
Introduction
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution which can be run on Linux, macOS, and FreeBSD. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers (e.g. web, application, database). It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
In this guide, you’ll get a general overview of what HAProxy is, review load-balancing terminology, and examples of how it might be used to improve the performance and reliability of your own server environment.
HAProxy Terminology
There are many terms and concepts that are important when discussing load balancing and proxying. You’ll go over commonly used terms in the following subsections.
Before you get into the basic types of load balancing, you should begin with a review of ACLs, backends, and frontends.
Access Control List (ACL)
In relation to load balancing, ACLs are used to test some condition and perform an action (e.g. select a server, or block a request) based on the test result. Use of ACLs allows flexible network traffic forwarding based on a variety of factors like pattern-matching and the number of connections to a backend, for example.
Example of an ACL:
acl url_blog path_beg /blog
This ACL is matched if the path of a user’s request begins with /blog. This would match a request of http://yourdomain.com/blog/blog-entry-1, for example.
For a detailed guide on ACL usage, check out the HAProxy Configuration Manual.
Backend
A backend is a set of servers that receives forwarded requests. Backends are defined in the backend section of the HAProxy configuration. In its most basic form, a backend can be defined by:
- which load balance algorithm to use
- a list of servers and ports
A backend can contain one or many servers in it. Generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
Here is an example of a two backend configuration, web-backend and blog-backend with two web servers in each, listening on port 80:
backend web-backend
balance roundrobin
server web1 web1.yourdomain.com:80 check
server web2 web2.yourdomain.com:80 check
backend blog-backend
balance roundrobin
mode http
server blog1 blog1.yourdomain.com:80 check
server blog1 blog1.yourdomain.com:80 check
balance roundrobin line specifies the load balancing algorithm, which is detailed in the Load Balancing Algorithms section.
mode http specifies that layer 7 proxying will be used, which is explained in the Types of Load Balancing section.
The check option at the end of the server directives specifies that health checks should be performed on those backend servers.
Frontend
A frontend defines how requests should be forwarded to backends. Frontends are defined in the frontend section of the HAProxy configuration. Their definitions are composed of the following components:
- a set of IP addresses and a port (e.g. 10.1.1.7:80, *:443, etc.)
- ACLs
use_backendrules, which define which backends to use depending on which ACL conditions are matched, and/or adefault_backendrule that handles every other case
A frontend can be configured to various types of network traffic, as explained in the next section.
Types of Load Balancing
Now that you have an understanding of the basic components that are used in load balancing, you can move into the basic types of load balancing.
No Load Balancing
A simple web application environment with no load balancing might look like the following:
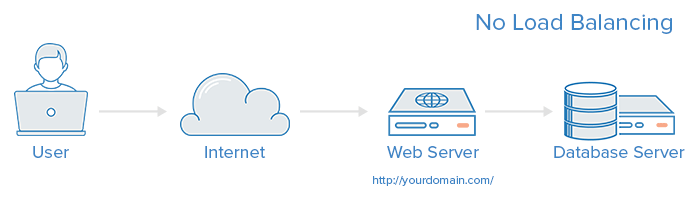
In this example, the user connects directly to your web server, at yourdomain.com and there is no load balancing. If your single web server goes down, the user will no longer be able to access your web server. Additionally, if many users are trying to access your server simultaneously and it is unable to handle the load, they may have a slow experience or they may not be able to connect at all.
Layer 4 Load Balancing
The simplest way to load balance network traffic to multiple servers is to use layer 4 (transport layer) load balancing. Load balancing this way will forward user traffic based on IP range and port (i.e. if a request comes in for http://yourdomain.com/anything, the traffic will be forwarded to the backend that handles all the requests for yourdomain.com on port 80). For more details on layer 4, check out the TCP subsection of our Introduction to Networking.
Here is a diagram of a simple example of layer 4 load balancing:
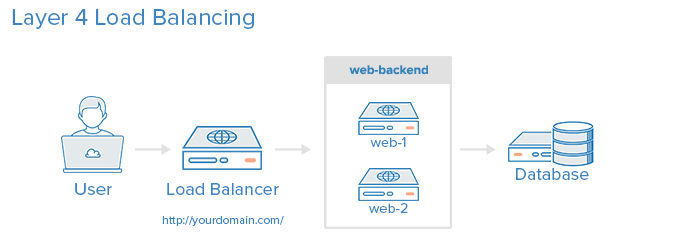
The user accesses the load balancer, which forwards the user’s request to the web-backend group of backend servers. Whichever backend server is selected will respond directly to the user’s request. Generally, all of the servers in the web-backend should be serving identical content–otherwise the user might receive inconsistent content. Note that both web servers connect to the same database server.
Layer 7 Load Balancing
Another, more complex way to load balance network traffic is to use layer 7 (application layer) load balancing. Using layer 7 allows the load balancer to forward requests to different backend servers based on the content of the user’s request. This mode of load balancing allows you to run multiple web application servers under the same domain and port. For more details on layer 7, check out the HTTP subsection of our Introduction to Networking.
Here is a diagram of a simple example of layer 7 load balancing:
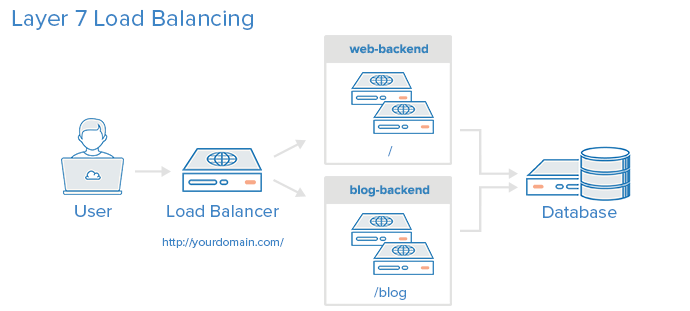
In this example, if a user requests yourdomain.com/blog, they are forwarded to the blog backend, which is a set of servers that run a blog application. Other requests are forwarded to web-backend, which might be running another application. Both backends use the same database server, in this example.
A snippet of the example frontend configuration would look like this:
frontend http
bind *:80
mode http
acl url_blog path_beg /blog
use_backend blog-backend if url_blog
default_backend web-backend
This configures a frontend named http, which handles all incoming traffic on port 80.
acl url_blog path_beg /blog matches a request if the path of the user’s request begins with /blog.
use_backend blog-backend if url_blog uses the ACL to proxy the traffic to blog-backend.
default_backend web-backend specifies that all other traffic will be forwarded to web-backend.
Load Balancing Algorithms
The load balancing algorithm that is used determines which server, in a backend, will be selected when load balancing. HAProxy offers several options for algorithms. In addition to the load balancing algorithm, servers can be assigned a weight parameter to manipulate how frequently the server is selected, compared to other servers.
A few of the commonly used algorithms are as follows:
roundrobin
Round Robin selects servers in turns. This is the default algorithm.
leastconn
Selects the server with the least number of connections. This is recommended for longer sessions. Servers in the same backend are also rotated in a round-robin fashion.
source
This selects which server to use based on a hash of the source IP address that users are making requests from. This method ensures that the same users will connect to the same servers.
Sticky Sessions
Some applications require that a user continues to connect to the same backend server. This can be achieved through sticky sessions, using the appsession parameter in the backend that requires it.
Health Check
HAProxy uses health checks to determine if a backend server is available to process requests. This avoids having to manually remove a server from the backend if it becomes unavailable. The default health check is to try to establish a TCP connection to the server.
If a server fails a health check, and therefore is unable to serve requests, it is automatically disabled in the backend, and traffic will not be forwarded to it until it becomes healthy again. If all servers in a backend fail, the service will become unavailable until at least one of those backend servers becomes healthy again.
For certain types of backends, like database servers, the default health check is not necessarily to determine whether a server is still healthy.
The Nginx web server can also be used as a standalone proxy server or load balancer, and is often used in conjunction with HAProxy for its caching and compression capabilities.
High Availability
The layer 4 and 7 load balancing setups described in this tutorial both use a load balancer to direct traffic to one of many backend servers. However, your load balancer is a single point of failure in these setups; if it goes down or gets overwhelmed with requests, it can cause high latency or downtime for your service.
A high availability (HA) setup is broadly defined as infrastructure without a single point of failure. It prevents a single server failure from being a downtime event by adding redundancy to every layer of your architecture. A load balancer facilitates redundancy for the backend layer (web/app servers), but for a true high availability setup, you need to have redundant load balancers as well.
Here is a diagram of a high availability setup:

In this example, you have multiple load balancers (one active and one or more passive) behind a static IP address that can be remapped from one server to another. When a user accesses your website, the request goes through the external IP address to the active load balancer. If that load balancer fails, your failover mechanism will detect it and automatically reassign the IP address to one of the passive servers. There are a number of different ways to implement an active/passive HA setup. To learn more, read How To Use Reserved IPs.
Conclusion
Now that you have an understanding of load balancing, and know how to make use of HAProxy, you have a solid foundation to get started on improving the performance and reliability of your own server environment.
If you’re interested in storing HAProxy’s output for later viewing, check out How To Configure HAProxy Logging with Rsyslog on CentOS 8 [Quickstart]
If you’re looking to solve an issue, check out Common HAProxy Errors. If even further troubleshooting is needed, take a look at How To Troubleshoot Common HAProxy Errors.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Load Balancing WordPress with HAProxy
Adding a load balancer to your server environment is a great way to increase reliability and performance. The first tutorial in this series will introduce you to load balancing concepts and terminology, followed by two tutorials that will teach you how to use HAProxy to implement layer 4 or layer 7 load balancing in your own WordPress environment. The last tutorial covers SSL termination with HAProxy.
About the author
Software Engineer @ DigitalOcean. Former Señor Technical Writer (I no longer update articles or respond to comments). Expertise in areas including Ubuntu, PostgreSQL, MySQL, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
If your load balancer went down in the environment described in this article, your site would become unavailable.
The easiest way to avoid having the load balancer be a single point of failure is to set up active/passive HAProxy pair. This would require two HAProxy servers and a virtual IP that can float between the two servers. The active HAProxy server would handle all of the requests unless it went down, at which point the passive HAProxy server would take over the requests.
@idanielinc: In this set up, the load balancer is still a single point of failure. This is still a fairly basic set up to illustrate the concepts. For true “high availability” you’d need to have multiple HAProxy servers with some sort of failover using VRRP (http://en.wikipedia.org/wiki/Virtual_Router_Redundancy_Protocol). Keepalived (http://www.keepalived.org/) is often used for this.
Take a look at route53 or another dns service that supports health checks. You can run two load balancers and if there is a problem it should automatically switch your sites IP to the redundant LB. If you set a low TTL on your sites A record it shouldn’t be too bad. I haven’t tried this ‘yet’ but it may be a replacement for a floating virtual ip?
I want to send requests to different backends, depending on the status of the response. I mean, one backend will be the primary one, receiving all requests if it is available, and the second backend will only be used when the first one is not available. If, in the first backend, the server is unavailable (response status code = 503), I would like to send the request to the second backend, but I have a problem when creating an ACL with the check of the status response to decide which backend to use.
The frontend part in my configuration file looks like the following (assuming my two groups of backends are named ‘backend_servers’, the primary one, and ‘backend_servers2’, the secondary one):
acl statusResponse status eq 503 use_backend backend_servers2 if statusResponse default_backend backend_servers
The HAProxy is returning the following error:
acl ‘statusResponse’ will never match because it only involves keywords that are incompatible with ‘frontend use-backend rule’
How can I get the desired balancing? (i.e. having a primary backend and a secondary backend, only used when the primary is not available).
@angelica1988: When you get 503 from the backend, this means that the request has already been received by HAProxy and routed to the backend and at this point the load balancing decision has been made. I think what you need is a http health check for the backend servers that will disable them if they respond with 503. The deeper the health check the better.
About that response:
“If your load balancer went down in the environment described in this article, your site would become unavailable. The easiest way to avoid having the load balancer be a single point of failure is to set up active/passive HAProxy pair. This would require two HAProxy servers and a virtual IP that can float between the two servers. The active HAProxy server would handle all of the requests unless it went down, at which point the passive HAProxy server would take over the requests.”
Can I have a virtual IP that can float between the two servers with Digital Ocean? How can I configure this?
I have two droplets with active/passive HAProxy pair + keepalived, but I don’t know how to set up the Virtual IP.
Thanks!
Nice tutorial mitch, if i may ask what is the image tool you used to created the gif image for “NYC3 high availability setup”?
Hi, In the article’s “Backend” section :
"backend blog-backend balance roundrobin mode http server blog1 blog1.yourdomain.com:80 check server blog1 blog1.yourdomain.com:80 check "
Kindly update the blog-backend second server to server blog2 blog2.yourdomain.com:80 check
Thanks, Reema
How can we achieve Load Balancing without using DNS server? And can we use one of the real server as a Load Balancer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.