By Andrew Dugan
Senior AI Technical Content Creator II

Introduction
NVIDIA has announced the newest additions to their Nemotron family of models, Nemotron 3. There are three separate models in the Nemotron 3 family that are being released, including Nano, Super, and Ultra, which have 30, 49, and 253 billion parameters respectively with up to 1M tokens in context length. Nano was released in December of 2025, and Super and Ultra are scheduled to be released later in 2026. They are being released on NVIDIA’s open model license, making them available for commercial use and modification and giving you ownership and complete control over generated outputs. Both the weights and training data are open and available on Hugging Face. This tutorial will discuss these models and how to deploy the currently available Nano on a DigitalOcean GPU Droplet.
Key Takeaways
- NVIDIA has announced Nemotron 3, a new addition to their Nemotron model lineup. Nemotron 3 consists of three new models, Nano (30B), Super (49B), and Ultra (253B).
- As of January, 2026, the smallest model, Nano, is the only one currently available for use. Super and Ultra are scheduled for release later in 2026.
- All of the models are open-weight, allowing for open access for commercial use and modification. The models’ architectures employ novel efficiency improvements to increase model throughput.
Model Overviews
The Nemotron 3 models use a Mixture of Experts hybrid Mamba-Transformer architecture that is meant to increase the token generation speed, otherwise known as throughput. This means that the models have fewer layers of self-attention and instead use Mamba-2 (state space model) layers and Mixture-of-Experts (MoE) layers that are computationally less expensive and faster, especially for longer input sequences. This allows the Nemotron 3 models to process longer texts faster while using less memory and resources. Some attention layers are included where needed to keep accuracy as high as possible.
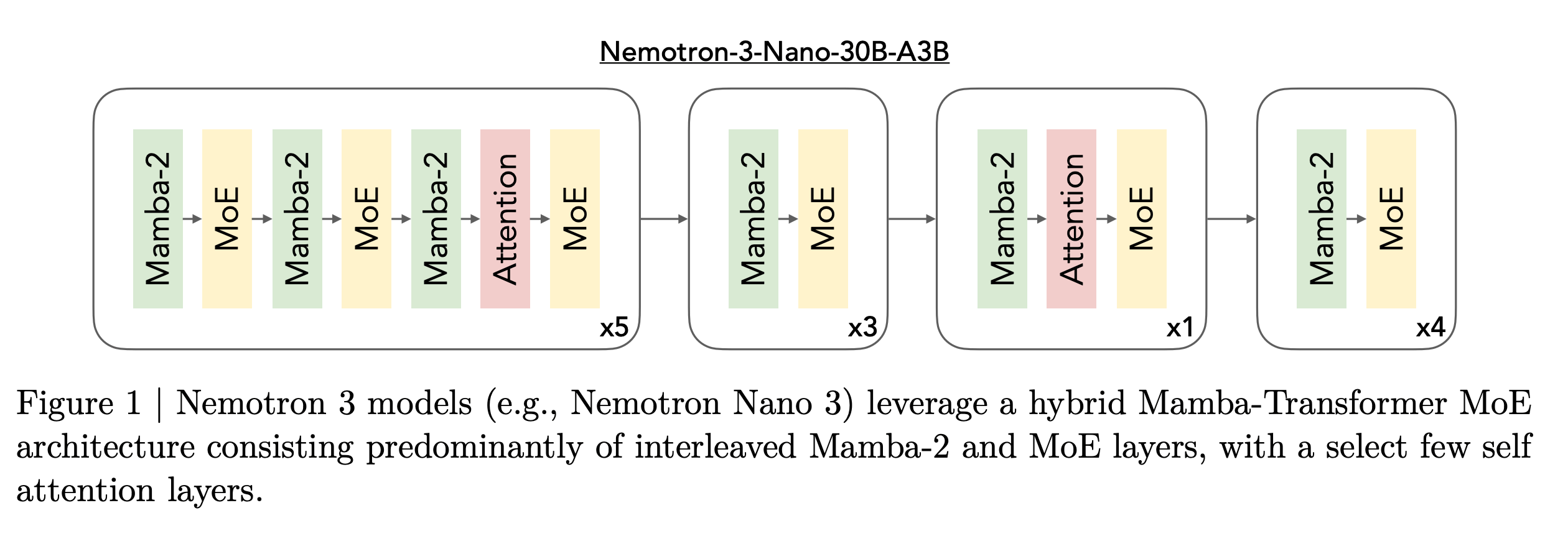
NVIDIA describes each of the three models as optimized for different platforms. Nano provides cost efficiency for targeted agentic tasks without sacrificing accuracy. Super offers high accuracy for multi-agentic reasoning. Ultra maximizes reasoning accuracy.
Nano is the smallest of the three and is comparable to Qwen3-30B and GPT-OSS-20B in performance. It is the only of the three that is available as of January, 2026.
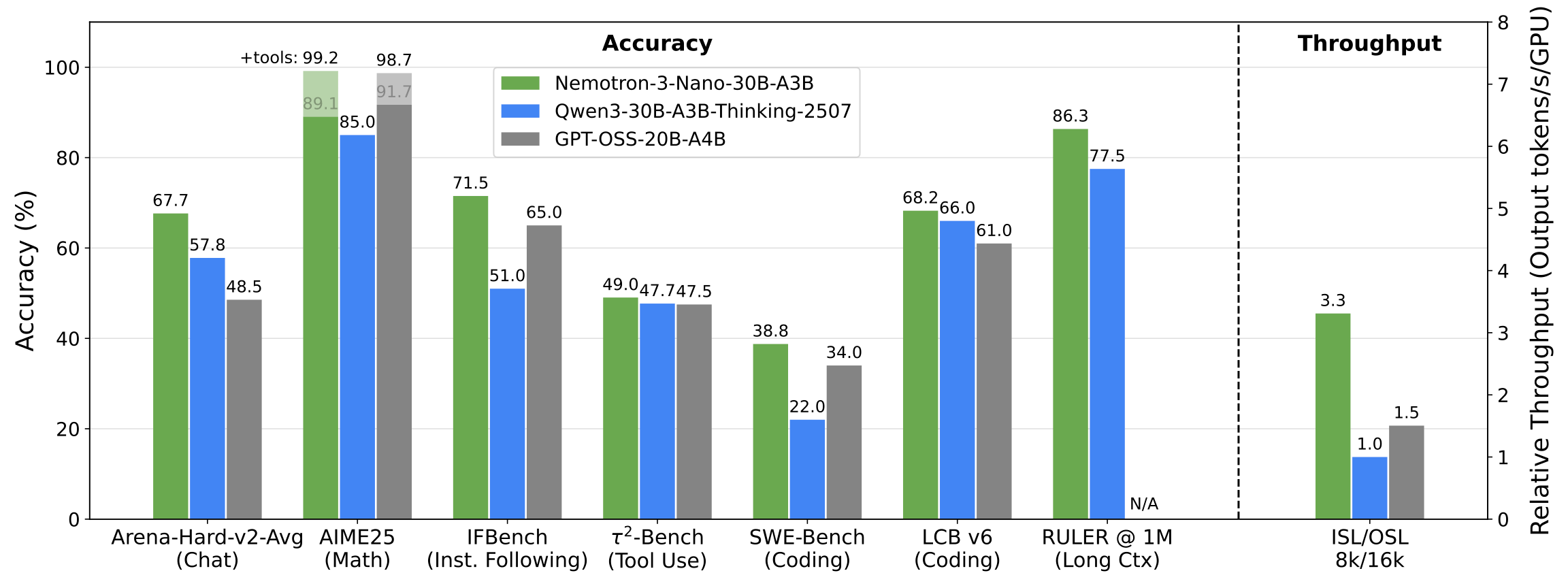
Nano can be used for both reasoning and non-reasoning tasks with an option to turn off the reasoning capabilities through a flag in the chat template. Responses will be less accurate if reasoning is disabled in the configuration.
Nano is a hybrid Mixture-of-Experts (MoE) architecture that consists of 23 Mamba-2 and MoE layers and six attention layers, with each MoE layer including 128 experts plus one shared expert. Five experts are activated per token, making 3.5 billion of the 30 billion total parameters active.
Super and Ultra both use LatentMoE and Multi-Token Prediction (MTP) layers that further increase text generation speed. MTP is the ability to predict multiple tokens at once in a single forward pass instead of only predicting a single token. LatentMoE is a novel approach to assigning experts that compresses the input data size each expert needs to process in order to reduce the amount of computation for each token. They use these efficiency savings to increase the number of experts that can be used for each token.
In NVIDIA’s white paper on the release, they describe Super as optimized for workloads like IT ticket automation where collaborative agents handle large-volume workloads. Ultra is the option to use when accuracy and reasoning performance are paramount.
Step 1 — Creating a GPU Droplet
To deploy the Nemotron 3 Nano on a DigitalOcean GPU Droplet, first, sign in to your DigitalOcean account and create a GPU Droplet.
Choose AI/ML-Ready as your image and select an NVIDIA H100. Add or select an SSH Key, and create the DigitalOcean Droplet.
Step 2 — Connecting to Your GPU Droplet
Once the DigitalOcean Droplet is created, you SSH (Secure Shell) into your server instance. Go to your command line and enter the following command, replacing the highlighted your_server_ip placeholder value with the Public IPv4 of your instance. You can find the IP in the Connection Details section of your GPU Instance Dashboard.
ssh root@your_server_ip
You may get a message that reads:
OutputThe authenticity of host 'your_server_ip (your_server_ip)' can't be established.....Are you sure you want to continue connecting (yes/no/[fingerprint])?
If you do, you can type yes and press ENTER.
Step 3 — Installing Python and vLLM
Next, verify you are still in the Linux instance, and install Python.
sudo apt install python3 python3-pip
It may notify you that additional space will be used and ask if you want to continue. If it does, type Y and press ENTER.
If you receive a “Daemons using outdated libraries” message asking which services to restart, you can press ENTER.
After Python has finished installing, install vLLM.
pip install vllm
This package might take a little while to install. After it is finished installing, download the custom parser from Hugging Face.
wget https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16/resolve/main/nano_v3_reasoning_parser.py
The custom parser interprets Nemotron-3 Nano v3’s reasoning and tool-calling markup so vLLM can correctly serve responses and route tool calls.
Step 4 — Serving the Nemotron Model
Specify exactly which model you want to serve using the model’s ID from Hugging Face.
vllm serve --model nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 \
--max-num-seqs 8 \
--tensor-parallel-size 1 \
--max-model-len 262144 \
--port 8000 \
--trust-remote-code \
--reasoning-parser-plugin nano_v3_reasoning_parser.py \
--reasoning-parser nano_v3
The max-num-seqs is the maximum number of outputs that can be processed concurrently. You can have up to eight single-output requests processed at a single time in this example.
The tensor-parallel-size is the number of GPUs you are spreading the model across via tensor parallelism. One is equal to a single GPU. The max-model-len is the maximum total tokens per request. trust-remote-code is necessary for Nemotron’s custom chat template and parsing logic.
Finally, the reasoning-parser-plugin and reasoning-parser parameters load and select the custom reasoning parser.
Once the model is loaded and served on your instance with vLLM, you can make inference calls to the endpoint using Python locally or from another server. Create a Python file called example_vllm_request.py and run the following code. Replace your_server_ip with the IP address of your GPU Droplet.
import requests
url = "http://your_server_ip:8000/v1/chat/completions"
data = {
"model": "nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 1000
}
response = requests.post(url, json=data)
message = response.json()['choices'][0]['message']['content']
print(message)
You will see output similar to the following:
OutputThe capital of France is **Paris**.
If you print out the entire response.json() object, you can view the reasoning tokens. If you would like to run it with reasoning disabled, you can add a chat_template_kwargs parameter to the data object above.
data = {
"model": "nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"max_tokens": 1000,
"chat_template_kwargs": {"enable_thinking": False},
}
FAQ
What are the hardware requirements and GPU memory needed to run Nemotron 3 Nano locally?
Nemotron 3 Nano can run on GPUs with at least 60 GB of VRAM in BF16 precision, such as an A100 80 GB or H100. A quantized version may allow it to run on GPUs with less memory.
Can I fine-tune Nemotron 3 Nano on my own data, and what are the licensing implications?
Yes, Nemotron 3 models are released under NVIDIA’s open model license, which permits commercial use, modification, and fine-tuning. You retain complete ownership of any outputs generated and can fine-tune the model on custom datasets for your specific use cases.
What is the difference between the Mixture-of-Experts (MoE) architecture and traditional transformer models in terms of inference cost?
The MoE architecture only activates five out of 128 experts per token (3.5B of 30B parameters), making inference much more efficient than traditional dense models.
Has NVIDIA released other LLMs in the past?
Yes, NVIDIA has released a large number of open models and datasets, including other Nemotron model versions, Megatron, ASR models, and more.
Conclusion
The Nemotron 3 family is a comparatively effective and efficient open model with fast inference and accurate results. The smallest version, Nano, is currently available as of January 2026, and the other two larger versions will become available in coming months.
In this tutorial, you deployed Nemotron 3 Nano on a DigitalOcean GPU Droplet. Next, you can build a workflow that uses it for any data sensitive applications that require a high degree of privacy and control.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Andrew is an NLP Scientist with 8 years of experience designing and deploying enterprise AI applications and language processing systems.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
