By Justin Ellingwood and Alex Garnett

Introduction
Backups are very important for cloud servers. Whether you are running a single project with all of its data stored on a single server, or deploying directly from Git to VMs that are spun up and torn down while retaining a minimum set of logs, you should always plan for a failure scenario. This can mean many different things depending on what applications you are using, how important it is to have immediate failover, and what kind of problems you are anticipating.
In this guide, you’ll explore the different approaches for providing backups and data redundancy. Because different use cases demand different solutions, this article won’t be able to give you a one-size-fits-all answer, but you will learn what is important in different scenarios and what implementations are best suited for your operation.
In the first part of this guide, you’ll look at several backup solutions and review the relative merits of each so that you can choose the approach that fits your environment. In part two, you’ll explore redundancy options.
Part 1 — What Is the Difference Between Redundancy and Backing Up?
The definitions of the terms redundant and backup are often overlapping and, in many cases, confused. These are two distinct concepts that are related, but different. Some solutions provide both.
Redundancy
Redundancy in data means that there is immediate failover in the event of a system problem. A failover means that if one set of data (or one host) becomes unavailable, another perfect copy is immediately swapped into production to take its place. This results in almost no perceivable downtime, and the application or website can continue serving requests as if nothing happened. In the meantime, the system administrator (in this case, you) have the opportunity to fix the problem and return the system to a fully operational state.
However, a redundancy solution is usually not also a backup solution. Redundant storage does not necessarily provide protection against a failure that affects the entire machine or system. For instance, if you have a mirrored RAID configured (such as RAID 1), your data is redundant in that if one drive fails, the other will still be available. However, if the machine itself fails, all of your data could be lost.
With redundancy solutions such as MySQL Group Replication, every operation is typically performed on every copy of the data. This includes malicious or accidental operations. By definition, a backup solution should also allow you to restore from a previous point where the data is known to be good.
Backup
In general, you need to maintain functional backups for your important data. Depending on your situation, this could mean backing up application or user data, or an entire website or machine. The idea behind backups is that in the event of a system, machine, or data loss, you can restore, redeploy, or otherwise access your data. Restoring from a backup may require downtime, but it can mean the difference between starting from a day ago and starting from scratch. Anything that you cannot afford to lose should, by definition, be backed up.
In terms of methods, there are quite a few different levels of backups. These can be layered as necessary to account for different kinds of problems. For instance, you may back up a configuration file prior to modifying it so that you can revert to your old settings should a problem arise. This is ideal for small changes that you are actively monitoring. However, this setup would fail in the case of a disk failure or anything more complex. You should also have regular, automated backups to a remote location.
Backups by themselves do not provide automatic failover. This means that your failures may not cost you any data (assuming your backups are 100% up-to-date), but they may cost you uptime. This is one reason why redundancy and backups are often used in combination with each other.
Part 2 — File-Level Backup
One of the most familiar forms of backing up is a file-level backup. This type of backup uses normal filesystem level copying tools to transfer files to another location or device.
How To Use the cp Command
In theory, you could back up a Linux machine, like your cloud server, with the cp command. This copies files from one local location to another. On a local computer, you could mount a removable drive, and then copy files to it:
- mount /dev/sdc /mnt/my-backup
- cp -a /etc/* /mnt/my-backup
- umount /dev/sdc
This example mounts a removable disk, sdc, as /mnt/my-backup and then copies the /etc directory to the disk. It then unmounts the drive, which can be stored somewhere else.
How to Use Rsync
A better alternative to cp is the rsync command. Rsync is a powerful tool that provides a wide array of options for replicating files and directories across many different environments, with built-in checksum validation and other features. Rsync can perform the equivalent of the cp operation above like so:
- mount /dev/sdc /mnt/my-backup
- rsync -azvP /etc/* /mnt/my-backup
- umount /dev/sdc
-azvP is a typical set of Rsync options. As a breakdown of what each of those do:
aenables “Archive Mode” for this copy operation, which preserves file modification times, owners, and so on. It is also the equivalent of providing each of the-rlptgoDoptions individually (yes, really). Notably, the-roption tells Rsync to recurse into subdirectories to copy nested files and folders as well. This option is common to many other copy operations, such ascpandscp.zcompresses data during the transfer itself, if possible. This is useful for any transfers over slow connections, especially when transferring data that compresses very effectively, like logs and other text.venables verbose mode, so you can read more details of your transfer while it is in progress.Ptells Rsync to retain partial copies of any files that do not transfer completely, so that transfers can be resumed later.
You can review other rsync options on its man page.
Of course, in a cloud environment, you would not normally be mounting and copying files to a mounted disk each time. Rsync can also perform remote backups over a network by providing SSH-style syntax. This will work on any host that you can SSH into, as long as Rsync is installed at both ends. Because Rsync is considered a core Linux tool, this is almost always a safe assumption, even if you are working locally on a Mac or Windows machine.
- rsync -azvP /etc/* username@remote_host:/backup/
This will back up the local machine’s /etc directory to a directory on remote_host located at /backup. This will succeed if you have permission to write to this directory and there is available space.
You can also review more information about how to use Rsync to sync local and remote directories.
How to Use Other Backup Tools
Although cp and rsync are useful and ubiquitous, they are not a complete solution on their own. To automate backups using Rsync, you would need to create your own automated procedures, backup schedule, log rotation, and so on. While this may be appropriate for some very small deployments which do not want to make use of external services, or very large deployments which have dedicated resources for maintaining very granular scripts for various purposes, many users may want to invest in a dedicated backup offering.
Bacula
Bacula is a complex, flexible solution that works on a client - server model. Bacula is designed with separate concepts of clients, backup locations, and directors (the component that orchestrates the actual backup). It also configures each backup task into a unit called a “job”.
This allows for extremely granular and flexible configuration. You can back up multiple clients to one storage device, one client to multiple storage devices, and modify the backup scheme by adding nodes or adjusting their details. It functions well over a networked environment and is expandable and modular, making it great for backing up a site or application spread across multiple servers.
Duplicity
Duplicity is another open source backup tool. It uses GPG encryption by default for transfers.
The obvious benefit of using GPG encryption for file backups is that the data is not stored in plain text. Only the owner of the GPG key can decrypt the data. This provides some level of security to offset the additional security measures required when your data is stored in multiple locations.
Another benefit that may not be apparent to those who do not use GPG regularly is that each transaction has to be verified to be completely accurate. GPG, like Rsync, enforces hash checking to ensure that there was no data loss during the transfer. This means that when restoring data from a backup, you will be significantly less likely to encounter file corruption.
Part 3 — Block-Level Backups
A slightly less common, but important alternative to file-level backups are block-level backups. This style of backup is also known as “imaging” because it can be used to duplicate and restore entire devices. Block-level backups allow you to copy on a deeper level than a file. While a file-based backup might copy file1, file2, and file3 to a backup location, a block-based backup system would copy the entire “block” that those files reside on. Another way of explaining the same concept is to say that block-level backups copy information bit after bit. They do not know about the files that may span those bits.
One advantage of the block-level backups is that they are typically faster. While file-based backups usually initiate a new transfer for each separate file, a block-based backup will transfer blocks, meaning that fewer non-sequential transfers need to be initiated to complete the copying.
Using dd to Perform Block-Level Backups
The most common method of performing block-level backups is with the dd utility. dd can be used to create entire disk images, and is also frequently used when archiving removable media like CDs or DVDs. This means that you can back up a partition or disk to a single file or a raw device without any preliminary steps.
To use dd, you need to specify an input location and an output location, like so:
- dd if=/path/of/original/device of=/path/to/place/backup
In this scenario, the if= argument specifies the input device or location. The of= arguments specifies the output file or location. Be careful not to confuse these, or you could erase an entire disk by mistake.
For example, to back up a partition containing your documents, which is located at /dev/sda3, you can create an image of that directory by providing an output path to an .img file:
- dd if=/dev/sda3 of=~/documents.img
Part 4 — Versioning Backups
One of the primary motivations for backing up data is being able to restore a previous version of a file in the event of an unwanted change or deletion. While all of the backup mechanisms mentioned so far can deliver this, you can also implement a more granular solution.
For example, a manual way of accomplishing this would be to create a backup of a file prior to editing it in nano:
- cp file1 file1.bak
- nano file1
You could even automate this process by creating timestamped hidden files every time you modify a file with your editor. For instance, you could place this in your ~/.bashrc file, so that every time you execute nano from your bash (i.e. $) shell, it automatically creates a backup stamped with year (%y), month (%m), day (%d), and so on:
- nano() { cp $1 .${1}.`date +%y-%m-%d_%H.%M.%S`.bak; /usr/bin/nano $1; }
This would work to the extent that you edit files manually with nano, but is limited in scope, and could quickly fill up a disk. You can see how it could end up being worse than manually copying files you are going to edit.
An alternative that solves many of the problems inherent in this design is to use Git as a version control system. Although it was developed primarily to focus on versioning plain text, usually source code, line-by-line, you can use Git to track almost any kind of file. To learn more, you can review How to Use Git Effectively.
Part 5 — Server-Level Backups
Most hosting providers will also provide their own optional backup functionality. DigtalOcean’s backup function regularly performs automated backups for droplets that have enabled this service. You can turn this on during droplet creation by checking the “Backups” check box:

This will back up your entire cloud server image on a regular basis. This means that you can redeploy from the backup, or use it as a base for new droplets.
For one-off imaging of your system, you can also create snapshots. These work in a similar way to backups, but are not automated. Although it’s possible to take a snapshot of a running system in some contexts, it is not always recommended, depending on how you are writing to your filesystem:
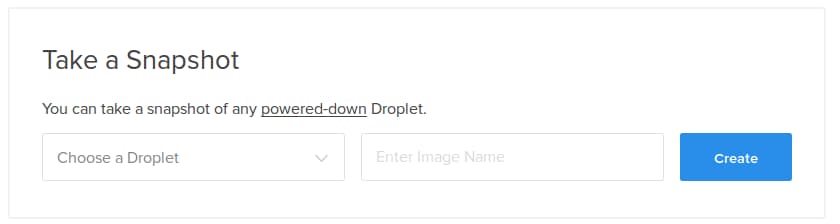
You can learn more about DigitalOcean backups and snapshots from the Containers and Images documentation.
GitOps
Finally, it is worth noting that there are some circumstances in which you will not necessarily be looking to implement backups on a per-server basis. For example, if your deployment follows the principles of GitOps, you may treat many of your individual cloud servers as disposable, and instead treat remote data sources like Git repositories as the effective source of truth for your data. Complex, modern deployments like this can be more scalable and less prone to failure in many cases. However, you will still want to implement a backup strategy for your data stores themselves, or for a centralized log server that each of these disposable servers may be sending information to. Consider which aspects of your deployment may not need to be backed up, and which do.
Conclusion
In this article, you explored various backup concepts and solutions. Next, you may want to review solutions to enable redundancy.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Former Senior Technical Writer at DigitalOcean, specializing in DevOps topics across multiple Linux distributions, including Ubuntu 18.04, 20.04, 22.04, as well as Debian 10 and 11.
Former Senior DevOps Technical Writer at DigitalOcean. Expertise in topics including Ubuntu 22.04, Linux, Rocky Linux, Debian 11, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Hi, Did you ever create the followup to this for “options to enable redundancy”? Thank you
@rebisall: Our automatic backups are configured to run a random schedule every 24-72 hours.
There is no point of having auto backup enabled on DigitalOcean. They say it is done every 36-72 hours. But for my droplet it is more than 7 days, backup has not been done.
This is response from support after follow up in 5 days
Hello,
The backup schedule is not fixed, as it runs backups in series, spreading them out to avoid load issues if they all ran at once. How often your backups are ran is dependent upon the load of the overall system, and does vary over time.
If you are concerned with having more regular backups, then I would recommend a file-based backup strategy, which you have complete control over https://www.digitalocean.com/community/articles/how-to-choose-an-effective-backup-strategy-for-your-vps
DigitalOcean Support
You also may want to explore backups from CodeGuard. They provide backup services for Rackspace, HostGator, and many other hosting providers. 99.9% reliability - incremental backups performed daily. www.codeguard.com
I can confirm Neeraj’s comment. My latest backups were 7 days ago then 9 days ago. I would have expected even distributions. It doesn’t appear to be worth paying extra for, if you have to create your own backup solution anyways.
Another good tool worth mentioning here is rdiff-backup. It’s sort of like rsync with versioning. It’s positioned above rsync and below a full backup tool…
One of my favorite backup tools is Rsnapshot. It can create incremental backups using rsync, cp, and hardlinks (I’m sure there are a few other tools).
Hi,
We’re building a new service, daily incremental backups for Digital Ocean droplets. Right now, it’s still in beta, backups work just fine but not everything is quite polished yet.
You can check it out on https://dobackup.io
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
