By Savic and Kathryn Hancox

Introduction
Structuring Terraform projects appropriately according to their use cases and perceived complexity is essential to ensure their maintainability and extensibility in day-to-day operations. A systematic approach to properly organizing code files is necessary to ensure that the project remains scalable during deployment and usable to you and your team.
In this tutorial, you’ll learn about structuring Terraform projects according to their general purpose and complexity. Then, you’ll create a project with a simple structure using the more common features of Terraform: variables, locals, data sources, and provisioners. In the end, your project will deploy an Ubuntu 20.04 server (Droplet) on DigitalOcean, install an Apache web server, and point your domain to the web server.
Prerequisites
-
A DigitalOcean Personal Access Token, which you can create via the DigitalOcean control panel. You can find instructions in the DigitalOcean product documents, How to Create a Personal Access Token.
-
A password-less SSH key added to your DigitalOcean account, which you can create by following How To Use SSH Keys with DigitalOcean Droplets.
-
Terraform installed on your local machine. For instructions according to your operating system, see Step 1 of the How To Use Terraform with DigitalOcean tutorial.
-
Python 3 installed on your local machine. You can complete Step 1 of How To Install and Set Up a Local Programming Environment for Python 3 for your OS.
-
A fully registered domain name added to your DigitalOcean account. For instructions on how to do that, visit the official docs.
Note: This tutorial has specifically been tested with Terraform 1.0.2.
Understanding a Terraform Project’s Structure
In this section, you’ll learn what Terraform considers a project, how you can structure the infrastructure code, and when to choose which approach. You’ll also learn about Terraform workspaces, what they do, and how Terraform is storing state.
A resource is an entity of a cloud service (such as a DigitalOcean Droplet) declared in Terraform code that is created according to specified and inferred properties. Multiple resources form infrastructure with their mutual connections.
Terraform uses a specialized programming language for defining infrastructure, called Hashicorp Configuration Language (HCL). HCL code is typically stored in files ending with the extension tf. A Terraform project is any directory that contains tf files and which has been initialized using the init command, which sets up Terraform caches and default local state.
Terraform state is the mechanism via which it keeps track of resources that are actually deployed in the cloud. State is stored in backends (locally on disk or remotely on a file storage cloud service or specialized state management software) for optimal redundancy and reliability. You can read more about different backends in the Terraform documentation.
Project workspaces allow you to have multiple states in the same backend, tied to the same configuration. This allows you to deploy multiple distinct instances of the same infrastructure. Each project starts with a workspace named default—this will be used if you do not explicitly create or switch to another one.
Modules in Terraform (akin to libraries in other programming languages) are parametrized code containers enclosing multiple resource declarations. They allow you to abstract away a common part of your infrastructure and reuse it later with different inputs.
A Terraform project can also include external code files for use with dynamic data inputs, which can parse the JSON output of a CLI command and offer it for use in resource declarations. In this tutorial, you’ll do this with a Python script.
Now that you know what a Terraform project consists of, let’s review two general approaches to Terraform project structuring.
Simple Structure
A simple structure is suitable for small and testing projects, with a few resources of varying types and variables. It has a few configuration files, usually one per resource type (or more helper ones together with a main), and no custom modules, because most of the resources are unique and there aren’t enough to be generalized and reused. Following this, most of the code is stored in the same directory, next to each other. These projects often have a few variables (such as an API key for accessing the cloud) and may use dynamic data inputs and other Terraform and HCL features, though not prominently.
As an example of the file structure of this approach, this is what the project you’ll build in this tutorial will look like in the end:
.
└── tf/
├── versions.tf
├── variables.tf
├── provider.tf
├── droplets.tf
├── dns.tf
├── data-sources.tf
└── external/
└── name-generator.py
As this project will deploy an Apache web server Droplet and set up DNS records, the definitions of project variables, the DigitalOcean Terraform provider, the Droplet, and DNS records will be stored in their respective files. The minimum required Terraform and DigitalOcean provider versions will be specified in versions.tf, while the Python script that will generate a name for the Droplet (and be used as a dynamic data source in data-sources.tf) will be stored in the external folder, to separate it from HCL code.
Complex Structure
Contrary to the simple structure, this approach is suitable for large projects, with clearly defined subdirectory structures containing multiple modules of varying levels of complexity, aside from the usual code. These modules can depend on each other. Coupled with version control systems, these projects can make extensive use of workspaces. This approach is suitable for larger projects managing multiple apps, while reusing code as much as possible.
Development, staging, quality assurance, and production infrastructure instances can also be housed under the same project in different directories by relying on common modules, thus eliminating duplicate code and making the project the central source of truth. Here is the file structure of an example project with a more complex structure, containing multiple deployment apps, Terraform modules, and target cloud environments:
.
└── tf/
├── modules/
│ ├── network/
│ │ ├── main.tf
│ │ ├── dns.tf
│ │ ├── outputs.tf
│ │ └── variables.tf
│ └── spaces/
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── applications/
├── backend-app/
│ ├── env/
│ │ ├── dev.tfvars
│ │ ├── staging.tfvars
│ │ ├── qa.tfvars
│ │ └── production.tfvars
│ └── main.tf
└── frontend-app/
├── env/
│ ├── dev.tfvars
│ ├── staging.tfvars
│ ├── qa.tfvars
│ └── production.tfvars
└── main.tf
This approach is explored further in the series How to Manage Infrastructure with Terraform.
You now know what a Terraform project is, how to best structure it according to perceived complexity, and what role Terraform workspaces serve. In the next steps, you’ll create a project with a simple structure that will provision a Droplet with an Apache web server installed and DNS records set up for your domain. You’ll first initialize your project with the DigitalOcean provider and variables, and then proceed to define the Droplet, a dynamic data source to provide its name, and a DNS record for deployment.
Step 1 — Setting Up Your Initial Project
In this section, you’ll add the DigitalOcean Terraform provider to your project, define the project variables, and declare a DigitalOcean provider instance, so that Terraform will be able to connect to your account.
Start off by creating a directory for your Terraform project with the following command:
- mkdir ~/apache-droplet-terraform
Navigate to it:
- cd ~/apache-droplet-terraform
Since this project will follow the simple structuring approach, you’ll store the provider, variables, Droplet, and DNS record code in separate files, per the file structure from the previous section. First, you’ll need to add the DigitalOcean Terraform provider to your project as a required provider.
Create a file named versions.tf and open it for editing by running:
- nano versions.tf
Add the following lines:
terraform {
required_providers {
digitalocean = {
source = "digitalocean/digitalocean"
version = "~> 2.0"
}
}
}
In this terraform block, you list the required providers (DigitalOcean, version 2.x). When you are done, save and close the file.
Then, define the variables your project will expose in the variables.tf file, following the approach of storing different resource types in separate code files:
- nano variables.tf
Add the following variables:
variable "do_token" {}
variable "domain_name" {}
Save and close the file.
The do_token variable will hold your DigitalOcean Personal Access Token and domain_name will specify your desired domain name. The deployed Droplet will have the SSH key, identified by the SSH fingerprint, automatically installed.
Next, let’s define the DigitalOcean provider instance for this project. You’ll store it in a file named provider.tf. Create and open it for editing by running:
- nano provider.tf
Add the provider:
provider "digitalocean" {
token = var.do_token
}
Save and exit when you’re done. You’ve defined the digitalocean provider, which corresponds to the required provider you specified earlier in provider.tf, and set its token to the value of the variable, which will be supplied during runtime.
In this step, you have created a directory for your project, requested the DigitalOcean provider to be available, declared project variables, and set up the connection to a DigitalOcean provider instance to use an authentication token that will be provided later. You’ll now write a script that will generate dynamic data for your project definitions.
Step 2 — Creating a Python Script for Dynamic Data
Before continuing on to defining the Droplet, you’ll create a Python script that will generate the Droplet’s name dynamically and declare a data source resource to parse it. The name will be generated by concatenating a constant string (web) with the current time of the local machine, expressed in the UNIX epoch format. A naming script can be useful when multiple Droplets are generated according to a naming scheme, in order to easily differentiate between them.
You’ll store the script in a file named name-generator.py, in a directory named external. First, create the directory by running:
- mkdir external
The external directory resides in the root of your project and will store non-HCL code files, like the Python script you’ll write.
Create name-generator.py under external and open it for editing:
- nano external/name-generator.py
Add the following code:
import json, time
fixed_name = "web"
result = {
"name": f"{fixed_name}-{int(time.time())}",
}
print(json.dumps(result))
This Python script imports the json and time modules, declares a dictionary named result, and sets the value of the name key to an interpolated string, which combines the fixed_name with the current UNIX time of the machine it runs on. Then, the result is converted into JSON and outputted on stdout. The output will be different each time the script is run:
Output{"name": "web-1597747959"}
When you’re done, save and close the file.
Note: Large and complex structured projects require more thought put into how external data sources are created and used, especially in terms of portability and error handling. Terraform expects the executed program to write a human-readable error message to stderr and gracefully exit with a non-zero status, which is something not shown in this step because of the simplicity of the task. Additionally, it expects the program to have no side effects, so that it can be re-run as many times as needed.
For more info on what Terraform expects, visit the official docs on data sources.
Now that the script is ready, you can define the data source, which will pull the data from the script. You’ll store the data source in a file named data-sources.tf in the root of your project as per the simple structuring approach.
Create it for editing by running:
- nano data-sources.tf
Add the following definition:
data "external" "droplet_name" {
program = ["python3", "${path.module}/external/name-generator.py"]
}
Save and close the file.
This data source is called droplet_name and executes the name-generator.py script using Python 3, which resides in the external directory you just created. It automatically parses its output and provides the deserialized data under its result attribute for use within other resource definitions.
With the data source now declared, you can define the Droplet that Apache will run on.
Step 3 — Defining the Droplet
In this step, you’ll write the definition of the Droplet resource and store it in a code file dedicated to Droplets, as per the simple structuring approach. Its name will come from the dynamic data source you have just created, and will be different each time it’s deployed.
Create and open the droplets.tf file for editing:
- nano droplets.tf
Add the following Droplet resource definition:
data "digitalocean_ssh_key" "ssh_key" {
name = "your_ssh_key_name"
}
resource "digitalocean_droplet" "web" {
image = "ubuntu-20-04-x64"
name = data.external.droplet_name.result.name
region = "fra1"
size = "s-1vcpu-1gb"
ssh_keys = [
data.digitalocean_ssh_key.ssh_key.id
]
}
You first declare a DigitalOcean SSH key resource called ssh_key, which will fetch a key from your account by its name. Make sure to replace the highlighted code with your SSH key name.
Then, you declare a Droplet resource, called web. Its actual name in the cloud will be different, because it’s being requested from the droplet_name external data source. To bootstrap the Droplet resource with a SSH key each time it’s deployed, the ID of the ssh_key is passed into the ssh_keys parameter, so that DigitalOcean will know which key to apply.
For now, this is all you need to configure related to droplet.tf, so save and close the file when you’re done.
You’ll now write the configuration for the DNS record that will point your domain to the just declared Droplet.
Step 4 — Defining DNS Records
The last step in the process is to configure the DNS record pointing to the Droplet from your domain.
You’ll store the DNS config in a file named dns.tf, because it’s a separate resource type from the others you have created in the previous steps. Create and open it for editing:
- nano dns.tf
Add the following lines:
resource "digitalocean_record" "www" {
domain = var.domain_name
type = "A"
name = "@"
value = digitalocean_droplet.web.ipv4_address
}
This code declares a DigitalOcean DNS record at your domain name (passed in using the variable), of type A. The record has a name of @, which is a placeholder routing to the domain itself and with the Droplet IP address as its value. You can replace the name value with something else, which will result in a subdomain being created.
When you’re done, save and close the file.
Now that you’ve configured the Droplet, the name generator data source, and a DNS record, you’ll move on to deploying the project in the cloud.
Step 5 — Planning and Applying the Configuration
In this section, you’ll initialize your Terraform project, deploy it to the cloud, and check that everything was provisioned correctly.
Now that the project infrastructure is defined completely, all that is left to do before deploying it is to initialize the Terraform project. Do so by running the following command:
- terraform init
You’ll receive the following output:
OutputInitializing the backend...
Initializing provider plugins...
- Finding digitalocean/digitalocean versions matching "~> 2.0"...
- Finding latest version of hashicorp/external...
- Installing digitalocean/digitalocean v2.10.1...
- Installed digitalocean/digitalocean v2.10.1 (signed by a HashiCorp partner, key ID F82037E524B9C0E8)
- Installing hashicorp/external v2.1.0...
- Installed hashicorp/external v2.1.0 (signed by HashiCorp)
Partner and community providers are signed by their developers.
If you'd like to know more about provider signing, you can read about it here:
https://www.terraform.io/docs/cli/plugins/signing.html
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
You’ll now be able to deploy your Droplet with a dynamically generated name and an accompanying domain to your DigitalOcean account.
Start by defining the domain name, SSH key fingerprint, and your personal access token as environment variables, so you won’t have to copy the values each time you run Terraform. Run the following commands, replacing the highlighted values:
- export DO_PAT="your_do_api_token"
- export DO_DOMAIN_NAME="your_domain"
You can find your API token in your DigitalOcean Control Panel.
Run the plan command with the variable values passed in to see what steps Terraform would take to deploy your project:
- terraform plan -var "do_token=${DO_PAT}" -var "domain_name=${DO_DOMAIN_NAME}"
The output will be similar to the following:
OutputTerraform used the selected providers to generate the following execution plan. Resource
actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# digitalocean_droplet.web will be created
+ resource "digitalocean_droplet" "web" {
+ backups = false
+ created_at = (known after apply)
+ disk = (known after apply)
+ id = (known after apply)
+ image = "ubuntu-20-04-x64"
+ ipv4_address = (known after apply)
+ ipv4_address_private = (known after apply)
+ ipv6 = false
+ ipv6_address = (known after apply)
+ locked = (known after apply)
+ memory = (known after apply)
+ monitoring = false
+ name = "web-1625908814"
+ price_hourly = (known after apply)
+ price_monthly = (known after apply)
+ private_networking = (known after apply)
+ region = "fra1"
+ resize_disk = true
+ size = "s-1vcpu-1gb"
+ ssh_keys = [
+ "...",
]
+ status = (known after apply)
+ urn = (known after apply)
+ vcpus = (known after apply)
+ volume_ids = (known after apply)
+ vpc_uuid = (known after apply)
}
# digitalocean_record.www will be created
+ resource "digitalocean_record" "www" {
+ domain = "your_domain'"
+ fqdn = (known after apply)
+ id = (known after apply)
+ name = "@"
+ ttl = (known after apply)
+ type = "A"
+ value = (known after apply)
}
Plan: 2 to add, 0 to change, 0 to destroy.
...
The lines starting with a green + signify that Terraform will create each of the resources that follow after—which is exactly what should happen, so you can apply the configuration:
- terraform apply -var "do_token=${DO_PAT}" -var "domain_name=${DO_DOMAIN_NAME}"
The output will be the same as before, except that this time you’ll be asked to confirm:
OutputPlan: 2 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: `yes`
Enter yes, and Terraform will provision your Droplet and the DNS record:
Outputdigitalocean_droplet.web: Creating...
...
digitalocean_droplet.web: Creation complete after 33s [id=204432105]
digitalocean_record.www: Creating...
digitalocean_record.www: Creation complete after 1s [id=110657456]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
Terraform has now recorded the deployed resources in its state. To confirm that the DNS records and the Droplet were connected successfully, you can extract the IP address of the Droplet from the local state and check if it matches public DNS records for your domain. Run the following command to get the IP address:
- terraform show | grep "ipv4"
You’ll receive your Droplet’s IP address:
Outputipv4_address = "your_Droplet_IP"
...
You can check the public A records by running:
- nslookup -type=a your_domain | grep "Address" | tail -1
The output will show the IP address to which the A record points:
OutputAddress: your_Droplet_IP
They are the same, as they should be, meaning that the Droplet and DNS record were provisioned successfully.
For the changes in the next step to take place, destroy the deployed resources by running:
- terraform destroy -var "do_token=${DO_PAT}" -var "domain_name=${DO_DOMAIN_NAME}"
When prompted, enter yes to continue.
In this step, you have created your infrastructure and applied it to your DigitalOcean account. You’ll now modify it to automatically install the Apache web server on the provisioned Droplet using Terraform provisioners.
Step 6 — Running Code Using Provisioners
Now you’ll set up the installation of the Apache web server on your deployed Droplet by using the remote-exec provisioner to execute custom commands.
Terraform provisioners can be used to execute specific actions on created remote resources (the remote-exec provisioner) or the local machine the code is executing on (using the local-exec provisioner). If a provisioner fails, the node will be marked as tainted in current state, which means that it will be deleted and recreated during the next run.
To connect to a provisioned Droplet, Terraform needs the private SSH key of the one set up on the Droplet. The best way to pass in the location of the private key is by using variables, so open variables.tf for editing:
- nano variables.tf
Add the highlighted line:
variable "do_token" {}
variable "domain_name" {}
variable "private_key" {}
You have now added a new variable, called private_key , to your project. Save and close the file.
Next, you’ll add the connection data and remote provisioner declarations to your Droplet configuration. Open droplets.tf for editing by running:
- nano droplets.tf
Extend the existing code with the highlighted lines:
data "digitalocean_ssh_key" "ssh_key" {
name = "your_ssh_key_name"
}
resource "digitalocean_droplet" "web" {
image = "ubuntu-20-04-x64"
name = data.external.droplet_name.result.name
region = "fra1"
size = "s-1vcpu-1gb"
ssh_keys = [
data.digitalocean_ssh_key.ssh_key.id
]
connection {
host = self.ipv4_address
user = "root"
type = "ssh"
private_key = file(var.private_key)
timeout = "2m"
}
provisioner "remote-exec" {
inline = [
"export PATH=$PATH:/usr/bin",
# Install Apache
"apt update",
"apt -y install apache2"
]
}
}
The connection block specifies how Terraform should connect to the target Droplet. The provisioner block contains the array of commands, within the inline parameter, that it will execute after provisioning. That is, updating the package manager cache and installing Apache. Save and exit when you’re done.
You can create a temporary environment variable for the private key path as well:
- export DO_PRIVATE_KEY="private_key_location"
Note: The private key, and any other file that you wish to load from within Terraform, must be placed within the project. You can see the How To Configure SSH Key-Based Authentication on a Linux Server tutorial for more info regarding SSH key set up on Ubuntu 20.04 or other distributions.
Try applying the configuration again:
- terraform apply -var "do_token=${DO_PAT}" -var "domain_name=${DO_DOMAIN_NAME}" -var "private_key=${DO_PRIVATE_KEY}"
Enter yes when prompted. You’ll receive output similar to before, but followed with long output from the remote-exec provisioner:
Outputdigitalocean_droplet.web: Creating...
digitalocean_droplet.web: Still creating... [10s elapsed]
digitalocean_droplet.web: Still creating... [20s elapsed]
digitalocean_droplet.web: Still creating... [30s elapsed]
digitalocean_droplet.web: Provisioning with 'remote-exec'...
digitalocean_droplet.web (remote-exec): Connecting to remote host via SSH...
digitalocean_droplet.web (remote-exec): Host: ...
digitalocean_droplet.web (remote-exec): User: root
digitalocean_droplet.web (remote-exec): Password: false
digitalocean_droplet.web (remote-exec): Private key: true
digitalocean_droplet.web (remote-exec): Certificate: false
digitalocean_droplet.web (remote-exec): SSH Agent: false
digitalocean_droplet.web (remote-exec): Checking Host Key: false
digitalocean_droplet.web (remote-exec): Connected!
...
digitalocean_droplet.web: Creation complete after 1m5s [id=204442200]
digitalocean_record.www: Creating...
digitalocean_record.www: Creation complete after 1s [id=110666268]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
You can now navigate to your domain in a web browser. You will see the default Apache welcome page.
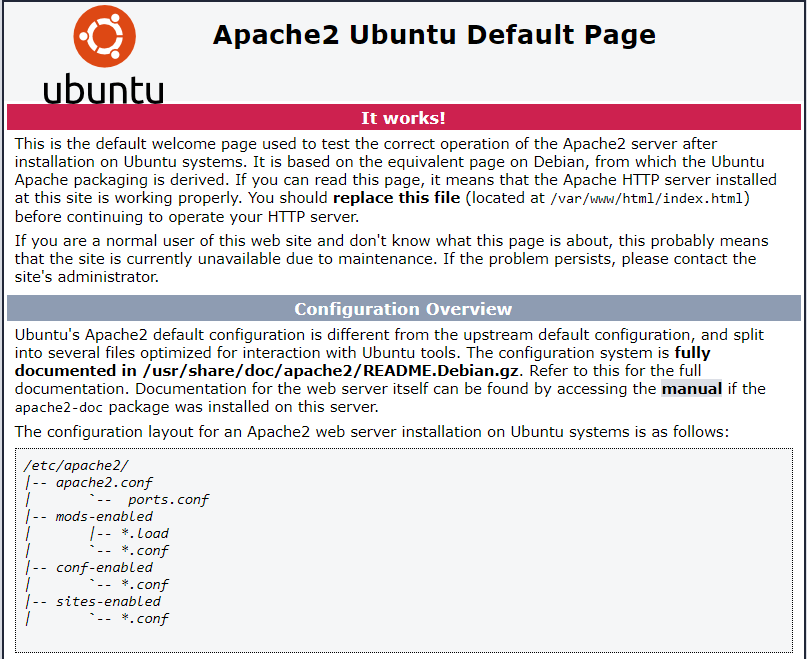
This means that Apache was installed successfully, and that Terraform provisioned everything correctly.
To destroy the deployed resources, run the following command and enter yes when prompted:
- terraform destroy -var "do_token=${DO_PAT}" -var "domain_name=${DO_DOMAIN_NAME}" -var "private_key=${DO_PRIVATE_KEY}"
You have now completed a small Terraform project with a simple structure that deploys the Apache web server on a Droplet and sets up DNS records for the desired domain.
Conclusion
You have learned about two general approaches for structuring your Terraform projects, according to their complexity. Following the simple structuring approach, and using the remote-exec provisioner to execute commands, you then deployed a Droplet running Apache with DNS records for your domain.
For reference, here is the file structure of the project you created in this tutorial:
.
└── tf/
├── versions.tf
├── variables.tf
├── provider.tf
├── droplets.tf
├── dns.tf
├── data-sources.tf
└── external/
└── name-generator.py
The resources you defined (the Droplet, the DNS record and dynamic data source, the DigitalOcean provider and variables) are stored each in its own separate file, according to the simple project structure outlined in the first section of this tutorial.
For more information about Terraform provisioners and their parameters, visit the official documentation.
This tutorial is part of the How To Manage Infrastructure with Terraform series. The series covers a number of Terraform topics, from installing Terraform for the first time to managing complex projects.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: How To Manage Infrastructure with Terraform
Terraform is a popular open source Infrastructure as Code (IAC) tool that automates provisioning of your infrastructure in the cloud and manages the full lifecycle of all deployed resources, which are defined in source code. Its resource-managing behavior is predictable and reproducible, so you can plan the actions in advance and reuse your code configurations for similar infrastructure.
In this series, you will build out examples of Terraform projects to gain an understanding of the IAC approach and how it’s applied in practice to facilitate creating and deploying reusable and scalable infrastructure architectures.
Browse Series: 12 tutorials
About the author(s)
Expert in cloud topics including Kafka, Kubernetes, and Ubuntu.
Former Senior Technical Editor at DigitalOcean, with a strong focus on DevOps and System Administration content. Areas of expertise include Terraform, PyTorch, Python, and Django.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Terraform expects the executed program to write a human-readable error message to stderr and gracefully exit with a non-zero status,
Do you mean stdout ?
Also, creating a droplet with a name based on time, wouldn’t it create a new droplet with each tf plan/apply?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
