AI Technical Writer

Deep learning has always revolved around one simple idea of including more and more layers to build models that can better understand, represent, and generate complex data. This layered design has become the foundation of modern artificial intelligence, from image recognition to natural language understanding.
However, when it comes to reasoning, the ability to think through problems, plan, or infer abstract relationships, even today’s most powerful large language models (LLMs) face clear limitations.
Large language model architectures have a fixed number of layers, which restricts how deeply they can process information, thus placing them within computational limits that prevent truly algorithmic reasoning. In simpler terms, while these models are excellent at generating text that sounds logical, they often struggle with tasks that require genuine multi-step reasoning, such as solving complex puzzles or making structured decisions.
To overcome this, researchers have often relied on Chain-of-Thought (CoT) prompting, which makes models “think out loud” by generating intermediate reasoning steps in natural language. While effective to an extent, this method becomes inefficient as it relies heavily on human-made prompts and produces lengthy text chains that slow down response times and consume massive amounts of training data.
The Hierarchical Reasoning Model (HRM) offers a new path forward. Much like neural networks, this approach is also inspired by the human brain. HRM introduces two interconnected modules: one for high-level abstract reasoning and another for fast, low-level computations. This structure enables the model to think deeply within its internal latent space rather than relying solely on language-based reasoning. This means that the model isn’t just reasoning based on the words (tokens) it sees, but instead, it’s performing deeper thinking inside its latent space; a hidden internal representation of concepts, patterns, and relationships learned during training.
By eliminating the need for Backpropagation Through Time and maintaining a constant memory footprint, HRM achieves remarkable efficiency and depth, solving complex tasks such as Sudoku and the ARC reasoning challenge with minimal data and far fewer parameters than today’s LLMs.
In this short article, we’ll take a closer look at Hierarchical Reasoning Models (HRMs), what they are, how they work, and why they mark a major step forward in building more capable and reasoning-driven AI systems.
Key Takeaways
- HRMs introduce a new reasoning model; moving from explicit, token-based logic to internal, hidden-state reasoning.
- Latent reasoning enables models to think more abstractly and efficiently without producing long text sequences.
- Hierarchical modules (H and L) work like the human brain, where one part handles complex thinking while another focuses on basic perception and understanding.
- Temporal separation ensures that high-level reasoning remains stable while low-level processing adapts rapidly.
- Recurrent feedback loops allow iterative refinement, helping HRMs converge on better solutions over time.
- HRMs require fewer computational steps and less data compared to traditional CoT-based methods.
- HRMs could serve as a foundation for next-generation AI models that reason and plan more like humans, bridging the gap between perception, cognition, and decision-making.
Latent Reasoning
Latent reasoning refers to the ability of a model to think and make decisions within its hidden (latent) state space, rather than relying completely on generating or analyzing tokens (words). Unlike traditional LLMs that depend on Chain-of-Thought (CoT) prompting reasoning step-by-step in natural language, latent reasoning operates silently within the model’s internal representations.
This approach is far more efficient and compact, as it eliminates unnecessary linguistic overhead and focuses directly on understanding relationships and patterns in data.
The Hierarchical Reasoning Model (HRM) incorporates this idea by performing multi-level reasoning inside its latent layers. Its high-level module manages abstract, global reasoning, while the low-level module refines detailed computations, all without producing long token chains.
Just as the human brain can solve problems or make decisions without verbalizing every thought, HRM reasons internally, using structured, layered representations instead of words.
An Overview of Hierarchical Reasoning Models
The Hierarchical Reasoning Model (HRM) is a brain-inspired AI architecture designed to allow deeper, more efficient reasoning than traditional LLMs. It draws from three key principles of how the brain processes information:
- Hierarchical Processing: HRM has two interconnected modules, a High-level module (H) for abstract reasoning and a Low-level module (L) for fast, detailed computation. The H module guides, while the L module executes and refines.
- Temporal Separation: These modules operate at different speeds; the H module updates slowly and stably, while the L module updates rapidly. This allows high-level reasoning to steer low-level actions effectively.
- Recurrent Connectivity: Like feedback loops in the brain, HRM continually refines its understanding through recurrence, improving context and accuracy without heavy computation like Backpropagation Through Time (BPTT).
The architecture consists of four key learnable components:
- Input network (fI) – encodes raw input into a working representation.
- Low-level recurrent module (fL) – performs fast, fine-grained computations.
- High-level recurrent module (fH) – handles abstract reasoning and context updates.
- Output network (fO) – generates the final prediction.
During a single forward pass, the model extends over N high-level cycles, each containing T low-level timesteps. The low-level module updates its state at every step, while the high-level module updates only once per cycle, creating a nested computation process. This structure allows HRMs to integrate short-term pattern recognition with long-term reasoning, much like the interaction between the neocortex and basal ganglia in the brain.
Hierarchical Convergence
One of the core innovations of HRM is hierarchical convergence, which addresses a common limitation in standard RNNs: early convergence. Traditional recurrent models often stall as their hidden states stabilize too quickly, reducing computational depth. In contrast, HRMs use a two-level convergence mechanism:
- The low-level module converges within each cycle toward a temporary equilibrium.
- The high-level module updates after each cycle, providing new context that “resets” the low-level computations.
This dynamic ensures that the model continues to evolve over multiple cycles, maintaining stable yet deep computation, which leads to better reasoning depth and performance.
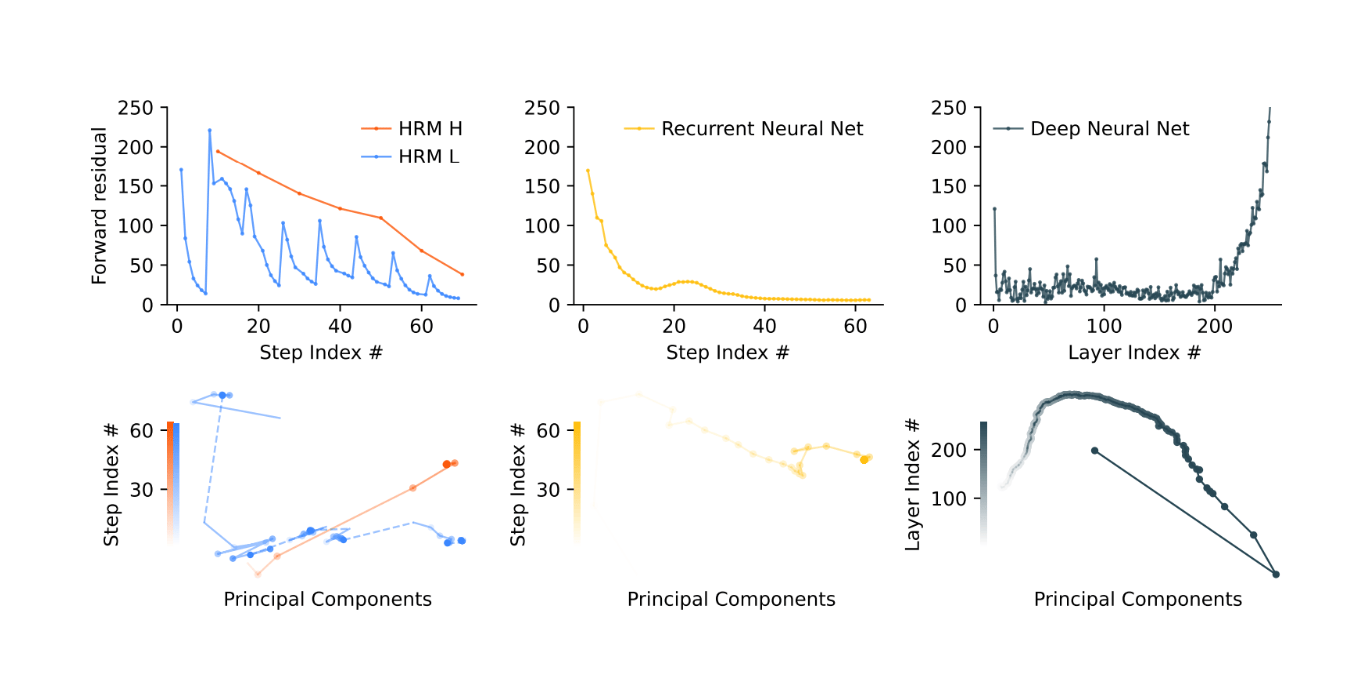
In HRM, the high-level module (H) converges gradually while the low-level module (L) repeatedly refines and resets, creating visible residual spikes. In contrast, RNNs converge too quickly, losing activity early, and DNNs suffer from vanishing gradients, where only the first and last layers stay active. This shows HRM sustains deeper, structured computation over time.
One-Step Gradient Approximation
Training recurrent models with Backpropagation Through Time (BPTT) can be memory-intensive. HRMs overcome this with a one-step gradient approximation, inspired by Deep Equilibrium Models (DEQ). Instead of unrolling through time, HRMs compute gradients directly from the final equilibrium state, significantly reducing memory usage from O(T) to O(1). This approach also aligns with biologically plausible local learning rules, as it relies on short-term activity rather than full sequence replay.
In simpler terms, this means that instead of keeping track of every step over time (which uses a lot of memory), HRMs only use the final stable state of the model to learn. This makes the process much more memory-efficient. It also works more like how the human brain learns, by using short bursts of activity to adjust connections, rather than replaying entire sequences of events.
Mathematically, the approximation uses the Implicit Function Theorem (IFT) to compute gradients at the model’s fixed point without explicit time unrolling. In practice, the 1-step gradient replaces complex matrix inversion with a simplified linear approximation, preserving learning efficiency while cutting computational cost. The gradient path is,
Output head → final state of the H-module → final state of the L-module → input embedding
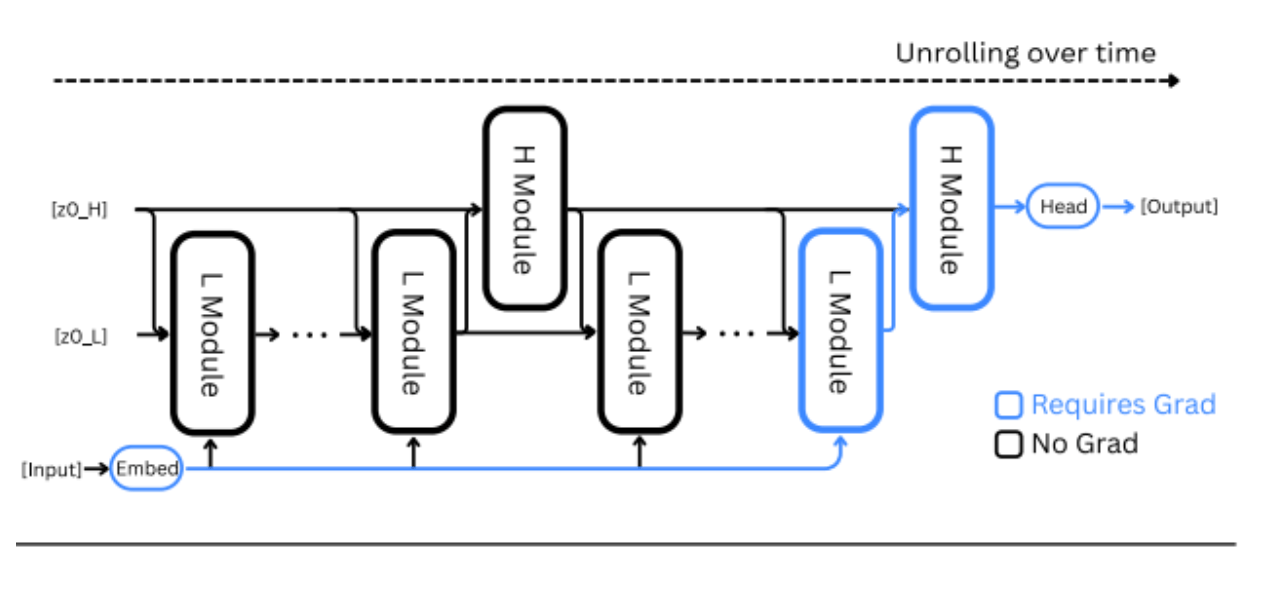
HRM with approximate gradient

This pseudocode illustrates how the Hierarchical Reasoning Model (HRM) operates and is trained. The model processes input data through an embedding layer, then alternates between a fast low-level module (L) and a slower high-level module (H). The L-module updates its state at every step, while the H-module updates less frequently to provide broader contextual guidance. A one-step gradient approximation simplifies training by reducing memory use, and deep supervision ensures the model learns effectively across multiple reasoning levels. Together, these mechanisms enable HRM to perform structured, layered reasoning efficiently.
Deep Supervision
Deep Supervision in HRM is inspired by how the brain periodically decides when to learn. Instead of waiting until the end of training to adjust weights, HRM provides feedback after every reasoning segment. Each forward pass (or segment) produces a prediction and computes its own loss. Before starting the next segment, the model detaches the previous one from the computation graph, meaning gradients don’t flow backward through earlier steps. This one-step gradient update allows HRM to learn more frequently and efficiently while avoiding heavy memory costs. It also stabilizes training and helps the model refine both high-level and low-level reasoning simultaneously.
Adaptive Computational Time (ACT)
ACT allows HRM to think dynamically, adjusting how long it “reasons” depending on the task’s complexity, much like how the human brain switches between quick intuition and slow, deliberate thinking. Using a reinforcement learning approach (Q-learning), the model learns when to halt or continue processing based on its confidence in the prediction. If the task seems easy, HRM stops early; for more complex problems, it takes additional steps. This adaptability ensures efficient use of computational resources without sacrificing performance. HRM can also scale up during inference simply by allowing more computation cycles, improving accuracy for tasks requiring deeper reasoning.
FAQ’s
1. What makes Hierarchical Reasoning Models (HRMs) different from traditional Large Language Models (LLMs)? Unlike conventional LLMs that depend on text-based reasoning or Chain-of-Thought (CoT) prompting, HRMs perform reasoning internally within their neural states. They don’t need to generate long textual explanations to “think.” Instead, they use hierarchical modules that communicate through hidden representations, thus making reasoning more structured, efficient, and closer to how the human brain processes abstract thought.
2. How does HRM’s hierarchical structure work? HRM is built on two key modules: a Low-level (L) module and a High-level (H) module.
- The L-module focuses on fast, detailed computations, similar to how sensory processing happens in the brain.
- The H-module operates at slower timescales, integrating broader context and guiding the L-module’s operations. This interaction creates a feedback loop where the H-module refines understanding while the L-module executes specific reasoning tasks. Over multiple cycles, HRMs develop deep and stable representations that lead to accurate predictions.
3. Why is latent reasoning more efficient than Chain-of-Thought prompting? CoT prompting expands reasoning into multiple textual steps, which can be verbose, computationally expensive, and prone to redundancy. Latent reasoning, on the other hand, happens entirely in the model’s hidden state space, the internal neural representations that don’t rely on language tokens. This makes HRMs faster, less resource-intensive, and capable of performing reasoning without producing unnecessary intermediate text.
4. How does HRM mimic how the human brain reasons? The HRM draws inspiration from neuroscience principles such as hierarchical processing, temporal separation, and recurrent connectivity. Much like the brain, it processes information across multiple layers, integrating high-level context while refining lower-level details. Humans don’t verbalize every thought step when solving problems; similarly, HRMs reason “silently,” relying on internal state updates rather than token generation.
5. Can HRMs replace current LLMs in practical applications?
Not immediately. HRMs are still under active research, but they present a promising shift toward models that understand and reason beyond language. In the future, they could enhance or complement LLMs by offering faster reasoning, fewer hallucinations, and greater interpretability, especially in areas like scientific discovery, planning, and multi-step decision-making.
6. What are the key benefits of using HRMs?
HRMs improve reasoning efficiency, scalability, and stability. They allow models to reason across longer timescales, maintain hierarchical coherence, and adaptively decide when to halt processing. This approach not only reduces computational overhead but also aligns AI reasoning more closely with human cognitive structures.
Conclusion
The Hierarchical Reasoning Model (HRM) is built to overcome the limitations of token-based reasoning in conventional LLMs. Instead of relying on long, text-based chains of thought, HRM performs reasoning directly within its latent state space , the internal numerical representations of knowledge.
By structuring its reasoning into two interacting modules, a Low-level (L) module for local pattern understanding and a High-level (H) module for global reasoning, HRM can process information in layers, much like how the human brain separates perception from reflection. The L-module refines immediate details, while the H-module guides long-term reasoning and periodically resets the lower layer to prevent overfitting to surface-level patterns.
This architecture allows HRM to reason more efficiently, minimize redundant computations, and maintain stability across complex, multi-step tasks; a significant leap beyond the token-bound reasoning of traditional LLMs.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
