By Erin Glass
Senior Manager, DevEd
 в Ubuntu 20.04")
Введение
Комплекс Elastic Stack (прежнее название — комплекс ELK) представляет собой набор программного обеспечения Elastic с открытым исходным кодом, обеспечивающий возможности поиска, анализа и визуализации журналов, сгенерированных любым источником в любом формате (централизованное ведение журнала). Централизованное ведение журнала очень полезно для выявления проблем с серверами или приложениями, поскольку обеспечивает возможности поиска всех журнальных записей в одном месте. Также данная возможность позволяет выявлять проблемы, распространяющиеся на несколько серверов, посредством сопоставления их журналов за определенный период времени.
Комплекс Elastic Stack имеет четыре основных компонента:
- Elasticsearch: распределенная поисковая система RESTful, которая сохраняет все собранные данные.
- Logstash: элемент обработки данных комплекса Elastic, отправляющий входящие данные в Elasticsearch.
- Kibana: веб-интерфейс для поиска и визуализации журналов.
- Beats: компактные элементы переноса данных одиночного назначения, которые могут отправлять данные с сотен или тысяч компютеров в Logstash или Elasticsearch.
В этом обучающем модуле вы научитесь устанавливать комплект Elastic на сервере Ubuntu 20.04. Вы научитесь устанавливать все компоненты Elastic Stack, в том числе Filebeat, инструмент для перенаправления и централизации журналов и файлов, а также настраивать эти компоненты для сбора и визуализации системных журналов. Кроме того, поскольку компонент Kibana обычно доступен только через localhost, мы будем использовать Nginx в качестве прокси для обеспечения доступа через браузер. Мы установим все эти компоненты на одном сервере, который будем называть нашим сервером Elastic Stack.
Примечание. При установке Elastic Stack необходимо использовать одну и ту же версию для всего комплекса. В этом обучающем модуле мы установим последние версии компонентов комплекта. На момент написания это Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 и Filebeat 7.7.1.
Предварительные требования
Для этого обучающего модуля вам потребуется следующее:
-
Сервер Ubuntu 20.04 с 4 ГБ оперативной памяти и 2 процессорами, а также настроенный пользователь без прав root с привилегиями sudo. Вы можете это сделать, воспользовавшись указаниями руководства Начальная настройка сервера Ubuntu 18.04. В этом обучающем руководстве мы будем использовать минимальное количество процессоров и оперативной памяти, необходимое для работы с Elasticsearch. Обратите внимание, что требования сервера Elasticsearch к количеству процессоров, оперативной памяти и хранению данных зависят от ожидаемого объема журналов.
-
Установленный пакет OpenJDK 11. Для настройки воспользуйтесь рекомендациями раздела «Установка комплекта JRE/JDK по умолчанию» in our guide в документе «Установка Java с помощью Apt в Ubuntu 20.04».
-
На сервере должен быть установлен Nginx, который мы позднее настроим как обратный прокси для Kibana. Для настройки следуйте указаниям нашего обучающего модуля «Установка Nginx в Ubuntu 20.04».
Кроме того, поскольку комплекс Elastic используется для доступа ценной информации о вашем сервере, которую вам нужно защищать, очень важно обеспечить защиту сервера сертификатом TLS/SSL. Это необязательно, но настоятельно рекомендуется.
Однако поскольку вы будете вносить изменения в серверный блок Nginx в ходе выполнения этого обучающего модуля, разумнее всего будет пройти обучающий модуль «Let’s Encrypt в Ubuntu 18.04» после прохождения второго шага настоящего обучающего модуля. Если вы планируете настроить на сервере Let’s Encrypt, вам потребуется следующее:
-
Полностью квалифицированное доменное имя (FQDN). В этом обучающем руководстве мы будем использовать
your_domain. Вы можете купить доменное имя на Namecheap, получить его бесплатно на Freenom или воспользоваться услугами любого предпочитаемого регистратора доменных имен. -
На вашем сервере должны быть настроены обе нижеследующие записи DNS. В руководстве Введение в DigitalOcean DNS содержится подробная информация по их добавлению.
- Запись A, где
your_domainуказывает на публичный IP-адрес вашего сервера. - Запись A, где
www.your_domainуказывает на публичный IP-адрес вашего сервера.
- Запись A, где
Шаг 1 — Установка и настройка Elasticsearch
Компоненты Elasticsearch отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавить список источников пакетов Elastic для установки Elasticsearch.
Для начала используйте cURL, инструмент командной строки для передачи данных с помощью URL, для импорта открытого ключа Elasticsearch GPG в APT. Обратите внимание, что мы используем аргументы -fsSL для подавления всех текущих и возможных ошибок (кроме сбоя сервера), а также чтобы разрешить cURL подать запрос на другой локации при переадресации. Выведите результаты команды cURL в программу apt-key, которая добавит открытый ключ GPG в APT.
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Затем добавьте список источников Elastic в директорию sources.list.d, где APT будет искать новые источники:
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
- sudo apt update
Установите Elasticsearch с помощью следующей команды:
- sudo apt install elasticsearch
Теперь система Elasticsearch установлена и готова к настройке. Используйте предпочитаемый текстовый редактор для изменения файла конфигурации Elasticsearch, elasticsearch.yml. Мы будем использовать nano:
- sudo nano /etc/elasticsearch/elasticsearch.yml
Примечание. Файл конфигурации Elasticsearch представлен в формате YAM. Это означает, что нам нужно сохранить формат отступов. Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Файл elasticsearch.yml предоставляет варианты конфигурации для вашего кластера, узла, пути, памяти, сети, обнаружения и шлюза. Большинство из этих вариантов уже настроены в файле, но вы можете изменить их в соответствии с вашими потребностями. В нашем случае для демонстрации односерверной конфигурации мы будем регулировать настройки только для хоста сети.
Elasticsearch прослушивает весь трафик порта 9200. По желанию вы можете ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не смогли прочесть ваши данные или отключить ваш кластер Elasticsearch через [REST API] (https://en.wikipedia.org/wiki/Representational_state_transfer). Для ограничения доступа и повышения безопасности найдите строку с указанием network.host, разкомментируйте ее и замените значение на localhost, чтобы она выглядела следующим образом:
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Мы указали localhost, и теперь Elasticsearch прослушивает все интерфейсы и связанные IP-адреса. Если вы хотите, чтобы прослушивался только конкретный интерфейс, вы можете указать его IP-адрес вместо localhost. Сохраните и закройте elasticsearch.yml. Если вы используете nano, вы можете сделать это, нажав CTRL+X, затем Y, а затем ENTER.
Это минимальные настройки, с которыми вы можете начинать использовать Elasticsearch. Теперь вы можете запустить Elasticsearch в первый раз.
Запустите службу Elasticsearch с помощью systemctl. Запуск Elasticsearch может занять некоторое время. В другом случае вы можете увидеть сообщение об ошибке подключения.
- sudo systemctl start elasticsearch
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
- sudo systemctl enable elasticsearch
Вы можете протестировать работу службы Elasticsearch, отправив запрос HTTP:
- curl -X GET "localhost:9200"
Вы получите ответ, содержащий базовую информацию о локальном узле:
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Мы настроили и запустили Elasticsearch, и теперь можем перейти к установке Kibana, следующего компонента комплекса Elastic.
Шаг 2 — Установка и настройка информационной панели Kibana
Согласно официальной документации, Kibana следует устанавливать только после установки Elasticsearch. Установка в этом порядке обеспечивает правильность установки зависимостей компонентов.
Поскольку вы уже добавили источник пакетов Elastic на предыдущем шаге, вы можете просто установить все остальные компоненты комплекса Elastic с помощью apt:
- sudo apt install kibana
Затем активируйте и запустите службу Kibana:
- sudo systemctl enable kibana
- sudo systemctl start kibana
Поскольку согласно настройкам Kibana прослушивает только localhost, мы должны задать обратный прокси, чтобы разрешить внешний доступ. Для этого мы используем Nginx, который должен быть уже установлен на вашем сервере.
Вначале нужно использовать команду openssl для создания административного пользователя Kibana, которого вы будете использовать для доступа к веб-интерфейсу Kibana. Для примера мы назовем эту учетную запись kibanaadmin, однако для большей безопасности мы рекомендуем выбрать нестандартное имя пользователя, которое будет сложно угадать.
Следующая команда создаст административного пользователя Kibana и пароль и сохранит их в файле htpasswd.users. Вы настроите Nginx для использования этого имени пользователя и пароля и моментально прочитаете этот файл:
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
Введите и подтвердить пароль в диалоговом окне. Запомните или запишите эти учетные данные, поскольку они вам потребуются для доступа к веб-интерфейсу Kibana.
Теперь мы создадим файл серверного блока Nginx. В качестве примера мы присвоим этому файлу имя your_domain, хотя вы можете дать ему более описательное имя. Например, если вы настроили записи FQDN и DNS для этого сервера, вы можете присвоить этому файлу имя своего FQDN:
Создайте файл серверного блока Nginx, используя nano или предпочитаемый текстовый редактор:
- sudo nano /etc/nginx/sites-available/your_domain
Добавьте в файл следующий блок кода и обязательно замените your_domain на FQDN или публичный IP-адрес вашего сервера. Этот код настраивает Nginx для перенаправления трафика HTTP вашего сервера в приложение Kibana, которое прослушивает порт localhost:5601. Также он настраивает Nginx для чтения файла htpasswd.users и требует использования базовой аутентификации.
Если вы выполнили предварительный обучающий модуль по Nginx до конца, возможно вы уже создали этот файл и заполнили его. В этом случае удалите из файла все содержание и добавьте следующее:
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Завершив редактирование, сохраните и закройте файл.
Затем активируйте новую конфигурацию, создав символическую ссылку на каталог sites-enabled. Если вы уже создали файл серверного блока с тем же именем, что и в обучающем модуле по Nginx, вам не нужно выполнять эту команду:
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
Затем проверьте конфигурацию на синтаксические ошибки:
- sudo nginx -t
Если в результатах будут показаны какие-либо ошибки, вернитесь и еще раз проверьте правильность изменений в файле конфигурации. Когда вы увидите на экране результатов сообщение syntax is ok, перезапустите службу Nginx:
- sudo systemctl reload nginx
Если вы следовали указаниям модуля по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить соединения с Nginx, мы можем изменить правила с помощью следующей команды:
- sudo ufw allow 'Nginx Full'
Примечание. Если вы выполнили предварительный обучающий модуль Nginx, вы могли уже создать правило UFW, разрешающее профилю Nginx HTTP доступ через брандмауэр. Поскольку профиль Nginx Full разрешает трафик HTTP и HTTPS на брандмауэре, вы можете безопасно удалить ранее созданное правило. Для этого нужно использовать следующую команду:
- sudo ufw delete allow 'Nginx HTTP'
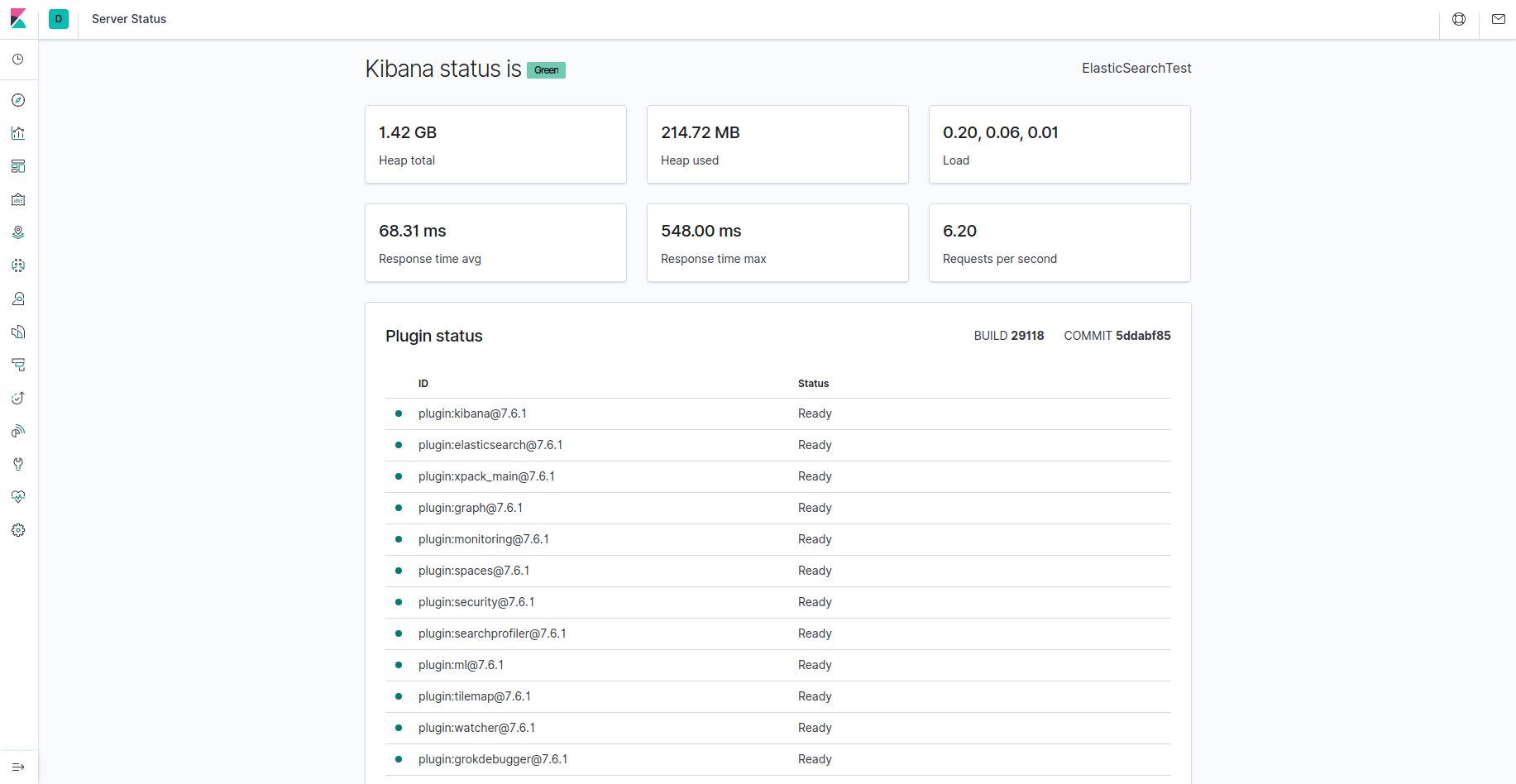
Теперь приложение Kibana доступно через FQDN или публичный IP-адрес вашего сервера комплекса Elastic. Вы можете посмотреть страницу состояния сервера Kibana, открыв следующий адрес и введя свои учетные данные в диалоге:
http://your_domain/status
На этой странице состояния отображается информация об использовании ресурсов сервера, а также выводится список установленных плагинов.
Примечание. Как указывалось в разделе предварительных требований, рекомендуется включить на сервере SSL/TLS. Теперь вы можете следовать указаниями обучающего модуля по Let’s Encrypt для получения бесплатного сертификата SSL для Nginx в Ubuntu 20.04. После получения сертификата SSL/TLS вы можете вернуться и завершить прохождение этого обучающего модуля.
Теперь информационная панель Kibana настроена и мы перейдем к установке следующего компонента: Logstash.
Шаг 3 — Установка и настройка Logstash
Хотя Beats может отправлять данные напрямую в базу данных Elasticsearch, мы рекомендуем использовать для обработки данных Logstash. Это даст вам гибкую возможность собирать данные из разных источников, преобразовывать их в общий формат и экспортировать в другую базу данных.
Установите Logstash с помощью следующей команды:
- sudo apt install logstash
После установки Logstash вы можете перейти к настройке. Файлы конфигурации Logstash находятся в каталоге /etc/logstash/conf.d. Дополнительную информацию о синтаксисе конфигурации можно найти в справочнике по конфигурации, предоставляемом Elastic. Во время настройки конфигурации в файле полезно рассматривать Logstash как конвейер, принимающий данные на одном конце, обрабатывающий и отправляющий их в пункт назначения (в нашем случае пунктом назначения является Elasticsearch). Конвейер Logstash имеет два обязательных элемента, input и output, а также необязательный элемент filter. Плагины ввода потребляют данные источника, плагины фильтра обрабатывают данные, а плагины вывода записывают данные в пункт назначения.
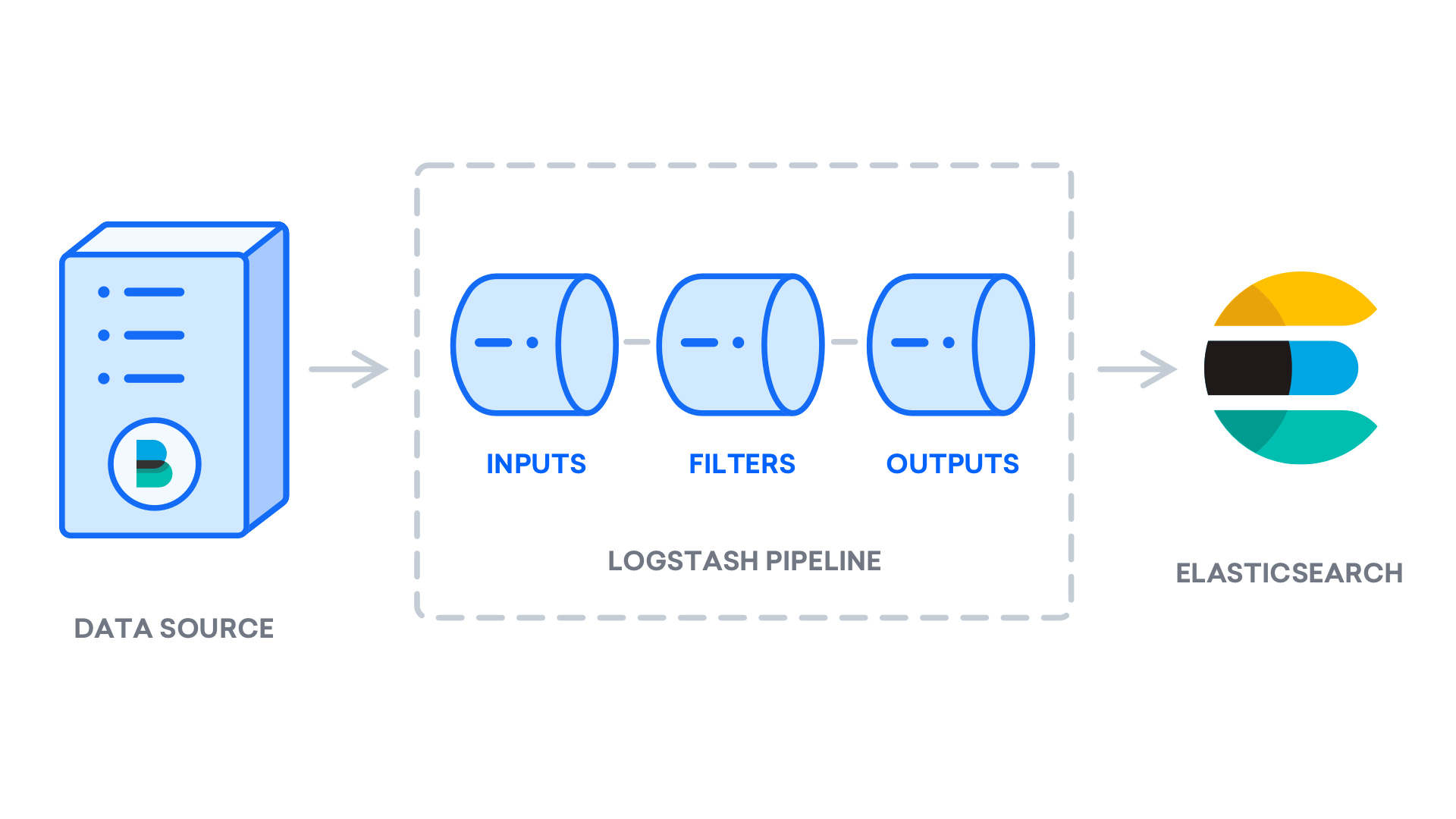
Создайте файл конфигурации с именем 02-beats-input.conf, где вы настроите ввод данных Filebeat:
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
Вставьте следующую конфигурацию ввода. В ней задается ввод beats, который прослушивает порт TCP 5044.
[label /etc/logstash/conf.d/02-beats-input.conf] input { beats { port => 5044 }
}
Сохраните и закройте файл.
Создайте файл конфигурации с именем 30-elasticsearch-output.conf:
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Вставьте следующую конфигурацию вывода. Этот вывод настраивает Logstash для хранения данных Beats в Elasticsearch, запущенном на порту localhost:9200, в индексе с названием используемого компонента Beat. В этом обучающем модуле используется компонент Beat под названием Filebeat:
[label /etc/logstash/conf.d/30-elasticsearch-output.conf] output { if
[@metadata][pipeline] { elasticsearch { hosts => ["localhost:9200"]
manage_template => false index =>
"%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" pipeline =>
"%{[@metadata][pipeline]}" } } else { elasticsearch { hosts =>
["localhost:9200"] manage_template => false index =>
"%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } }
Сохраните и закройте файл.
Протестируйте свою конфигурацию Logstash с помощью следующей команды:
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Если ошибок синтаксиса не будет, в выводе появится сообщение Config Validation Result: OK. Exiting Logstash через несколько секунд после запуска. Если вы не увидите этого сообщения, проверьте ошибки вывода и обновите конфигурацию для их исправления. Обратите внимание, что вы получите предупреждения от OpenJDK, но они не должны вызывать проблем, и их можно игнорировать.
Если тестирование конфигурации выполнено успешно, запустите и активируйте Logstash, чтобы изменения конфигурации вступили в силу:
- sudo systemctl start logstash
- sudo systemctl enable logstash
Теперь Logstash работает нормально и полностью настроен, и мы можем перейти к установке Filebeat.
Шаг 4 — Установка и настройка Filebeat
Комплекс Elastic использует несколько компактных элементов транспортировки данных (Beats) для сбора данных из различных источников и их транспортировки в Logstash или Elasticsearch. Ниже перечислены компоненты Beats, доступные в Elastic:
- Filebeat: собирает и отправляет файлы журнала.
- Metricbeat: собирает метрические показатели использования систем и служб.
- Packetbeat: собирает и анализирует данные сети.
- Winlogbeat: собирает данные журналов событий Windows.
- Auditbeat: собирает данные аудита Linux и отслеживает целостность файлов.
- Heartbeat: отслеживает доступность услуг посредством активного зондирования.
В этом обучающем модуле мы используем Filebeat для перенаправления локальных журналов в комплекс Elastic.
Установите Filebeat с помощью apt:
- sudo apt install filebeat
Затем настройте Filebeat для подключения к Logstash. Здесь мы изменим образец файла конфигурации, входящий в комплектацию Filebeat.
Откройте файл конфигурации Filebeat:
- sudo nano /etc/filebeat/filebeat.yml
Примечание. Как и в Elasticsearch, файл конфигурации Filebeat имеет формат YAML. Это означает, что в файле учитываются отступы, и вы должны использовать точно такое количество пробелов, как указано в этих инструкциях.
Filebeat поддерживает разнообразные выводы, но обычно события отправляются только напрямую в Elasticsearch или в Logstash для дополнительной обработки. В этом обучающем модуле мы будем использовать Logstash для дополнительной обработки данных, собранных Filebeat. Filebeat не потребуется отправлять данные в Elasticsearch напрямую, поэтому мы отключим этот вывод. Для этого мы найдем раздел output.elasticsearch и поставим перед следующими строками значок комментария #:
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
Затем настроим раздел output.logstash. Уберите режим комментариев для строк output.logstash: и hosts: ["localhost:5044"], удалив значки #. Так мы настроим Filebeat для подключения к Logstash на сервере комплекса Elastic Stack через порт 5044, который мы ранее задали для ввода Logstash:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
Сохраните и закройте файл.
Функции Filebeat можно расширить с помощью модулей Filebeat. В этом обучающем модуле мы будем использовать модуль system, который собирает и проверяет данные журналов, созданных службой регистрации систем в распространенных дистрибутивах Linux.
Давайте активируем его:
- sudo filebeat modules enable system
Вы увидите список включенных и отключенных модулей с помощью следующей команды:
- sudo filebeat modules list
Вы увидите примерно следующий список:
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...
Filebeat по умолчанию настроен для использования путей по умолчанию для системных журналов и журналов авторизации. Для целей данного обучающего модуля вам не нужно ничего изменять в конфигурации. Вы можете посмотреть параметры модуля в файле конфигурации /etc/filebeat/modules.d/system.yml.
Затем нам нужно настроить конвейеры обработки Filebeat, выполняющие синтаксический анализ данных журнала перед их отправкой через logstash в Elasticsearch. Чтобы загрузить конвейер обработки для системного модуля, введите следующую команду:
- sudo filebeat setup --pipelines --modules system
Затем загрузите в Elasticsearch шаблон индекса. Индекс Elasticsearch — это коллекция документов со сходными характеристиками. Индексы идентифицируются по имени, которое используется для ссылки на индекс при выполнении различных операций внутри него. Шаблон индекса применяется автоматически при создании нового индекса.
Используйте следующую команду для загрузки шаблона:
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
В комплект Filebeat входят образцы информационных панелей Kibana, позволяющие визуализировать данные Filebeat в Kibana. Прежде чем вы сможете использовать информационные панели, вам нужно создать шаблон индекса и загрузить информационные панели в Kibana.
При загрузке информационных панелей Filebeat подключается к Elasticsearch для проверки информации о версиях. Для загрузки информационных панелей при включенном Logstash необходимо отключить вывод Logstash и активировать вывод Elasticsearch:
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Результат должен выглядеть примерно следующим образом:
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Теперь вы можете запустить и активировать Filebeat:
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Если вы правильно настроили комплекс Elastic, Filebeat начнет отправлять системный журнал и журналы авторизации в Logstash, откуда эти данные будут загружаться в Elasticsearch.
Чтобы подтвердить получение этих данных в Elasticsearch необходимот отправить в индекс Filebeat запрос с помощью следующей команды:
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Результат должен выглядеть примерно следующим образом:
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
Если в результатах показано 0 совпадений, Elasticsearch не выполняет загрузку журналов в индекс, который вы искали, и вам нужно проверить настройки на ошибки. Если вы получили ожидаемые результаты, перейдите к следующему шагу, где мы увидим, как выполняется навигация по информационным панелям Kibana.
Шаг 5 — Изучение информационных панелей Kibana
Вернемся в веб-интерфейс Kibana, который мы установили ранее.
Откройте в браузере FQDN или публичный IP-адрес вашего сервера с комплексом Elastic. Если сессия была прервана, вам нужно будет повторно ввести учетные данные, которые вы определили на шаге 2. После входа в систему вы получите домашнюю страницу Kibana:
Нажмите ссылку Discover (Изучение) в левой панели навигации (возможно вам нужно будет нажать значок раскрытия в нижнем левом углу, чтобы увидеть все элементы меню навигации). Выберите на странице Discover (Изучение) заранее настроенный индекс filebeat-* для просмотра данных Filebeat. По умолчанию при этом будут выведены все данные журналов за последние 15 минут. Ниже вы увидите гистограмму с событиями журнала и некоторыми сообщениями журнала:
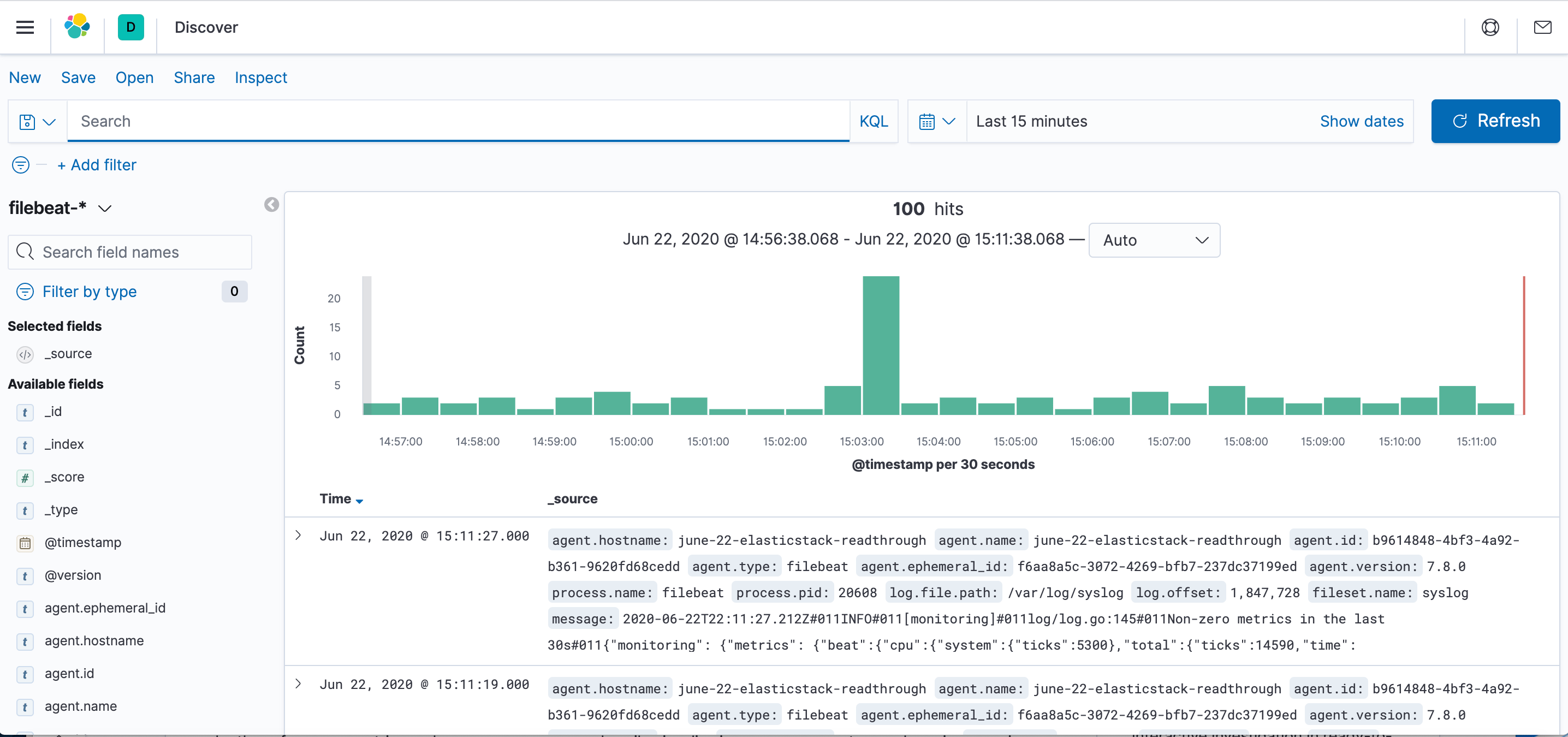
Здесь вы можете искать и просматривать журналы, а также настраивать информационные панели. Сейчас на этой странице будет немного данных, потому что вы собираете системные журналы только со своего сервера Elastic Stack.
Используйте левую панель навигации для перехода на страницу Dashboard и выполните на этой странице поиск информационных панелей Filebeat System. После этого вы можете выбрать образцы панелей управления, входящие в комплект модуля Filebeat system.
Например, вы можете просматривать подробную статистику по сообщениям системного журнала:
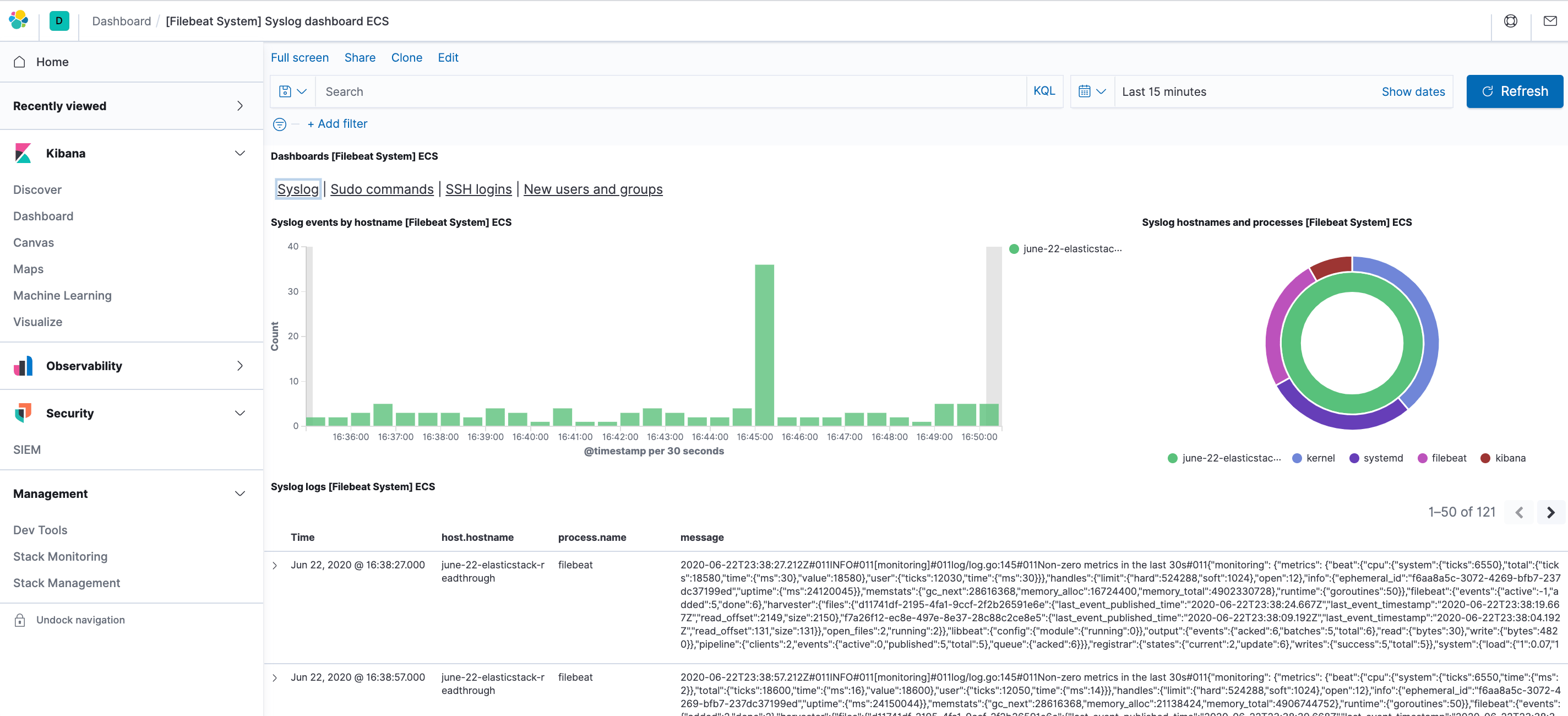
Также вы сможете видеть, какие пользователи использовали команду sudo и когда:
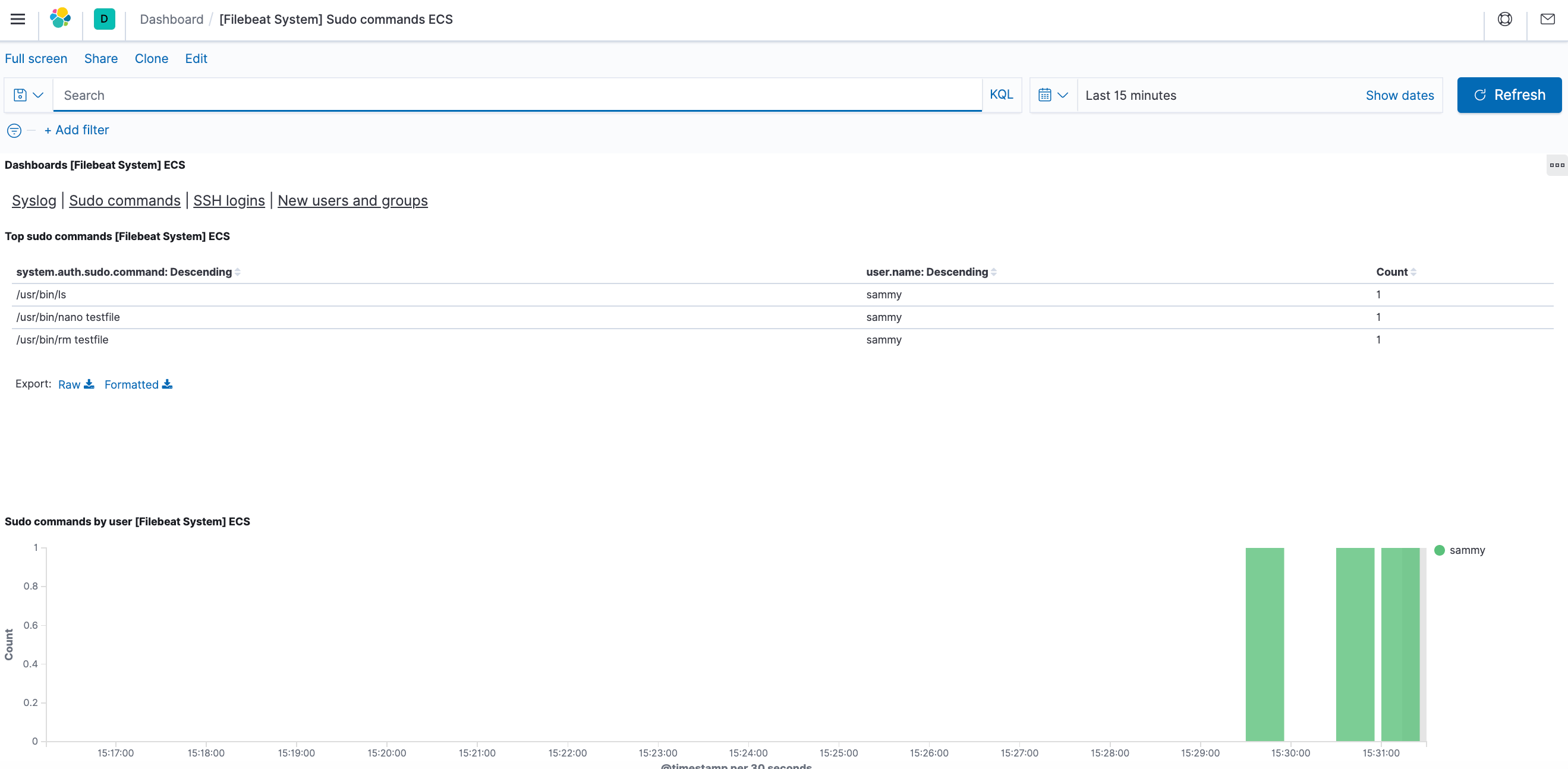
В Kibana имеется множество других функций, в том числе функции фильтрации и составления диаграмм, так что вы можете свободно их исследовать.
Заключение
В этом обучающем модуле вы научились устанавливать и настраивать комплекс Elastic Stack для сбора и анализа данных системных журналов. Помните, что вы можете отправлять в Logstash практически любые типы данных журнала и индексированных данных с помощью Beats, однако данные будут более полезны, если они будут проанализированы и структурированы с помощью фильтра Logstash, который преобразует данные в единый формат, легко читаемый Elasticsearch.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Open source advocate and lover of education, culture, and community.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
