguns dos dados estatísticos no Kibana.
Passo 4 — Explorando os Dados Importados no Kibana
Nesta seção, você verá como você pode explorar os dados estatísticos que descrevem o desempenho do seu banco de dados no Kibana.
No seu navegador, navegue até a instalação do Kibana que você configurou como pré-requisito. Você verá a página de boas-vindas padrão.
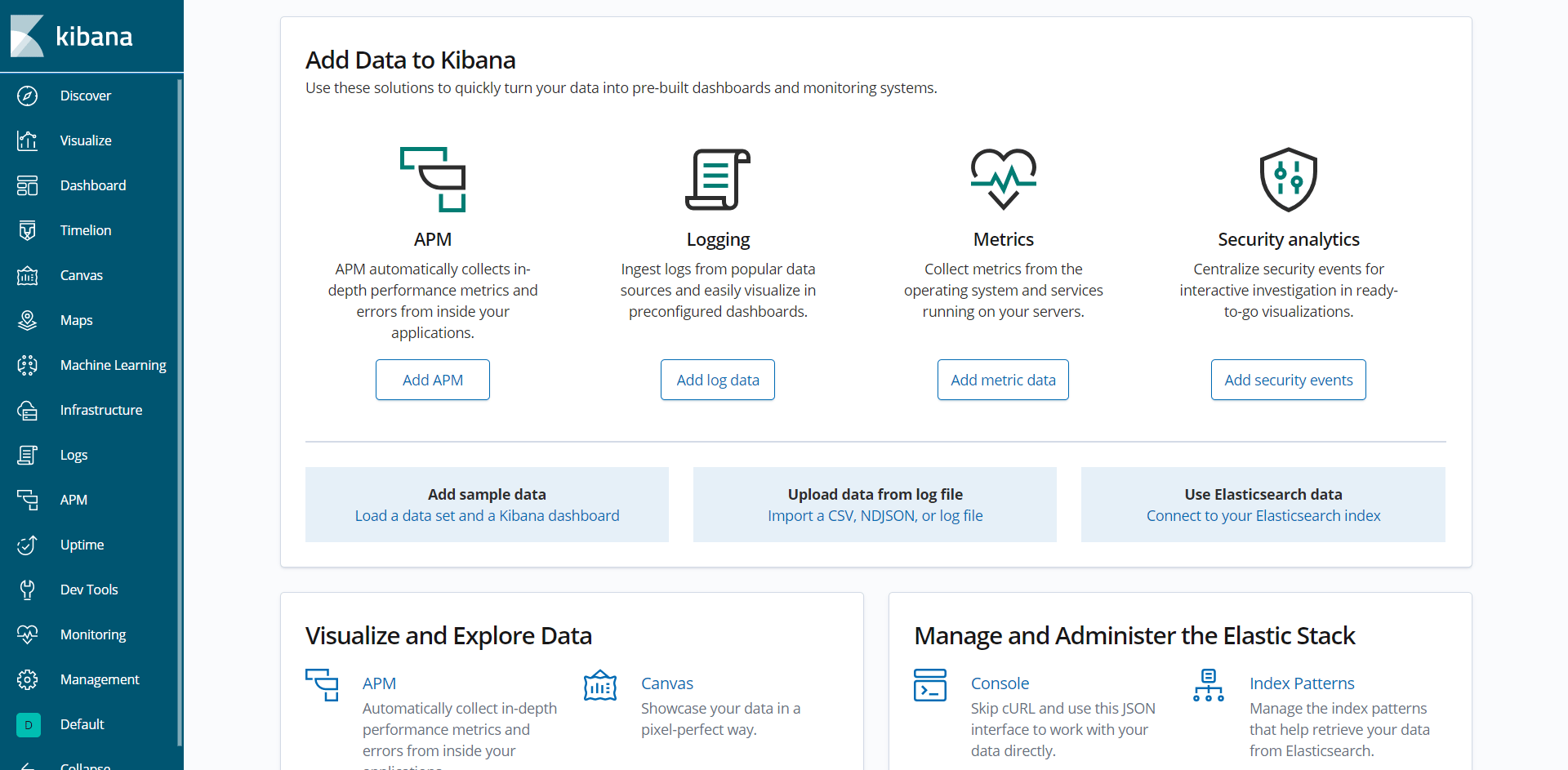
Para interagir com os índices do Elasticsearch no Kibana, você precisará criar um padrão de índice ou Index patterns. Index patterns especificam em quais índices o Kibana deve operar. Para criar um, pressione o último ícone (chave inglesa) na barra lateral vertical esquerda para abrir a página Management. Em seguida, no menu esquerdo, clique em Index Patterns abaixo de Kibana… Você verá uma caixa de diálogo para criar um padrão de índice.
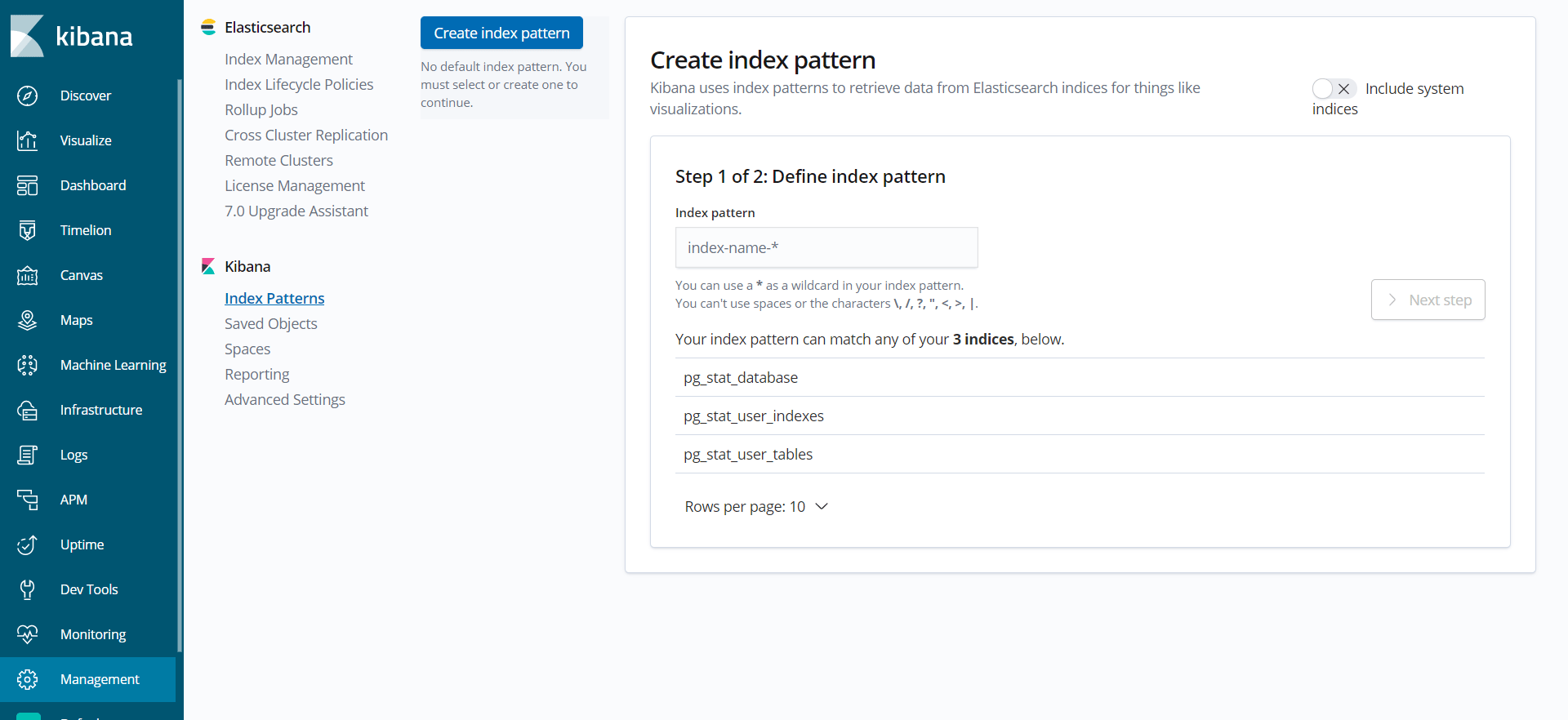
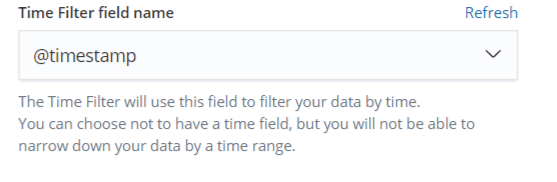
Aqui estão listados os três índices para os quais o Logstash está enviando estatísticas. Digite pg_stat_database na caixa de entrada Index Pattern e pressione Next step. Você será solicitado a selecionar um campo que armazene tempo, para poder restringir seus dados posteriormente por um intervalo de tempo. No menu suspenso, selecione @timestamp.
Clique em Create index pattern para concluir a criação do padrão de índice. Agora você poderá explorá-lo usando o Kibana. Para criar uma visualização, clique no segundo ícone na barra lateral e, em seguida, em Create new visualization. Selecione a visualização Line quando o formulário aparecer e escolha o padrão de índice que você acabou de criar (pg_stat_database). Você verá uma visualização vazia.
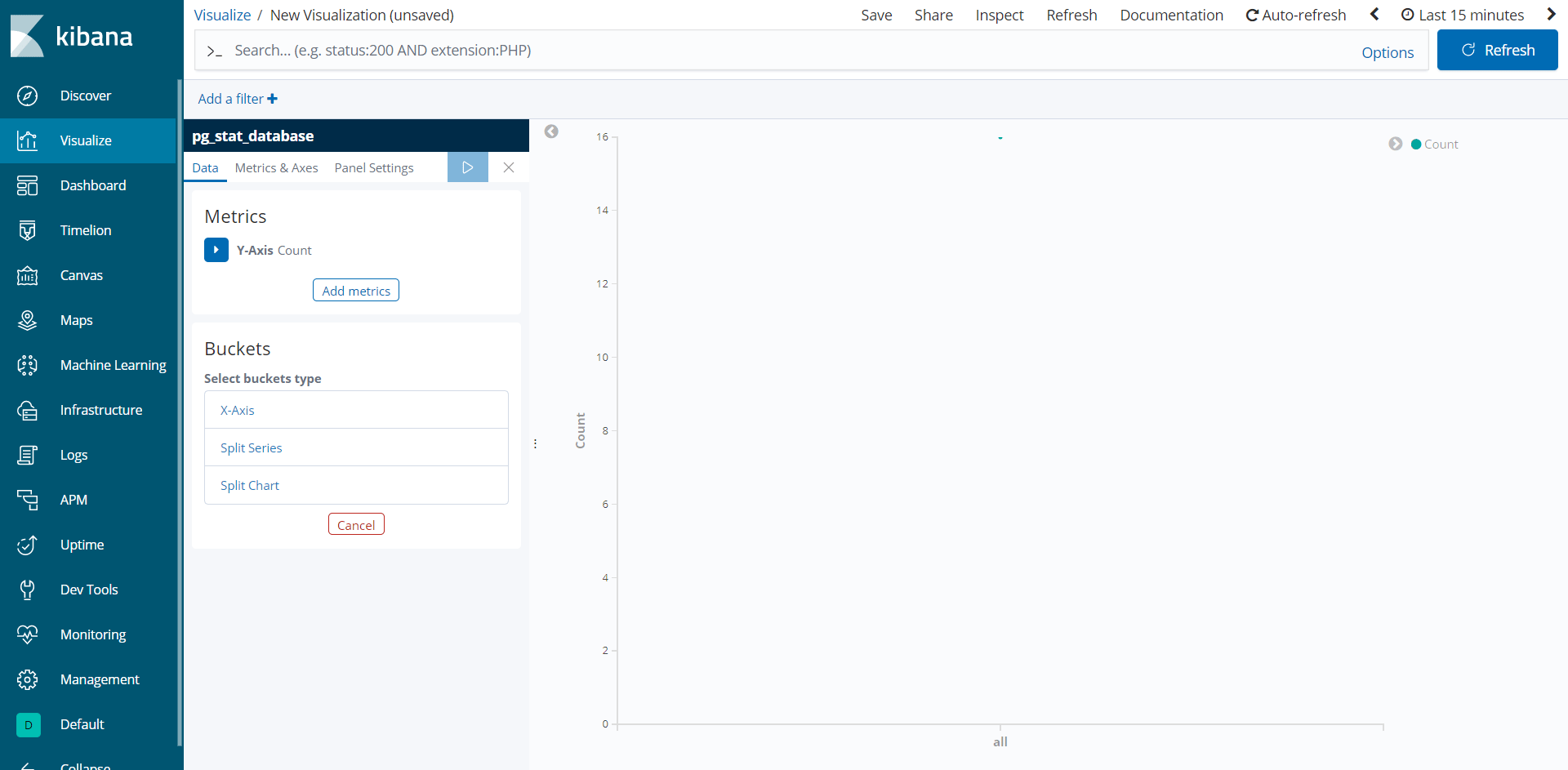
Na parte central da tela está o gráfico resultante — o painel do lado esquerdo governa sua geração a partir da qual você pode definir os dados para os eixos X e Y. No lado superior direito da tela, está o seletor de período. A menos que você escolha especificamente outro intervalo ao configurar os dados, esse intervalo será mostrado no gráfico.
Agora você visualizará o número médio de tuplas de dados inseridas (INSERT) em minutos no intervalo especificado. Clique em Y-Axis em Metrics no painel à esquerda para expandir. Selecione Average ou média como Aggregation e selecione tup_inserted como Field ou campo. Isso preencherá o eixo Y do gráfico com os valores médios.
Em seguida, clique em X-Axis em Buckets. Para Aggregation, escolha Date Histogram. @timestamp deve ser selecionado automaticamente como o Field. Em seguida, pressione o botão play azul na parte superior do painel para gerar seu gráfico. Se o seu banco de dados for novo e não for usado, você não verá nada ainda. Em todos os casos, no entanto, você verá um retrato preciso do uso do banco de dados.
O Kibana suporta muitas outras formas de visualização — você pode explorar outras formas na documentação do Kibana. Você também pode adicionar os dois índices restantes, mencionados no Passo 2 ao Kibana para poder visualizá-los também.
Neste passo, você aprendeu como visualizar alguns dos dados estatísticos do PostgreSQL, usando o Kibana.
Passo 5 — (Opcional) Fazendo Benchmark Usando pgbench
Se você ainda não trabalhou no seu banco de dados fora deste tutorial, você pode concluir esta etapa para criar visualizações mais interessantes usando o pgbench para fazer benchmark do seu banco de dados. O pgbench executará os mesmos comandos SQL repetidamente, simulando o uso do banco de dados no mundo real por um cliente real.
Você primeiro precisará instalar o pgbench executando o seguinte comando:
- sudo apt install postgresql-contrib -y
Como o pgbench irá inserir e atualizar dados de teste, você precisará criar um banco de dados separado para ele. Para fazer isso, vá para a guia Users & Databases no Painel de Controle do seu banco de dados gerenciado e role para baixo até a seção Databases. Digite pgbench como o nome do novo banco de dados e pressione Save. Você passará esse nome, bem como as informações de host, porta e nome de usuário para o pgbench.
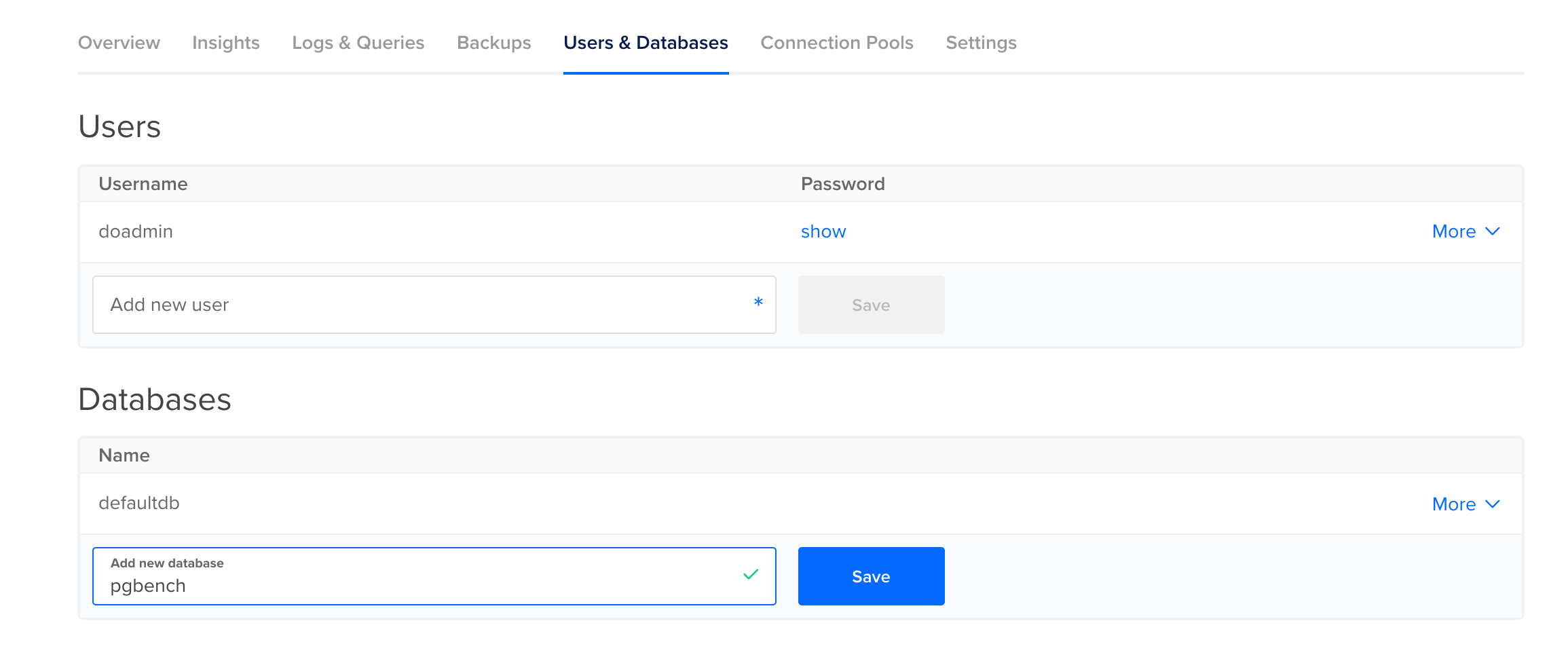
Antes de executar de fato o pgbench, você precisará executá-lo com a flag -i para inicializar seu banco de dados:
- pgbench -h host -p port -U username -i pgbench
Você precisará substituir host pelo seu endereço de host, port pela porta à qual você pode se conectar ao seu banco de dados e username com o nome do usuário do banco de dados. Você pode encontrar todos esses valores no painel de controle do seu banco de dados gerenciado.
Observe que o pgbench não possui um argumento de senha; em vez disso, você será solicitado sempre que executá-lo.
A saída terá a seguinte aparência:
OutputNOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.16 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
O pgbench criou quatro tabelas que serão usadas para o benchmarking e as preencheu com algumas linhas de exemplo. Agora você poderá executar benchmarks.
Os dois argumentos mais importantes que limitam por quanto tempo o benchmark será executado são -t, que especifica o número de transações a serem concluídas, e -T, que define por quantos segundos o benchmark deve ser executado. Essas duas opções são mutuamente exclusivas. No final de cada benchmark, você receberá estatísticas, como o número de transações por segundo (tps).
Agora, inicie um benchmark que durará 30 segundos executando o seguinte comando:
- pgbench -h host -p port -U username pgbench -T 30
A saída será semelhante a:
Outputstarting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
duration: 30 s
number of transactions actually processed: 7602
latency average = 3.947 ms
tps = 253.382298 (including connections establishing)
tps = 253.535257 (excluding connections establishing)
Nesta saída, você vê as informações gerais sobre o benchmark, como o número total de transações executadas. O efeito desses benchmarks é que as estatísticas enviadas pelo Logstash para o Elasticsearch refletirão esse número, o que tornará as visualizações no Kibana mais interessantes e mais próximas dos gráficos do mundo real. Você pode executar o comando anterior mais algumas vezes e talvez alterar a duração.
Quando terminar, vá para o Kibana e clique em Refresh no canto superior direito. Agora você verá uma linha diferente da anterior, que mostra o número de INSERTs. Sinta-se à vontade para alterar o intervalo de tempo dos dados mostrados, alterando os valores no seletor posicionado acima do botão de atualização. Aqui está como o gráfico pode se apresentar após vários benchmarks de duração variável:
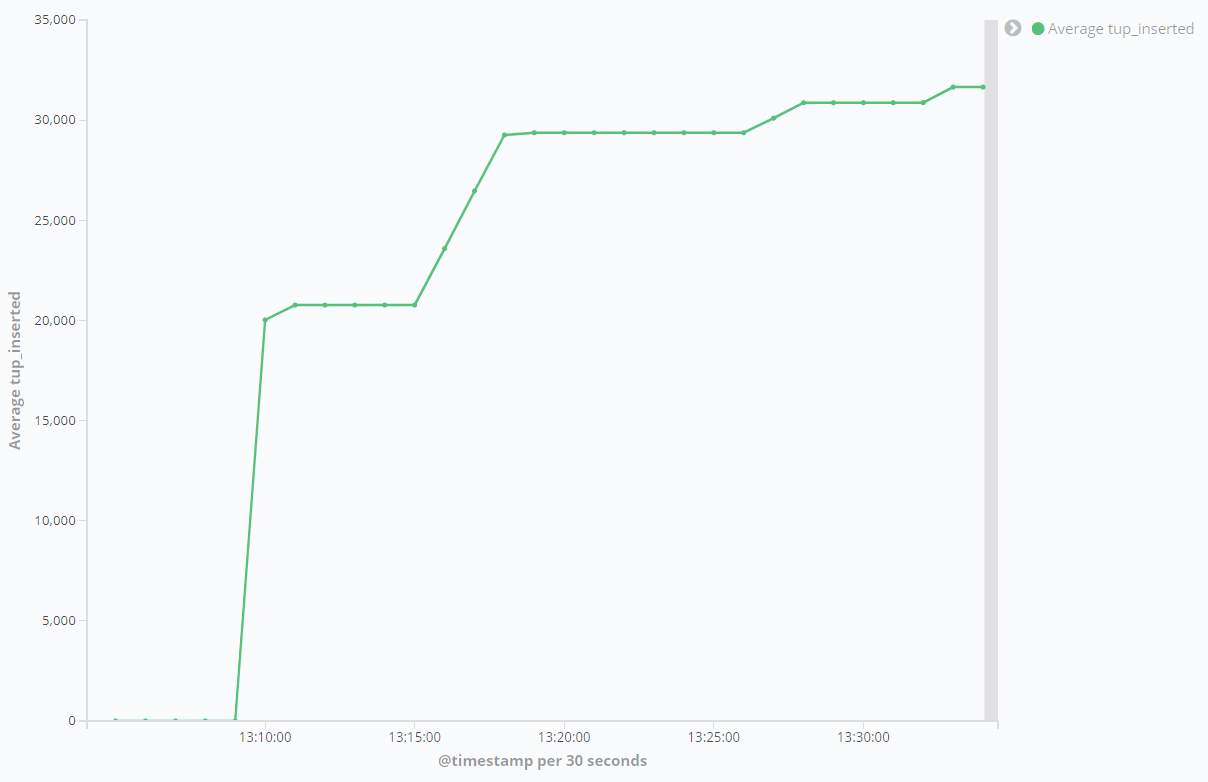
Você usou o pgbench para fazer benchmark em seu banco de dados e avaliou os gráficos resultantes no Kibana.
Conclusão
Agora você tem a pilha Elastic instalada em seu servidor e configurada para coletar regularmente dados estatísticos do banco de dados PostgreSQL gerenciado. Você pode analisar e visualizar os dados usando o Kibana, ou algum outro software adequado, que o ajudará a reunir informações valiosas e correlações do mundo real sobre o desempenho do seu banco de dados.
Para obter mais informações sobre o que você pode fazer com o banco de dados gerenciado do PostgreSQL, visite a documentação de produto.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Expert in cloud topics including Kafka, Kubernetes, and Ubuntu.
Former Senior Technical Editor at DigitalOcean, with a strong focus on DevOps and System Administration content. Areas of expertise include Terraform, PyTorch, Python, and Django.
I’m a consultant and technical expert in Linux, Datacenter, and Cloud. I've been worked with Customer Support because I love helping people.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
