Sr. Developer Advocate - AI/ML

Introduction
When building LLM-powered applications, model availability can be unpredictable. Rate limits, temporary outages, or regional availability issues can break your application at the worst possible time. This post demonstrates how to build resiliency into your LangChain app through automatic model fallback via DigitalOcean’s serverless inferencing. You’ll learn how to:
Key Takeaways
- Implement automatic LLM fallback with zero retries for fast switching - Learn how to build resilient AI applications that automatically switch between models when failures occur, ensuring your users never experience downtime
- Leverage DigitalOcean’s serverless inference API - Access multiple AI models through a single, unified API without managing infrastructure or dealing with complex provider integrations
- Build production-ready error handling for LLM applications - Implement robust error handling patterns that gracefully manage model failures, rate limits, and availability issues in production environments
- Master the LangChain-Gradient Platform integration - Use the official LangChain integration to seamlessly connect your applications with DigitalOcean’s AI platform
- Optimize for cost and performance - Learn how to strategically order models based on your application’s performance requirements and budget constraints
Prerequisites
- LangChain - An framework for developing applications powered by language models. If you’re new to LangChain, check out our Getting Started with LangChain tutorial for the basics.
- DigitalOcean Gradient Platform - DigitalOcean’s AI platform that provides access to multiple AI models through serverless inference. Learn more in our Gradient Platform overview and Serverless Inference guide
- Python - Version 3.8 or higher. If you need to install Python, follow our Python installation guide
- uv - A fast Python package installer and resolver. We’ll use this for dependency management in this tutorial
- DigitalOcean account - You’ll need a DigitalOcean account to access the GGradient™ AI Platform. Sign up here if you don’t have one
- Basic understanding of APIs - Familiarity with REST APIs and environment variables will be helpful. Check out our API basics tutorial if you need a refresher
Why Serverless Inference?
The DigitalOcean Gradient Platform revolutionizes the development of AI applications by providing a seamless integration of various AI models. The serverless inference feature is a game-changer, allowing you to access a wide range of popular open-source and proprietary models through a single, unified API. This approach offers numerous advantages, including:
- Serverless: Scalable access to AI models without the need for infrastructure management, ensuring your application can handle sudden spikes in traffic or demand without worrying about server capacity.
- Multi-model access: The ability to access over a dozen AI models through a single API, giving you the flexibility to experiment with different models and find the best fit for your application.
- Unified billing: Consolidated billing for all model usage under a single platform, making it easier to manage costs and track usage across different models.
- Pay-per-use pricing: A cost-effective pricing model that only charges you for the resources you use, ensuring you only pay for the compute time and resources needed to run your AI models.
By leveraging serverless inference, you can focus on building and deploying AI applications without worrying about the underlying infrastructure, model management, or complex billing processes. This enables you to accelerate your AI development, reduce costs, and improve the overall efficiency of your projects.
Quick Start
Execute the below code to clone and run the repository - you can read the code explanation below. This project uses the package manager uv, so ensure it is installed on your system.
# Clone the repository
git clone https://github.com/do-community/langchain-gradient-ai-switch-providers.git
cd langchain-gradient-ai-switch-providers
# Install dependencies with uv
uv sync
# Set up environment
cp .env.example .env
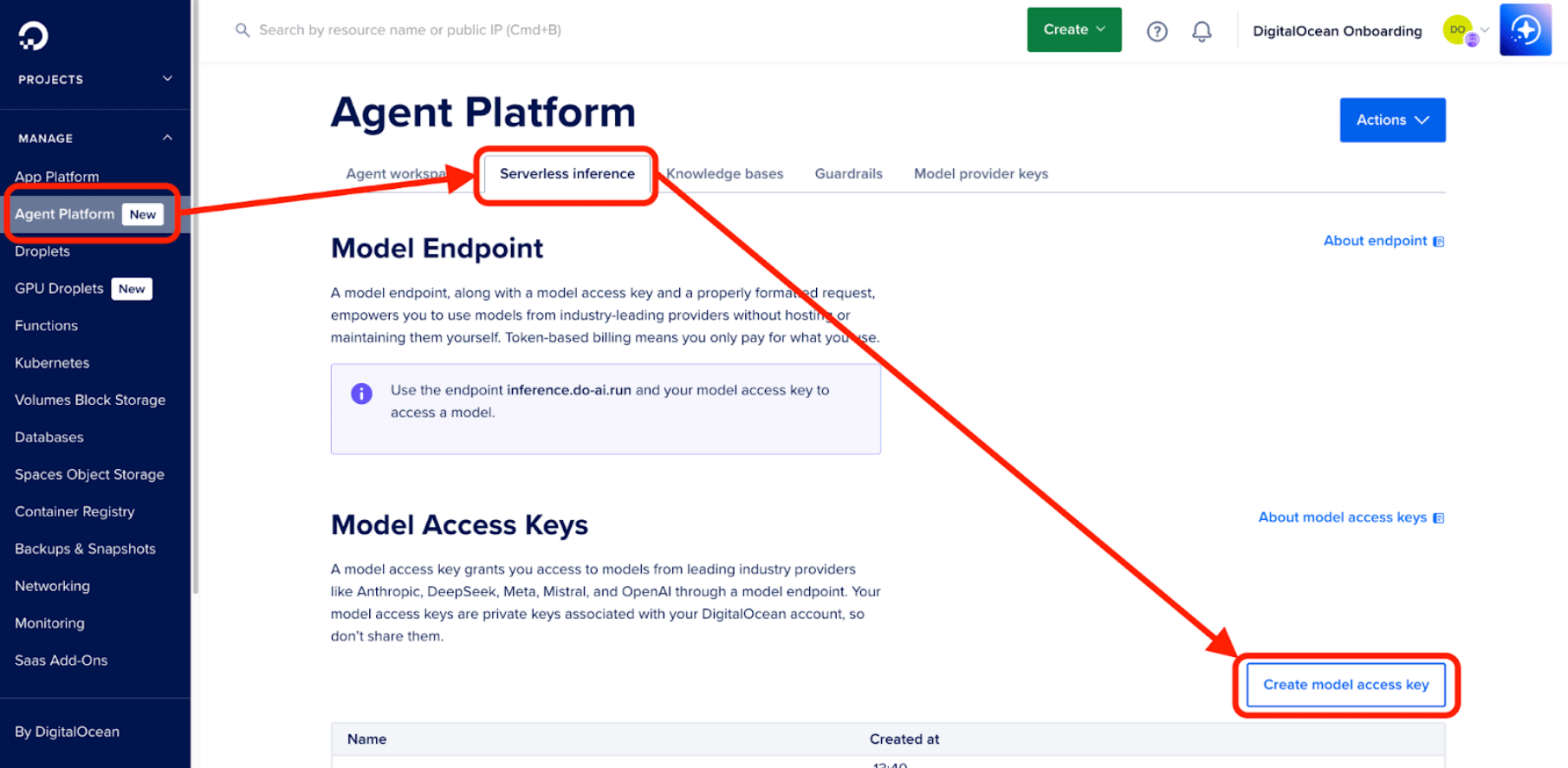
Next, go to your DigitalOcean Cloud console, select Agent Platform in the sidebar, then click the Serverless inference tab, and finally the Create model access key button. Name your key, and then paste its value into the .env file as the value for the DIGITALOCEAN_INFERENCE_KEY environment variables.
Now you can run the code:
uv run main.py
This will prompt LLaMa 3 70B (Instruct), falling back to LLaMa 3 8B (Instruct) if there is an error. To simulate a failure, use the --mock flag:
uv run main.py --mock
This will create a mock failure for the first call, falling back to the secondary model to successfully complete the request.
Code explanation
The model enum
The models.py file contains an enumeration of all of the models available in DigitalOcean Serverless Inference, including Claude, GPT, and Llama. Defining an enumeration provides static type checking support, IDE completion, and prevents typos that may cause runtime errors.
from enum import Enum
class GradientModel(Enum):
LLAMA3_3_70B_INSTRUCT = "llama3.3-70b-instruct"
ANTHROPIC_CLAUDE_3_5_SONNET = "anthropic-claude-3.5-sonnet"
OPENAI_GPT_4O = "openai-gpt-4o"
# ...
Core fallback implementation
ChatGradientAI, in the langchain-gradientai integration, is the LangChain object that provides access to the Gradient AI Platform. We extend this class to add a fallback mechanism.
The FallbackChatGradientAI class takes in a list of models to try in sequential order when making an LLM call. If one model fails, it moves on to the next and repeats the call until there is a success. If all models fail, it raises an exception.
class FallbackChatGradientAI:
def __init__(
self,
models: List[GradientModel],
api_key: Optional[str] = None,
**kwargs
):
if not models:
raise ValueError("At least one model must be provided")
self.models = models
self.api_key = api_key or os.getenv("DIGITALOCEAN_INFERENCE_KEY")
self.kwargs = kwargs
if not self.api_key:
raise ValueError("API key must be provided or set in DIGITALOCEAN_INFERENCE_KEY")
def invoke(self, input_data: Any) -> Any:
last_exception = None
for i, model in enumerate(self.models):
logger.info(f"Attempting request with model: {model.value}")
try:
llm = self._create_llm(model)
result = llm.invoke(input_data)
if i > 0:
logger.info(f"Successfully fell back to model: {model.value}")
return result
except Exception as e:
logger.warning(f"Model {model.value} failed: {str(e)}")
last_exception = e
continue
# If we get here, all models failed
raise Exception(f"All models failed. Last error: {str(last_exception)}")
This design features:
- No retries - Immediate fallback for faster response times (implicitly assuming persistent failure if a provider fails at all)
- Sequential trying - Models attempted in order of preference, allowing you to rank for cost/performance for your app
- Comprehensive logging - Track which models fail and succeed
Mocking failures
The MockFallbackChatGradientAI overrides FallbackChatGradientAI by creating a mock object in place of the first LLM that intentionally raises an exception when called:
class MockFallbackChatGradientAI(FallbackChatGradientAI):
def _create_llm(self, model: GradientModel) -> ChatGradientAI:
if self.fail_first and model == self.models[0]:
mock_instance = Mock()
mock_instance.invoke.side_effect = Exception("Mocked failure for testing")
return mock_instance
return super()._create_llm(model)
Main script
The main scripts, main.py contains three isolated examples, accessed via different command-line flags:
- A basic example (no fallback) showing how to use DigitalOcean’s Serverless Inference (run with
uv run main.py --basic) - A real fallback example, where a backup model is provided should the first fail (run with
uv run main.py) - A mock fallback example, where a mock failed call is simulated to demonstrate the fallback behavior (run with
uv run main.py --mock)\
FAQs
1. How does LLM fallback improve application reliability?
LLM fallback significantly improves application reliability by automatically switching to backup AI models when the primary model fails. This approach eliminates single points of failure and ensures your application continues functioning even during model outages, rate limiting, or regional availability issues. With DigitalOcean’s serverless inference, you can access multiple models through a single API, making fallback implementation seamless and cost-effective.
Key benefits:
- Zero downtime - Automatic model switching prevents service interruptions
- Cost optimization - Use cheaper models as fallbacks for non-critical requests
- Performance flexibility - Balance speed vs. quality based on your needs
- Regional resilience - Overcome location-based model availability issues
2. What’s the difference between retry logic and fallback strategies?
Retry logic and fallback strategies serve different purposes in LLM applications:
Retry Logic:
- Attempts the same model multiple times with delays
- Useful for temporary network issues or rate limits
- Can increase response times significantly
- May not resolve persistent model failures
Fallback Strategies:
- Immediately switches to alternative models
- Provides faster response times during failures
- Offers different model capabilities and pricing
- Ensures continuous service availability
The implementation in this tutorial uses zero-retry fallback for immediate switching, which is ideal for production environments where speed and reliability are critical.
3. How do I choose the right models for my fallback strategy?
Selecting the right models for your fallback strategy involves balancing several factors:
Primary Model Selection:
- Choose based on your application’s primary requirements (speed, accuracy, cost)
- Consider model capabilities for your specific use case
- Factor in expected request volume and budget constraints
Fallback Model Considerations:
- Performance tiering: Use progressively smaller/faster models (e.g., 70B → 8B → 7B)
- Cost optimization: Balance quality vs. expense for different request types
- Specialization: Consider domain-specific models for specialized tasks
- Availability: Ensure fallback models are in different regions or from different providers
Example Strategy:
models = [
GradientModel.LLAMA3_3_70B_INSTRUCT, # High quality, higher cost
GradientModel.LLAMA3_3_8B_INSTRUCT, # Good quality, moderate cost
GradientModel.ANTHROPIC_CLAUDE_3_5_SONNET # Alternative provider
]
4. Can I implement fallback with other AI providers besides DigitalOcean?
Yes, you can implement LLM fallback with other AI providers, but DigitalOcean’s approach offers unique advantages:
Multi-Provider Fallback:
- Complexity: Requires managing multiple API keys, rate limits, and billing
- Integration: Need to handle different response formats and error patterns
- Cost: Multiple billing accounts and potential overage charges
- Maintenance: More complex monitoring and alerting systems
DigitalOcean Gradient AI Advantages:
- Single API: Unified interface for all models
- Unified billing: One account, one bill, simplified cost management
- Consistent responses: Standardized output format across all models
- Built-in redundancy: Multiple models from different providers automatically available
- Simplified monitoring: Single dashboard for all model usage and performance
Implementation Example:
# Multi-provider approach (complex)
class MultiProviderFallback:
def __init__(self):
self.openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.anthropic_client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
self.gradient_client = ChatGradientAI(api_key=os.getenv("GRADIENT_API_KEY"))
# DigitalOcean approach (simple)
class SimpleFallback:
def __init__(self):
self.client = FallbackChatGradientAI(
models=[GradientModel.LLAMA3_3_70B_INSTRUCT, GradientModel.ANTHROPIC_CLAUDE_3_5_SONNET]
)
5. How do I monitor and debug fallback behavior in production?
Effective monitoring and debugging of fallback behavior is crucial for production applications:
Key Metrics to Track:
- Fallback frequency: How often models fail and trigger fallbacks
- Response times: Performance comparison between primary and fallback models
- Success rates: Model-specific reliability metrics
- Cost impact: Billing differences between primary and fallback usage
Implementation Strategies:
import logging
from datetime import datetime
class MonitoredFallbackChatGradientAI(FallbackChatGradientAI):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.metrics = {
'total_requests': 0,
'fallbacks_triggered': 0,
'model_performance': {},
'errors': []
}
def invoke(self, input_data: Any) -> Any:
start_time = datetime.now()
self.metrics['total_requests'] += 1
try:
result = super().invoke(input_data)
self._record_success(start_time)
return result
except Exception as e:
self._record_error(e)
raise
def _record_success(self, start_time):
duration = (datetime.now() - start_time).total_seconds()
# Log success metrics and performance data
logging.info(f"Request completed in {duration}s")
def _record_error(self, error):
self.metrics['errors'].append({
'timestamp': datetime.now(),
'error': str(error),
'model_attempted': getattr(self, 'current_model', 'unknown')
})
Monitoring Tools:
- Application logs: Track fallback events and performance metrics
- APM solutions: Monitor response times and error rates
- Custom dashboards: Visualize fallback patterns and costs
- Alerting: Set up notifications for unusual fallback behavior
Debugging Tips:
- Enable detailed logging for all model interactions
- Track request IDs across fallback attempts
- Monitor model-specific error patterns
- Set up cost alerts for unexpected usage spikes
Conclusion
Congratulations! You’ve successfully learned how to implement automatic LLM fallback in your LangChain applications using DigitalOcean Gradient Platform. This approach provides production-ready resilience that ensures your AI-powered applications remain operational even when individual models experience issues.
What You’ve Accomplished
- Built a robust fallback system that automatically switches between AI models
- Implemented zero-retry logic for faster response times during failures
- Created production-ready error handling with comprehensive logging
- Optimized for cost and performance through strategic model selection
- Leveraged DigitalOcean’s unified platform for simplified management
Key Benefits of This Approach
The fallback strategy you’ve implemented offers several advantages over traditional single-model approaches:
- Improved reliability - Your applications won’t fail due to model unavailability
- Better user experience - Seamless service continuity during outages
- Cost optimization - Strategic use of different model tiers
- Simplified operations - Single API and unified billing through DigitalOcean
Get started with DigitalOcean Gradient Platform and build your own resilient LLM applications today. The platform provides everything you need to implement robust fallback strategies, from unified API access to comprehensive monitoring tools.
Ready to Build More Cool Stuff?
Visit the official Langchain Gradient Platform GitHub repository to read the code, or check out some of the other repos in the DigitalOcean Community organization.
Check out some of our other similar tutorials, like:
- LangChain: A Beginner’s Guide to Harness the Power of Language Models - Master the fundamentals of LangChain for building LLM-powered applications
- A Practical Guide to RAG with Haystack and LangChain - Learn how to build production-ready Retrieval-Augmented Generation pipelines
- Interactive Conversations with PDFs Using LangChain - Create AI applications that can understand and chat about document content
- A Beginner’s Guide to Machine Learning in Python - Build a strong foundation in machine learning with Python and Scikit-Learn
- How to Integrate DataForSEO APIs with ChatGPT - Learn how to use DataForSEO APIs in ChatGPT to build a custom GPT.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
