
Introdução
Machine learning ou Aprendizado de máquina é um campo de pesquisa em ciência da computação, inteligência artificial, e estatística. O foco do Machine Learning é treinar algoritmos para aprender padrões e fazer previsões a partir de dados. Machine learning é especialmente valioso porque ele nos leva a utilizar computadores para automatizar o processo de tomada de decisões.
Você encontrará aplicações de Machine learning em todos os lugares. Netflix e Amazon usam machine learning para fazer novas recomendações de produtos. Bancos usam machine learning para detectar atividades fraudulentas em transações de cartões de crédito, e empresas de assistência à saúde estão começando a usar machine learning para monitorar, avaliar e diagnosticar pacientes.
Neste tutorial vamos implementar um algoritmo simples de machine learning em Python utilizando Scikit-learn, uma ferramenta de machine learning para Python. Usando um banco de dados de informações sobre tumores de câncer de mama, iremos usar um classificador Naive Bayes (NB) que prevê se um tumor é maligno ou benigno.
No final deste tutorial, você saberá como construir o seu próprio modelo de machine learning em Python.
Pré-requisitos
Para completar este tutorial, você precisará de:
- Python 3 e um ambiente de programação local configurado em seu computador. Você pode seguir o guia de instalação e configuração apropriado para o seu sistema operacional para configurar isso.
- Se você é novo no Python, você pode exlporar How to Code in Python 3 para familiarizar-se com a linguagem.
- Jupyter Notebook instalado no virtualenv para este tutorial. Jupiter Notebooks são extremamente úteis ao se executar experimentos de machine learning. Você pode executar pequenos blocos de código e ver os resultados rapidamente, facilitando o teste e a depuração de seu código.
Passo 1 — Importando o Scikit-learn
Vamos começar instalando o módulo Python Scikit-learn, um das melhores e mais bem documentadas bibliotecas de machine learning para Python.
Para começar com nosso projeto de codificação, vamos ativar nosso ambiente de programação Python 3. Certifique-se de estar no diretório onde o seu ambiente está localizado, e execute o seguinte comando:
- . my_env/bin/activate
Com seu ambiente de programação ativado, verifique se o módulo Scikit-learn já está instalado:
- python -c "import sklearn"
Se o sklearn estiver instalado, este comando irá completar sem erros. Se ele não estiver instalado, você verá a seguinte mensagem de erro:
OutputTraceback (most recent call last): File "<string>", line 1, in <module> ImportError: No module named 'sklearn'
A mensagem de erro indica que o módulo sklearn não está instalado, então baixe o biblioteca usando o pip:
- pip install scikit-learn[alldeps]
Quando a instalação estiver concluída, inicie o Jupyter Notebook:
- jupyter notebook
No Jupyter, crie um novo Python Notebook chamado ML Tutorial. Na primeira célula do Notebook, importe o módulo sklearn.
import sklearn
Seu notebook deve se parecer com a figura a seguir:

Agora que temos o sklearn importado em nosso notebook, podemos começar a trabalhar com o dataset para o nosso modelo de machine learning.
Passo 2 — Importando o Dataset do Scikit-learn
O dataset com o qual estaremos trabalhando neste tutorial é o Breast Cancer Wisconsin Diagnostic Database. O dataset inclui várias informações sobre tumores de câncer de mama, bem como rótulos de classificação como malignos ou benignos. O dataset tem 569 instâncias, ou dados, sobre 569 tumores e inclui informações sobre 30 atributos, ou características, tais como o raio do tumor, textura, suavidade, e área.
Utilizando este dataset, construiremos um modelo de machine learning para utilizar as informações sobre tumores para prever se um tumor é maligno ou benigno.
O Scikit-learn vem instalado com vários datasets que podemos carregar no Python, e o dataset que queremos está incluído. Importe e carregue o dataset:
...
from sklearn.datasets import load_breast_cancer
# Carregar o dataset
data = load_breast_cancer()
A variável data representa um objeto Python que funciona como um dicionário. As chaves importantes do dicionário a considerar são os nomes dos rótulos de classificação (target_names), os rótulos reais (target), os nomes de atributo/característica (feature_names), e os atributos (data).
Atributos são uma parte crítica de qualquer classificador. Os atributos capturam características importantes sobre a natureza dos dados. Dado o rótulo que estamos tentando prever (tumor maligno versus benigno), os possíveis atributos úteis incluem o tamanho, raio, e a textura do tumor.
Crie novas variáveis para cada conjunto importante de informações e atribua os dados:
...
# Organizar nossos dados
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
Agora temos listas para cada conjunto de informações. Para entender melhor nosso conjunto de dados, vamos dar uma olhada em nossos dados imprimindo nossos rótulos de classe, o primeiro rótulo da instância de dados, nossos nomes de características, e os valores das características para a primeira instância de dados.
...
# Olhando para os nossos dados
print(label_names)
print(labels[0])
print(feature_names[0])
print(features[0])
Você verá os seguintes resultados se você executar o código:
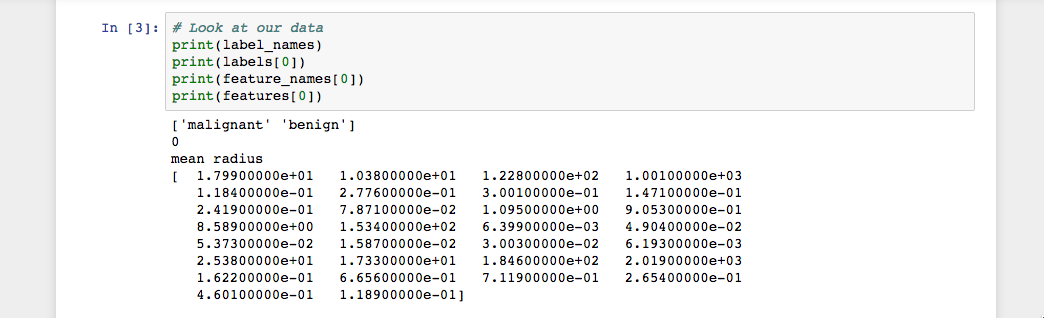
Como mostra a imagem, nossos nomes de classes são malignant and benign (maligno e benigno), que são então mapeados para valores binários de 0 e 1, onde 0 representa tumores malignos e 1 representa tumores benignos. Portanto, nossa primeira instância de dados é um tumor maligno cujo raio médio é 1.79900000e+01.
Agora que temos nossos dados carregados, podemos trabalhar com eles para construir nosso classificador de machine learning.
Passo 3 — Organizando Dados em Conjuntos
Para avaliar o desempenho de um classificador, você deve sempre testar o modelo em dados não visualizados. Portanto, antes da construção de um modelo, divida seus dados em duas partes: um conjunto de treinamento e um conjunto de testes.
Você usa o conjunto de testes para treinar e avaliar o modelo durante o estágio de desenvolvimento. Então você usa o modelo treinado para fazer previsões no conjunto de testes não visualizado. Essa abordagem lhe dá uma noção do desempenho e robustez do modelo.
Felizmente, o sklearn tem uma função chamada train_test_split(), que divide seus dados nesses conjuntos. Importe a função e em seguida utilize-a para dividir os dados:
...
from sklearn.model_selection import train_test_split
# Dividir nossos dados
train, test, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=42)
A função divide aleatoriamente os dados usando o parâmetro test_size. Neste exemplo, agora temos um conjunto de testes (test) que representa 33% do dataset original. Os dados restantes (train) formam então os dados de treinamento. Também temos os respectivos rótulos para ambas as variáveis train/test, ou seja, train_labels e test_labels.
Agora podemos passar para o treinamento do nosso primeiro modelo.
Passo 4 — Construindo e Avaliando o Modelo
Existem muitos modelos para machine learning, e cada modelo tem seus pontos fortes e fracos. Neste tutorial, vamos nos concentrar em um algoritmo simples que geralmente funciona bem em tarefas de classificação binária, a saber Naive Bayes (NB).
Primeiro, importe o módulo GaussianNB. Em seguida inicialize o modelo com a função GaussianNB(), depois treine o modelo, ajustando-o aos dados usando gnb.fit():
...
from sklearn.naive_bayes import GaussianNB
# Inicializar nosso classificador
gnb = GaussianNB()
# Treinar nosso classificador
model = gnb.fit(train, train_labels)
Depois de treinarmos o modelo, podemos usar o modelo treinado para fazer previsões no nosso conjunto de teste, o que fazemos utilizando a função predict(). A função predict() retorna uma matriz de previsões para cada instância de dados no conjunto de testes. Podemos então, imprimir nossas previsões para ter uma ideia do que o modelo determinou.
Utilize a função predict() com o conjunto test e imprima os resultados:
...
# Fazer previsões
preds = gnb.predict(test)
print(preds)
Execute o código e você verá os seguintes resultados:
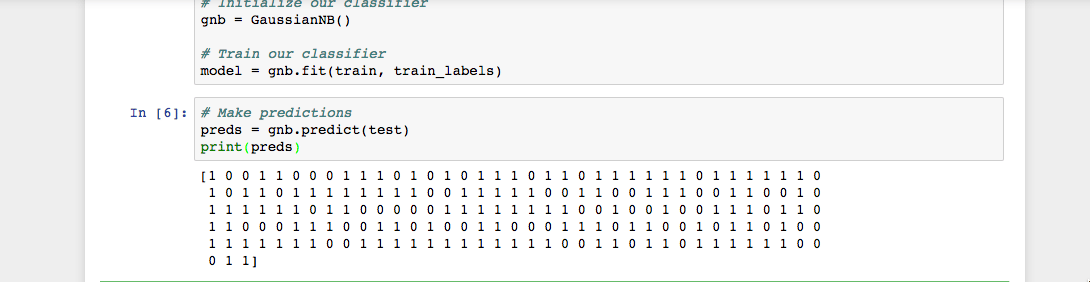
Como você vê na saída do Jupyter Notebook, a função predict() retornou uma matriz de 0s e 1s que representa nossos valores previstos para a classe tumor (maligno vs. benigno).
Agora que temos nossas previsões, vamos avaliar o desempenho do nosso classificador.
Passo 5 — Avaliando a Precisão do Modelo
Usando a matriz de rótulos de classe verdadeira, podemos avaliar a precisão dos valores previstos do nosso modelo comparando as duas matrizes (test_labels vs. preds). Utilizaremos a função accuracy_score() do sklearn para determinar a precisão do nosso classificador de machine learning.
...
from sklearn.metrics import accuracy_score
# Avaliar a precisão
print(accuracy_score(test_labels, preds))
Você verá os seguintes resultados:

Como você vê na saída, o classificador NB é 94.15% preciso. Isso significa que 94,15 porcento do tempo o classificador é capaz de fazer a previsão correta se o tumor é maligno ou benigno. Esses resultados sugerem que nosso conjunto de características de 30 atributos são bons indicadores da classe do tumor.
Você construiu com sucesso seu primeiro classificador de machine learning. Vamos reorganizar o código colocando todas as declarações import no topo do Notebook ou script. A versão final do código deve ser algo assim:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# Carregar o dataset
data = load_breast_cancer()
# Organizar nossos dados
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
# Olhando para os nossos dados
print(label_names)
print('Class label = ', labels[0])
print(feature_names)
print(features[0])
# Dividir nossos dados
train, test, train_labels, test_labels = train_test_split(features,
labels,
test_size=0.33,
random_state=42)
# Inicializar nosso classificador
gnb = GaussianNB()
# Treinar nosso classificador
model = gnb.fit(train, train_labels)
# Fazer previsões
preds = gnb.predict(test)
print(preds)
# Avaliar a precisão
print(accuracy_score(test_labels, preds))
Agora você pode continuar trabalhando com seu código para ver se consegue fazer com que seu classificador tenha um desempenho ainda melhor. Você pode experimentar com diferentes subconjuntos de características ou mesmo tentar algoritmos completamente diferentes. Confira o website do Scikit-learn para mais ideias sobre machine learning.
Conclusão
Neste tutorial, você aprendeu como construir um classificador de machine learning em Python. Agora você pode carregar dados, organizar dados, treinar, prever e avaliar classificadores de machine learning em Python usando o Scikit-learn. Os passos deste tutorial devem ajudá-lo a facilitar o processo de trabalhar com seus próprios dados no Python.
Traduzido Por Fernando Pimenta
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Managed the Write for DOnations program, wrote and edited community articles, and makes things on the Internet. Expertise in DevOps areas including Linux, Ubuntu, Debian, and more.
I’m a consultant and technical expert in Linux, Datacenter, and Cloud. I've been worked with Customer Support because I love helping people.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
