
Introduction
A Twitterbot is a program that integrates with the Twitter platform, automatically posting, retweeting, liking, or following other users. Twitterbots can prove to be useful through providing interesting information or updates, and they can also be fun or humorous.
It is important to exercise care when creating Twitterbots, as not only are harassment and spamming not OK, but they will cause your Twitterbot’s account to be suspended for violating Twitter’s Terms of Service. Prior to creating a Twitterbot, you should become familiar with Twitter’s Automation rules and best practices to ensure that your Twitterbot is a good member of the Twitter community.
This tutorial will walk you through two Twitterbot programs, one that tweets from a file, and one that retweets, follows, and favorites. Additionally, we’ll go through storing your credentials in a separate program file, and keeping the Twitterbot running on a server. Each of these steps are optional, but they’re presented in the order you would carry them out.
Prerequisites
Although you can use a local computer to set up and run a Twitterbot, if you would like it to be continuously running, a Python programming environment on a server would be ideal for this project.
Additionally, you should have a Twitter account that is associated with a valid phone number, which you can add via the Mobile section of your Settings when you’re logged in. You’ll need to create a Twitter app and install the Python Tweepy library, which you can do by following our “How To Create a Twitter App” tutorial. You should have your Consumer Key, Consumer Secret, Access Token, and Access Token Secret in hand before beginning this tutorial.
As part of this project, we’ll be using Python to read files. To familiarize yourself with working with text files in Python, you can read our “How To Handle Plain Text Files in Python 3 guide.
Storing Credentials
You can keep your Twitter Consumer Key, Consumer Secret, Access Token, and Access Token Secret at the top of your program file, but for best practices, we should store these in a separate Python file that our main program file(s) can access. Anyone who has access to these strings can use your Twitter account, so you don’t want to share these or make them public. In addition to security, keeping a separate file can allow us to easily access our credentials in each program file we create.
To start, we should ensure we’re in our virtual environment with the Tweepy library installed. With the environment activated, we can then create a directory for our project to keep it organized:
- mkdir twitterbot
- cd twitterbot
Next, let’s open up a text editor such as nano and create the file credentials.py to store these credentials:
- nano credentials.py
We’ll create variables for each key, secret, and token that we generated (if you need to generate those, follow these steps. Replace the items in single quotes with your unique strings from the Twitter apps website (and keep the single quotes).
consumer_key = 'your_consumer_key'
consumer_secret = 'your_consumer_secret'
access_token = 'your_access_token'
access_token_secret = 'your_access_token_secret'
We’ll be calling these variables in our other program files. Creating this separate credentials.py file also allows us to add it to our .gitignore file in case we plan to release our code through Git.
Twitterbot that Tweets from a File
We can use Python’s ability to handle and read from files to update our Twitter status. For this example, we’ll use a file that already exists, but you may want to create your own file, or modify an existing file.
Setting up the Program File
Let’s begin by creating our program file, using a text editor such as nano:
- nano twitterbot_textfile.py
Next, let’s set up our Twitter credentials by either adding them to the top of our file, or importing what we have stored in the credentials.py file we set up in the section above. We’ll also add 3 lines to interact with the credential variables via the Tweepy library.
# Import our Twitter credentials from credentials.py
from credentials import *
# Access and authorize our Twitter credentials from credentials.py
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
To learn more about this set up, be sure to have a look at “How To Create a Twitter App.” To find out more about OAuth, you can read our introduction.
Getting a Text File to Read From
For this Twitterbot, we’ll need a text file to read from, so let’s download one from Project Gutenberg, a volunteer project that provides free eBooks (mostly in the public domain) to readers. Let’s save an English translation of Twenty Thousand Leagues under the Sea by Jules Verne as a file called verne.txt with curl:
- curl http://www.gutenberg.org/cache/epub/164/pg164.txt --output verne.txt
We’ll be using Python’s file handling capabilities, first to open the file, then to read lines from the file, and finally to close the file.
Opening and Reading the File with Python
With our file downloaded, we can create variables and add the relevant functions underneath the lines we’ve just set up to handle credentials.
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# Open text file verne.txt (or your chosen file) for reading
my_file = open('verne.txt', 'r')
# Read lines one by one from my_file and assign to file_lines variable
file_lines = my_file.readlines()
# Close file
my_file.close()
With this set up, we can now work on adding code to make these lines output as status updates to our Twitter account.
Tweeting Lines from the Text File
With our file’s lines stored in a variable, we’re ready to update our Twitterbot account.
We’ll be using the Tweepy library to interact with the Twitter API, so we should import the library into our program.
We’re also going to be automating our Tweeting in a time-based way, so we should import the module time. For our purposes, we’ll only be using the sleep() function, so we’ll only import that specific method.
# Add all import statements at top of file
import tweepy
from time import sleep
from credentials import *
...
Our Twitter account’s status updates will be coming from the lines from verne.txt that we have assigned to the file_lines variable. These lines need to be iterated over, so we’ll start by creating a for loop. To make sure everything is working, let’s use the print() function to print those lines out:
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
my_file=open('verne.txt','r')
file_lines=my_file.readlines()
my_file.close()
# Create a for loop to iterate over file_lines
for line in file_lines:
print(line)
If you run the program at this point with the command python twitter_textfile.py, you’ll see the entire verne.txt file output onto your terminal window since we have no other code or call for it to stop.
Rather than receive output in our terminal window, we want every line to become a new tweet. To achieve this, we’ll need to use the tweepy function api.update_status(). This is used to update the authenticated user’s status, but will only update if the status is either: 1) not a duplicate, or 2) 140 characters or less.
Let’s add that function and pass the line variable into it:
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
my_file=open('verne.txt','r')
file_lines=my_file.readlines()
my_file.close()
for line in file_lines:
print(line)
api.update_status(line)
Now our program is setup to tweet lines to our account.
Exception Handling and Timing Tweets
With a working program at this point, if we run the code, the first line will print. However, we won’t get far before we receive an error:
Output...
tweepy.error.TweepError: [{'code': 170, 'message': 'Missing required parameter: status.'}]
This is because the second line in the file is a blank line which cannot be used as a status. To handle this issue, let’s only print the line if it is not a blank line. We’ll add an if statement that looks like this:
if line != '\n':
In Python, \n is the escape character for blank lines, so our ifstatement is telling the program, if the line is not equal (!=) to a blank line, then we should go ahead and print it. Otherwise, Python should ignore the line. We’ll look at the statement in context just below.
One more thing we should add is sleep() to ensure that these tweets don’t all go out at once. The function sleep() works with the time unit measure of seconds, so if we want an hour between tweets, we should write the function as sleep(3600) because there are 3,600 seconds in an hour.
For our testing purposes (and only for our testing purposes), let’s use 5 seconds instead. Once we are running our Twitterbot regularly, we’ll want to greatly increase the time between tweets.
You can play around with where you add sleep(5) — where we have placed it below will cause a little more of a delay between tweets since there will be a delay even if the line is blank.
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
my_file=open('verne.txt','r')
file_lines=my_file.readlines()
my_file.close()
for line in file_lines:
print(line)
# Add if statement to ensure that blank lines are skipped
if line != '\n':
api.update_status(line)
# Add an else statement with pass to conclude the conditional statement
else:
pass
# Add sleep method to space tweets by 5 seconds each
sleep(5)
When you run the program at this point — if you have not run the program before — you’ll start getting output on your terminal of the first lines of the file. These lines will also post to your authenticated Twitter account.
However, if you already ran the program, you may receive the following error:
Outputtweepy.error.TweepError: [{'code': 187, 'message': 'Status is a duplicate.'}]
You can fix this by deleting either your previous tweet from your Twitter account, or by deleting the first line of your file verne.txt and saving it.
To stop the program from outputting status updates to your Twitter account, hold down the CTRL (or control) and C keys together on your keyboard to interrupt the process in your terminal window.
At this point, your program can run, but let’s handle that error that we get when the status is a duplicate. To do that, we’ll add a try ... except block to our code, and have the console print out the reason for the error.
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
my_file=open('verne.txt','r')
file_lines=my_file.readlines()
my_file.close()
for line in file_lines:
# Add try ... except block to catch and output errors
try:
print(line)
if line != '\n':
api.update_status(line)
else:
pass
except tweepy.TweepError as e:
print(e.reason)
sleep(5)
Running the program now will handle exceptions so that you can keep the program running. You can modify the time between tweets to, say, 15 minutes, by modifying the sleep(5) function to sleep(900).
Improving the Twitterbot Program
To continue to improve your program, you may consider defining some of these code blocks as functions, and adding additional sleep() functions to handle different situations, as in:
...
# Tweet a line every 15 minutes
def tweet():
for line in file_lines:
try:
print(line)
if line != '\n':
api.update_status(line)
sleep(900)
else:
pass
except tweepy.TweepError as e:
print(e.reason)
sleep(2)
tweet()
As you continue to work with files in Python, you can create separate scripts to chunk the lines of your files in ways that make more sense to you, being mindful of the 140-character tweet limit.
At this point we have a fully functional Twitterbot that tweets from a source file. In the next section we’ll go over an alternative Twitterbot that retweets, follows, and favorites. You can also skip ahead to the section on Keeping the Twitterbot Running.
Twitterbot that Retweets, Follows, and Favorites
By using the Tweepy library, we can set up a Twitterbot that can retweet and favorite the tweets of others, as well as follow other users. In our example, we’ll base these behaviors on querying a search term in the form of a hashtag.
Setting up the Program File
To begin, let’s create a Python file called twitterbot_retweet.py. We should either add our credentials to the top of the file, or add our import statements and access to each of our keys, secrets, and tokens via the credentials.py file we created in the Storing Credentials section above. We’ll also add 3 lines to interact with the credential variables via the Tweepy library.
# Import Tweepy, sleep, credentials.py
import tweepy
from time import sleep
from credentials import *
# Access and authorize our Twitter credentials from credentials.py
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
To learn more about this set up, be sure to have a look at “How To Create a Twitter App.” To find out more about OAuth, you can read our introduction.
Finding Tweets based on a Query
Next, we’ll create a for loop that can iterate over tweets. We’ll be looking at tweets that have the hashtag #ocean, so we’ll use q='#ocean' to run that query as part of our parameters. To start with, let’s have our terminal print out the usernames associated with tweets that use the #ocean hashtag, and then also limit the number of items (or tweets) returned to 10 so that our output does not go on for a long time:
# For loop to iterate over tweets with #ocean, limit to 10
for tweet in tweepy.Cursor(api.search,q='#ocean').items(10):
# Print out usernames of the last 10 people to use #ocean
print('Tweet by: @' + tweet.user.screen_name)
There are a lot of additional parameters we can add to our for loop, including:
- a date range using
sinceanduntil(though note that due to the restrictions of the API, tweets must be from no earlier than the previous week) - a
geocodethat will take in latitude, longitude, and a given radius around that location in kilometers - a specific language using
langand setting it to the 2-letter ISO 639-1 code for the language you wish to designate
While this specific scenario does not actually yield any results, let’s keep our query of #ocean, then designate a time frame of two days to retrieve tweets, limit our location to 100km around Singapore, and ask for French-language tweets. To play around, you should swap out each of the strings to get results that are meaningful to you.
for tweet in tweepy.Cursor(api.search,
q='#ocean',
since='2016-11-25',
until='2016-11-27',
geocode='1.3552217,103.8231561,100km',
lang='fr').items(10):
print('Tweet by: @' + tweet.user.screen_name)
To learn more about the different parameters you can pass through this and other Tweepy functions, consult the Tweepy API Reference.
For our example program here, we’ll just be searching for the #ocean query. You can leave the .items() method open, but you may receive the following error for having made too many requests and exhausting the resource:
Outputtweepy.error.TweepError: Twitter error response: status code = 429
All error codes and responses are available via the Tweepy API.
Exception Handling
To improve our code, rather than just printing the associated Twitter username, let’s use some error handling with a try ... except block. We’ll also add a StopIteration exception that will break the for loop.
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
for tweet in tweepy.Cursor(api.search, q='#ocean').items():
try:
print('Tweet by: @' + tweet.user.screen_name)
except tweepy.TweepError as e:
print(e.reason)
except StopIteration:
break
Now we can start telling our Twitterbot to do some actions based on the data being collected.
Retweeting, Favoriting, and Following
We’ll first have the Twitterbot retweet tweets with the .retweet() function. We’ll also provide feedback to the Terminal of what we have done, and add a \n line break to organize this output a little better:
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
for tweet in tweepy.Cursor(api.search, q='#ocean').items():
try:
# Add \n escape character to print() to organize tweets
print('\nTweet by: @' + tweet.user.screen_name)
# Retweet tweets as they are found
tweet.retweet()
print('Retweeted the tweet')
sleep(5)
except tweepy.TweepError as e:
print(e.reason)
except StopIteration:
break
While the program is running, you should open a browser to check that these retweets are posting to your Twitterbot account. Your account should begin to be populated by retweets, and look something like this:
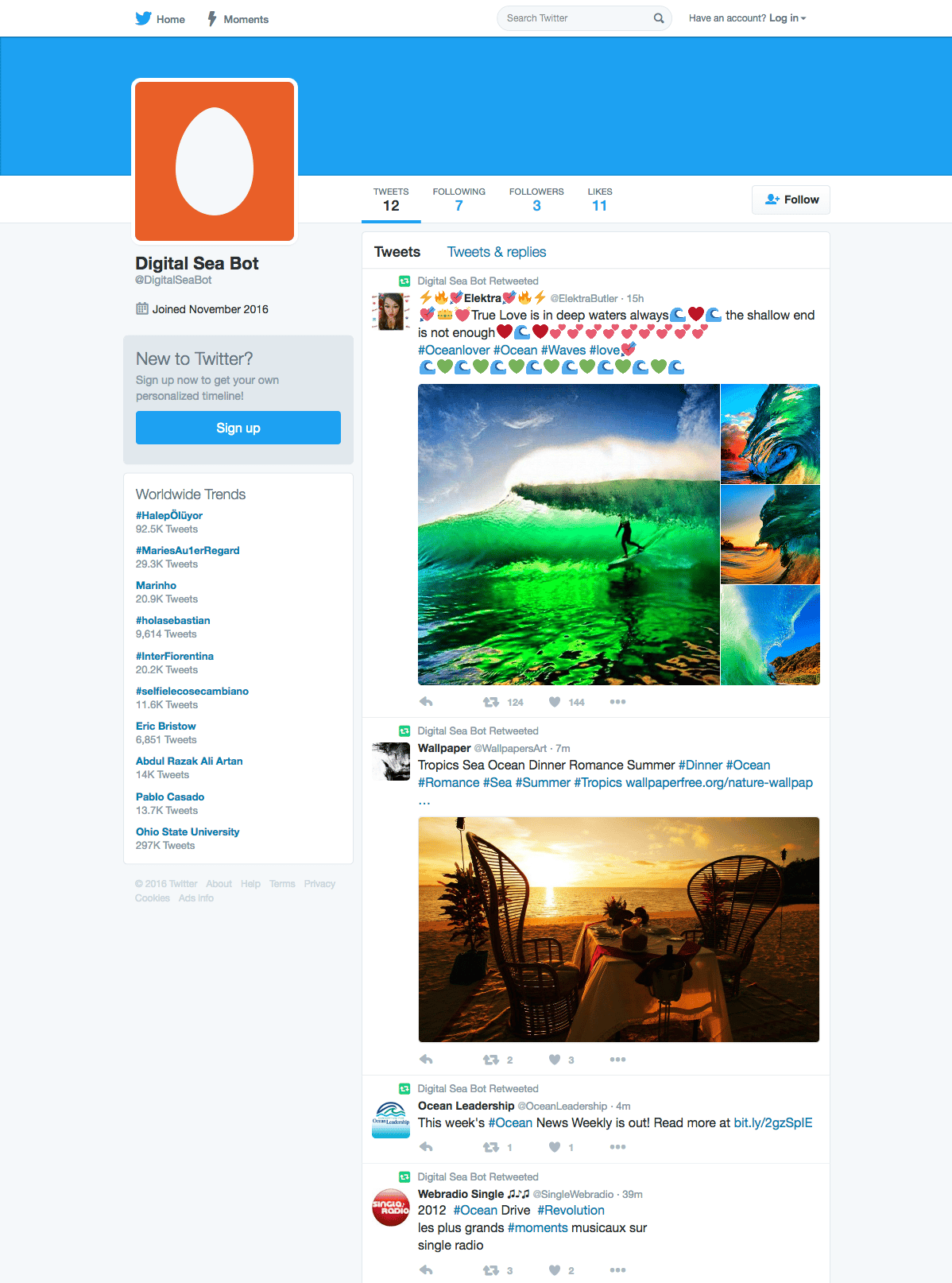
If you run the program several times, you may find that the Twitterbot is finding the same tweets again, but because of the tweepy.TweepError exception handling, your Twitterbot will not retweet these and instead provide the following output:
Output[{'message': 'You have already retweeted this tweet.', 'code': 327}]
We can add functionality to have the Twitterbot favorite the found tweet and follow the user who produced the tweet. This is done in a similar syntax and style to the format for retweeting.
import tweepy
from time import sleep
from credentials import *
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
for tweet in tweepy.Cursor(api.search, q='#ocean').items():
try:
print('\nTweet by: @' + tweet.user.screen_name)
tweet.retweet()
print('Retweeted the tweet')
# Favorite the tweet
tweet.favorite()
print('Favorited the tweet')
# Follow the user who tweeted
tweet.user.follow()
print('Followed the user')
sleep(5)
except tweepy.TweepError as e:
print(e.reason)
except StopIteration:
break
You may notice that the Tweepy error handling is not accounting for following users that have already been followed, so we can introduce an if statement before the .user.follow() function:
...
if not tweet.user.following:
# Don't forget to indent
tweet.user.follow()
print('Followed the user')
...
You can continue to modify this code to your liking and introduce more ways to handle various situations.
Now let’s get into how to keep this Twitterbot running on our server.
Keeping the Twitterbot Running
Because Twitterbots do ongoing and automated tasks, you may want to keep the program running even when your computer is sleeping or turned off. With a server, you can keep your program running as long as you would like.
For this example, we’ll use the twitter_retweet.py file, but you can also use the twitterbot_textfile.py file, or any other Twitterbot file you’ve created. Ensure that all associated files are available in the same directory of the server.
Note: Before keeping one of these programs running, it’s best to modify your program in order to pass more time to the relevant sleep() functions since your Twitterbot will be running 24/7 until you manually stop it (or until the text file you pass to it is complete). Recall that the sleep() function takes in seconds as its parameter, so sleep(3600) would time your tweets to occur every hour, sleep(7200) would time your tweets to occur every two hours, etc. The more frequently you tweet, especially with a given hashtag, the more likely your Twitterbot will get unwelcome attention and bother other users causing your account to be locked. Again, refer to Twitter’s Automation rules and best practices if you’re unsure about how best to use your Twitterbot.
To keep our Twitterbot program running, we’ll be using the nohup command which ignores the hangup (HUP) signal. By using nohup, output that normally appears in the terminal window will instead print to a file called nohup.out.
Ensure that you’re in your Python environment with access to the Tweepy library, and in the directory where your Python program file lives, and type the following command:
- nohup python twitterbot_retweet.py &
You should receive output with a number in brackets ([1] if this is the first process you’re starting) and a string of numbers:
Output[1] 21725
At this point, verify that your Twitterbot is running by checking your account’s Twitter page. At least one new tweet should have posted before the program gets to your sleep() function. If the new tweet is not there, you can take a look at the nohup.out file with a text editor such as nano:
- nano nohup.out
Check to see if there are errors and make modifications to the program as needed, kill the process, and then run the nohup command again and check your Twitter account for a new tweet.
Once you have verified that your Twitterbot is running, use logout to close the connection to your server.
- logout
If you keep your process running for a long time without monitoring it, and depending on your server’s capacity, nohup.out may fill up your disk space. When you want or need to, you can stop your Twitterbot by logging back into your server and using the kill command. You’ll use this command with the string of numbers that was generated above. In our example we would use kill 21725. As you may no longer have that number handy, you can easily retrieve the string of numbers by running the ps command for process status, and the -x flag to include all processes not attached to terminals:
- ps -x
You should receive output that looks something like this:
Output PID TTY STAT TIME COMMAND
21658 ? Ss 0:00 /lib/systemd/systemd --user
21660 ? S 0:00 (sd-pam)
21725 ? S 0:02 python twitterbot_retweet.py
21764 ? S 0:00 sshd: sammy@pts/0
21765 pts/0 Ss 0:00 -bash
21782 pts/0 R+ 0:00 ps xw
You should see your Python program running, in our case its ID is 21725, in the third line. Now we can stop the process:
- kill 21725
If you run the command ps -x again, the process of the Python Twitterbot will no longer be there.
Conclusion
This tutorial walked through setting up and running two different versions of Twitterbots to automatically interact with the Twitter social media platform. There is a lot more that you can do with the Twitter API and with libraries like Tweepy that make it easy for developers to make use of Twitter.
From here, you can also go deeper into the Tweepy library and Twitter API to create lists, add users to lists, engage with direct messages, and streaming with Twitter to download tweets in real time. You may also consider combining the functionality of the two Twitterbots we created above. In addition to making interactive Twitterbots, you can also do substantial data mining by making use of the Twitter API.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Community and Developer Education expert. Former Senior Manager, Community at DigitalOcean. Focused on topics including Ubuntu 22.04, Ubuntu 20.04, Python, Django, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Doesn’t work. Just gives me this error
Traceback (most recent call last): File “twitterbot_retweet.py”, line 5, in <module> auth = tweepy.OAuthHandler(consumer_key, consumer_secret) AttributeError: module ‘tweepy’ has no attribute ‘OAuthHandler’
I just wanted to thank you for sharing this code It actually works! Still have not figured out the server code because I am using Windows but the rest works in Python 3.6 very well.
Hi, great article. I developed an simple app for auto follow my follower. I wrote it in python tweepy and test it running the .py script from my computer. It seems running well. My problem is that I don’t know how to “installl” it on twitter so that it can run automatically. Could someone help me? Thanks in advance.
Thank you that was a great tutorial. Please make more tutorials on tweepy, specially on how to store the data received from api requests into CSVs or other file formats… to perform further analysis :)
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
