By Oreolorun Olu-Ipinlaye and Shaoni Mukherjee

Convolutional Neural Networks (CNNs) are well-known for their ability to process images by transforming a two-dimensional image into a compact, one-dimensional vector that captures the essential features. But what if we could reverse this process? If we can learn a mapping from an image to a vector, can we also learn to map that vector back into an image?
This idea forms the basis of Convolutional Autoencoders (CAEs) — special types of neural networks designed not just to compress image data into a lower-dimensional representation (encoding), but also to reconstruct the original image from that compressed form (decoding). In simple terms, CAEs learn how to efficiently represent and rebuild images.
Convolutional Autoencoders have become an important tool in deep learning, with a wide range of applications, such as:
- Image Denoising: Cleaning up noisy or corrupted images by reconstructing cleaner versions.
- Image Compression: Reducing the size of images for storage or transmission without losing important details.
- Feature Extraction: Automatically learning important features from images for tasks like classification or clustering.
- Anomaly Detection: Spotting unusual patterns in images, useful in fields like medical imaging and manufacturing quality control.
- Data Generation: Helping create new, realistic images, often used alongside generative models.
In this article, we’ll explore how Convolutional Autoencoders work, why they are so effective, and how they are used in real-world deep learning applications.
Prerequisites
Before diving into Convolutional Autoencoders, it will help if you have a basic understanding of:
- How Convolutional Neural Networks (CNNs) work.
- Concepts of encoding (compressing) and decoding (reconstructing) data.
- Basic knowledge of how neural networks are trained (e.g., loss functions, backpropagation.
- Familiarity with Python and deep learning frameworks like TensorFlow or PyTorch is a plus.
ConvNets as Feature Extractors
Convolutional Neural Networks (ConvNets or CNNs) are powerful tools for automatically extracting meaningful patterns from images. Instead of manually designing features like edges, corners, or textures, CNNs learn to detect these features directly from raw image data during training.
At the start of CNN, the network captures simple patterns like edges and colors. As data flows through deeper layers, the network identifies more complex features — such as shapes, textures, and even entire objects. Each convolutional layer builds on the patterns detected by the previous one, hence creating a rich and compressed feature representation of the image.
By the time the data reaches the later layers of a CNN, it is transformed from a 2D image into a compact 1D vector that captures the most important information. This feature vector can then be used for various tasks like image classification, clustering, retrieval, or even as input to other models.
Convolutional Neural Networks (ConvNets) excel at learning compressed yet informative feature representations. This capability makes autoencoders highly effective for various applications, including image reconstruction and noise reduction, among others.
The extracted features are then passed unto linear layers which perform the actual classification (exceptions are made for architectures that utilize 1 x 1 convolution layers for downsampling).
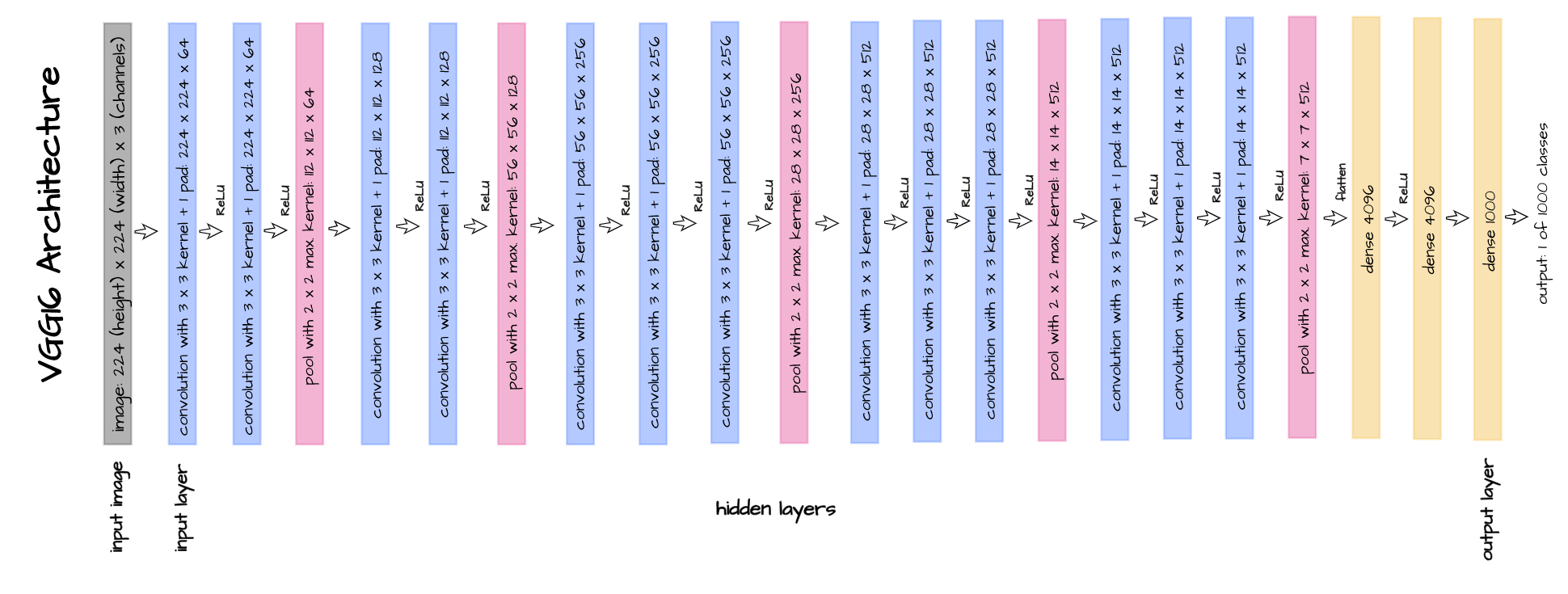
Consider VGG-16 with its architecture depicted above, from the input layer right till the point where the pooled 7 x 7 x 512 feature maps are flattened to create a vector of size 25,088 elements: that portion of the network serves as a feature extractor. Essentially, a 224 x 224 image with a total of 50,176 pixels is processed to create a 25,088-element feature vector, and this feature vector is then passed to the linear layers for classification.
Since these features are extracted by a convnet, it is logical to assume that another convnet could make sense of these features, and put the original image that those features belong to back together, basically reversing the feature extraction process. This is essentially what an Autoencoder does.
Structure of an Autoencoder
As stated in the previous section, autoencoders are deep learning architectures capable of reconstructing data instances from their feature vectors. They work on all sorts of data, but this article is primarily concerned with their application to image data. An autoencoder is made up of 3 main components, namely, an encoder, a bottleneck, and a decoder.
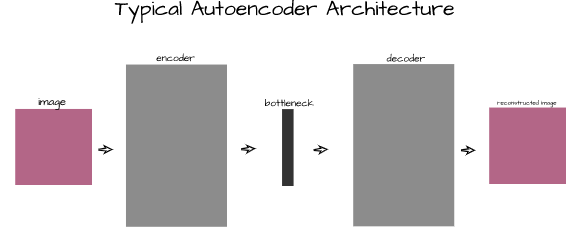
Encoder
The first section of an autoencoder, the encoder, is the convnet that acts specifically as a feature extractor. Its primary function is to help extract the most salient features from images and return them as a vector.
Bottleneck
Located right after the encoder, the bottleneck, also called a code layer, serves as an extra layer that helps to compress the extracted features into a smaller vector representation. This is done in a bid to make it more difficult for the decoder to make sense of the features and force it to learn more complex mappings.
Decoder
The last section of an autoencoder, the decoder, is what that convnet attempts to make sense of the features coming from the encoder, which have been subsequently compressed in the bottleneck, to reconstruct the original image as it was.
Training an Autoencoder
In this section, we shall be implementing an autoencoder from scratch in PyTorch and training it on a specific dataset.
Let’s start by quickly importing our required packages.
# article dependencies
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as Datasets
from torch.utils.data import Dataset, DataLoader
import numpy as np
import matplotlib.pyplot as plt
import cv2
from tqdm.notebook import tqdm
from tqdm import tqdm as tqdm_regular
import seaborn as sns
from torchvision.utils import make_grid
import random
# configuring device
if torch.cuda.is_available():
device = torch.device('cuda:0')
print('Running on the GPU')
else:
device = torch.device('cpu')
print('Running on the CPU')
Preparing Data
For the purpose of this article, we will utilize the CIFAR-10 dataset in training a convolutional autoencoder. It can be loaded as seen in the code cell below.
# loading training data
training_set = Datasets.CIFAR10(root='./', download=True,
transform=transforms.ToTensor())
# loading validation data
validation_set = Datasets.CIFAR10(root='./', download=True, train=False,
transform=transforms.ToTensor())
Next, we need to extract only the images from the dataset. Since we are trying to teach an autoencoder to reconstruct images, the targets will not be class labels but the actual images themselves. An image from each class is also extracted and stored in the object ‘test_images’ just for visualization purposes, more on this later.
def extract_each_class(dataset):
"""
This function searches for and returns
one image per class.
"""
images = []
iterate = True
i = 0
j = 0
while iterate:
for label in tqdm(dataset.targets):
if label == j:
images.append(dataset.data[i])
print(f'Class {j} found')
i += 1
j += 1
if j == 10:
iterate = False
break
else:
i += 1
return images
# Extracting training images
training_images = [x for x in training_set.data]
# Extracting validation images
validation_images = [x for x in validation_set.data]
# Extracting one test image per class for visualization
test_images = extract_each_class(validation_set)
Now we need to define a PyTorch dataset class to be able to use the images as tensors. This, along with class instantiation, is done in the code cell below.
from torch.utils.data import Dataset
import torchvision.transforms as transforms
# Defining the custom dataset class
class CustomCIFAR10(Dataset):
def __init__(self, data, transforms=None):
self.data = data
self.transforms = transforms
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
image = self.data[idx]
if self.transforms is not None:
image = self.transforms(image)
return image
# Creating PyTorch datasets
transform_pipeline = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
training_data = CustomCIFAR10(training_images, transforms=transform_pipeline)
validation_data = CustomCIFAR10(validation_images, transforms=transform_pipeline)
test_data = CustomCIFAR10(test_images, transforms=transform_pipeline)
Autoencoder Architecture
A custom convolutional autoencoder architecture is defined for the purpose of this article, as illustrated below. This architecture is designed to work with the CIFAR-10 dataset as its encoder takes in 32 x 32 pixel images with three channels and processes them until 64 8 x 8 feature maps are produced.
These feature maps are then flattened to produce a vector of 4096 elements, which is then compressed to just 200 elements in the bottleneck. The decoder takes this 200-element vector representation and processes it via transposed convolution until a 3 x 32 x 32 image is returned as output.
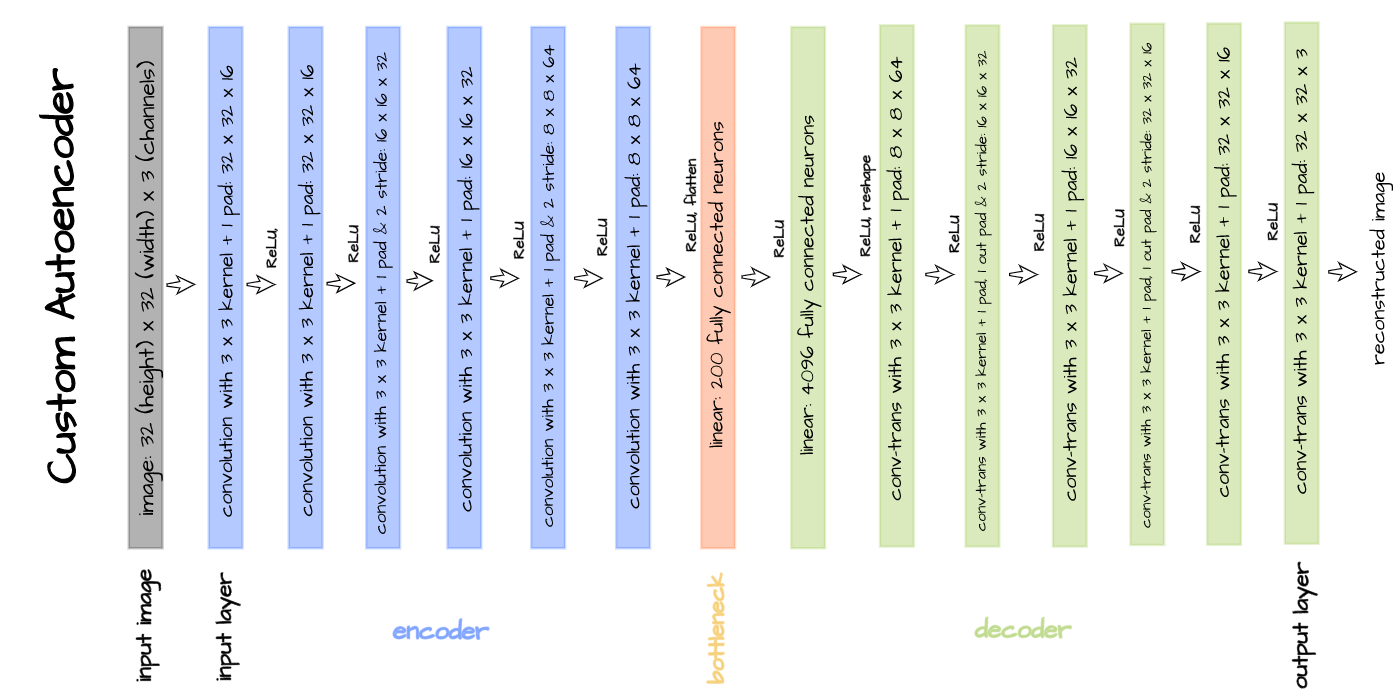
The above defined architecture is implemented in the code cell below. The parameter ‘latent_dim’ in this instance refers to the size of the bottleneck, which we have specified to be 200.
import torch
import torch.nn as nn
# Defining the Encoder
class Encoder(nn.Module):
def __init__(self, in_channels=3, out_channels=16, latent_dim=200, act_fn=nn.ReLU()):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1), # (32, 32)
act_fn,
nn.Conv2d(out_channels, out_channels, 3, padding=1),
act_fn,
nn.Conv2d(out_channels, 2 * out_channels, 3, padding=1, stride=2), # (16, 16)
act_fn,
nn.Conv2d(2 * out_channels, 2 * out_channels, 3, padding=1),
act_fn,
nn.Conv2d(2 * out_channels, 4 * out_channels, 3, padding=1, stride=2), # (8, 8)
act_fn,
nn.Conv2d(4 * out_channels, 4 * out_channels, 3, padding=1),
act_fn,
nn.Flatten(),
nn.Linear(4 * out_channels * 8 * 8, latent_dim),
act_fn
)
def forward(self, x):
x = x.view(-1, 3, 32, 32)
output = self.net(x)
return output
# Defining the Decoder
class Decoder(nn.Module):
def __init__(self, in_channels=3, out_channels=16, latent_dim=200, act_fn=nn.ReLU()):
super().__init__()
self.out_channels = out_channels
self.linear = nn.Sequential(
nn.Linear(latent_dim, 4 * out_channels * 8 * 8),
act_fn
)
self.conv = nn.Sequential(
nn.ConvTranspose2d(4 * out_channels, 4 * out_channels, 3, padding=1), # (8, 8)
act_fn,
nn.ConvTranspose2d(4 * out_channels, 2 * out_channels, 3, padding=1, stride=2, output_padding=1), # (16, 16)
act_fn,
nn.ConvTranspose2d(2 * out_channels, 2 * out_channels, 3, padding=1),
act_fn,
nn.ConvTranspose2d(2 * out_channels, out_channels, 3, padding=1, stride=2, output_padding=1), # (32, 32)
act_fn,
nn.ConvTranspose2d(out_channels, out_channels, 3, padding=1),
act_fn,
nn.ConvTranspose2d(out_channels, in_channels, 3, padding=1)
)
def forward(self, x):
output = self.linear(x)
output = output.view(-1, 4 * self.out_channels, 8, 8)
output = self.conv(output)
return output
# Defining the Autoencoder
class Autoencoder(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder.to(device)
self.decoder = decoder.to(device)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
Per usual, we now need to define a class that will help make training and validation more seamless. In this case, since we are training a generative model, losses might not carry too much information. In general, we want the loss to be reduced, and we can also use loss values to be able to see how well the autoencoder reconstructs images for every epoch. For this reason, I have included a visualization block as seen below.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
from tqdm import tqdm
# Defining the Convolutional Autoencoder Wrapper
class ConvolutionalAutoencoder():
def __init__(self, autoencoder):
self.network = autoencoder
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=1e-3)
def train(self, loss_function, epochs, batch_size, training_set, validation_set, test_set):
# Creating log
log_dict = {
'training_loss_per_batch': [],
'validation_loss_per_batch': [],
'visualizations': []
}
# Defining weight initialization function
def init_weights(module):
if isinstance(module, nn.Conv2d):
torch.nn.init.xavier_uniform_(module.weight)
module.bias.data.fill_(0.01)
elif isinstance(module, nn.Linear):
torch.nn.init.xavier_uniform_(module.weight)
module.bias.data.fill_(0.01)
# Initializing network weights
self.network.apply(init_weights)
# Creating dataloaders
train_loader = DataLoader(training_set, batch_size=batch_size)
val_loader = DataLoader(validation_set, batch_size=batch_size)
test_loader = DataLoader(test_set, batch_size=10)
# Setting network to training mode
self.network.train()
self.network.to(device)
for epoch in range(epochs):
print(f'Epoch {epoch + 1}/{epochs}')
train_losses = []
# ------------
# TRAINING
# ------------
print('Training...')
for images in tqdm(train_loader):
# Zeroing gradients
self.optimizer.zero_grad()
# Sending images to device
images = images.to(device)
# Reconstructing images
output = self.network(images)
# Computing loss
loss = loss_function(output, images.view(-1, 3, 32, 32))
# Calculating gradients
loss.backward()
# Optimizing weights
self.optimizer.step()
# Logging
log_dict['training_loss_per_batch'].append(loss.item())
# ------------
# VALIDATION
# ------------
print('Validating...')
for val_images in tqdm(val_loader):
with torch.no_grad():
val_images = val_images.to(device)
output = self.network(val_images)
val_loss = loss_function(output, val_images.view(-1, 3, 32, 32))
log_dict['validation_loss_per_batch'].append(val_loss.item())
# ------------
# VISUALIZATION
# ------------
print(f'Training Loss: {round(loss.item(), 4)} | Validation Loss: {round(val_loss.item(), 4)}')
for test_images in test_loader:
test_images = test_images.to(device)
with torch.no_grad():
reconstructed_imgs = self.network(test_images)
reconstructed_imgs = reconstructed_imgs.cpu()
test_images = test_images.cpu()
# Visualization
imgs = torch.stack([test_images.view(-1, 3, 32, 32), reconstructed_imgs], dim=1).flatten(0, 1)
grid = make_grid(imgs, nrow=10, normalize=True, padding=1)
grid = grid.permute(1, 2, 0)
plt.figure(dpi=170)
plt.title('Original / Reconstructed')
plt.imshow(grid)
plt.axis('off')
plt.show()
log_dict['visualizations'].append(grid)
return log_dict
def autoencode(self, x):
return self.network(x)
def encode(self, x):
encoder = self.network.encoder
return encoder(x)
def decode(self, x):
decoder = self.network.decoder
return decoder(x)
With everything set, we can then instantiate our autoencoder as a member of the convolutional autoencoder class we defined below, using the parameters as specified in the code cell that follows.
# training model
model = ConvolutionalAutoencoder(Autoencoder(Encoder(), Decoder()))
log_dict = model.train(nn.MSELoss(), epochs=10, batch_size=64, training_set=training_data, validation_set=validation_data, test_set=test_data)
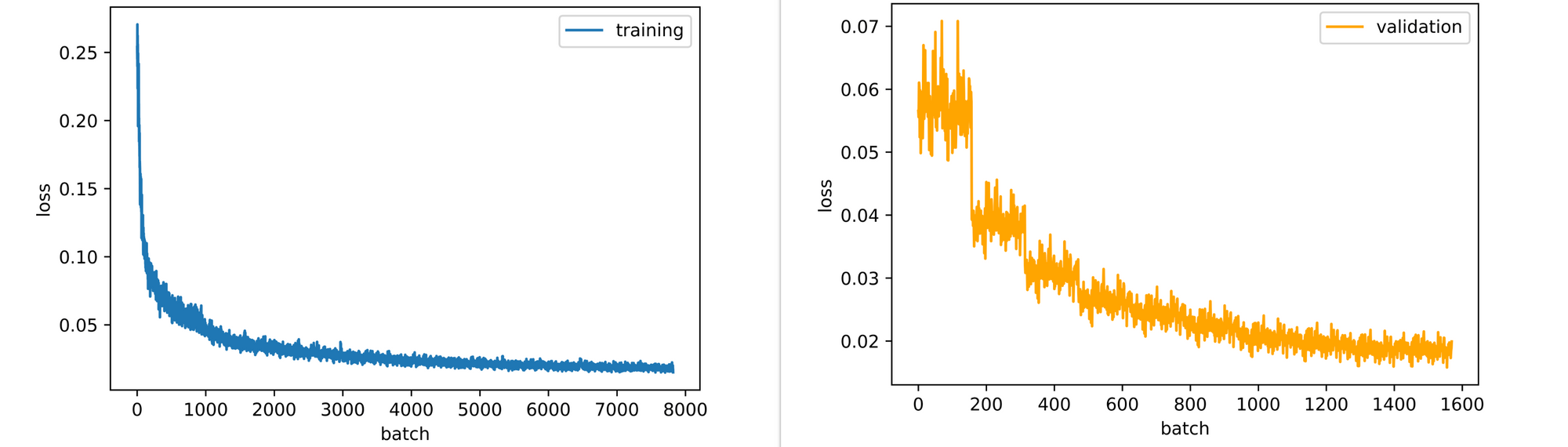
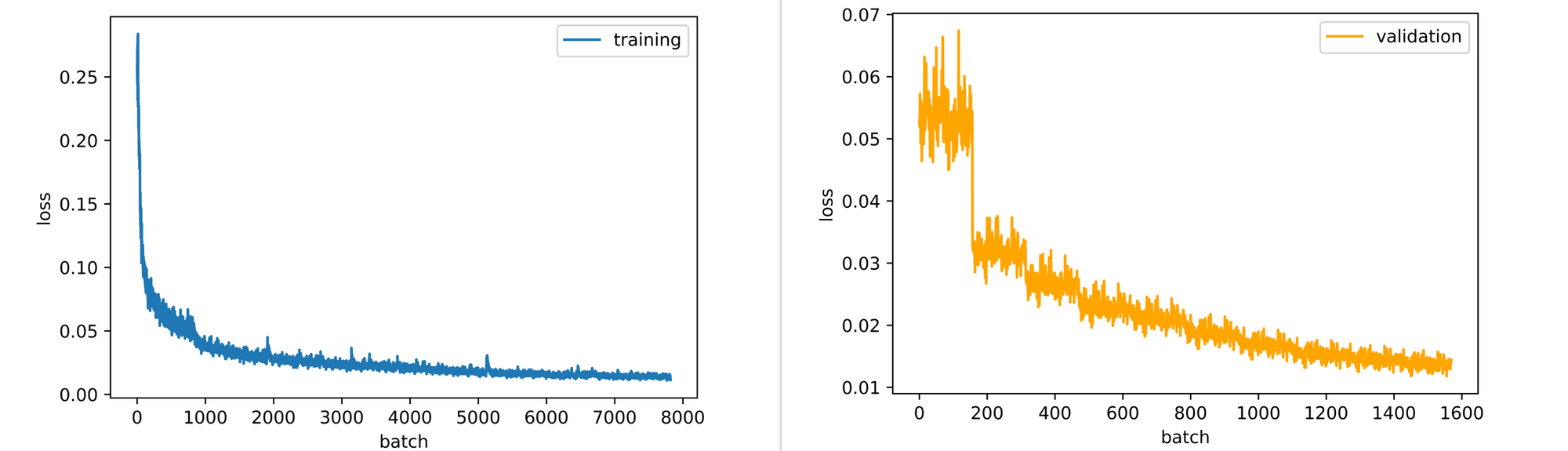
Right from the end of the first epoch, it is evident that our decoder has begun to develop a sense of how to reconstruct images fed into the encoder, even though it only had access to a compressed 200 element feature vector representation. Reconstructed images continue to increase in detail right up till the 10th epoch as well.
Looking at the training and validation losses, the autoencoder could still benefit slightly from some more epochs of training as its losses are still downtrending. This is the case for the validation loss more so than tthe raining loss, which seems to be plateauing.
Bottleneck and Details
In one of the previous sections, I had mentioned how the bottleneck code layer serves the purpose of further compressing a feature vector, so as to force the decoder to learn a more complex and generalizable mapping. On the flip side, a fine balance is to be sought as the magnitude of compression in the code layer would also influence how well a decoder can reconstruct an image.
The smaller the vector representation passed to the decoder, the fewer image features the decoder has access to and the less detailed its reconstructions will be. In the same sense, the bigger the vector representation passed to the decoder, the more image features it has access to and the more detailed its reconstructions will be. Following this line of thinking, let’s train the same autoencoder architecture, but this time using a bottleneck of size 1000.
# training model
model = ConvolutionalAutoencoder(Autoencoder(Encoder(latent_dim=1000), Decoder(latent_dim=1000)))
log_dict = model.train(nn.MSELoss(), epochs=10, batch_size=64,
training_set=training_data, validation_set=validation_data,
test_set=test_data)
From the visualizations generated per epoch, it is immediately evident that the decoder does a better job at reconstructing images in terms of detail and visual accuracy. This goes down to the fact that the new decoder has access to more features, as the original feature vector of 4096 elements is now downsampled to 1000 elements instead of 200.

Epoch 1 (top) vs Epoch 10 (bottom).
Again, the autoencoder could benefit from some more epochs of training. Its training and validation losses are still down-trending, with slopes steeper than those we observed when we trained our autoencoder with a bottleneck of just 200 elements.
Comparing bottlenecks of size 200 and 1000, both at the 10th epoch, shows clearly that images generated with a bottleneck of 1000 elements are clearer/more detailed than those generated with a bottleneck of 200 elements.

Bottleneck 200 (top) vs bottleneck 1000 (bottom), both at the 10th epoch.
Training to Absolute Refinement
At what point is a convolutional autoencoder optimally trained? From the two autoencoders we have trained, we can observe that reconstructions are still blurry at the 10th epoch, even though our loss plots had begun to flatten. Increasing the bottleneck size will only ameliorate this issue to an extent, but will not completely solve it.
This is partly down to the loss function used in this case, mean squared error, as it does not do too well while measuring losses in generative models. For the most part, these blurry reconstructions are the bane of convolutional autoencoder tasks. If one’s goal is to reconstruct or generate images, a generative adversarial network (GAN) or diffusion model may be a safer bet. However, that is not to say that convolutional autoencoders are not useful, as they can be used for anomaly detection, image denoising, and so on.
Real-world applications
Convolutional autoencoders’ ability to compress, reconstruct, and learn meaningful representations of complex visual data enables a wide range of real-world deep learning applications. Here are some prominent areas where convolutional autoencoders are making a significant impact:
1. Image Denoising
Real-world images often suffer from noise due to poor lighting, sensor imperfections, or transmission errors. Convolutional autoencoders excel at removing noise while preserving important image features. By training on pairs of noisy and clean images, a CAE learns to reconstruct a cleaner version, making it invaluable for:
- Medical imaging (e.g., reducing noise in MRI or X-ray scans)
- Astronomy (enhancing images captured through atmospheric disturbances)
- Mobile photography (improving low-light photos)
2. Anomaly Detection
Since CAEs are trained to reconstruct “normal” data patterns, they naturally struggle to accurately reconstruct anomalous or abnormal samples. This property is harnessed for detecting anomalies in:
- Industrial manufacturing: Identifying defective parts on production lines.
- Cybersecurity: Spotting unusual patterns in network traffic or system logs.
- Healthcare: Detecting abnormalities in medical images like CT or MRI scans.
3. Dimensionality Reduction and Feature Extraction
Traditional methods like PCA (Principal Component Analysis) are linear, but convolutional autoencoders perform non-linear dimensionality reduction, capturing richer, hierarchical representations. These compressed features can then be used for:
- Preprocessing inputs for supervised learning tasks.
- Visualizing complex datasets in lower-dimensional spaces (2D or 3D embeddings).
- Accelerating downstream classification or clustering tasks.
4. Image Compression
Autoencoders can learn efficient data representations that minimize reconstruction error with fewer bits, enabling lossy image compression. Companies and researchers use CAEs for:
- Compressing images for web and mobile applications to reduce bandwidth.
- Developing codecs tailored for specific image domains (e.g., satellite imagery).
5. Image Generation and Data Augmentation
By sampling from the latent space or introducing controlled perturbations, convolutional autoencoders can generate new, realistic images similar to the training data. This capability is useful for:
- Synthetic data generation to augment training datasets.
- Pretraining for generative models like Variational Autoencoders (VAEs) or GANs.
- Artistic style transfer and content-aware editing.
6. Medical Imaging and Diagnostics
In healthcare, convolutional autoencoders assist in:
- Segmentation tasks: Pretraining models to segment organs or tumors.
- Reconstruction: Improving the quality of low-dose CT scans.
- Rare disease detection: Learning representations from limited, clean datasets and detecting outliers.
7. Self-supervised Learning
Modern deep learning increasingly relies on self-supervised methods where labels are scarce or unavailable. Convolutional autoencoders play a key role by enabling models to learn useful representations simply by trying to reconstruct their input data, without requiring manual labeling. These learned embeddings can later boost the performance of supervised models with fewer labeled examples.
Final Remarks
In this article, we explored the concept of autoencoders, specifically for the image data. We understood the workings of convolutional autoencoders (CAEs), aiming to build an intuition about their underlying principles and their powerful capabilities in learning efficient representations of images.
We then broke down the architecture of a convolutional autoencoder, examining each component to understand its role in processing and reconstructing images. To solidify our understanding, we defined a custom autoencoder model, trained it on real-world image data, and reviewed the results to evaluate its performance.
For those looking to experiment with convolutional autoencoders and similar models, DigitalOcean offers excellent resources to accelerate development and deployment. DigitalOcean GPU Droplets are perfect for training large models like convolutional autoencoders, offering flexible, high-performance environments.
As the field of deep learning continues to evolve, having access to reliable cloud resources like those from DigitalOcean will only make it easier to experiment and scale your models.
Resources
- PyTorch 101, Understanding Graphs, Automatic Differentiation and Autograd
- Intro to optimization in deep learning: Gradient Descent
- Deep Learning Architectures Explained: ResNet, InceptionV3, SqueezeNet
- Evaluating The Key Metrics of Deep Learning Models
- The encoder-decoder architecture
- Encoder-Decoder: Features Extraction
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
