By Mateusz Papiernik and Mark Drake

The author selected the Open Internet/Free Speech Fund to receive a donation as part of the Write for DOnations program.
Introduction
Database sharding is the process of splitting up records that would normally be held in the same table or collection and distributing them across multiple machines, known as shards. Sharding is especially useful in cases where you’re working with large amounts of data, as it allows you to scale your base horizontally by adding more machines that can function as new shards.
In this tutorial, you’ll learn how to deploy a sharded MongoDB cluster with two shards. This guide will also outline how to choose an appropriate shard key as well as how to verify whether your MongoDB documents are being split up across shards correctly and evenly.
Warning: The goal of this guide is to outline how sharding works in MongoDB. To that end, it demonstrates how to get a sharded cluster set up and running quickly for use in a development environment. Upon completing this tutorial you’ll have a functioning sharded cluster, but it will not have any security features enabled.
Additionally, MongoDB recommends that a sharded cluster’s shard servers and config server all be deployed as replica sets with at least three members. Again, though, in order to get a sharded cluster up and running quickly, this guide outlines how to deploy these components as single-node replica sets.
For these reasons, this setup is not considered secure and should not be used in production environments. If you plan on using a sharded cluster in a production environment, we strongly encourage you to review the official MongoDB documentation on Internal/Membership Authentication as well as our tutorial on How To Configure a MongoDB Replica Set on Ubuntu 20.04.
Prerequisites
To follow this tutorial, you will need:
- Four separate servers. Each of these should have a regular, non-root user with
sudoprivileges and a firewall configured with UFW. This tutorial was validated using four servers running Ubuntu 20.04, and you can prepare your servers by following this initial server setup tutorial for Ubuntu 20.04 on each of them. - MongoDB installed on each of your servers. To set this up, follow our tutorial on How to Install MongoDB on Ubuntu 20.04 for each server.
- All four of your servers configured with remote access enabled for each of the other instances. To set this up, follow our tutorial on How to Configure Remote Access for MongoDB on Ubuntu 20.04. As you follow this guide, make sure that each server has the other three servers’ IP addresses added as trusted IP addresses to allow for open communication between all of the servers.
Note: The linked tutorials on how to configure your server, install MongoDB, and then allow remote access to MongoDB all refer to Ubuntu 20.04. This tutorial concentrates on MongoDB itself, not the underlying operating system. It will generally work with any MongoDB installation regardless of the operating system as long as each of the four servers are configured as outlined previously.
For clarity, this tutorial will refer to the four servers as follows:
- mongo-config, which will function as the cluster’s config server.
- mongo-shard1 and mongo-shard2, which will serve as shard servers where the data will actually be distributed.
- mongo-router, which will run a
mongosinstance and function as the shard cluster’s query router.
For more details on what these roles are and how they function within a sharded MongoDB cluster, please read the following section on Understanding MongoDB’s Sharding Topology.
Commands that must be executed on mongo-config will have a blue background, like this:
-
Commands that must be executed on mongo-shard1 will have a red background:
-
Commands run on mongo-shard2 will have a green background:
-
And the mongo-router server’s commands will have a violet background:
-
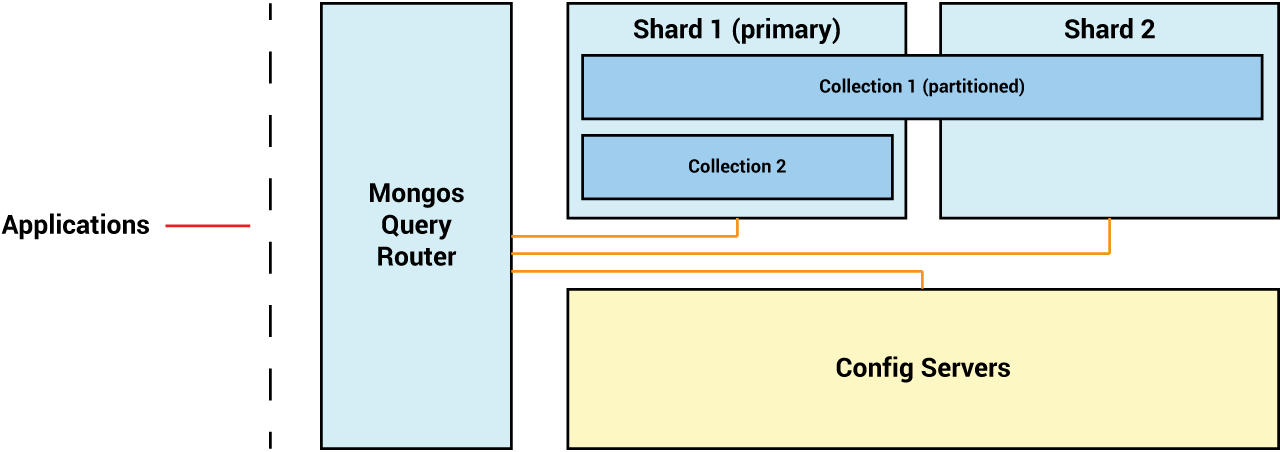
Understanding MongoDB’s Sharding Topology
When working with a standalone MongoDB database server, you connect to that instance and use it to directly manage your data. In an unsharded replica set, you connect to the cluster’s primary member, and any changes you make to the data there are automatically carried over to the set’s secondary members. Sharded MongoDB clusters, though, are slightly more complex.
Sharding is meant to help with horizontal scaling, also known as scaling out, since it splits up records from one data set across multiple machines. If the workload becomes too great for the shards in your cluster, you can scale out your database by adding another separate shard to take on some of the work. This contrasts with vertical scaling, also known as scaling up, which involves migrating one’s resources to larger or more powerful hardware.
Because data is physically divided into multiple database nodes in a sharded database architecture, some documents will be available only on one node, while others will reside on another server. If you decided to connect to a particular instance to query the data, only a subset of the data would be available to you. Additionally, if you were to directly change any data held on one shard, you run the risk of creating inconsistency between your shards.
To mitigate these risks, sharded clusters in MongoDB are made up of three separate components:
- Shard servers are individual MongoDB instances used to store a subset of a larger collection of data. Every shard server must always be deployed as a replica set. There must be a minimum of one shard in a sharded cluster, but to gain any benefits from sharding you will need at least two.
- The cluster’s config server is a MongoDB instance that stores metadata and configuration settings for the sharded cluster. The cluster uses this metadata for setup and management purposes. Like shard servers, the config server must be deployed as a replica set to ensure that this metadata remains highly available.
mongosis a special type of MongoDB instance that serves as a query router.mongosacts as a proxy between client applications and the sharded cluster, and is responsible for deciding where to direct a given query. Every application connection goes through a query router in a sharded cluster, thereby hiding the complexity of the configuration from the application.
Because sharding in MongoDB is done at a collection level, a single database can contain a mixture of sharded and unsharded collections. Although sharded collections are partitioned and distributed across the multiple shards of the cluster, one shard is always elected as a primary shard. Unsharded collections are stored in their entirety on this primary shard.
Since every application connection must go through the mongos instance, the mongos query router is what’s responsible for making all data consistently available and distributed across individual shards.
Step 1 — Setting Up a MongoDB Config Server
After completing the prerequisites, you’ll have four MongoDB installations running on four separate servers. In this step, you’ll convert one of these instances — mongo-config — into a replica set that you can use for testing or development purposes. You’ll also set this MongoDB instance up with features that will allow it to serve as a config server for a sharded cluster.
Warning: Starting with MongoDB 3.6, both individual shards and config servers must be deployed as replica sets. It’s recommended to always have replica sets with at least three members in a production environment. Using replica sets with three or more members is helpful for keeping your data available and secure, but it also substantially increases the complexity of the sharded architecture. However, you can use single-node replica sets for local development, as this guide outlines.
To reiterate the warning given previously in the introduction, this guide outlines how to get a sharded cluster up and running quickly. Hence, it outlines how to deploy a sharded cluster using shard servers and a config server that each consist of a single-node replica set. Because of this, and because it will not have any security features enabled, this setup is not secure and should not be used in a production environment.
On mongo-config, open the MongoDB configuration file in your preferred text editor. Here, we’ll use nano:
- sudo nano /etc/mongod.conf
Find the configuration section with lines that read #replication: and #sharding: towards the bottom of the file:
. . .
#replication:
#sharding:
Uncomment the #replication: line by removing the pound sign (#). Then add a replSetName directive below the replication: line, followed by a name MongoDB will use to identify the replica set. Because you’re setting up this MongoDB instance as a replica set that will function as a config server, this guide will use the name config:
. . .
replication:
replSetName: "config"
#sharding:
. . .
Note that there are two spaces preceding the new replSetName directive and that its config value is wrapped in quotation marks. This syntax is required for the configuration to be read properly.
Next, uncomment the #sharding: line as well. On the next line after that, add a clusterRole directive with a value of configsvr:
. . .
replication:
replSetName: "config"
sharding:
clusterRole: configsvr
. . .
The clusterRole directive tells MongoDB that this server will be a part of the sharded cluster and will take the role of a config server (as indicated by the configsvr value). Again, be sure to precede this line with two spaces.
Note: When both the replication and security lines are enabled in the mongod.conf file, MongoDB also requires you to configure some means of authentication other than password authentication, such as keyfile authentication or setting up x.509 certificates. If you followed our How To Secure MongoDB on Ubuntu 20.04 tutorial and enabled authentication on your MongoDB instance, you will only have password authentication enabled.
Rather than setting up more advanced security measures, for the purposes of this tutorial it would be prudent to disable the security block in your mongod.conf file. Do so by commenting out every line in the security block with a pound sign:
. . .
#security:
# authorization: enabled
. . .
As long as you only plan to use this database to practice sharding or other testing purposes, this won’t present a security risk. However, if you plan to use this MongoDB instance to store any sensitive data in the future, be sure to uncomment these lines to re-enable authentication.
After updating these two sections of the file, save and close the file. If you used nano, you can do so by pressing CTRL + X, Y, and then ENTER.
Then, restart the mongod service:
- sudo systemctl restart mongod
With that, you’ve enabled replication for the server. However, the MongoDB instance isn’t yet replicating any data. You’ll need to start replication through the MongoDB shell, so open it up with the following command:
- mongo
From the MongoDB shell prompt, run the following command to initiate this replica set:
- rs.initiate()
This command will start the replication with the default configuration inferred by the MongoDB server. When setting up a replica set that consists of multiple separate servers, as would be the case if you were deploying a production-ready replica set, you would pass a document to the rs.initiate() method that describes the configuration for the new replica set. However, because this guide outlines how to deploy a sharded cluster using a config server and shard servers that each consist of a single node, you don’t need to pass any arguments to this method.
MongoDB will automatically read the replica set name and its role in a sharded cluster from the running configuration. If this method returns "ok" : 1 in its output, it means the replica set was started successfully:
Output{
"info2" : "no configuration specified. Using a default configuration for the set",
. . .
"ok" : 1,
. . .
}
Assuming this is the case, your MongoDB shell prompt will change to indicate that the instance the shell is connected to what is now a member of the rs0 replica set:
-
The first part of this new prompt will be the name of the replica set you configured previously.
Note that the second part this example prompt shows that this MongoDB instance is a secondary member of the replica set. This is to be expected, as there is usually a gap between the time when a replica set is initiated and the time when one of its members becomes the primary member.
If you were to run a command or even just press ENTER after waiting a few moments, the prompt would update to reflect that you’re connected to the replica set’s primary member:
-
You can verify that the replica set was configured properly by executing the following command in the MongoDB shell:
- rs.status()
This will return a lot of output about the replica set configuration, but a few keys are especially important:
Output{
. . .
"set" : "config",
. . .
"configsvr" : true,
"ok" : 1,
. . .
}
The set key shows the replica set name, which is config in this example. The configsvr key indicates whether it’s a config server replica set in a sharded cluster, in this case showing true. Lastly, the ok flag has a value of 1, meaning the replica set is working correctly.
In this step, you’ve configured your first replica set for the config servers in sharded clusters. In the next step, you’ll follow through a similar configuration for the two individual shards.
Step 2 — Configuring Shard Server Replica Sets
After completing the previous step, you will have a fully configured replica set that can function as the config server for a sharded cluster. In this step, you’ll convert the mongo-shard1 and mongo-shard2 instances into replica sets as well. Rather than setting them up as config servers, though, you will configure them to function as the actual shards within your sharded cluster.
In order to set this up, you’ll need to make a few changes to both mongo-shard1 and mongo-shard2’s configuration files. Because you’re setting up two separate replica sets, though, each configuration will use different replica set names.
On both mongo-shard1 and mongo-shard2, open the MongoDB configuration file in your preferred text editor:
- sudo nano /etc/mongod.conf
- sudo nano /etc/mongod.conf
Find the configuration section with lines that read #replication: and #sharding: towards the bottom of the files. Again, these lines will be commented out in both files by default:
#replication:
#sharding:
In both configuration files, uncomment the #replication: line by removing the pound sign (#). Then, add a replSetName directive below the replication: line, followed by the name MongoDB will use to identify the replica set. These examples use the name shard1 for the replica set on mongo-shard1 and shard2 for the set on mongo-shard2:
. . .
replication:
replSetName: "shard1"
#sharding:
. . .
. . .
replication:
replSetName: "shard2"
#sharding:
. . .
Then uncomment the #sharding: line and add a clusterRole directive below that line in each configuration file. In both files, set the clusterRole directive value to shardsvr. This tells the respective MongoDB instances that these servers will function as shards.
. . .
replication:
replSetName: "shard1"
sharding:
clusterRole: shardsvr
. . .
. . .
replication:
replSetName: "shard2"
sharding:
clusterRole: shardsvr
. . .
After updating these two sections of the files, save and close the files. Then, restart the mongod service by issuing the following command on both servers:
- sudo systemctl restart mongod
- sudo systemctl restart mongod
With that, you’ve enabled replication for the two shards. As with the config server you set up in the previous step, these replica sets must also be initiated through the MongoDB shell before they can be used. Open the MongoDB shells on both shard servers with the mongo command:
- mongo
- mongo
To reiterate, this guide outlines how to deploy a sharded cluster with a config server and two shard servers, all of which are made up of single-node replica sets. This kind of setup is useful for testing and outlining how sharding works, but it is not suitable for a production environment.
Because you’re setting up these MongoDB instances to function as single-node replica sets, you can initiate replication on both shard servers by executing the rs.initiate() method without any further arguments:
- rs.initiate()
- rs.initiate()
These will start replication on each MongoDB instance using the default replica set configuration. If these commands return "ok" : 1 in their output, it means the initialization was successful:
Output{
"info2" : "no configuration specified. Using a default configuration for the set",
. . .
"ok" : 1,
. . .
}
Output{
"info2" : "no configuration specified. Using a default configuration for the set",
. . .
"ok" : 1,
. . .
}
As with the config server replica set, each of these shard servers will be elected as a primary member after only a few moments. Although their prompts may at first read SECONDARY>, if you press the ENTER key in the shell after a few moments the prompts will change to confirm that each server is the primary instance of their respective replica set. The prompts on the two shards will differ only in name, with one reading shard1:PRIMARY> and the other shard2:PRIMARY>.
You can verify that each replica set was configured properly by executing the rs.status() method in both MongoDB shells. First, check wither the mongo-shard1 replica set was set up correctly:
- rs.status()
If this method’s output includes "ok" : 1, it means the replica set is functioning properly:
Output{
. . .
"set" : "shard1",
. . .
"ok" : 1,
. . .
}
Executing the same command on mongo-shard2 will show a different replica set name but otherwise will be nearly identical:
- rs.status()
Output{
. . .
"set" : "shard2",
. . .
"ok" : 1,
. . .
}
With that, you’ve successfully configured both mongo-shard1 and mongo-shard2 as single-node replica sets. At this point, though, neither these two replica sets nor the config server replica set you created in the previous step are aware of each other. In the next step, you’ll run a query router and connect all of them together.
Step 3 — Running mongos and Adding Shards to the Cluster
mongos and Adding Shards to the ClusterThe three replica sets you’ve configured so far, one config server and two individual shards, are currently running but are not yet part of a sharded cluster. To connect these components as parts of a sharded cluster, you’ll need one more tool: a mongos query router. This will be responsible for communicating with the config server and managing the shard servers.
You’ll use your fourth and final MongoDB server — mongo-router — to run mongos and function as your sharded cluster’s query router. The query router daemon is included as part of the standard MongoDB installation, but is not enabled by default and must be run separately.
First, connect to the mongo-router server and stop the MongoDB database service from running:
- sudo systemctl stop mongod
Because this server will not act as a database itself, disable the mongod service from starting whenever the server boots up:
- sudo systemctl disable mongod
Now, run mongos and connect it to the config server replica set with a command like the following:
- mongos --configdb config/mongo_config_ip:27017
The first part of this command’s connection string, config, is the name of the replica you defined earlier. Be sure to change this, if different, and update mongo_config_ip with the IP address of your mongo-config server.
By default, mongos runs in the foreground and binds only to the local interface, thereby disallowing remote connections. With no additional security configured apart from firewall settings limiting traffic between all of your servers, this is a sound safety measure.
Note: In MongoDB, it’s customary to differentiate the ports on which the config server and shard servers run, with 27019 being commonly used for config servers replica set and 27018 used for shards. To keep things simple, this guide did not change the port that any of the MongoDB instances in this cluster are running on. Thus, all replica sets are running on the default port of 27017.
The previous mongos command will produce a verbose and detailed output in a format similar to system logs. At the beginning, you’ll find a message like this:
Output{"t":{"$date":"2021-11-07T15:58:36.278Z"},"s":"W", "c":"SHARDING", "id":24132, "ctx":"main","msg":"Running a sharded cluster with fewer than 3 config servers should only be done for testing purposes and is not recommended for production."}
. . .
This means the query router connected to the config server replica set correctly and noticed it’s built with only a single node, a configuration not recommended for production environments.
Note: Although running in the foreground like this is its default behavior, mongos is typically run as a daemon using a process like systemd.
Running mongos as a system service is beyond the scope of this tutorial, but we encourage you to learn more about using and administering the mongos query router by reading the official documentation.
Now you can add the shards you configured previously to the sharded cluster. Because mongos is running in the foreground, open another shell window connected to mongo-router. From this new window, open up the MongoDB shell:
- mongo
This command will open the MongoDB shell connected to the local MongoDB instance, which is not a MongoDB server but a running mongos query router. Your prompt will change to indicate this by reading mongos> instead of the MongoDB shell’s usual >.
You can verify that the query router is connected to the config server by running the sh.status() method:
- sh.status()
This command returns the current status of the sharded cluster. At this point, it will show an empty list of connected shards in the shards key:
Output--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("6187ea2e3d82d39f10f37ea7")
}
shards:
active mongoses:
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
. . .
To add the first shard to the cluster, execute the following command. In this example, shard1 is the replica set name of the first shard, and mongo_shard1_ip is the IP address of the server on which that shard, mongo-shard1, is running:
- sh.addShard("shard1/mongo_shard1_ip:27017")
This command will return a success message:
Output{
"shardAdded" : "shard1",
"ok" : 1,
"operationTime" : Timestamp(1636301581, 6),
"$clusterTime" : {
"clusterTime" : Timestamp(1636301581, 6),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
Follow that by adding the second shard:
- sh.addShard("shard2/mongo_shard2_ip:27017")
Notice that not only the IP address in this command is different, but the replica set name is different as well. The command will return a success message:
Output{
"shardAdded" : "shard2",
"ok" : 1,
"operationTime" : Timestamp(1639724738, 6),
"$clusterTime" : {
"clusterTime" : Timestamp(1639724738, 6),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
You can check that both shards have been properly added by issuing the sh.status() command again:
- sh.status()
Output--- Sharding Status ---
sharding version: {
"_id" : 1,
"minCompatibleVersion" : 5,
"currentVersion" : 6,
"clusterId" : ObjectId("6187ea2e3d82d39f10f37ea7")
}
shards:
{ "_id" : "shard1", "host" : "shard1/mongo_shard1_ip:27017", "state" : 1 }
{ "_id" : "shard2", "host" : "shard2/mongo_shard2_ip:27017", "state" : 1 }
active mongoses:
"4.4.10" : 1
autosplit:
Currently enabled: yes
balancer:
Currently enabled: yes
Currently running: no
Failed balancer rounds in last 5 attempts: 0
Migration Results for the last 24 hours:
No recent migrations
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
. . .
With that, you have a fully working sharded cluster consisting of two up and running shards. In the next step, you’ll create a new database, enable sharding for the database, and begin partitioning data in a collection.
Step 4 — Partitioning Collection Data
One shard within every sharded MongoDB cluster will be elected to be the cluster’s primary shard. In addition to the partitioned data stored across every shard in the cluster, the primary shard is also responsible for storing any non-partitioned data.
At this point, you can freely use the mongos query router to work with databases, documents, and collections just like you would with a typical unsharded database. However, with no further setup, any data you add to the cluster will end up being stored only on the primary shard; it will not be automatically partitioned, and you won’t experience any of the benefits sharding provides.
In order to use your sharded MongoDB cluster to its fullest potential, you must enabling sharding for a database within the cluster. A MongoDB database can only contain sharded collections if it has sharding enabled.
To better understand MongoDB’s behavior as it partitions data, you’ll need a set of documents you can work with. This guide will use a collection of documents representing a few of the most populated cities in the world. As an example, the following sample document represents Tokyo:
{
"name": "Tokyo",
"country": "Japan",
"continent": "Asia",
"population": 37.400
}
You’ll store these documents in a database called populations and a collection called cities.
You can enable sharding for a database before you explicitly create it. To enable sharding for the populations database, run the following enableSharding() method:
- sh.enableSharding("populations")
The command will return a success message:
Output{
. . .
"ok" : 1,
. . .
}
Now that the database is configured to allow partitioning, you can enable partitioning for the cities collection.
MongoDB provides two ways to shard collections and determine which documents will be stored on which shard: ranged sharding and hashed sharding. This guide focuses on how to implement hashed sharding, in which MongoDB maintains an automated hashed index on a field that has been selected to be the cluster’s shard key. This helps to achieve an even distribution of documents. If you’d like to learn about ranged sharding in MongoDB, please refer to the official documentation.
When implementing a hash-based sharding strategy, it’s the responsibility of the database administrator to choose an appropriate shard key. A poorly chosen shard key has the potential to mitigate many of benefits one might gain from sharding.
In MongoDB, a document field that would function well as a shard key should follow these principles:
- The chosen field should be of high cardinality, meaning that it can have many possible values. Every document added to the collection will always end up being stored on a single shard, so if the field chosen as the shard key will have only a few possible values, adding more shards to the cluster will not benefit performance. Considering the example
populationsdatabase, thecontinentfield would not be a good shard key since it can only contain a few possible values. - The shard key should have a low frequency of duplicate values. If the majority of documents share duplicate values for the field used as the shard key, it’s likely that some shards will be used to store more data than others. The more even the distribution of values in the sharded key across the entire collection, the better.
- The shard key should facilitate queries. For example, a field that’s frequently used as a query filter would be a good choice for a shard key. In a sharded cluster, the query router uses a single shard to return a query result only if the query contains the shard key. Otherwise, the query will be broadcast to all shards for evaluation, even though the returned documents will come from a single shard. Thus, the
populationfield would not be the best key, as it’s unlikely the majority of queries would involve filtering by the exact population value.
For the example data used in this guide, the country name field would be a good choice for the cluster’s shard key, since it has the highest cardinality of all fields that will likely be frequently used in filter queries.
Partition the cities collection — which hasn’t yet been created — with the country field as its shard key by running the following shardCollection() method:
- sh.shardCollection("populations.cities", { "country": "hashed" })
The first part of this command refers to the cities collection in the populations database, while the second part selects country as the shard key using the hashed partition method.
The command will return a success message:
Output{
"collectionsharded" : "populations.cities",
"collectionUUID" : UUID("03823afb-923b-4cd0-8923-75540f33f07d"),
"ok" : 1,
. . .
}
Now you can insert some sample documents to the sharded cluster. First, switch to the populations database:
- use populations
Then insert 20 sample documents with the following insertMany command:
- db.cities.insertMany([
- {"name": "Seoul", "country": "South Korea", "continent": "Asia", "population": 25.674 },
- {"name": "Mumbai", "country": "India", "continent": "Asia", "population": 19.980 },
- {"name": "Lagos", "country": "Nigeria", "continent": "Africa", "population": 13.463 },
- {"name": "Beijing", "country": "China", "continent": "Asia", "population": 19.618 },
- {"name": "Shanghai", "country": "China", "continent": "Asia", "population": 25.582 },
- {"name": "Osaka", "country": "Japan", "continent": "Asia", "population": 19.281 },
- {"name": "Cairo", "country": "Egypt", "continent": "Africa", "population": 20.076 },
- {"name": "Tokyo", "country": "Japan", "continent": "Asia", "population": 37.400 },
- {"name": "Karachi", "country": "Pakistan", "continent": "Asia", "population": 15.400 },
- {"name": "Dhaka", "country": "Bangladesh", "continent": "Asia", "population": 19.578 },
- {"name": "Rio de Janeiro", "country": "Brazil", "continent": "South America", "population": 13.293 },
- {"name": "São Paulo", "country": "Brazil", "continent": "South America", "population": 21.650 },
- {"name": "Mexico City", "country": "Mexico", "continent": "North America", "population": 21.581 },
- {"name": "Delhi", "country": "India", "continent": "Asia", "population": 28.514 },
- {"name": "Buenos Aires", "country": "Argentina", "continent": "South America", "population": 14.967 },
- {"name": "Kolkata", "country": "India", "continent": "Asia", "population": 14.681 },
- {"name": "New York", "country": "United States", "continent": "North America", "population": 18.819 },
- {"name": "Manila", "country": "Philippines", "continent": "Asia", "population": 13.482 },
- {"name": "Chongqing", "country": "China", "continent": "Asia", "population": 14.838 },
- {"name": "Istanbul", "country": "Turkey", "continent": "Europe", "population": 14.751 }
- ])
The output will be similar to the typical MongoDB output since, from the user’s perspective, the sharded cluster behaves like a normal MongoDB database:
Output{
"acknowledged" : true,
"insertedIds" : [
ObjectId("61880330754a281b83525a9b"),
ObjectId("61880330754a281b83525a9c"),
ObjectId("61880330754a281b83525a9d"),
ObjectId("61880330754a281b83525a9e"),
ObjectId("61880330754a281b83525a9f"),
ObjectId("61880330754a281b83525aa0"),
ObjectId("61880330754a281b83525aa1"),
ObjectId("61880330754a281b83525aa2"),
ObjectId("61880330754a281b83525aa3"),
ObjectId("61880330754a281b83525aa4"),
ObjectId("61880330754a281b83525aa5"),
ObjectId("61880330754a281b83525aa6"),
ObjectId("61880330754a281b83525aa7"),
ObjectId("61880330754a281b83525aa8"),
ObjectId("61880330754a281b83525aa9"),
ObjectId("61880330754a281b83525aaa"),
ObjectId("61880330754a281b83525aab"),
ObjectId("61880330754a281b83525aac"),
ObjectId("61880330754a281b83525aad"),
ObjectId("61880330754a281b83525aae")
]
}
Under the hood, however, MongoDB distributed the documents across the sharded nodes.
You can access information about how the data was distributed across your shards with the getShardDistribution() method:
- db.cities.getShardDistribution()
This method’s output provides statistics for every shard that is part of the cluster:
OutputShard shard2 at shard2/mongo_shard2_ip:27017
data : 943B docs : 9 chunks : 2
estimated data per chunk : 471B
estimated docs per chunk : 4
Shard shard1 at shard1/mongo_shard1_ip:27017
data : 1KiB docs : 11 chunks : 2
estimated data per chunk : 567B
estimated docs per chunk : 5
Totals
data : 2KiB docs : 20 chunks : 4
Shard shard2 contains 45.4% data, 45% docs in cluster, avg obj size on shard : 104B
Shard shard1 contains 54.59% data, 55% docs in cluster, avg obj size on shard : 103B
This output indicates that the automated hashing strategy on the country field resulted in a mostly even distribution across two shards.
You have now configured a fully working sharded cluster and inserted data that has been automatically partitioned across multiple shards. In the next step, you’ll learn how to monitor shard usage when executing queries.
Step 5 — Analyzing Shard Usage
Sharding is used to scale the performance of the database system and, as such, works best if it’s used efficiently to support database queries. If most of your queries to the database need to scan every shard in the cluster in order to be executed, any benefits of sharding would be lost in the system’s increased complexity.
This step focuses on verifying whether a query is optimized to only use a single shard or if it spans multiple shards to retrieve a result.
Start with selecting every document in the cities collection. Since you want to retrieve all the documents, it’s guaranteed that every shard must be used to perform the query:
- db.cities.find()
The query will, unsurprisingly, return all cities. Re-run the query, this time with the explain() method attached to the end of it:
- db.cities.find().explain()
The long output will provide details about how the query was executed:
Output{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SHARD_MERGE",
"shards" : [
{
"shardName" : "shard1",
. . .
},
{
"shardName" : "shard2",
. . .
}
]
}
},
. . .
Notice that the winning plan refers to the SHARD_MERGE strategy, which means that multiple shards were used to resolve the query. In the shards key, MongoDB returns the list of shards taking part in the evaluation. In this case, this list includes both shards of the cluster.
Now test whether the result will be any different if you query against the continent field, which is not the chosen shard key:
- db.cities.find({"continent": "Europe"}).explain()
This time, MongoDB also had to use both shards to satisfy the query. The database had no way to know which shard contains documents for European cities:
Output{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SHARD_MERGE",
. . .
}
},
. . .
The result should be different when filtering against the shard key. Try filtering cities only from Japan using the country field, which you previously selected as the shard key:
- db.cities.find({"country": "Japan"}).explain()
Output{
"queryPlanner" : {
"mongosPlannerVersion" : 1,
"winningPlan" : {
"stage" : "SINGLE_SHARD",
"shards" : [
{
"shardName" : "shard1",
. . .
}
. . .
This time, MongoDB used a different query strategy: SINGLE_SHARD instead of SHARD_MERGE. This means that only a single shard was needed to satisfy the query. In the shards key, only a single shard will be mentioned. In this example, documents for Japan were stored on the first shard in the cluster.
By using the explain feature on the query cursor you can check whether the query you are running spans one or multiple shards. In turn, it can also help you determine whether the query will overload the cluster by reaching out to every shard at once. You can use this method — alongside rules of thumb for shard key selection — to select the shard key that will yield the most performance gains.
Conclusion
Sharding has seen wide use as a strategy to improve the performance and scalability of large data clusters. When paired with replication, sharding also has the potential to improve availability and data security. Sharding is also MongoDB’s core means of horizontal scaling, in that you can extend the database cluster performance by adding more nodes to the cluster instead of migrating databases to bigger and more powerful servers.
By completing this tutorial, you’ve learned how sharding works in MongoDB, how to configure config servers and individual shards, and how to connect them together to form a sharded cluster. You’ve used the mongos query router to administer the shard, introduce data partitioning, execute queries against the database, and monitor sharding metrics.
This strategy comes with many benefits, but also with administrative challenges such as having to manage multiple replica sets and more complex security considerations. To learn more about sharding and running a sharded cluster outside the development environment, we encourage you to check out the official MongoDB documentation on the subject. Otherwise, we encourage you to check out the other tutorials in our series on How To Manage Data with MongoDB.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: How To Manage Data with MongoDB
MongoDB is a document-oriented NoSQL database management system (DBMS). Unlike traditional relational DBMSs, which store data in tables consisting of rows and columns, MongoDB stores data in JSON-like structures referred to as documents.
This series provides an overview of MongoDB’s features and how you can use them to manage and interact with your data.
Browse Series: 16 tutorials
About the author(s)
Creating bespoke software ◦ CTO & co-founder at Makimo. I'm a software enginner & a geek. I like making impossible things possible. And I need tea.
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
