By Saurabh Chaturvedi and Kathryn Hancox

The author selected The Computer History Museum to receive a donation as part of the Write for DOnations program.
Introduction
Twitter bots are a powerful way of managing your social media as well as extracting information from the microblogging network. By leveraging Twitter’s versatile APIs, a bot can do a lot of things: tweet, retweet, “favorite-tweet”, follow people with certain interests, reply automatically, and so on. Even though people can, and do, abuse their bot’s power, leading to a negative experience for other users, research shows that people view Twitter bots as a credible source of information. For example, a bot can keep your followers engaged with content even when you’re not online. Some bots even provide critical and helpful information, like @EarthquakesSF. The applications for bots are limitless. As of 2019, it is estimated that bots account for about 24% of all tweets on Twitter.
In this tutorial, you’ll build a Twitter bot using this Twitter API library for Python. You’ll use API keys from your Twitter account to authorize your bot and build a to capable of scraping content from two websites. Furthermore, you’ll program your bot to alternately tweet content from these two websites and at set time intervals. Note that you’ll use Python 3 in this tutorial.
Prerequisites
You will need the following to complete this tutorial:
- A local Python 3 programming environment set up by following How To Install and Set Up a Local Programming Environment For Python 3.
- Have a text editor of your choice installed, such as Visual Studio Code, Atom, or Sublime Text.
Note: You’ll be setting up a developer account with Twitter, which involves an application review by Twitter before you can access the API keys you require for this bot. Step 1 walks through the specific details for completing the application.
Step 1 — Setting Up Your Developer Account and Accessing Your Twitter API Keys
Before you begin coding your bot, you’ll need the API keys for Twitter to recognize the requests of your bot. In this step, you’ll set up your Twitter Developer Account and access your API keys for your Twitter bot.
To get your API keys, head over to developer.twitter.com and register your bot application with Twitter by clicking on Apply in the top right section of the page.
Now click on Apply for a developer account.
Next, click on Continue to associate your Twitter username with your bot application that you’ll be building in this tutorial.
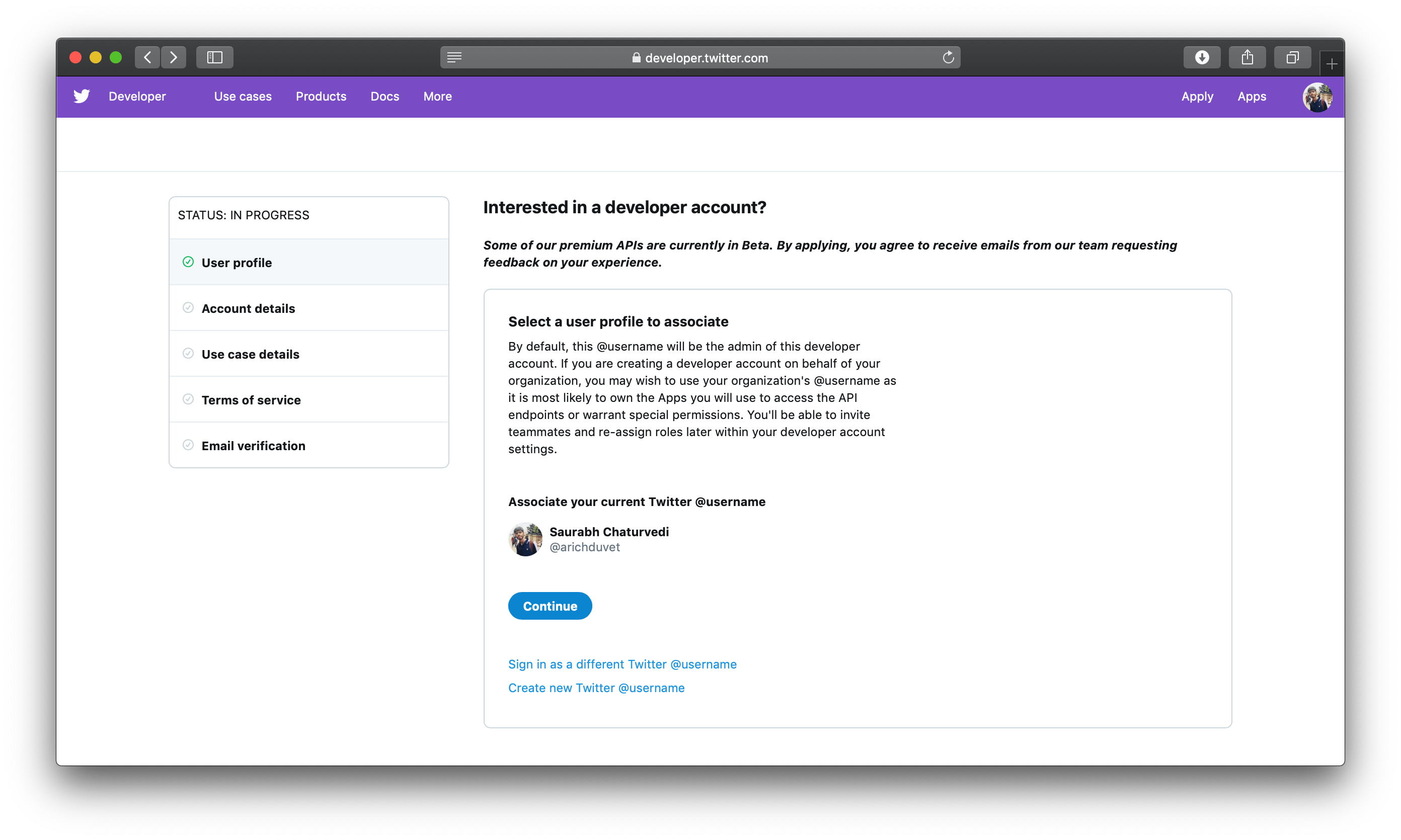
On the next page, for the purposes of this tutorial, you’ll choose the I am requesting access for my own personal use option since you’ll be building a bot for your own personal education use.
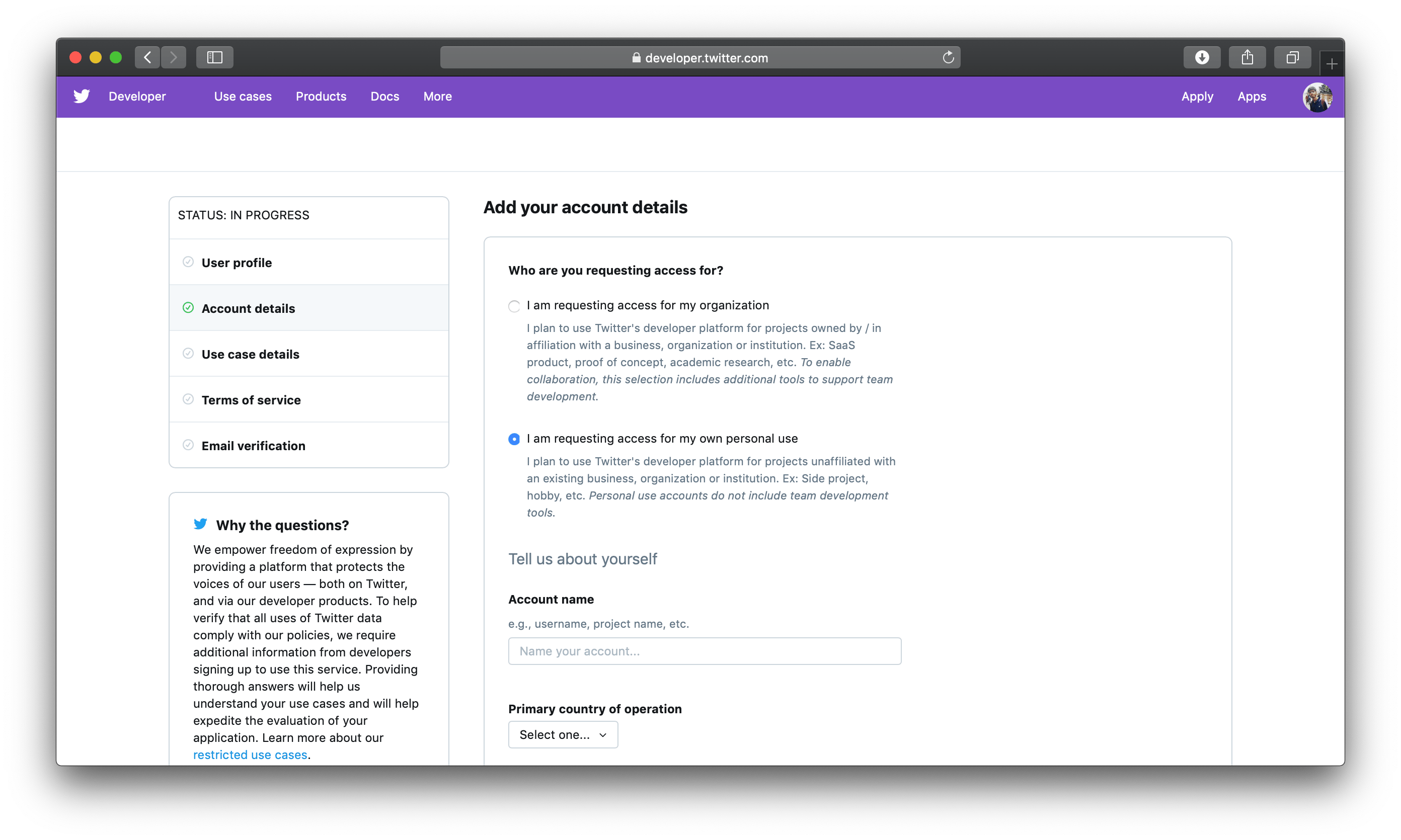
After choosing your Account Name and Country, move on to the next section. For What use case(s) are you interested in?, pick the Publish and curate Tweets and Student project / Learning to code options. These categories are the best representation of why you’re completing this tutorial.
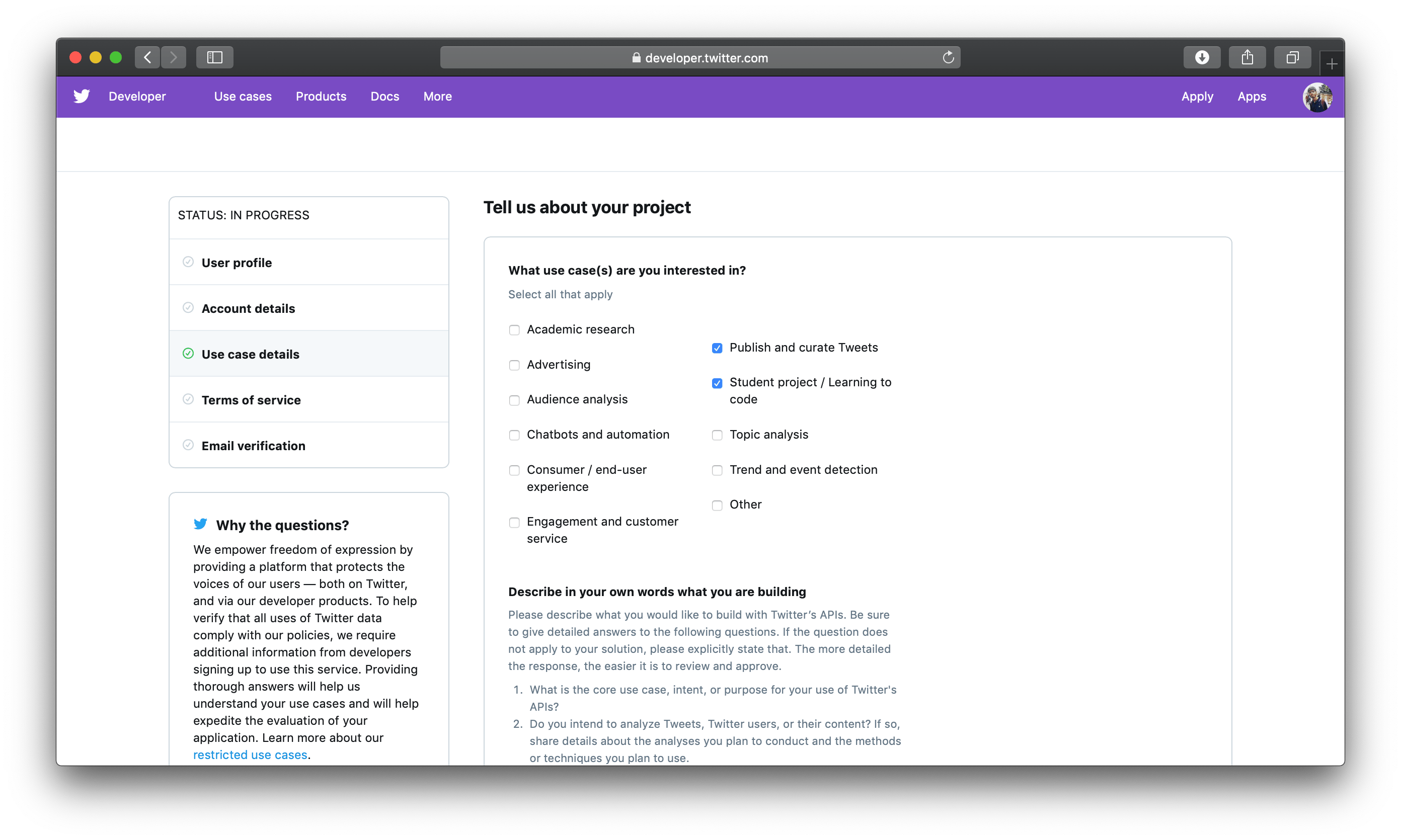
Then provide a description of the bot you’re trying to build. Twitter requires this to protect against bot abuse; in 2018 they introduced such vetting. For this tutorial, you’ll be scraping tech-focused content from The New Stack and The Coursera Blog.
When deciding what to enter into the description box, model your answer on the following lines for the purposes of this tutorial:
I’m following a tutorial to build a Twitter bot that will scrape content from websites like thenewstack.io (The New Stack) and blog.coursera.org (Coursera’s Blog) and tweet quotes from them. The scraped content will be aggregated and will be tweeted in a round-robin fashion via Python generator functions.
Finally, choose no for Will your product, service, or analysis make Twitter content or derived information available to a government entity?
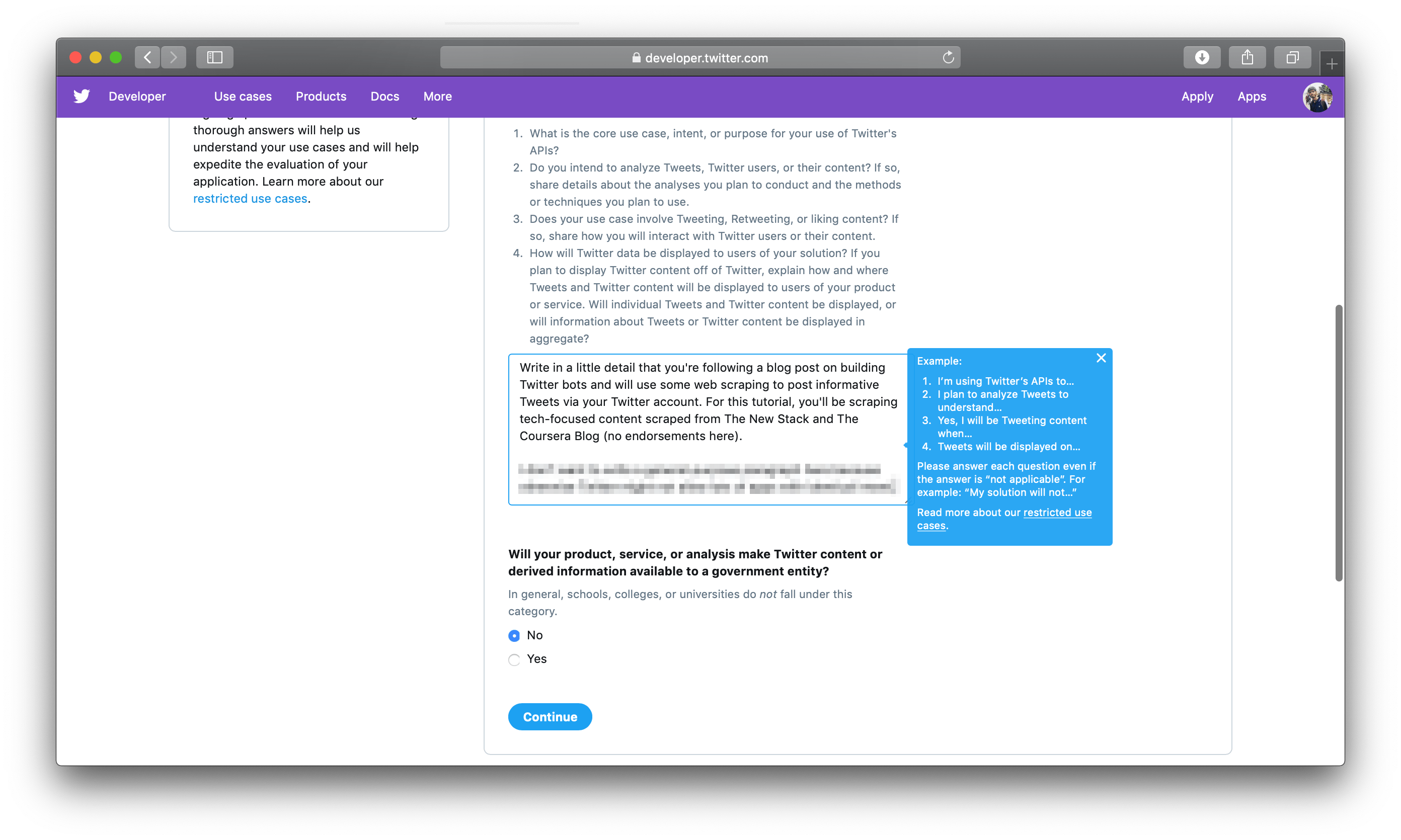
Next, accept Twitter’s terms and conditions, click on Submit application, and then verify your email address. Twitter will send a verification email to you after your submission of this form.
Once you verify your email, you’ll get an Application under review page with a feedback form for the application process.
You will also receive another email from Twitter regarding the review:
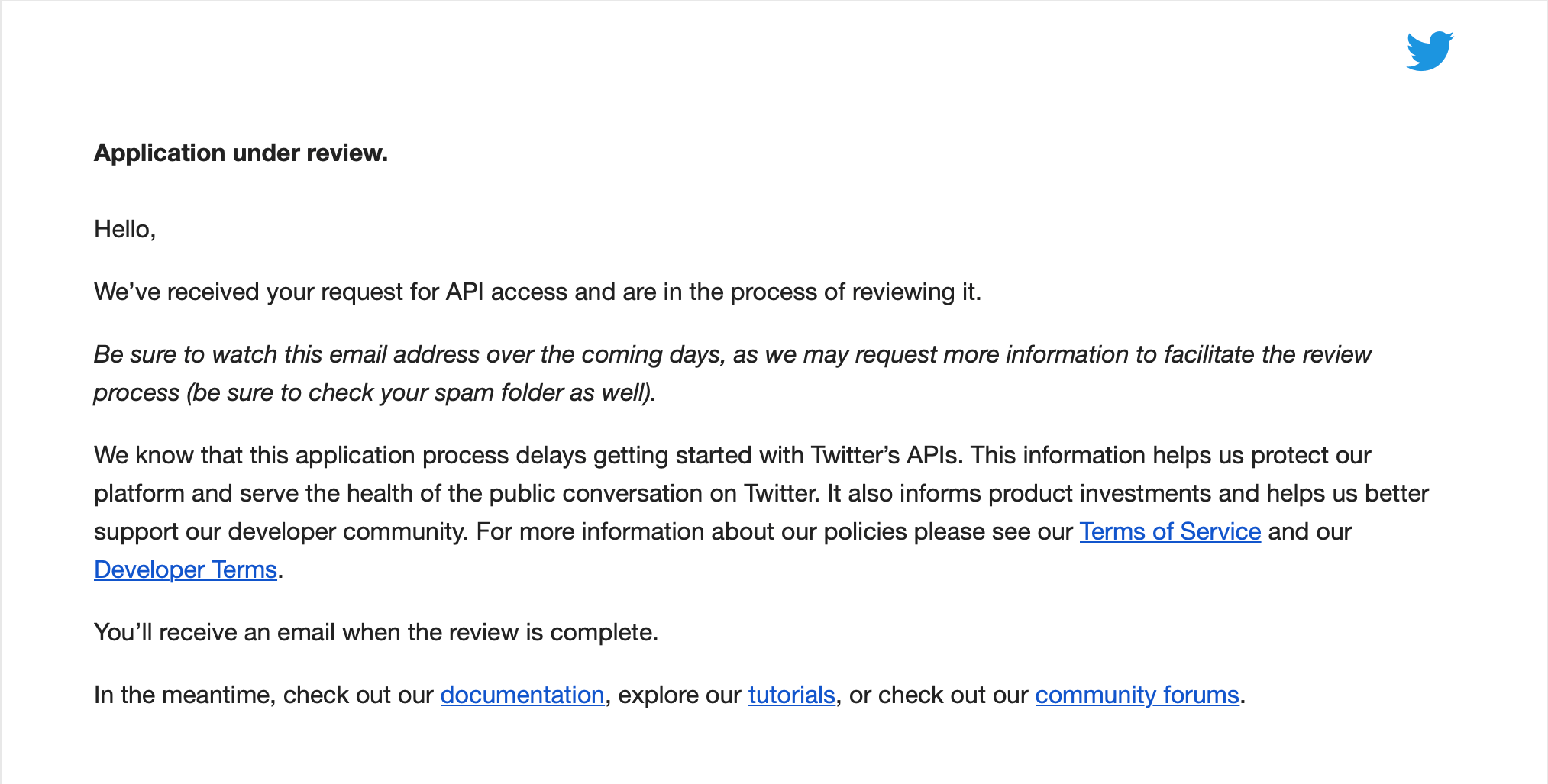
The timeline for Twitter’s application review process can vary significantly, but often Twitter will confirm this within a few minutes. However, should your application’s review take longer than this, it is not unusual, and you should receive it within a day or two. Once you receive confirmation, Twitter has authorized you to generate your keys. You can access these under the Keys and tokens tab after clicking the details button of your app on developer.twitter.com/apps.
Finally go to the Permissions tab on your app’s page and set the Access Permission option to Read and Write since you want to write tweet content too. Usually, you would use the read-only mode for research purposes like analyzing trends, data-mining, and so on. The final option allows users to integrate chatbots into their existing apps, since chatbots require access to direct messages.
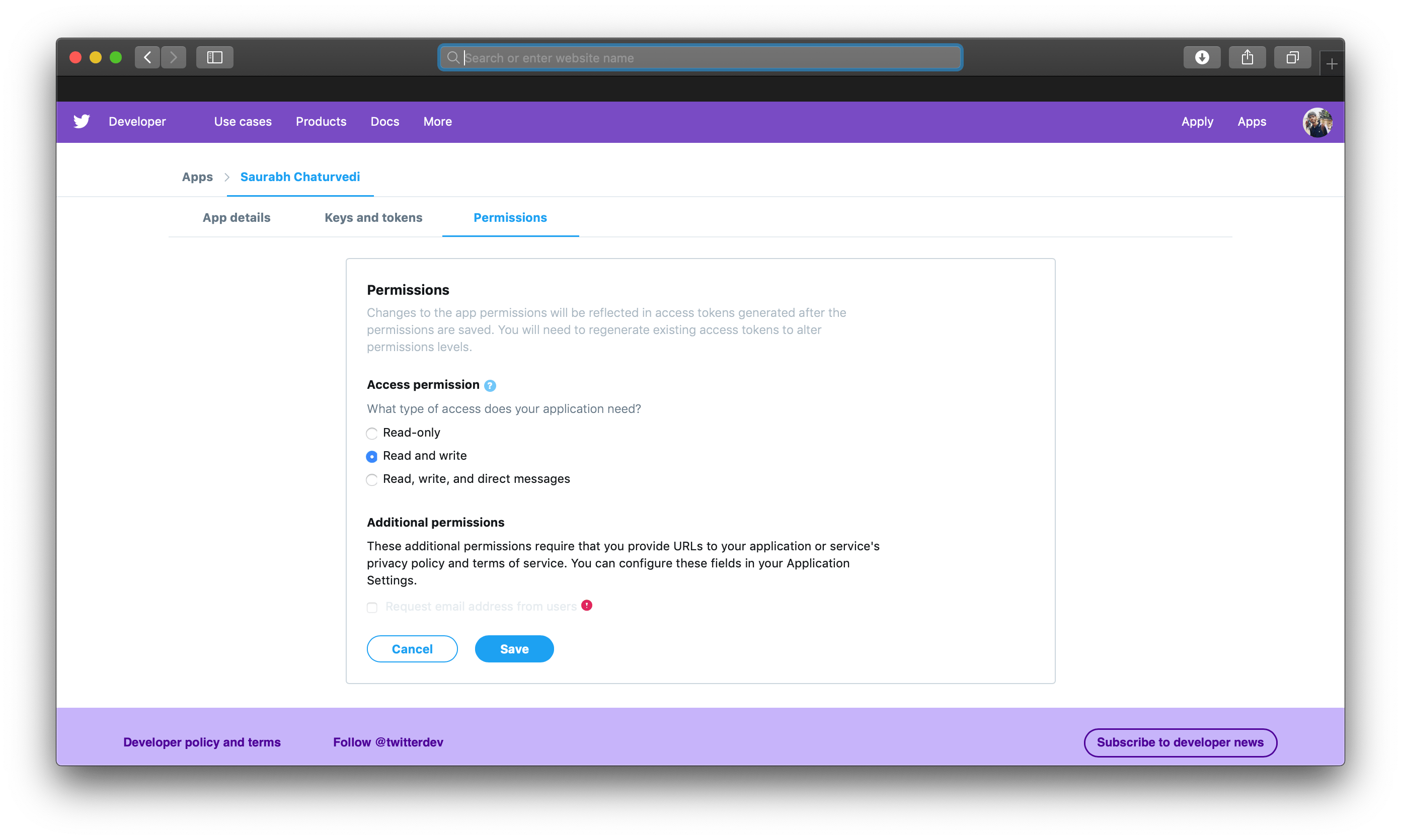
You have access to Twitter’s powerful API, which will be a crucial part of your bot application. Now you’ll set up your environment and begin building your bot.
Step 2 — Building the Essentials
In this step, you’ll write code to authenticate your bot with Twitter using the API keys, and make the first programmatic tweet via your Twitter handle. This will serve as a good milestone in your path towards the goal of building a Twitter bot that scrapes content from The New Stack and the Coursera Blog and tweets them periodically.
First, you’ll set up a project folder and a specific programming environment for your project.
Create your project folder:
- mkdir bird
Move into your project folder:
- cd bird
Then create a new Python virtual environment for your project:
- python3 -m venv bird-env
Then activate your environment using the following command:
- source bird-env/bin/activate
This will attach a (bird-env) prefix to the prompt in your terminal window.
Now move to your text editor and create a file called credentials.py, which will store your Twitter API keys:
- nano credentials.py
Add the following content, replacing the highlighted code with your keys from Twitter:
ACCESS_TOKEN='your-access-token'
ACCESS_SECRET='your-access-secret'
CONSUMER_KEY='your-consumer-key'
CONSUMER_SECRET='your-consumer-secret'
Now, you’ll install the main API library for sending requests to Twitter. For this project, you’ll require the following libraries: nltk, requests, twitter, lxml, random, and time. random and time are part of Python’s standard library, so you don’t need to separately install these libraries. To install the remaining libraries, you’ll use pip, a package manager for Python.
Open your terminal, ensure you’re in the project folder, and run the following command:
- pip3 install lxml nltk requests twitter
lxmlandrequests: You will use them for web scraping.twitter: This is the library for making API calls to Twitter’s servers.nltk: (natural language toolkit) You will use to split paragraphs of blogs into sentences.random: You will use this to randomly select parts of an entire scraped blog post.time: You will use to make your bot sleep periodically after certain actions.
Once you have installed the libraries, you’re all set to begin programming. Now, you’ll import your credentials into the main script that will run the bot. Alongside credentials.py, from your text editor create a file in the bird project directory, and name it bot.py:
- nano bot.py
In practice, you would spread the functionality of your bot across multiple files as it grows more and more sophisticated. However, in this tutorial, you’ll put all of your code in a single script, bot.py, for demonstration purposes.
First you’ll test your API keys by authorizing your bot. Begin by adding the following snippet to bot.py:
import random
import time
from lxml.html import fromstring
import nltk
nltk.download('punkt')
import requests
from twitter import OAuth, Twitter
import credentials
Here, you import the required libraries; and in a couple of instances you import the necessary functions from the libraries. You will use the fromstring function later in the code to convert the string source of a scraped webpage to a tree structure that makes it easier to extract relevant information from the page. OAuth will help you in constructing an authentication object from your keys, and Twitter will build the main API object for all further communication with Twitter’s servers.
Now extend bot.py with the following lines:
...
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
oauth = OAuth(
credentials.ACCESS_TOKEN,
credentials.ACCESS_SECRET,
credentials.CONSUMER_KEY,
credentials.CONSUMER_SECRET
)
t = Twitter(auth=oauth)
nltk.download('punkt') downloads a dataset necessary for parsing paragraphs and tokenizing (splitting) them into smaller components. tokenizer is the object you’ll use later in the code for splitting paragraphs written in English.
oauth is the authentication object constructed by feeding the imported OAuth class with your API keys. You authenticate your bot via the line t = Twitter(auth=oauth). ACCESS_TOKEN and ACCESS_SECRET help in recognizing your application. Finally, CONSUMER_KEY and CONSUMER_SECRET help in recognizing the handle via which the application interacts with Twitter. You’ll use this t object to communicate your requests to Twitter.
Now save this file and run it in your terminal using the following command:
- python3 bot.py
Your output will look similar to the following, which means your authorization was successful:
Output[nltk_data] Downloading package punkt to /Users/binaryboy/nltk_data...
[nltk_data] Package punkt is already up-to-date!
If you do receive an error, verify your saved API keys with those in your Twitter developer account and try again. Also ensure that the required libraries are installed correctly. If not, use pip3 again to install them.
Now you can try tweeting something programmatically. Type the same command on the terminal with the -i flag to open the Python interpreter after the execution of your script:
- python3 -i bot.py
Next, type the following to send a tweet via your account:
- t.statuses.update(status="Just setting up my Twttr bot")
Now open your Twitter timeline in a browser, and you’ll see a tweet at the top of your timeline containing the content you posted.
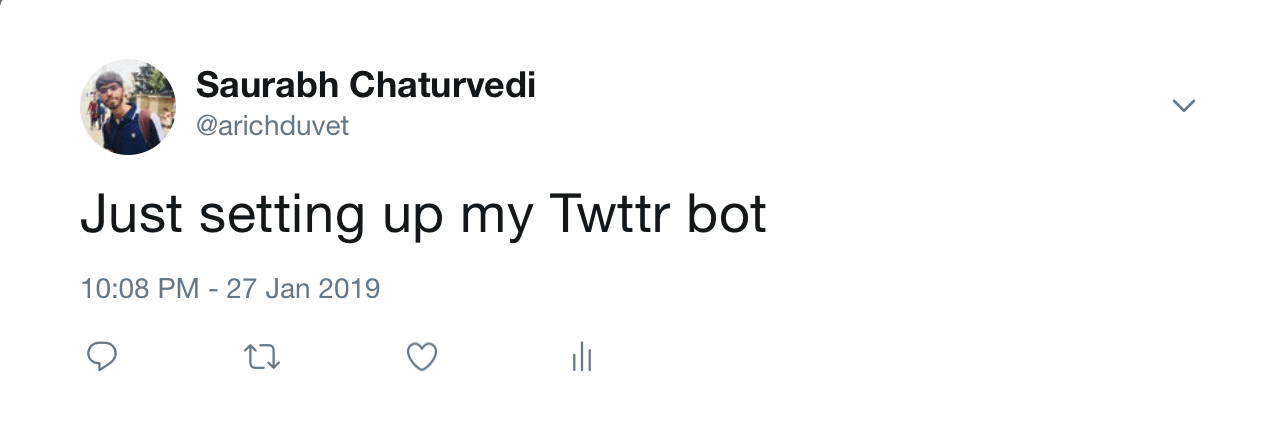
Close the interpreter by typing quit() or CTRL + D.
Your bot now has the fundamental capability to tweet. To develop your bot to tweet useful content, you’ll incorporate web scraping in the next step.
Step 3 — Scraping Websites for Your Tweet Content
To introduce some more interesting content to your timeline, you’ll scrape content from the New Stack and the Coursera Blog, and then post this content to Twitter in the form of tweets. Generally, to scrape the appropriate data from your target websites, you have to experiment with their HTML structure. Each tweet coming from the bot you’ll build in this tutorial will have a link to a blog post from the chosen websites, along with a random quote from that blog. You’ll implement this procedure within a function specific to scraping content from Coursera, so you’ll name it scrape_coursera().
First open bot.py:
- nano bot.py
Add the scrape_coursera() function to the end of your file:
...
t = Twitter(auth=oauth)
def scrape_coursera():
To scrape information from the blog, you’ll first request the relevant webpage from Coursera’s servers. For that you will use the get() function from the requests library. get() takes in a URL and fetches the corresponding webpage. So, you’ll pass blog.coursera.org as an argument to get(). But you also need to provide a header in your GET request, which will ensure Coursera’s servers recognize you as a genuine client. Add the following highlighted lines to your scrape_coursera() function to provide a header:
def scrape_coursera():
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
This header will contain information pertaining to a defined web browser running on a specific operating system. As long as this information (usually referred to as User-Agent) corresponds to real web browsers and operating systems, it doesn’t matter whether the header information aligns with the actual web browser and operating system on your computer. Therefore this header will work fine for all systems.
Once you have defined the headers, add the following highlighted lines to make a GET request to Coursera by specifying the URL of the blog webpage:
...
def scrape_coursera():
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
r = requests.get('https://blog.coursera.org', headers=HEADERS)
tree = fromstring(r.content)
This will fetch the webpage to your machine and save the information from the entire webpage in the variable r. You can assess the HTML source code of the webpage using the content attribute of r. Therefore, the value of r.content is the same as what you see when you inspect the webpage in your browser by right clicking on the page and choosing the Inspect Element option.
Here you’ve also added the fromstring function. You can pass the webpage’s source code to the fromstring function imported from the lxml library to construct the tree structure of the webpage. This tree structure will allow you to conveniently access different parts of the webpage. HTML source code has a particular tree-like structure; every element is enclosed in the <html> tag and nested thereafter.
Now, open https://blog.coursera.org in a browser and inspect its HTML source using the browser’s developer tools. Right click on the page and choose the Inspect Element option. You’ll see a window appear at the bottom of the browser, showing part of the page’s HTML source code.
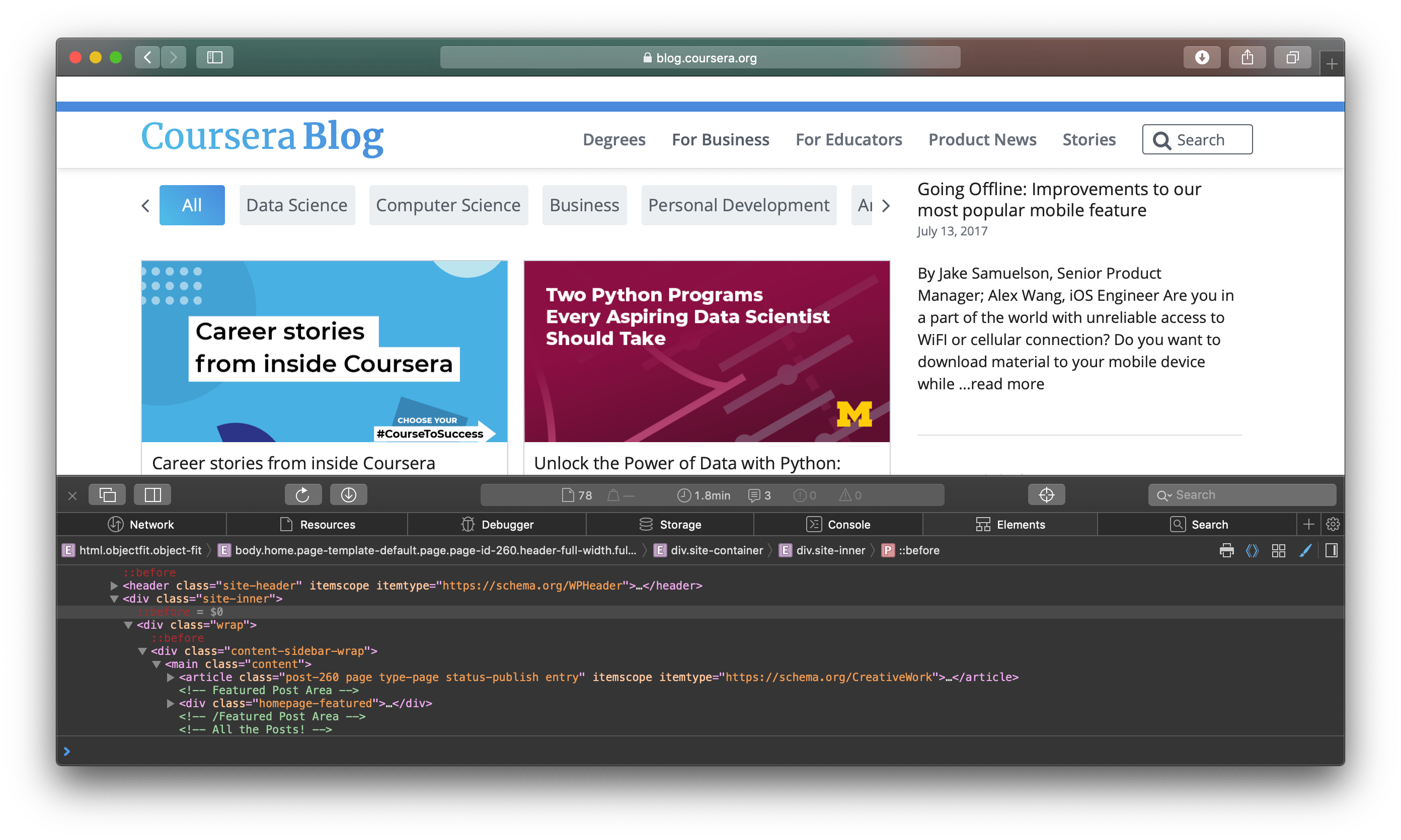
Next, right click on the thumbnail of any visible blog post and then inspect it. The HTML source will highlight the relevant HTML lines where that blog thumbnail is defined. You’ll notice that all blog posts on this page are defined within a <div> tag with a class of "recent" :
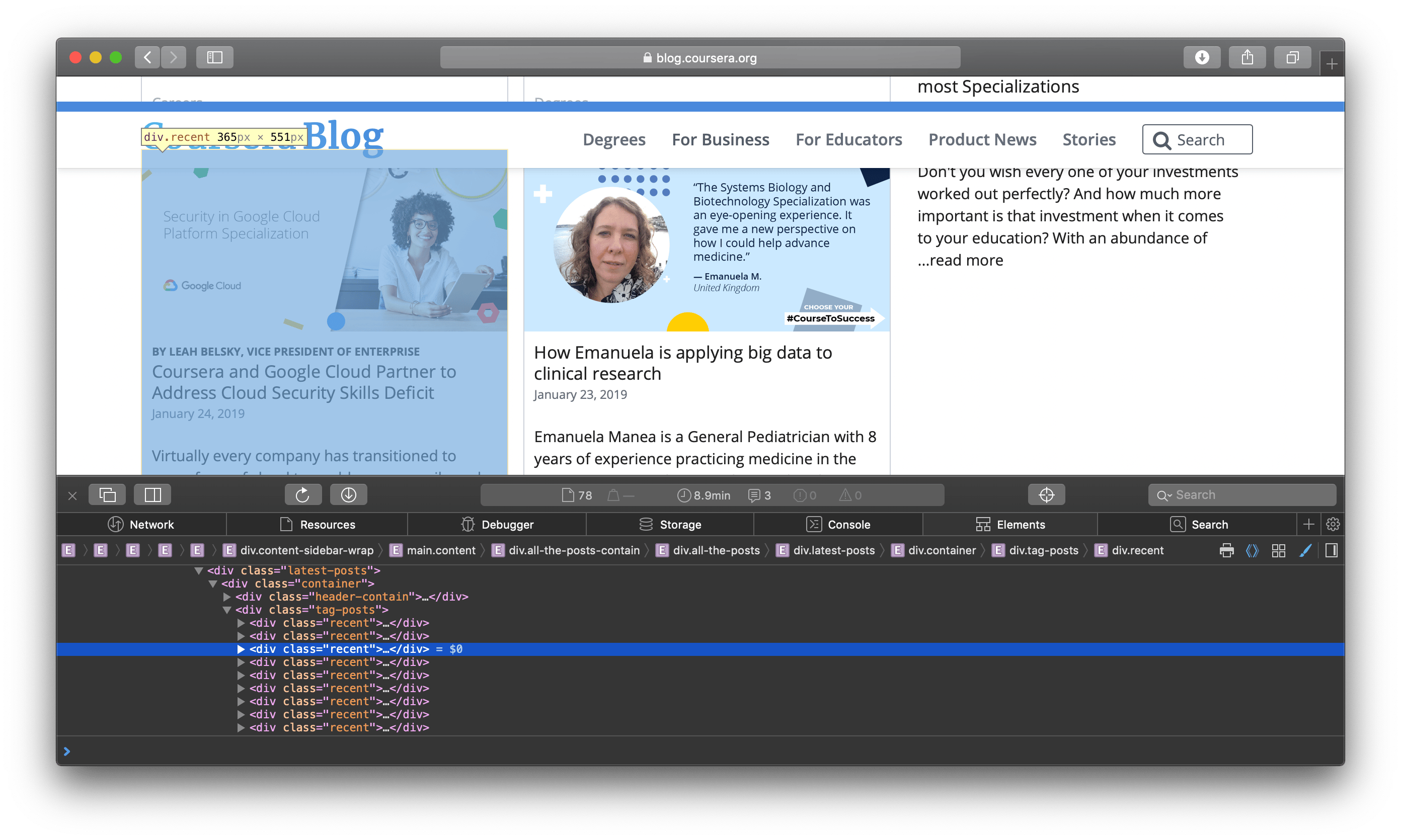
Thus, in your code, you’ll use all such blog post div elements via their XPath, which is a convenient way of addressing elements of a web page.
To do so, extend your function in bot.py as follows:
...
def scrape_coursera():
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
r = requests.get('https://blog.coursera.org', headers=HEADERS)
tree = fromstring(r.content)
links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
print(links)
scrape_coursera()
Here, the XPath (the string passed to tree.xpath()) communicates that you want div elements from the entire web page source, of class "recent". The // corresponds to searching the whole webpage, div tells the function to extract only the div elements, and [@class="recent"] asks it to only extract those div elements that have the values of their class attribute as "recent".
However, you don’t need these elements themselves, you only need the links they’re pointing to, so that you can access the individual blog posts to scrape their content. Therefore, you extract all the links using the values of the href anchor tags that are within the previous div tags of the blog posts.
To test your program so far, you call the scrape_coursera() function at the end of bot.py.
Save and exit bot.py.
Now run bot.py with the following command:
- python3 bot.py
In your output, you’ll see a list of URLs like the following:
Output['https://blog.coursera.org/career-stories-from-inside-coursera/', 'https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/', ...]
After you verify the output, you can remove the last two highlighted lines from bot.py script:
...
def scrape_coursera():
...
tree = fromstring(r.content)
links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
~~print(links)~~
~~scrape_coursera()~~
Now extend the function in bot.py with the following highlighted line to extract the content from a blog post:
...
def scrape_coursera():
...
links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
for link in links:
r = requests.get(link, headers=HEADERS)
blog_tree = fromstring(r.content)
You iterate over each link, fetch the corresponding blog post, extract a random sentence from the post, and then tweet this sentence as a quote, along with the corresponding URL. Extracting a random sentence involves three parts:
- Grabbing all the paragraphs in the blog post as a list.
- Selecting a paragraph at random from the list of paragraphs.
- Selecting a sentence at random from this paragraph.
You’ll execute these steps for each blog post. For fetching one, you make a GET request for its link.
Now that you have access to the content of a blog, you will introduce the code that executes these three steps to extract the content you want from it. Add the following extension to your scraping function that executes the three steps:
...
def scrape_coursera():
...
for link in links:
r = requests.get(link, headers=HEADERS)
blog_tree = fromstring(r.content)
paras = blog_tree.xpath('//div[@class="entry-content"]/p')
paras_text = [para.text_content() for para in paras if para.text_content()]
para = random.choice(paras_text)
para_tokenized = tokenizer.tokenize(para)
for _ in range(10):
text = random.choice(para_tokenized)
if text and 60 < len(text) < 210:
break
If you inspect the blog post by opening the first link, you’ll notice that all the paragraphs belong to the div tag having entry-content as its class. Therefore, you extract all paragraphs as a list with paras = blog_tree.xpath('//div[@class="entry-content"]/p').
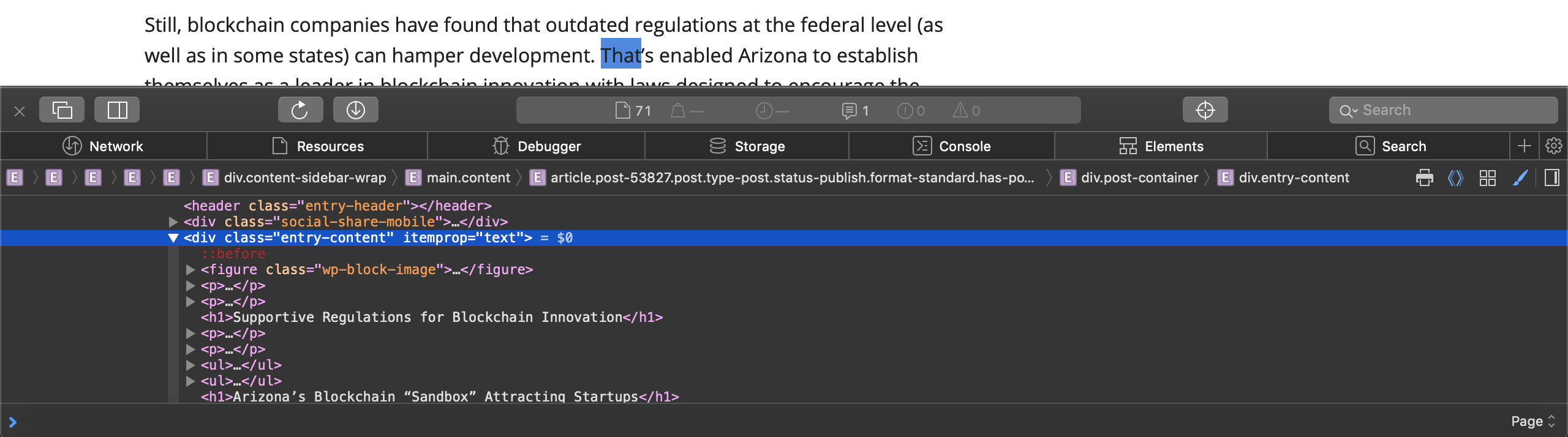
The list elements aren’t literal paragraphs; they are Element objects. To extract the text out of these objects, you use the text_content() method. This line follows Python’s list comprehension design pattern, which defines a collection using a loop that is usually written out in a single line. In bot.py, you extract the text for each paragraph element object and store it in a list if the text is not empty. To randomly choose a paragraph from this list of paragraphs, you incorporate the random module.
Finally, you have to select a sentence at random from this paragraph, which is stored in the variable para. For this task, you first break the paragraph into sentences. One approach to accomplish this is using the Python’s split() method. However this can be difficult since a sentence can be split at multiple breakpoints. Therefore, to simplify your splitting tasks, you leverage natural language processing through the nltk library. The tokenizer object you defined earlier in the tutorial will be useful for this purpose.
Now that you have a list of sentences, you call random.choice() to extract a random sentence. You want this sentence to be a quote for a tweet, so it can’t exceed 280 characters. However, for aesthetic reasons, you’ll select a sentence that is neither too big nor too small. You designate that your tweet sentence should have a length between 60 to 210 characters. The sentence random.choice() picks might not satisfy this criterion. To identify the right sentence, your script will make ten attempts, checking for the criterion each time. Once the randomly picked-up sentence satisfies your criterion, you can break out of the loop.
Although the probability is quite low, it is possible that none of the sentences meet this size condition within ten attempts. In this case, you’ll ignore the corresponding blog post and move on to the next one.
Now that you have a sentence to quote, you can tweet it with the corresponding link. You can do this by yielding a string that contains the randomly picked-up sentence as well as the corresponding blog link. The code that calls this scrape_coursera() function will then post the yielded string to Twitter via Twitter’s API.
Extend your function as follows:
...
def scrape_coursera():
...
for link in links:
...
para_tokenized = tokenizer.tokenize(para)
for _ in range(10):
text = random.choice(para)
if text and 60 < len(text) < 210:
break
else:
yield None
yield '"%s" %s' % (text, link)
The script only executes the else statement when the preceding for loop doesn’t break. Thus, it only happens when the loop is not able to find a sentence that fits your size condition. In that case, you simply yield None so that the code that calls this function is able to determine that there is nothing to tweet. It will then move on to call the function again and get the content for the next blog link. But if the loop does break it means the function has found an appropriate sentence; the script will not execute the else statement, and the function will yield a string composed of the sentence as well as the blog link, separated by a single whitespace.
The implementation of the scrape_coursera() function is almost complete. If you want to make a similar function to scrape another website, you will have to repeat some of the code you’ve written for scraping Coursera’s blog. To avoid rewriting and duplicating parts of the code and to ensure your bot’s script follows the DRY principle (Don’t Repeat Yourself), you’ll identify and abstract out parts of the code that you will use again and again for any scraper function written later.
Regardless of the website the function is scraping, you’ll have to randomly pick up a paragraph and then choose a random sentence from this chosen paragraph — you can extract out these functionalities in separate functions. Then you can simply call these functions from your scraper functions and achieve the desired result. You can also define HEADERS outside the scrape_coursera() function so that all of the scraper functions can use it. Therefore, in the code that follows, the HEADERS definition should precede that of the scraper function, so that eventually you’re able to use it for other scrapers:
...
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
def scrape_coursera():
r = requests.get('https://blog.coursera.org', headers=HEADERS)
...
Now you can define the extract_paratext() function for extracting a random paragraph from a list of paragraph objects. The random paragraph will pass to the function as a paras argument, and return the chosen paragraph’s tokenized form that you’ll use later for sentence extraction:
...
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
def extract_paratext(paras):
"""Extracts text from <p> elements and returns a clean, tokenized random
paragraph."""
paras = [para.text_content() for para in paras if para.text_content()]
para = random.choice(paras)
return tokenizer.tokenize(para)
def scrape_coursera():
r = requests.get('https://blog.coursera.org', headers=HEADERS)
...
Next, you will define a function that will extract a random sentence of suitable length (between 60 and 210 characters) from the tokenized paragraph it gets as an argument, which you can name as para. If such a sentence is not discovered after ten attempts, the function returns None instead. Add the following highlighted code to define the extract_text() function:
...
def extract_paratext(paras):
...
return tokenizer.tokenize(para)
def extract_text(para):
"""Returns a sufficiently-large random text from a tokenized paragraph,
if such text exists. Otherwise, returns None."""
for _ in range(10):
text = random.choice(para)
if text and 60 < len(text) < 210:
return text
return None
def scrape_coursera():
r = requests.get('https://blog.coursera.org', headers=HEADERS)
...
Once you have defined these new helper functions, you can redefine the scrape_coursera() function to look as follows:
...
def extract_paratext():
for _ in range(10):<^>
text = random.choice(para)
...
def scrape_coursera():
"""Scrapes content from the Coursera blog."""
url = 'https://blog.coursera.org'
r = requests.get(url, headers=HEADERS)
tree = fromstring(r.content)
links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
for link in links:
r = requests.get(link, headers=HEADERS)
blog_tree = fromstring(r.content)
paras = blog_tree.xpath('//div[@class="entry-content"]/p')
para = extract_paratext(paras)
text = extract_text(para)
if not text:
continue
yield '"%s" %s' % (text, link)
Save and exit bot.py.
Here you’re using yield instead of return because, for iterating over the links, the scraper function will give you the tweet strings one-by-one in a sequential fashion. This means when you make a first call to the scraper sc defined as sc = scrape_coursera(), you will get the tweet string corresponding to the first link among the list of links that you computed within the scraper function. If you run the following code in the interpreter, you’ll get string_1 and string_2 as displayed below, if the links variable within scrape_coursera() holds a list that looks like ["https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference/", "https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/", ...].
- python3 -i bot.py
Instantiate the scraper and call it sc:
>>> sc = scrape_coursera()
It is now a generator; it generates or scrapes relevant content from Coursera, one at a time. You can access the scraped content one-by-one by calling next() over sc sequentially:
>>> string_1 = next(sc)
>>> string_2 = next(sc)
Now you can print the strings you’ve defined to display the scraped content:
>>> print(string_1)
"Other speakers include Priyanka Sharma, director of cloud native alliances at GitLab and Dan Kohn, executive director of the Cloud Native Computing Foundation." https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference/
>>>
>>> print(string_2)
"You can learn how to use the power of Python for data analysis with a series of courses covering fundamental theory and project-based learning." https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/
>>>
If you use return instead, you will not be able to obtain the strings one-by-one and in a sequence. If you simply replace the yield with return in scrape_coursera(), you’ll always get the string corresponding to the first blog post, instead of getting the first one in the first call, second one in the second call, and so on. You can modify the function to simply return a list of all the strings corresponding to all the links, but that is more memory intensive. Also, this kind of program could potentially make a lot of requests to Coursera’s servers within a short span of time if you want the entire list quickly. This could result in your bot getting temporarily banned from accessing a website. Therefore, yield is the best fit for a wide variety of scraping jobs, where you only need information scraped one-at-a-time.
Step 4 — Scraping Additional Content
In this step, you’ll build a scraper for thenewstack.io. The process is similar to what you’ve completed in the previous step, so this will be a quick overview.
Open the website in your browser and inspect the page source. You’ll find here that all blog sections are div elements of class normalstory-box.
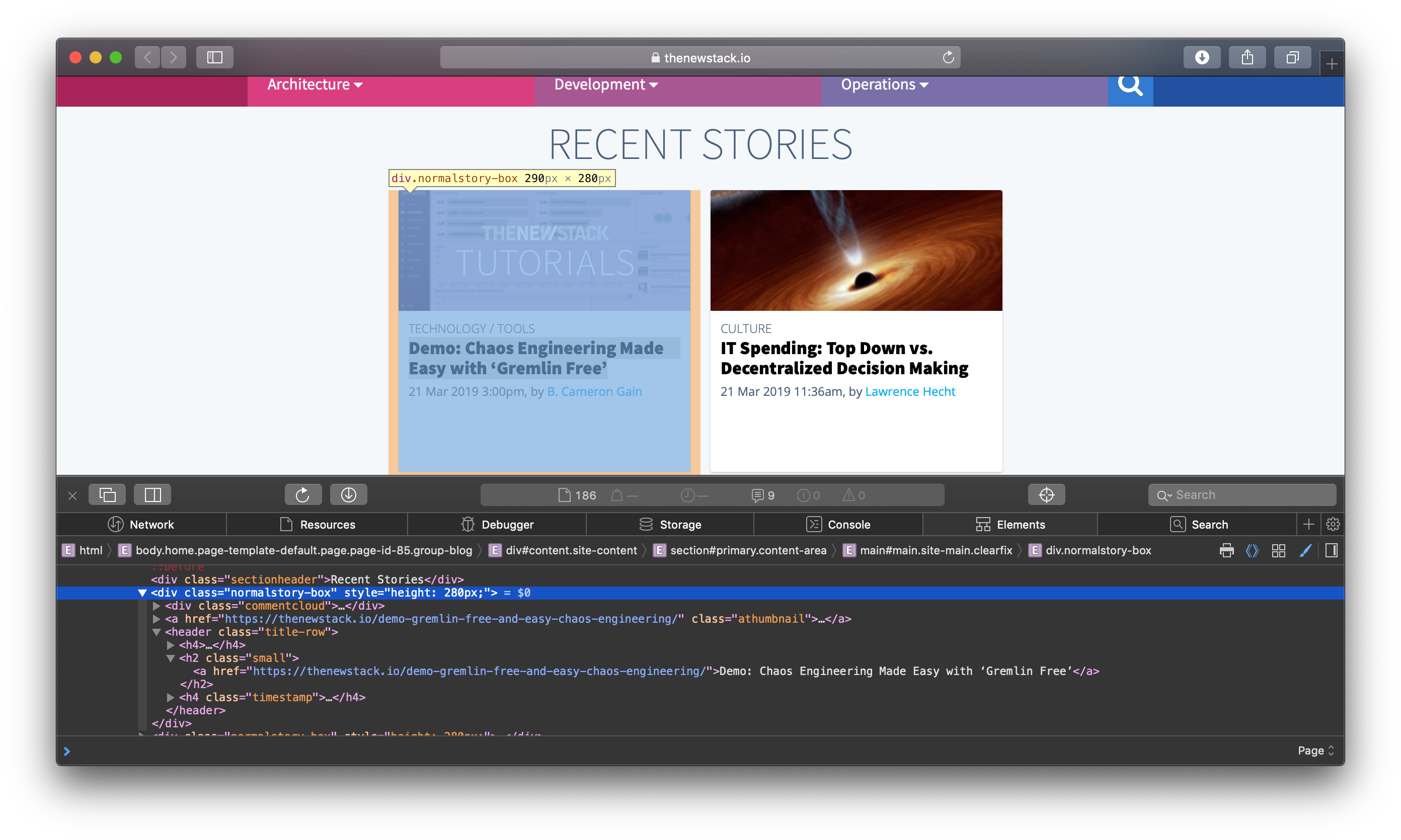
Now you’ll make a new scraper function named scrape_thenewstack() and make a GET request to thenewstack.io from within it. Next, extract the links to the blogs from these elements and then iterate over each link. Add the following code to achieve this:
...
def scrape_coursera():
...
yield '"%s" %s' % (text, link)
def scrape_thenewstack():
"""Scrapes news from thenewstack.io"""
r = requests.get('https://thenewstack.io', verify=False)
tree = fromstring(r.content)
links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
for link in links:
You use the verify=False flag because websites can sometimes have expired security certificates and it’s OK to access them if no sensitive data is involved, as is the case here. The verify=False flag tells the requests.get method to not verify the certificates and continue fetching data as usual. Otherwise, the method throws an error about expired security certificates.
You can now extract the paragraphs of the blog corresponding to each link, and use the extract_paratext() function you built in the previous step to pull out a random paragraph from the list of available paragraphs. Finally, extract a random sentence from this paragraph using the extract_text() function, and then yield it with the corresponding blog link. Add the following highlighted code to your file to accomplish these tasks:
...
def scrape_thenewstack():
...
links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
for link in links:
r = requests.get(link, verify=False)
tree = fromstring(r.content)
paras = tree.xpath('//div[@class="post-content"]/p')
para = extract_paratext(paras)
text = extract_text(para)
if not text:
continue
yield '"%s" %s' % (text, link)
You now have an idea of what a scraping process generally encompasses. You can now build your own, custom scrapers that can, for example, scrape the images in blog posts instead of random quotes. For that, you can look for the relevant <img> tags. Once you have the right path for tags, which serve as their identifiers, you can access the information within tags using the names of corresponding attributes. For example, in the case of scraping images, you can access the links of images using their src attributes.
At this point, you’ve built two scraper functions for scraping content from two different websites, and you’ve also built two helper functions to reuse functionalities that are common across the two scrapers. Now that your bot knows how to tweet and what to tweet, you’ll write the code to tweet the scraped content.
Step 5 — Tweeting the Scraped Content
In this step, you’ll extend the bot to scrape content from the two websites and tweet it via your Twitter account. More precisely, you want it to tweet content from the two websites alternately, and at regular intervals of ten minutes, for an indefinite period of time. Thus, you will use an infinite while loop to implement the desired functionality. You’ll do this as part of a main() function, which will implement the core high-level process that you’ll want your bot to follow:
...
def scrape_thenewstack():
...
yield '"%s" %s' % (text, link)
def main():
"""Encompasses the main loop of the bot."""
print('---Bot started---\n')
news_funcs = ['scrape_coursera', 'scrape_thenewstack']
news_iterators = []
for func in news_funcs:
news_iterators.append(globals()[func]())
while True:
for i, iterator in enumerate(news_iterators):
try:
tweet = next(iterator)
t.statuses.update(status=tweet)
print(tweet, end='\n\n')
time.sleep(600)
except StopIteration:
news_iterators[i] = globals()[newsfuncs[i]]()
You first create a list of the names of the scraping functions you defined earlier, and call it as news_funcs. Then you create an empty list that will hold the actual scraper functions, and name that list as news_iterators. You then populate it by going through each name in the news_funcs list and appending the corresponding iterator in the news_iterators list. You’re using Python’s built-in globals() function. This returns a dictionary that maps variable names to actual variables within your script. An iterator is what you get when you call a scraper function: for example, if you write coursera_iterator = scrape_coursera(), then coursera_iterator will be an iterator on which you can invoke next() calls. Each next() call will return a string containing a quote and its corresponding link, exactly as defined in the scrape_coursera() function’s yield statement. Each next() call goes through one iteration of the for loop in the scrape_coursera() function. Thus, you can only make as many next() calls as there are blog links in the scrape_coursera() function. Once that number exceeds, a StopIteration exception will be raised.
Once both the iterators populate the news_iterators list, the main while loop starts. Within it, you have a for loop that goes through each iterator and tries to obtain the content to be tweeted. After obtaining the content, your bot tweets it and then sleeps for ten minutes. If the iterator has no more content to offer, a StopIteration exception is raised, upon which you refresh that iterator by re-instantiating it, to check for the availability of newer content on the source website. Then you move on to the next iterator, if available. Otherwise, if execution reaches the end of the iterators list, you restart from the beginning and tweet the next available content. This makes your bot tweet content alternately from the two scrapers for as long as you want.
All that remains now is to make a call to the main() function. You do this when the script is called directly by the Python interpreter:
...
def main():
print('---Bot started---\n')<^>
news_funcs = ['scrape_coursera', 'scrape_thenewstack']
...
if __name__ == "__main__":
main()
The following is a completed version of the bot.py script. You can also view the script on this GitHub repository.
"""Main bot script - bot.py
For the DigitalOcean Tutorial.
"""
import random
import time
from lxml.html import fromstring
import nltk
nltk.download('punkt')
import requests
from twitter import OAuth, Twitter
import credentials
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
oauth = OAuth(
credentials.ACCESS_TOKEN,
credentials.ACCESS_SECRET,
credentials.CONSUMER_KEY,
credentials.CONSUMER_SECRET
)
t = Twitter(auth=oauth)
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
}
def extract_paratext(paras):
"""Extracts text from <p> elements and returns a clean, tokenized random
paragraph."""
paras = [para.text_content() for para in paras if para.text_content()]
para = random.choice(paras)
return tokenizer.tokenize(para)
def extract_text(para):
"""Returns a sufficiently-large random text from a tokenized paragraph,
if such text exists. Otherwise, returns None."""
for _ in range(10):
text = random.choice(para)
if text and 60 < len(text) < 210:
return text
return None
def scrape_coursera():
"""Scrapes content from the Coursera blog."""
url = 'https://blog.coursera.org'
r = requests.get(url, headers=HEADERS)
tree = fromstring(r.content)
links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
for link in links:
r = requests.get(link, headers=HEADERS)
blog_tree = fromstring(r.content)
paras = blog_tree.xpath('//div[@class="entry-content"]/p')
para = extract_paratext(paras)
text = extract_text(para)
if not text:
continue
yield '"%s" %s' % (text, link)
def scrape_thenewstack():
"""Scrapes news from thenewstack.io"""
r = requests.get('https://thenewstack.io', verify=False)
tree = fromstring(r.content)
links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
for link in links:
r = requests.get(link, verify=False)
tree = fromstring(r.content)
paras = tree.xpath('//div[@class="post-content"]/p')
para = extract_paratext(paras)
text = extract_text(para)
if not text:
continue
yield '"%s" %s' % (text, link)
def main():
"""Encompasses the main loop of the bot."""
print('Bot started.')
news_funcs = ['scrape_coursera', 'scrape_thenewstack']
news_iterators = []
for func in news_funcs:
news_iterators.append(globals()[func]())
while True:
for i, iterator in enumerate(news_iterators):
try:
tweet = next(iterator)
t.statuses.update(status=tweet)
print(tweet, end='\n')
time.sleep(600)
except StopIteration:
news_iterators[i] = globals()[newsfuncs[i]]()
if __name__ == "__main__":
main()
Save and exit bot.py.
The following is a sample execution of bot.py:
- python3 bot.py
You will receive output showing the content that your bot has scraped, in a similar format to the following:
Output[nltk_data] Downloading package punkt to /Users/binaryboy/nltk_data...
[nltk_data] Package punkt is already up-to-date!
---Bot started---
"Take the first step toward your career goals by building new skills." https://blog.coursera.org/career-stories-from-inside-coursera/
"Other speakers include Priyanka Sharma, director of cloud native alliances at GitLab and Dan Kohn, executive director of the Cloud Native Computing Foundation." https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference/
"You can learn how to use the power of Python for data analysis with a series of courses covering fundamental theory and project-based learning." https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/
"“Real-user monitoring is really about trying to understand the underlying reasons, so you know, ‘who do I actually want to fly with?" https://thenewstack.io/how-raygun-co-founder-and-ceo-spun-gold-out-of-monitoring-agony/
After a sample run of your bot, you’ll see a full timeline of programmatic tweets posted by your bot on your Twitter page. It will look something like the following:
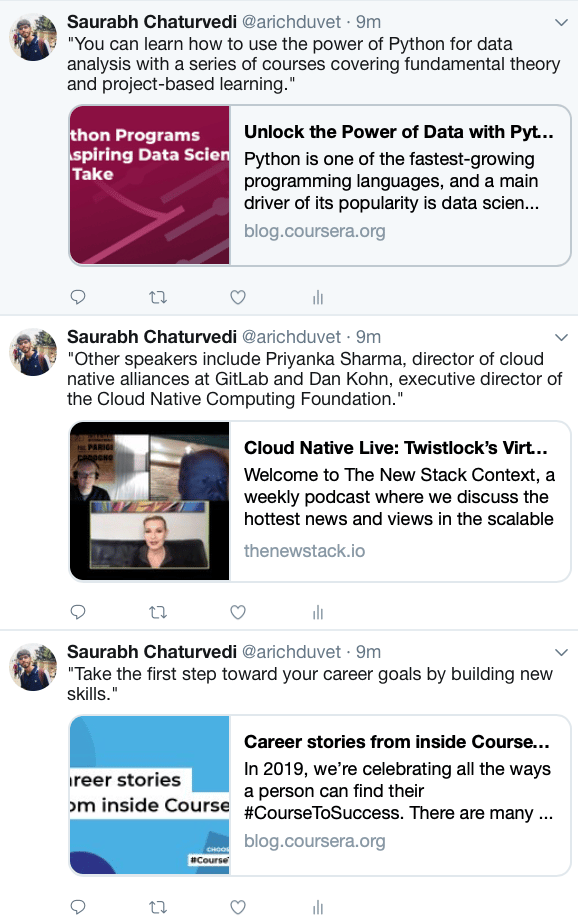
As you can see, the bot is tweeting the scraped blog links with random quotes from each blog as highlights. This feed is now an information feed with tweets alternating between blog quotes from Coursera and thenewstack.io. You’ve built a bot that aggregates content from the web and posts it on Twitter. You can now broaden the scope of this bot as per your wish by adding more scrapers for different websites, and the bot will tweet content coming from all the scrapers in a round-robin fashion, and in your desired time intervals.
Conclusion
In this tutorial you built a basic Twitter bot with Python and scraped some content from the web for your bot to tweet. There are many bot ideas to try; you could also implement your own ideas for a bot’s utility. You can combine the versatile functionalities offered by Twitter’s API and create something more complex. For a version of a more sophisticated Twitter bot, check out chirps, a Twitter bot framework that uses some advanced concepts like multithreading to make the bot do multiple things simultaneously. There are also some fun-idea bots, like misheardly. There are no limits on the creativity one can use while building Twitter bots. Finding the right API endpoints to hit for your bot’s implementation is essential.
Finally, bot etiquette or (“botiquette”) is important to keep in mind when building your next bot. For example, if your bot incorporates retweeting, make all tweets’ text pass through a filter to detect abusive language before retweeting them. You can implement such features using regular expressions and natural language processing. Also, while looking for sources to scrape, follow your judgment and avoid ones that spread misinformation. To read more about botiquette, you can visit this blog post by Joe Mayo on the topic.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Python and C++ Programmer
Former Senior Technical Editor at DigitalOcean, with a strong focus on DevOps and System Administration content. Areas of expertise include Terraform, PyTorch, Python, and Django.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
it shows error Please Help Me
warnings.warn(
Traceback (most recent call last):
File "bot.py", line 113, in main
tweet = next(iterator)
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "bot.py", line 121, in <module>
main()
File "bot.py", line 118, in main
news_iterators[i] = globals()[newsfuncs[i]]()
NameError: name 'newsfuncs' is not defined
Hey Saurabh Chaturvedi, This is a great tutorial on web scraping and Twitter automation! Python makes it so much easier to gather and share insights. If anyone needs historical Twitter data for research or trend analysis, TrackMyHashtag is a handy tool to retrieve past tweets and analyze engagement patterns!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
