By Oreolorun Olu-Ipinlaye and Shaoni Mukherjee
")
In the world of deep learning, Convolutional Neural Networks (CNNs) have changed the way we understand image processing and recognition tasks. CNNs are a class of artificial neural networks specifically designed to handle grid-like data, such as images. They excel in extracting spatial hierarchies of features, enabling them to detect patterns, shapes, textures, and objects from raw pixel values. This ability to learn hierarchical feature representations makes CNNs the go-to model for computer vision tasks like image classification, object detection, and segmentation.
Unlike traditional Multi-Layer Perceptrons (MLPs), which are fully connected networks where each neuron in a layer is connected to every neuron in the next layer, CNNs employ a more specialized architecture. The key innovation behind CNNs is the use of filters—learnable, 2-dimensional matrices (often square in shape) that slide over the image to perform convolutions. These filters are trained to detect specific patterns, such as edges, textures, or more complex features, by examining local patches of the image.
Why are CNNs necessary? The answer lies in their efficiency and effectiveness when dealing with high-dimensional data like images. Traditional methods of image processing relied on manual feature extraction, which was both time-consuming and often suboptimal. CNNs, on the other hand, automate this process and learn the most relevant features directly from the data. As a result, CNNs have become the backbone of modern computer vision applications, powering everything from self-driving cars to facial recognition systems.
In this article, we’ll dive deeper into the role of filters in CNNs, exploring how they interact with an image as it passes through different layers of the network. By understanding the significance of these learnable parameters, you’ll gain a clearer picture of how CNNs are able to process complex image data and make intelligent predictions.
Prerequisites
A basic understanding of Python code and Neural Networks is needed to follow along with this tutorial. We recommend this article to intermediate to advanced coders with experience developing novel architectures.
The code in this article can be executed on a normal home PC or DigitalOcean Droplet.
Neural Nets and Feature Extraction
An essential capability of neural networks is their ability to extract features from data to then use them in achieving a certain goal, be it classification, regression, etc. In MLPs, this process is easy to conceptualize; data points, which are often attributes of a particular instance of data, are mapped to trained weights to combine or transform them in some form into essential features. On the other hand, feature extraction is not as clear-cut when it comes to CNNs, as they do not deal with a vector of attributes; rather, they deal with images, which are a 2-dimensional matrix of attributes (pixels).
Besides, what would represent a feature when it comes to images anyway? When talking about a tabular dataset of houses, for instance, columns that hold attributes such as the number of bedrooms or the size of the living room are said to be features of a particular house instance. So what about an enhanced definition (480p) image of a cat, which has a size of (640, 480) pixels? This image has 640 columns and 480 rows, a total of 307,200 attributes (pixels), which represents features in this case?
Images On Edge
A lot of the details of what makes up an image are contained in its edges or outlines. It’s one of the reasons why we can easily distinguish objects in cartoon sketches. There are numerous studies to suggest that edge perception is one of the first techniques utilized by the human brain when processing visual cues coming from the eyes (Willian Mcllhagga, 2018). Edge perception is not just limited to human vision, some studies have argued that it is one of the reasons why Avians (birds) are so adept at dodging obstacles mid-flight at such high speeds as well as landing on small targets from so far away with pinpoint accuracy (Partha Bhagavatula et al, 2009).

The only information we have is edges, and we all know what this is.
CNNs and Human Vision
There has been a lot of talk about how neural networks mimic the human brain. One scenario that gives some credence to this is the fact that just as the human brain begins to process visual cues coming from the eyes by perceiving edges, Convolutional Neural Networks also begin to extract features from images by detecting edges, in fact it can be said that edges represent image features. The tools it uses for this purpose are its learnable parameters and its filters.
That is specifically the purpose served by filters in a Convolutional Neural Network; they are there to help extract features from images. While the first few layers of a CNN are comprised of edge detection filters (low-level feature extraction), deeper layers often learn to focus on specific shapes and objects in the image. For this article, the major focus will be on edge detection in the first few layers, as it is quite an intriguing process, and the filters are easily comprehensible.
Filtering Out Edges
Convolutional Neural Networks (CNNs) possess a remarkable capability: they can learn specialized edge detection filters tailored to the statistical patterns within a given dataset and the network’s specific goals. While CNNs autonomously learn these filters, established, manually designed edge detection filters offer valuable insight into the concept of edge detection in computer vision. Examples of these traditional filters include Prewitt, Sobel, Laplacian, Robinson Compass, and Krisch Compass filters.
To examine what these filters do, let’s do some grunt work by applying them to images using the manually written convolution function given below.
import numpy as np
import torch
import torch.nn.functional as F
import cv2
from tqdm import tqdm
import matplotlib.pyplot as plt
def convolve(image_filepath, filter, title=''):
"""
This function performs convolution and
returns both the original and convolved
images.
"""
# reading image in grayscale format
image = cv2.imread(image_filepath, cv2.IMREAD_GRAYSCALE)
# defining filter size
filter_size = filter.shape[0]
# creating an array to store convolutions (x-m+1, y-n+1)
convolved = np.zeros(((image.shape[0] - filter_size) + 1,
(image.shape[1] - filter_size) + 1))
# performing convolution
for i in tqdm(range(image.shape[0])):
for j in range(image.shape[1]):
try:
convolved[i,j] = (image[i:(i+filter_size),
j:(j+filter_size)] * filter).sum()
except Exception:
pass
# converting to tensor
convolved = torch.tensor(convolved)
# applying relu activation
convolved = F.relu(convolved)
# producing plots
figure, axes = plt.subplots(1,2, dpi=120)
plt.suptitle(title)
axes[0].imshow(image, cmap='gray')
axes[0].axis('off')
axes[0].set_title('original')
axes[1].imshow(convolved, cmap='gray')
axes[1].axis('off')
axes[1].set_title('convolved')
pass
Convolution function
This function replicates the convolution process with an additional step of ReLU activation as expected in a typical convnet. Utilizing this function, we will be detecting edges in the image below using the filters listed above.

Prewitt Filters
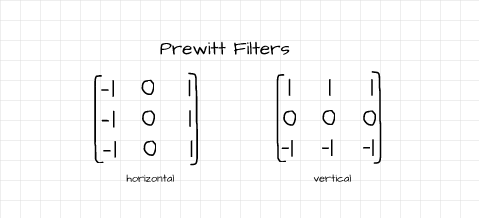
The vertical and horizontal Prewitt filters
The Prewitt operator is comprised of two filters which help to detect vertical and horizontal edges. The horizontal (x-direction) filter helps to detect edges in the image which cut perpendicularly through the horizontal axis and vise versa for the vertical (y-direction) filter.
# utilizing the horizontal filter
convolve('image.jpg', horizontal)

# utilizing the vertical filter
convolve('image.jpg', vertical)

Sobel Filters
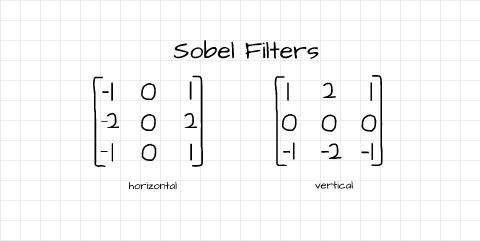
The vertical and horizontal Sobel filters
Just like the Prewitt operator, the Sobel operator is also made up of a vertical and horizontal edge detection filter. Detected edges are quite similar to results obtained using Prewitt filters, but with a distinction of higher edge pixel intensity. In other words, edges detected using the Sobel filters are sharper in comparison to Prewitt filters.
# utilizing the horizontal filter
convolve('image.jpg', horizontal)

# utilizing the vertical filter
convolve('image.jpg', vertical)

Laplacian Filter
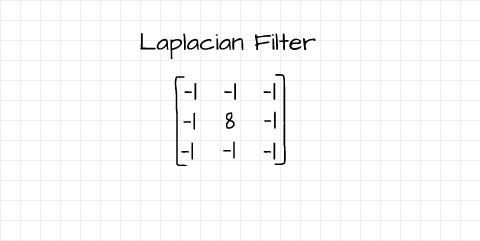
Unlike the Prewitt and Sobel filters, the Laplacian filter is a single filter which detects edges of different orientation. From a mathematical standpoint, it computes second order derivatives of pixel values unlike the Prewitt and Sobel filters which compute first order derivatives.
# utilizing the filter
convolve('image.jpg', filter)

Robinson Compass Masks
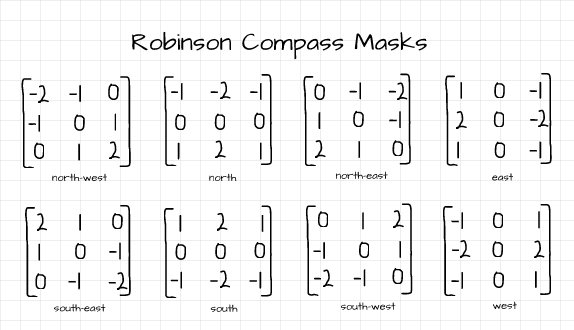
All 8 Robinson Compass masks
The Robinson Compass masks are edge detection filters which are made up of 8 different filters accounting for the 8 geographical compass directions as shown in the image above. These filters help to detect edges oriented in those compass directions. For brevity, just two of the filters are used for illustration purposes.
# utilizing the north_west filter
convolve('image.jpg', north_west)

# utilizing the north_east filter
convolve('image.jpg', north_east)

Krisch Compass Masks
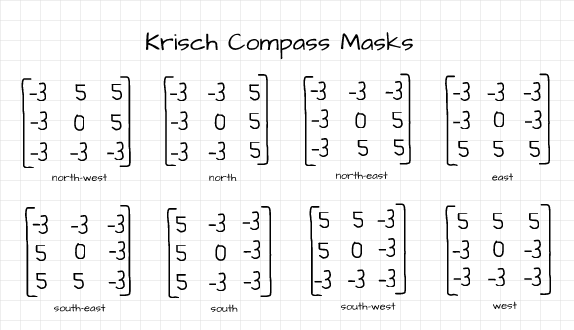
All 8 Krisch Compass masks
Similar to the Robinson Compass masks, the Krisch Compass mask is also comprised of 8 filters which help to detect edges in geographical compass directions. two of the filters are used below.
# utilizing the south_west filter
convolve('image.jpg', south_west)

# utilizing the south_east filter
convolve('image.jpg', south_east)

Filter Notations
There’s a pretty important statement above which you most likely missed,
The horizontal (x-direction) filter helps to detect edges in the image that cut perpendicularly through the horizontal axis, and vice versa for the vertical (y-direction) filter.
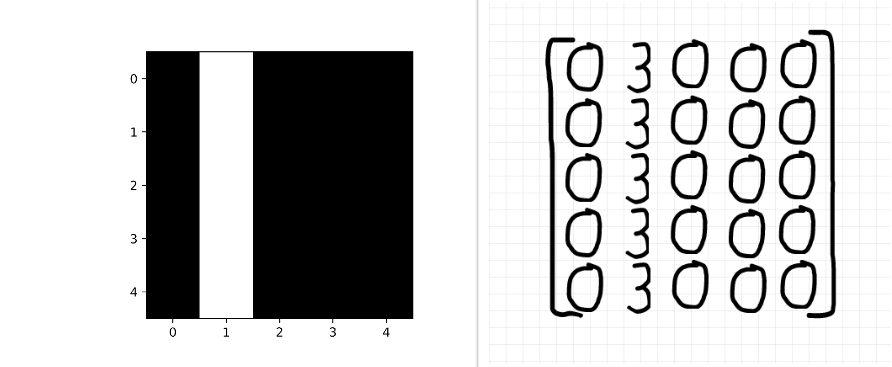
That statement might seem a bit confusing, but I’ll break it down further in this section. Consider the image below; the figure on the right is what the human eye sees, while the figure on the left is what a computer perceives. As evident in the image, the white line delineates a clear vertical edge on the black ‘canvas’, to the human eye this is evident because of the contrast between that line and its surroundings (In the same vane, a computer needs to be able to perceive this change in contrast on a pixel level and that’s essentially what edge detection entails).
In order to physically encounter this edge however, one would need to run a finger from left to right (horizontally) or vice versa. The same applies to edge detection filters, to detect a vertical edge you need to utilize an horizontal filter.

What you see vs. what a computer ‘sees’
Let’s attempt to detect edges in the image using both the horizontal and vertical Prewitt filters. The math behind the edge detection process is illustrated in the image below. The math behind the convolution process is quite easy to follow as outlined.
- Place the filter at the top left corner.
- Perform element-wise multiplication.
- Compute a cumulative sum.
- Return the obtained sum as a corresponding pixel in an empty array.
- Shift the filter to the right by one pixel and repeat steps 1 - 4 as you continue to populate the first row in the empty array towards the right.
- Stop when the filter falls out of bounds.
- Shift the filter downwards by one pixel to the second row.
- Repeat steps 1 - 6 as you populate the second row in the empty array.
- Do the same for all rows until the filter falls out of bounds in the vertical axis (dim 1).
Activation is done using the ReLU function, which simply casts any negative pixel to 0. After convolution and activation, the vertical edge is highlighted by the horizontal filter while the vertical filter returns a blacked-out image (all zero pixels), meaning it has detected no edge.
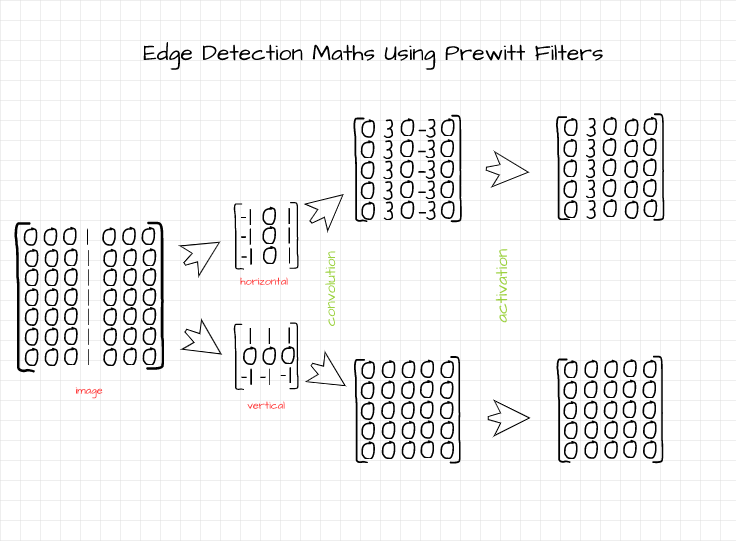
Edge detection math
The resulting detected edge is visualized below. Following the same logic, if the line were to be horizontal, representing a horizontal edge, the vertical filter would highlight the horizontal edge while the horizontal filter returns a blacked-out image.
Edge detected by the horizontal filter
Using The Convolution Function
For those who might want to use the convolution function above on a different image or to test out different filters for edge detecting or other image processing tasks, this section is a quick guide on how to do so.
The function takes 3 parameters, namely, ‘image_filepath’, ‘filter’, and ‘title’.
Image_filepath
This refers to the location of the desired image on your local drive or cloud. In a case where your image is in the current working directory, all you need to do is enter the image name complete with its file extension. If not, you’ll need to provide an absolute path, something of the form ‘C:/Users/Username/Downloads/image_name.jpg’ (forward slash in this case since we are working in Python).
Filter
This is in fact the filter you would like to use in the convolution process. Filters are quite easy to make using NumPy as demonstrated below. All you need to do afterwards is to supply the filter object in the function.
# creating a Prewitt horizontal filter
prewitt_x = np.array(([-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]))
# creating a laplacian filter
laplacian = np.array(([-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]))
Final Remarks
Convolutional Neural Networks (CNNs) stand out because of their ability to automatically extract features from two-dimensional data representations like image pixels. They achieve this through specialized components known as filters, which help identify patterns such as edges.
In this article, we explored how edge detection and feature extraction work in computer vision using predefined filters. However, it’s important to note that in practice, a CNN doesn’t rely on fixed filters—it learns the most effective filters during training to best capture features from the specific dataset. If you’re building and training CNN models, platforms like DigitalOcean GPU Droplets offer the scalable infrastructure needed to accelerate this learning process, helping you quickly experiment with and optimize your neural networks.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
