Machine Learning vs. Natural Language Processing Explained
By Jess Lulka
Content Marketing Manager
- Published:
- 12 min read
Key takeaways:
- Machine learning (ML) is a broad field of AI focusing on algorithms that learn from data to make predictions or decisions, whereas Natural Language Processing (NLP) is a subfield of AI that deals specifically with understanding and generating human language.
- ML provides the techniques (like neural networks, decision trees, etc.) that can be applied across domains, while NLP applies those techniques (and language-specific rules) to tasks such as text analysis, translation, sentiment detection, and speech recognition.
- In essence, NLP is powered by machine learning methods but is specialized for linguistic data, enabling computers to process and interact with human language in applications like chatbots, translators, and voice assistants.
Artificial intelligence (AI) has spawned the entire field of machine learning and, within it, the practical application of natural language processing (NLP). With this evolution, it’s tough to sometimes know the differences between each technology, what they do, and how they intersect to create intelligent, coherent applications that can interact with humans.
According to DigitalOcean’s 2025 Currents report, 79% of respondents are already using AI in some way. This means you’re seeing machine learning and NLP in your day-to-day as you use AI-based software or find yourself training models and refining algorithms to create chatbots, code review software, or other AI tools.
Let’s examine machine learning vs. natural language processing, their main features, use cases, and how the technologies work together.
Experience the power of AI and machine learning with DigitalOcean Gradient GPU Droplets. Leverage NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs to accelerate your AI/ML workloads, deep learning projects, and high-performance computing tasks with simple, flexible, and cost-effective cloud solutions.
Sign up today to access DigitalOcean Gradient GPU Droplets and scale your AI projects on demand without breaking the bank.
What is machine learning?
Machine learning is a subsection of AI that trains computer systems to effectively process and use data. It uses algorithms to detect and learn patterns in data sets. It is used for for computer system automation, data labeling, data collection, large language models, audio classification/recommendation systems, large language models, and more.
Machine learning begins with data collection. These datasets are often very large and collected from a variety of sources, such as customer interactions, sensor readings, server transactions, specific commands, or cloud transactions. After all the data is assembled, it goes into preprocessing. To effectively clean the data, you must eliminate duplicate entries, standardize numerical data formats, fill in missing values, and convert non-numerical values into a machine-readable format.
With clean data in hand, the model selection and training process starts. This requires you to select a specific type of machine learning algorithm, feed the selected data, and calibrate the data as it tries to solve the problem at hand or detect patterns within the dataset. Throughout this process, you’ll continue to provide feedback and adjust parameters to help produce the most accurate outputs.
After the initial training period, you’ll move on to testing and evaluation. This can involve introducing a new, unseen dataset to see how well the model will perform when presented with new information. You can then evaluate if the machine learning model is adequate or requires more training, and start the process again.
Use cases for machine learning include:
-
Image analysis and detection: Machine learning can analyze images to identify patterns or gather specific information. This can include medical imaging analysis, facial recognition, or traffic patterns.
-
Predictive maintenance: When it comes to hardware, sensor data can work with machine learning algorithms to gather machine health data. It can then send updates when the machine requires maintenance or needs replacement.
-
Threat detection: Detection algorithms can help find vulnerabilities across infrastructure systems and then route alerts through the necessary workflows. This can help with more immediate threat detection, but sometimes can cause alert fatigue or false positives.
Types of machine learning
Machine learning requires algorithmic training to effectively discover patterns and produce readable outputs. The four main types of machine learning algorithms are supervised, unsupervised, semi-supervised, and reinforcement learning.
-
Supervised learning: Training data is labeled as either a “correct” or “incorrect” output so the algorithm can learn what is an acceptable output based on the input data. Examples include linear regression, decision trees, neural networks, random forests, and support vector machines.
-
Unsupervised learning: The algorithm finds hidden patterns in the data without any outside input or labeling. Examples are K-means clustering, hierarchical clustering, autoencoders, and principal component analysis.
-
Semi-supervised learning: The dataset has a mix of both labeled and unlabeled inputs. Examples include image classification, text classification, and anomaly detection.
-
Reinforcement learning: An AI agent figures out optimal behavior through repeated behavior in a specified environment. This includes model-based and model-free learning, deep reinforcement learning, multi-agent reinforcement learning, hierarchical reinforcement learning, and value-based and policy-based learning methods.
What is natural language processing?
Natural language processing is a subfield of AI that helps computers process, analyze, and generate human language. It relies on machine learning algorithms to analyze and process text and spoken language. It is ideal for applications such as text classification, semantic analysis, large language modeling, and translation.
Natural language processing uses machine learning and computational linguistics to help further the system’s understanding of natural speech and adjust to any modifications or requirements over time.
Simple language models might be able to identify certain words and phrases in a dataset on their own, but more powerful machine learning algorithms may be able to go even further to effectively grasp the complexity of human language and generate more sophisticated outputs.
Implementation of natural language processing is just like any machine learning. It requires data collection, data pre-processing, and model training. However, the pre-processing phase uses several techniques (tokenization, stemming, lemmatization, and stop word removal) to ensure the data is useful for training.
Use cases for natural language processing include:
-
Large language models (LLMs): This NLP model type is designed to comprehend and generate human language at a more advanced level than smaller models. LLMs can be used for knowledge base answers, code generation, copywriting, and text generation and classification.
-
Language translation: Machine-based translation (NLP) can translate large amounts of text from one language to another and help with language classification and identification.
-
Predictive text: Formerly known as natural language generation (NLG), this use case will provide predictive text for any type of written format, such as emails, documents, texts, or social media posts. It can also adapt over time to learn your preference for specific phrases or words to fit your writing style.
Natural language processing techniques
There are a few techniques that NLP uses to gather information and parse language. They are:
-
Tokenization: This breaks down text in a dataset so it is machine-readable and can help the algorithm identify patterns without losing context. NLP can use word, character, or subword tokenization. For example, the machine could break down the phrase “DigitalOcean is scalable” into [“Digital”, “Ocean”, “is”, “scalable”]. or [“DigitalOcean”, “is scalable”]. to look for patterns or gather context.
-
Sentiment analysis: This technique analyzes text to determine if its tone is positive, negative, or neutral. The data is preprocessed via tokenization, lemmatization, and filler word removal. The algorithm then uses keywords to gauge sentiment and provide feedback on perceived emotions within the given text. In this case, the sentence “Developers can use Linux virtual machines as an affordable option." might be classified as “Developers (entity) Linux (entity) virtual machines (entity) affordable” (positive).
-
Named entity recognition: Also known as entity extraction, chunking, and identification, this technique involves the NLP algorithm identifying certain elements. These could be names, locations, products, themes, monetary values, or topics. The algorithm can use supervised machine learning, rule-based systems, dictionary-based systems, or deep learning systems to extract information. One use case could be to search a large chunk of text for “DigitalOcean,” “Droplets,” and “50%”.
NLP also relies on supervised and unsupervised machine learning to refine its knowledge base and increase accuracy. It’s impossible for NLP to work effectively without datasets or any sort of algorithm training. This process involves processing the data, feeding the NLP model the labeled or unlabeled dataset, evaluating its performance, and then further model optimization.
Machine learning vs. natural language processing
The biggest commonality between machine learning and natural language processing is that they are subsets of AI. NLP uses machine learning and Deep Learning to complete more complex applications and tasks. However, the two technologies have differences regarding their main functions, data types, use cases, algorithm types, and computational complexity.
Machine learning is designed to make predictions from a designated dataset and recognize patterns. It uses structured and unstructured data along with clustering, classification, or regression algorithms for analysis and optimization. The complexity of these models will increase with the size of the dataset and type of data (such as images vs. numbers). Machine learning is also applicable to many industries and is seeing advancements for a variety of use cases.
Since NLP is a machine learning use case, it is narrower in its scope and requirements. It is mainly used for language-based applications and use cases, so you can effectively interact with computers through text-based language. It relies on text and speech input to run sentiment detection, semantic analysis, and parsing algorithms. Due to the variability of human language, NLP models are usually very complex and computationally intensive, and can be tricky to interpret. The most recent advancements in NLP have focused on conversational AI.
| Feature | Machine Learning | Natural Language Processing |
|---|---|---|
| Definition | Models that learn to make predictions from data | Systems that learn to understand and generate language |
| Primary function | Optimization, prediction, and pattern recognition | Language comprehension and interaction |
| Input data types | Unstructured and structured | Mainly unstructured, text, and speech |
| Algorithm types | Clustering, classification, regression | Sentiment detection, semantic analysis, and parsing |
| Use cases | Predictions, recommendations, and image recognition | Language translation, chatbots, and sentiment analysis |
| Computational complexity | Data and model dependent | Increases depending on the scale of text or speech analysis |
| Model interpretability | Varies by algorithm | Complex because of language context |
| Need for feature engineering | Important for most uses and applications | Combined with linguistic preprocessing |
Here’s how the overlap of machine learning vs. natural language processing might look in relation to AI and deep learning:
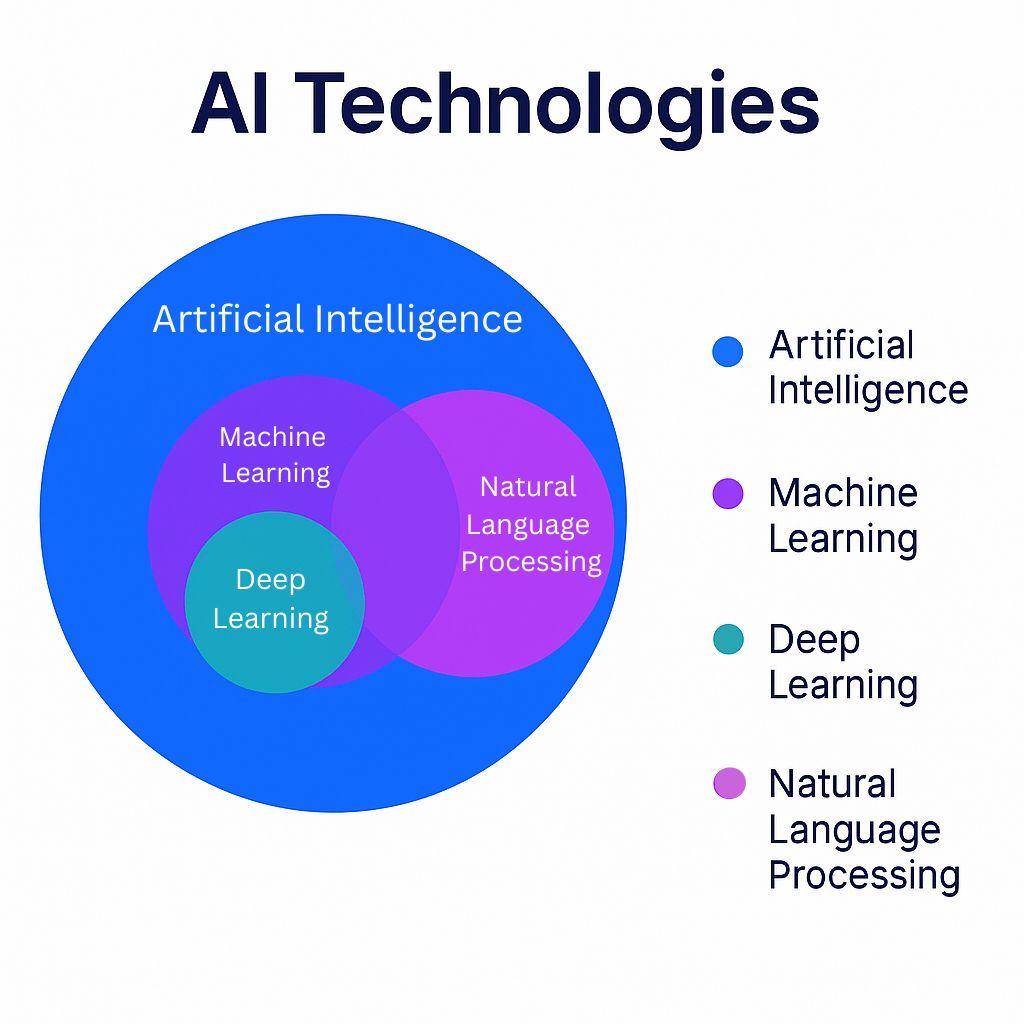
How ML and NLP work together in AI applications
Machine learning and NLP are often used together in AI-based business applications. Machine learning datasets and algorithms can provide a base-level understanding of language and detect speech or word patterns. NLP can then use sentiment analysis, tokenization, or named entity recognition to learn more about the text.
Together, the two technologies can support applications such as:
Chatbots
Originally designed to answer simple, one-off questions, chatbots have evolved over time and can now support more in-depth conversations. Natural language processing now enables AI chatbots to analyze and determine the nature of the request and the tone of the question and then turn the request into a machine-readable query. Once the system receives this query, it can follow the appropriate workflow to respond to the original request. Machine learning supports NLP and learns over time what queries are most popular and how to provide the correct or most helpful response.
Code review
You can use machine learning and NLP tools to review code for function, quality, and style. These tools can provide suggestions or automated fixes, reducing the time spent manually reviewing and updating code. Machine learning models help identify inconsistencies and vulnerabilities across code bases via static code analysis, dynamic code analysis, and rule-based systems. NLP models can then review code syntax and structure, and catch errors that might affect code performance or cause issues once the code is deployed.
Common challenges with machine learning and natural language processing
Even with all the interesting applications of machine learning and NLP, there are still challenges. The two main ones that often surface are explainability and scalability.
Explainability
With machine learning, though algorithms can produce useful information and identify key patterns, the code can change over time without manual input, and is often done so without explanation. This makes it hard to track code changes and sometimes understand outputs. In the case of NLP, explainability can be difficult as linguistic and contextual nuances might make it harder to understand certain model choices or decisions.
You and your team might require professional expertise or implement specific tools to increase explainability and effectively understand the relationships between any input data and its output.
Scalability
Both machine learning and NLP require lots of data at scale for adequate training and performance. This creates issues around storing large data volumes, collecting a variety of data, efficient data processing, and having enough compute power for all of these functions.
Additionally, at a certain level of complexity, your team might have to consider tradeoffs between model complexity and computational efficiency. You can address some of these challenges with data management best practices and by ensuring that you choose a cloud provider familiar with the scalability challenges of AI/machine learning.
Want to be able to scale your infrastructure and keep costs in line? Quickly spin up your virtual infrastructure in seconds with DigitalOcean’s Droplets. Suited for general computing workloads all the way to AI/ML training, you can find the ideal VM for your needs.
→ Get started with Droplets
Machine learning and natural language processing FAQs
What is the main difference between machine learning and NLP?
Both machine learning and natural language processing are subsets of AI. The main difference is their primary objective. Machine learning focuses on pattern recognition and detection. Natural language processing looks at language standards and language-related tasks.
How does machine learning help NLP?
Machine learning helps natural language processing identify patterns in human speech, pick up contextual clues, understand context, specific sections of speech, and specific components of text or voice inputs.
Is NLP a type of machine learning?
No, NLP is not a type of machine learning. It relies on deep learning, computational linguistics, and machine learning to analyze and process language.
What are some common applications of NLP?
NLP’s common applications include chatbots, grammar checking, plagiarism detection, language translation, text analysis and categorization, sentiment analysis, and speech and voice recognition.
How do deep learning and NLP work together?
Deep learning models help NLP recognize speech patterns based on text input without specific programming requirements and increase overall task accuracy. Before deep learning algorithms, most NLP tasks relied on rule-based methods and human expertise to classify language.
Can NLP exist without machine learning?
Generally, no. NLP relies on machine learning to help with complex language analysis. But rule-based NLP (which uses pre-defined linguistic rules) does not require machine learning and can help pre-process text data.
Resources
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean Gradient GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean Gradient GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Jess Lulka is a Content Marketing Manager at DigitalOcean. She has over 10 years of B2B technical content experience and has written about observability, data centers, IoT, server virtualization, and design engineering. Before DigitalOcean, she worked at Chronosphere, Informa TechTarget, and Digital Engineering. She is based in Seattle and enjoys pub trivia, travel, and reading.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
