
Introduction
Z.ai (formerly Zhipu AI) released GLM-4.5 (355B total parameters, 32B activated) and GLM-4.5-Air (106B parameters, 32B activated) with the goal of unifying reasoning, coding, and agentic capabilities into a single model.
There are two modes one can use the model in: thinking mode for responses that require complex reasoning and tool use, and non-thinking mode for quick responses. The model is available on Z.ai; Z.ai API and open-weights are available on both HuggingFace and ModelScope.
This article is part of a series where we are covering open-source agentic, coding, and/or reasoning models such as gpt-oss, Kimi K2, and Qwen3-Coder.
Key Takeaways
- GLM-4.5 Models: Z.ai released GLM-4.5 (355B total parameters, 32B activated) and GLM-4.5-Air (106B parameters, 32B activated) to unify reasoning, coding, and agentic capabilities.
- Performance: GLM-4.5 shows strong benchmark performance, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. It ranked third overall and second on agentic benchmarks despite having fewer parameters than many similar models.
- Architecture: GLM-4.5 utilizes a Mixture of Experts (MoE) architecture with sigmoid gates, Grouped-Query Attention (GQA) with partial RoPE, QK-norm, and MoE layers as MTP layers to support speculative decoding.
- Training Process: The model was trained in a multi-step process:
- Pre-training: On a 23T token dataset curated from diverse sources, with emphasis on high-quality data through techniques like SemDeDup and quality-tiered up-sampling.
- Mid-training: Progressively extending sequence length up to 128K for repo-level code, synthetic reasoning data, and long-context/agent training.
- Post-training: Divided into “Expert Training” (creating specialists) and “Unified Training” (integrating experts with self-distillation).
- RL Infrastructure (Slime): Slime is an open-source SGLang-native post-training framework that supports flexible hybrid training architecture (“colocated, synchronous mode” for reasoning tasks and “disaggregated, asynchronous mode” for agentic tasks).
- Specialized RL Techniques:
- Reasoning RL: Used a two-stage difficulty-based curriculum and found single-stage RL at max output length effective.
- Agentic RL: Focused on web-search and code-generation agents with iterative self-distillation.
- General RL: Combined rule-based, human (RLHF), and model-based (RLAIF) feedback for overall performance improvement.
- Hardware Requirements: Running GLM-4.5 and GLM-4.5-Air requires specific GPU configurations on DigitalOcean GPU Droplets, varying by model version, precision (BF16 or FP8), and desired context length. For example, GLM-4.5-Air with FP8 precision can run on a single H100 GPU droplet for standard configurations.
Benchmark performance
This model performs quite well on benchmarks as indicated from the figure Z.ai presented in their GLM-4.5 blog post. The model scored 70.1% on the TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. Despite having far fewer parameters than many similar models, GLM-4.5 ranked third overall and second specifically on agentic benchmarks among all models the researchers evaluated against.
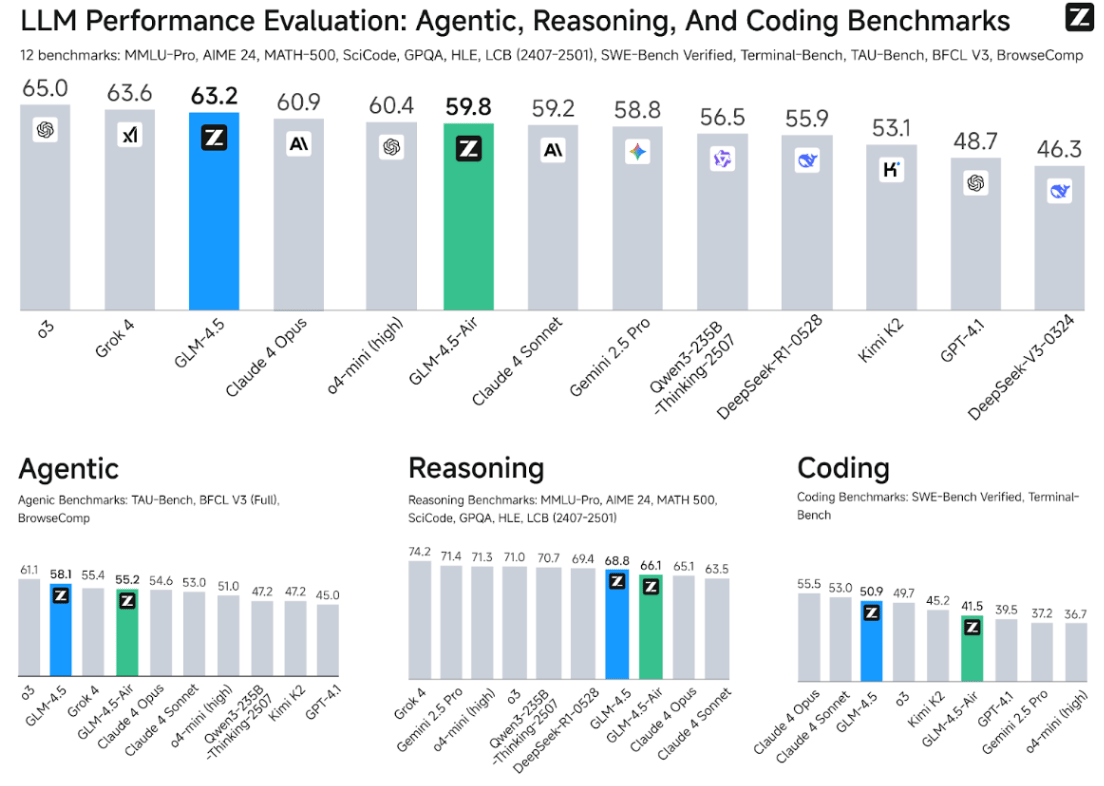
We encourage you to read this article alongside the GLM-4.5 tech report. In this article, we are going to pay particular attention to the architecture used in GLM-4.5, hyperparameters used in pre-training, and its Reinforcement Learning infrastructure.
Model Architecture
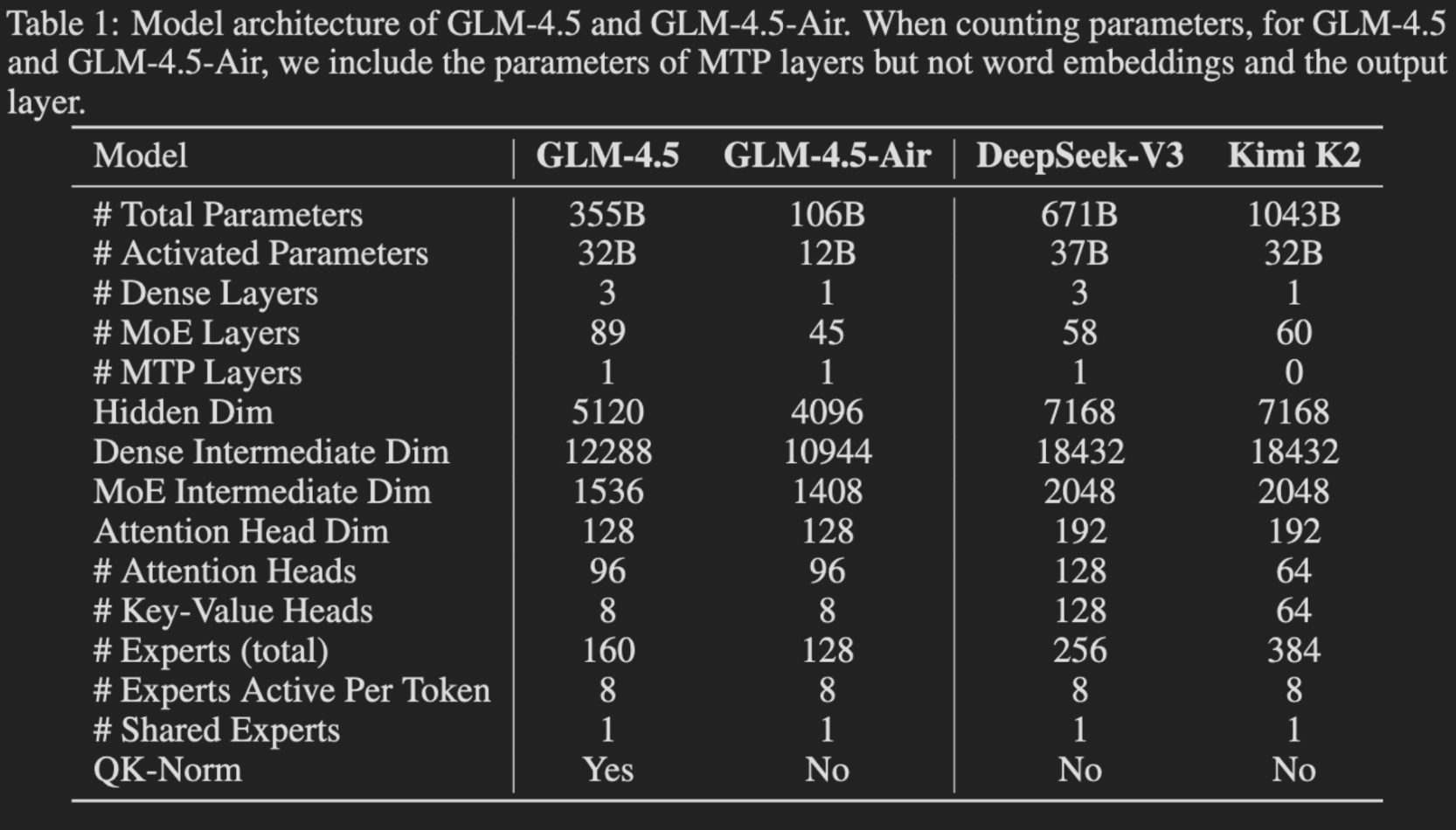
The table below caught our eye since Kimi K2 included a similar table in the K2 tech report comparing K2 and DeepSeek-V3 (Table 2).
| Spec | Relevance |
|---|---|
| Mixture of Experts (MoE) architecture | The Mixture of Experts (MoE) architecture uses sparse Feedforward Neural Network (FFN) layers (experts) and a gate network (router) to selectively route tokens to top-k experts, activating only a subset of parameters per token The use of MoE over a dense architecture improves computational efficiency of training and inference since only relevant experts are routed to for each input. |
| MoE Routers with sigmoid gates | Sigmoid gates are used for MoE Routers just like in DeepSeek-V3.They are believed to be more sample efficient than say softmax gates. |
| Grouped-Query Attention (GQA) with partial RoPE and 2.5 times more attention heads | This combination consistently improved performance on reasoning benchmarks. |
| QK-norm | QK-norm was used to stabilize the range of attention logits. Unlike Kimi-K2 which used Multihead Latent Attention and therefore could not use QK-norm, GLM-4.5 utilizes GQA. |
| MoE layer as the MTP layer | Supports speculative decoding during inference |
GLM-4.5 was trained in a multistep process, starting with pre-training on a massive 23T token dataset and followed by several mid-training stages to enhance performance on specific tasks (e.g., repo-level coding, synthetic reasoning, agentic workflows requiring long-context)
Pretraining
The pre-training corpus was curated from webpages, books, papers, social media, and code repositories. High-quality data was prioritized through several techniques:
Web data was sorted into quality buckets, with higher-quality documents being up-sampled. A process called SemDeDup was used to remove webpages that were semantically similar, which MinHash deduplication couldn’t catch.
Code data was classified into three quality tiers, with high-quality code being up-sampled and low-quality code excluded.
Math & Science data was enhanced by using an LLM to score and up-sample documents with high educational value.
The pre-training itself was split into two stages: the first focused on general documents, while the second up-sampled data related to coding, math, and science.
Hyperparameters
The researchers used the muon optimizer which they found accelerated convergence. Additionally, the adoption of a cosine decay schedule for the learning rate, in direct contrast to the popular warmup-stable-decay (WSD) schedule, was quite interesting.
Midtraining
After pre-training, the model underwent several mid-training stages to enhance its reasoning and agentic skills, progressively extending the sequence length from 4K up to 128K.
Repo-Level Code Training: The sequence length was extended to 32K to train the model on concatenated code files from the same repository, helping it learn cross-file dependencies.
Synthetic Reasoning Data Training: Synthetic reasoning data for math, science, and coding competitions were added at this stage.
Long-Context & Agent Training: The sequence length was pushed to 128K, and the model was trained on long documents and large-scale synthetic agent trajectories.
Post-Training
The post-training process was designed to refine the model’s abilities in two main stages: Expert Training (creating specialists in Reasoning, Agent, and General chat) and Unified Training (integrating these experts into one comprehensive model with self-distillation).
Supervised Fine-Tuning (SFT)
SFT was used to give the expert models a “cold start” with basic chat and reasoning skills. In the unified training stage, SFT served to distill the capabilities from the different expert models into the final hybrid reasoning model.
RL infrastructure
Slime is an open-source SGLang-native post-training framework designed to scale RL models with flexibility and efficiency. A key architectural feature is its support for a flexible hybrid training architecture, which can operate in either a “colocated, synchronous mode” or a “disaggregated, asynchronous mode”. The choice of mode is directly tied to the nature of the task. Synchronous modes were shown to be more effective for reasoning tasks like math and code generation, where the training and inference engines reside on the same worker, maximizing GPU utilization. The researchers explain that asynchronous modes were better for agentic tasks, where data generation can be slow. This disaggregated model decouples the training and rollout processes, allowing agent environments to continuously generate data without being stalled by the training cycle.
The team developed a suite of specialized RL techniques to effectively train the models.
Reasoning RL: To avoid getting stuck with reward signals that were all 0s or 1s, the team used a two-stage difficulty-based curriculum, moving from moderate to extremely difficult problems as the model improved. They also found that a single-stage RL process at the maximum 64K output length was more effective than progressively increasing the length, as shorter stages could cause the model to “unlearn” its long-context abilities.
Agentic RL: This focused on web-search and code-generation agents where actions could be automatically verified, providing dense and reliable reward signals. The training involved an iterative self-distillation approach, where an RL-trained model was used to generate better data for a new SFT model, which was then further trained with RL.
General RL: To improve overall performance, a multi-source feedback system combined rule-based feedback, human feedback (RLHF), and model-based feedback (RLAIF). This included targeted training to improve instruction following and fix pathological behaviors like repetition or formatting mistakes.
Using GLM-4.5
DigitalOcean has a variety of GPU Droplets available for you to run inference with GLM-4.5 and GLM-4.5-Air. The models require specific GPU configurations depending on the version and desired precision. For instance, running the GLM-4.5 model with BF16 precision requires 16 H100 and 8 H200 GPUs. In contrast, the GLM-4.5-Air model with FP8 precision can run on a single H100 GPU droplet.
Hardware Requirements
The GLM-4.5 models can run under various GPU configurations, as detailed below. All configurations use the sglang test framework.
Standard Configurations
- GLM-4.5 (BF16): Requires 16 H100 and 8 H200 GPUs.
- GLM-4.5 (FP8): Requires 8 H100 and 4 H200 GPUs.
- GLM-4.5-Air (BF16): Requires 4 H100 and 2 H200 GPUs.
- GLM-4.5-Air (FP8): Requires 2 H100 and 1 H200 GPUs.
Full Context Length (128K) Configurations
To use the full 128K context length, more powerful configurations are needed.
- GLM-4.5 (BF16): Requires 32 H100 and 16 H200 GPUs.
- GLM-4.5 (FP8): Requires 16 H100 and 8 H200 GPUs.
- GLM-4.5-Air (BF16): Requires 8 H100 and 4 H200 GPUs.
- GLM-4.5-Air (FP8): Requires 4 H100 and 2 H200 GPUs.
For additional implementation details, feel free to consult the GLM-4.5 repo.
Final Thoughts
Through a deep mixture-of-experts architecture and a carefully optimized multi-stage training pipeline, the team at Z.ai has created a model that excels in agentic behaviour, reasoning, and coding. GLM-4.5’s performance rivals that of both open and closed leaders in the space, and the release of model weights and their RL infrastructure, slime, accelerates progress for the entire field. This is another clear example of how open research can push the boundaries of what’s possible in AI!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
