By Shubham and Anish Singh Walia

Introduction
 .
.
Scikit-learn is one of the most widely used Python libraries for machine learning. Whether you’re working on classification, regression, or clustering tasks, Scikit-learn provides simple and efficient tools to build and evaluate models.
It features several regression, classification, and clustering algorithms, including SVMs, gradient boosting, k-means, random forests, and DBSCAN. It is designed to work with Python Numpy and SciPy.
What is Scikit-learn in Python?
Scikit Learn is written in Python (most of it), and some of its core algorithms are written in Cython for even better performance. Scikit-learn is used to build models and it is not recommended to use it for reading, manipulating and summarizing data as there are better frameworks available for the purpose. It is open source and released under BSD license.
It provides various tools for:
-
Classification (e.g., Support Vector Machines, Random Forests).
-
Regression (e.g., Linear Regression, Ridge Regression).
-
Clustering (e.g., K-Means, DBSCAN).
-
Dimensionality Reduction (e.g., PCA, LDA).
-
Feature Selection.
Using Scikit Learn
Install Scikit Learn
Scikit assumes you have a running Python 2.7 or above platform with NumPY (1.8.2 and above) and SciPY (0.13.3 and above) packages on your device. Once we have these packages installed we can proceed with the installation. For pip installation, run the following command in the terminal:
pip install scikit-learn
If you like conda, you can also use the conda for package installation, run the following command:
conda install scikit-learn
Using Scikit-Learn
Once you are done with the installation, you can use scikit-learn easily in your Python code by importing it as:
import sklearn
Scikit Learn Loading Dataset
Let’s start with loading a dataset to play with. Let’s load a simple dataset named Iris. It is a dataset of a flower, it contains 150 observations about different measurements of the flower. Let’s see how to load the dataset using scikit-learn.
# Import scikit learn
from sklearn import datasets
# Load data
iris= datasets.load_iris()
# Print shape of data to confirm data is loaded
print(iris.data.shape)
We are printing shape of data for ease, you can also print whole data if you wish so, running the codes gives an output like this: 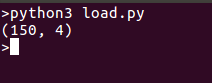
Scikit Learn SVM - Learning and Predicting
Now we have loaded data, let’s try learning from it and predict on new data. For this purpose we have to create an estimator and then call its fit method.
from sklearn import svm
from sklearn import datasets
# Load dataset
iris = datasets.load_iris()
clf = svm.LinearSVC()
# learn from the data
clf.fit(iris.data, iris.target)
# predict for unseen data
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Parameters of model can be changed by using the attributes ending with an underscore
print(clf.coef_ )
Here is what we get when we run this script: 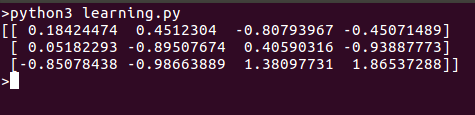
Scikit Learn Linear Regression
Creating various models is rather simple using scikit-learn. Let’s start with a simple example of regression.
#import the model
from sklearn import linear_model
reg = linear_model.LinearRegression()
# use it to fit a data
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Let's look into the fitted data
print(reg.coef_)
Running the model should return a point that can be plotted on the same line: 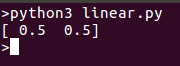
k-Nearest neighbour classifier
Let’s try a simple classification algorithm. This classifier uses an algorithm based on ball trees to represent the training samples.
from sklearn import datasets
# Load dataset
iris = datasets.load_iris()
# Create and fit a nearest-neighbor classifier
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Predict and print the result
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
Let’s run the classifier and check results, the classifier should return 0. Let’s try the example: 
K-means clustering
This is the simplest clustering algorithm. The set is divided into ‘k’ clusters and each observation is assigned to a cluster. This is done iteratively until the clusters converge. We will create one such clustering model in the following program:
from sklearn import cluster, datasets
# load data
iris = datasets.load_iris()
# create clusters for k=3
k=3
k_means = cluster.KMeans(k)
# fit data
k_means.fit(iris.data)
# print results
print( k_means.labels_[::10])
print( iris.target[::10])
On running the program we’ll see separate clusters in the list. Here is the output for above code snippet: 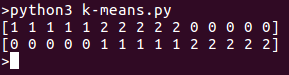 .
.
Scikit-learn vs. TensorFlow vs. PyTorch
| Feature | Scikit-learn | TensorFlow | PyTorch |
|---|---|---|---|
| Use Case | Traditional ML | Deep Learning | Deep Learning |
| Ease of Use | Simple API | Requires tuning | More flexible |
| Performance | Efficient for small datasets | Optimized for large datasets | GPU-accelerated |
| Scalability | Limited for big data | Distributed training | Dynamic computation graphs |
Scikit-learn is ideal for traditional machine learning models, while TensorFlow and PyTorch excel in deep learning and large-scale AI applications.
Handling Large Datasets in Scikit-learn
Scikit-learn is a powerful library for machine learning, but it’s optimized for small to medium-sized datasets. When working with large datasets, you need to handle them efficiently. Here are some strategies:
-
Use
partial_fit(): This method supports incremental learning for large datasets. It’s particularly useful when you can’t fit the entire dataset into memory at once. -
Apply Feature Selection: Reducing the number of features in your dataset can significantly reduce memory usage and computation time.
-
Leverage
joblibfor Parallel Processing: This library can be used to distribute tasks across multiple cores, which can greatly speed up your computations.
Here’s an example of using partial_fit():
from sklearn.linear_model import SGDClassifier
import numpy as np
# Initialize a Stochastic Gradient Descent (SGD) Classifier model
model = SGDClassifier()
# Loop through 10 batches of data
for batch in range(10):
# Generate a batch of random features (X_batch) with shape (1000, 20)
X_batch = np.random.rand(1000, 20)
# Generate a batch of random target values (y_batch) with shape (1000,) containing either 0 or 1
y_batch = np.random.randint(0, 2, 1000)
# Use the partial_fit method to train the model on the current batch of data
# This method is particularly useful for large datasets that cannot fit into memory at once
# The 'classes' parameter is specified to ensure the model is aware of the classes it's training on
model.partial_fit(X_batch, y_batch, classes=[0, 1])
FAQs
1. What is Scikit-learn used for?
Scikit-learn is used for traditional machine learning tasks such as classification, regression, clustering, and feature selection.
2. How does Scikit-learn compare to TensorFlow and PyTorch?
Scikit-learn is better suited for small-scale, traditional machine learning tasks, while TensorFlow and PyTorch are designed for deep learning and large-scale computations.
3. Can Scikit-learn handle deep learning?
No, Scikit-learn is not designed for deep learning. Instead, it integrates well with deep learning libraries when needed.
4. Limitations of Scikit-learn
| Limitation | Description |
|---|---|
| Not designed for deep learning | Scikit-learn is not optimized for deep learning tasks, which are better handled by libraries like TensorFlow and PyTorch. |
| Limited support for GPU acceleration | Scikit-learn does not have native support for GPU acceleration, which can limit its performance on large datasets. |
| Not optimized for big data | Scikit-learn is designed for small to medium-sized datasets and can become inefficient when dealing with very large datasets. |
| Limited support for dynamic computation graphs | Scikit-learn does not support dynamic computation graphs, which are useful for complex models and rapid prototyping. |
5. How do I optimize model performance in Scikit-learn?
Optimizing model performance is crucial to achieve the best results in machine learning. Here are some strategies to optimize model performance in Scikit-learn:
Hyperparameter Tuning: Use GridSearchCV to perform hyperparameter tuning. This involves searching for the best combination of hyperparameters that result in the best model performance.
Feature Selection: Apply feature selection techniques to reduce the dimensionality of your dataset. This can help in reducing overfitting, improving model interpretability, and enhancing model performance.
Ensemble Methods: Utilize ensemble methods like Random Forests and Gradient Boosting. These methods combine the predictions of multiple models to produce a more accurate and robust prediction model.
Conclusion
In this tutorial, you learned about the versatility of Scikit-Learn, which simplifies the implementation of various machine learning algorithms. We have delved into examples of Regression, Classification, and Clustering. Despite being in the development phase and maintained by volunteers, Scikit-Learn is widely popular in the community. We encourage you to experiment with your own examples.
You can also check out these tutorials:
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
Hi,… While installing i am getting the following error rom distutils customize MSVCCompiler Missing compiler_cxx fix for MSVCCompiler customize MSVCCompiler using build_clib building ‘libsvm-skl’ library compiling C sources error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: https://landinghub.visualstudio.com/visual-cpp-build-tools ---------------------------------------- Command “c:\users\sidtrive\appdata\local\programs\python\python37-32\python.exe -u -c “import setuptools, tokenize;__file__=‘C:\\Users\\sidtrive\\AppData\\Local \\Temp\\pip-install-2rnp9ekh\\scikit-learn\\setup.py’;f=getattr(tokenize, ‘open’ , open)(__file__);code=f.read().replace(‘\r\n’, ‘\n’);f.close();exec(compile(cod e, __file__, ‘exec’))” install --record C:\Users\sidtrive\AppData\Local\Temp\pip -record-g6eq9i3m\install-record.txt --single-version-externally-managed --compil e” failed with error code 1 in C:\Users\sidtrive\AppData\Local\Temp\pip-install- 2rnp9ekh\scikit-learn\
- Sid
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
