AI/ML Technical Content Strategist

One of our favorite applications of language-based Deep Learning technology that has spread across the web is the ability to mimic the speech patterns and knowledge of fictional characters. We can say this for a number of reasons, but we want to hone in on the entertainment and educational value of these tools first and foremost. There is just too much fun and learning to be had by conversing with these “characters.”
The best place to get started and join in on these conversations is at character.ai. Powered and accelerated by DigitalOcean, character.ai is the premiere platform where users can chat with, create, and roleplay with AI personalities based on fictional characters, historical figures, or entirely original creations, using text or voice. With character, it is easy to get started chatting with any of your favorite characters, historical figures, and more within just moments. Not only is there an existing, large library of characters to choose from, but the website also makes it simple to make your own character AIs. Furthermore, they even have a talk feature that is mind-blowingly fast and makes it possible to converse in real-time with these agentic characters with speech.
But what if we want to go further? We have custom audio responses from these models, so the next step is to add video! This is now possible with the power of LTX-2.
In this tutorial, we will show how to use LTX-2 to create an interactive conversational video with an AI powered character. This pipeline starts from generating the text/audio on character.ai, and then shows how to use Qwen3-TTS to create the characters voice from source media or text descriptions, and finally concludes with using LTX-2 to animate a still image of the character to speak with the generated speech. Follow along for a full walkthrough and demo of the pipeline, with brief introductions to the technologies used.
Key Takeaways
- character.ai can be combined with open-source tools like LTX-2 and Qwen3-TTS to make videos of the characters, extending the potential of all tools through combination
- LTX-2 is a powerful video generation model rivaling closed-source models like Kling and Sora
- Qwen3-TTS is incredibly versatile, and can capably clone voices in moments to generate realistic speech from text
The Pipeline
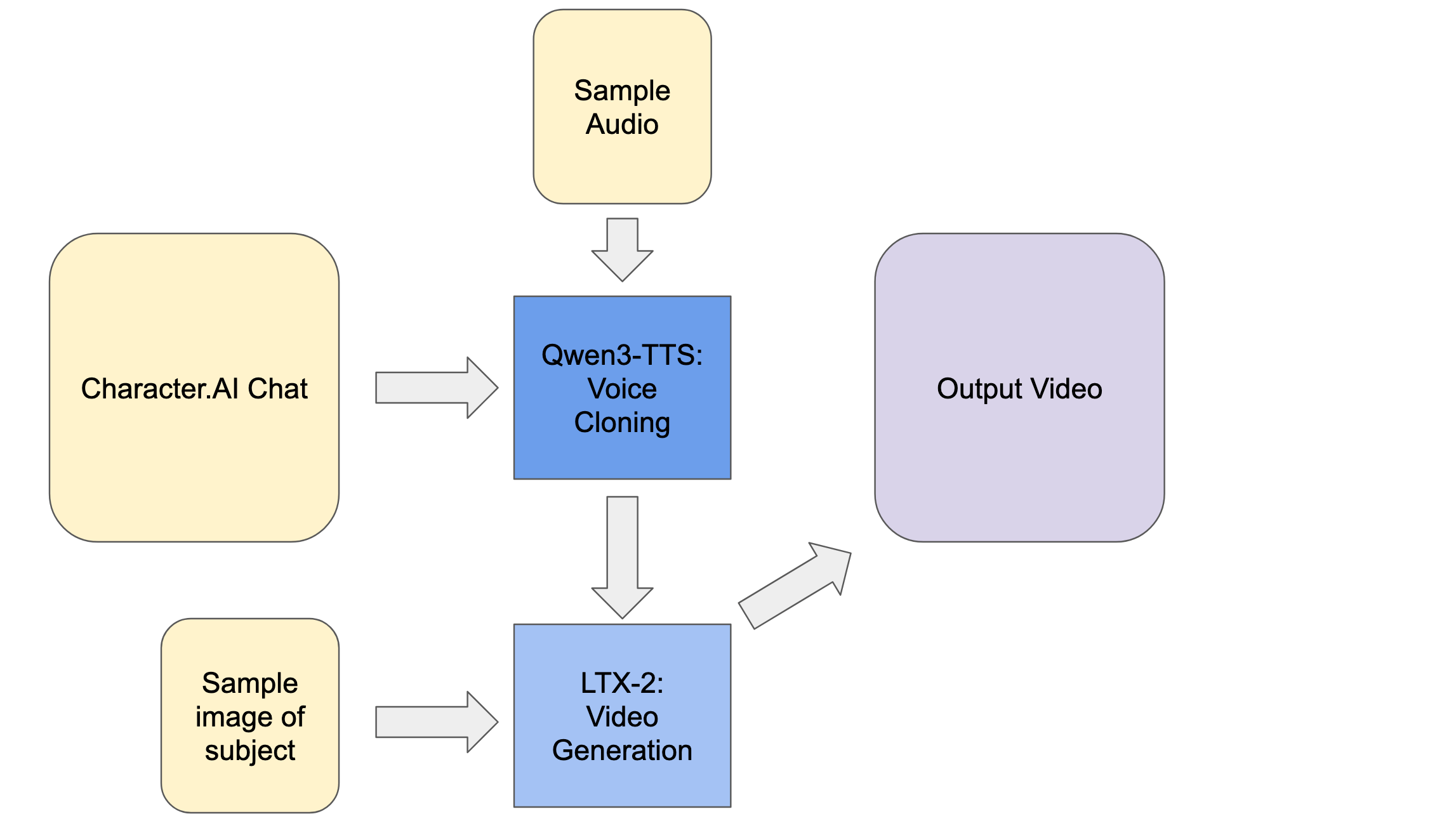
Above, we can see the pipeline for creating the videos. First, we are going to generate our inputs using character AI, and source the rest from the internet. These are then loaded into Qwen3-TTS and, subsequently, LTX-2 to generate the final output. Follow along for an in depth explanation of each of the components.
character.ai
To get started, we need to chat with a character of our choice at character.ai. These LLM powered characters are some of the best GPT based conversational agents on the internet! Choose one that resonates with you and has a voice that can be sourced somewhere from the internet. Popular characters from entertainment media make the best subjects because we can source their voices from places like YouTube. Once you have picked out your character, input your request to the model. This will give a response in the character’s tone and with their “knowledge”. We can then take this as our input for the next part of the pipeline, Qwen3-TTS CustomVoice
Qwen3-TTS CustomVoice
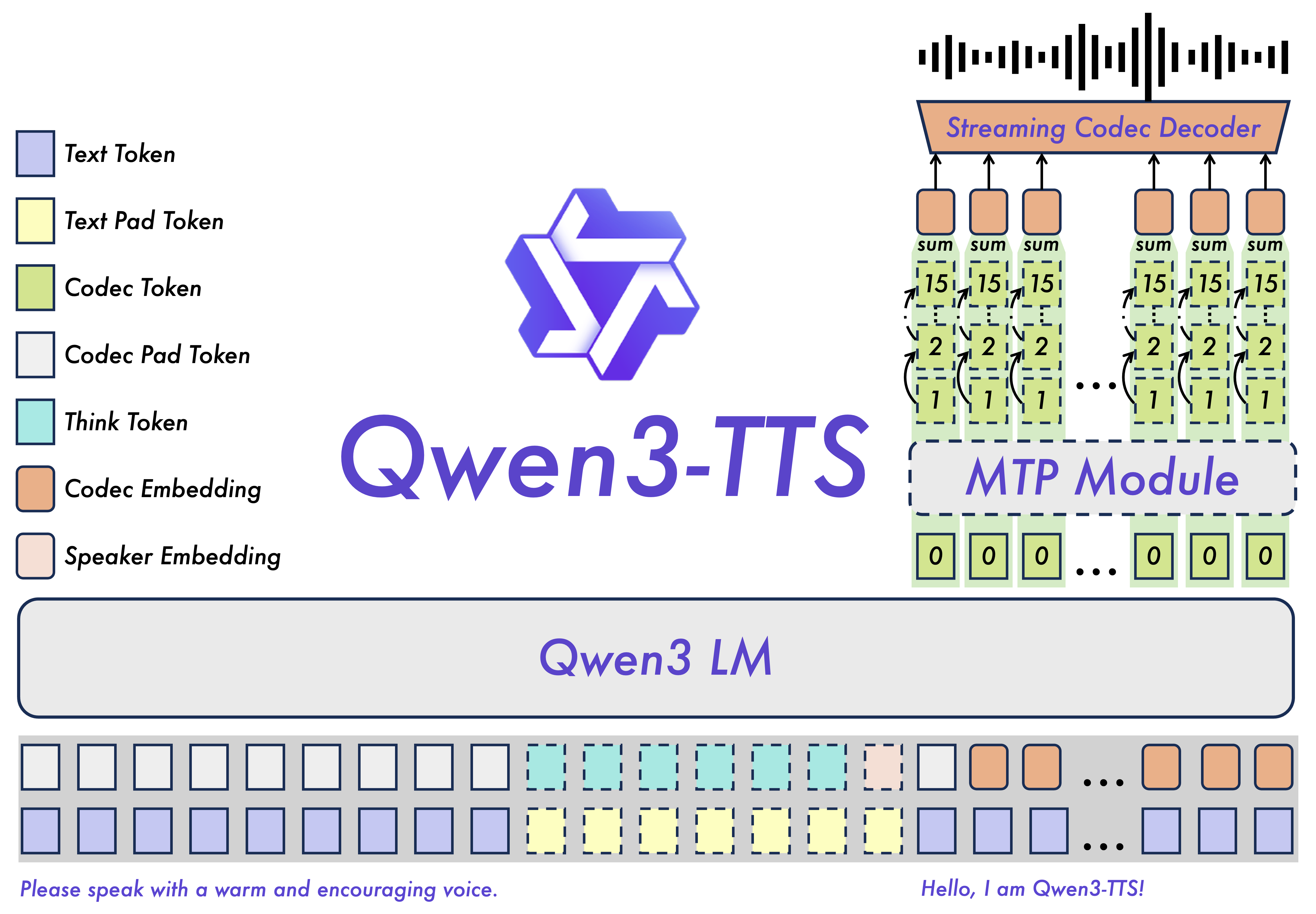
Qwen3-TTS is a multilingual, low-latency text-to-speech system supporting ten major languages and multiple dialectal voice profiles, designed for global, real-time applications with strong contextual understanding that enables dynamic control of tone, speed, prosody, and emotional expression even from noisy input text. Built on the Qwen3-TTS-Tokenizer-12Hz and a universal end-to-end discrete multi-codebook architecture, it preserves rich paralinguistic and acoustic detail while avoiding the bottlenecks and cascading errors of traditional Language Model + Diffusion Transformer pipelines, delivering efficient, high-fidelity speech generation. Its Dual-Track hybrid streaming design allows a single model to handle both streaming and non-streaming synthesis, emitting audio after a single character and achieving end-to-end latency as low as 97 ms, while natural-language-driven voice control ensures lifelike, intent-aligned speech output.
We are using Qwen3-TTS to clone the voice of our subject. This is where Youtube and other resources come in. Get a clear audio recording of your subject ready for the next step.
LTX-2
We are using LTX-2 as the driver for this pipeline. It does the work of animating a still image of our character for us, and matching the visuals to the audio stream. Recent text-to-video diffusion systems like Wan2.2 and Hunyuan 1.5 are awesome, but lacking in this way. What we mean by this is that they are capable of producing visually compelling sequences, but they typically lack synchronized audio, omitting the semantic, emotional, and atmospheric dimensions that sound provides (Source).
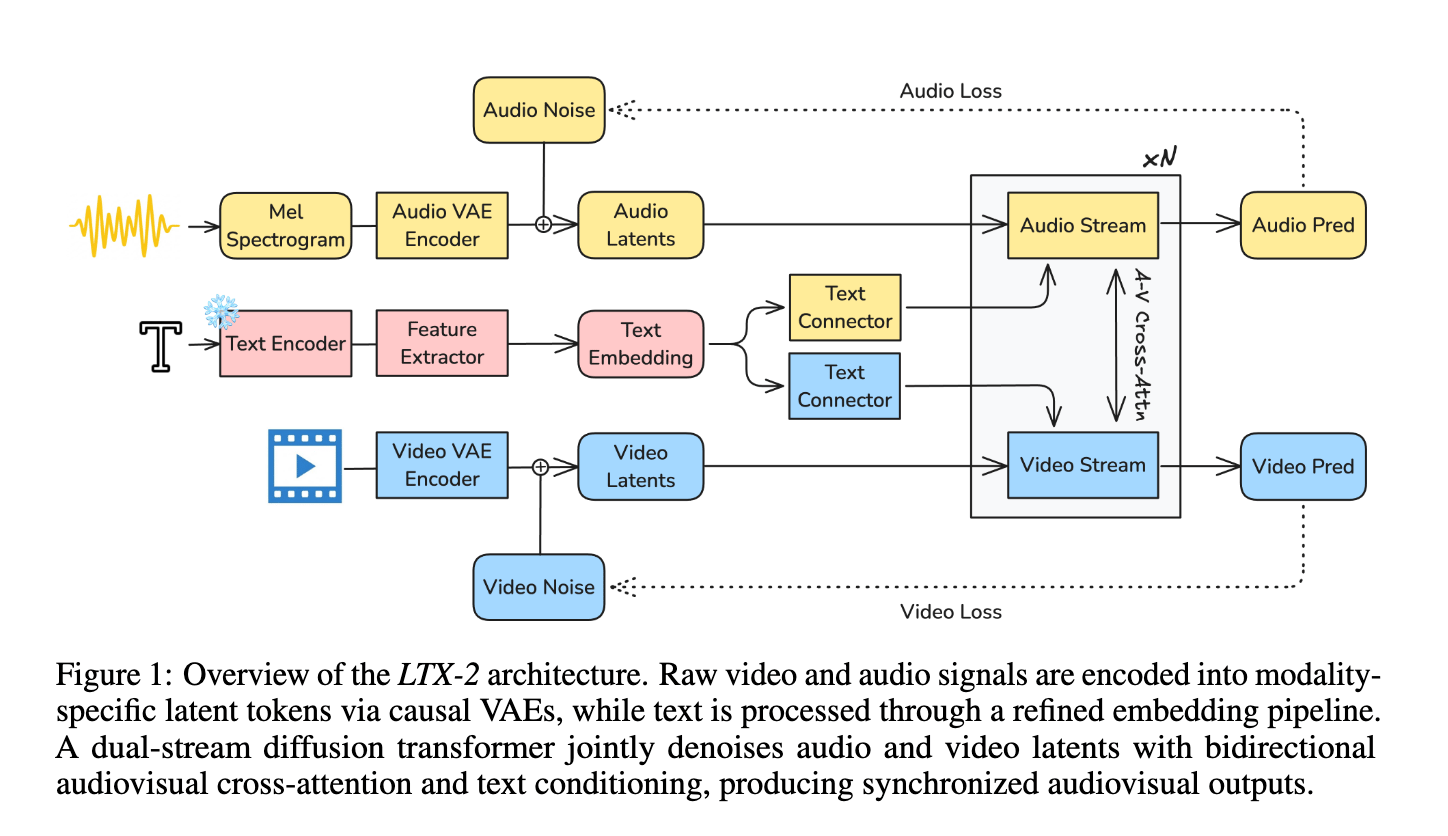
To address this gap, Lightricks created a new flagship, foundation model: LTX-2. An open-source foundational model that generates high-quality, temporally aligned audiovisual content within a single unified framework, LTX-2 is built around an asymmetric dual-stream transformer architecture. It consists of a 14B-parameter video stream and a 5B-parameter audio stream, interconnected via bidirectional audio–video cross-attention layers that incorporate temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This design enables efficient joint training and inference while deliberately allocating greater model capacity to video generation than audio. The system employs a multilingual text encoder to improve prompt comprehension across languages and introduces a modality-aware classifier-free guidance (modality-CFG) mechanism to enhance audiovisual alignment and controllability (Source).
Beyond speech synthesis, LTX-2 generates rich, coherent audio tracks that reflect on-screen characters, environmental context, stylistic intent, and emotional tone, including natural background ambience and foley effects. Empirically, LTX-2 achieves state-of-the-art audiovisual quality and prompt adherence among open-source models, delivering performance comparable to proprietary systems while requiring significantly less compute and inference time, with all model weights and code fully released to the public (Source).
Demo
Now that we have outlined the pipeline, we can begin the demonstration. To get started, first follow the instructions in this environment setup tutorial for GPU Droplets. It outlines everything you need to do to set up your environment for this demo. First, we create our GPU Droplet with sufficient power to run the demo, ideally an NVIDIA H200. Then, we access the GPU Droplet from our local machine using SSH to the terminal and VS Code/Cursor’s Simple Browser feature.
Once your machine is spun up, proceed to the next section.
Setting up the ComfyUI for LTX-2
Copy and paste the following code snippet into your terminal window. Make sure you are first in the directory of your choice!
git clone https://github.com/Comfy-Org/ComfyUI
cd ComfyUI
python3 -m venv venv_comfy
source venv_comfy/bin/activate
pip install -r requirements.txt
cd models/diffusion_models/
wget https://huggingface.co/Lightricks/LTX-2/resolve/main/ltx-2-19b-dev.safetensors
cd ../loras/
wget https://huggingface.co/Lightricks/LTX-2/resolve/main/ltx-2-19b-distilled-lora-384.safetensors
cd ../vae
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/VAE/LTX2_video_vae_bf16.safetensors
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/VAE/LTX2_audio_vae_bf16.safetensors
cd ../text_encoders/
wget https://huggingface.co/Kijai/LTXV2_comfy/resolve/main/text_encoders/ltx-2-19b-embeddings_connector_dev_bf16.safetensors
wget https://huggingface.co/DreamFast/gemma-3-12b-it-heretic/resolve/main/comfyui/gemma_3_12B_it_heretic.safetensors
cd ../checkpoints
wget https://huggingface.co/Kijai/MelBandRoFormer_comfy/resolve/main/MelBandRoformer_fp32.safetensors
cd ../..
python main.py
This process will take a few minutes, but once completed, you will have the output ComfyUI URL. Copy it and put it in the Simple Browser of your VS Code/Cursor connected to the machine via SSH. Then, click the arrow in the top right corner of the Simple Browser to open the ComfyUI in your default browser on your local machine. Finally, take the JSON file template, and upload it to the ComfyUI to get started with the template. It should look something like this:
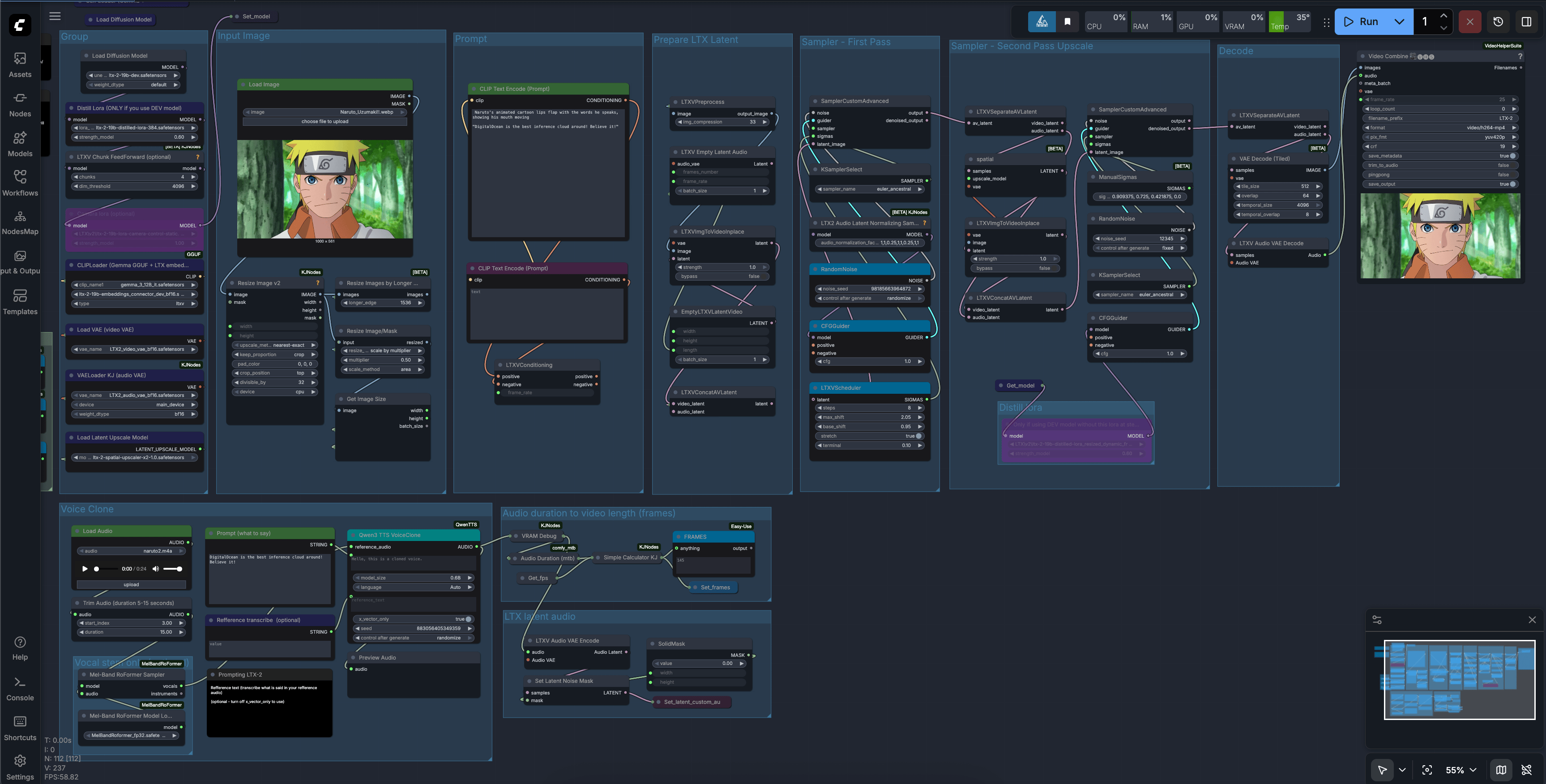
This example uses a popular anime character, but you can replace it with whatever character you like. Take the audio sample you sourced earlier for cloning, the response to your question generated by character AI, the image of your character you want to use as the base sample for the video, and fill in the template with these values. Then, click run to generate the video. If you use the sample we provided, it should look something like this (note while we did generate sound, we are unable to share the video on this platform):

Now you can modify this workflow as needed! The pipeline is extremely versatile, able to take on a variety of voices and animate a variety of subjects in different mediums like anime, cartoon, artwork, and real life. This has a variety of uses, like creating visualizations for interviews, animating speech for characters in scenes, and much more!
Closing thoughts
By combining character.ai’s expressive, real-time dialogue with Qwen3-TTS voice synthesis and LTX-2’s unified audiovisual generation, this pipeline shows how quickly character conversations can evolve from text on a screen into fully animated, speaking personas. What once required complex, bespoke animation and audio workflows can now be prototyped by a single developer with open-source tools and a GPU, unlocking new possibilities for storytelling, education, entertainment, and interactive media. As audiovisual foundation models like LTX-2 continue to mature, the line between chatting with a character and watching them come alive on screen will only keep getting thinner.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
