
Introduction
Another moonshot from Moonshot AI. Kimi K2.5, a visual agentic intelligence model, is ranked highly in popularity on OpenRouter indicating usage and outperforms closed-source models across benchmarks, indicating research breakthroughs. Clearly, this model is worth exploring from an architecture, training, and implementation lens.
We had fun talking about Kimi K2 in our previous articles on the model, with particular emphasis on its post-training. We also took a look at Kimi Linear, a linear attention architecture the Kimi team introduced. In addition to standout releases, Moonshot AI releases excellent information-dense technical reports. When reading this article, be sure to consult the Kimi-K2.5 technical report as well.
The Kimi-K2.5 release features the post-trained checkpoints and is available for use under an Modified MIT licence.
The goal of this article is to highlight what we found most interesting – and by interesting we mean what exactly did the Kimi K2 team do to achieve such excellent performance? We’ll also show you how to run this model on a DigitalOcean GPU Droplet.
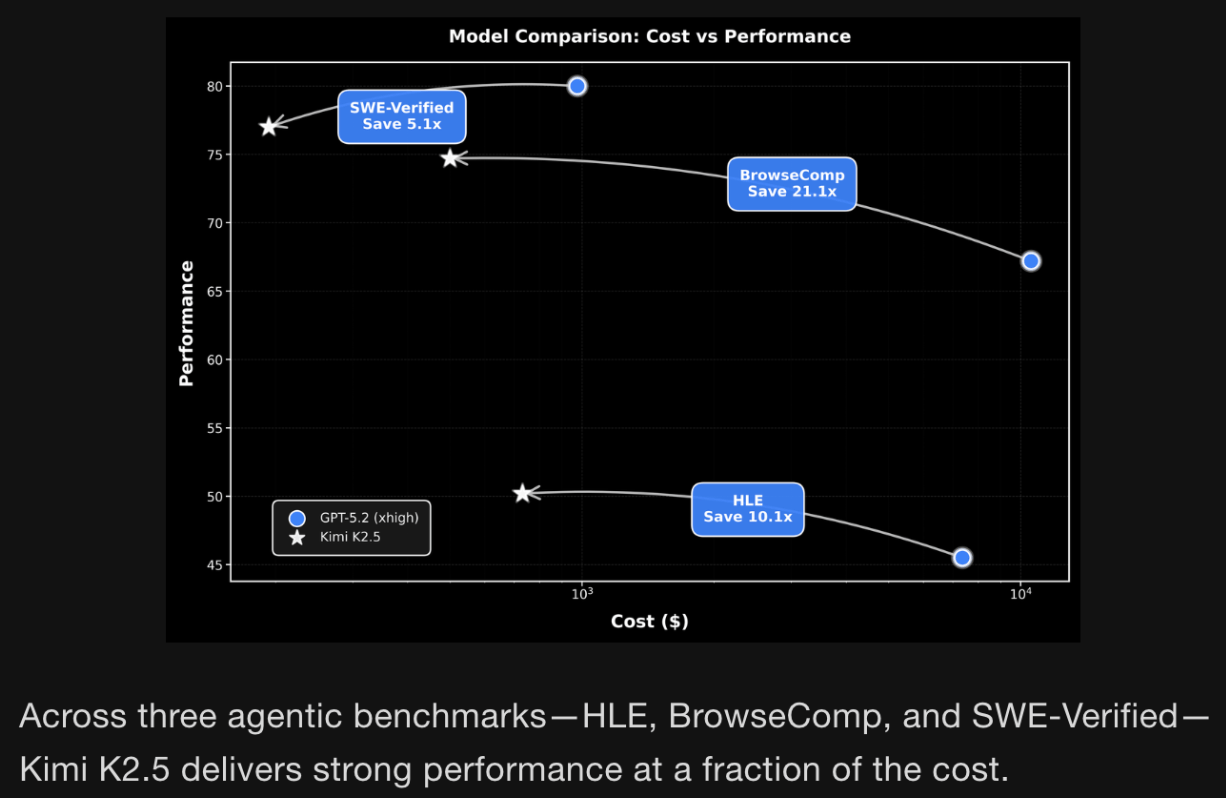
(source)
Key Takeaways
- Kimi K2.5, like Kimi K2, has a MoE architecture of 1 trillion total parameters and 32 B active parameters. It is likely this is named K2.5 and not K3 because Kimi K2.5 is built on K2 with large-scale joint pre-training where the model is trained on 15 trillion visual and textual tokens.
- The main difference between Kimi K2 and K2.5 is that there is greater emphasis on joint-vision training - particularly with pretraining and the RL stage of post-training. Supervised Finetuning, however, is text-only.
- The model is available with a Modified MIT licence. The release features post-trained checkpoints. There are three modes of the model: instant mode, thinking mode, and agent mode.
- Agent Swarm and PARL, Parallel Agent Reinforcement Learning, are introduced to address the limited capacity of a single agent in handling complex scenarios
- The Toggle heuristic allows for token efficient reinforcement learning by alternating between inference-time scaling and budget constrained optimization.
- The Decoupled Encoder Process (DEP) handles the load imbalances and memory fluctuations that occur when processing visual data of varying sizes (like images and videos) alongside text.
- For more complex tasks, Kimi K2.5 can self-direct an agent swarm with up to 100 sub-agents, allowing for the execution of parallel workflows across up to 1,500 tool calls. The subaegents are specialized (e.g., AI Researcher, Physics Researcher, Fact Checker).
Model Overview
| Spec | Description |
|---|---|
| Architecture: Transformer, Mixture-of-Experts (MoE) | The Mixture of Experts (MoE) architecture allows for greater model size and quality while reducing compute costs. It uses sparse Feedforward Neural Network (FFN) layers (experts) and a gate network (router) to selectively route tokens to top-k experts, activating only a subset of parameters per token. This approach enables larger models without proportionally increasing computational costs. |
| Parameters: 1 trillion total parameters, 32 billion active parameters | As K2 is a MoE architecture, there are total and active parameters. Total parameters refers to the sum of all parameters across the entire model, including all expert networks, the router/gating network, and shared components, regardless of which experts are used during inference. This contrasts with active parameters, which only counts the subset of parameters utilized for a specific input - typically the activated experts plus shared components. |
| Attention Mechanism: MLA (Multi-head Latent Attention) | MLA was introduced by DeepSeek V2 (Section 2.1) as an attention mechanism to boost inference efficiency. 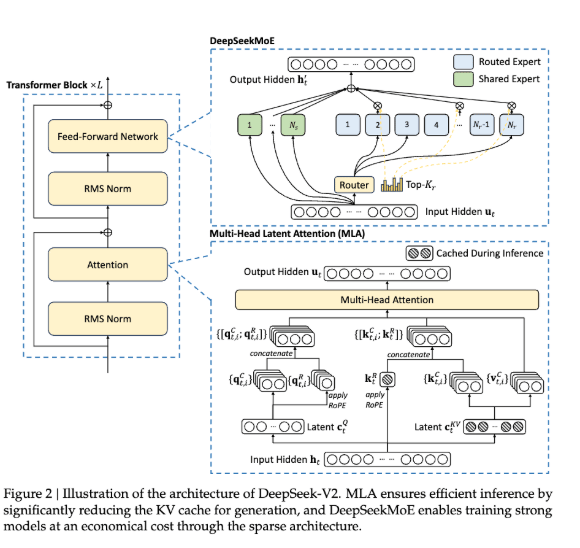 MLA works by compressing the attention input into a low-dimensional latent vector which can be later calculated by recovering the keys and values. Due to the use of MLA in K2, QK-Norm, a normalization technique typically applied to query-key matrices, is not applicable to scaling up Muon training since the key matrices in MLA are not fully materialized during inference. As a result, the K2 researchers incorporated QK-Clip, a weight-clipping mechanism to constrain attention logits that arise with large-scale Muon-optimized training. MLA works by compressing the attention input into a low-dimensional latent vector which can be later calculated by recovering the keys and values. Due to the use of MLA in K2, QK-Norm, a normalization technique typically applied to query-key matrices, is not applicable to scaling up Muon training since the key matrices in MLA are not fully materialized during inference. As a result, the K2 researchers incorporated QK-Clip, a weight-clipping mechanism to constrain attention logits that arise with large-scale Muon-optimized training. |
| Optimizer: MuonClip | Muon, while a token-efficient optimizer, needs to be modified for large-scale training. The MuonClip optimizer, introduced in Section 2.1 of the Kimi K2 tech report, is Muon integrated with weight decay, consistent RMS matching, and QK-Clip. |
| Number of Experts: 384 ; Selected Experts per Token: 8 ; Number of Shared Experts: 1 | Refer to the sparsity section of our Kimi K2 article to better understand how increasing the total number of experts increases sparsity. |
| Number of Layers: 61 (including 1 Dense layer) | We didn’t really elaborate on this in our K2 article - but the “layers” refer to the number of transformer blocks in the model. Each layer processes and refines the input data, allowing the model to learn increasingly abstract representations. A dense layer is fully connected. |
| Number of Attention Heads: 64 ; Attention Hidden Dimension: 7168 | Attention heads allow the model to focus on different parts of the input simultaneously. Each head learns to capture different types of relationships in the data. |
| MoE Hidden Dimension (per Expert): 2048 | Each individual expert processes a 2048-dimensional representation. |
| Activation Function: SwiGLU | This isn’t a surprise. SwiGLU is the current standard in modern LLMs. ex: gpt-oss |
| Vision Encoder: MoonViT-3D (400M parameters) | This is new from Kimi K2. If you’re familiar with Kimi-VL, you’ll recognize MoonViT. KimiK2 has MoonViT-3D, which is a continual pre-train of SigLIP on image-text and video-text pairs. Here, consecutive frames are grouped in fours, processed through the shared MoonViT encoder, and temporally averaged at the patch level – this design allows K2.5 to process videos 4x longer within the same context window. |
This paper explores three interconnected themes:
- Vision-language integration through joint optimization techniques that allow text and vision modalities to co-enhance each other. Pre-training and RL stages are multi-modal.
- Scalable parallelism via Agent Swarm, enabling concurrent execution of heterogeneous sub-tasks by specialized agents
- Reinforcement Learning: This model leverages RL in a number of different ways, we’ll elaborate on this further in the article.
- Joint multimodal RL
- Outcome-based visual RL
- PARL (Parallel Agent Reinforcement Learning)
- Inference optimization which allows the researchers to achieve up to 4.5× latency reduction while improving task performance. As a result of inference improvements from parallelization, Kimi K2.5 is able to process videos up to 4x longer in the same context window while maintaining complete weight sharing between image and video encoders.

The results in this table indicate that vision-RL is advantageous in areas requiring complex reasoning and knowledge integration, demonstrating consistent performance gains across diverse benchmarks that test both factual understanding and long-context comprehension.
Agent Swarm
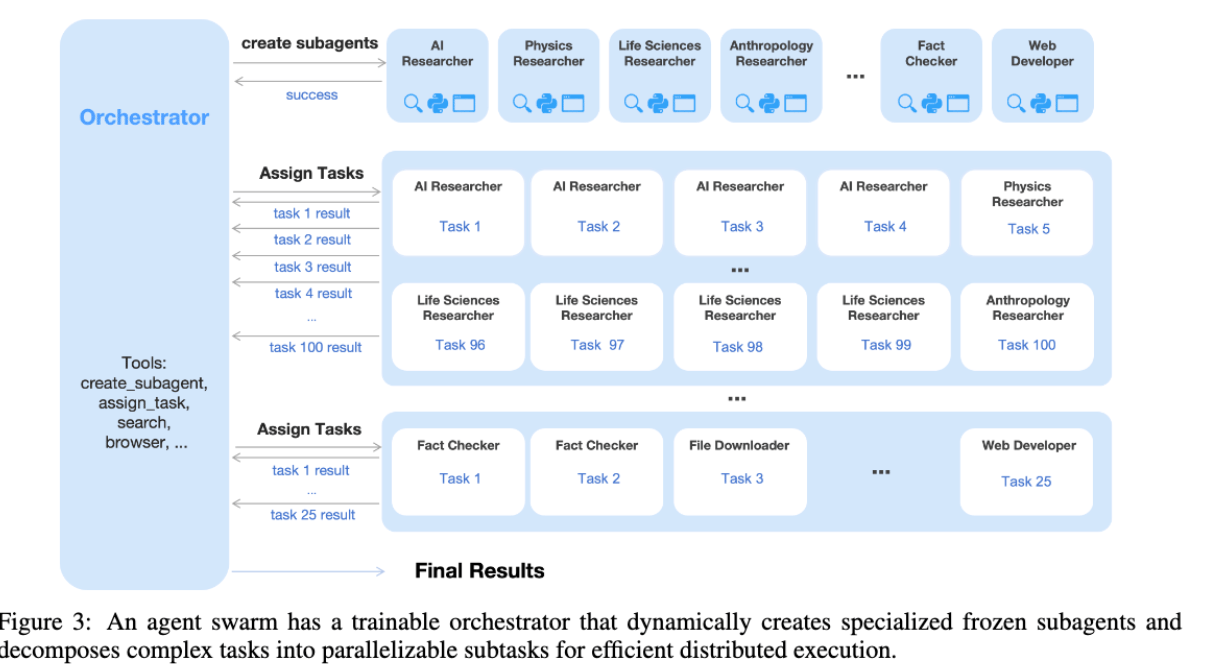
With agent swarm, there is:
- dynamic task decomposition
- subagent instantiation
- parallel subtask scheduling
On the Kimi website, you can actually try out K2.5 Agent Swarms.
Section 5.2 of the K2.5 technical report goes into detail on how this translates into performance. Three benchmarks evaluate the agent swarm framework: BrowseComp for browsing hard-to-find information & deep reasoning, WideSearch for large-scale retrieval, and an in-house Swarm Bench for real-world complexity. The in-house benchmark tests orchestration, scalability, and coordination across four domains. It’s interesting to see the prioritization of doing the following at-scale: information gathering, downloading, interpretation, and writing.
| In-House Swarm Bench Task | Description |
|---|---|
| WildSearch | Unrestricted gathering of information from the entire internet without limitations |
| Batch Download | Mass collection of various types of files and materials at scale |
| WideRead | Processing and understanding large volumes of text across 100+ documents |
| Long-Form Writing | Creating lengthy, well-structured written content spanning over 100,000 words |
PaRL
With K2.5, parallel agent reinforcement learning (PARL) means that decisions that pertain to parallelization are learned through environmental feedback and RL-driven exploration. The way this works is that K2.5 has a trainable orchestrator agent. The RL framework improves efficiency by training the orchestrator with small-size subagents and dynamically adjusting inference instance ratios.
A common failure mode the researchers observe is serial collapse where the orchestrator would default to single-agent execution despite parallel capacity being available. To address this, PARL would utilize staged reward that encourages parallelism early in training and gradually shifts focus toward task success.
Post-training
Supervised Finetuning
You may be wondering why this stage is text-only. The researchers found that adding human-designed visual trajectories in SFT negatively impacts generalization. On the other hand, text-only SFT has higher performance which the researchers speculate is because joint pre-training establishes a vision-text alignment that promotes generalization.
The synthetic data generation pipeline produces high-quality candidate text responses from K2, K2 thinking, and a suite of proprietary in-house expert models. We’re very curious about these in-house models. The resulting instruction-tuning dataset features diverse prompts and prioritizes training the model for reasoning and tool-calling.
Reinforcement learning
What was done here is new from traditional approaches because the RL domains are not organized input modalities (e.g., image, text) but rather by abilities (e.g., knowledge, reasoning, coding, agentic, etc.).
Unified Agent Reinforcement Learning Environment
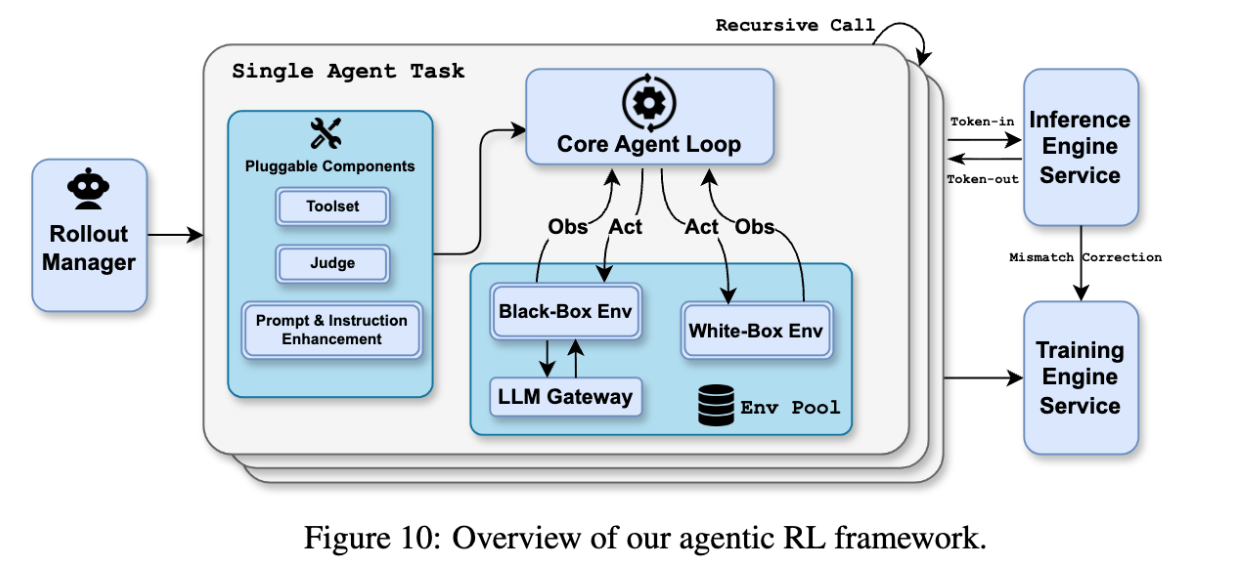
(source)
To minimize overhead involved in customizing and implementing environments, there is a standardized Gym-like interface with pluggable components (e.g., toolset, judge, prompt and instruction enhancement)
| Module | Purpose |
|---|---|
| Toolset | Supporting various tools with sandboxes |
| Judge | Multi-faceted reward signals |
| Prompt diversification and instruction-following enhancement | Diversifying prompts and improving instruction following |
Performance
The Kimi K2.5 technical report goes into detail on the model’s performance in section 5 of the paper. It appears K2.5 has strong performance in the following areas:
- Reasoning and general
- Complex coding & software engineering
- Agentic capabilities
- Vision, reasoning knowledge, and perception
- Video understanding
- Computer-use capability
Running K2.5 on DigitalOcean
There are a number of ways to run different versions of Kimi K2.5: vllm, sglang, unsloth. Note the memory requirements: The 1T parameter hybrid reasoning model requires 600GB of disk space, whereas the quantized Unsloth Dynamic 1.8-bit version reduces this to 240GB (-60% size): Kimi-K2.5-GGUF
Begin by setting up a DigitalOcean GPU Droplet and ssh into your droplet. Be mindful of how many GPUs you’ll need.
vLLM Implementation
We’re following this usage guide.
uv pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
We set -tp to 1 to split the individual layers and mathematical operation of the model into “shards” across 1 GPU. Note that the original documentation has -tp 8 to distribute the model across 8 GPUs using 8-way tensor parallelism.
vllm serve $MODEL_PATH -tp 1 --mm-encoder-tp-mode data --trust-remote-code --tool-call-parser kimi_k2 --reasoning-parser kimi_k2
Sglang Implementation
Here, we’re following the sglang implementation from the Kimi-K2.5 Deployment Guide.
pip install "sglang @ git+https://github.com/sgl-project/sglang.git#subdirectory=python"
pip install nvidia-cudnn-cu12==9.16.0.29
sglang serve --model-path $MODEL_PATH --tp 8 --trust-remote-code --tool-call-parser kimi_k2 --reasoning-parser kimi_k2
Key parameter notes:
–tool-call-parser kimi_k2: Required when enabling tool usage. –reasoning-parser kimi_k2: Required for correctly processing reasoning content.
FAQ
Why is the model called K2.5 and not K3?
K2.5 is built directly on the K2 base, extended through large-scale joint pre-training on 15 trillion visual and text tokens. Because the core architecture (MoE, parameter counts, MuonClip optimizer) remains unchanged, the team positioned it as an evolution of K2 rather than an entirely new generation.
Why does early vision fusion with a lower vision ratio outperform aggressive late-stage vision injection?
The paper’s ablation studies (Table 1) showed that introducing vision data early at a modest ratio (10:90 vision-to-text) consistently outperforms late fusion at high ratios (50:50). Late fusion causes a “dip-and-recover” pattern where text performance initially degrades from the modality domain shift. Early fusion avoids this disruption and allows both modalities to co-develop unified representations from the start.
Why does visual RL improve text performance?
The paper found that outcome-based visual RL improved MMLU-Pro, GPQA-Diamond, and LongBench v2 scores. The likely explanation is that visual tasks involving counting, OCR, and structured extraction sharpen calibration and reduce uncertainty in analogous text-based reasoning patterns.
Why is SFT text-only if K2.5 is a multimodal model?
Adding human-designed visual trajectories at the SFT stage was found to hurt generalization. The joint pre-training stage already establishes strong vision-text alignment, so text-only SFT is sufficient to activate visual reasoning without the risk of overfitting to low-diversity visual demonstrations. This is what the paper calls “Zero-Vision SFT.”
How does Toggle prevent models from becoming too token-efficient at the cost of reasoning quality?
Toggle alternates between two phases every m training iterations: a budget-constrained phase that rewards concise reasoning, and a standard scaling phase that allows full token usage. This prevents “length overfitting”, which is where models trained under rigid budgets fail to use additional compute effectively on harder problems. On average, Toggle reduces output tokens by 25-30% with negligible performance loss.
How does Agent Swarm differ from simply calling tools in parallel?
Agent Swarm is not static parallelism — the orchestrator learns when and how to parallelize through PARL. The orchestrator dynamically decomposes tasks, instantiates specialized subagents, and schedules them concurrently. Crucially, subagents maintain independent working memories and only return task-relevant outputs to the orchestrator, which acts as proactive context management rather than reactive truncation.
Why are subagents frozen during PARL training?
Training both the orchestrator and subagents simultaneously creates credit assignment ambiguity — a correct final answer doesn’t mean every subagent performed well, and vice versa. By freezing subagents and treating their outputs as environmental observations, the team could train only the orchestrator stably, disentangling high-level coordination from low-level execution.
What is “serial collapse” and how is it addressed?
Serial collapse is when the orchestrator learns to default to single-agent execution despite having parallel capacity available — essentially the path of least resistance. The PARL reward includes an instantiation reward (rparallel) that explicitly incentivizes spawning subagents early in training. This auxiliary reward is then annealed to zero so the model eventually optimizes purely for task success rather than parallelism for its own sake.
What does it mean for hyperparameters to be annealed to 0? (See Section 3 where it covers the PARL reward)
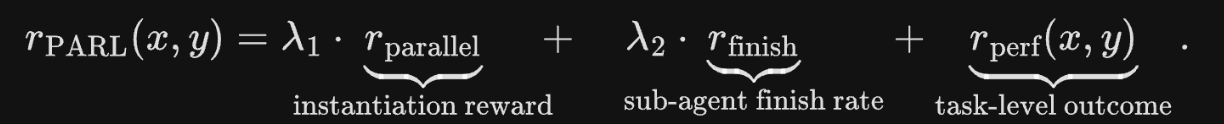
In the context of Kimi K2.5’s Agent Swarm training, annealing hyperparameters to 0 means gradually reducing the weights of auxiliary rewards during the reinforcement learning process.
- Initial Phase: The weights λ1 and λ2 are set above zero to provide “training wheels” that encourage the model to explore parallel execution rparallel and ensure sub-tasks are actually completed rfinish.
- Transition: These values are lowered over time to prevent the model from “reward-hacking” or prioritizing concurrency over quality.
- Final Phase: Once the weights reach 0, the model is optimized purely for the primary objective: successfully solving the task
rperf.
What is Spurious parallelism and how is it prevented? (See Section 3 where it covers the PARL reward)
Spurious parallelism is a “reward-hacking” behaviour where an orchestrator spawns numerous subagents without meaningful task decomposition just to inflate parallelization metrics.
It is prevented through:
- The rfinish reward, which incentivizes the successful completion of assigned subtasks to ensure decompositions are feasible and valid.
- The Critical Steps metric, which measures the longest execution path rather than total steps, making excessive subtask creation that doesn’t reduce latency useless
- Hyperparameter Annealing, which gradually reduces auxiliary rewards for parallelism to zero so the model eventually prioritizes the primary task outcome.
What are the GPU memory requirements for running K2.5?
The full 1T parameter model requires approximately 600GB of disk space. The quantized Unsloth Dynamic 1.8-bit GGUF version reduces this to around 240GB. For full-precision deployment via vLLM or SGLang, you’ll need to distribute across multiple GPUs using tensor parallelism (the documentation recommends -tp 8 for 8-way distribution).
What is the Decoupled Encoder Process (DEP) and why does it matter for training efficiency?
In standard pipeline parallelism, the vision encoder sits in Stage-0 alongside text embeddings, causing severe load imbalances because images vary widely in resolution and count. DEP separates the vision forward pass, backbone training, and vision recomputation into three distinct stages per training step. This achieves load balance without requiring custom pipeline configurations, and K2.5 reaches 90% of text-only training efficiency despite the added multimodal complexity.
Final Thoughts
What stands out most to us is how the Moonshot AI team approached the problem systematically: joint multimodal pretraining to establish a strong vision-text foundation before RL, text-only SFT to preserve generalization, and RL organized around abilities rather than modalities. Each decision reflects deliberate reasoning about what the model needs to learn and when. PARL is arguably the most forward-looking contribution here. The insight that parallelization behaviour should be learned rather than hard-coded and that serial collapse is a real failure mode requiring staged reward shaping suggests the team is thinking seriously about what agentic reliability looks like at scale. The Toggle heuristic similarly shows sophistication: rather than treating inference-time scaling and budget optimization as competing objectives, they alternate between them.
For practitioners, a 1T parameter MoE model with 32B active parameters, available under a Modified MIT license, deployable via vLLM or SGLang, is genuinely accessible. The quantized GGUF variants offered by unsloth lower the barrier further. Whether you’re exploring multimodal reasoning pipelines or building agents that need to orchestrate parallel workstreams, K2.5 warrants serious evaluation.
The Moonshot AI team continues to ship both openly available strong models and dense technical reports to the benefit the broader developer and research community. We’re excited to cover more releases from this team and other open models with great technical reports and impressive usage by the community.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
