
Introduction
There’s been a slew of Qwen releases recently. Among them is Qwen 3 Coder, an agentic Mixture of Experts (MoE) model with 405B parameters and 35B active parameters, designed for high-performance coding assistance and multi-turn tool use. The brief window (not even two weeks) between Kimi-K2 and Qwen3-Coder’s debut demonstrates how aggressively teams are pushing specialized open-weight agentic coding models into the hands of developers. What makes this particular model stand out is its lower total parameter count (than say Kimi K2’s 1 trillion parameters) and impressive benchmark performance.
Qwen3 was released in May of this year, and in the conclusion of its technical report, they say “we will work on improving model architecture and training methods for the purposes of effective compression, scaling to extremely long contexts, etc. In addition, we plan to increase computational resources for reinforcement learning, with a particular emphasis on agent-based RL systems that learn from environmental feedback.”
Released in July, the updated Qwen3 model involves pretraining and reinforcement learning (RL) phases with a modified version of Group Relative Policy Optimization (GRPO) called Group Sequence Policy Optimization (GSPO) and a scalable system built to run 20 000 independent environments in parallel. We’re very excited (for the release of an updated technical report?) to learn more about the specifics.
Key Takeaways
- 405B parameter Mixture of Experts model with 35B active parameters
- 160 experts with 8 active per token
- 256K token context length extendable to 1M with YaRN
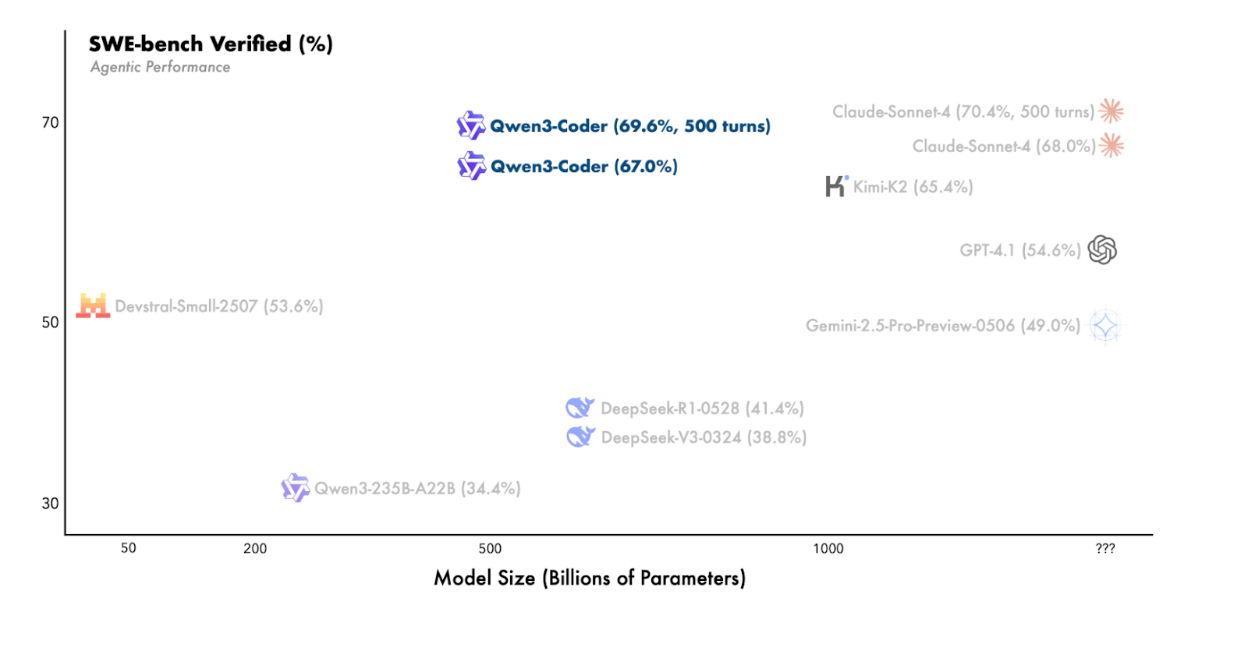
- High SWE-bench verified score on long horizon tasks (69.6 with 500 turns vs Claude-Sonnet-4 at 70.4% with 500 turns)
- Trained with Group Sequence Policy Optimization
- Smaller 30B A3B Instruct variant runs on a single H100 GPU
- Qwen Code CLI open-sourced as a fork of Gemini CLI
Here’s a high level overview to get you up to speed with Qwen3-Coder’s internals.
Model Overview
| Spec | Relevance |
|---|---|
| Mixture of Experts (MoE) | The Mixture of Experts (MoE) architecture allows for greater model size and quality while reducing compute costs. It employs sparse Feedforward Neural Network (FFN) layers, known as experts, along with a gating mechanism to route tokens to the top-k experts, thereby activating only a subset of the parameters for each token. |
| 405B parameters, 35B active parameters | As Qwen3-Coder has a MoE architecture, there are total and active parameters. “Total parameters” encompasses the cumulative count of all parameters within the model, including all expert networks, the router or gating network, and shared components, irrespective of which experts are engaged during the inference process. This is distinct from “active parameters,” which refers to the subset of parameters employed for a particular input, generally comprising the activated experts along with shared components. |
| Number of Experts =160, Number of Activated Experts = 8 | This is very interesting because (click link). |
| Context length = 256K tokens natively, 1M with YaRN | YaRN (Yet another RoPE extensioN method), is a compute-efficient method to extend the context window of transformer-based language models. Its use in Qwen3-Coder extends its context length to a million. |
| GSPO (Group Sequence Policy Optimization) | In Qwen’s recent paper, they introduce GSPO with results indicative of superior training efficiency and performance compared to GRPO (Group Relative Policy Optimization). GSPO stabilizes MoE RL training and has the potential to simplify the design of RL infrastructure. |
On benchmarks, Qwen3-Coder’s performance is impressive with its score of 67.0% on SWE bench verified - which increases to 69.6% with 500 turns. The 500-turn result simulates a more realistic coding workflow - where the model can read feedback (like test failures), modify code, rerun tests, and repeat until the solution works.
Implementation
This article will include implementation details for a smaller variant, Qwen3-Coder-30B-A3B-Instruct. For those curious about the name of this variant, there are 30 billion total parameters and 3 billion active parameters. The instruct indicates it’s an instruction-tuned variant of the base model.
| Number of Parameters | 30.5B total, 3.3B activated |
|---|---|
| Number of Layers | 48 |
| Number of Attention Heads (GQA) | 32for Q, and 4 for KV |
| Number of Experts and Activated Experts | 128 experts, 8 activated experts |
| Context Length | 262,144 native context (without YaRN) |
So as we can see this particular model has slightly different specs, but can run on a single H100 GPU.
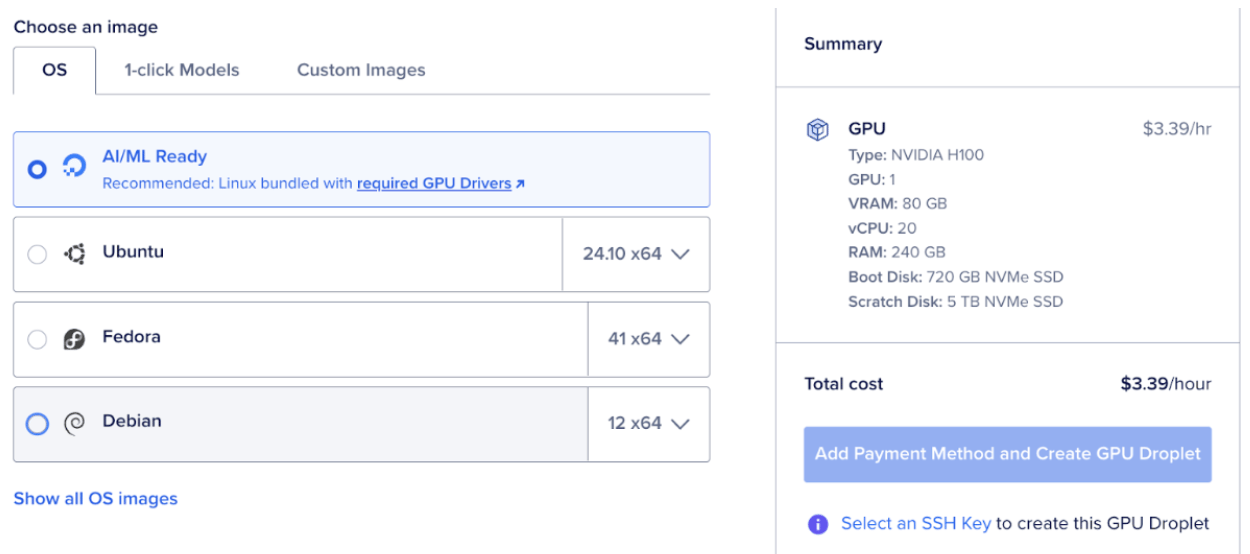
Step 1 : Set up a GPU Droplet
Begin by setting up a DigitalOcean GPU Droplet, select AI/ML and choose the NVIDIA H100 option.
Step 2: Web Console
Once your GPU Droplet finishes loading, you’ll be able to open up the Web Console.web console

Step 3: Install Dependendencies
apt install python3-pip
pip3 install transformers>=4.51.0
Step 4: Run the Model
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-30B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
Qwen Code: Open-Source CLI
Qwen Code is an open-source command-line interface for working with the Qwen3-Coder model on agentic coding tasks.
It’s a fork of the Gemini CLI, modified to work seamlessly with Qwen3’s capabilities.
We’ve included the steps to install the CLI, configure it, and run it with the Qwen3-Coder model.
Step 1: Install Node.js (Version 20 or Later)
Before you begin, make sure you have Node.js20+ installed on your device.
In your terminal:
node -v
Step 2: Install Qwen Code CLI
Once Node.js is ready, install Qwen Code globally:
npm install -g qwen-code
This makes the qwen-code command available from anywhere on your system.
Step 3: Get an API Key
Get an API key from openAI
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
Step 4: Vibe Code
 Type
Type qwen in your terminal and you’ll be able to vibe code.
For alternate ways to use Qwen3-Coder, check out the Qwen Coder blog post.
Qwen3 From Scratch
Here’s a notebook that may be of interest to those who want to improve their intuition around Qwen3’s underlying architecture.
Implement Qwen3 Mixture-of-Experts From Scratch by Sebastian Raschka: “this notebook runs Qwen3-Coder-30B-A3B-Instruct (aka Qwen3 Coder Flash) and requires 80 GB of VRAM (e.g., a single A100 or H100).”
Final Thoughts
We’re very excited to see the community play with these open-weight agentic coding models such as Qwen3-Coder, Kimi K2, Devstral, and integrate them in their workflows. What we’re most impressed about with Qwen3-Coder is its context window. At 246K tokens, extendable to a million, we’re excited to see how effective this model is in real-word software engineering use cases in comparison to alternative open-weight models. With its impressive context window, availability of accessible smaller variants with Qwen3-Coder-30B-A3B-Instruct, and the introduction of the Qwen Code CLI, this model is poised to empower developers with powerful, agentic coding assistance.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
