Sr Technical Content Strategist and Team Lead

Introduction
Multiclass classification problems are common in machine learning, but they can be complex to manage and interpret. Converting a multiclass dataset to a binary one can simplify your workflow, particularly when using binary classification models like logistic regression or support vector machines (SVM).
In this tutorial, you’ll learn how to convert a multiclass dataset to a binary one using Python, scikit-learn, and different strategy options like One-vs-Rest and custom label filtering. You’ll also learn how to avoid common problems in binary classification preprocessing.
Prerequisites
To complete this tutorial, you should have:
-
Familiarity with basic machine learning concepts.
-
Experience using Python and the scikit-learn library.
-
Python 3 installed on your machine.
-
pandas, scikit-learn, matplotlib, and seaborn installed.
pip install pandas scikit-learn matplotlib seaborn
Multiclass Dataset vs Binary Dataset
A multiclass dataset is a dataset that has more than two classes. For example, a dataset with three classes would be a multiclass dataset. A binary dataset is a dataset that has only two classes. For example, a dataset with two classes would be a binary dataset.
To illustrate the difference, let’s consider an example. Suppose we have a dataset of images labeled as either “dog”, “cat”, or “bird”. This dataset would be considered a multiclass dataset because it has three classes. If we were to convert this dataset to a binary dataset, we might choose to label the images as either “dog” or “not dog”. This would result in a binary dataset with two classes.
Here’s an example code block in Python that demonstrates how to convert a multiclass dataset to a binary dataset:
# Assuming 'labels' is a list of multiclass labels
binary_labels = [1 if label == 'dog' else 0 for label in labels]
In this example, we’re converting the multiclass labels to binary labels by checking if each label is “dog”. If it is, we assign a binary label of 1; otherwise, we assign a binary label of 0. This results in a binary dataset where each sample is classified as either “dog” (1) or “not dog” (0).
Why Convert a Multiclass Dataset to Binary?
Converting a multiclass dataset to a binary one can be beneficial in various scenarios. Here are some compelling reasons to consider this approach:
- Algorithm limitations: Some machine learning models, such as logistic regression, are designed to handle binary classification problems. By converting a multiclass dataset to binary, you can utilize these models effectively.
- Simplifying the problem: Binary classification problems are often easier to understand and optimize compared to their multiclass counterparts. This simplification can lead to faster model development and better performance.
- Business requirements: In some cases, the primary goal is to distinguish a specific class from all others. For instance, in medical diagnosis, identifying a particular disease might be more critical than differentiating between multiple diseases. Binary classification can help focus on this specific task.
- Model performance: Multiclass classification problems can be challenging due to the increased complexity of the problem space. By reducing the problem to a binary classification task, you can potentially improve model performance by simplifying the learning task and reducing the risk of overfitting.
When Not to Convert to Binary
It is essential to carefully consider the implications of converting a multiclass dataset to a binary one. There are scenarios where this conversion might not be the best approach. Avoid converting to binary when:
- Preserving relationships between classes is crucial: In cases where the relationships between classes are essential for the downstream task, converting to binary might lead to a loss of valuable information. For instance, in a sentiment analysis task, understanding the nuances between positive, neutral, and negative sentiments is vital. Reducing this to a binary classification problem might oversimplify the task and result in suboptimal performance.
- Working with ordinal classes: Ordinal classes, such as ratings (e.g., 1-5 stars), have an inherent order or ranking. Converting these to binary would disregard this ordering, potentially leading to inaccurate or misleading results. In such cases, it is more appropriate to use ordinal regression or other specialized techniques that account for the ordinal nature of the classes.
- Class balance is critical: If the conversion to binary would introduce severe class imbalance, it might be detrimental to the model’s performance. For example, if the original multiclass dataset has a balanced distribution of classes, but the binary conversion would result in one class having significantly more instances than the other, this could lead to biased models that favor the majority class. In such scenarios, it is crucial to address class imbalance issues before or during the conversion process.
- Hierarchical or structured relationships exist: In datasets with hierarchical or structured relationships between classes, converting to binary might not capture these relationships effectively. For instance, in a dataset with classes like “animal”, “mammal”, “dog”, and “cat”, there is a clear hierarchical structure. Reducing this to a binary classification problem might not adequately represent these relationships, leading to suboptimal performance or inaccurate predictions.
In these scenarios, it is often more appropriate to use multiclass classification or hierarchical classification techniques that can effectively capture the complexities and relationships within the dataset.
Summary Table: When to Convert Multiclass to Binary
| Scenario | Convert to Binary | Do Not Convert to Binary |
|---|---|---|
| Algorithm Limitations | When using models designed for binary classification, like logistic regression. For example, if you have a dataset with classes “cat”, “dog”, and “bird”, and you want to use logistic regression, you can convert it to “dog” vs “not dog”. | No |
| Simplifying the Problem | When a simpler problem can lead to faster development and better performance. For instance, converting a multiclass sentiment analysis task (“positive”, “neutral”, “negative”) to binary (“positive” vs “not positive”) can simplify the model. | No |
| Business Requirements | When the goal is to distinguish a specific class from all others. For example, in fraud detection, you might convert a dataset to “fraud” vs “not fraud” to focus on identifying fraudulent transactions. | No |
| Model Performance | When reducing complexity can improve performance and reduce overfitting. For instance, if a multiclass image classification model is overfitting, converting to binary (“cat” vs “not cat”) might help. | No |
| Preserving Class Relationships | No | When relationships between classes are crucial for the task. For example, in a language classification task, preserving the distinction between dialects might be important. |
| Ordinal Classes | No | When classes have an inherent order or ranking. For example, converting a rating system (1-5 stars) to binary would lose the ordinal information. |
| Class Balance | No | When conversion introduces severe class imbalance. For instance, if converting a balanced dataset of “apple”, “banana”, “cherry” to “apple” vs “not apple” results in 90% “not apple”, it could bias the model. |
| Hierarchical Relationships | No | When classes have hierarchical or structured relationships. For example, in a taxonomy of animals, converting to binary might lose the hierarchical context, such as “mammal” vs “reptile”. |
This table provides a quick reference to help decide whether to convert a multiclass dataset to a binary one based on specific scenarios and considerations.
Common Strategies to Convert Multiclass to Binary
There are several strategies to convert a multiclass dataset to a binary one. Here are some of the most common ones:
1. One-vs-Rest (OvR) Classification
One-vs-Rest (OvR) classification is a strategy that builds one binary classifier per class. Each classifier learns to distinguish one class from all others.
When to use One-vs-Rest (OvR) Classification
- When you want to compare each class against all others.
- Useful for multiclass problems where each class is distinct and equally important.
- Can be beneficial when classes are balanced or nearly balanced, meaning each class has a similar number of samples. This is important because One-vs-Rest classification can be sensitive to class imbalance, where one class has significantly more samples than others. For example, if we have a dataset with two classes, “dog” and “not dog”, and the “dog” class has 1000 samples while the “not dog” class has 100 samples, the model might be biased towards the “dog” class due to its larger sample size. In such cases, One-vs-Rest classification might not perform well. However, if the classes are balanced or nearly balanced, this approach can be effective.
Advantages:
- Allows for a more detailed understanding of each class’s relationship with others.
- Can be used with various binary classification algorithms.
- Enables the identification of the most discriminative features for each class.
Implementation in Python:
Here’s an example implementation using scikit-learn’s OneVsRestClassifier with the Iris dataset:
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Define the One-vs-Rest classifier with Logistic Regression
ovr_classifier = OneVsRestClassifier(LogisticRegression())
# Fit the classifier
ovr_classifier.fit(X, y)
# Predictions
predictions = ovr_classifier.predict(X)
# Output
print("Predictions:")
print(predictions)
OutputPredictions:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1
1 1 1 2 1 1 1 1 1 2 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2
2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Explanation of the code block:
-
We first load the Iris dataset, which is a multiclass problem with three classes.
-
We then define a OneVsRestClassifier with LogisticRegression as the base estimator.
-
The
fitmethod is used to train the classifier on the dataset. -
Finally, we use the trained classifier to make predictions on the dataset.
-
The
OneVsRestClassifierwill train three binary classifiers, one for each class in the Iris dataset, to distinguish each class from the rest. -
The predictions will be a binary vector for each class, indicating whether a sample belongs to that class or not.
This implementation demonstrates how to apply the One-vs-Rest strategy to a multiclass problem using scikit-learn.
When to avoid One-vs-Rest (OvR) Classification
- Class imbalance: One-vs-Rest classification can be sensitive to class imbalance, where one class has significantly more samples than others. This can lead to biased models that favor the majority class, resulting in poor performance on minority classes. For instance, in a dataset with two classes, “dog” and “not dog”, if the “dog” class has 1000 samples while the “not dog” class has 100 samples, the model might be biased towards the “dog” class due to its larger sample size.
- Non-mutually exclusive classes: One-vs-Rest classification assumes that each sample belongs to only one class. However, in scenarios where classes are not mutually exclusive, meaning a sample can belong to more than one class, this approach can lead to inaccurate results. For example, in a dataset where a sample can be both “dog” and “pet”, the One-vs-Rest approach would not capture this relationship accurately.
- High-dimensional datasets: One-vs-Rest classification can be computationally expensive and prone to overfitting when dealing with high-dimensional datasets. This is because the approach trains a binary classifier for each class, which can lead to an explosion in the number of models to train and evaluate.
- Noise or outliers in the data: The presence of noise or outliers in the dataset can negatively impact the performance of One-vs-Rest classification. Since the approach trains a binary classifier for each class, noisy or outlier samples can significantly affect the model’s performance, leading to inaccurate results.
- Classes with complex relationships: One-vs-Rest classification might not capture complex relationships between classes accurately. For instance, in a dataset where classes have hierarchical or nested relationships, this approach might not effectively model these relationships, leading to suboptimal performance.
2. One-vs-One (OvO) Classification
One-vs-One (OvO) classification is a strategy that builds one binary classifier for every pair of classes. Each classifier learns to distinguish one class from the other. This approach is particularly useful when you want to compare two specific classes or understand the relationships between each pair of classes in a multiclass problem.
When to use One-vs-One (OvO) Classification
- When you want to compare two specific classes, OvO classification provides a detailed understanding of how each class differs from the other.
- In scenarios where the number of classes is relatively small, OvO classification can be beneficial as it trains a binary classifier for each pair of classes, resulting in a more comprehensive analysis of the relationships between classes.
- OvO classification is also suitable for problems where there are more than two classes, and the classes are not mutually exclusive, and a sample can belong to more than one class.
Implementation in Python:
Here’s an example implementation using scikit-learn’s OneVsOneClassifier with the Iris dataset:
from sklearn.multiclass import OneVsOneClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Define the One-vs-One classifier with Logistic Regression
ovo_classifier = OneVsOneClassifier(LogisticRegression())
# Fit the classifier
ovo_classifier.fit(X, y)
# Predictions
predictions = ovo_classifier.predict(X)
# Output
print("Predictions:")
print(predictions)
OutputPredictions:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1
1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
Explanation of the code block:
-
We first load the Iris dataset, which is a multiclass problem with three classes.
-
We then define a OneVsOneClassifier with LogisticRegression as the base estimator.
-
The
fitmethod is used to train the classifier on the dataset. -
Finally, we use the trained classifier to make predictions on the dataset.
-
The
OneVsOneClassifierwill train three binary classifiers, one for each pair of classes in the Iris dataset, to distinguish each pair of classes from each other. -
The predictions will be a binary vector for each pair of classes, indicating whether a sample belongs to one class or the other.
This implementation demonstrates how to apply the One-vs-One strategy to a multiclass problem using scikit-learn.
When to avoid One-vs-One (OvO) Classification
- Class imbalance: One-vs-One classification can be sensitive to class imbalance, where one class has significantly more samples than others. This can lead to biased models that favor the majority class, resulting in poor performance on minority classes. For instance, in a dataset with two classes, “dog” and “not dog”, if the “dog” class has 1000 samples while the “not dog” class has 100 samples, the model might be biased towards the “dog” class due to its larger sample size.
- Non-mutually exclusive classes: One-vs-One classification assumes that each sample belongs to only one class. However, in scenarios where classes are not mutually exclusive, meaning a sample can belong to more than one class, this approach can lead to inaccurate results. For example, in a dataset where a sample can be both “dog” and “pet”, the One-vs-One approach would not capture this relationship accurately.
- High-dimensional datasets: One-vs-One classification can be computationally expensive and prone to overfitting when dealing with high-dimensional datasets. This is because the approach trains a binary classifier for each pair of classes, which can lead to an explosion in the number of models to train and evaluate.
- Noise or outliers in the data: The presence of noise or outliers in the dataset can negatively impact the performance of One-vs-One classification. Since the approach trains a binary classifier for each pair of classes, noisy or outlier samples can significantly affect the model’s performance, leading to inaccurate results.
- Classes with complex relationships: One-vs-One classification might not capture complex relationships between classes accurately. For instance, in a dataset where classes have hierarchical or nested relationships, this approach might not effectively model these relationships, leading to suboptimal performance.
Label Filtering (Manual Relabeling)
Label filtering, also known as manual relabeling, is a straightforward approach to convert a multiclass dataset into a binary dataset by manually selecting specific classes of interest and discarding the rest. This strategy is particularly beneficial when the analysis requires a focus on a subset of classes, simplifying the problem and improving model interpretability.
When to use Label Filtering
- Focused analysis: Label filtering is ideal when the analysis needs to concentrate on a specific subset of classes, reducing the complexity of the problem and enhancing model interpretability.
- Non-mutually exclusive classes: This approach is suitable when the classes are not mutually exclusive, meaning a sample can belong to more than one class. For example, in a dataset of animals, a sample can be both a “mammal” and a “carnivore”. Label filtering allows for the selection of specific classes without affecting the overall dataset structure.
Implementation in Python:
Here’s an example implementation of label filtering using the Iris dataset, focusing on classes 0 and 1:
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Filter labels to include only classes 0 and 1
filtered_X = X[y <= 1]
filtered_y = y[y <= 1]
# Output
print("Filtered Dataset:")
print("X shape:", filtered_X.shape)
print("y shape:", filtered_y.shape)
OutputFiltered Dataset:
X shape: (100, 4)
y shape: (100,)
Explanation of the code block:
- We first load the Iris dataset, which is a multiclass problem with three classes.
- We then filter the dataset to include only samples from classes 0 and 1 by applying a condition to the target variable
y. - The filtered dataset is stored in
filtered_Xandfiltered_y, which now contain only the samples and labels related to classes 0 and 1. - The output shows the shape of the filtered dataset, indicating the number of samples and features retained after applying label filtering.
This implementation demonstrates how to apply label filtering to a multiclass problem using Python, focusing on specific classes of interest and simplifying the dataset for analysis.
When to avoid Label Filtering
- Loss of information: Label filtering discards information about other classes. This can be a significant drawback if the discarded classes contain valuable information for your use case. Consider if this is acceptable for your problem.
- Inappropriate grouping: Avoid grouping classes randomly, as this can lead to meaningless or misleading binary splits. Instead, base your grouping on the problem’s domain knowledge and the relationships between the classes. For example, in a dataset of animals, grouping “mammals” and “birds” together might not be as meaningful as grouping “carnivores” and “herbivores”.
Transforming Multiclass to Binary Classification with the Wine Dataset Using scikit-learn
scikit-learnIn this section, you’ll learn how to convert a multiclass dataset (the Wine dataset) into a binary classification problem using scikit-learn. You will learn to implement the full pipeline — from data loading and label transformation to model training, evaluation, and visualization.
The Wine dataset includes three classes of wine (Class 0, Class 1, Class 2), based on chemical composition. Specifically:
- Class 0 represents wines from the Barolo region, known for their rich, full-bodied flavor profile.
- Class 1 represents wines from the Grignolino region, characterized by their crisp acidity and fruity flavors.
- Class 2 represents wines from the Barbaresco region, recognized for their balanced tannins and complex aromas.
We’ll simplify this into a binary classification task:
Predict whether a wine sample is of Class 0 (yes/no).
This means:
- 1 = Wine is from Class 0 (Barolo region)
- 0 = Wine is from Class 1 (Grignolino region) or Class 2 (Barbaresco region)
You will use a One-vs-Rest strategy, where you isolate one class of interest and group the rest.
Step 1 - Load and Inspect the Data
from sklearn.datasets import load_wine
import pandas as pd
# Load the dataset
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)
wine_df['target'] = wine.target
# View class distribution
print(wine_df['target'].value_counts())
Outputtarget
1 71
0 59
2 48
Name: count, dtype: int64
As per the output this dataset is fairly balanced, making it a better choice for binary classification task.
Step 2 - Convert Multiclass Labels to Binary
We’ll now convert the original target column into a binary target:
wine_df['binary_target'] = (wine_df['target'] == 0).astype(int)
Here, we’re asking: “Is this sample Class 0 (value = 1) or not (value = 0)?”
Step 3 - Visualize the Class Distribution
Understanding class balance is important to avoid training on biased data.
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data=wine_df, x='binary_target')
plt.title("Binary Class Distribution: Class 0 vs Others")
plt.xlabel("Binary Target (0 = Others, 1 = Class 0)")
plt.ylabel("Sample Count")
plt.tight_layout()
plt.show()
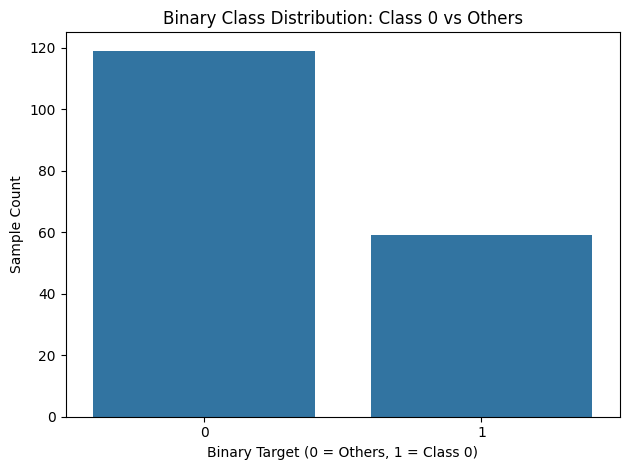
This plot helps verify whether your dataset is balanced after the label transformation.
Next, let’s build a binary classification model.
Step 4 - Prepare Features and Labels
Split the dataset into features and binary labels:
X = wine_df[wine.feature_names]
y = wine_df['binary_target']
Split it into training and test sets:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
Step 5 - Train a Binary Classification Model
You’ll use a simple logistic regression model for this task.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
Step 6 - Evaluate the Model
In this step, you’ll evaluate the model’s performance on the test set. The classification report provides a detailed breakdown of the model’s performance for each class.
from sklearn.metrics import classification_report
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
Output precision recall f1-score support
0 0.95 0.91 0.93 19
1 0.96 0.98 0.97 35
accuracy 0.95 54
macro avg 0.95 0.95 0.95 54
weighted avg 0.95 0.95 0.95 54
The output shows that the model has achieved high precision, recall, and f1-score for both classes. The precision for class 0 is 0.95, indicating that 95% of the samples predicted as class 0 are actually class 0. The recall for class 0 is 0.91, indicating that 91% of the actual class 0 samples were correctly predicted. The f1-score, which is the harmonic mean of precision and recall, is 0.93 for class 0. Similarly, the model has achieved high precision, recall, and f1-score for class 1.
The accuracy of the model is 0.95, indicating that the model correctly classified 95% of the samples in the test set. The macro average and weighted average scores are also high, indicating that the model is performing well across both classes.
Overall, the model’s performance is excellent, indicating that it is capable of accurately distinguishing between the two classes.
Step 7 - Visualize the Model’s Performance
You can visualize the model’s performance using a confusion matrix.
The confusion matrix gives a clear picture of how well your binary classifier is performing by breaking down:
-
True Positives (TP): Correctly predicting a sample as class 1 when it is actually class 1.
-
True Negatives (TN): Correctly predicting a sample as class 0 when it is actually class 0.
-
False Positives (FP): Incorrectly predicting a sample as class 1 when it is actually class 0.
-
False Negatives (FN): Incorrectly predicting a sample as class 0 when it is actually class 1.
Use scikit-learn’s confusion_matrix and ConfusionMatrixDisplay utilities:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Predictions
y_pred = model.predict(X_test)
# Confusion matrix
confusion = confusion_matrix(y_test, y_pred)
# Displaying the confusion matrix
disp = ConfusionMatrixDisplay(confusion_matrix=confusion)
disp.plot()
plt.title('Confusion Matrix')
plt.colorbar()
plt.show()
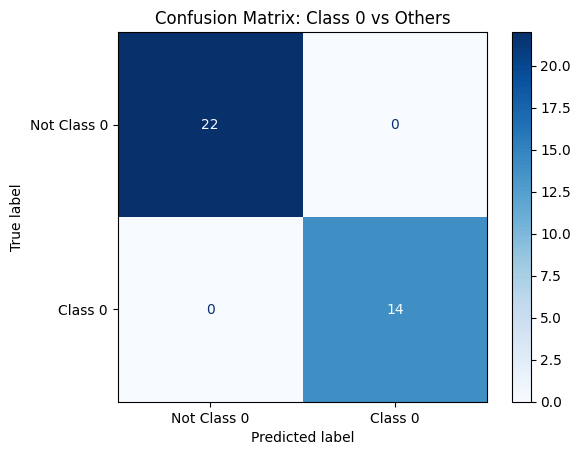
The confusion matrix shows that the model has correctly predicted 14 samples as class 0 (True Negatives) and 22 samples as class 1 (True Positives). It has also incorrectly predicted 0 sample as class 1 (False Positives) and 0 samples as class 0 (False Negatives).
This visualization helps you understand the model’s performance in terms of precision, recall, and overall accuracy.
Common Pitfalls and How to Avoid Them
When converting a multiclass dataset to a binary one, it’s essential to be aware of potential pitfalls that can impact the accuracy and reliability of your model. Here are some common mistakes to watch out for and tips on how to avoid them:
-
Data leakage during relabeling:
Data leakage occurs when information from the test set influences the training process, leading to overfitting and poor generalization. To avoid this, always split your dataset into training and testing sets before relabeling. This ensures that the model is trained and evaluated on separate datasets, preventing data leakage and ensuring a more accurate assessment of its performance.For example, consider a dataset where you want to predict whether a customer will churn or not based on their usage patterns. If you relabel the dataset without splitting it first, the model might learn patterns specific to the test set, leading to overfitting. To avoid this, split the dataset into training and testing sets before relabeling:
from sklearn.model_selection import train_test_split # Assuming X is the feature set and y is the target variable X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) -
Loss of information:
The process of converting a multiclass dataset to a binary one inherently discards information about other classes. This can be problematic if the discarded classes are relevant to the problem you’re trying to solve. Before converting your dataset, consider whether the loss of information is acceptable for your specific use case. If not, you may need to explore alternative approaches, such as using a multiclass classification algorithm or retaining the original multiclass structure.For instance, suppose you have a dataset for classifying images into three categories: animals, vehicles, and buildings. If you convert this dataset to a binary problem by grouping animals and vehicles together, you might lose valuable information about the differences between these two classes. In such cases, it might be better to use a multiclass classification algorithm or retain the original multiclass structure.
-
Inappropriate grouping:
When grouping classes into a binary classification problem, it’s crucial to ensure that the grouping makes sense for your problem. Avoid grouping classes arbitrarily, as this can lead to a model that’s not well-suited to the task at hand. Instead, carefully consider the relationships between classes and group them in a way that aligns with the problem’s context and goals.For example, consider a dataset for sentiment analysis where you want to classify customer reviews as positive or negative. If you group neutral reviews with positive reviews, the model might not capture the nuances between these two classes, leading to poor performance. A better approach would be to group neutral reviews with negative reviews, as they are more likely to share similar characteristics.
Advanced Topics
One-vs-One SVM
Scikit-learn’s SVC (Support Vector Classifier) employs the One-vs-One (OvO) strategy by default for multiclass problems. This approach involves training a binary classifier for each pair of classes, resulting in a total of n*(n-1)/2 classifiers for n classes. The OvO strategy can be beneficial for datasets with a large number of classes, as it allows for more nuanced classification boundaries. For explicit control over the OvO strategy, you can use sklearn.multiclass.OneVsOneClassifier, which provides a more transparent and customizable approach to multiclass classification.
Here’s an example of how to implement the SVC with OvO strategy for a multiclass classification problem:
from sklearn.svm import SVC
from sklearn.multiclass import OneVsOneClassifier
# Assuming X is the feature set and y is the target variable
# Train a OneVsOneClassifier with SVC as the base estimator
ovo_svm = OneVsOneClassifier(SVC(kernel='linear', C=1))
ovo_svm.fit(X_train, y_train)
# Predict on the test set
y_pred = ovo_svm.predict(X_test)
Label Encoding for Binary Classification
When converting a multiclass dataset to a binary one, it’s essential to ensure that the labels are correctly encoded for binary classification. If your original labels are not 0/1, you’ll need to transform them into a binary format. Scikit-learn’s LabelEncoder is a convenient tool for this task. Here’s an example of how to use LabelEncoder to transform your labels:
from sklearn.preprocessing import LabelEncoder
# Assuming y is your original label array
le = LabelEncoder()
y_binary = le.fit_transform(y)
By applying LabelEncoder, you can transform your labels into a binary format, where each unique label is mapped to a unique integer. This is particularly useful when working with algorithms that require binary labels, such as logistic regression or support vector machines.
FAQs
1. Why would I convert a multiclass dataset to binary?
Converting a multiclass dataset to binary is beneficial in scenarios where you want to apply algorithms that are specifically designed for binary classification problems. This might be the case when working with algorithms that are optimized for binary classification, such as logistic regression or support vector machines (SVMs). Additionally, converting to binary can be useful when you want to focus on a specific class of interest within the multiclass dataset. For example, if you’re working with a dataset that classifies images into different categories (e.g., animals, vehicles, buildings), you might want to convert the dataset to binary to focus on distinguishing between animals and non-animals.
2. What is One-vs-Rest (OvR) classification?
One-vs-Rest (OvR) classification is a strategy used for multiclass classification problems. It involves training a binary classifier for each class in the dataset, where the positive class is the class of interest, and the negative class includes all other classes. This approach results in as many binary classifiers as there are classes in the dataset. For example, if you have a dataset with three classes (A, B, C), the OvR strategy would train three binary classifiers: one for A vs. not A (B and C), one for B vs. not B (A and C), and one for C vs. not C (A and B). The OvR strategy is useful when you want to distinguish each class from all others, but it can be computationally expensive for datasets with a large number of classes.
3. Can I use scikit-learn to convert my dataset?
Yes, scikit-learn provides tools and strategies for converting multiclass datasets to binary. It offers support for both One-vs-Rest (OvR) and One-vs-One (OvO) strategies, which are commonly used for multiclass classification problems. Additionally, scikit-learn includes tools for label encoding, which is necessary for converting multiclass labels to binary labels. The LabelEncoder class in scikit-learn can be used to transform multiclass labels into binary labels, making it easier to work with algorithms that require binary classification.
4. Does converting to binary affect performance?
Converting a multiclass dataset to binary can indeed affect the performance of your model. The conversion process can result in the loss of information and context, particularly if the original multiclass structure is important for the problem you’re trying to solve. For example, if you’re working with a dataset that classifies images into different categories, converting to binary might lose the nuances between the original classes. Therefore, it’s essential to validate your model’s performance after converting the dataset to binary to ensure that the conversion does not negatively impact the model’s ability to generalize.
Conclusion
Converting a multiclass dataset to a binary one is a crucial preprocessing step in machine learning, particularly when working with algorithms designed for binary classification problems. By grasping the nuances of different strategies such as One-vs-Rest (OvR), One-vs-One (OvO), and manual filtering, you can adapt your approach to the specific requirements of your problem. This understanding is essential for avoiding common challenges that might arise from the conversion process, such as information loss or misinterpretation of results. It is vital to validate your results thoroughly and consider the implications of discarding information, ensuring that the conversion does not compromise the integrity of your dataset.
To further enhance your skills in binary classification, we recommend exploring our comprehensive tutorials on:
- Logistic Regression with scikit-learn, a tutorial that provides an in-depth look at implementing logistic regression for binary classification tasks using
scikit-learn. - Adaboost Optimizer, a tutorial that delves into the application of Adaboost as an optimizer for binary classification problems.
- Gradient Boosting for Classification, a detailed tutorial on utilizing gradient boosting for classification tasks, including binary classification scenarios.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
