
Introdução
Se você estiver desenvolvendo ativamente um aplicativo, usar o Docker pode simplificar seu fluxo de trabalho e o processo de implantação do seu aplicativo para produção. Trabalhar com contêineres no desenvolvimento oferece os seguintes benefícios:
- Os ambientes são consistentes, o que significa que você pode escolher as linguagens e dependências que quiser para seu projeto sem se preocupar com conflitos de sistema.
- Os ambientes são isolados, tornando mais fácil a resolução de problemas e a adição de novos membros de equipe.
- Os ambientes são portáteis, permitindo que você empacote e compartilhe seu código com outros.
Este tutorial mostrará como configurar um ambiente de desenvolvimento para um aplicativo Ruby on Rails usando o Docker. Você criará vários contêineres - para o aplicativo em si, o banco de dados PostgreSQL, o Redis e um serviço Sidekiq — com o Docker Compose. A configuração fará o seguinte:
- Sincronize o código do aplicativo no host com o código no contêiner para facilitar as alterações durante o desenvolvimento.
- Mantenha os dados do aplicativo entre as reinicializações do contêiner.
- Configure os threads de trabalho do Sidekiq para processar os trabalhos, conforme o esperado.
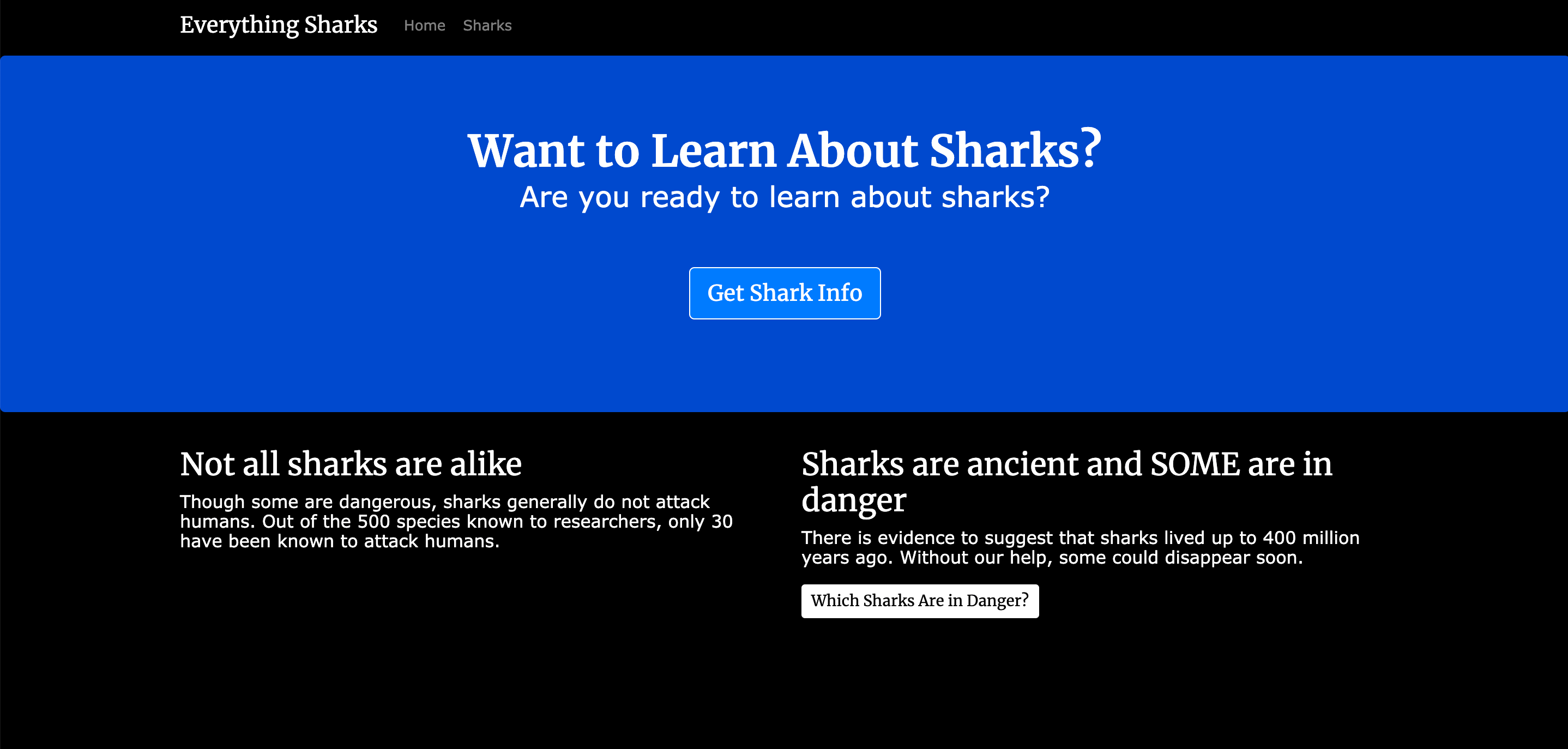
No final deste tutorial, você terá um aplicativo funcional de informações sobre tubarões sendo executado em contêineres do Docker:
Pré-requisitos
Para seguir este tutorial, será necessário:
- Um servidor ou máquina de desenvolvimento local executando o Ubuntu 18.04, junto com um usuário não raiz com privilégios
sudoe um firewall ativo. Para saber como configurar isso, consulte este guia de Configuração inicial do servidor. - O Docker instalado no seu computador local, seguindo os Passos 1 e 2 do artigo sobre Como instalar e usar o Docker no Ubuntu 18.04.
- O Docker Compose instalado em seu computador local ou servidor, seguindo o Passo 1 do artigo sobre Como instalar o Docker Compose no Ubuntu 18.04.
Passo 1 — Clonando o projeto e adicionando dependências
Nosso primeiro passo será clonar o repositório rails-sidekiq da conta da Comunidade DigitalOcean no GitHub. Esse repositório inclui o código da configuração descrita em Como adicionar o Sidekiq e o Redis em um aplicativo Ruby on Rails, que explica como adicionar o Sidekiq a um projeto Rails 5 existente.
Clone o repositório em um diretório chamado rails-docker:
- git clone https://github.com/do-community/rails-sidekiq.git rails-docker
Navegue até o diretório rails-docker:
- cd rails-docker
Nesse tutorial, usaremos o PostgreSQL como um banco de dados. Para trabalhar com o PostgreSQL, em vez do SQLite 3, será necessário adicionar a gem pgàs dependências do projeto, que estão listadas em seu respectivo Gemfile. Abra aquele arquivo para edição usando o nano ou seu editor favorito:
- nano Gemfile
Adicione a gem em qualquer lugar das dependências principais do projeto (acima das dependências de desenvolvimento):
. . .
# Reduces boot times through caching; required in config/boot.rb
gem 'bootsnap', '>= 1.1.0', require: false
gem 'sidekiq', '~>6.0.0'
gem 'pg', '~>1.1.3'
group :development, :test do
. . .
Também podemos comentar a gem sqlite, uma vez que não a iremos usar mais:
. . .
# Use sqlite3 as the database for Active Record
# gem 'sqlite3'
. . .
Por fim, comente a gem spring-watcher-listen em development:
. . .
gem 'spring'
# gem 'spring-watcher-listen', '~> 2.0.0'
. . .
Se não desativarmos essa gema, veremos mensagens de erro persistentes ao acessar o console do Rails. Essas mensagens de erro resultam do fato de que essa gem permite que o Rails listen para monitorar as alterações em desenvolvimento, em vez de sondar o sistema de arquivos quanto a mudanças. Como essa gem monitora a raiz do projeto, incluindo o diretório node_modules, ela irá gerar mensagens de erro sobre quais diretórios estão sendo monitorados, sobrecarregando o console. No entanto, se estiver preocupado em preservar recursos da CPU, desativar essa gem pode não funcionar para você. Neste caso, pode ser uma boa ideia fazer o upgrade do seu aplicativo Rails para o Rails 6.
Salve e feche o arquivo quando você terminar a edição.
Com seu repositório de projeto em vigor, a gem pg adicionada ao seu Gemfile e a gem spring-watcher-listen comentada, você estará pronto para configurar seu aplicativo para trabalhar com o PostgreSQL.
Passo 2 — Configurando o aplicativo para trabalhar com o PostgreSQL e o Redis
Para trabalhar com o PostgreSQL e o Redis em desenvolvimento, precisamos fazer o seguinte:
- Configurar o aplicativo para funcionar com o PostgreSQL como o adaptador padrão.
- Adicionar um arquivo
.envao projeto com nosso nome de usuário do banco de dados e senha, além do host do Redis. - Criar um script
init.sqlpara criar um usuáriosammypara o banco de dados. - Adicionar um inicializador ao Sidekiq, de modo que ele possa funcionar com nosso serviço
redisem contêiner. - Adicionar o arquivo
.enve outros arquivos relevantes aos arquivosgitignoreedockerignoredo projeto. - Criar operações de propagação do banco de dados, de modo que o nosso aplicativo tenha alguns registros com os quais poderemos trabalhar quando o inicializarmos.
Primeiro, abra seu arquivo de configuração do banco de dados, localizado em config/database.yml:
- nano config/database.yml
Atualmente, o arquivo inclui as seguintes configurações default [padrão], que serão aplicadas na ausência de outras configurações:
default: &default
adapter: sqlite3
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
Precisamos alterar essas configurações para refletir o fato de que usaremos o adaptador postgresql, já que vamos criar um serviço do PostgreSQL com o Docker Compose para manter os dados do nosso aplicativo.
Exclua o código que define o SQLite como o adaptador e substitua-o pelas seguintes configurações, que irão configurar o adaptador de maneira apropriada e as outras variáveis necessárias para a conexão:
default: &default
adapter: postgresql
encoding: unicode
database: <%= ENV['DATABASE_NAME'] %>
username: <%= ENV['DATABASE_USER'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
port: <%= ENV['DATABASE_PORT'] || '5432' %>
host: <%= ENV['DATABASE_HOST'] %>
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
. . .
Em seguida, vamos modificar a configuração do ambiente development, já que este é o ambiente que estamos usando nesta configuração.
Exclua a configuração existente do banco de dados SQLite para que a seção fique parecida com esta:
. . .
development:
<<: *default
. . .
Por fim, exclua também as configurações do database para os ambientes production e test:
. . .
test:
<<: *default
production:
<<: *default
. . .
Essas modificações nas configurações padrão do banco de dados nos permitirão definir as informações do nosso banco de dados dinamicamente usando variáveis de ambiente definidas nos arquivos .env, as quais não serão aplicadas no controle de versão.
Salve e feche o arquivo quando você terminar a edição.
Note que, se você estiver criando um projeto Rails a partir do zero, você poderá definir o adaptador com o comando rails new, como descrito no Passo 3 do artigo sobre Como usar o PostgreSQL com seu aplicativo Ruby on Rails no Ubuntu 18.04. Isso irá definir seu adaptador em config/database.yml e adicionará automaticamente a gem pg ao projeto.
Agora que referenciamos nossas variáveis de ambiente, podemos criar um arquivo para elas com nossas configurações preferidas. Extrair definições de configuração dessa maneira faz parte da Abordagem de 12 fatores para o desenvolvimento de aplicativos, a qual define as melhores práticas para obtenção de resiliência dos aplicativos em ambientes distribuídos. Agora, quando estivermos definindo nossos ambientes de produção e teste no futuro, configurar nossas definições de banco de dados envolverá a criação de arquivos .env adicionais e o referenciamento do arquivo apropriado nos nossos arquivos do Docker Compose.
Abra um arquivo .env:
- nano .env
Adicione os valores a seguir ao arquivo:
DATABASE_NAME=rails_development
DATABASE_USER=sammy
DATABASE_PASSWORD=shark
DATABASE_HOST=database
REDIS_HOST=redis
Além de definir nosso nome de banco de dados, usuário e senha, também definimos um valor para o DATABASE_HOST. O valor, database, refere-se ao serviço de database do PostgreSQL que vamos criar usando o Docker Compose. Também definimos um REDIS_HOST para especificar nosso serviço redis.
Salve e feche o arquivo quando você terminar a edição.
Para criar o usuário de banco de dados sammy, podemos escrever um script init.sql o qual poderemos, então, montar no contêiner do banco de dados quando ele for iniciado.
Abra o arquivo de script:
- nano init.sql
Adicione o código a seguir para criar um usuário sammy com privilégios administrativos:
CREATE USER sammy;
ALTER USER sammy WITH SUPERUSER;
Esse script criará o usuário apropriado no banco de dados e concederá privilégios administrativos a esse usuário.
Defina permissões apropriadas no script:
- chmod +x init.sql
Em seguida, vamos configurar o Sidekiq para que trabalhe com nosso serviço redis em contêiner. Podemos adicionar um inicializador ao diretório config/initializers, onde o Rails procura as definições de configuração assim que os frameworks e plug-ins estiverem carregados, que define um valor para um host do Redis.
Abra um arquivo sidekiq.rb para especificar essas configurações:
- nano config/initializers/sidekiq.rb
Adicione o código a seguir ao arquivo para especificar valores para um REDIS_HOST e REDIS_PORT:
Sidekiq.configure_server do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Sidekiq.configure_client do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Assim como acontece com as definições da configuração do nosso banco de dados, tais definições nos dão a capacidade de definir dinamicamente os parâmetros de nosso host e porta. Isso, por sua vez, nos permite substituir os valores apropriados em tempo de execução sem ter que modificar o código do aplicativo propriamente dito. Além de um REDIS_HOST, temos um valor padrão definido para o REDIS_PORT, caso não seja definido em outro lugar.
Salve e feche o arquivo quando você terminar a edição.
Em seguida, para garantir que os dados sensíveis do nosso aplicativo não sejam copiados para o controle de versão, podemos adicionar .env ao arquivo .gitignore do nosso projeto, que diz ao Git quais arquivos ignorar no nosso projeto. Abra o arquivo para edição:
- nano .gitignore
Ao final do arquivo, adicione uma entrada para .env:
yarn-debug.log*
.yarn-integrity
.env
Salve e feche o arquivo quando você terminar a edição.
Em seguida, vamos criar um arquivo .dockerignore para definir o que não deve ser copiado para nossos contêineres. Abra o arquivo para edição:
- .dockerignore
Adicione o código a seguir ao arquivo, que diz ao Docker para ignorar algumas das coisas que não precisamos que sejam copiadas para nossos contêineres:
.DS_Store
.bin
.git
.gitignore
.bundleignore
.bundle
.byebug_history
.rspec
tmp
log
test
config/deploy
public/packs
public/packs-test
node_modules
yarn-error.log
coverage/
Adicione também .env ao final deste arquivo:
. . .
yarn-error.log
coverage/
.env
Salve e feche o arquivo quando você terminar a edição.
Como passo final, criaremos alguns dados de propagação, de modo que o nosso aplicativo tenha alguns registros quando o inicializarmos.
Abra um arquivo para os dados de propagação no diretório db:
- nano db/seeds.rb
Adicione o código a seguir ao arquivo para criar quatro tubarões de demonstração e um post de exemplo:
# Adding demo sharks
sharks = Shark.create([{ name: 'Great White', facts: 'Scary' }, { name: 'Megalodon', facts: 'Ancient' }, { name: 'Hammerhead', facts: 'Hammer-like' }, { name: 'Speartooth', facts: 'Endangered' }])
Post.create(body: 'These sharks are misunderstood', shark: sharks.first)
Esses dados de propagação criarão quatro tubarões e um post que será associado ao primeiro tubarão.
Salve e feche o arquivo quando você terminar a edição.
Com seu aplicativo configurado para funcionar com o PostgreSQL e suas variáveis de ambiente criadas, você está pronto para escrever seu aplicativo Dockerfile.
Passo 3 — Escrevendo os scripts do Dockerfile e de ponto de entrada
Seu Dockerfile especifica o que será incluído no contêiner do seu aplicativo quando ele estiver criado. Usar um Dockerfile permite que você defina seu ambiente de contêiner e evite discrepâncias com as dependências ou versões de tempo de execução.
Ao seguir essas diretrizes para criação de contêineres otimizados, tornaremos nossa imagem o mais eficiente possível usando uma base Alpine e tentando minimizar nossas camadas de imagem no geral.
Abra um Dockerfile em seu diretório atual:
- nano Dockerfile
As imagens do Docker são criadas com uma sucessão de imagens em camadas que são baseadas umas nas outras. Nosso primeiro passo será adicionar a imagem base para nosso aplicativo, que formará o ponto inicial da compilação do aplicativo.
Adicione o código a seguir ao arquivo para adicionar a imagem alpine do Ruby como uma base:
FROM ruby:2.5.1-alpine
A imagem alpine é derivada do projeto Alpine Linux e nos ajudará a manter nossa imagem com tamanho reduzido. Para obter mais informações sobre se a imagem alpine é a escolha certa para seu projeto, consulte a discussão completa na seção de Variantes de imagem da página de imagens do Docker Hub Ruby.
Alguns fatores a serem levados em consideração ao se usar o alpine no desenvolvimento:
- Manter a imagem com tamanho reduzido irá diminuir os tempos de carregamento da página e de recursos, especialmente se você também mantiver os volumes a um mínimo. Isso tornará a experiência do seu usuário - durante o desenvolvimento - rápida e mais próxima da experiência de se trabalhar localmente, em um ambiente não conteinerizado.
- A paridade entre as imagens de desenvolvimento e de produção facilita implantações bem-sucedidas. Como as equipes optam frequentemente por usar imagens do Alpine na produção - pelos benefícios em termos de velocidade, o desenvolvimento com uma base de Alpine ajuda a compensar os problemas na transição para a produção.
Em seguida, defina uma variável de ambiente para especificar a versão Bundler:
. . .
ENV BUNDLER_VERSION=2.0.2
Esse é um dos passos que vamos adotar para evitar conflitos de versão entre a versão bundler padrão, disponível no nosso ambiente e nosso código de aplicativo, que exige o Bundler 2.0.2.
Em seguida, adicione ao Dockerfile os pacotes necessários para trabalhar com o aplicativo:
. . .
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
Esses pacotes incluem o nodejs e yarn, entre outros. Como nosso aplicativo atende os ativos com o webpack, precisamos incluir o Node.js e o Yarn para que o aplicativo funcione conforme o esperado.
Lembre-se de que a imagem alpine tem tamanho diminuto: a lista apresentada aqui não esgota os pacotes que você talvez queira ou precise no desenvolvimento, quando estiver conteinerizando o seu próprio aplicativo.
Em seguida, instale a versão do bundler apropriada:
. . .
RUN gem install bundler -v 2.0.2
Esse passo irá garantir a paridade entre o nosso ambiente conteinerizado e as especificações no arquivo Gemfile.lock desse projeto.
Agora, defina o diretório de trabalho para o aplicativo no contêiner:
. . .
WORKDIR /app
Copie para lá o seu Gemfile e o Gemfile.lock:
. . .
COPY Gemfile Gemfile.lock ./
Copiar esses arquivos como um passo independente, seguido de bundle install, significa que as gems do projeto não precisam ser recompiladas toda vez que você fizer alterações no código do seu aplicativo. Isso funcionará em conjunto com o volume da gem que vamos incluir no nosso arquivo Compose, o qual irá montar as gems para o seu contêiner de aplicativo, nos casos em que o serviço for recriado.As gems do projeto, porém, permanecerão as mesmas.
Em seguida, defina as opções de configuração para a compilação da gem nokogiri:
. . .
RUN bundle config build.nokogiri --use-system-libraries
. . .
Esse passo compila a nokigiri com as versões de biblioteca libxml2 e libxslt que adicionamos ao contêiner do aplicativo no passo RUN apk add... acima.
Em seguida, instale as gems do projeto:
. . .
RUN bundle check || bundle install
Antes de instalar as gems, essa instrução verifica se elas já estão instaladas.
Em seguida, vamos repetir o mesmo procedimento que usamos com as gems em relação aos nossos pacotes e dependências do JavaScript. Primeiro, vamos copiar os metadados do pacote; em seguida, vamos instalar as dependências e, por fim, vamos copiar o código do aplicativo na imagem do contêiner.
Para começar com a seção Javascript do nosso Dockerfile, copie os arquivos package.json e yarn.lock do diretório de seu projeto atual, no host, para o contêiner:
. . .
COPY package.json yarn.lock ./
Depois, instale os pacotes necessários com yarn install:
. . .
RUN yarn install --check-files
Essa instrução inclui um sinalizador --check-files com o comando yarn, um recurso que garante que nenhum arquivo instalado anteriormente tenha sido removido. Como no caso das nossas gems, vamos gerenciar a permanência dos pacotes no diretório node_modules com um volume, quando escrevermos nosso arquivo Compose.
Por fim, copie o resto do código do aplicativo e inicie o aplicativo com um script de ponto de entrada:
. . .
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
Usar um script de ponto de entrada nos permite executar o contêiner como um executável.
O Dockerfile final ficará parecido com este:
FROM ruby:2.5.1-alpine
ENV BUNDLER_VERSION=2.0.2
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
RUN gem install bundler -v 2.0.2
WORKDIR /app
COPY Gemfile Gemfile.lock ./
RUN bundle config build.nokogiri --use-system-libraries
RUN bundle check || bundle install
COPY package.json yarn.lock ./
RUN yarn install --check-files
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
Salve e feche o arquivo quando você terminar a edição.
Em seguida, crie um diretório chamado entrypoints para os scripts de ponto de entrada:
- mkdir entrypoints
Esse diretório incluirá nosso script de ponto de entrada principal e um script para o nosso serviço Sidekiq.
Abra o arquivo para o script de ponto de entrada do aplicativo:
- nano entrypoints/docker-entrypoint.sh
Adicione o código a seguir ao arquivo:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec rails s -b 0.0.0.0
A primeira linha importante é set -e, que diz ao shell /bin/sh - que executa o script - para falhar rapidamente se houver problemas mais tarde no script. Em seguida, o script verifica se o tmp/pids/server.pid não está presente, a fim de garantir que não haverá conflitos de servidor quando iniciarmos o aplicativo. Por fim, o script inicia o servidor Rails com o comando bundle exec rails s. Usamos a opção -b com esse comando para vincular o servidor a todos os endereços IP e não para o localhost padrão. Essa invocação faz com que o servidor Rails encaminhe os pedidos de entrada para o IP do contêiner e não para o localhost padrão.
Salve e feche o arquivo quando você terminar a edição.
Crie o executável do script:
- chmod +x entrypoints/docker-entrypoint.sh
Em seguida, vamos criar um script para iniciar nosso serviço sidekiq, que irá processar nossas tarefas do Sidekiq. Para obter mais informações sobre como esse aplicativo usa o Sidekiq, consulte o artigo sobre Como adicionar o Sidekiq e o Redis a um aplicativo Ruby on Rails.
Abra um arquivo para o script de ponto de entrada do Sidekiq:
- nano entrypoints/sidekiq-entrypoint.sh
Adicione o código a seguir ao arquivo para iniciar o Sidekiq:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec sidekiq
Esse script inicia o Sidekiq no contexto do nosso pacote de aplicativo.
Salve e feche o arquivo quando você terminar a edição. Torne-o executável:
- chmod +x entrypoints/sidekiq-entrypoint.sh
Com seus scripts de ponto de entrada e o Dockerfile instalados, você está pronto para definir seus serviços no seu arquivo Compose.
Passo 4 — Definindo serviços com o Docker Compose
Usando o Docker Compose, conseguiremos executar vários contêineres necessários para nossa configuração. Vamos definir nossos serviços do Compose no nosso arquivo principal docker-compose.yml. Um serviço no Compose é um contêiner em execução e as definições de serviço — que você incluirá no seu arquivo docker-compose.yml — contém informações sobre como cada imagem de contêiner será executada. A ferramenta Compose permite que você defina vários serviços para construir aplicativos multi-contêiner.
Nossa configuração do aplicativo incluirá os seguintes serviços:
- O aplicativo em si
- O banco de dados PostgreSQL
- Redis
- Sidekiq
Também vamos incluir uma montagem bind como parte da nossa preparação, de modo que qualquer alteração de código que fizermos durante o desenvolvimento será imediatamente sincronizada com os contêineres que precisam de acesso a esse código.
Note que não estamos definindo um serviço de test, uma vez que testar está fora do âmbito deste tutorial e desta série. Porém, você pode fazer esse teste, seguindo o anterior que estamos usando aqui para o serviço do sidekiq.
Abra o arquivo docker-compose.yml:
- nano docker-compose.yml
Primeiro, adicione a definição de serviço do aplicativo:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
A definição de serviço do app inclui as seguintes opções:
build: define as opções de configuração, incluindo ocontextedockerfile, que serão aplicadas quando o Compose construir a imagem do aplicativo. Se quisesse usar uma imagem existente de um registro como o Docker Hub, você poderia usar como alternativa a instruçãoimage, com informações sobre seu nome de usuário, repositório e tag da imagem.context: define o contexto de construção para a construção da imagem — neste caso, o diretório atual do projeto.dockerfile: especifica oDockerfileno diretório atual do seu projeto como o arquivo que o Compose usará para construir a imagem do aplicativo.depends_on: esta opção define primeiro os contêineresdatabaseeredis, de modo que eles estejam em funcionamento antes doapp.ports: esta opção mapeia a porta3000no host até a porta3000no contêiner.volumes: estamos incluindo dois tipos de montagens aqui:- A primeira é uma montagem bind que monta o código do nosso aplicativo no host para o diretório
/appno contêiner. Isso facilitará o desenvolvimento rápido, uma vez que quaisquer alterações que você faça no código do seu host serão povoadas imediatamente no contêiner. - A segunda é um volume nomeado, o
gem_cache. Quando a instruçãobundle installexecuta no contêiner, ela instala as gems do projeto. Adicionar esse volume significa que, caso você recriar o contêiner, as gems serão montadas no novo contêiner. Essa montagem pressupõe que não houve nenhuma alteração no projeto. Assim, caso você de fato faça alterações nas gems do seu projeto no desenvolvimento, você precisará lembrar de excluir esse volume antes de recriar o serviço do seu aplicativo. - O terceiro volume é um volume nomeado para o diretório
node_modules. Em vez de ter onode_modulesmontado no host, o qual pode levar a discrepâncias de pacotes e conflitos de permissões no desenvolvimento, esse volume irá garantir que os pacotes neste diretório sejam mantidos e reflitam o estado atual do projeto. Novamente, se você modificar as dependências do Node do projeto, precisará remover e recriar esse volume.
- A primeira é uma montagem bind que monta o código do nosso aplicativo no host para o diretório
env_file: esta opção diz ao Compose que gostaríamos de adicionar variáveis de ambiente de um arquivo chamado.env, localizado no contexto da compilação.environment: usar esta opção nos permite definir uma variável de ambiente não confidencial, enviando informações sobre o ambiente do Rails para o contêiner.
Em seguida, abaixo da definição de serviço do app, adicione o código a seguir para definir seu serviço de database:
. . .
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
Ao contrário do serviço app, o serviço database extrai uma imagem postgres diretamente do Docker Hub. Note que estamos também fixando a versão aqui, em vez de defini-la como latest [mais recente] ou sem especificá-la (que, por padrão, é definida como latest). Dessa forma, podemos garantir que essa configuração funcione com as versões especificadas aqui e evitar surpresas inesperadas com as alterações de falha do código na imagem.
Também estamos incluindo aqui um volume db_data, o qual manterá os dados do nosso aplicativo entre as inicializações do contêiner. Além disso, montamos nosso script de inicialização init.sql no diretório apropriado, docker-entrypoint-initdb.d/ no contêiner, para criar nosso usuário de banco de dados sammy. Depois que o ponto de entrada da imagem criar o usuário e banco de dados padrão postgres, ele executará quaisquer scripts encontrados no diretório docker-entrypoint-initdb.d/, que você poderá usar para as tarefas de inicialização necessárias. Para obter mais detalhes, examine a seção Inicialização de scripts da documentação da imagem do PostgreSQL.
Em seguida, adicione a definição de serviço redis:
. . .
redis:
image: redis:5.0.7
Assim como o serviço de database, o serviço de redis usa uma imagem do Docker Hub. Neste caso, não vamos manter o cache do trabalho do Sidekiq.
Por fim, adicione a definição de serviço do sidekiq:
. . .
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
Nosso serviço sidekiq se assemelha ao serviço app em alguns aspectos: ele usa o mesmo contexto e imagem de compilação, variáveis de ambiente e volumes. No entanto, ele é depende dos serviços app, redis e database e, portanto, será o último a ser iniciado. Além disso, ele usa um entrypoint que irá substituir o ponto de entrada definido no Dockerfile. Essa configuração do entrypoint aponta para entrypoints/sidekiq-entrypoint.sh, que inclui o comando apropriado para iniciar o serviço sidekiq.
Como passo final, adicione as definições de volume abaixo da definição de serviço sidekiq:
. . .
volumes:
gem_cache:
db_data:
node_modules:
Nossa chave de nível superior de volumes define os volumes gem_cache, db_data e node_modules. Quando o Docker cria volumes, o conteúdo do volume é armazenado em uma parte do sistema de arquivos do host, /var/lib/docker/volumes/, que é gerenciado pelo Docker. O conteúdo de cada volume é armazenado em um diretório em /var/lib/docker/volumes/ e é montado em qualquer contêiner que utilize o volume. Dessa forma, os dados de informações sobre tubarões - a serem criados por nossos usuários - irão permanecer no volume db_data, mesmo se removermos e recriarmos o serviço de database.
O arquivo final se parecerá com este:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
redis:
image: redis:5.0.7
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
volumes:
gem_cache:
db_data:
node_modules:
Salve e feche o arquivo quando você terminar a edição.
Com as definições do seu serviço gravadas, você estará pronto para iniciar o aplicativo.
Passo 5 — Testando o aplicativo
Com seu arquivo docker-compose.yml funcionando, você pode criar seus serviços com o comando docker-compose up e propagar o seu banco de dados. Você também pode testar se seus dados serão mantidos, interrompendo e removendo seus contêineres com o docker-compose down e recriando-os.
Primeiro, compile as imagens de contêiner e crie os serviços, executando o docker-compose up com o sinalizador -d, o qual executará os contêineres em segundo plano:
- docker-compose up -d
Você verá um resultado, confirmando que seus serviços foram criados:
OutputCreating rails-docker_database_1 ... done
Creating rails-docker_redis_1 ... done
Creating rails-docker_app_1 ... done
Creating rails-docker_sidekiq_1 ... done
Você também pode obter informações mais detalhadas sobre os processos de inicialização exibindo o resultado do registro dos serviços:
- docker-compose logs
Você verá algo simelhante a isso caso tudo tenha iniciado corretamente:
Outputsidekiq_1 | 2019-12-19T15:05:26.365Z pid=6 tid=grk7r6xly INFO: Booting Sidekiq 6.0.3 with redis options {:host=>"redis", :port=>"6379", :id=>"Sidekiq-server-PID-6", :url=>nil}
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Running in ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux-musl]
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: See LICENSE and the LGPL-3.0 for licensing details.
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Upgrade to Sidekiq Pro for more features and support: http://sidekiq.org
app_1 | => Booting Puma
app_1 | => Rails 5.2.3 application starting in development
app_1 | => Run `rails server -h` for more startup options
app_1 | Puma starting in single mode...
app_1 | * Version 3.12.1 (ruby 2.5.1-p57), codename: Llamas in Pajamas
app_1 | * Min threads: 5, max threads: 5
app_1 | * Environment: development
app_1 | * Listening on tcp://0.0.0.0:3000
app_1 | Use Ctrl-C to stop
. . .
database_1 | PostgreSQL init process complete; ready for start up.
database_1 |
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: starting PostgreSQL 12.1 (Debian 12.1-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv6 address "::", port 5432
database_1 | 2019-12-19 15:05:20.163 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
database_1 | 2019-12-19 15:05:20.182 UTC [63] LOG: database system was shut down at 2019-12-19 15:05:20 UTC
database_1 | 2019-12-19 15:05:20.187 UTC [1] LOG: database system is ready to accept connections
. . .
redis_1 | 1:M 19 Dec 2019 15:05:18.822 * Ready to accept connections
Você também pode verificar o status dos seus contêineres com o docker-compose ps:
- docker-compose ps
Você verá um resultado indicando que seus contêineres estão funcionando:
Output Name Command State Ports
-----------------------------------------------------------------------------------------
rails-docker_app_1 ./entrypoints/docker-resta ... Up 0.0.0.0:3000->3000/tcp
rails-docker_database_1 docker-entrypoint.sh postgres Up 5432/tcp
rails-docker_redis_1 docker-entrypoint.sh redis ... Up 6379/tcp
rails-docker_sidekiq_1 ./entrypoints/sidekiq-entr ... Up
Em seguida, crie e propague seu banco de dados e execute migrações nele com o comando docker-compose exec a seguir:
- docker-compose exec app bundle exec rake db:setup db:migrate
O comando docker-compose exec permite que você execute comandos nos seus serviços. Aqui, nós o estamos usando para executar rake db:setup e db:migrate, no contexto do pacote do nosso aplicativo, com o objetivo de criar e propagar o banco de dados e executar as migrações. Como você trabalha com desenvolvimento, o docker-compose exec se mostrará útil quando quiser executar migrações em relação ao seu banco de dados de desenvolvimento.
Você verá o seguinte resultado após executar este comando:
OutputCreated database 'rails_development'
Database 'rails_development' already exists
-- enable_extension("plpgsql")
-> 0.0140s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0097s
-- create_table("posts", {:force=>:cascade})
-> 0.0108s
-- create_table("sharks", {:force=>:cascade})
-> 0.0050s
-- enable_extension("plpgsql")
-> 0.0173s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0088s
-- create_table("posts", {:force=>:cascade})
-> 0.0128s
-- create_table("sharks", {:force=>:cascade})
-> 0.0072s
Com seus serviços em execução, você pode acessar o localhost:3000 ou o http://your_server_ip:3000 no navegador. Você verá uma página de destino que se parece com esta:
Agora, podemos testar a permanência dos dados. Crie um novo tubarão, clicando no botão** Get Shark Info**, que levará você até a rota shark/index:
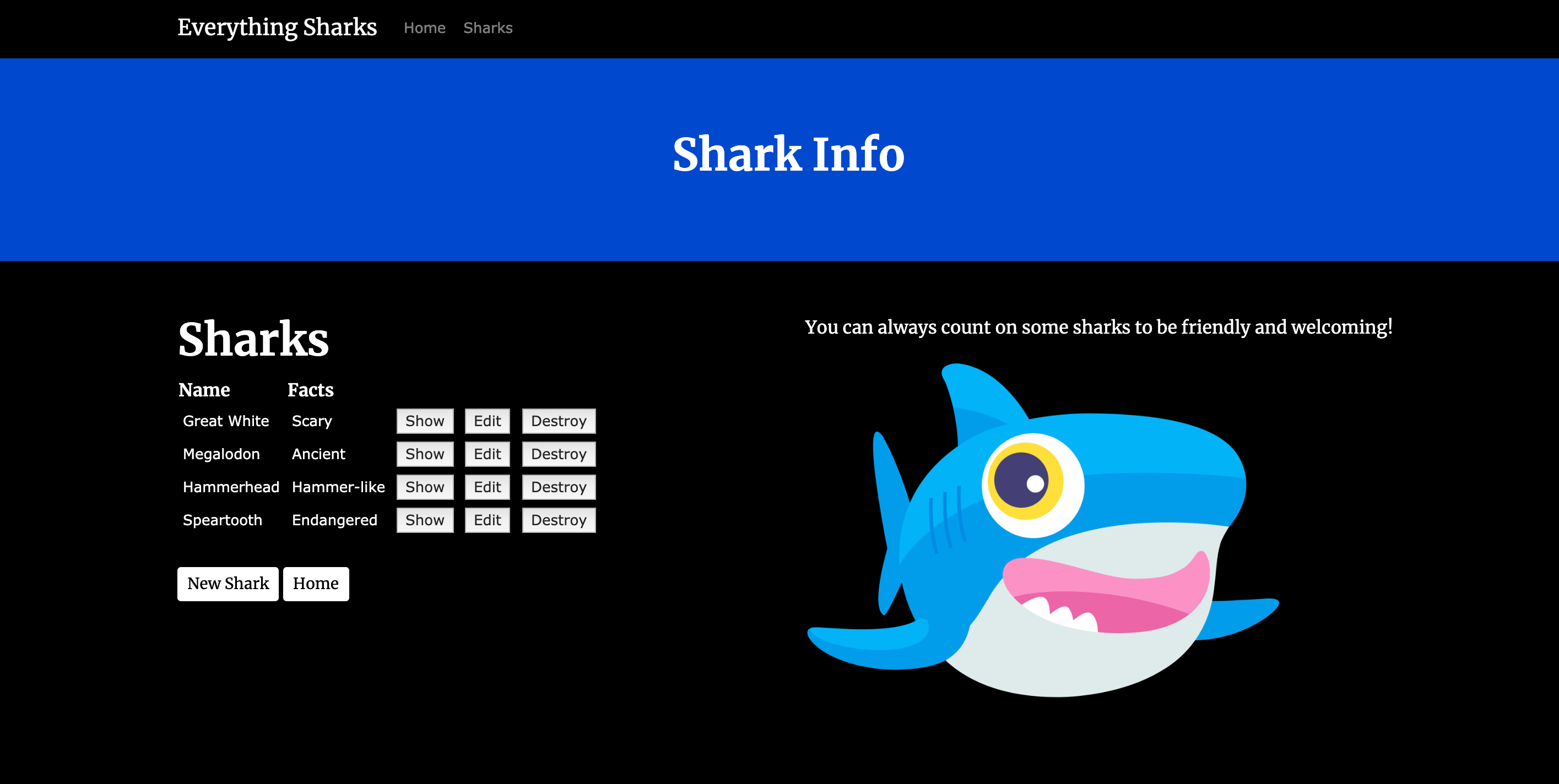
Para verificar se o aplicativo está funcionando, podemos adicionar algumas informações de demonstração a ele. Clique em New Shark. Será solicitado que coloque um nome de usuário (sammy) e senha (shark), graças às configurações de autenticação do projeto.
Na página New Shark, digite “Mako” no campo Name e “Fast” no campo Facts.
Clique no botão Create Shark para criar o tubarão. Assim que tiver criado o tubarão, clique em Home, na barra de navegação do site para voltar à página de destino principal do aplicativo. Agora, podemos testar se o Sidekiq está funcionando.
Clique no botão Which Sharks Are in Danger? [Quais tubarões estão em perigo?] . Como não fez upload de nenhum tubarão em perigo, isso levará você até a visualização de index endangered [em perigo]:
 [Em perigo]
[Em perigo]
Clique em Import Endangered Sharks para importar os tubarões. Você verá uma mensagem de status informando que os tubarões foram importados:

Você verá também o início da importação. Atualize sua página para ver a tabela inteira:

Graças ao Sidekiq, o upload de nosso lote grande de tubarões em perigo foi bem-sucedido, sem bloquear o navegador ou interferir com outras funcionalidades do aplicativo.
Clique no botão Home, no final da página, para voltar à página principal do aplicativo:
A partir daqui, clique em Which Sharks Are in Danger? novamente. Você verá os tubarões que foram carregados novamente.
Agora que sabemos que nosso aplicativo está funcionando corretamente, podemos testar a permanência dos nossos dados.
De volta ao seu terminal, digite o seguinte comando para interromper e remover seus contêineres:
- docker-compose down
Note que não estamos incluindo a opção --volumes; desta forma, nosso volume db_data não foi removido.
O resultado a seguir confirma que seus contêineres e rede foram removidos:
OutputStopping rails-docker_sidekiq_1 ... done
Stopping rails-docker_app_1 ... done
Stopping rails-docker_database_1 ... done
Stopping rails-docker_redis_1 ... done
Removing rails-docker_sidekiq_1 ... done
Removing rails-docker_app_1 ... done
Removing rails-docker_database_1 ... done
Removing rails-docker_redis_1 ... done
Removing network rails-docker_default
Recrie os contêineres:
- docker-compose up -d
Abra o console do Rails no contêiner do app com o docker-compose exec e bundle exec rails console:
- docker-compose exec app bundle exec rails console
No prompt, inspecione o registro do last [último] do Tubarão no banco de dados:
- Shark.last.inspect
Você verá o registro que acabou de criar:
IRB session Shark Load (1.0ms) SELECT "sharks".* FROM "sharks" ORDER BY "sharks"."id" DESC LIMIT $1 [["LIMIT", 1]]
=> "#<Shark id: 5, name: \"Mako\", facts: \"Fast\", created_at: \"2019-12-20 14:03:28\", updated_at: \"2019-12-20 14:03:28\">"
Depois, você poderá verificar se os seus tubarões Endangered permaneceram, usando o seguinte comando:
- Endangered.all.count
IRB session (0.8ms) SELECT COUNT(*) FROM "endangereds"
=> 73
Seu volume db_data foi montado com sucesso no serviço database recriado, possibilitando que seu serviço app acesse os dados salvos. Se navegar diretamente até a página index shark - visitando o localhost:3000/sharks ou http://your_server_ip:3000/sharks, você também verá aquele registro sendo exibido:

Seus tubarões em perigo também estarão em exibição em localhost:3000/endangered/data ou http://your_server_ip:3000/endangered/data:
Seu aplicativo agora está funcionando em contêineres do Docker com persistência de dados e sincronização de código habilitados. Você pode seguir em frente e testar as alterações do código local no seu host, as quais serão sincronizadas com o seu contêiner, graças à montagem bind que definimos como parte do serviço do app.
Conclusão
Ao seguir este tutorial, você criou uma configuração de desenvolvimento para o seu aplicativo Rails, usando os contêineres do Docker. Você tornou seu projeto mais modular e portátil, extraindo informações confidenciais e desassociando o estado do seu aplicativo do seu código. Você também configurou um arquivo clichê docker-compose.yml que pode revisar conforme suas necessidades de desenvolvimento e exigências mudem.
Conforme for desenvolvendo, você pode se interessar em aprender mais sobre a concepção de aplicativos para fluxos de trabalho em contêiner e Cloud Native. Consulte o artigo Arquitetando aplicativos para o Kubernetes e Modernizando aplicativos para o Kubernetes para obter mais informações sobre esses tópicos. Ou, caso queira investir em uma sequência de aprendizagem do Kubernetes, veja o artigo sobre o Kubernetes para obter o currículo dos desenvolvedores de pilha completa.
Para aprender mais sobre o código do aplicativo em si, consulte os outros tutoriais nesta série:
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Developer at DigitalOcean community. Expertise in areas including Ubuntu, Docker, Ruby on Rails, Debian, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Olá Obrigado pela postagem!
Estou com um problema no serviço do database. Ele informa que a variável POSTGRES_PASSWORD é obrigatória para a imagem postgres. Se eu coloco a variável para o serviço database, ele faz o up, mas então encontro erro na autenticação do usuário sammy. password authentication failed for user “sammy”
Sabe o que está faltando na minha configuração?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
