AI Technical Writer

Large Language Models have changed how we build applications, write content, and automate our day-to-day tasks. However, even the most capable LLMs are trained to be general-purpose systems. They do not naturally understand your internal documentation, your brand voice, or your company’s documentation. Prompt engineering can help to some extent, but prompts become longer, fragile, and inconsistent over time.
One way is to build your own model using your own data, or another shortcut is model fine-tuning**. Model Fine-tuning** offers a more powerful solution by allowing the model to adapt its behavior based on examples. Among modern fine-tuning techniques, LoRA has emerged as one of the most practical and cost-efficient ways to teach an LLM something new.
This article explains LoRA, clarifies what LoRA fine-tuning actually means, and walks through a complete implementation using custom data, including code and real-world guidance.
Key Takeaways
- LoRA enables parameter-efficient fine-tuning by freezing the base model and training only a small number of low-rank adapter weights, significantly reducing compute and memory requirements.
- This approach preserves the general reasoning capabilities of large language models while changing the model’s behavior, tone, and structure to a specific domain.
- LoRA fine-tuning is best suited for behavioral and task adaptation rather than injecting large volumes of new factual knowledge.
- High-quality, well-structured datasets have a greater impact on LoRA performance than sheer dataset size.
- LoRA adapters are lightweight and modular, making it possible to maintain multiple domain-specific behaviors using a single base model.
- LoRA integrates well with retrieval-based techniques, such as RAG, thereby allowing for scalable systems that combine learned behavior with dynamic knowledge access.
- The low cost and fast iteration cycle of LoRA make it particularly suitable for experimentation, prototyping, and production deployments.
Understanding LoRA at a Deeper Level
LoRA, which stands for Low-Rank Adaptation, is a parameter-efficient fine-tuning method designed specifically for large neural networks such as transformers. Traditional fine-tuning requires updating all model weights, which is computationally expensive and memory-intensive when dealing with models containing billions of parameters. LoRA avoids this by freezing the original model weights entirely and introducing a small number of new trainable parameters that learn how to adapt the model’s behavior.
Inside transformer models, most of the learning capacity comes from large matrix multiplications, particularly in attention layers. LoRA works by approximating updates to these large matrices using two much smaller matrices whose product represents the change needed for the task.
Because these matrices are low-rank, the number of parameters that need to be trained is dramatically reduced. The base model remains unchanged, preserving its general knowledge, while the LoRA layers specialize it for a new task or domain.
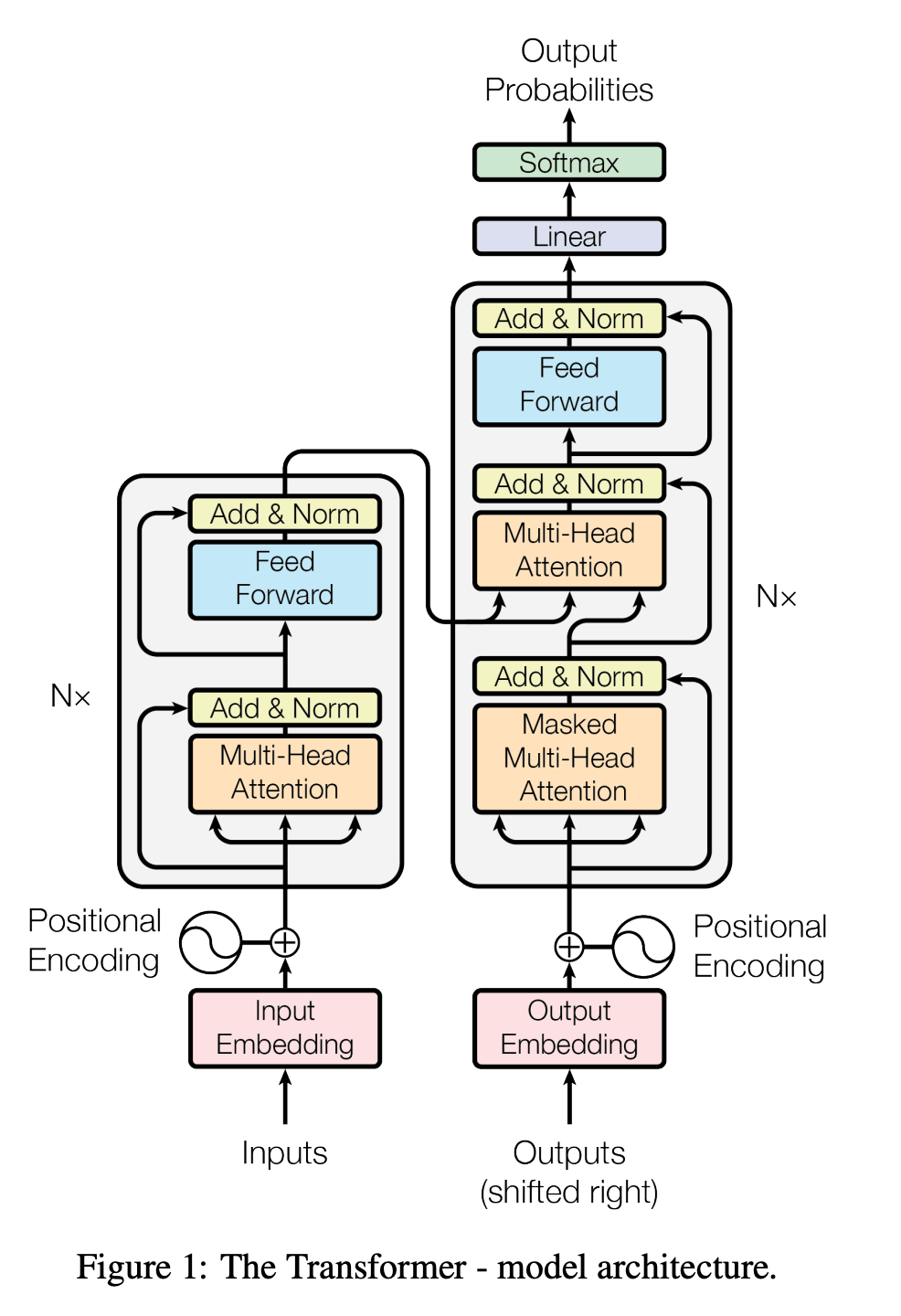
One of the most powerful aspects of LoRA is that these adaptations are modular. A single base model can support multiple LoRA adapters, each trained for a different purpose, and they can be swapped in and out without retraining or redeploying the entire model.
What LoRA Fine-Tuning Actually Means
LoRA fine-tuning refers to the process of training only the LoRA adapter layers on a custom dataset while keeping the base language model frozen. Instead of teaching the model everything from scratch, you are guiding it toward a specific behavior by adjusting how it processes information in key layers. This approach is particularly effective when the goal is to modify writing style, response structure, tone, or domain understanding rather than to inject massive amounts of new factual knowledge.
When you fine-tune with LoRA, the model learns patterns from your examples and internalizes them in the adapter weights. During inference, the model combines its original knowledge with the learned adaptations, resulting in outputs that feel native to your domain while retaining general reasoning capabilities.
This is fundamentally different from retrieval-based approaches such as RAG, where external documents are fetched at runtime. LoRA fine-tuning changes how the model behaves, whereas RAG changes what the model has access to.
Preparing Custom Data for LoRA Fine-Tuning
The quality of a LoRA fine-tuned model is determined largely by the quality of the training data. Since LoRA relies on fewer parameters, it is especially sensitive to inconsistencies, noise, and poorly structured examples. The most effective datasets are formatted as instruction-response pairs or chat conversations that closely resemble how the model will be used in production.
Each example should clearly demonstrate the behavior you want the model to learn. If the task involves summarization, explanations, or domain-specific writing, the outputs should be consistent in tone, length, and structure. Repetitive or contradictory examples should be avoided because they can confuse the adapter and reduce generalization.
Hands-On training LoRA Fine-Tuning Qwen on a custom Dataset
In this section, we will fine-tune a Qwen instruction model using LoRA to teach it knowledge specific to DigitalOcean. The goal is to teach the model about DigitalOcean so it can confidently answer customer-support-style questions about GPU Droplets, SSH access, and VS Code workflows, without retraining the full model.
We use a lightweight JSON dataset and train only a small set of parameters using LoRA, making this approach efficient even on a single GPU Droplet.
Define the Dataset Format
Qwen works well with a simple causal language modeling format where each example consists of a prompt followed by its expected completion. Each training sample must contain exactly two keys: prompt and completion.
Here is an example of the custom dataset saved as digitalocean.json:
{
"prompt": "What is a DigitalOcean GPU Droplet?",
"completion": "A DigitalOcean GPU Droplet is a cloud virtual machine equipped with NVIDIA GPUs, designed for compute-intensive workloads such as machine learning training, deep learning inference, and large-scale data processing."
}
Another example might look like this:
{
"prompt": "Why can't I connect to my GPU Droplet using SSH?",
"completion": "SSH connection issues usually occur due to incorrect usernames, missing SSH keys, or firewall rules blocking port 22. Verifying the Droplet status and SSH configuration typically resolves the issue."
}
This format allows the model to learn how to respond naturally to user questions, which is ideal for customer-support-style assistants.
Load the Dataset
Once the dataset is ready, we load it using the Hugging Face datasets library.
from datasets import load_dataset
dataset = load_dataset(
"json",
data_files="digitalocean.json"
)
print(dataset["train"][0])
At this stage, each entry is still raw text and must be tokenized before training.
Tokenization and Preprocessing
Qwen models expect tokenized inputs where the model predicts the next token in a sequence. To achieve this, we concatenate the prompt and completion into a single training string and use the same tokens as labels.
from transformers import AutoTokenizer
model_name = "Qwen/Qwen2.5-3B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess(example):
combined_text = example["prompt"] + "\n" + example["completion"]
tokens = tokenizer(
combined_text,
max_length=256,
padding="max_length",
truncation=True
)
tokens["labels"] = tokens["input_ids"].copy()
return tokens
tokenized_data = dataset.map(preprocess)
By setting labels equal to input IDs, we train the model in a causal language modeling setup, where it learns to generate the completion given the prompt.
Load the Base Qwen Model
Next, we load the base Qwen model in half precision to reduce GPU memory usage. This is especially important when running on a single GPU Droplet.
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
At this point, the model is still fully frozen and has not been adapted to DigitalOcean-specific knowledge or to the custom data.
Attach LoRA Adapters
Instead of fine-tuning all model parameters, we attach LoRA adapters to the attention layers. These adapters will be the only trainable components during training.
from peft import LoraConfig, get_peft_model, TaskType
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["q_proj", "k_proj", "v_proj"]
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
This step typically reduces the number of trainable parameters to well under one percent of the original model size.
Train the LoRA Adapter
With the dataset prepared and LoRA configured, we can proceed with training. The training configuration below is intentionally simple and works well for small to medium-sized datasets.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./qwen-do-lora",
num_train_epochs=8,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=2e-4,
logging_steps=20,
fp16=True,
save_strategy="epoch",
report_to="none"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_data["train"]
)
trainer.train()
Training typically completes within minutes on a GPU with 16 GB of VRAM, depending on dataset size and sequence length.
Save the Fine-Tuned Adapter
After training finishes, we save only the LoRA adapter and tokenizer. This keeps the output lightweight and easy to deploy.
model.save_pretrained("./qwen-do-lora")
tokenizer.save_pretrained("./qwen-do-lora")
The base model remains unchanged and can be reused for other adapters.
Load the Fine-Tuned Model for Inference
To use the fine-tuned model, we reload the base model and attach the trained LoRA adapter.
from peft import PeftModel, PeftConfig
adapter_path = "./qwen-do-lora"
config = PeftConfig.from_pretrained(adapter_path)
base_model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
torch_dtype=torch.float16,
device_map="auto"
)
model = PeftModel.from_pretrained(base_model, adapter_path)
tokenizer = AutoTokenizer.from_pretrained(adapter_path)
Ask the Fine-Tuned Model a Question
Now the model can answer questions based on your custom dataset that it was not explicitly trained for during pretraining.
inputs = tokenizer(
"How does VS Code connect to a DigitalOcean GPU Droplet?",
return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=150
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
VS Code connects to a DigitalOcean GPU Droplet using SSH through the Remote SSH extension.
After installing the extension, you configure an SSH host that points to your Droplet’s public IP address and authentication key.
Once connected, VS Code runs commands directly on the remote machine, allowing you to edit files, run training scripts, and monitor GPU workloads as if the environment were local.
The response will reflect the tone, clarity, and technical focus learned from your DigitalOcean dataset.
LoRA, or low-rank adaptation fine-tuning, works best when the dataset is in synched with real usage. If the training data is too small, inconsistent, or incorrect, the model may overfit or produce unstable outputs. The quality of your training data directly determines what the model learns and how well it performs.
Adjusting the rank, learning rate, and number of epochs can significantly improve results, but these changes should always be validated using test examples. In many production systems, LoRA is combined with RAG to balance behavioral adaptation with up-to-date factual accuracy.
FAQs
Is LoRA fine-tuning the same as full fine-tuning?
No, LoRA fine-tuning is fundamentally different from full fine-tuning. Full fine-tuning updates all model parameters, which is expensive and often unnecessary. However, LoRA fine-tuning freezes the base model and trains only a small number of additional parameters, making it faster, cheaper, and more stable while still achieving strong domain adaptation.
How much data do I need for LoRA fine-tuning?
LoRA can produce meaningful results with a relatively small dataset, often a few hundred high-quality examples. The key factor is not volume but consistency and relevance. Well-curated examples that reflect real usage patterns are far more effective than large, noisy datasets.
Can LoRA add new factual knowledge to a model?
LoRA is not ideal for injecting large amounts of new factual information. It is best suited for teaching style, tone, task structure, and domain-specific reasoning. For frequently changing or large factual datasets, retrieval-augmented generation is a better solution.
Which models work best with LoRA?
LoRA works well with most transformer-based causal language models, including Qwen, LLaMA, Mistral, and DeepSeek. Models with clearly defined attention projection layers are particularly easy to adapt using LoRA, as these layers are common targets for low-rank adapters.
Does LoRA affect inference speed?
LoRA adds minimal overhead during inference. Since the adapters are small and only modify a subset of computations, the performance impact is typically negligible compared to the base model. In many cases, inference speed remains nearly identical.
Can I use multiple LoRA adapters with one base model?
Yes. One of LoRA’s strengths is modularity. You can maintain multiple adapters for different domains or tasks and load them dynamically on top of the same base model, avoiding the need to store or deploy multiple full model checkpoints.
How do I evaluate whether LoRA fine-tuning worked?
Evaluation should focus on task-specific outputs rather than generic benchmarks. Comparing responses before and after fine-tuning, testing on held-out examples, and validating behavior consistency are often more informative than raw accuracy metrics.
Is LoRA suitable for production systems?
Yes, LoRA is well-suited for production use. Its low memory footprint, fast training time, and modular deployment model make it easier to version, monitor, and update compared to full fine-tuned models.
Conclusions
LoRA fine-tuning is one of the easiest and cost-effective ways to make your model understand your custom data. Instead of treating fine-tuning as an expensive, high-risk operation, LoRA reframes it as a lightweight and repeatable process that fits naturally into modern development workflows. By keeping the base model intact and learning only what’s necessary, LoRA makes customization feel approachable instead of overwhelming.
What really stands out is how flexible this approach is. You don’t need a new model for every use case. One strong foundation model can support many different behaviors through small, interchangeable adapters. This makes it much easier to evolve a system over time, respond to new requirements, and keep costs under control without sacrificing quality.
At its core, LoRA is less about forcing models to learn more and more data and more about teaching them how to behave in the right way. With thoughtful examples and clear intent, you can guide a model to speak your domain’s language, follow your structure, and support real users more effectively.
References
- How to Fine Tune a LLM using LoRA
- Implementing LoRA From Scratch for Fine-tuning LLMs
- Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
- Fine-Tuning a Language Model with Custom Knowledge
- LoRA: Low-Rank Adaptation of Large Language Models Explained
- Fine-Tuning LLMs on a Budget: Using DigitalOcean GPU Droplets
- LLM Fine-Tuning: A Guide for Domain-Specific Models
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
