
Introducción
Si desarrolla activamente una aplicación, usando Docker, puede simplificar su flujo de trabajo y el proceso de implementación de su aplicación para producción. El trabajo con contenedores en tareas de desarrollo tiene los siguientes beneficios:
- Los entornos son uniformes, lo cual significa que puede elegir los lenguajes y las dependencias que desee para su proyecto sin tener que preocuparse por posibles conflictos del sistema.
- Los entornos están aislados. Esto facilita la resolución de problemas y la admisión de nuevos miembros del equipo.
- Los entornos son portátiles; esto permite empaquetar y compartir su código con otros.
A través de este tutorial, verá la forma de configurar un entorno de desarrollo para una aplicación de Ruby on Rails usando Docker. Con Docker Compose, creará varios contenedores para la propia aplicación, la base de datos de PostgreSQL, Redis y un servicio Sidekiq. La configuración hará lo siguiente:
- Sincronizar el código de la aplicación del host con el código del contenedor para facilitar los cambios durante el desarrollo.
- Conservar los datos de la aplicación entre reinicios del contenedor.
- Configurar trabajadores de Sidekiq para que procesen las tareas como se espera
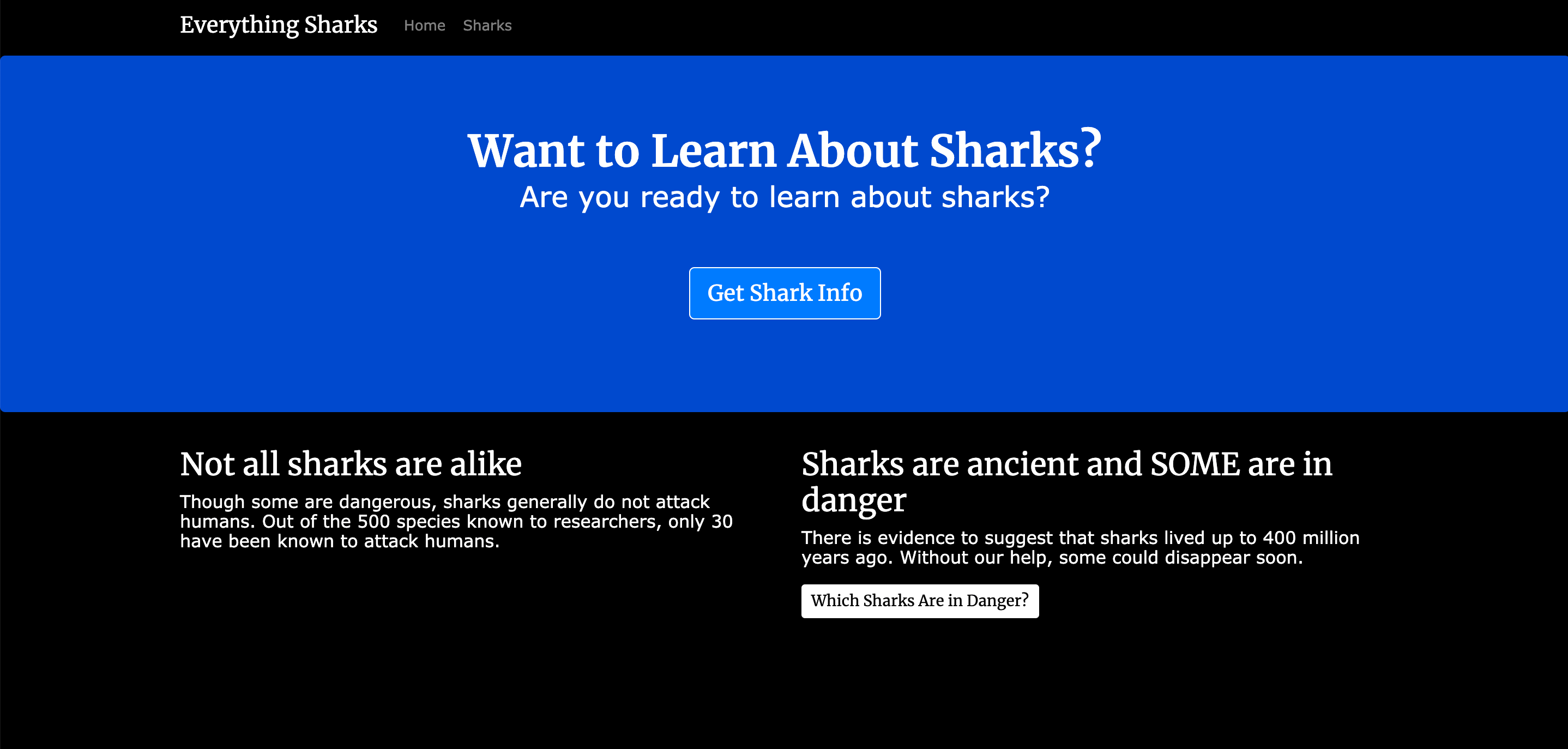
Al finalizar este tutorial, contará con una aplicación de información sobre tiburones en funcionamiento en contenedores de Docker:
Requisitos previos
Para este tutorial, necesitará lo siguiente:
- Una máquina para desarrollo local que funcione con Ubuntu 18.04, junto con un usuario no root con privilegios
sudoy un firewall activo. Para obtener información sobre cómo configurarlos, consulte esta guía de configuración inicial de servidores. - Docker instalado en su servidor o máquina local conforme a los pasos 1 y 2 de Cómo instalar y usar Docker en Ubuntu 18.04.
- Docker Compose instalado en su servidor o máquina local conforme al paso 1 de Cómo instalar Docker Compose en Ubuntu 18.04.
Paso 1: Clonar el proyecto y agregar dependencias
Nuestro primer paso será clonar el repositorio de rails-sidekiq de la cuenta de GitHub comunitaria de DigitalOcean. En este repositorio se incluye el código de la configuración descrita en el artículo Cómo agregar Sidekiq y Redis a una aplicación de Ruby on Rails, en el que se explica la forma de añadir Sidekiq a un proyecto de Rails 5 existente.
Clone el repositorio en un directorio llamado rails-docker:
- git clone https://github.com/do-community/rails-sidekiq.git rails-docker
Diríjase al directorio rails-docker:
- cd rails-docker
En este tutorial, usaremos PostgreSQL como base de datos. Para trabajar con PostgreSQL en lugar de SQLite 3, deberá añadir la gema pg a las dependencias del proyecto, que se enumeran en su Gemfile. Abra ese archivo para la edición usando nano o su editor favorito:
- nano Gemfile
Añada la gema en cualquier punto de las dependencias del proyecto principal (encima de las dependencias de desarrollo):
. . .
# Reduces boot times through caching; required in config/boot.rb
gem 'bootsnap', '>= 1.1.0', require: false
gem 'sidekiq', '~>6.0.0'
gem 'pg', '~>1.1.3'
group :development, :test do
. . .
También se puede excluir la gema sqlite, ya que dejaremos de usarla:
. . .
# Use sqlite3 as the database for Active Record
# gem 'sqlite3'
. . .
Por último, excluya la gema spring-watcher-listen en development:
. . .
gem 'spring'
# gem 'spring-watcher-listen', '~> 2.0.0'
. . .
Si no desactivamos esta gema, veremos mensajes de error persistentes al acceder a la consola de Rails. Estos mensajes de error derivan del hecho de que esta gema hace que Rails use listen para mantenrse informado sobre cambios en el desarrollo, en lugar de sondear el sistema de archivos en busca de cambios. Debido a que esta gema supervisa la raíz del proyecto, incluido el directorio node_modules, emitirá mensajes de error sobre los directorios controlados, lo que sobrecargará la consola. Sin embargo, si se ocupa de conservar los recursos de CPU, es posible que la desactivación de esta gema no funcione para usted. En este caso, puede ser recomendable actualizar su aplicación de Rails a Rails 6.
Guarde y cierre el archivo cuando concluya la edición.
Una vez que se establezca el repositorio de su proyecto, se añada la gema pg a su Gemfile y se excluya la gema spring-watcher-listen, estará listo para configurar su aplicación y trabajar con PostgreSQL.
Paso 2: Configurar la aplicación para que funcione con PostgreSQL y Redis
Para trabajar con PostgreSQL y Redis en proyectos de desarrollo, nos convendrá hacer lo siguiente:
- Configurar la aplicación para que funcione con PostgreSQL como adaptador predeterminado.
- Añadir un archivo
.enval proyecto con el nombre de usuario y la contraseña de nuestra base de datos y el host de Redis. - Crear una secuencia de comandos
init.sqla fin de generar un usuariosammypara la base de datos. - Añadir un inicializador para Sidekiq, de modo que pueda funcionar con nuestro servicio
redisen contenedor. - Añadir el archivo
.envy otros archivos pertinentes a los archivosgitignoreydockerignoredel proyecto. - Crear semillas de base de datos para que nuestra aplicación tenga algunos registros con los que podamos trabajar cuando la iniciemos.
Primero, abra el archivo de configuración de su base de datos, ubicado en config/database.yml:
- nano config/database.yml
Actualmente, en el archivo se incluye la siguiente configuración predeterminada, que se aplica en caso de que no haya otra disponible:
default: &default
adapter: sqlite3
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
Debemos cambiarla para que refleje el hecho de que usaremos el adaptador postgresql, ya que crearemos un servicio PostgreSQL con Docker Compose para conservar los datos de nuestra aplicación.
Elimine el código que establece SQLite como adaptador y sustitúyalo por la siguiente configuración, que acondicionará el adaptador de forma adecuada junto con las demás variables necesarias para establecer conexión:
default: &default
adapter: postgresql
encoding: unicode
database: <%= ENV['DATABASE_NAME'] %>
username: <%= ENV['DATABASE_USER'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
port: <%= ENV['DATABASE_PORT'] || '5432' %>
host: <%= ENV['DATABASE_HOST'] %>
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
. . .
A continuación, modificaremos la configuración del entorno development, ya que este es el entorno que usaremos en esta configuración.
Elimine la configuración de base de datos de SQLite existente de modo que la sección tenga el siguiente aspecto:
. . .
development:
<<: *default
. . .
Por último, elimine la configuración de database para los entornos production y test:
. . .
test:
<<: *default
production:
<<: *default
. . .
Estas modificaciones de la configuración de nuestra base de datos predeterminada nos permitirán establecer la información de nuestra base de datos de forma dinámica usando variables de entorno definidas en los archivos .env, que no se asignarán al control de versiones.
Guarde y cierre el archivo cuando concluya la edición.
Tenga en cuenta que si crea un proyecto de Rails desde cero, puede configurar el adaptador con el comando de rails new, como se indica en el Paso 3 de Cómo usar PostgreSQL con su aplicación de Ruby on Rails en Ubuntu 18.04. De esta forma, su adaptador quedará configurado en config/database.yml y se agregará automáticamente la gema pg al proyecto.
Ahora que hicimos referencia a nuestras variables de entorno, podemos crear un archivo para ellas con nuestra configuración preferida. Extraer ajustes de configuración de esta manera forma parte del enfoque de 12 factores para el desarrollo de aplicaciones, que define las prácticas recomendadas para lograr resiliencia en aplicaciones en entornos distribuidos. Ahora, cuando configuremos nuestro entorno de producción y prueba en el futuro, definir los ajustes de nuestra base de datos implicará crear archivos adicionales .env y hacer referencia al archivo correspondiente de nuestros archivos de Docker Compose.
Abra un archivo .env:
- nano .env
Añada los siguientes valores al archivo:
DATABASE_NAME=rails_development
DATABASE_USER=sammy
DATABASE_PASSWORD=shark
DATABASE_HOST=database
REDIS_HOST=redis
Además de establecer el nombre, el usuario y la contraseña de nuestra base de datos, fijamos un valor para DATABASE_HOST. El valor, database, hace referencia al servicio database de PostgreSQL que crearemos con Docker Compose. También configuramos un REDIS_HOST para especificar nuestro servicio de redis.
Guarde y cierre el archivo cuando concluya la edición.
Para crear el usuario de base de datos sammy, podemos escribir una secuencia de comandos init.sql que podemos montar en el contenedor de base de datos cuando se inicia.
Abra el archivo de secuencia de comandos:
- nano init.sql
Añada el siguiente código para crear un usuario sammy con privilegios administrativos:
CREATE USER sammy;
ALTER USER sammy WITH SUPERUSER;
Esta secuencia de comandos creará el usuario apropiado en la base de datos y otorgará a este privilegios administrativos.
Establezca los permisos apropiados en la secuencia de comandos:
- chmod +x init.sql
A continuación, configuraremos Sidekiq para que funcione con nuestro servicio de redis en contenedor. Podemos añadir un inicializador al directorio config/initializers, en el que Rails busca ajustes de configuración una vez que se cargan los marcos y los complementos, con lo cual se establece un valor para un host de Redis.
Abra un archivo sidekiq.rb para especificar estas configuraciones:
- nano config/initializers/sidekiq.rb
Añada el siguiente código al archivo para especificar valores de REDIS_HOST y REDIS_PORT:
Sidekiq.configure_server do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Sidekiq.configure_client do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Al igual que los ajustes de configuración de nuestra base de datos, estos ajustes nos permiten establecer los parámetros de hosts y puertos de forma dinámica, lo cual nos permite sustituir los valores apropiados en el tiempo de ejecución sin necesidad de modificar el propio código de la aplicación. Además de un REDIS_HOST, tenemos un valor predeterminado establecido para REDIS_PORT en caso de que no esté configurado en otro lugar.
Guarde y cierre el archivo cuando concluya la edición.
A continuación, para garantizar que los datos confidenciales de nuestra aplicación no se copien al control de versiones, podemos añadir .env al archivo .gitignore de nuestro proyecto, lo cual indica a Git los archivos que se deben ignorar en nuestro proyecto. Abra el archivo para editarlo:
- nano .gitignore
En la parte inferior del archivo, añada una entrada para .env:
yarn-debug.log*
.yarn-integrity
.env
Guarde y cierre el archivo cuando concluya la edición.
A continuación, crearemos un archivo .dockerignore para establecer lo que no debe copiarse a nuestros contenedores. Abra el archivo para editarlo:
- .dockerignore
Añada al archivo el siguiente código, el cual indica a Docker que ignore algunas de las cosas que no necesitamos copiar a nuestros contenedores:
.DS_Store
.bin
.git
.gitignore
.bundleignore
.bundle
.byebug_history
.rspec
tmp
log
test
config/deploy
public/packs
public/packs-test
node_modules
yarn-error.log
coverage/
Añada .env al final de este archivo:
. . .
yarn-error.log
coverage/
.env
Guarde y cierre el archivo cuando concluya la edición.
Como paso final, crearemos algunos datos semilla de modo que nuestra aplicación tenga algunos registros cuando la iniciemos.
Abra un archivo para los datos semilla del directorio db:
- nano db/seeds.rb
Añada el siguiente código al archivo para crear cuatro tiburones y una publicación de muestra:
# Adding demo sharks
sharks = Shark.create([{ name: 'Great White', facts: 'Scary' }, { name: 'Megalodon', facts: 'Ancient' }, { name: 'Hammerhead', facts: 'Hammer-like' }, { name: 'Speartooth', facts: 'Endangered' }])
Post.create(body: 'These sharks are misunderstood', shark: sharks.first)
Estos datos semilla crearán cuatro tiburones y una publicación asociada al primero.
Guarde y cierre el archivo cuando concluya la edición.
Una vez que configure su aplicación para que funcione con PostgreSQL y cree sus variables de entorno, estará listo para escribir el Dockerfile de su aplicación.
Paso 3: Escribir las secuencias de comandos de Dockerfile y puntos de entrada.
Su Dockerfile especifica lo que se incluirá en el contenedor de su aplicación cuando se cree. Usar Dockerfile le permite definir el entorno de su contenedor y evitar discrepancias con las dependencias o versiones de tiempo de ejecución.
Siguiendo estas directrices sobre la creación de contenedores optimizados, haremos que nuestra imagen sea lo más eficiente posible usando una base de Alpine e intentando minimizar las capas de nuestra imagen en general.
Abra un Dockerfile en su directorio actual:
- nano Dockerfile
Las imágenes de Docker se crean usando una sucesión de imágenes en capas que se acumulan unas sobre otras. El primer paso será añadir la imagen de base para nuestra aplicación, que formará el punto de partida de la compilación de la aplicación.
Añada el siguiente código al archivo para agregar la imagen alpine de Ruby como base:
FROM ruby:2.5.1-alpine
La imagen alpine se deriva del proyecto Alpine Linux, y nos ayudará a mantener el tamaño de las imágenes bajo. Para obtener más información sobre si la imagen alpine es la opción correcta para su proyecto, consulte la discusión completa en la sección de variantes de imagen de la página de imágenes de Ruby de Docker Hub.
Algunos factores que es necesario tener en cuenta a la hora de usar alpine para el desarrollo:
- Una imagen de tamaño reducido hará que se acorten los tiempos de carga de páginas y recursos, en particular si también mantiene los volúmenes en valores mínimos. Esto le permite lograr una experiencia de usuario de desarrollo rápida y más cercana a la que habría disponible si trabajara a nivel local en un entorno no dispuesto en contenedor.
- La paridad entre imágenes de desarrollo y producción facilita la implementación correcta. Debido a que en los equipos se suele optar por usar imágenes de Alpine en la producción para lograr beneficios en términos de velocidad, el desarrollo con una base de Alpine ayuda a resolver problemas al realizar la transición hacia la producción.
A continuación, establezca una variable de entorno para especificar la versión de Bundler:
. . .
ENV BUNDLER_VERSION=2.0.2
Este es uno de los pasos que daremos para evitar conflictos de versiones entre la versión predeterminada de bundler disponible en nuestro entorno y el código de nuestra aplicación, que requiere de Bundler 2.0.2.
A continuación, añada al Dockerfile los paquetes que necesita para trabajar con la aplicación:
. . .
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
Entre estos paquetes se incluyen nodejs y yarn. Debido a que nuestra aplicación proporciona activos con webpack, debemos incluir Node.js y Yarn para que funcione como se espera.
Tenga en cuenta que el contenido de la imagen alpine es extremadamente reducido: los paquetes que se mencionan aquí no contemplan por completo lo que usted podría desear o necesitar durante el desarrollo, cuando disponga en un contenedor su propia aplicación.
A continuación, instale la versión de bundler apropiada:
. . .
RUN gem install bundler -v 2.0.2
Este paso garantizará la paridad entre nuestro entorno en contenedor y las especificaciones del archivo Gemfile.lock de este proyecto.
Ahora, establezca el directorio de trabajo para la aplicación en el contenedor:
. . .
WORKDIR /app
Copie su Gemfile y Gemfile.lock:
. . .
COPY Gemfile Gemfile.lock ./
Si se copian estos archivos como paso independiente y luego se aplica bundle install, no es necesario volver a compilar las gemas del proyecto cada vez que se hacen cambios en el código de su aplicación. Esto funcionará junto con el volumen de gema que incluiremos en nuestro archivo Compose, que montará gemas en el contenedor de su aplicación en los casos en que se vuelva a crear el servicio, pero las gemas del proyecto siguen siendo iguales.
A continuación, establezca las opciones de configuración para la compilación de la gema nokogiri:
. . .
RUN bundle config build.nokogiri --use-system-libraries
. . .
Con este paso se crea nokigiri con las versiones de bibliotecas libxml2 y libxslt que añadimos al contenedor de la aplicación en el paso anterior con apk RUN add…
A continuación, instale las gemas del proyecto:
. . .
RUN bundle check || bundle install
Antes del proceso, esta instrucción verifica que las gemas no estén ya instaladas.
A continuación, repetiremos el mismo procedimiento que usamos con gemas con nuestros paquetes y dependencias de JavaScript. Primero, copiaremos los metadatos de paquetes, luego instalaremos dependencias y, por último, copiaremos el código de la aplicación a la imagen del contenedor.
Para comenzar con la sección Javascript de nuestro Dockerfile, copie el package.json y yarn.lock desde el directorio de su proyecto actual del host al contenedor:
. . .
COPY package.json yarn.lock ./
A continuación instale los paquetes necesarios con yarn install:
. . .
RUN yarn install --check-files
Esta instrucción incluye una bandera --check-files con el comando yarn, una función que garantiza que no se hayan eliminado archivos previamente instalados. Como en el caso de nuestras gemas, administraremos la persistencia de los paquetes en el directorio node_modules con un volumen cuando escribamos nuestro archivo Compose.
Por último, copie el resto del código de la aplicación e iniícela con una secuencia de comandos de punto de entrada:
. . .
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
El uso de una secuencia de comandos de punto de entrada nos permite ejecutar el contenedor como un ejecutable.
El Dockerfile final tendrá el siguiente aspecto:
FROM ruby:2.5.1-alpine
ENV BUNDLER_VERSION=2.0.2
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
RUN gem install bundler -v 2.0.2
WORKDIR /app
COPY Gemfile Gemfile.lock ./
RUN bundle config build.nokogiri --use-system-libraries
RUN bundle check || bundle install
COPY package.json yarn.lock ./
RUN yarn install --check-files
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
Guarde y cierre el archivo cuando concluya la edición.
A continuación, cree un directorio llamado entry points para las secuencias de comandos de punto de entrada:
- mkdir entrypoints
En este directorio se incluirán nuestra secuencia de comandos de punto de entrada principal y una secuencia de comandos para nuestro servicio Sidekiq.
Abra el archivo de la secuencia de comandos de punto de entrada de la aplicación:
- nano entrypoints/docker-entrypoint.sh
Añada el siguiente código al archivo:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec rails s -b 0.0.0.0
La primera línea importante es set -e, e indica al shell /bin/sh que ejecuta la secuencia de comandos que genere un fallo inmediato si hay problemas más adelante en la secuencia de comandos. A continuación, la secuencia de comandos verifica que tmp/pids/server.pid no esté presente para garantizar que no se produzcan conflictos de servidores cuando iniciemos la aplicación. Por último, la secuencia de comandos inicia el servidor de Rails con el comando bundle exec rails s. Usamos la opción -b con este comando para vincular el servidor a todas las direcciones IP y no a la predeterminada, localhost. Esta invocación hace que el servidor de Rails dirija las solicitudes a la dirección IP del contenedor en lugar de usar el localhost predeterminado.
Guarde y cierre el archivo cuando concluya la edición.
Haga que la secuencia de comandos sea ejecutable:
- chmod +x entrypoints/docker-entrypoint.sh
A continuación, crearemos una secuencia de comandos para iniciar nuestro servicio sidekiq que procesará nuestros trabajos de Sidekiq. Para obtener más información sobre la forma en que esta aplicación usa Sidekiq, consulte Cómo agregar Sidekiq y Redis a una aplicación de Ruby on Rails.
Abra un archivo para la secuencia de comandos de punto de entrada de Sidekiq:
- nano entrypoints/sidekiq-entrypoint.sh
Añada el siguiente código al archivo para iniciar Sidekiq:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec sidekiq
Esta secuencia de comandos inicia Sidekiq en el contexto de nuestro paquete de aplicaciones.
Guarde y cierre el archivo cuando concluya la edición. Haga que sea ejecutable:
- chmod +x entrypoints/sidekiq-entrypoint.sh
Con sus secuencias de comandos de punto de entrada y Dockerfile, estará listo para definir sus servicios en su archivo de Compose.
Paso 4: Definir servicios con Docker Compose
Usando Docker Compose, podremos ejecutar los diferentes contenedores necesarios para nuestra configuración. Definiremos nuestros servicios de Compose en nuestro archivo docker-compose.yml principal: Un servicio en Compose es un contenedor en ejecución y las definiciones del servicio, que incluirá en su archivo docker-compose.yml, contienen información sobre cómo se ejecutará cada imagen del contenedor. La herramienta Compose le permite definir varios servicios para crear aplicaciones en diferentes contenedores.
En la configuración de nuestra aplicación se incluirán los siguientes servicios:
- La propia aplicación
- La base de datos de PostgreSQL
- Redis
- Sidekiq
También incluiremos un montaje bind como parte de nuestra configuración, de modo que cualquier cambio de código que hagamos durante el desarrollo se sincronice de inmediato con los contenedores que necesiten acceso a este código.
Tenga en cuenta que no definiremos un servicio test, ya que estas encuentran fuera del alcance de este tutorial y esta serie, pero podría hacerlo siguiendo el anterior que usaremos aquí para el servicio sidekiq.
Abra el archivo docker-compose.yml:
- nano docker-compose.yml
Primero, añada la definición del servicio de la aplicación:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
La definición del servicio app incluye las siguientes opciones:
build: define las opciones de configuración, incluido elcontextydockerfile, que se aplicarán cuando Compose cree la imagen de la aplicación. Si desea utilizar una imagen existente de un registro como Docker Hub, podría utilizar la instrucciónimagecomo alternativa, con información sobre su nombre de usuario, repositorio y etiqueta de imagen.context: esto define el contexto de compilación para la compilación de la imagen; en este caso, el directorio del proyecto actual.dockerfile: esto especifica elDockerfiledel directorio actual de su directorio como el archivo que Compose usará para complilar la imagen de la aplicación.depends_on: esto establece primerodatabasey los contenedores deredispara que estén listos y en ejecución antes queapp.ports: asigna el puerto3000del host al puerto3000del contenedor.volumes: incluiremos dos tipos de montajes aquí:- El primero es un montaje bind, que monta el código de nuestra aplicación del host en el directorio
/appdel contenedor. Esto facilitará un desarrollo rápido, ya que cualquier cambio que realice a su código de host se completará de inmediato en el contenedor. - El segundo es un volumen con nombre:
gem_cache. Cuando la instrucciónbundle installse ejecute en el contenedor, instalará las gemas del proyecto. Añadir este volumen significa que si recrea el contenedor, las gemas se montarán en el nuevo contenedor. Para este montaje se prevé que no se produjeron cambios en el proyecto, de modo que si realiza cambios en las gemas de su proyecto, deberá recordar eliminar este volumen antes de recrear el servicio de su aplicación. - El tercero es un volumen con nombre para el directorio
node_modules. En lugar de contar connode_modulesmontados en el host, que pueden generar discrepancias de paquetes y conflictos de permisos durante el desarrollo, este volumen garantizará que los paquetes de este directorio se mantengan y reflejen el estado actual del proyecto. Una vez más, si modifica las dependencias del proyecto de Node, deberá eliminar y recrear este volumen.
- El primero es un montaje bind, que monta el código de nuestra aplicación del host en el directorio
env_file: indica a Compose que deseamos añadir variables de entorno de un archivo llamado.env, ubicado en el contexto de compilación.environment: usar esta opción nos permite establecer una variable de entorno no sensible y pasar información sobre el entorno de Rails al contenedor.
A continuación, debajo de la definición del servicio app, añada el siguiente código para definir su servicio database:
. . .
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
A diferencia del servicio app, el servicio database obtiene una imagen de postgres directamente del Hub de Docker. Tenga en cuenta que también anclaremos la versión aquí, en lugar de fijarla en latest o no especificarla (su valor predeterminado es latest). De esta forma, podemos garantizar que esta configuración funcione con las versiones aquí especificadas y evitar sorpresas inesperadas con cambios por código dañado en la imagen.
Aquí, también incluiremos un volumen db_data, que conservará los datos de nuestra aplicación entre uno y otro inicio del contenedor. Además, montamos nuestra secuencia de comandos de inicio init.sql en el directorio apropiado, docker-entrypoint-initdb.d/ del contenedor, a fin de crear nuestro usuario de base de datos sammy. Después de que el punto de entrada de imagen cree el usuario y la base de datos de postgres predeterminados, ejecutará cualquier secuencia de comandos del directorio docker-entrypoint-initdb.d/ que puede usar para las tareas de inicialización necesarias. Para obtener más información, consulte la sección Secuencias de comandos de inicialización de la documentación de imagen de PostgreSQL.
A continuación, añada la definición del servicio de redis:
. . .
redis:
image: redis:5.0.7
Al igual que el servicio database, el servicio de redis utiliza una imagen del Hub de Docker. En este caso, no conservaremos la caché de trabajo de Sidekiq.
Por último, añada la definición del servicio sidekiq:
. . .
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
Nuestro servicio sidekiq se asemeja a nuestro servicio app en algunos aspectos: el contexto y la imagen de compilación, las variables de entorno y el volumen que usa son los mismos. Sin embargo, depende de los servicios app, redis y database, y se iniciará en último lugar. Además, utiliza un entrypoint que anulará el punto de entrada establecido en el Dockerfile. Este ajuste entrypoint apunta a entrypoints/sidekiq-entrypoint.sh, que incluye el comando indicado para iniciar el servicio sidekiq.
Como paso final, añada las definiciones de volumen que se encuentran debajo de la definición del servicio sidekiq:
. . .
volumes:
gem_cache:
db_data:
node_modules:
Nuestra clave de volúmenes de nivel superior define lo volúmenes gem_cache, db_data y node_modules. Cuando Docker crea volúmenes, el contenido de estos se almacena en una parte del sistema de archivos de host, /var/ib/docker/volume/, que Docker administra. El contenido de cada volumen se almacena en un directorio en /var/lib/docker/volume/ y se monta en cualquier contenedor que utilice el volumen. De esta forma, los datos sobre tiburones que nuestros usuarios crearán persistirán en el volumen db_data, incluso si eliminamos y volvemos a crear el servicio database.
El archivo terminado tendrá este aspecto:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
redis:
image: redis:5.0.7
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
volumes:
gem_cache:
db_data:
node_modules:
Guarde y cierre el archivo cuando concluya la edición.
Una vez escritas sus definiciones de su servicios, estará listo para iniciar la aplicación.
Paso 5: Probar la aplicación
Una vez implementado su archivo docker-compose.yml, puede crear sus servicios con el comando docker-compose up y propagar su base de datos. También puede comprobar que sus datos persisitirán deteniendo y eliminando sus contenedores con docker-compose down y volviendo a crearlos.
Primero, compile las imágenes del contenedor y cree los servicios ejecutando docker-compose up con el indicador -d, que luego ejecutará los contenedores en segundo plano.
- docker-compose up -d
Verá un resultado que indicará la creación de sus servicios:
OutputCreating rails-docker_database_1 ... done
Creating rails-docker_redis_1 ... done
Creating rails-docker_app_1 ... done
Creating rails-docker_sidekiq_1 ... done
También puede obtener información más detallada sobre los procesos de inicio mostrando el resultado del registro de los servicios:
- docker-compose logs
Si todo se inició de forma correcta, verá algo similar a esto:
Outputsidekiq_1 | 2019-12-19T15:05:26.365Z pid=6 tid=grk7r6xly INFO: Booting Sidekiq 6.0.3 with redis options {:host=>"redis", :port=>"6379", :id=>"Sidekiq-server-PID-6", :url=>nil}
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Running in ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux-musl]
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: See LICENSE and the LGPL-3.0 for licensing details.
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Upgrade to Sidekiq Pro for more features and support: http://sidekiq.org
app_1 | => Booting Puma
app_1 | => Rails 5.2.3 application starting in development
app_1 | => Run `rails server -h` for more startup options
app_1 | Puma starting in single mode...
app_1 | * Version 3.12.1 (ruby 2.5.1-p57), codename: Llamas in Pajamas
app_1 | * Min threads: 5, max threads: 5
app_1 | * Environment: development
app_1 | * Listening on tcp://0.0.0.0:3000
app_1 | Use Ctrl-C to stop
. . .
database_1 | PostgreSQL init process complete; ready for start up.
database_1 |
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: starting PostgreSQL 12.1 (Debian 12.1-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv6 address "::", port 5432
database_1 | 2019-12-19 15:05:20.163 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
database_1 | 2019-12-19 15:05:20.182 UTC [63] LOG: database system was shut down at 2019-12-19 15:05:20 UTC
database_1 | 2019-12-19 15:05:20.187 UTC [1] LOG: database system is ready to accept connections
. . .
redis_1 | 1:M 19 Dec 2019 15:05:18.822 * Ready to accept connections
También puede verificar el estado de sus contenedores con docker-compose ps:
- docker-compose ps
Verá un resultado que indicará que sus contenedores están en ejecución:
Output Name Command State Ports
-----------------------------------------------------------------------------------------
rails-docker_app_1 ./entrypoints/docker-resta ... Up 0.0.0.0:3000->3000/tcp
rails-docker_database_1 docker-entrypoint.sh postgres Up 5432/tcp
rails-docker_redis_1 docker-entrypoint.sh redis ... Up 6379/tcp
rails-docker_sidekiq_1 ./entrypoints/sidekiq-entr ... Up
A continuación, cree y propague su base de datos, y ejecute migraciones en ella con el siguiente comando docker-compose exec:
- docker-compose exec app bundle exec rake db:setup db:migrate
El comando docker-compose exec le permite ejecutar comandos en sus servicios; lo usaremos aquí para que ejecute rake db:setup y db:migrate en el contexto del paquete de nuestra aplicación, a fin de crear y sembrar la base de datos y ejecutar migraciones. A medida que trabaje en el desarrollo, docker-compose exec será útil para usted cuando desee ejecutar migraciones con su base de datos de desarrollo.
Verá el siguiente resultado después de ejecutar este comando:
OutputCreated database 'rails_development'
Database 'rails_development' already exists
-- enable_extension("plpgsql")
-> 0.0140s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0097s
-- create_table("posts", {:force=>:cascade})
-> 0.0108s
-- create_table("sharks", {:force=>:cascade})
-> 0.0050s
-- enable_extension("plpgsql")
-> 0.0173s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0088s
-- create_table("posts", {:force=>:cascade})
-> 0.0128s
-- create_table("sharks", {:force=>:cascade})
-> 0.0072s
Una vez que sus servicios estén en ejecución, puede visitar localhost:3000 o http://your_server_ip:3000 en el navegador. Verá una página de aterrizaje similar a esta:
Ahora, podemos probar la persistencia de datos. Cree un nuevo tiburón haciendo clic en el botón Get Shark Info, que lo dirigirá a la ruta sharks/index:
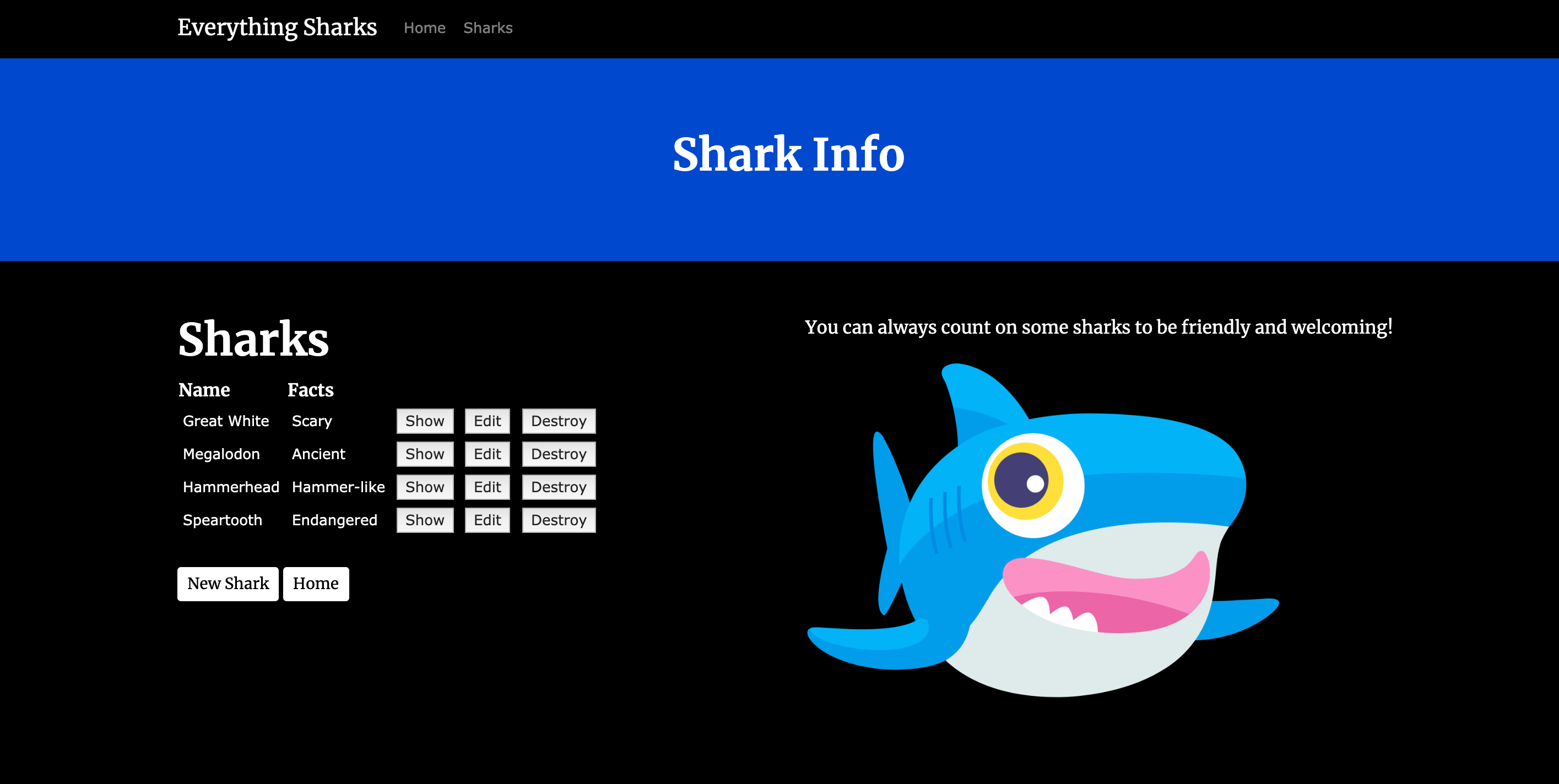
Para verificar que la aplicación funcione, podemos añadirle información de prueba. Haga clic en New Shark. Gracias a la configuración de autenticación del proyecto, se le solicitará un nombre de usuario (sammy) y una contraseña (tiburón).
En la página New Shark, ingrese “Mako” en el campo Name y “Fast” en el campo Facts.
Haga clic en el botón Create Shark para crear el tiburón. Una vez que haya creado el tiburón, haga clic en Home en la barra de navegación del sitio para volver a la página de aterrizaje de la aplicación. Ahora, podemos probar que Sidekiq funciona.
Haga clic en el botón** ¿Which Sharks Are In Danger?** . Debido a que no cargó ningún tiburón en peligro, esto lo dirigirá a la vista de endangered index:

Haga clic en Import Endangered Sharks para importar los tiburones. Verá un mensaje de estado que le indicará que los tiburones se importaron:

También verá el comienzo de la importación. Actualice su página para ver la tabla entera:

Gracias a Sidekiq, realizamos la carga del gran lote de tiburones en peligro sin cerrar el navegador ni interferir con otras funciones de la aplicación.
Haga clic en el botón Home en la parte inferior de la página, que lo llevará de vuelta a la página principal de la aplicación:
Aquí, haga clic en Which Sharks Are in Danger? nuevamente. Verá los tiburones cargados otra vez.
Ahora que sabemos que nuestra aplicación funciona correctamente, podemos probar la persistencia de nuestros datos.
Cuando regrese a su terminal, escriba el siguiente comando para detener y eliminar sus contenedores:
- docker-compose down
Tenga en cuenta que no incluiremos la opción --volumes; por lo tanto, no se eliminará nuestro volumen db_data.
El siguiente resultado confirma que se eliminaron sus contenedores y su red:
OutputStopping rails-docker_sidekiq_1 ... done
Stopping rails-docker_app_1 ... done
Stopping rails-docker_database_1 ... done
Stopping rails-docker_redis_1 ... done
Removing rails-docker_sidekiq_1 ... done
Removing rails-docker_app_1 ... done
Removing rails-docker_database_1 ... done
Removing rails-docker_redis_1 ... done
Removing network rails-docker_default
Vuelva a crear los contenedores:
- docker-compose up -d
Abra la consola de Rails en el contenedor app con docker-compose exec y bundle exec rails console:
- docker-compose exec app bundle exec rails console
En el símbolo de sistema, inspeccione el registro last de Tiburón de la base de datos:
- Shark.last.inspect
Verá el registro que acaba de crear:
IRB session Shark Load (1.0ms) SELECT "sharks".* FROM "sharks" ORDER BY "sharks"."id" DESC LIMIT $1 [["LIMIT", 1]]
=> "#<Shark id: 5, name: \"Mako\", facts: \"Fast\", created_at: \"2019-12-20 14:03:28\", updated_at: \"2019-12-20 14:03:28\">"
Luego, puede verificar que sus tiburones endangered se hayan conservado con el siguiente comando:
- Endangered.all.count
IRB session (0.8ms) SELECT COUNT(*) FROM "endangereds"
=> 73
Su volumen db_data se montó correctamente en el servicio database recreado, lo cual posibilitó que su servicio app accediera a los datos guardados. Si accede directamente a la página index shark visitando localhost:3000/sharks o http://your_server_ip:3000/sharks, también verá el registro:

Sus tiburones en peligro también se encontrarán en la vista localhost:3000/endangered/data o http://your_server_ip:3000/endangered/data:
Su aplicación ahora se ejecuta en los contenedores de Docker con la persistencia de datos y la sincronización de códigos habilitadas. Puede probar los cambios de código local en su host, que se sincronizarán con su contenedor gracias al montaje que definimos como parte del servicio de app.
Conclusión
Siguiendo este tutorial, creó una configuración de desarrollo para su aplicación de Rails usando contenedores de Docker. Hizo que su proyecto fuera más modular y portátil mediante la extracción de información confidencial y la desvinculación del estado de su aplicación de su código. También configuró un archivo docker-compose.yml estándar que podrá revisar a medida que sus necesidades y requisitos de desarrollo cambien.
A medida que realice desarrollos, es posible que le interese aprender más sobre cómo diseñar aplicaciones para flujos de trabajo en contenedores y de Cloud Native. Consulte Crear aplicaciones para Kubernetes y Modernizar aplicaciones para Kubernetes para obtener más información sobre estos temas. O bien, si desea invertir en una secuencia de aprendizaje de Kubernetes, consulte Kubernetes para desarrolladores Full-Stack.
Para obtener más información sobre el código de la aplicación en sí, consulte los otros tutoriales de esta serie:
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Developer at DigitalOcean community. Expertise in areas including Ubuntu, Docker, Ruby on Rails, Debian, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
great tutorial, it help me a lot. But I think you miss the password assignation to the user sammy in postgresql. How do you recommend to do this and keep the password out of code?
Very complete tutorial. I had troubles with the python package, had to change it to python3 so the docker could build the app image.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
