AI Technical Writer

Introduction
In recent years, we have seen models like Large Language Models (LLMs) such as GPT, LLaMA, and Falcon have shown incredible capabilities in writing human-like text, translating languages, coding, summarizing documents, and more. But what if you want to make one of these models better at a very specific task, like analyzing legal documents or generating customer service replies in a specific tone?
Well, there is a way to do so with these models, and it is by fine-tuning the models on specific datasets.
Fine-tuning is the process of teaching a pre-trained model new tricks by training it further on a domain-specific dataset. While it sounds straightforward, the reality is… It’s expensive.
Key Takeaways
- LoRA (Low-Rank Adaptation) is a lightweight way to fine-tune large language models (LLMs) without updating all their parameters.
- It works by injecting small trainable matrices into the frozen model layers, reducing GPU memory usage and training cost.
- LoRA is ideal when full fine-tuning is too expensive or unnecessary.
- It integrates easily with the Hugging Face PEFT (Parameter-Efficient Fine-Tuning) library.
- LoRA is widely used in chatbot training, instruction tuning, and domain-specific LLMs.
- It’s also effective in fine-tuning multimodal models like MiniGPT-4 and LLaVA.
- Despite its benefits, LoRA has limitations, like being task-specific and less effective on very small datasets.
- The future of LoRA includes dynamic routing, adapter composition, and better support for quantized models (like QLoRA).
Why Full Fine-Tuning Is So Resource-Intensive
Imagine having a 65-billion parameter model and needing to update all of those parameters to adapt it to your specific task. Full fine-tuning means retraining every one of those billions of parameters, which requires:
- Massive compute power (think multiple GPUs or even TPUs),
- Huge amounts of memory and storage, and
- A long training time, which increases both cost and complexity.
- Complex infrastructure setup and management.
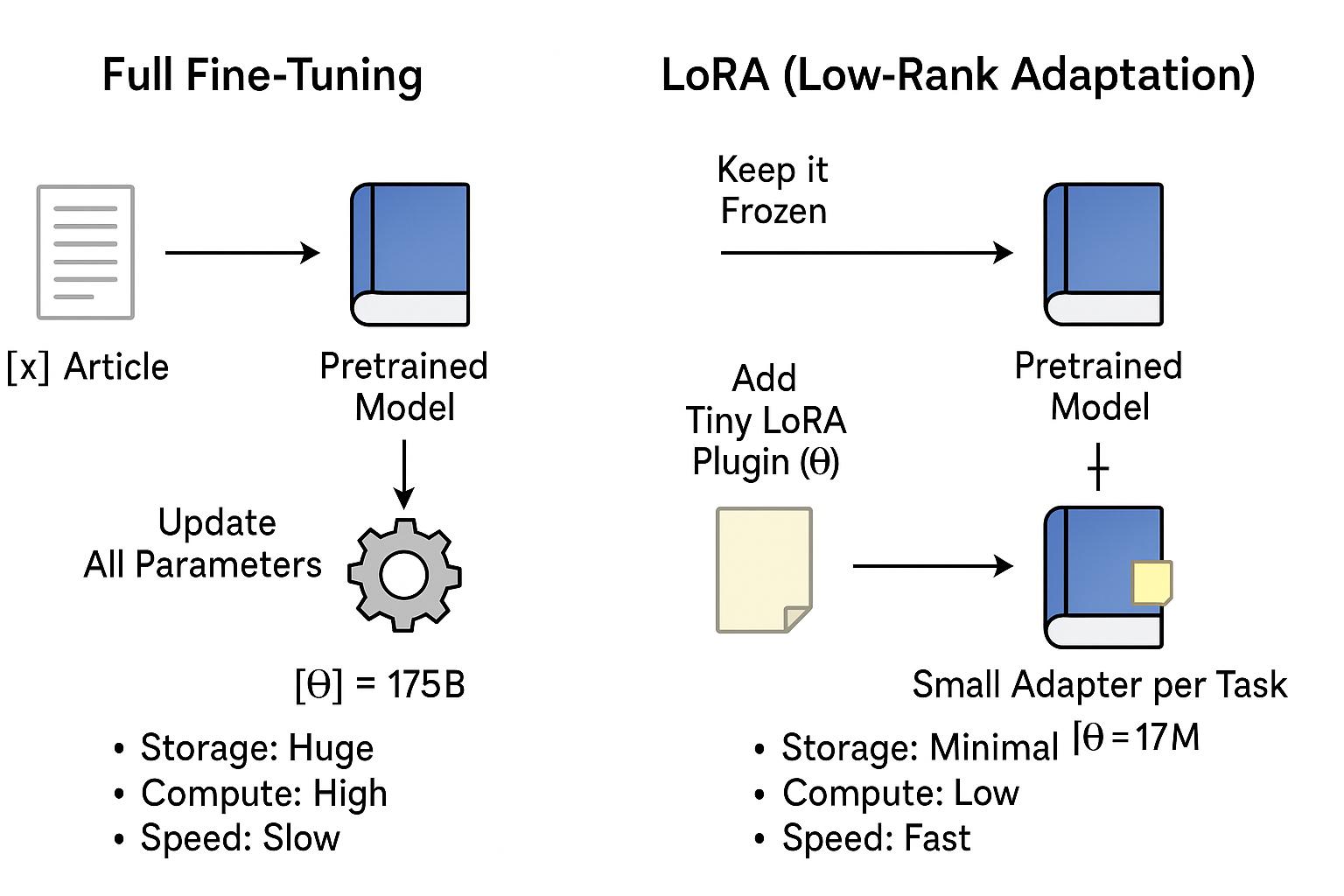
For individuals, startups, and even large enterprises, this can be impractical unless you have access to high-end infrastructure (like NVIDIA H100s or large-scale cloud GPU clusters).
One of the practical solutions is DigitalOcean’s Gradient. DigitalOcean’s virtual machines come with dedicated GPU access available with powerful hardware like NVIDIA RTX 4000 Ada Generation and H100, designed specifically for AI/ML workloads.
With GPU Droplets, you can:
- Launch a GPU droplet for LLM fine-tuning within minutes.
- Choose from different GPU types depending on your compute needs.
- Scale up or down based on training phases (e.g., heavier compute for training, lighter for inference).
- Avoid the complexity of managing hardware or provisioning clusters.
- Optimize cost by paying only for what you use.
For example, if you’re fine-tuning a model on domain-specific customer support queries using a 67B parameter model, you could spin up a DigitalOcean H100 GPU Droplet, run your training pipeline using tools like Hugging Face Transformers or PEFT libraries, and shut it down after completion without needing to invest in physical hardware.
PEFT: Smarter Fine-Tuning
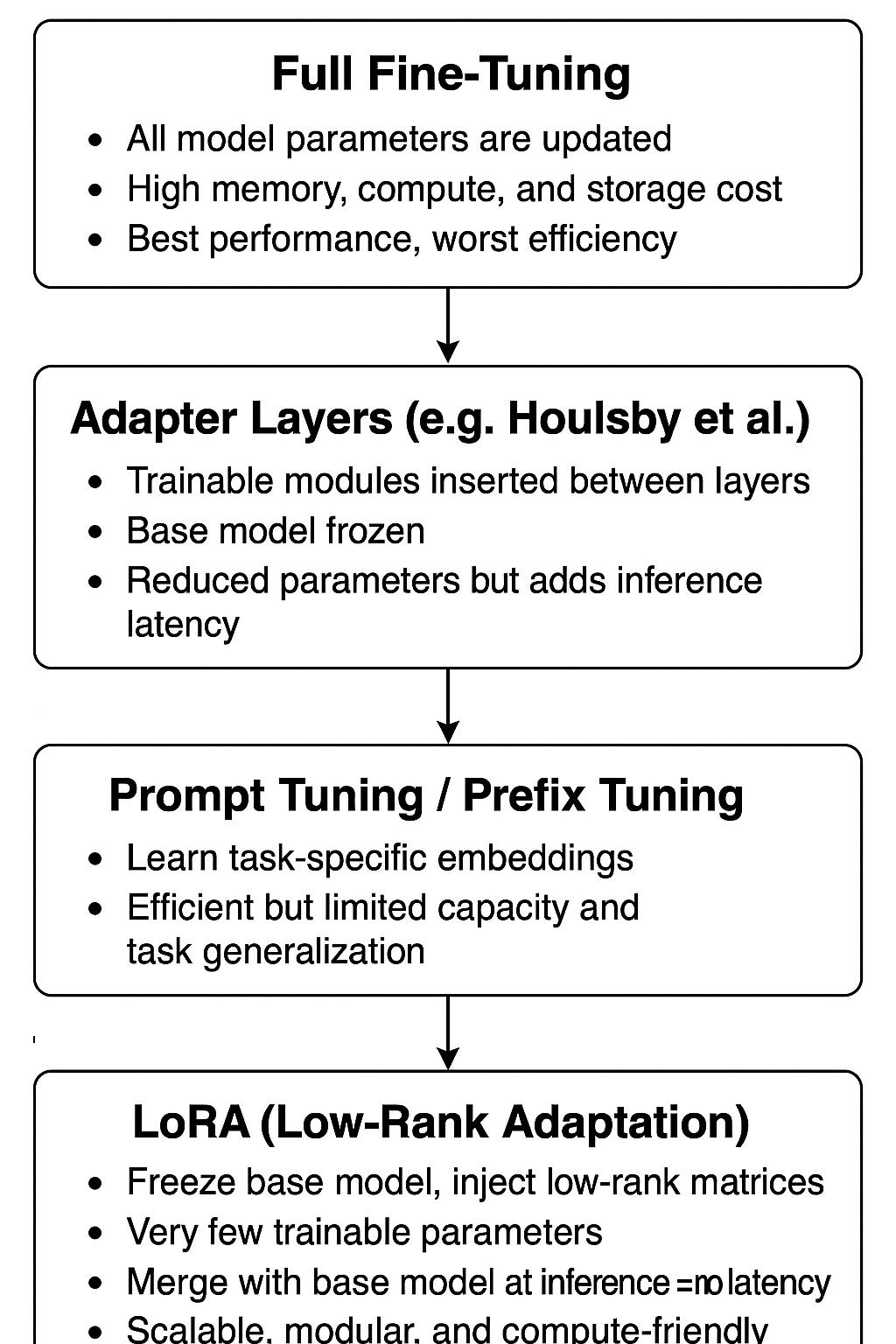
Parameter-Efficient Fine-Tuning (PEFT) techniques come to the rescue. Instead of updating all of a model’s parameters, PEFT methods focus on tweaking only a small portion, leaving the rest of the model untouched. It’s like adding a few smart layers on top of an already brilliant mind, instead of reprogramming the entire brain.
There are several PEFT methods like adapters, prefix tuning, and LoRA, but in this article, we’ll focus on one of the most widely adopted and efficient: LoRA (Low-Rank Adaptation).
What is LoRA?
LoRA is a parameter-efficient fine-tuning technique for large language models (LLMs). Imagine a pretrained LLM like a huge book that has thousands of pages, but now you want to finish the book in a day, so instead of going through the entire book, you just read the highlighted portions of the book.
Full fine-tuning is like reading the entire book, and LoRA is like reading only the highlighted points, which are important.
LoRA is a parameter-efficient fine-tuning technique for large language models (LLMs). Instead of updating all the model’s weights during fine-tuning (which can be billions of parameters), LoRA introduces small trainable matrices that approximate the weight updates using low-rank decomposition.
This drastically reduces:
- Training costs
- GPU memory usage
- Time taken to adapt models for new tasks
How LoRA Works (Technically Simplified)
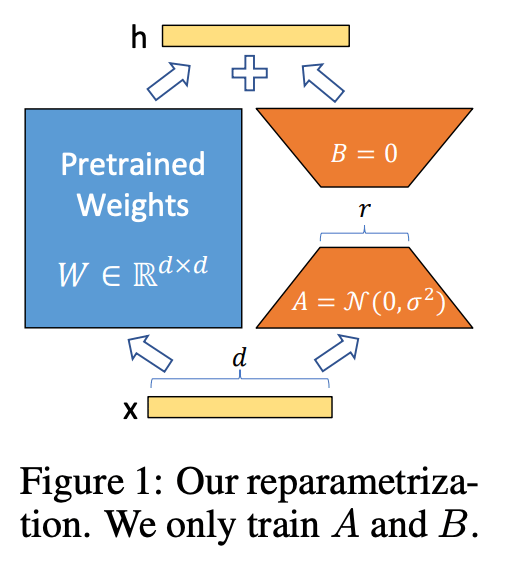
Let’s now break down how LoRA (Low-Rank Adaptation) works in detail and why this approach is efficient.
In deep learning models that come with a large number of parameters, weights are large matrices (W) that hold the learned knowledge of the model. These matrices define how input data gets transformed at each layer of the dense network.
For example, in a Transformer model:
- A weight matrix
Wmight transform an input vector into a query, key, or value vector. - These matrices are huge, especially in large models like GPT-3.
Now, during full fine-tuning, we update all weights W to better fit a specific task. For a model like GPT-3 with 175 billion parameters, this is resource-heavy and hard to store/deploy for each task. Hence, instead of changing the original weights W, LoRA keeps them frozen and adds a small trainable update using two smaller matrices: A and B.
Therefore, the new weight becomes:
W′ = W + ΔW = W + A⋅B
Where:
Wis the original pre-trained weight (not updated)AandBare small, trainable matricesΔW = A·Bis a low-rank approximation of the full update
Understanding A and B Matrices
Suppose W is a matrix of shape (d × k). Let us take the value of the matrix as 1024 × 1024.
Then we define:
Aas a matrix of shape(d × r)Bas a matrix of shape(r × k)- Where
ris the low-rank dimension (typically small, e.g.,r = 8orr = 4)
So:
A·Bgives a matrix of shape(d × k), same asW, but is constructed from two much smaller matrices.
By training only A and B, we get an efficient approximation of the full ΔW.
What is Low-Rank Dimension r?
The rank of a matrix is the number of independent rows or columns it has.
- A “full-rank” matrix uses its full dimensional capacity, which is expensive.
- A low-rank approximation assumes that the meaningful information can be captured by fewer dimensions (
r << d or k).
LoRA assumes that the most useful fine-tuning information can be captured with small changes to the original matrix, so we don’t need a full-rank update.
By choosing a small r (like 4, 8, or 16), we thus reduce the number of trainable parameters and reduce the memory usage, which in turn speeds up the training process.
Typically, the training Flow in LoRA follows the steps below:
- Start with a pretrained model → Keep all weights frozen
- For certain matrices (like in attention layers), add LoRA:
W′=W+A⋅B - Only train
AandB(Θ parameters) - At inference time,
A·Bis merged intoW, or applied dynamically
LoRA is modular, which means you can apply it to selected parts of the model, which gives even more control over efficiency.
For example:
Say the original weight W is 1024×1024 = 1 million parameters
-
Full update: 1M trainable parameters
-
LoRA with
r = 8:A: 1024×8 = 8,192B: 8×1024 = 8,192- Total: 16,384 trainable parameters → Only 1.6% of full
LoRA and related works
Transformer-Based Language Models
The foundation of LoRA lies in the widespread success of Transformer architectures, which introduced self-attention mechanisms for sequence modeling. This architecture was adapted for autoregressive language modeling and later scaled significantly in models like GPT-2 and GPT-3. Fine-tuning large pre-trained models such as BERT and GPT-2 on downstream tasks became the standard practice, offering strong performance gains. However, this process is computationally expensive and memory-intensive, especially for very large models like GPT-3 with 175 billion parameters.
Prompt Engineering and Full Fine-Tuning
While prompt engineering has emerged as a lightweight way to condition models on specific tasks, its effectiveness is highly sensitive to prompt format. Fine-tuning all parameters of a large model often yields better performance but is limited by high compute requirements and large checkpoint sizes.
Parameter-Efficient Alternatives
Several methods have been proposed to reduce the resource burden of full fine-tuning. Adapter-based methods insert small trainable modules between layers of a frozen base model. However, such methods often introduce latency during inference, as the adapter layers must be computed separately.
LoRA differs by using a low-rank decomposition of the weight update, allowing the trainable parameters to be merged with the frozen base model at inference time, eliminating additional latency.
Prompt Tuning and Embedding Optimization
Other techniques, like prompt tuning, optimize continuous input embeddings to steer the model’s behavior. While lightweight and effective for small-scale tasks, these methods are constrained by prompt length and often underperform on complex or multi-task learning scenarios.
Low-Rank Structures in Deep Learning
The idea of using low-rank approximations in deep learning is well-supported by earlier work. Prior studies suggest that over-parameterized neural networks often develop low-rank properties after training. Several researchers have even trained models with explicit low-rank constraints. However, LoRA is distinct in applying low-rank updates to a frozen pretrained model to adapt it for downstream tasks, which had not been deeply explored before.
Theoretical work also supports the potential of low-rank structures for improved generalization and adversarial robustness, adding further motivation for LoRA’s approach.
Real-World Applications
Instead of training a separate language model for each industry (like healthcare, law, or finance), you can use a single general-purpose model and add a LoRA adapter trained on your domain data.
- Medical QA: Fine-tune a LoRA adapter on PubMed articles to answer patient questions.
- Legal Assistant: Add an adapter trained on court judgments and legal clauses.
- Finance: Use domain-specific LoRA for compliance report generation or financial statement analysis.
- LoRA in Multimodal LLMs (e.g., LLaVA, MiniGPT-4): Multimodal LLMs process both text and images. LoRA helps make them task-aware without retraining the full image-text model.
How it works:
Real-world examples:
Image Captioning
Company: Caption Health (acquired by GE HealthCare)
- Use Case: Trains AI models to interpret and describe ultrasound images for medical diagnostics.
- LoRA Relevance: LoRA enables fine-tuning large vision-language models on specific datasets like echocardiograms without needing full retraining, which is critical for updating models with new scanning protocols or patient demographics efficiently.
Visual Question Answering (VQA)
Company: Abridge AI
- Use Case: Processes clinical notes, reports, and visuals (like lab charts or prescription tables) to extract answers to doctors’ queries.
- LoRA Relevance: Enables rapid, domain-specific fine-tuning on medical chart datasets to improve model performance without exceptionally high GPU costs.
Multimodal Tutoring Bots
Company: Socratic by Google
- Use Case: Assists students by analyzing homework problems, including diagrams and handwritten equations.
- LoRA Relevance: Allows continuous improvement of tutoring models on niche educational content e.g., physics circuit diagrams without retraining the entire model.
Fine-tune MiniGPT-4 with a LoRA adapter on annotated graphs and scientific papers, the model learns to understand and explain visual data.
Code Example: Fine-Tuning with LoRA (using Hugging Face PEFT library)
Here’s a detailed, complete example of how to fine-tune a model using LoRA with the Hugging Face PEFT library (Parameter-Efficient Fine-Tuning). We’ll walk through the following steps:
Step 1: Environment Setup
Install all necessary libraries:
pip install transformers datasets peft accelerate bitsandbytes
Step 2: Load a Base Model (e.g., GPT2)
For demonstration, we’ll use GPT2 and fine-tune it on a small dataset like IMDb reviews (for sentiment generation). You can replace this with LLaMA or any other model if needed.
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load GPT2 model and tokenizer
base_model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
model = AutoModelForCausalLM.from_pretrained(base_model_name)
# GPT2 doesn't have pad token by default
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
Step 3: Apply LoRA Using PEFT
from peft import get_peft_model, LoraConfig, TaskType
# Define the LoRA configuration
lora_config = LoraConfig(
r=8, # Low-rank dimension
lora_alpha=32,
target_modules=["c_attn"], # Target GPT2's attention layers
lora_dropout=0.1,
bias="none",
task_type=TaskType.CAUSAL_LM # Causal Language Modeling task
)
# Apply LoRA to the model
from peft import prepare_model_for_kbit_training
model = get_peft_model(model, lora_config)
# Check the number of trainable parameters
model.print_trainable_parameters()
Step 4: Dataset and Tokenization
Let’s use Hugging Face’s IMDb dataset for demonstration:
from datasets import load_dataset
# Load small dataset
dataset = load_dataset("imdb", split="train[:1%]")
# Preprocess the data
def tokenize(example):
return tokenizer(example["text"], padding="max_length", truncation=True, max_length=128)
tokenized_dataset = dataset.map(tokenize, batched=True)
tokenized_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
Step 5: Training
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./lora_gpt2_imdb",
per_device_train_batch_size=8,
num_train_epochs=1,
logging_steps=10,
save_steps=100,
save_total_limit=2,
fp16=True,
report_to="none"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset
)
trainer.train()
Step 6: Saving LoRA Adapters
# Save the LoRA adapter (not full model)
model.save_pretrained("./lora_adapter_only")
tokenizer.save_pretrained("./lora_adapter_only")
Step 7: Inference (with or without merging)
Option 1: Using LoRA adapters only (faster to switch tasks)
from peft import PeftModel, PeftConfig
# Load base model again
base_model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Load LoRA adapter
peft_model = PeftModel.from_pretrained(base_model, "./lora_adapter_only")
peft_model.eval()
# Inference
prompt = "Once upon a time"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = peft_model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Option 2: Merge LoRA into base weights (for export/deployment)
merged_model = peft_model.merge_and_unload()
# Save merged model (optional)
merged_model.save_pretrained("./gpt2_with_lora_merged")
# Inference with merged model
outputs = merged_model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Here is a complete recap of the steps to use LoRA
| Step | Description |
|---|---|
| Setup | Install required libraries |
| Base Model | Loaded GPT2 (can replace with LLaMA etc.) |
| LoRA Config | Applied using peft.LoraConfig |
| Training | Using Hugging Face Trainer |
| Saving | Saved only the adapter (efficient!) |
| Inference | Adapter-based or merged weights |
Feel free to try out the same tutorial using LLaMA or with int8/4-bit quantization for GPU memory savings!
Limitations and Considerations
While LoRA offers an efficient and cost-effective way to fine-tune large models, it’s not without its trade-offs. Understanding these limitations helps ensure you choose the right approach for your specific use case. Here are a few important considerations to keep in mind:
Task-Specific: LoRA adapters trained on one task may not generalize well to others. You may need separate adapters for different tasks.
Batching Complications: If you want to run multiple tasks at the same time (say, for different users or use cases), it’s harder to combine them into a single forward pass, especially if each one uses a different LoRA module. This can be tricky in real-time systems that need fast responses.
Inference Latency Trade-offs: If you “merge” LoRA with the base model for faster inference, it’s harder to switch between tasks on the fly. If you don’t merge them, you can switch tasks more flexibly—but your model might run a little slower.
Adapter Management: When using multiple adapters (e.g., for multi-task learning), managing and composing them correctly can be challenging.
Future of LoRA and PEFT
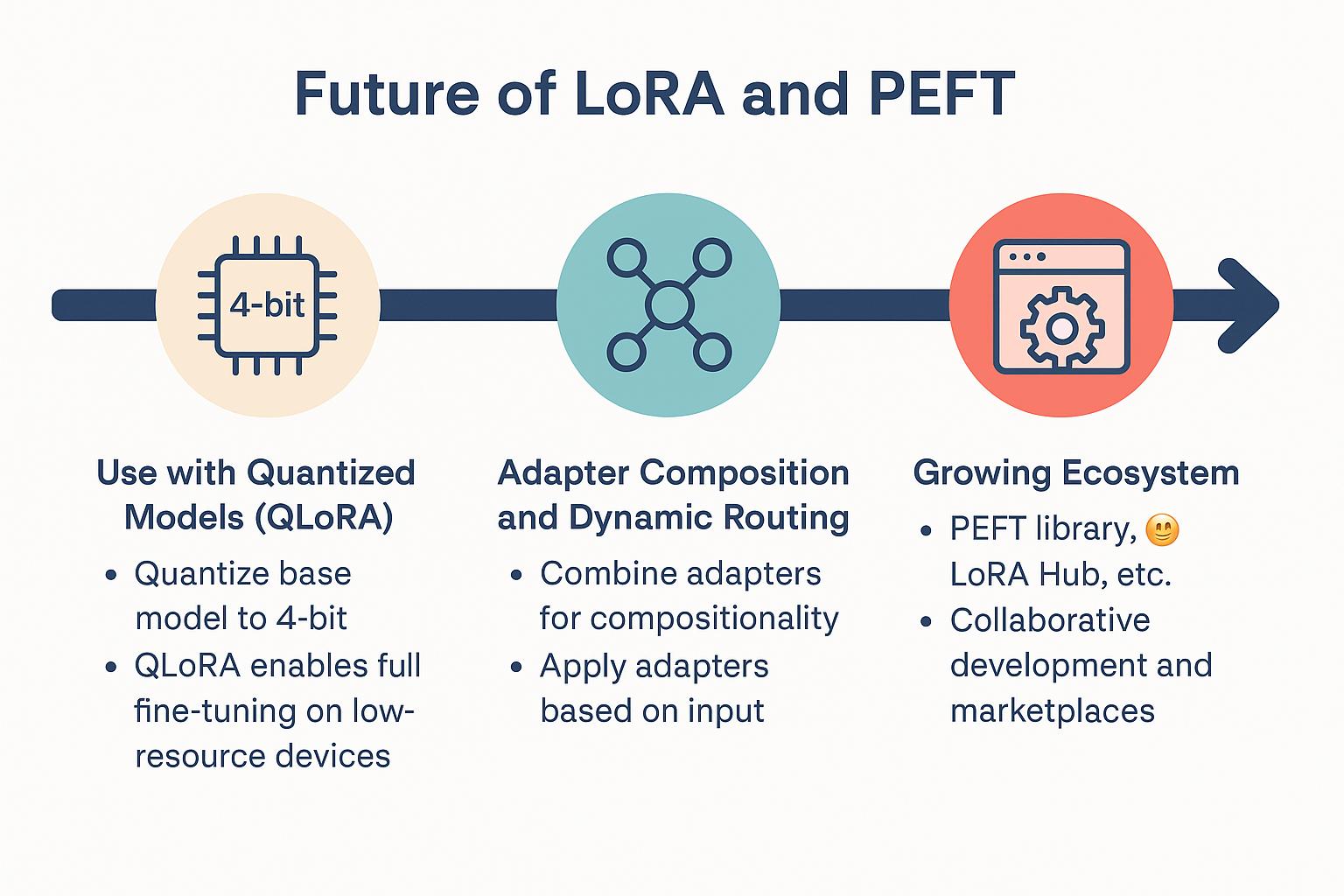
As the demand for deploying large language models (LLMs) on low-resource hardware and edge devices grows, the field of parameter-efficient fine-tuning (PEFT) is rapidly evolving. LoRA (Low-Rank Adaptation) has emerged as a frontrunner in this space, and its future is increasingly tied to several complementary advancements that extend its scalability, flexibility, and real-world applicability.
Use with Quantized Models (QLoRA)
One of the most impactful developments is QLoRA, a combination of quantization and LoRA. Traditional LoRA reduces the number of trainable parameters, but still assumes that the base model remains in full precision (usually FP16 or BF16). QLoRA pushes the boundary by quantizing the base model to 4-bit precision (e.g., using NF4) while still applying LoRA adapters for task-specific fine-tuning.
This dramatically reduces GPU memory usage without sacrificing accuracy, allowing full fine-tuning of massive models like LLaMA 65B on a single consumer-grade GPU. QLoRA has opened the door to low-cost, high-performance fine-tuning, making LLM adaptation feasible even on laptops and edge devices.
Adapter Composition and Dynamic Routing
As models are increasingly used for multi-task and multi-user environments, there’s a growing need for modularity and dynamic adaptability. Future research and tooling around LoRA are focused on:
Adapter Composition: This allows combining multiple LoRA adapters either additively or via weighted averaging to support compositional generalization across tasks (e.g., combining a domain-specific adapter with a sentiment-specific adapter).
Dynamic Routing: In more advanced applications, LoRA adapters could be dynamically selected or composed during inference depending on the input. For example, a system could detect the task or domain of an incoming request and automatically apply the most relevant adapter.
These techniques will help LLMs become more context-aware and customizable, enabling truly general-purpose AI systems with minimal switching overhead.
Growing Ecosystem: PEFT Library, LoRA Hub, and Beyond
The adoption of LoRA and other PEFT methods is being accelerated by a fast-growing open-source ecosystem:
-
Hugging Face PEFT Library: This Python package provides an easy-to-use interface to apply LoRA, Prefix Tuning, Prompt Tuning, and more to Hugging Face-compatible models. It abstracts away boilerplate code and makes experimentation fast and reproducible.
-
LoRA Hub: This is a new initiative that allows users to share and download LoRA adapters for various models and tasks, without needing to download or modify the base model itself.
-
Integration with Model Serving Frameworks: Tools like Hugging Face Accelerate, Transformers, and Text Generation Inference (TGI) now support LoRA-based serving, making it easier to deploy adapters in production without changing the base pipeline.
Frequently Asked Questions (FAQs)
Q1: What is LoRA in simple words?
A: LoRA is a method that lets you fine-tune big AI models by training only a small part of them, making it cheaper and faster.
It works by inserting small trainable matrices into the model instead of changing all its weights.
Q2: Why is LoRA useful?
A: It saves time and resources. You don’t need to retrain the whole model—just tweak small parts.
This makes it ideal for running on lower-cost GPUs or edge devices.
Q3: Can I use LoRA with Hugging Face models? A: Yes! Hugging Face’s PEFT library supports LoRA and makes integration simple with a few lines of code. It also supports popular architectures like LLaMA, BERT, and T5.
Q4: What are some real-life uses of LoRA?
A: LoRA is used to fine-tune chatbots, enhance image-to-text models, and adapt LLMs to specific industries or tasks.
For example, healthcare companies use it to personalize models for radiology reports, and edtech tools use it for diagram explanation.
Q5: Is LoRA better than full fine-tuning? A: It depends. LoRA is great when you want to save compute and still get good results, but full fine-tuning may perform better for very complex tasks. In many practical scenarios, LoRA achieves near full-tuning performance at a fraction of the cost.
Conclusion
Approaches like Low-Rank Adaptation (LoRA) and QLoRA are revolutionizing the way we approach fine-tuning large language models. These innovations are making the process significantly more efficient, affordable, and scalable. Rather than retraining billions of parameters, LoRA injects lightweight, low-rank matrices into frozen pre-trained models, thus preserving performance while cutting down resource usage. As discussed in this article, these innovation not only reduces training time and memory requirements but also enable multiple task-specific adapters to coexist with a single base model, unlocking new possibilities for modular, multi-task learning.
The strength of LoRA lies in its practicality. It acts as a bridge between the high-performance world of large language models and the growing demand for accessible, edge-compatible AI solutions. Through strategic use cases—ranging from domain-specific adaptation and chatbot fine-tuning to instruction and multimodal tuning—LoRA empowers researchers and developers to experiment and deploy at scale without needing massive infrastructure.
As the parameter-efficient fine-tuning (PEFT) ecosystem continues to grow with innovations like QLoRA, adapter routing, and community-driven sharing hubs, LoRA stands at the center of a movement focused on democratizing AI. Supported by tooling such as Hugging Face’s peft library and LoRA-compatible model hubs, it is now easier than ever to integrate and iterate on fine-tuned adapters with minimal cost or complexity.
For developers and startups looking to train or fine-tune models with LoRA, DigitalOcean’s Gradient AI platform offers a seamless, cost-effective solution. Whether you’re fine-tuning LLaMA, BERT, or your custom model, Gradient AI provides scalable compute and a clean interface for experimentation. If you’re aiming to get started with LoRA without breaking the bank or wrestling with complex cloud configurations, DigitalOcean’s GPU Droplets and Gradient AI workspace offer an ideal platform to build, test, and deploy AI faster.
References and Further Reading
- LoRA paper: https://arxiv.org/abs/2106.09685
- Hugging Face PEFT: https://github.com/huggingface/peft
- QLoRA: https://arxiv.org/abs/2305.14314
- LangChain Explained: The Ultimate Framework for Building LLM Applications
- Fine-Tune Mistral-7B with LoRA A Quickstart Guide
- What is LoRA (low-rank adaption)?
- Understanding LoRA – Low Rank Adaptation For Finetuning Large Models
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
