By Sam P. and Sharon Campbell

Introduction
RethinkDB is a NoSQL database. It has an easy to use API for interacting with the database. RethinkDB also makes it simple to set up database clusters; that is, groups of servers serving the same databases and tables. Clusters are a way to easily scale your databases without any downtime.
This tutorial will look at how to set up a cluster, import data, and secure it. If you are new to RethinkDB, look at the basics in this tutorial before diving into the more complex cluster configuration process.
Prerequisites
This tutorial requires at least 2 Droplets running Ubuntu 14.04 LTS, named rethink1 & rethink2(These names will be used throughout this tutorial). You should set up a non root sudo user on each Droplet before setting up RethinkDB – doing so is a good security practice.
This tutorial also references the Python client driver, which is explained in this tutorial.
Setting Up a Node
Clusters in RethinkDB have no special nodes; it is a pure peer-to peer-network. Before we can configure the cluster, we need to install RethinkDB. On each server, from your home directory, add the RethinkDB key and repository to apt-get:
source /etc/lsb-release && echo "deb http://download.rethinkdb.com/apt $DISTRIB_CODENAME main" | sudo tee /etc/apt/sources.list.d/rethinkdb.list
wget -qO- http://download.rethinkdb.com/apt/pubkey.gpg | sudo apt-key add -
Then update apt-get and install RethinkDB:
sudo apt-get update
sudo apt-get install rethinkdb
Next, we need to set RethinkDB to run on startup. RethinkDB ships with a script to run on startup, but that script needs to be enabled:
sudo cp /etc/rethinkdb/default.conf.sample /etc/rethinkdb/instances.d/cluster_instance.conf
The startup script also serves as a configuration file. Let’s open this file:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
The machine’s name (the one in the web management console and log files) is set in this file. Let’s make this the same as the machine’s hostname by finding the line (at the very bottom):
# machine-name=server1
And changing it to:
machine-name=rethink1
(Note: If you don’t set the name before starting RethinkDB for the first time, it will automatically set a DOTA-themed name.)
Set RethinkDB so it is accessible from all network interfaces by finding the line:
# bind=127.0.0.1
And changing it to:
bind=all
Save the configuration and close nano (by pressing Ctrl-X, then Y, then Enter). We can now start RethinkDB with the new configuration file:
sudo service rethinkdb start
You should see this output:
rethinkdb: cluster_instance: Starting instance. (logging to `/var/lib/rethinkdb/cluster_instance/data/log_file')
RethinkDB is now up and running.
Securing RethinkDB
We have turned on the bind=all option, making RethinkDB accessible from outside the server. This is insecure. So, we will need to block RethinkDB off from the Internet. But we need to allow access to its services from authorized computers.
For the cluster port, we will use a firewall to enclose our cluster. For the web management console and the driver port, we will use SSH tunnels to access them from outside the server. SSH tunnels redirect requests on a client computer to a remote computer over SSH, giving the client access to all of the services only available on the remote server’s localhost name space.
Repeat these steps on all your RethinkDB servers.
First, block all outside connections:
# The Web Management Console
sudo iptables -A INPUT -i eth0 -p tcp --dport 8080 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 8080 -j ACCEPT
# The Driver Port
sudo iptables -A INPUT -i eth0 -p tcp --dport 28015 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 28015 -j ACCEPT
# The Cluster Port
sudo iptables -A INPUT -i eth0 -p tcp --dport 29015 -j DROP
sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 29015 -j ACCEPT
For more information on configuring IPTables, check out this tutorial.
Let’s install “iptables-persistent” to save our rules:
sudo apt-get update
sudo apt-get install iptables-persistent
You will see a menu like this:
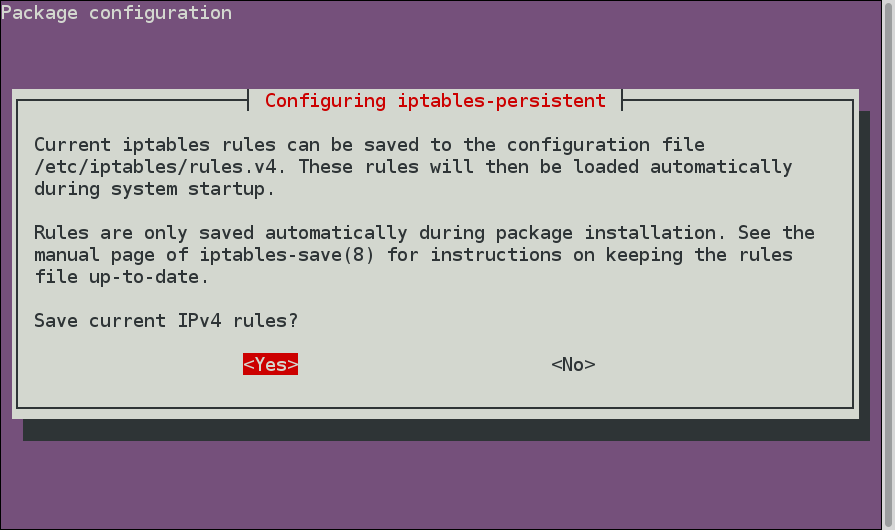
Select the Yes option (press Enter) to save the firewall rules. You will also see a similar menu about IPv6 rules, which you can save too.
Setting up a management user
To access RethinkDB’s web management console and the driver interface we need to set up the SSH tunnel. Let’s create a new user for the ssh tunnel on rethink1:
sudo adduser ssh-to-me
Then set up the authorized keys file for our new user:
sudo mkdir /home/ssh-to-me/.ssh
sudo touch /home/ssh-to-me/.ssh/authorized_keys
If you are using SSH to connect to the cloud server, open a terminal on your local computer. If you are not, you may want to learn more about SSH keys. Get your public key and copy it to your clipboard:
cat ~/.ssh/id_rsa.pub
Then add that key to the new account by opening the authorized_keys file on the server:
sudo nano /home/ssh-to-me/.ssh/authorized_keys
Paste your key into the file. Then save and close nano (Ctrl-X, then Y, then Enter).
You need to repeat all of these steps for your other cluster nodes.
Importing or Creating a Database
You may want to import a pre-existing database into your cluster. This is only needed if you have a pre-existing database on another server or on this server; otherwise, RethinkDB will automatically create an empty database.
If you need to import an external database:
If the database you wish to import is not stored on rethink1, you need to copy it across. First, find the path of your current RethinkDB database. This would be the auto-created rethinkdb_data directory if you used the rethinkdb command to start your old database. Then, copy it using scp on rethink1:
sudo scp -rpC From Server User@From Server IP:/RethinkDB Data Folder/* /var/lib/rethinkdb/cluster_instance/data
For example:
sudo scp -rpC root@111.222.111.222:/home/user/rethinkdb_data/* /var/lib/rethinkdb/cluster_instance/data
Then restart RethinkDB:
sudo service rethinkdb restart
If you have an existing database on rethink1:
If you have an existing RethinkDB database on rethink1, the procedure is different. First open the configuration file on rethink1:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
Then, find the path of the RethinkDB database you want to import. This would be the auto-created rethinkdb_data directory if you used the rethinkdb command to start your old database. Insert that path into the configuration file by adding the line:
directory=/home/user/rethink/rethinkdb_data/
Close the file to save your changes (using Ctrl-X, then Y, then Enter). Now restart RethinkDB:
sudo service rethinkdb restart
It is important to note that importing a pre-existing database will mean that rethink1 will inherit the name of the database’s old machine. You will need to know this when managing the sharding of the database later on.
Creating a Cluster
In order to create a cluster, you need to allow all of the cluster machines through each other’s firewalls. On your rethink1 machine, add an IPTables rule to allow the other nodes through the firewall. In this example, you should replace rethink2 IP with the IP address of that server:
sudo iptables -I INPUT -i eth0 -s rethink2 IP -p tcp --dport 29015 -j ACCEPT
Repeat the command for any other nodes you want to add.
Then save the firewall rules:
sudo sh -c "iptables-save > /etc/iptables/rules.v4"
Then repeat these steps for your other nodes. For a two-server setup, you should now connect to rethink2 and unblock the IP of rethink1.
Now you need to connect all of the nodes to create a cluster. Use SSH to connect to rethink2 and open the configuration file:
sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
The join option specifies the address of the cluster to join. Find the join line in the configuration file:
# join=example.com:29015
And replace it with:
join=rethink1 IP
Save and close the configuration file (using Ctrl-X, then Y, then Enter). Then restart RethinkDB:
sudo service rethinkdb restart
The first node, rethink1, does NOT need the join update. Repeat the configuration file editing on all of the other nodes, except for rethink1.
You now have a fully functioning RethinkDB cluster!
Connecting to the Web Management Console
The web management console is an easy to use, online interface that gives access to the basic management functions of RethinkDB. This console is useful when you need to view the status of the cluster, run single RethinkDB commands, and change basic table settings.
Every RethinkDB instance in the cluster is serving a management console, but this is only available from the server’s localhost name space, since we used the firewall rules to block it off from the rest of the world. We can use an SSH tunnel to redirect our requests for localhost:8080 to rethink1, which will send the request to localhost:8080 inside its name space. This will allow you to access the web management console. You can do this using SSH on your local computer:
ssh -L 8080:localhost:8080 ssh-to-me@rethink1 IP
If you go to localhost:8080 in your browser you will now see your RethinkDB web management console.
If you receive a bind: Address already in use error, you are already using port 8080 on your computer. You can forward the web management console to a different port, one which is available on your computer. For example, you can forward it to port 8081 and go to localhost:8081:
ssh -L 8081:localhost:8080 ssh-to-me@rethink1 IP
If you see a conflict about having two test databases, you can rename one of them.
Connecting to the Cluster with the Python Driver
In this setup, all of the RethinkDB servers (the web management console, driver port, and cluster port) are blocked off from the outside world. We can use an SSH tunnel to connect to the driver port, just like with the web management console. The driver port is how the RethinkDB API drivers (the ones you build applications with) connect to your cluster.
First, pick a node to connect with. If you have multiple clients (e.g., web app servers) connecting to the cluster, you will want to balance them out across the cluster. It would be a good idea to write a list of your clients, then allocate a server for each client. Try to group the clients so clients that need similar tables connect to the same cloud server or group of servers and so no server becomes overloaded with lots of clients.
In this example, we’ll use rethink2 as our connecting server. However, in a larger system where your database and web app servers are separate, you’d want to do this from a web app server that’s actually making database calls.
Then, on the connecting server, generate an SSH key:
ssh-keygen -t rsa
And copy that to your clipboard:
cat ~/.ssh/id_rsa.pub
Then authorize the new key on the cluster node (in this example, rethink1) by opening the authorized_keys file and pasting the key on a new line:
sudo nano /home/ssh-to-me/.ssh/authorized_keys
Close nano and save the file (Ctrl-X, then Y, then Enter).
Next, use SSH tunneling to access the driver port, from the connecting sever:
ssh -L 28015:localhost:28015 ssh-to-me@Cluster Node IP -f -N
The driver is now accessible from localhost:28015. If you get a bind: Address already in use error, you can change the port. For example, use port 28016:
ssh -L 28016:localhost:28015 ssh-to-me@Cluster Node IP -f -N
Install the Python driver on the connecting server. There’s a quick run-through of the commands here, and you can read about them in more detail in this tutorial.
Install the Python virtual environment:
sudo apt-get install python-virtualenv
Make the ~/rethink directory:
cd ~
mkdir rethink
Move into the directory and create the new virtual environment structure:
cd rethink
virtualenv venv
Activate the environment (you must activate the environment every time before starting the Python interface, or you’ll get an error about missing modules):
source venv/bin/activate
Install the RethinkDB module:
pip install rethinkdb
Now start Python from the connecting server:
python
Connect to the database, making sure to replace 28015 with the port you used, if necessary:
import rethinkdb as r
r.connect("localhost", 28015).repl()
Create the table test:
r.db("test").table_create("test").run()
Insert data into the table test:
r.db("test").table("test").insert({"hello":"world"}).run()
r.db("test").table("test").insert({"hello":"world number 2"}).run()
And print out the data:
list(r.db("test").table("test").run())
You should see output similar to the following:
[{u'hello': u'world number 2', u'id': u'0203ba8b-390d-4483-901d-83988e6befa1'},
{u'hello': u'world', u'id': u'7d17cd96-0b03-4033-bf1a-75a59d405e63'}]
Setting Up Sharding
In RethinkDB, you can configure a table to be sharded (split) across multiple cloud servers. Sharding is an easy way to have data sets larger than what fits in the RAM of a single machine perform well, since more RAM is available for caching. Since sharding also splits the dataset across multiple machines, you can have larger, low-performance tables, since more disk space is available to the table. This can be done through the Web Management Console.
To do this, go to the Tables tab in the Web Management Console.
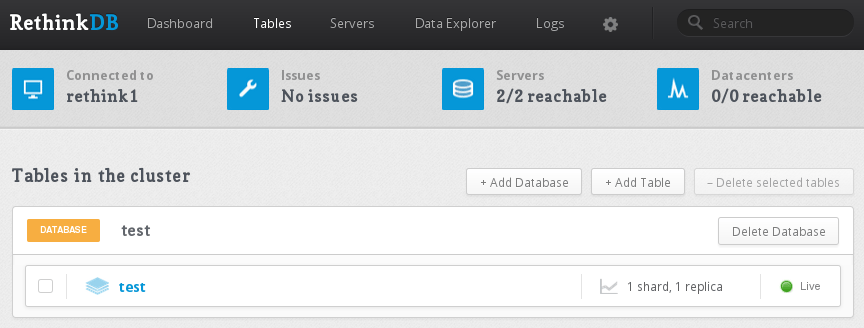
Click on the test table (the one we created in the previous section) to enter its settings. Scroll down to the Sharding settings card.
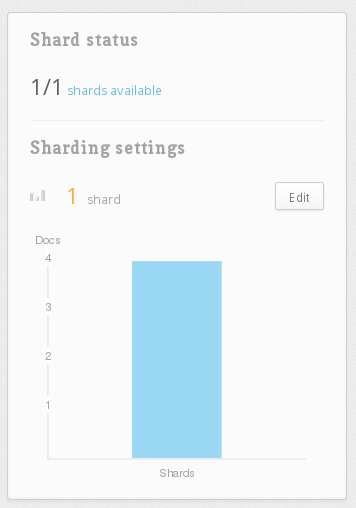
Click the Edit button. There, you can enter the number of servers to split the table over. Enter 2 for this example. Click the Rebalance button to save the setting.
You may notice that there is a maximum to the amount of shards you can have. This is equal to the number of documents in your database. If you are trying to set up sharding for a new table, you will either need to wait for more data or add dummy data to allow yourself to add more shards.
Advanced Sharding
Internally, RethinkDB has range-based shards, based on the document IDs. This means that if we have a dataset with the IDs A, B, C, and D, RethinkDB might split it into 2 shards: A, B (-infinity to C) and C, D (C to +infinity). If you were to insert a document with the ID A1, that would be within the first shard’s range (-infinity to C), so it would go in that shard. We can set the boundaries of the shards, which can optimize your database configuration.
Before we can do that, we will want to add a dataset to play with. In the Data Explorer tab of the web management console we can create a table by running this command (click Run after typing):
r.db('test').tableCreate('testShards')
Then insert our test data:
r.db("test").table("testShards").insert([
{id:"A"},
{id:"B"},
{id:"C"},
{id:"D"},
{id:"E"}])
Now we can configure the shards in detail. To do so, we need to enter the admin shell. The admin shell is a more advanced way of controlling your cluster, allowing you to fine-tune your set up. On the rethink1 machine, open the admin shell:
rethinkdb admin
Then we can view some information about our table:
ls test.testShards
Expected output:
table 'testShards' b91fda27-a9f1-4aeb-bf6c-a7a4211fb674
...
1 replica for 1 shard
shard machine uuid name primary
-inf-+inf 91d89c12-01c7-487f-b5c7-b2460d2da22e rethink1 yes
In RethinkDB there are many ways to name a table. You can use database.name (test.testShards), the name (testShards) or the table uuid (e780f2d2-1baf-4667-b725-b228c7869aab). These can all be used interchangeably.
Let’s split this shard. We will make 2 shards: -infinity to C and C to +infinity:
split shard test.testShards C
The generic form of the command is:
split shard TABLE SPLIT-POINT
Running ls testShards again shows the shard has been split. You may want to move the new shard from one machine to another. For this example, we can pin (move) the shard -inf-C (-infinty to C) to the machine rethink2:
pin shard test.testShards -inf-C --master rethink2
The generic form of the command is:
pin shard TABLE SHARD-RANGE --master MACHINE-NAME
If you ls testShards again, you should see that the shard has moved to a different server.
We can also merge 2 shards if we know the common boundary. Let’s merge the shards we just made (-infinity to C and C to +infinity):
merge shard test.testShards C
The generic form of the command is:
merge shard TABLE COMMON-BOUNDARY
To exit the shell, type exit
Safely Removing a Machine
When a document is split over multiple machines, one machine will always hold its primary index. If the cloud server with the primary index for a particular document is taken offline, the document will be lost. So, before you remove a machine, you should migrate all the primary shards on it away from it.
In this example, we will try to migrate the data off the node rethink2 to leave rethink1 as the sole node.
Enter the RethinkDB admin shell on rethink1:
rethinkdb admin
First, let’s list the shards (groups of documents) that rethink2 is responsible for:
ls rethink2
Your output should look something like this:
machine 'rethink2' bc2113fc-efbb-4afc-a2ed-cbccb0c55897
in datacenter 00000000-0000-0000-0000-000000000000
hosting 1 replicas from 1 tables
table name shard primary
b91fda27-a9f1-4aeb-bf6c-a7a4211fb674 testShards -inf-+inf yes
This shows that rethink2 is responsible for the primary shard of a table with the id “bdfceefb-5ebe-4ca6-b946-869178c51f93”. Next, we will move this shard to rethink1. This is referred to as pinning:
pin shard test.testShards -inf-+inf --master rethink1
The generic form of the command is:
pin shard TABLE SHARD-RANGE --master MACHINE-NAME
If you now run ls rethink1 you will see that the shard has been moved to that machine. Once every shard has been moved from rethink2 to rethink1, you should exit the admin shell:
exit
It is now safe to stop RethinkDB on the unwanted server. Important: run this on the machine you want to remove. In this example, we will run this on rethink2:
sudo service rethinkdb stop
The next time you visit the web management console, RethinkDB will display a bright red warning. Click Resolve issues.
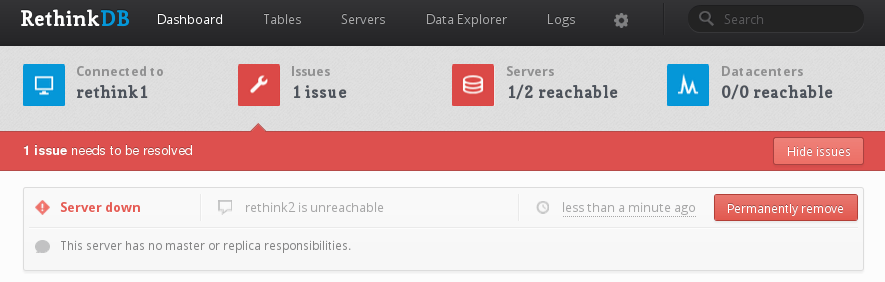
If the issue shown looks like the one above, and no master responsibilities are listed, click Permanently remove. This will remove the machine from the cluster. If it lists any master responsibilities, turn RethinkDB back on (sudo service rethinkdb start) and make sure you migrate every primary shard off that server.
Note: If you try to re-add the machine to the cluster, you will see messages about a zombie machine. You can remove the data directory to rectify this issue:
sudo rm -r /var/lib/rethinkdb/cluster_instance/
sudo service rethinkdb restart
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Current fan and former Editorial Manager at DigitalOcean. Hi! Expertise in areas including Ubuntu, Docker, Rails, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
If you lose the primary of a shard, you lose the data of the shard only if you have no replica for the shard. As long as you have a replica, you can declare the permanently remove the master from the cluster, and a replica will be elected master.
Can you explain cluster little bit more?
let say you have 10 servers? What do you put on join for rest of 9 servers? just join rethink1 or you do for example on
rehtink2:
join rethink1 join rethink3 join rethink4 join rethink5 join rethink6 join rethink7 join rethink8 join rethink9 join rethink10
or on rehtink3:
join rethink1 join rethink2 join rethink4 join rethink5 join rethink6 join rethink7 join rethink8 join rethink9 join rethink10
It would be great if you can answer this.
what if rethink1 goes down?
I see you covered a lot but you have not explain at all what happens if rehtink1 goes down in 2 node cluster setup?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
