Technical Writer II

Introduction
Database normalization is an important process in relational database design aimed at organizing data to minimize redundancy, enhance data integrity, and improve database efficiency. Whether you’re a database administrator, developer, or data analyst, understanding normalization is crucial for creating scalable, reliable, and performant databases. Whether you’re aiming to normalize a database from scratch or improve an existing schema, this guide will walk you through every key step.
We will discuss the basics of database normalization and get to know the major normal forms (1NF, 2NF, 3NF and BCNF) in this in-depth guide, provide a set of vivid examples along with transformations, and talk about the cases when it is better to normalize a database and when not.
Key Takeaways
- Database normalization is a step by step approach to structuring data in a way that reduces redundancy and preserves data integrity.
- The process is organized into a series of normal forms 1NF, 2NF, 3NF, and BCNF, each designed to resolve specific types of data anomalies and structural problems.
- Applying normalization helps prevent insertion, update, and deletion anomalies, leading to more consistent and maintainable databases.
- This guide provides clear, step-by-step examples and transformations for each normal form, illustrating how to convert poorly structured tables into optimized ones.
- You’ll also learn about the pros and cons of normalization versus denormalization, so you can make informed decisions about which approach best fits your needs.
- In addition, the guide includes practical SQL tips, answers to common questions, and further resources to help you confidently implement normalization in real-world database projects.
Prerequisites
Before diving into this guide on database normalization, you should have a basic understanding of:
- Relational databases: Familiarity with tables, rows, and columns.
- SQL basics: Knowing how to write simple SELECT, INSERT, and JOIN queries.
- Primary and foreign keys: Understanding how keys are used to uniquely identify records and establish relationships.
- Data types: Awareness of common data types like INT, VARCHAR, and DATE. See our SQL data types overview for a quick refresher.
While this guide explains normalization in detail with examples, having this foundational knowledge will help you follow along more effectively and apply the concepts in real-world scenarios.
What is Database Normalization?
Database normalization is a systematic process used in relational database design to organize data efficiently by dividing large, complex tables into smaller, related tables. The main motive of this is to confirm redundancy of data (duplicate data) is minimal and unwanted attributes such as insertion, update and deletion anomalies are avoided. Normalization does this through a set of rules known as the normal forms each having distinct requirements that narrow down how the database would be designed.
Definition:
Database normalization is the process of structuring a relational database to reduce redundancy and improve data integrity through a set of rules called normal forms.
Understanding how to normalize a database helps eliminate redundancy and improve data clarity, especially in transactional systems.
Different types of databases like relational, document, and key-value handle normalization differently based on their design models; you can learn more about these categories in our guide to types of databases.
Objectives of Database Normalization
- Eliminate Data Redundancy: By breaking data into logical tables and removing duplicate information, normalization helps us make sure that each piece of data is stored only once. This reduces storage requirements and prevents inconsistencies.
- Confirming Data Integrity: Normalization enforces data consistency by establishing clear relationships and dependencies between tables. This maintains accurate and reliable data throughout the database.
- Prevent Anomalies: Proper normalization prevents common data anomalies:
- Insertion Anomaly: Difficulty adding new data due to missing other data.
- Update Anomaly: Inconsistencies that arise when updating data in multiple places.
- Deletion Anomaly: Unintended loss of data due to deletion of other data.
- Optimize Query Performance: Well-structured tables can improve the efficiency of queries, especially for updates and maintenance, by reducing the amount of data processed.
What is the Requirement for Database Normalization?
Database normalization is important for several reasons. It plays a foundational role in confirming that databases are not just collections of tables, but well-structured systems capable of handling growth, change, and complexity over time. By applying normalization, organizations can avoid a wide range of data-related issues while providing consistency and performance across applications, whether in traditional RDBMS or modern workflows like data normalization in Python.
This also applies to statistical and scientific environments. See how it works in practice with our guide to normalizing data in R.
- Consistency and Accuracy: Without normalization, the same data may be stored in multiple places, leading to inconsistencies and errors. Normalization ensures that updates to data are reflected everywhere, maintaining accuracy is one of the primary benefits of database normalization.
- Efficient Data Management: Normalized databases are easier to maintain and modify. Changes to the database structure or data can be made with minimal risk of introducing errors.
- Scalability: As databases grow, normalized structures make it easier to scale and adapt to new requirements without major redesigns.
- Data Integrity Enforcement: By defining clear relationships and constraints, normalization helps enforce business rules and data integrity automatically.
- Reduced Storage Costs: Eliminating redundant data reduces the amount of storage required, which can be significant in large databases.
What are the Features of Database Normalization?
The main features of database normalization include:
- Atomicity: Data is broken down into the smallest meaningful units, ensuring that each field contains only one value (no repeating groups or arrays).
- Logical Table Structure: Data is organized into logical tables based on relationships and dependencies, making the database easier to understand and manage.
- Use of Keys: Primary keys, foreign keys, and candidate keys are used to uniquely identify records and establish relationships between tables.
- Hierarchical Normal Forms: The process follows a hierarchy of normal forms (1NF, 2NF, 3NF, BCNF, etc.), each with stricter requirements to further reduce redundancy and dependency.
- Referential Integrity: Relationships between tables are maintained through foreign key constraints, ensuring that related data remains consistent.
- Flexibility and Extensibility: Normalized databases can be easily extended or modified to accommodate new data types or relationships without major restructuring.
By following the principles of normalization, database designers can create robust, efficient, and reliable databases that support the needs of modern applications and organizations.
Types of Normal Forms in Database Normalization
Before we dive into each normal form, here’s a quick visual summary of how 1NF, 2NF, and 3NF differ:
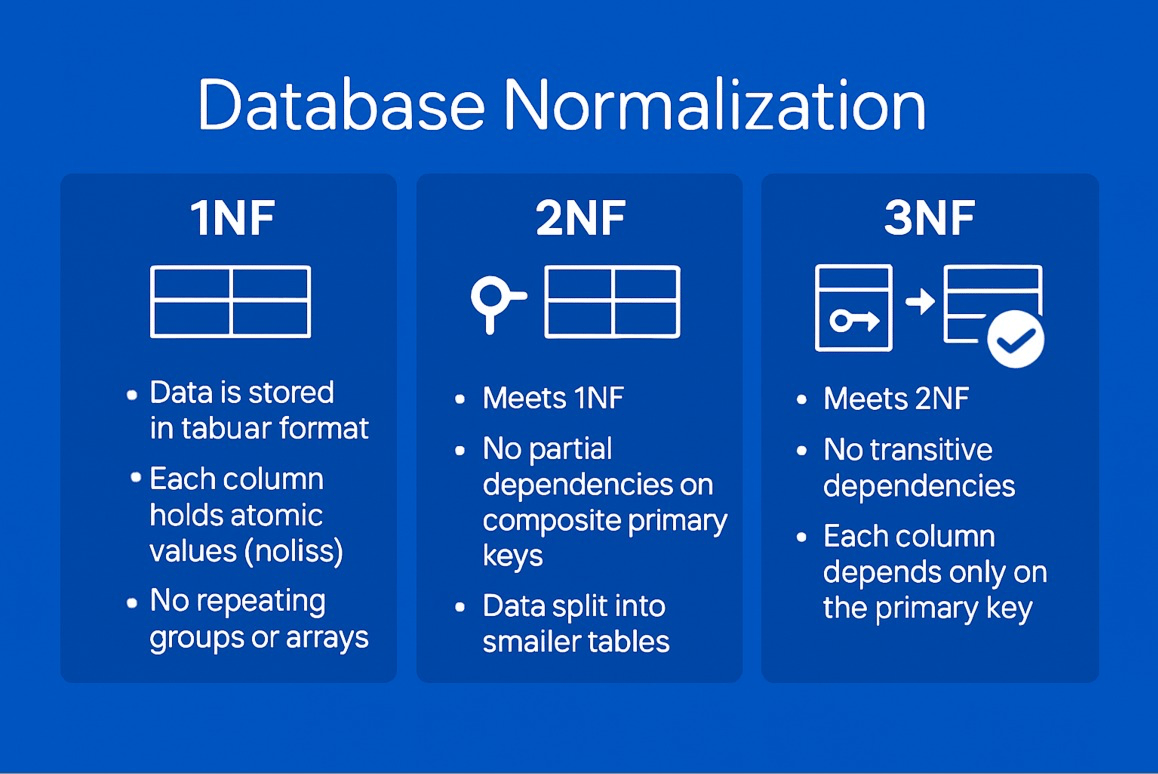
To help you quickly compare the most common normal forms, here’s a summary table outlining their purpose and focus:
| Normal Form | Rule Enforced | Problem Solved | Dependency Focus |
|---|---|---|---|
| 1NF | Atomicity | Repeating/multi-valued data | None |
| 2NF | Full Dependency | Partial dependency | Composite Primary Key |
| 3NF | Transitive | Transitive dependency | Non-key attributes |
| BCNF | Superkey Rule | Remaining anomalies | All determinants |
Database normalization is structured around a series of increasingly strict rules called normal forms. Each normal form addresses specific types of redundancy and dependency issues, guiding you toward a more robust and maintainable relational schema. The most widely applied normal forms are First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), and Boyce-Codd Normal Form (BCNF).
First Normal Form (1NF)
First Normal Form (1NF) is the initial stage in the process of database normalization. It ensures that each column in a table contains only atomic, indivisible values, and that each row is uniquely identifiable. By removing repeating groups and multi-valued attributes, 1NF lays the groundwork for a more organized and consistent database structure. This makes querying, updating, and maintaining data more efficient and reliable, and it helps avoid redundancy right from the beginning of database design.
Key Requirements:
- All columns contain atomic values (no lists, sets, or composite fields).
- Each row is unique (typically enforced by a primary key).
- No repeating groups or arrays within a row.
- Each column contains values of a single data type.
Example: Transforming to 1NF
Suppose you have a table tracking customer purchases, where the “Purchased Products” column contains a comma-separated list of products:
| Customer ID | Customer Name | Purchased Products |
|---|---|---|
| 101 | John Doe | Laptop, Mouse |
| 102 | Jane Smith | Tablet |
| 103 | Alice Brown | Keyboard, Monitor, Pen |
Why is this not in 1NF?
- Non-atomic values: “Purchased Products” contains multiple items per cell.
- Querying and updating are complex: Searching for customers who bought “Mouse” requires string parsing.
- Data integrity risks: No way to enforce referential integrity between products and customers.
- Inconsistent data entry: Different delimiters or typos can creep in.
Real-World Impact:
- Reporting (e.g., “Who bought a Laptop?”) is error-prone.
- Updates (e.g., renaming “Mouse” to “Wireless Mouse”) are tedious and unreliable.
- Referential integrity cannot be enforced.
Real-World Issues:
- Reporting challenges: Generating reports such as “How many customers bought a Laptop?” becomes complicated, as you cannot simply filter a column for “Laptop”, you must parse the string.
- Update anomalies: If a product name changes (e.g., “Mouse” to “Wireless Mouse”), you must update every occurrence in every cell, increasing the risk of missing some entries.
- Data integrity risks: There is no way to enforce referential integrity between products and customers, which can lead to orphaned or inconsistent data.
Summary:
This unnormalized table structure is easy to read for small datasets but quickly becomes unmanageable and unreliable as the amount of data grows. To comply with First Normal Form (1NF), we must ensure that each field contains only a single value, and that the table structure supports efficient querying, updating, and data integrity.
Problems with the Unnormalized Table:
- Non-atomic values: The “Purchased Products” column contains multiple items in a single cell, making it difficult to query or update individual products.
- Data redundancy and inconsistency: If a customer purchases more products, the list grows, increasing the risk of inconsistent data entry (e.g., different delimiters, typos).
- Difficulties in searching and reporting: Queries to find all customers who purchased a specific product become complex and inefficient.
Transformation Steps to Achieve 1NF:
- Identify columns with non-atomic values: In this case, “Purchased Products” contains multiple values.
- Split the multi-valued column into separate rows: Each product purchased by a customer should be represented as a separate row, ensuring that every field contains only a single value.
Transformed Table in 1NF:
| Customer ID | Customer Name | Product |
|---|---|---|
| 101 | John Doe | Laptop |
| 101 | John Doe | Mouse |
| 102 | Jane Smith | Tablet |
| 103 | Alice Brown | Keyboard |
| 103 | Alice Brown | Monitor |
| 103 | Alice Brown | Pen |
Explanation:
- Each row now represents a single product purchased by a customer.
- All columns contain atomic values (no lists or sets).
- The table can be easily queried, updated, and maintained. For example, finding all customers who purchased “Mouse” is now straightforward.
-- Unnormalized structure (not in 1NF)
CREATE TABLE Purchases (
CustomerID INT,
CustomerName VARCHAR(100),
PurchasedProducts VARCHAR(255) -- Comma-separated values
);
-- Normalized 1NF structure
CREATE TABLE CustomerProducts (
CustomerID INT,
CustomerName VARCHAR(100),
Product VARCHAR(100)
);
-- Sample data for CustomerProducts table (1NF)
INSERT INTO CustomerProducts (CustomerID, CustomerName, Product) VALUES
(101, 'John Doe', 'Laptop'),
(101, 'John Doe', 'Mouse'),
(102, 'Jane Smith', 'Tablet'),
(103, 'Alice Brown', 'Keyboard'),
(103, 'Alice Brown', 'Monitor'),
(103, 'Alice Brown', 'Pen');
Key Takeaways:
- 1NF requires that each field in a table contains only one value (atomicity).
- Repeating groups and arrays are eliminated by creating separate rows for each value.
- This transformation lays the foundation for further normalization steps by ensuring a consistent and logical table structure.
Key Benefits:
- Simplifies data retrieval.
- Establishes a baseline structure.
Second Normal Form (2NF)
Definition:
A table is in 2NF if it is in 1NF and every non-prime attribute (i.e., non-primary key attribute) is fully functionally dependent on the entire primary key. This addresses partial dependencies, where a non-key attribute depends only on part of a composite key.
Example Transformation to 2NF
1NF Table:
| Order ID | Customer ID | Customer Name | Product |
|---|---|---|---|
| 201 | 101 | John Doe | Laptop |
| 202 | 101 | John Doe | Mouse |
| 203 | 102 | Jane Smith | Tablet |
Issue:
“Customer Name” depends only on “Customer ID”, not the full primary key (“Order ID”, “Customer ID”). This is a partial dependency.
Normalization to 2NF:
- Separate customer information into its own table.
Orders Table:
| Order ID | Customer ID | Product |
|---|---|---|
| 201 | 101 | Laptop |
| 202 | 101 | Mouse |
| 203 | 102 | Tablet |
Customers Table:
| Customer ID | Customer Name |
|---|---|
| 101 | John Doe |
| 102 | Jane Smith |
Benefits:
- Eliminates redundancy of customer details.
- Simplifies data maintenance and updates.
By moving CustomerName into a separate Customers table, we ensure it’s only dependent on CustomerID and eliminate partial dependency on a composite key.
-- Orders table after 2NF
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
Product VARCHAR(100)
);
-- Customers table after 2NF
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
-- Example foreign key constraint
ALTER TABLE Orders
ADD FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID);
-- Sample data for Customers and Orders (2NF)
INSERT INTO Customers (CustomerID, CustomerName) VALUES
(101, 'John Doe'),
(102, 'Jane Smith');
INSERT INTO Orders (OrderID, CustomerID, Product) VALUES
(201, 101, 'Laptop'),
(202, 101, 'Mouse'),
(203, 102, 'Tablet');
-- Sample data for Products and Suppliers (3NF)
INSERT INTO Suppliers (SupplierID, SupplierName) VALUES
(401, 'HP'),
(402, 'Logitech'),
(403, 'Apple');
INSERT INTO Products (ProductID, ProductName, SupplierID) VALUES
(301, 'Laptop', 401),
(302, 'Mouse', 402),
(303, 'Tablet', 403);
INSERT INTO Orders (OrderID, CustomerID, ProductID) VALUES
(201, 101, 301),
(202, 101, 302),
(203, 102, 303);
Third Normal Form (3NF)
Definition:
A table is in 3NF if it is in 2NF and all the attributes are functionally dependent only on the primary key, there are no transitive dependencies (i.e., non-key attributes depending on other non-key attributes).
Example Transformation to 3NF
2NF Table:
| Order ID | Customer ID | Product | Supplier |
|---|---|---|---|
| 201 | 101 | Laptop | HP |
| 202 | 101 | Mouse | Logitech |
| 203 | 102 | Tablet | Apple |
Issue:
“Supplier” depends on “Product”, not directly on the primary key.
Normalization to 3NF:
- Move product and supplier information to separate tables.
Orders Table:
| Order ID | Customer ID | Product ID |
|---|---|---|
| 201 | 101 | 301 |
| 202 | 101 | 302 |
| 203 | 102 | 303 |
Products Table:
| Product ID | Product Name | Supplier ID |
|---|---|---|
| 301 | Laptop | 401 |
| 302 | Mouse | 402 |
| 303 | Tablet | 403 |
Suppliers Table:
| Supplier ID | Supplier Name |
|---|---|
| 401 | HP |
| 402 | Logitech |
| 403 | Apple |
Benefits:
- Removes transitive dependencies.
- Reduces data duplication.
- Improves data integrity and maintainability.
Visualizing the 2NF to 3NF Transformation
To further clarify the 2NF to 3NF normalization process and illustrate the elimination of transitive dependencies, refer to the schema diagram below:
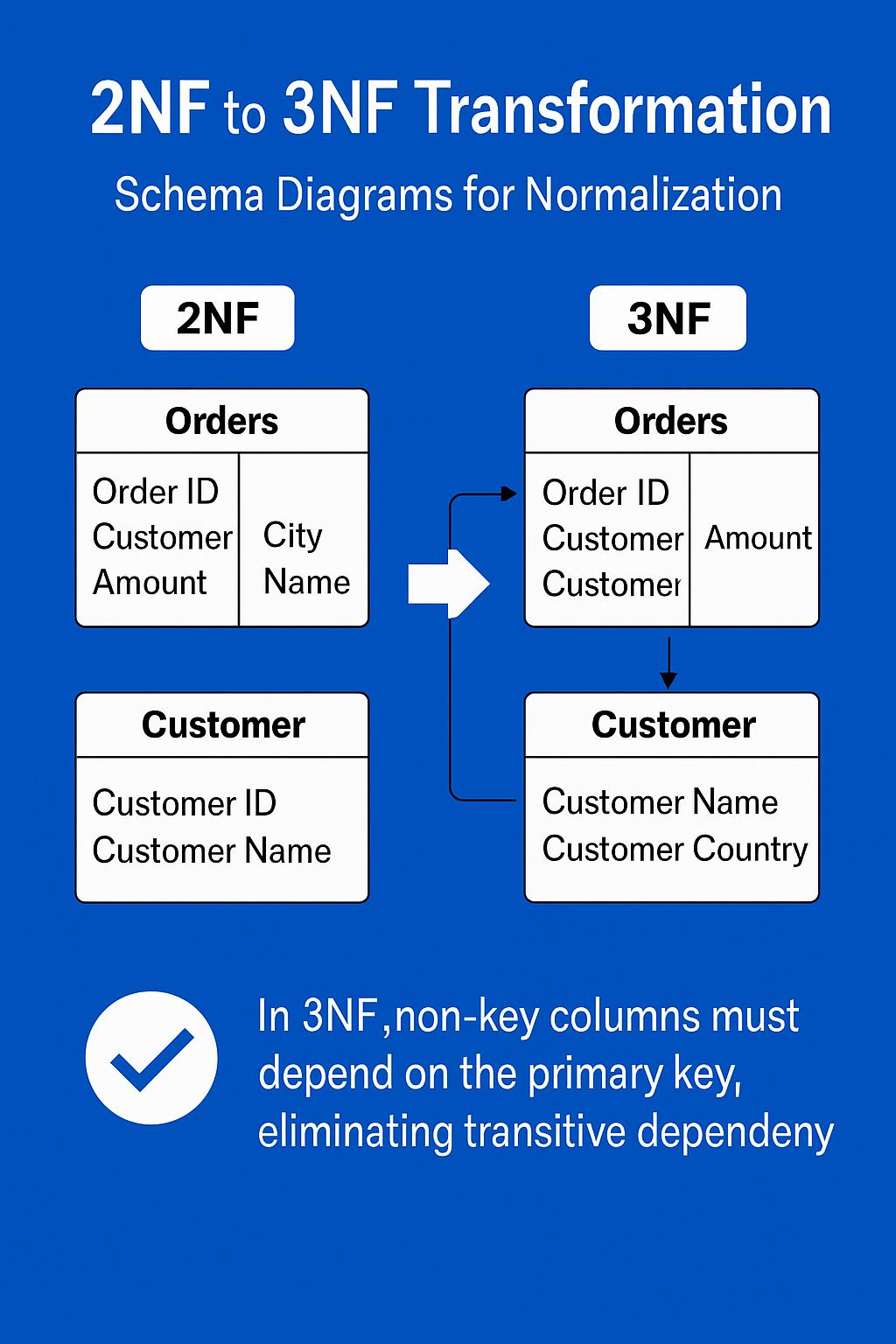
This transformation improves maintainability and aligns with best practices for how to normalize a database effectively.
Since Supplier depends on Product and not directly on the primary key (OrderID), we isolate it into a new Suppliers table and reference it via the Products table. This removes transitive dependencies and aligns with 3NF rules.
Boyce-Codd Normal Form (BCNF)
Definition:
BCNF is a stricter version of 3NF. A table is in BCNF if, for every non-trivial functional dependency X → Y, X is a superkey. In other words, every determinant must be a candidate key.
When is BCNF Needed?
BCNF addresses certain edge cases where 3NF does not eliminate all redundancy, particularly when there are overlapping candidate keys or complex dependencies.
Example Transformation to BCNF
Let’s walk through a detailed example of how to transform a table that is in Third Normal Form (3NF) but not in Boyce-Codd Normal Form (BCNF).
Scenario:
Suppose we have a university database that tracks which students are enrolled in which courses, and who teaches each course. The initial table structure is as follows:
Original Table:
| StudentID | Course | Instructor |
|---|---|---|
| 1 | Math | Dr. Smith |
| 2 | Math | Dr. Smith |
| 3 | History | Dr. Jones |
| 4 | History | Dr. Jones |
Explanation of Columns:
- StudentID: Unique identifier for each student.
- Course: The course in which the student is enrolled.
- Instructor: The instructor teaching the course.
Functional Dependencies in the Table:
- (StudentID, Course) → Instructor
Each unique combination of student and course determines the instructor for that course. - Course → Instructor
Each course is always taught by the same instructor.
Candidate Keys:
- The only candidate key in this table is the composite key (StudentID, Course), since both are needed to uniquely identify a row.
Why is this Table in 3NF?
- All non-prime attributes (Instructor) are fully functionally dependent on the candidate key (StudentID, Course).
- There are no transitive dependencies (i.e., no non-prime attribute depends on another non-prime attribute through the candidate key).
Why is this Table Not in BCNF?
- The functional dependency Course → Instructor exists, but “Course” is not a superkey (it does not uniquely identify a row in the table).
- BCNF requires that for every non-trivial functional dependency X → Y, X must be a superkey. Here, “Course” is not a superkey, so this violates BCNF.
How to Normalize to BCNF:
To resolve the BCNF violation, we need to decompose the table so that every determinant is a candidate key in its respective table. This is done by splitting the original table into two separate tables:
-
StudentCourses Table:
This table records which students are enrolled in which courses.StudentID Course 1 Math 2 Math 3 History 4 History - Primary Key: (StudentID, Course)
- This table no longer contains the Instructor column, so there are no functional dependencies that violate BCNF.
-
CourseInstructors Table:
This table records which instructor teaches each course.Course Instructor Math Dr. Smith History Dr. Jones - Primary Key: Course
- The dependency Course → Instructor is now valid, as “Course” is the primary key (and thus a superkey) in this table.
Resulting Structure and Benefits:
- All functional dependencies in both tables have determinants that are candidate keys, so both tables are in BCNF.
- Data redundancy is reduced: the instructor for each course is stored only once, rather than repeated for every student enrolled in the course.
- Updates are easier and less error-prone: if an instructor changes for a course, you only need to update one row in the CourseInstructors table.
Summary Table of the Decomposition:
| Table Name | Columns | Primary Key | Purpose |
|---|---|---|---|
| StudentCourses | StudentID, Course | (StudentID, Course) | Tracks which students are in which courses |
| CourseInstructors | Course, Instructor | Course | Tracks which instructor teaches each course |
-- Original table (not in BCNF)
CREATE TABLE StudentCoursesWithInstructor (
StudentID INT,
Course VARCHAR(100),
Instructor VARCHAR(100)
);
-- Normalized BCNF tables
-- Table tracking which students are in which courses
CREATE TABLE StudentCourses (
StudentID INT,
Course VARCHAR(100),
PRIMARY KEY (StudentID, Course)
);
-- Table mapping each course to an instructor
CREATE TABLE CourseInstructors (
Course VARCHAR(100) PRIMARY KEY,
Instructor VARCHAR(100)
);
-- Sample data for BCNF decomposition
INSERT INTO StudentCourses (StudentID, Course) VALUES
(1, 'Math'),
(2, 'Math'),
(3, 'History'),
(4, 'History');
INSERT INTO CourseInstructors (Course, Instructor) VALUES
('Math', 'Dr. Smith'),
('History', 'Dr. Jones');
By decomposing the original table in this way, we have eliminated the BCNF violation and created a more robust, maintainable database structure.
Summary:
Applying these normal forms in sequence helps you design databases that are efficient, consistent, and scalable. For most practical applications, achieving 3NF (or BCNF in special cases) is sufficient to avoid the majority of data anomalies and redundancy issues.
Normalization vs. Denormalization: Pros & Cons
Understanding the trade-offs between normalization and denormalization is crucial for designing databases that are both performant and maintainable. The tables below summarize the key advantages and disadvantages of each approach.
Comparing Advantages of Normalization and Denormalization
| Aspect | Normalization | Denormalization |
|---|---|---|
| Data Integrity | Ensures consistency by reducing redundancy and enforcing relationships | May compromise integrity due to data duplication |
| Efficient Updates | Easier to maintain and update individual data points | Requires updating in multiple places, increasing maintenance burden |
| Clear Relationships | Clarifies data structure through foreign keys and normalization rules | Can obscure logical data relationships due to flattened design |
| Storage Optimization | Reduces storage by eliminating duplicate data | Consumes more space due to repeated data |
| Scalability | Easier to evolve schema without risking inconsistency | Risk of inconsistency increases as system scales |
Comparing Disadvantages of Normalization and Denormalization
| Aspect | Normalization | Denormalization |
|---|---|---|
| Query Complexity | Requires joins across multiple tables, increasing query complexity | Simpler queries due to flat structure |
| Performance Overhead | Slower reads in complex queries due to multiple joins | Faster read performance with reduced need for joins |
| Development Time | Requires thoughtful schema design and maintenance | Quicker setup for specific reporting or analytic needs |
| Flexibility for BI/Analytics | Less suited for ad-hoc reporting; requires views or intermediate layers | Better aligned with analytics use cases due to consolidated data |
| Risk of Anomalies | Minimal if properly normalized | Higher chance of anomalies from data duplication and inconsistency |
Normalization vs Denormalization: What’s Best for Performance?
When designing a database, it’s important to balance data integrity with system performance. Normalization improves consistency and reduces redundancy, but can introduce complexity and slow down queries due to the need for joins. Denormalization, on the other hand, can speed up data retrieval and simplify reporting, but increases the risk of data anomalies and requires more storage. Understanding these trade-offs helps you choose the right approach for your application’s specific needs and workload patterns.
Join Performance vs. Flat Tables
Normalized databases store related data in separate tables, which means retrieving information often requires joining these tables together. This structure assists in ensuring the constancy and integrity of data but may slacken the speed of querying particularly in case of intricate queries or data sets of significant sizes. Denormalized databases on the other hand contain related data in the same table and hence, require fewer joins. This can speed up the read operations, but this would multiply the storage needs and the possibility of duplicating or non-consistent data.
Summary of Trade-offs:
- Normalized Models: Provide strong data integrity and make updates easier, but can result in slower queries that require many joins.
- Denormalized Models: Offer faster reads and simpler reporting, but are more susceptible to data duplication and update anomalies.
When Should we Consider Denormalization?
Normalization is generally best during the initial design of a database. However, denormalization can be helpful in situations where performance is critical or the workload is heavily focused on reading data. Common scenarios where denormalization is advantageous include:
- Analytics and business intelligence (BI) platforms that need to quickly aggregate data across wide tables.
- Content delivery systems that use denormalized cache layers to speed up response times.
- Data warehouses where historical data snapshots and simplified queries are more important than frequent updates.
Before denormalizing, always weigh the potential performance improvements against the increased risk of data duplication and the added complexity of maintaining consistency.
The Role of Normalization in AI, Big Data, and NoSQL
With the rise of AI, real-time analytics, and distributed systems, the approach to normalization is changing. While traditional relational databases (RDBMS) still benefit from strict normalization, modern data systems often use a mix of normalized and denormalized structures:
- Big Data platforms (like Hadoop and Spark) typically use denormalized, wide-column formats to improve performance and enable parallel processing.
- NoSQL databases (such as MongoDB and Cassandra) focus on flexible schemas and high performance, often avoiding strict normalization.
- AI and machine learning pipelines prefer denormalized datasets to reduce pre-processing and speed up model training.
For hands-on examples of this transformation, see our guide on how to normalize data in Python.
R users working with data frames and statistical models can also benefit from proper normalization techniques, explore more in our tutorial on how to normalize data in R.
Even as these new technologies emerge, understanding normalization remains important, especially when building core relational systems or preparing data for downstream processes. Many modern architectures use normalized databases for core storage, then create denormalized layers or views to optimize performance for specific use cases.
Practical Tips for Normalizing Databases in SQL
Normalization in SQL involves practical steps:
-- Example: Creating separate tables for normalization
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
Product VARCHAR(100),
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
When designing your tables, it’s also important to choose appropriate data types for each column, refer to our SQL data types tutorial to ensure you’re using the right types for performance and storage efficiency.
FAQs
Q: What is 1NF, 2NF, and 3NF in database normalization?
A: These are the first three stages of database normalization. 1NF removes repeating groups and ensures atomicity. 2NF builds on this by eliminating partial dependencies, meaning every non-key attribute must depend on the entire primary key. 3NF removes transitive dependencies, ensuring non-key attributes only depend on primary keys. Each stage progressively refines the data model, reducing redundancy and improving data consistency. Understanding these forms is crucial for creating scalable, maintainable relational database schemas.
Q: What is normalization in a database, and why is it important?
A: Normalization is a database design technique that structures data to reduce duplication and improve data integrity. By organizing data into related tables and applying rules (normal forms), it prevents anomalies during data insertion, updates, and deletions. Normalization also makes querying more efficient and ensures logical data grouping. It’s especially important in relational databases where accuracy and consistency are critical. For systems handling large volumes of transactions or frequent updates, normalization is foundational for performance and reliability.
Q: What are the rules of database normalization?
A: Normalization follows a hierarchy of normal forms 1NF, 2NF, 3NF, and BCNF each with stricter rules. 1NF requires atomic values and unique rows. 2NF requires full functional dependency on the primary key. 3NF eliminates transitive dependencies. BCNF ensures that every determinant is a candidate key. These rules aim to eliminate redundancy, ensure data integrity, and optimize storage. Proper application of these rules results in more reliable, maintainable, and scalable database schemas.
Q: How do you normalize a database using SQL?
A: Normalizing a database in SQL involves decomposing large tables into smaller ones and establishing foreign key relationships. For example, to convert a table with customer and order data into 2NF, you’d separate customer details into one table and orders into another, linking them with a foreign key. Use SQL CREATE TABLE, INSERT, and FOREIGN KEY constraints to maintain referential integrity. Normalization typically involves restructuring existing data with careful planning to avoid loss or inconsistency during transformation.
Q: What are the benefits and drawbacks of normalization?
A: Advantages of normalization are less data redundancy, data integrity, and easy updates. It makes sure that modification done at a certain point is reproduced in other connected documents in an appropriate way. Its disadvantages however, are that it has an overhead performance with regards to joins and that it is very complex to write queries especially in highly normalized databases. Denormalization can be more preferable in high-read situations such as analytics dashboards. The rationale to normalize should, therefore, follow the needs of use cases, performance requirements, and maintenance.
Q: What is the difference between normalization and denormalization?
A: Normalization breaks down data into smaller, related tables to reduce redundancy and improve consistency. Denormalization, on the other hand, combines related data into fewer tables to speed up read operations and simplify queries. While normalization improves data integrity and is ideal for transaction-heavy systems, denormalization is often used in read-heavy systems like reporting tools. The choice depends on the trade-off between write efficiency and read performance.
Q: When should I denormalize a database instead of normalizing it?
A: Denormalization is suitable when read performance is critical and the data doesn’t change frequently. Use it in analytics, reporting, or caching layers where real-time joins would impact speed. Also, in NoSQL or big data environments, denormalization aligns with the storage and access patterns. However, it should be approached cautiously since it increases data duplication and the risk of inconsistency. In many systems, a hybrid model using both normalized core tables and denormalized views or summaries works best.
Q: Is normalization still relevant for modern databases and AI applications?
A: Yes, normalization remains essential, especially for transactional systems and data integrity-focused applications. In AI and big data contexts, normalized structures are often used as the source of truth before being transformed into denormalized datasets for training or analysis. Even in NoSQL and distributed systems, understanding normalization helps in modeling relationships and verifying consistency at the design level. While modern workloads may relax strict normalization, its principles are foundational for long-term data quality and manageability.
Summary
Knowing how to normalize a database also makes it possible to make effective, scalable systems with minimal duplication and long-term stability. In terms of normalization forms, 1NF, 2NF, 3NF, BCNF Determining the correct form of normalization, by diminishing multiple versions of the data, you will avoid redundancy and uphold integrity of the data and thus enhance the performance of the system. Assess your database requirements and strike the balance between normalization and denormalization depending on the use-case details.
Additional Resources on Database Normalization
For more insights and practical guides related to database normalization and data management, check out these resources:
- How to Normalize Data in Python: Practical examples of normalization techniques using Python.
- How to Normalize Data in R: Step-by-step instructions for data normalization in statistical analyses with R.
- Types of Databases Explained: Understand different database models and how normalization fits into each.
- SQL Data Types Overview: Comprehensive coverage of SQL data types, crucial for effective database design.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Building future-ready infrastructure with Linux, Cloud, and DevOps. Full Stack Developer & System Administrator. Technical Writer @ DigitalOcean | GitHub Contributor | Passionate about Docker, PostgreSQL, and Open Source | Exploring NLP & AI-TensorFlow | Nailed over 50+ deployments across production environments.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
