
Trees are basically just fancy linked lists and creating and deleting nodes on a tree is incredibly simple. Searching on the other hand is a bit more tricky when they’re unsorted, so we’re going to look into a few different ways to handle searching through an entire tree.
Prerequisites
You will need a basic understanding of what trees are and how they work. Our particular example with be utilizing a Binary Search Tree, but these are more of techniques and patterns than exact implementations and can be easily adapted for any type of tree.
Concepts
With binary search trees we could use the same system to create a new node as to find one. Standard trees, like your file system, don’t follow any particular rules and force us to look at every item through a tree or subtree to find what we want. This is why running a search for a particular file can take so long.
There aren’t many ways to optimize past O(n) but there are two main “philosophies” for searching through the entire tree, either by searching breadth-first (horizontally between siblings) or depth-first (vertically between parents and children).
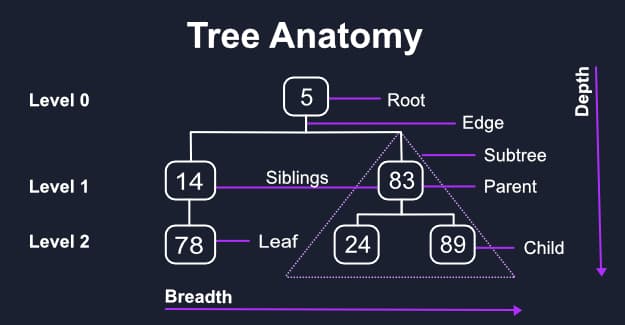
Tree
Since a binary search tree is the easiest to set up, we can just throw together a quick one that can only add nodes.
class Node {
constructor(val) {
this.val = val;
this.right = null;
this.left = null;
};
};
class BST {
constructor() {
this.root = null;
};
create(val) {
const newNode = new Node(val);
if (!this.root) {
this.root = newNode;
return this;
};
let current = this.root;
const addSide = side => {
if (!current[side]) {
current[side] = newNode;
return this;
};
current = current[side];
};
while (true) {
if (val === current.val) return this;
if (val < current.val) addSide('left');
else addSide('right');
};
};
};
const tree = new BST();
tree.create(20);
tree.create(14);
tree.create(57);
tree.create(9);
tree.create(19);
tree.create(31);
tree.create(62);
tree.create(3);
tree.create(11);
tree.create(72);
Breadth-First Search
Breadth-first search is characterized by the fact that it focuses on every item, from left to right, on every level before moving to the next.
There are three main parts to this, the current node, our list of visited nodes, and a basic queue for keeping track of which nodes we need to look at (we’ll just use an array since it’ll never get very long).
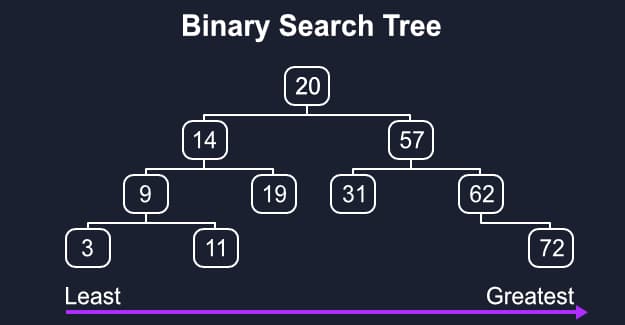
Let’s work through how it would look on this tree.
Whatever is our current, we’ll push its children (from left to right) into our queue, so it’ll look like [20, 14, 57]. Then we’ll change current to the next item in the queue and add its left and right children to the end of the queue, [14, 57, 9, 19].
Our current item can now be removed and added to visited while we move on to the next item, look for its children, and add them to the queue. This will repeat until our queue is empty and every value is in visited.
BFS() {
let visited = [],
queue = [],
current = this.root;
queue.push(current);
while (queue.length) {
current = queue.shift();
visited.push(current.val);
if (current.left) queue.push(current.left);
if (current.right) queue.push(current.right);
};
return visited;
}
console.log(tree.BFS()); //[ 20, 14, 57, 9, 19, 31, 62, 3, 11, 72 ]
Depth-First Search
Depth-first searches are more concerned with completing a traversal down the whole side of the tree to the leafs than completing every level.
There are three main ways to handle this, preOrder, postOrder, and inOrder but they’re just very slight modifications of each other to change the output order. Better yet, we don’t even need to worry about a queue anymore.
Starting from the root, we’ll use a short recursive function to log our node before moving down to the left as far as possible, logging its path along the way. When the left side is done it’ll start working on the remaining right values until the whole tree has been logged. By the end visited should look like [24, 14, 9, 3, 11, 19, ...].
preOrder() {
let visited = [],
current = this.root;
let traverse = node => {
visited.push(node.val);
if (node.left) traverse(node.left);
if (node.right) traverse(node.right);
};
traverse(current);
return visited;
}
console.log(tree.preOrder()); // [ 20, 14, 9, 3, 11, 19, 57, 31, 62, 72 ]
As you may have guessed, postOrder is the opposite of preOrder, we’re still working vertically but instead of moving from the root to leafs, we’ll search from the bottom to top.
We’ll start from the bottommost left node and log it and its siblings before moving up to their parent. The first half of visited should look like this, [3, 11, 9, 19, 14, ...], as it works it bubbles up the tree.
We can easily achieve this by pushing our nodes into visited after both traversals are completed.
postOrder() {
let visited = [],
current = this.root;
let traverse = node => {
if (node.left) traverse(node.left);
if (node.right) traverse(node.right);
visited.push(node.val);
};
traverse(current);
return visited;
}
console.log(tree.postOrder()); // [ 3, 11, 9, 19, 14, 31, 72, 62, 57, 20 ]
Similar to postOrder, preOrder visits works from the bottom up but it just visits the parent before any siblings.
Instead of the beginning or end we can push onto our list after we traverse the left side and before the right. Our results will look something like this, [3, 9, 11, 14, 19, 20, ...].
inOrder() {
let visited = [],
current = this.root;
let traverse = node => {
if (node.left) traverse(node.left);
visited.push(node.val);
if (node.right) traverse(node.right);
};
traverse(current);
return visited;
}
console.log(tree.inOrder()); // [ 3, 9, 11, 14, 19, 20, 31, 57, 62, 72 ]
Closing Thoughts
Of course all of these algorithms will be O(n) since the point is to look at every node, there isn’t much room for cutting corners or clever tricks.
Keep in mind that these aren’t exact implementations that need to be memorized but general patterns for solving problems and building more valuable algorithms. Once you understand the underlining concepts, they can easily be adapted for any language or framework.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
It would be nice if these examples had an explanation of why one might be preferred over another.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
