By Ellie Birbeck and Fernando Pimenta

Introdução
Redes neurais são usadas como um método de deep learning ou aprendizado profundo, um dos vários subcampos da inteligência artificial. Elas foram propostas pela primeira vez há cerca de 70 anos como uma tentativa de simular a maneira como o cérebro humano funciona, embora de uma forma muito mais simplificada. Os “neurônios” individuais são conectados em camadas, com pesos designados para determinar como o neurônio responde quando os sinais são propagados pela rede. Anteriormente, as redes neurais eram limitadas no número de neurônios que elas eram capazes de simular e, portanto, a complexidade do aprendizado que podiam alcançar. Mas nos últimos anos, devido aos avanços no desenvolvimento de hardware, pudemos construir redes muito profundas e treiná-las em enormes datasets ou conjuntos de dados para obter avanços na inteligência de máquinas.
Essas inovações permitiram que as máquinas correspondessem e excedessem as capacidades dos humanos em realizar certas tarefas. Uma dessas tarefas é o reconhecimento de objetos. Embora as máquinas tenham sido historicamente incapazes de corresponder à visão humana, avanços recentes em deep learning tornaram possível construir redes neurais capazes de reconhecer objetos, rostos, textos e até mesmo emoções.
Neste tutorial, você implementará uma pequena subseção de reconhecimento de objeto recognition—digit. Utilizando o TensorFlow, uma biblioteca Python open-source desenvolvida pelos laboratórios do Google Brain para pesquisa em deep learning, você pegará imagens desenhadas à mão dos números de 0 a 9 e construirá e treinará uma rede neural para reconhecer e prever o rótulo correto para o dígito exibido.
Embora você não precise de experiência prévia em deep learning prático ou de uso do TensorFlow para acompanhar este tutorial, vamos assumir alguma familiaridade com termos e conceitos de machine learning, como treinamento e testes, recursos e rótulos, otimização e avaliação. Você pode aprender mais sobre esses conceitos em Uma Introdução ao Machine Learning.
Pré-requisitos
Para completar esse tutorial, você vai precisar de:
- Um ambiente local de desenvolvimento Python 3, incluindo pip, uma ferramenta para instalação de pacotes Python, e o venv, para a criação de ambientes virtuais.
Passo 1 — Configurando o Projeto
Antes de desenvolver o programa de reconhecimento, você precisará instalar algumas dependências e criar um espaço de trabalho para armazenar seus arquivos.
Usaremos um ambiente virtual do Python 3 para gerenciar as dependências do nosso projeto. Crie um novo diretório para o seu projeto e navegue até o novo diretório:
- mkdir tensorflow-demo
- cd tensorflow-demo
Execute os seguintes comandos para configurar o ambiente virtual para este tutorial:
- python3 -m venv tensorflow-demo
- source tensorflow-demo/bin/activate
Em seguida, instale as bibliotecas que você usará neste tutorial. Usaremos versões específicas dessas bibliotecas criando um arquivo requirements.txt no diretório do projeto, que especifica o requisito e a versão que precisamos. Crie o arquivo requirements.txt:
- touch requirements.txt
Abra o arquivo em seu editor de textos e adicione as seguintes linhas para especificar as bibliotecas Image, NumPy, e TensorFlow e suas versões:
image==1.5.20
numpy==1.14.3
tensorflow==1.4.0
Salve o arquivo e saia do editor. Em seguida instale estas bibliotecas com o seguinte comando:
- pip install -r requirements.txt
Com as dependências instaladas, podemos começar a trabalhar no nosso projeto.
Passo 2 — Importando o Dataset MNIST
O dataset que estaremos utilizando neste tutorial é chamado de dataset MNIST, e ele é um clássico na comunidade de machine learning. Este dataset é composto de imagens de dígitos manuscritos, com 28x28 pixels de tamanho. Aqui estão alguns exemplos dos dígitos incluídos no dataset:
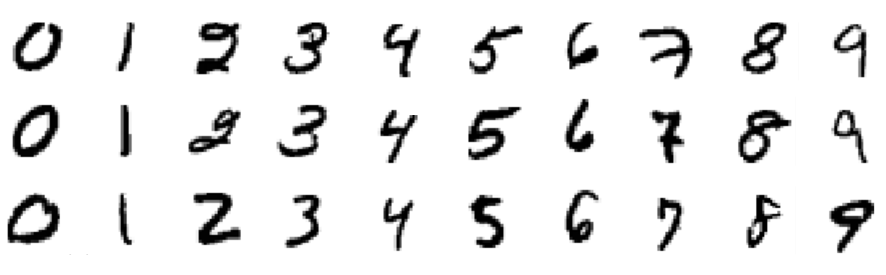
Vamos criar um programa Python para trabalhar com este dataset. Usaremos um arquivo para todo o nosso trabalho neste tutorial. Crie um novo arquivo chamado main.py:
- touch main.py
Agora abra este arquivo no editor de textos de sua preferência e adicione esta linha de código ao arquivo para importar a biblioteca do TensorFlow:
import tensorflow as tf
Adicione as seguintes linhas de código ao seu arquivo para importar o dataset MNIST e armazenar os dados da imagem na variável mnist:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # y labels are oh-encoded
Ao ler os dados, estamos usando one-hot-encoding para representar os rótulos (o dígito real desenhado, por exemplo “3”) das imagens. O one-hot-encoding utiliza um vetor de valores binários para representar valores numéricos ou categóricos. Como nossos rótulos são para os dígitos de 0 a 9, o vetor contém dez valores, um para cada dígito possível. Um desses valores é definido como 1, para representar o dígito nesse índice do vetor, e o restante é difinido como 0. Por exemplo, o dígito 3 é representado usando o vetor [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]. Como o valor no índice 3 está armazenado como 1, o vetor representa o dígito 3.
Para representar as imagens, os 28x28 pixels são achatados em um vetor 1D com 784 pixels de tamanho. Cada um dos 784 pixels que compõem a imagem é armazenado como um valor entre 0 e 255. Isso determina a escala de cinza do pixel, pois nossas imagens são apresentadas apenas em preto e branco. Portanto, um pixel preto é representado por 255 e um pixel branco por 0, com os vários tons de cinza em algum lugar entre eles.
Podemos usar a variável mnist para descobrir o tamanho do dataset que acabamos de importar. Observando os num_examples para cada um dos três subconjuntos, podemos determinar que o dataset foi dividido em 55.000 imagens para treinamento, 5000 para validação e 10.000 para teste. Adicione as seguintes linhas ao seu arquivo:
n_train = mnist.train.num_examples # 55,000
n_validation = mnist.validation.num_examples # 5000
n_test = mnist.test.num_examples # 10,000
Agora que temos nossos dados importados, é hora de pensar sobre a rede neural.
Passo 3 — Definindo a Arquitetura da Rede Neural
A arquitetura da rede neural refere-se a elementos como o número de camadas na rede, o número de unidades em cada camada e como as unidades são conectadas entre as camadas. Como as redes neurais são vagamente inspiradas no funcionamento do cérebro humano, aqui o termo unidade é usado para representar o que seria biologicamente um neurônio. Assim como os neurônios transmitem sinais pelo cérebro, as unidades tomam alguns valores das unidades anteriores como entrada, realizam uma computação e, em seguida, transmitem o novo valor como saída para outras unidades. Essas unidades são colocadas em camadas para formar a rede, iniciando no mínimo com uma camada para entrada de valores e uma camada para valores de saída. O termo hidden layer ou camada oculta é usado para todas as camadas entre as camadas de entrada e saída, ou seja, aquelas “ocultas” do mundo real.
Arquiteturas diferentes podem produzir resultados drasticamente diferentes, já que o desempenho pode ser pensado como uma função da arquitetura entre outras coisas, como os parâmetros, os dados e a duração do treinamento.
Adicione as seguintes linhas de código ao seu arquivo para armazenar o número de unidades por camada nas variáveis globais. Isso nos permite alterar a arquitetura de rede em um único lugar e, no final do tutorial, você pode testar por si mesmo como diferentes números de camadas e unidades afetarão os resultados de nosso modelo:
n_input = 784 # input layer (28x28 pixels)
n_hidden1 = 512 # 1st hidden layer
n_hidden2 = 256 # 2nd hidden layer
n_hidden3 = 128 # 3rd hidden layer
n_output = 10 # output layer (0-9 digits)
O diagrama a seguir mostra uma visualização da arquitetura que projetamos, com cada camada totalmente conectada às camadas adjacentes:
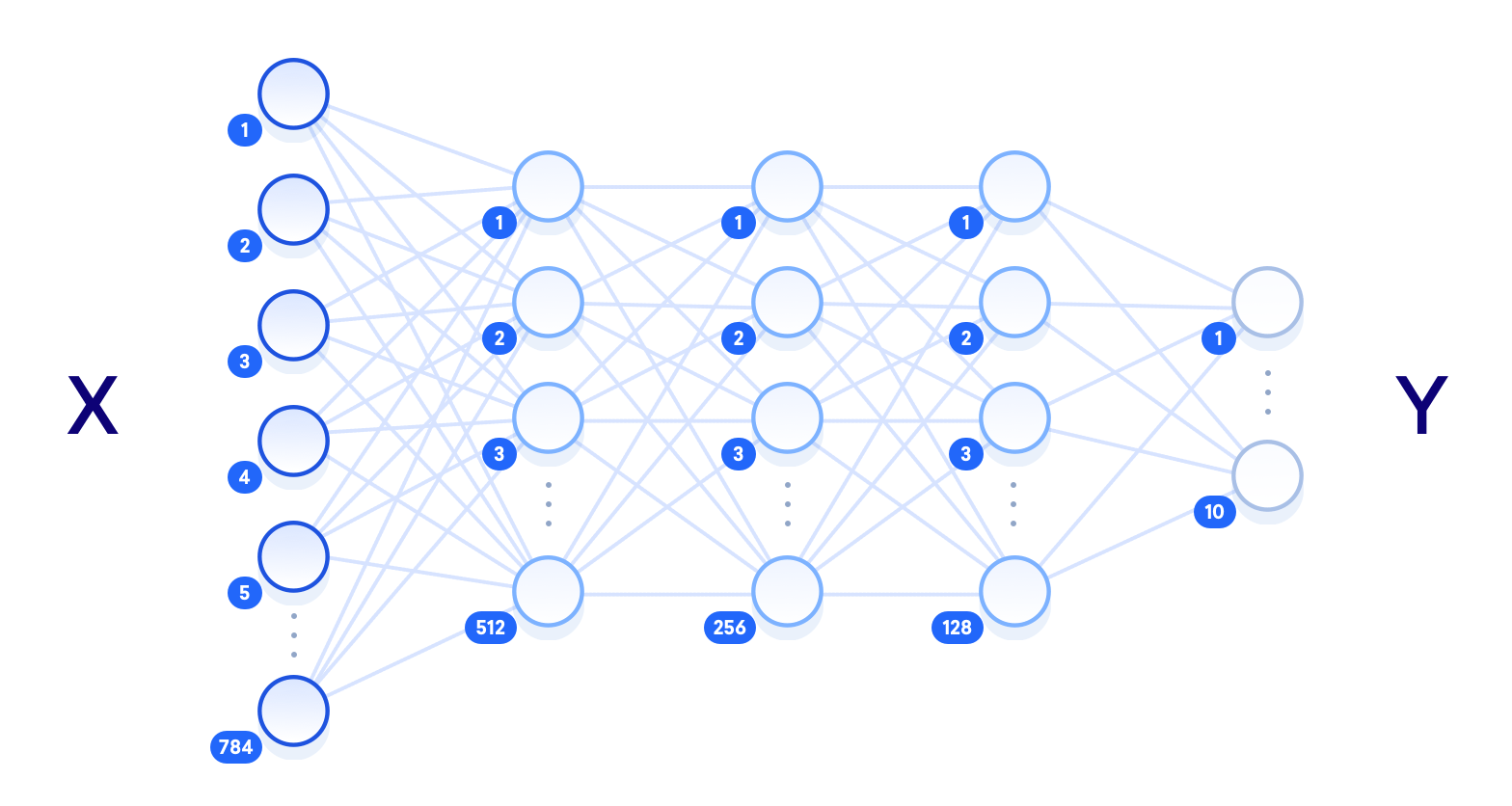
O termo “deep neural network” ou rede neural profunda se relaciona com o número de camadas ocultas, com “superficial” geralmente significando apenas uma camada oculta e “profunda”, referindo-se a várias camadas ocultas. Fornecidos dados de treinamento suficientes, uma rede neural superficial com um número suficiente de unidades deve teoricamente ser capaz de representar qualquer função que uma rede neural profunda possa. Mas é mais eficiente computacionalmente usar uma rede neural profunda menor para realizar a mesma tarefa que exigiria uma rede superficial com exponencialmente mais unidades ocultas. Redes neurais superficiais também freqüentemente encontram overfitting, onde a rede essencialmente memoriza os dados de treinamento que viu e não é capaz de generalizar o conhecimento para novos dados. É por isso que as redes neurais profundas são mais comumente usadas: as várias camadas entre os dados brutos de entrada e o rótulo de saída permitem que a rede aprenda recursos em vários níveis de abstração, tornando a própria rede mais capaz de generalizar.
Outros elementos da rede neural que precisam ser definidos aqui são os hiperparâmetros. Ao contrário dos parâmetros que serão atualizados durante o treinamento, esses valores são definidos inicialmente e permanecem constantes durante todo o processo. No seu arquivo, defina as seguintes variáveis e valores:
learning_rate = 1e-4
n_iterations = 1000
batch_size = 128
dropout = 0.5
A taxa de aprendizado, learning_rate, representa o quanto os parâmetros serão ajustados em cada etapa do processo de aprendizado. Esses ajustes são um componente-chave do treinamento: depois de cada passagem pela rede, ajustamos os pesos ligeiramente para tentar reduzir a perda. Taxas de aprendizado maiores podem convergir mais rapidamente, mas também têm o potencial de ultrapassar os valores ideais à medida que são atualizados. O número de iterações, n_iterations, refere-se a quantas vezes passamos pela etapa de treinamento e o tamanho do lote ou batch_size se refere a quantos exemplos de treinamento estamos usando em cada etapa. A variável dropout representa um limiar no qual eliminamos algumas unidades aleatoriamente. Estaremos usando dropout em nossa última camada oculta para dar a cada unidade 50% de chance de ser eliminada em cada etapa de treinamento. Isso ajuda a evitar o overfitting.
Agora já definimos a arquitetura de nossa rede neural e os hiperparâmetros que impactam o processo de aprendizagem. O próximo passo é construir a rede como um gráfico do TensorFlow.
Passo 4 — Construindo o Gráfico do TensorFlow
Para construir nossa rede, vamos configurará-la como um gráfico computacional para o TensorFlow executar. O conceito central do TensorFlow é o tensor, uma estrutura de dados semelhante a uma matriz ou lista inicializada, manipulada à medida que passa pelo gráfico e atualizada através do processo de aprendizado.
Começaremos definindo três tensores como placeholders ou marcadores de posição, que são tensores nos quais alimentaremos os valores posteriormente. Adicione o seguinte ao seu arquivo:
X = tf.placeholder("float", [None, n_input])
Y = tf.placeholder("float", [None, n_output])
keep_prob = tf.placeholder(tf.float32) ^
O único parâmetro que precisa ser especificado em sua declaração é o tamanho dos dados os quais estaremos alimentando. Para X usamos um formato [None, 784] , onde None representa qualquer quantidade, pois estaremos alimentando em um número indefinido de imagens de 784 pixels. O formato de Y é [None, 10] pois iremos usá-lo para um número indefinido de saídas de rótulo, com 10 classes possíveis. O tensor keep_prob é usado para controlar a taxa de dropout, e nós o inicializamos como um placeholder ao invés de uma variável imutável porque queremos usar o mesmo tensor tanto para treinamento (quando dropout é definido para 0.5) quanto para testes (quando dropout é definido como 1.0).
Os parâmetros que a rede atualizará no processo de treinamento são os valores weight e bias, portanto, precisamos definir um valor inicial em vez de um placeholder vazio. Esses valores são essencialmente onde a rede faz seu aprendizado, pois são utilizados nas funções de ativação dos neurônios, representando a força das conexões entre as unidades.
Como os valores são otimizados durante o treinamento, podemos defini-los para zero por enquanto. Mas o valor inicial realmente tem um impacto significativo na precisão final do modelo. Usaremos valores aleatórios de uma distribuição normal truncada para os pesos. Queremos que eles estejam próximos de zero, para que possam se ajustar em uma direção positiva ou negativa, e um pouco diferente, para que gerem erros diferentes. Isso garantirá que o modelo aprenda algo útil. Adicione estas linhas:
weights = {
'w1': tf.Variable(tf.truncated_normal([n_input, n_hidden1], stddev=0.1)),
'w2': tf.Variable(tf.truncated_normal([n_hidden1, n_hidden2], stddev=0.1)),
'w3': tf.Variable(tf.truncated_normal([n_hidden2, n_hidden3], stddev=0.1)),
'out': tf.Variable(tf.truncated_normal([n_hidden3, n_output], stddev=0.1)),
}
Para o bias ou tendência, usamos um pequeno valor constante para garantir que os tensores se ativem nos estágios iniciais e, portanto, contribuam para a propagação. Os pesos e tensores de bias são armazenados em objetos de dicionário para facilitar o acesso. Adicione este código ao seu arquivo para definir cada bias:
biases = {
'b1': tf.Variable(tf.constant(0.1, shape=[n_hidden1])),
'b2': tf.Variable(tf.constant(0.1, shape=[n_hidden2])),
'b3': tf.Variable(tf.constant(0.1, shape=[n_hidden3])),
'out': tf.Variable(tf.constant(0.1, shape=[n_output]))
}
Em seguida, configure as camadas da rede definindo as operações que manipularão os tensores. Adicione estas linhas ao seu arquivo:
layer_1 = tf.add(tf.matmul(X, weights['w1']), biases['b1'])
layer_2 = tf.add(tf.matmul(layer_1, weights['w2']), biases['b2'])
layer_3 = tf.add(tf.matmul(layer_2, weights['w3']), biases['b3'])
layer_drop = tf.nn.dropout(layer_3, keep_prob)
output_layer = tf.matmul(layer_3, weights['out']) + biases['out']
Cada camada oculta executará a multiplicação da matriz nas saídas da camada anterior e os pesos da camada atual e adicionará o bias a esses valores. Na última camada oculta, aplicaremos uma operação de eliminação usando nosso valor keep_prob de 0.5.
O passo final na construção do gráfico é definir a função de perda que queremos otimizar. Uma escolha popular da função de perda nos programas do TensorFlow é a cross-entropy ou entropia cruzada, também conhecida como log-loss, que quantifica a diferença entre duas distribuições de probabilidade (as predições e os rótulos). Uma classificação perfeita resultaria em uma entropia cruzada de 0, com a perda completamente minimizada.
Também precisamos escolher o algoritmo de otimização que será usado para minimizar a função de perda. Um processo denominado otimização gradiente descendente é um método comum para encontrar o mínimo (local) de uma função, tomando etapas iterativas ao longo do gradiente em uma direção negativa (descendente). Existem várias opções de algoritmos de otimização de gradiente descendente já implementados no TensorFlow, e neste tutorial vamos usar o otimizador Adam. Isso se estende à otimização de gradiente descendente usando o momento para acelerar o processo através do cálculo de uma média exponencialmente ponderada dos gradientes e usando isso nos ajustes. Adicione o seguinte código ao seu arquivo:
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=output_layer))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
Agora acabamos de definir a rede e a construímos com o TensorFlow. O próximo passo é alimentar os dados através do gráfico para treiná-los e, em seguida, testar se realmente aprendeu alguma coisa.
Passo 5 — Treinando e Testando
O processo de treinamento envolve alimentar o dataset de treinamento através do gráfico e otimizar a função de perda. Toda vez que a rede itera um lote de mais imagens de treinamento, ela atualiza os parâmetros para reduzir a perda, a fim de prever com mais precisão os dígitos exibidos. O processo de teste envolve a execução do nosso dataset de teste através do gráfico treinado e o acompanhamento do número de imagens que são corretamente previstas, para que possamos calcular a precisão.
Antes de iniciar o processo de treinamento, definiremos nosso método de avaliação da precisão para que possamos imprimi-lo em mini-lotes de dados enquanto treinamos. Estas declarações impressas nos permitem verificar que, da primeira iteração até a última, a perda diminui e a precisão aumenta; elas também nos permitem rastrear se executamos ou não repetições suficientes para alcançar um resultado consistente e ideal:
correct_pred = tf.equal(tf.argmax(output_layer, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
Em correct_pred, usamos a função arg_max para comparar quais imagens estão sendo previstas corretamente observando output_layer (predições) e Y (labels), e usamos a função equal para retornar isso como uma lista de Booleanos. Podemos, então, converter essa lista em floats e calcular a média para obter uma pontuação total da precisão.
Agora estamos prontos para inicializar uma sessão para executar o gráfico. Nesta sessão, vamos alimentar a rede com nossos exemplos de treinamento e, uma vez treinados, alimentamos o mesmo gráfico com novos exemplos de teste para determinar a precisão do modelo. Adicione as seguintes linhas de código ao seu arquivo:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
A essência do processo de treinamento em deep learning é otimizar a função de perda. Aqui, pretendemos minimizar a diferença entre os rótulos previstos das imagens e os rótulos verdadeiros das imagens. O processo envolve quatro etapas que são repetidas para um número definido de iterações:
-
Propagar valores para frente através da rede
-
Computar a perda
-
Propagar valores para trás pela rede
-
Atualizar parâmetros
Em cada etapa de treinamento, os parâmetros são ligeiramente ajustados para tentar reduzir a perda para a próxima etapa. À medida que o aprendizado avança, devemos ver uma redução na perda e, eventualmente, podemos parar de treinar e usar a rede como um modelo para testar nossos novos dados.
Adicione este código ao arquivo:
# train on mini batches
for i in range(n_iterations):
batch_x, batch_y = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={X: batch_x, Y: batch_y, keep_prob:dropout})
# print loss and accuracy (per minibatch)
if i%100==0:
minibatch_loss, minibatch_accuracy = sess.run([cross_entropy, accuracy], feed_dict={X: batch_x, Y: batch_y, keep_prob:1.0})
print("Iteration", str(i), "\t| Loss =", str(minibatch_loss), "\t| Accuracy =", str(minibatch_accuracy))
Após 100 iterações de cada etapa de treinamento em que alimentamos um mini-lote de imagens através da rede, imprimimos a perda e a precisão desse lote. Observe que não devemos esperar uma perda decrescente e uma precisão crescente aqui, pois os valores são por lote, não para o modelo inteiro. Usamos mini-lotes de imagens em vez de alimentá-las individualmente para acelerar o processo de treinamento e permitir que a rede veja vários exemplos diferentes antes de atualizar os parâmetros.
Quando o treinamento estiver concluído, podemos executar a sessão nas imagens de teste. Desta vez estamos usando uma taxa de dropout keep_prob de 1.0 para garantir que todas as unidades estejam ativas no processo de teste.
Adicione este código ao arquivo:
test_accuracy = sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels, keep_prob:1.0})
print("\nAccuracy on test set:", test_accuracy)
Agora é hora de executar nosso programa e ver com que precisão nossa rede neural pode reconhecer esses dígitos manuscritos. Salve o arquivo main.py e execute o seguinte comando no terminal para executar o script:
- python3 main.py
Você verá uma saída semelhante à seguinte, embora os resultados individuais de perda e precisão possam variar um pouco:
OutputIteration 0 | Loss = 3.67079 | Accuracy = 0.140625
Iteration 100 | Loss = 0.492122 | Accuracy = 0.84375
Iteration 200 | Loss = 0.421595 | Accuracy = 0.882812
Iteration 300 | Loss = 0.307726 | Accuracy = 0.921875
Iteration 400 | Loss = 0.392948 | Accuracy = 0.882812
Iteration 500 | Loss = 0.371461 | Accuracy = 0.90625
Iteration 600 | Loss = 0.378425 | Accuracy = 0.882812
Iteration 700 | Loss = 0.338605 | Accuracy = 0.914062
Iteration 800 | Loss = 0.379697 | Accuracy = 0.875
Iteration 900 | Loss = 0.444303 | Accuracy = 0.90625
Accuracy on test set: 0.9206
Para tentar melhorar a precisão do nosso modelo, ou para saber mais sobre o impacto dos hiperparâmetros de ajuste, podemos testar o efeito de alterar a taxa de aprendizado, o limite de dropout, o tamanho do lote e o número de iterações. Também podemos alterar o número de unidades em nossas camadas ocultas e alterar a quantidade das próprias camadas ocultas, para ver como diferentes arquiteturas aumentam ou diminuem a precisão do modelo.
Para demonstrar que a rede está realmente reconhecendo as imagens desenhadas à mão, vamos testá-la em uma única imagem nossa.
Primeiro, faça o download dessa amostra de imagem de teste ou abra um editor gráfico e crie sua própria imagem de 28x28 pixels de um dígito.
Abra o arquivo main.py no seu editor e adicione as seguintes linhas de código ao topo do arquivo para importar duas bibliotecas necessárias para a manipulação de imagens.
import numpy as np
from PIL import Image
...
Em seguida, no final do arquivo, adicione a seguinte linha de código para carregar a imagem de teste do dígito manuscrito:
img = np.invert(Image.open("test_img.png").convert('L')).ravel()
A função open da biblioteca Image carrega a imagem de teste como um array 4D contendo os três canais de cores RGB e a transparência Alpha. Esta não é a mesma representação que usamos anteriormente ao ler o dataset com o TensorFlow, portanto, precisamos fazer algum trabalho extra para corresponder ao formato.
Primeiro, usamos a função convert com o parâmetro L para reduzir a representação 4D RGBA para um canal de cor em escala de cinza. Aarmazenamos isso como um array numpy e o invertemos usando np.invert, porque a matriz atual representa o preto como 0 e o branco como 255, porém, precisamos do oposto. Finalmente, chamamos ravel para achatar o array.
Agora que os dados da imagem estão estruturados corretamente, podemos executar uma sessão da mesma forma que anteriormente, mas desta vez apenas alimentando uma imagem única para teste. Adicione o seguinte código ao seu arquivo para testar a imagem e imprimir o rótulo de saída.
[labe main.py]
prediction = sess.run(tf.argmax(output_layer,1), feed_dict={X: [img]})
print ("Prediction for test image:", np.squeeze(prediction))
A função np.squeeze é chamada na predição para retornar o único inteiro da matriz (ou seja, para ir de [2] para 2). A saída resultante demonstra que a rede reconheceu essa imagem como o dígito 2.
OutputPrediction for test image: 2
Você pode tentar testar a rede com imagens mais complexas - dígitos que se parecem com outros dígitos, por exemplo, ou dígitos que foram mal desenhados ou desenhados incorretamente - para ver como ela se sai.
Conclusão
Neste tutorial você treinou com sucesso uma rede neural para classificar o dataset MNIST com cerca de 92% de precisão e testou em uma imagem sua. O estado da arte em pesquisa atual alcança cerca de 99% neste mesmo problema, usando arquiteturas de rede mais complexas envolvendo camadas convolucionais. Elas usam a estrutura 2D da imagem para melhor representar o conteúdo, ao contrário do nosso método que achata todos os pixels em um vetor de 784 unidades. Você pode ler mais sobre esse tópico no website do TensorFlow, e ver os documentos de pesquisa detalhando os resultados mais precisos no wesite do MNIST.
Agora que você sabe como construir e treinar uma rede neural, pode tentar usar essa implementação em seus próprios dados ou testá-la em outros datasets populares, como o Google StreetView House Numbers, ou o dataset CIFAR-10 para um reconhecimento de imagem mais genérico.
Por Ellie Birbeck
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I’m a consultant and technical expert in Linux, Datacenter, and Cloud. I've been worked with Customer Support because I love helping people.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
