
Introduction
Coding models have made tremendous progress this year. GLM-4.5, Kimi-K2, and Qwen-3 Coder have all been standout releases. We covered the original Devstral earlier this year and weren’t expecting another iteration from Mistral so soon.
Devstral 2
Devstral 2 is Mistral’s new family of coding and agentic LLMs designed for software engineering, available in 24B and 123B parameter sizes. The 123B model achieves state-of-the-art performance on SWE-bench and excels in coding, tool-calling, and agentic use cases. The 24B model fits comfortably in 25GB of RAM/VRAM, while the 123B requires 128GB.
Architecture-wise, Mistral’s decision to stick with a dense architecture for the 123B model instead of a Mixture of Experts (MoE) is quite interesting. We’re curious about what went into the model’s impressive performance-to-efficiency ratios. The model scores 72.2% on SWE-bench Verified and supports a 256K context window!!
While the 123B variant can’t run on consumer hardware, the 24B variant can. Devstral Small 2 scores 68.0% on SWE-bench Verified.
In this article, we’ll be taking Devstral 2 for a spin.
Note that the 123B parameter has a modified MIT licence and that the 23B parameter version has a Apache 2.0 licence.
Prerequisites
Before you begin this tutorial, you’ll need:
- A DigitalOcean account with access to GPU Droplets
- Basic familiarity with Linux command line
Running Devstral 2 on DigitalOcean
Devstral 2 is tailored for datacenter-grade GPUs and needs at least 4 H100-class GPUs to run.
Devstral Small 2 is designed to function on a single GPU and is compatible with various NVIDIA hardware, such as DGX Spark and GeForce RTX systems. Support for NVIDIA NIM is coming in the near future. Devstral Small can operate on consumer-level GPUs and also works on CPU-only setups without needing a dedicated graphics card.
Begin by setting up a DigitalOcean GPU Droplet.
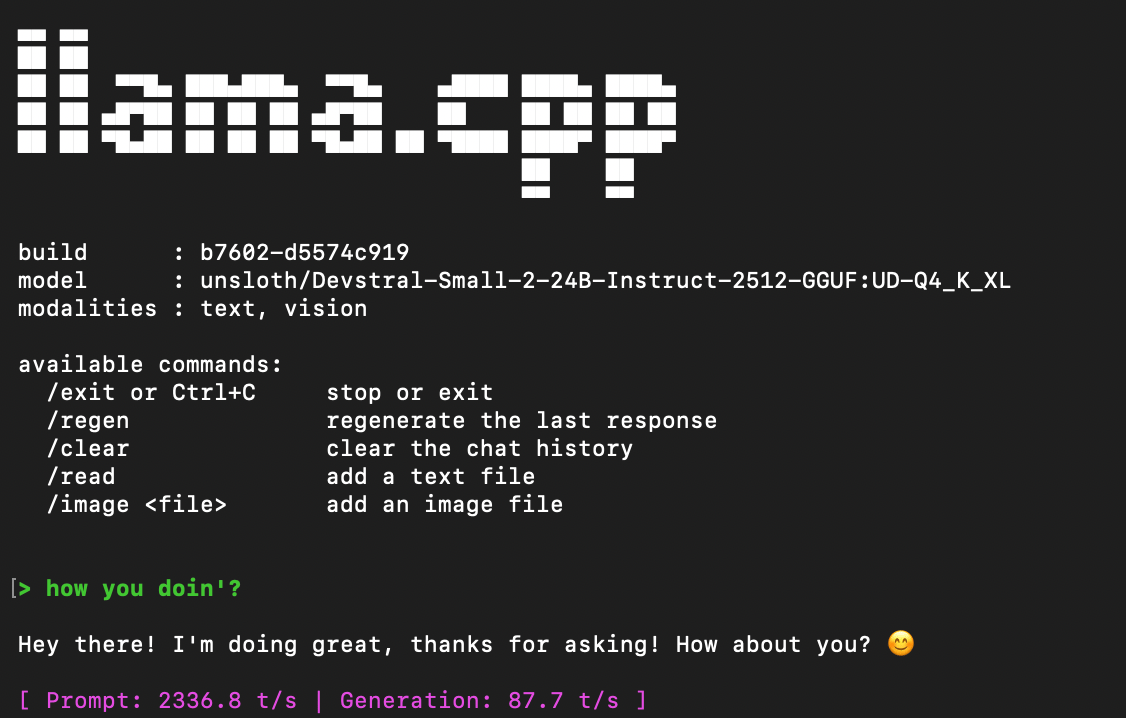
We will be running the unsloth implementation. Shoutout unsloth.
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-mtmd-cli llama-server llama-gguf-split
cp llama.cpp/build/bin/llama-* llama.cpp
./llama.cpp/llama-cli \
-hf unsloth/Devstral-2-123B-Instruct-2512-GGUF:UD-Q2_K_XL \
--jinja -ngl 99 --threads -1 --ctx-size 16384 \
--temp 0.15\
./llama.cpp/llama-cli \
--model unsloth/Devstral-2-123B-Instruct-2512-GGUF/Devstral-2-123B-Instruct-2512-UD-Q2_K_XL.gguf \
--mmproj unsloth/Devstral-2-123B-Instruct-2512-GGUF/mmproj-F16.gguf \
--threads -1 \
--ctx-size 16384 \
--n-gpu-layers 99 \
--seed 3407 \
--prio 2 \
--temp 0.15 \
--jinja
Final Thoughts
These models can integrate with workflows, working with IDEs, CI/CD, and issue trackers to influence software development. Give it a go and let us know:)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
