
Introduction
Moonshot AI has done it again. We were impressed with their release of Kimi-K2 and their post-training approach. Now, in addition to Kimi-K2-Thinking (which we encourage you to check out), they also released Kimi Linear, a hybrid linear attention architecture where they introduce a new attention mechanism, Kimi Delta Attention (KDA).
The release features an open-source KDA kernel (written in triton), vLLM implementations, as well as the pre-trained and instruction-tuned model checkpoints (48B total parameters, 3B activated parameters, 1 million context length).
In this article, we are going to discuss key findings from the Kimi Linear paper and show how you can run the model with DigitalOcean.
Key Takeaways
- Kimi Delta Attention (KDA) is a linear attention mechanism with fine-grained, channel-wise gating, improving memory management and hardware efficiency over past methods such as Gated DeltaNet (GDN) and Mamba2.
- KDA utilizes a specialized variant of Diagonal-Plus-Low-Rank (DPLR) transition matrices that increases utilization of the Tensor Cores.
- Kimi Linear features a hybrid architecture with 3 layers of KDA combined with 1 layer of MLA. This architecture reduces KV cache usage by 75% and give us up to 6x higher decoding throughput at 1M context length
In the first two paragraphs of our FlashAttention article, we talked about the attention mechanism and the importance of developing hardware-aware algorithms. Developing attention mechanisms that are more hardware-aware and memory-efficient continues to be an active area of research and therefore we’re going to continue to see advances being made here. Kimi Delta Attention (KDA) is a linear attention variant – one that incorporates gating. We’re going to provide you with a primer on both linear attention and the role of gating mechanisms in memory efficiency and numerical stability to give you an intuition behind why the Kimi folks are even bothering with introducing a new attention variant in the first place.
Primer on Linear Attention
Traditional attention methods compute attention scores using softmax over a similarity matrix, which is quadratic in time and memory with respect to sequence length (O(n^2)). There are a number of different linear attention variants that seek to reduce the quadratic complexity of standard attention. Now linear attention is an approximation attention method which seeks to improve efficiency with some tradeoff in accuracy.
With linear attention, the softmax in traditional attention is replaced with a positive feature map. The feature map is designed so that the resulting kernel (dot product) is always positive, mimicking the effect of the softmax but without the explicit normalization step.
Linear attention struggles with long-context retrieval, which is why, as we’ll discuss later, Kimi Linear adopts a hybridized architecture.
The Role of Gating

Given that managing information effectively over long sequences is a running challenge in the field, gating mechanisms seek to improve memory efficiency. They do this by incorporating a selective forgetting factor into the attention process. You may have seen this concept used in recurrent neural networks like LSTMs.
Gating with Linear Attention
When it comes to gating mechanisms with linear attention, the quadratic, ever-expanding Key-Value (KV) cache of traditional attention is replaced by a fixed-size, matrix-valued state and learnable gates. As the sequence is processed, this design allows the model to be selective about which information to retain and forget.
Gating is often combined with a delta update rule (as in KDA and Gated DeltaNet), allowing for precise memory modifications. By the delta update rule, we are referring to computing the difference (delta) between new and predicted values to update the hidden state that is used as a memory state.
Designing Hardware-Aware Algorithms
Designing hardware-aware algorithms involves understanding the hardware and revisiting the math. Modern GPUs really shine when presented with parallelizable workloads that are mostly matrix multiplications. Conversely, they struggle with sequential dependencies and non-matrix operations. This creates a challenge for Linear Attention models like KDA, which are inherently recurrent.
This means when designing algorithms for the recurrent KDA, we want to make the computation as chunkable as possible for easy parallelization as well as get rid of any non-matmul operations that don’t affect the overall calculation. Reducing the number of non-matmul FLOPs was also the intuition behind developing FlashAttention-2 as this allows for maximum utilization of the Tensor Cores, which are optimized to accelerate throughput for matrix multiplication.
We’re going to try to explain how the Kimi team applied this logic in the development of Kimi Linear (section 3).
So as we said before, the KDA update is recurrent – a sequential, autoregressive process. In other words, to get the state at time St, we must know the state at time (St-1). If implemented naively, this would force the GPU to process tokens one by one – leaving massive amounts of compute power idle
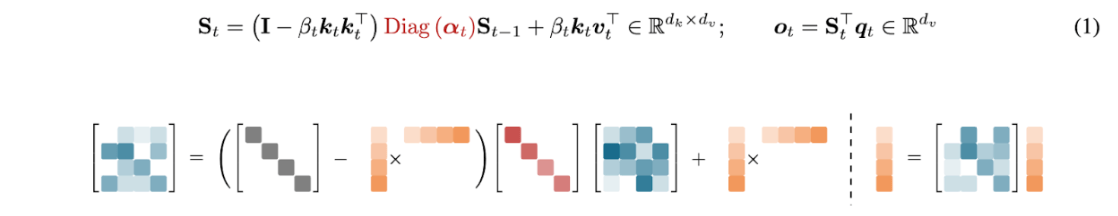
To address this inefficiency, the equation for Sr[t], was divided into chunks.
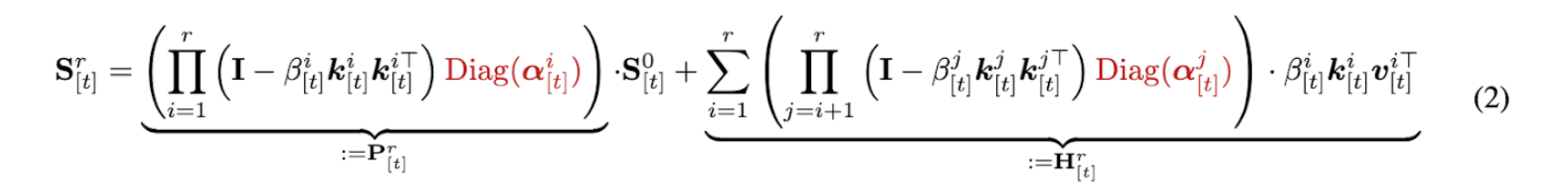
The significance of this step is that it mathematically transforms a calculation that must be done sequentially into a calculation that can be done in parallel, where multiple chunks are processed at once.
They used the WY representation to pack a series of rank-1 updates into a compact form. This avoids expensive matrix inversions during computation. Additionally the researchers applied a UT (Upper Triangular) transform to reduce the number of non-matmul FLOPs.
Kimi Linear Architecture
The Kimi team is also behind Moonlight, which builds on the success of Muon, the optimizer we explain in our Kimi K2 article. In addition to demonstrating Muon’s scalability for large-scale LLM training, Moonlight forms the backbone of the Kimi Linear model architecture.
The Kimi Linear architecture combines several KDA layers with standard full attention layers in a 3:1 ratio.
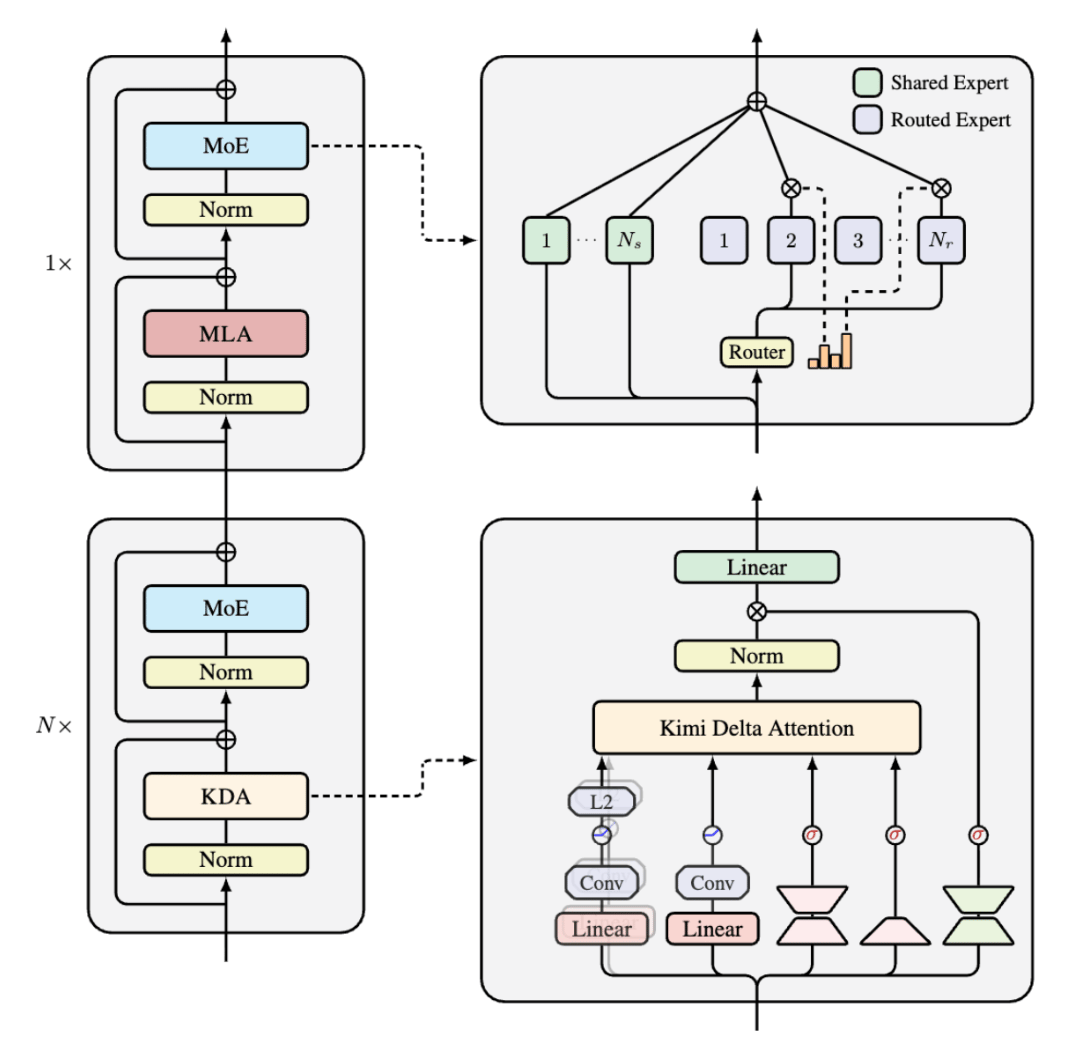
Hybridization
You may be curious to know why there is a hybrid approach. That is, why is Kimi Linear designed such that global attention (full MLA) is mixed in with KDA. The answer lies in linear attention’s weakness with long context retrieval. If you’ve read our LLM inference optimization article, you may recall us explaining how global attention, while computationally more expensive and memory-intensive from processing all token pairs (and therefore slower inference speed), is better able to capture full context and long-range dependencies.
Positional encodings? NoPE
Because the standard transformer attention mechanism doesn’t inherently recognize the sequence order of the input elements, explicit positional encodings are required to introduce this information. RoPE (Rotary Position Embeddings) is one of the more popular forms of positional encodings.
With Kimi Linear, the researchers opted to forgo positional encodings with NoPE (No Position Encoding). NoPE allows these models to be transformed into the more computationally efficient pure Multi-Query Attention (MQA) format when running inference. Additionally, it makes training on long contexts easier by eliminating the requirement to modify RoPE parameters – such as adjusting the frequency base or applying techniques like YaRN.
The Kimi Linear technical report also cited a few papers that demonstrated the effectiveness of forgoing positional encodings (NoPE).
Rope to nope and back again: A new hybrid attention strategy
Round and round we go! what makes rotary positional encodings useful?
Deepseek-v3 technical report
Implementation
Begin by setting up a DigitalOcean GPU Droplet. We’re going to select the inference-optimized image.
To run this model we’re going to use a 4XH100 cluster.
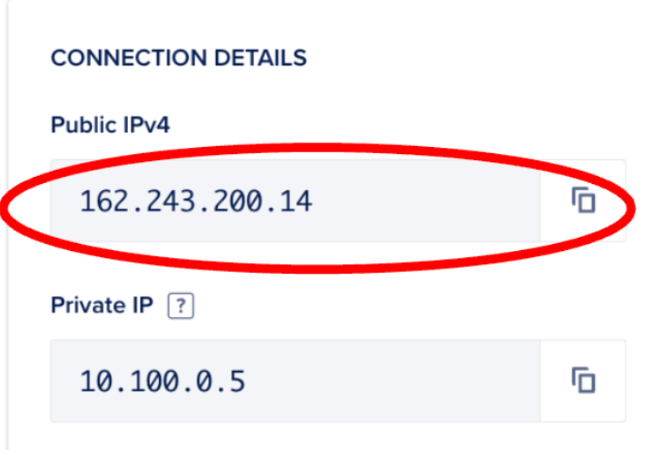
SSH into your droplet with your favourite IDE and Public IPv4 address. We’re using cursor.
ssh root@your_droplet_ip
apt install python3.10-venv
# Install PyTorch with CUDA 12.1 support (standard for H100)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Install Hugging Face Transformers, Accelerate, and Kimi dependencies
pip install transformers accelerate bitsandbytes sentencepiece protobuf tiktoken
# Install the specific Flash Linear Attention core required by Kimi
pip install vllm
pip install -U fla-core
vllm serve moonshotai/Kimi-Linear-48B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 1048576 \
--trust-remote-code
Final Thoughts
Kimi-linear is a hardware-aware architecture. Kimi Delta Attention (KDA) is Kimi Linear’s main innovation; it involves fine-grained, channel-wise gating and mathematical modifications like chunking the recurrent update, allowing for better memory management and utilization of the Tensor Cores. The model’s hybrid architecture (a 3:1 ratio of KDA to full attention MLA) strategically mitigates linear attention’s weakness in long-context retrieval, a common trade-off for efficiency. Furthermore, the adoption of NoPE (No Position Encoding) simplifies training and streamlines the model for efficient Multi-Query Attention (MQA) inference. The result is a highly performant model that demonstrates a 75% reduction in KV cache usage and up to 6x higher decoding throughput at 1M context length, paving the way for more scalable and cost-effective LLM deployment.
FAQ
What is the significance of linear attention replacing the softmax in traditional attention with a positive feature map?
In the context of Linear Attention, a positive feature map is a mathematical function used to approximate the softmax operation in the attention mechanism, without explicitly computing the large similarity matrix. The softmax in traditional attention ensures that attention weights are positive and sum to 1, but it requires computing pairwise similarities between all elements in a sequence, leading to O(n²) complexity. This transformation allows the attention to be computed using associative operations (like matrix multiplications), which can be done in linear time, O(n), rather than quadratic time.
What is Mamba?
Mamba is a state space model, which is an alternative architecture to transformers.
What is gated attention?
Gated attention is a modification of the standard full attention mechanism that incorporates an extra sigmoid gate.
How does channel-wise gating enhance memory control?
The channel-wise gating in Kimi Delta Attention (KDA) enhances memory control by introducing a fine-grained, per-dimension forgetting mechanism, as opposed to the coarser, head-wise or scalar gating used in previous models like GDN or Mamba2.
| Traditional Gating (e.g., GDN, Mamba2) | Channel-Wise Gating (KDA) |
|---|---|
| Uses a single scalar gate per attention head, meaning the entire memory state for that head is decayed uniformly. This can lead to either too much or too little forgetting, as all dimensions are treated equally. | Uses a diagonal matrix of gates (one gate per feature dimension). Each dimension of the memory state can decay at its own rate, allowing the model to selectively retain or forget information based on the importance of each feature dimension. |
What are data-dependent vs data-independent forget gates?
In the context of attention mechanisms and recurrent sequence models, data-dependent and data-independent refer to how a model’s parameters, particularly the forget gate or decay factor, are computed. These factors determine how quickly or slowly the model “forgets” past information stored in its memory state.
Kimi Delta Attention (KDA) and Gated DeltaNet (GDN) use a data-dependent gate at, and Mamba2 employs a data-dependent scalar at.
References and Additional Resources
Paper: Kimi Linear: An Expressive, Efficient Attention Architecture
Blog posts
Beyond Standard LLMs by Sebastia Raschka: We like how this resource in section 2 explained the revival of linear attention,introduced gated attention and gave us a concise overview of gated deltanet.
A Visual Guide to Mamba and State Space Models : This resource by Maarten Grootendorst is golden for brushing up your understanding of how great self-attention is for training but not necessarily for inference. The blog post also covers RNNs and state space models.
GPU Mode Lecture 60: Optimizing Linear Attention by Songlin Yang
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
