AI/ML Technical Content Strategist

There have been a plethora of new video models this year, and it’s sufficient to say that 2025 is the first year that video modeling has truly dominated public interest around AI technologies. With the proliferation of Sora 2, this is becoming more and more clear. Thanks to OpenAI’s series of mobile applications, access to generation tools for videos is the most possible and popular it has ever been. But closed-source models are not the focus of this blog, and the open-source competition for these models is actually becoming more impressive than ever.
Earlier this year, HunyuanVideo and Wan2.1 rocked the open-source world with their incredible fidelity, relatively inexpensive nature, and public availability. This trend in development has only continued, with new versions of Wan releasing and other competitors entering the scene.
In this article, we want to introduce the latest video model to become publicly available: Meituan’s LongCat Video. This awesome video model is the latest and greatest open source tool to enter our kit, and we are excited to show, in this tutorial, how you can begin generating your own videos today with DigitalOcean.
Follow along for a brief overview of how LongCat Video works, and a tutorial showing how to set up and begin running LongCat Video on a NVIDIA powered DigitalOcean GPU Droplet.
Key Takeaways
- LongCat Video is the best open-source competitor to Sora 2 now available
- Users can use DigitalOcean GPU Droplets to generate videos competitive in quality with Sora 2 using their own prompts and machinery
- Running LongCat Video requires at least 80GB of VRAM on an NVIDIA GPU system, but can be extended to run on a multi-GPU setup for faster generation speeds
LongCat Video: An Overview
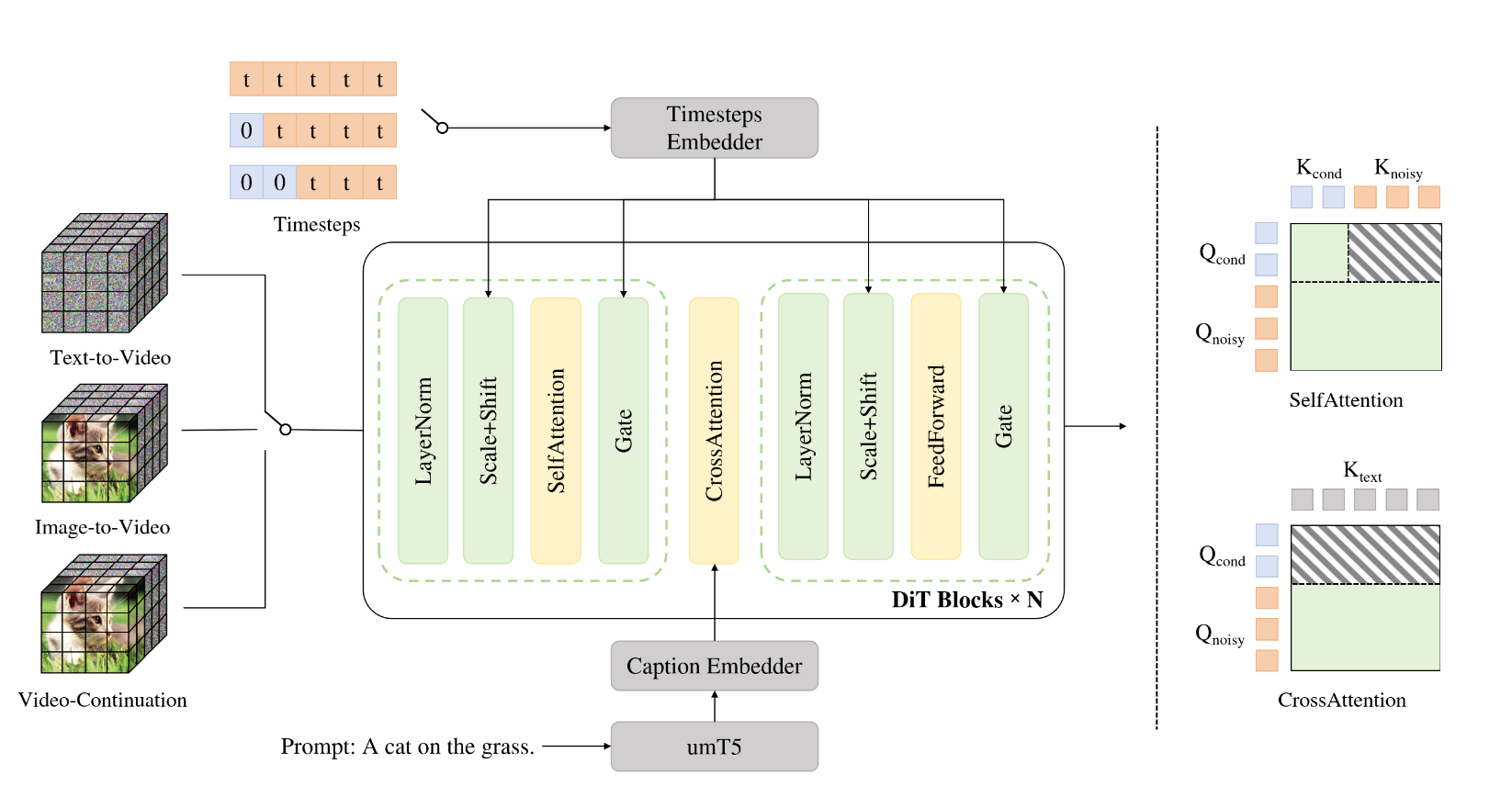
The beauty of LongCat Video lies in its architecture at its core. This is because they have very cleverly designed a single pipeline for multiple tasks, including text-to-video, image-to-video, and video continuation. They argue that all of these tasks should be defined as video continuation, where the model predicts future frames conditioned on a given set of preceding condition frames.
To achieve this, they employ a relatively standard Diffusion Transformer architecture with single-stream transformer blocks. “Each block consists of a 3D self-attention layer, a cross-attention layer for text conditioning, and a Feed-Forward Network (FFN) with SwiGLU. For modulation, [they] utilize AdaLN-Zero, where each block incorporates a dedicated modulation MLP. To enhance training stability, RMSNorm is applied as QKNorm within both the self-attention and cross-attention modules. Additionally, 3D RoPE is adopted for positional encoding of visual tokens.” Source This unified architecture allows for any of the three video tasks to be completed using the same model design.
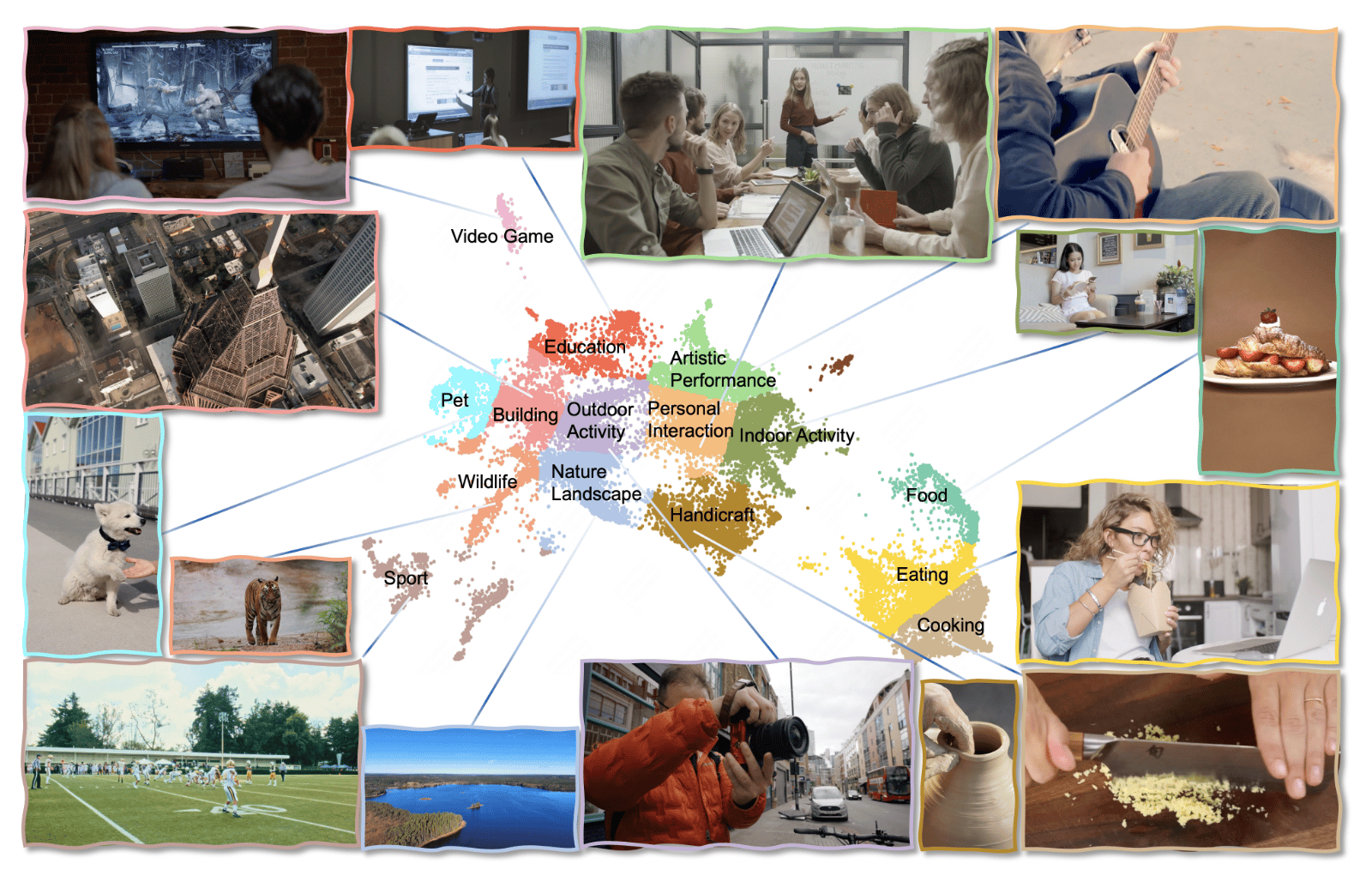
The model was trained on a massive corpus of annotated videos from a wide variety of different sources, video types, and subject matters. We can see a rough clustering of the subjects included in the training data above. For this data, they employed a strong data preprocessing and data annotation pipeline for text labeling. First, the data is collected and processed to make sure there are no duplicates, black borders are cropped, and video transition segmentation. They do not discuss in detail where their data is being sourced from, at this time. (Source)
Where LongCat Video shines and differs from competitors is its long video generation capability and efficient inference strategy. For long video generation, LongCat-Video is natively pretrained on Video-Continuation tasks, enabling it to produce minutes-long videos without color drifting or quality degradation. In practice, this is thanks to the robustness of the training strategy, where the focus on extending videos shows as a result of the training. For the efficient inference strategy, we are referring to the coarse-to-fine strategy. In LongCat Video, “videos are first generated at 480p, 15fps, and subsequently refined to 720p, 30fps.” (Source) Furthermore, they implemented a novel block sparse attention mechanism, which effectively reduces attention computations to less than 10% of those required by standard dense attention. This design significantly enhances efficiency in the high-resolution refinement stage. Finally, they used a novel Group Relative Policy Optimization (GRPO) strategy to refine their pipeline further. They effectively do the reinforcement learning paradigm with multiple rewards in place.
Put together, Meituan LongCat Video is a powerful Video generation and continuation model that is both versatile and powerful as a tool. They argue that their model is competitive with SOTA competition, and we would like to use this article to show how you can use it yourself on DigitalOcean hardware.
LongCat Video Demo: How to run LongCat Video on a DigitalOcean GPU Droplet
Set up a GPU Droplet
To get started with running LongCat Video, we recommend starting with a DigitalOcean GPU Droplet. These GPU Droplets come with the GPU technology required to run this tutorial. We recommend at least a single NVIDIA H200 GPU, but users with a 8xH100 or 8xH200 setup will see faster generation times.
To startup a GPU Droplet and set up your environment to run this demo, we recommend using this tutorial to get started.
Once you have accessed your running GPU Droplet from your local terminal, continue to the next section.
Set up your Remote Environment for LongCat Video
Once you have SSH’d into your remote machine, navigate to the directory you would like to work in. Once there, paste the following code into begin setting up your environment.
git clone https://github.com/meituan-longcat/LongCat-Video
cd LongCat-Video
pip install torch==2.6.0+cu124 torchvision==0.21.0+cu124 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
pip install ninja
pip install psutil
pip install packaging
pip install flash_attn==2.7.4.post1
pip install -r requirements.txt
With that complete, we are almost ready to get started. All we have to do now is download the model checkpoints! Use the following snippet to do so:
pip install "huggingface_hub[cli]"
huggingface-cli download meituan-longcat/LongCat-Video --local-dir ./weights/LongCat-Video
Using the Streamlit application to Generate LongCat Videos
For the demo, we recommend using the Streamlit application provided by the authors to run video generation. This Streamlit demo makes it simple to generate videos at different resolutions, generate videos from still images, and continue videos for longer lengths.
With setup complete, we can run the demo. Paste the following to run the demo.
streamlit run ./run_streamlit.py --server.fileWatcherType none --server.headless=false
Copy the Streamlit window URL, and then use Cursor or VS Code’s simple browser feature to access the window from your local. The steps for setting up your VS Code environment are outlined in this tutorial.
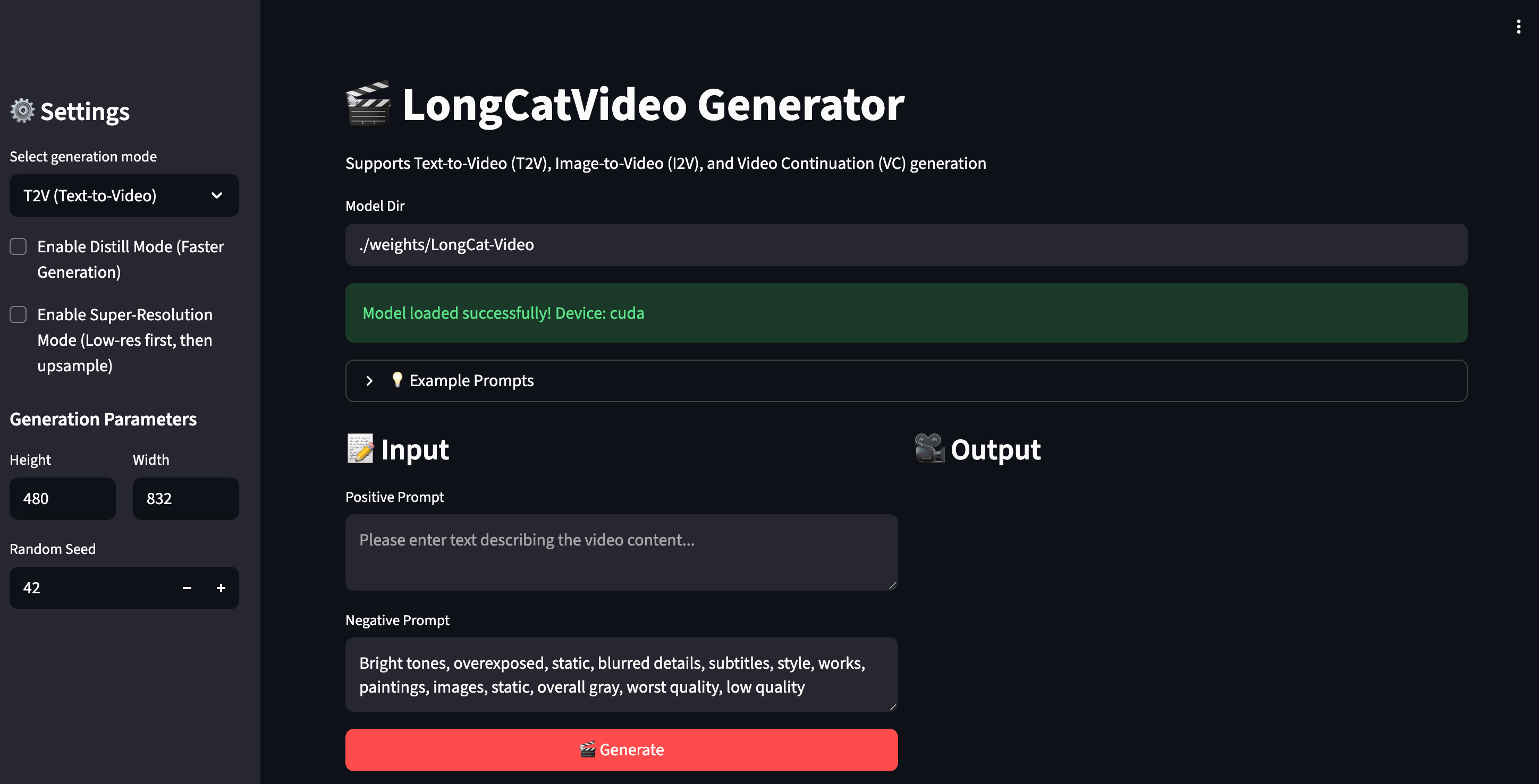
Above we can see the Streamlit demo after loading. On the left, there’s a drop-down where we can change our task between the three options, enable distil mode (which limits the model to 16 inference steps instead of 50), enable super resolution (coarse-to-fine upscaling), and the generation parameters. In the window itself, we have options to input prompt text for the positive and negative prompts, and, on other tasks, add an image or video as needed.
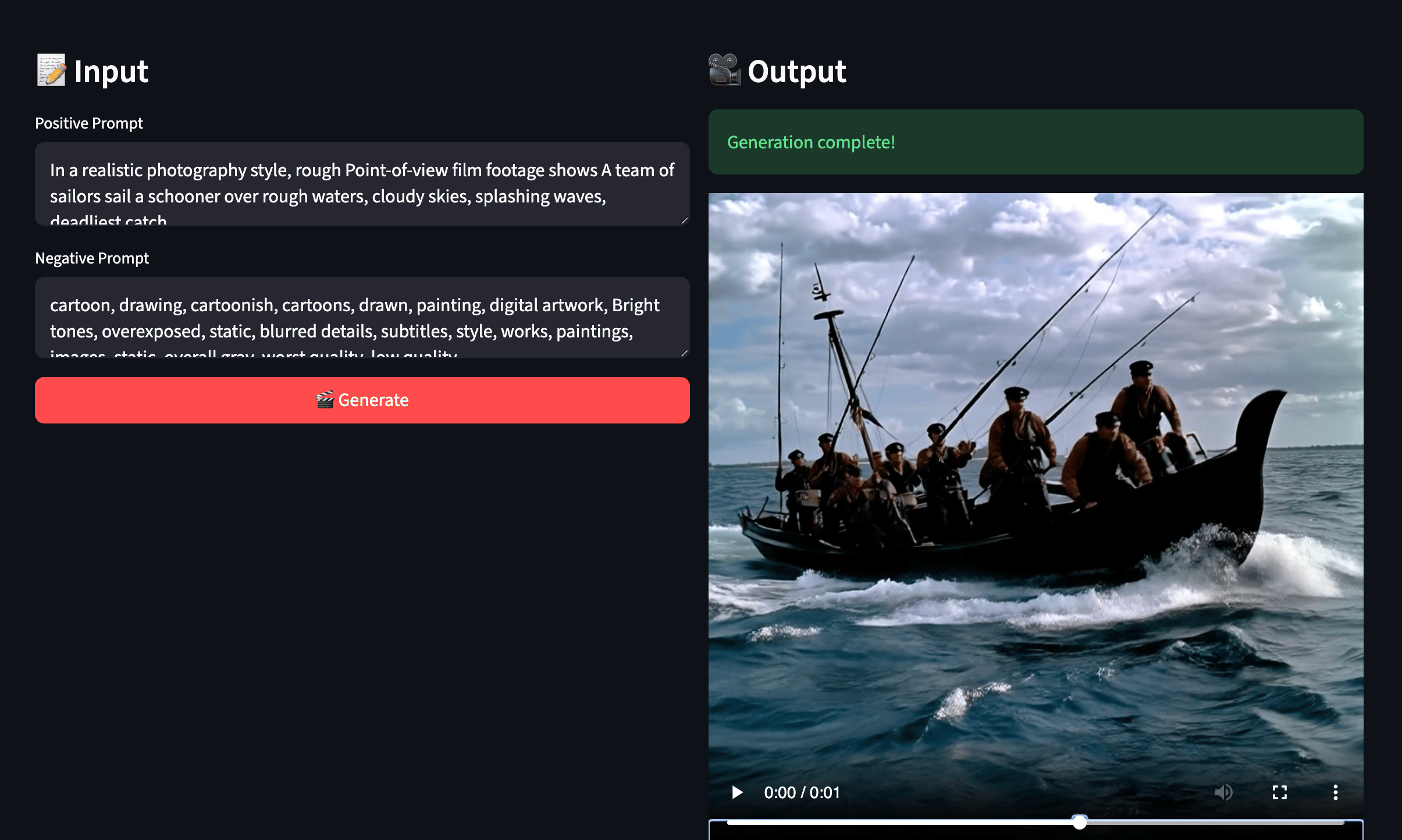
When we run the generator, we get our video output on the right side! Be sure to try out a wide variety of prompt subject matters to really test this model out!
Closing Thoughts
Meituan LongCat Video is a truly powerful video generation paradigm. We are incredibly impressed with both its versatility and capability. In our testing, it is truly a step forward from Wan2.1 and HunyuanVideo, and is on par with SOTA models like Wan2.2. Not only that, the unified framework makes this pipeline even more impressive and versatile than the competition. We look forward to seeing an ecosystem develop around LongCat Video going forward.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
