By Mark Drake
Manager, Developer Education

Einführung
Datenbankmanagementsysteme (DBMS) sind Computerprogramme, mit denen Benutzer mit einer Datenbank interagieren können. Ein DBMS ermöglicht es Benutzern, den Zugriff auf eine Datenbank zu steuern, Daten zu schreiben, Abfragen auszuführen und andere Aufgaben im Zusammenhang mit der Datenbankverwaltung durchzuführen.
Um eine dieser Aufgaben auszuführen, muss das DBMS jedoch eine Art zugrunde liegendes Modell haben, das definiert, wie die Daten organisiert sind. Das relationale Modell ist ein Ansatz zur Organisation von Daten, der in der Datenbanksoftware seit seiner Entwicklung in den späten 60er Jahren breite Verwendung gefunden hat, sodass zum Zeitpunkt der Erstellung dieses Artikels vier der fünf beliebtesten DBMS relational sind.
Dieser konzeptionelle Artikel skiziert die Geschichte des relationalen Modells, wie relationale Datenbanken Daten organisieren und wie sie heute verwendet werden.
Geschichte des relationalen Modells
Datenbanken sind logisch modellierte Cluster von Informationen oder Daten. Jede Sammlung von Daten ist eine Datenbank, unabhängig davon, wie oder wo sie gespeichert ist. Sogar ein Aktenschrank mit Lohn- und Gehaltsabrechnungsinformationen ist eine Datenbank, ebenso wie ein Stapel von Krankenhauspatientenformularen oder die Sammlung von Kundeninformationen eines Unternehmens, die über mehrere Standorte verteilt sind. Bevor die Speicherung und Verwaltung von Daten mit Computern gängige Praxis war, waren physische Datenbanken wie diese die einzigen Datenbanken, die Behörden und Unternehmen zur Speicherung von Informationen zur Verfügung standen.
Um die Mitte des 20. Jahrhunderts führten Entwicklungen in der Informatik zu Computern mit mehr Verarbeitungsleistung sowie größerer lokaler und externer Speicherkapazität. Diese Fortschritte führten dazu, dass Computerwissenschaftler begannen, das Potenzial für die Speicherung und Verwaltung immer größerer Datenmengen zu erkennen.
Es gab jedoch keine Theorien darüber, wie Computer Daten auf sinnvolle, logische Weise organisieren können. Es ist eine Sache, unsortierte Daten auf einem Computer zu speichern, aber es ist viel komplizierter, Systeme zu entwerfen, die es erlauben, diese Daten auf konsistente, praktische Weise hinzuzufügen, abzurufen, zu sortieren und anderweitig zu verwalten. Der Bedarf an einem logischen Rahmen zur Speicherung und Organisation von Daten führte zu einer Reihe von Vorschlägen, wie Computer für die Datenverwaltung nutzbar gemacht werden können.
Ein frühes Datenbankmodell war das hierarchische Modell, bei dem die Daten in einer baumartigen Struktur organisiert sind, ähnlich wie bei modernen Dateisystemen. Das folgende Beispiel zeigt, wie das Layout eines Teils einer hierarchischen Datenbank zur Kategorisierung von Tieren aussehen könnte:
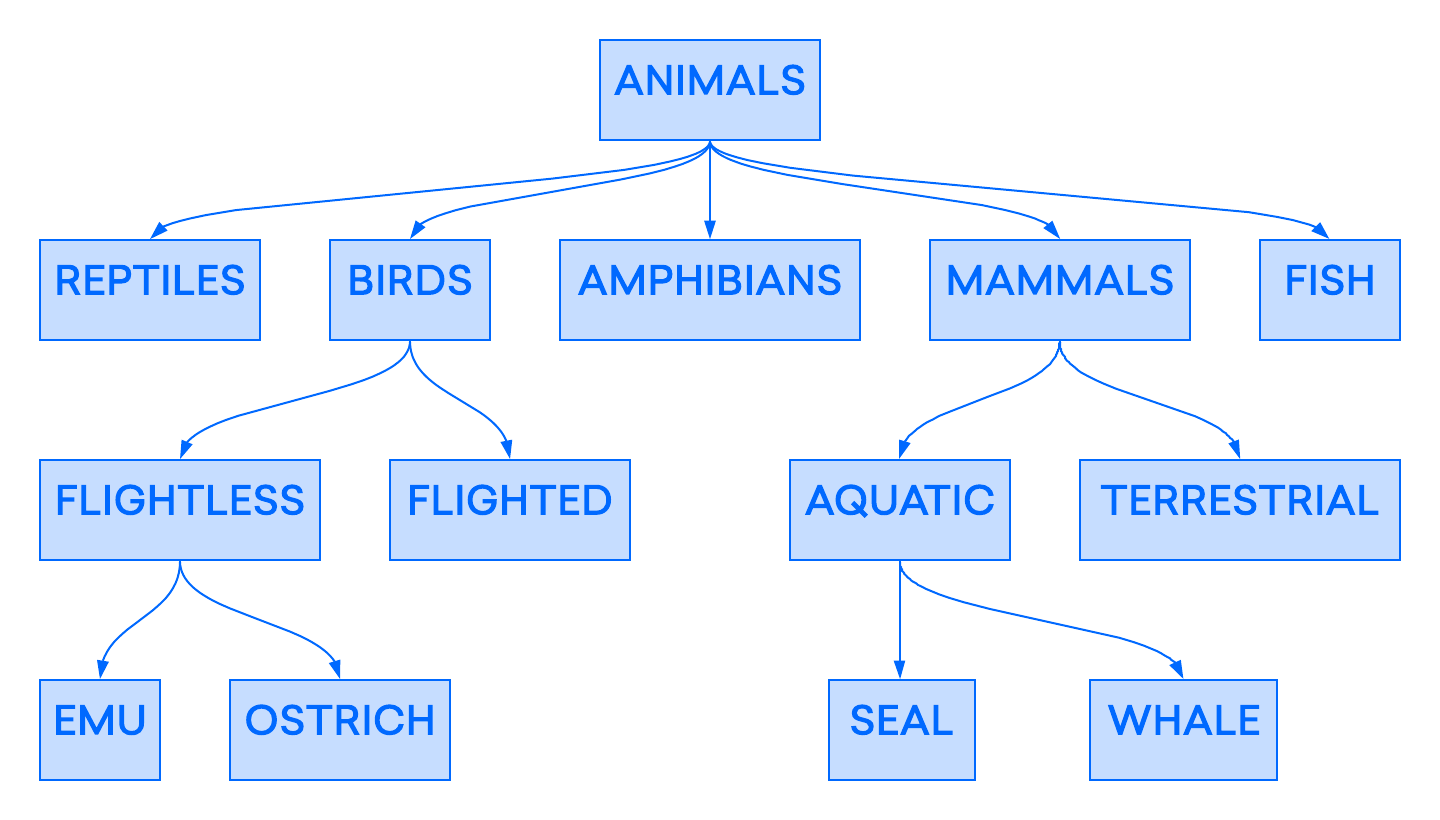
Das hierarchische Modell wurde in den frühen Datenbankmanagementsystemen verbreitet eingesetzt, erwies sich aber auch als etwas unflexible. Obwohl in diesem Modell einzelne Datensätze mehrere „untergeordnete Datensätze“ haben können, kann jeder Datensatz nur einen „übergeordneten“ Datensatz in der Hierarchie haben. Aus diesem Grund waren diese früheren hierarchischen Datenbanken darauf beschränkt, nur „Eins-zu-Eins“ und „Eins-zu-Viele“-Beziehungen darzustellen. Dieser Mangel an „Viele-zu-Viele“-Beziehungen könnte zu Problemen führen, wenn Sie mit Datenpunkten arbeiten, die Sie mit mehr als einem übergeordneten Datensatz verknüpfen möchten.
In den späten 1960er Jahren entwickelte Edgar F. Codd, ein Informatiker, der bei IBM arbeitete, das relationale Modell der Datenbankverwaltung. Das relationale Modell von Codd ermöglichte es, einzelne Datensätze mit mehr als einer Tabelle zu verknüpfen, wodurch zusätzlich zu den „Eins-zu-Viele“-Beziehungen auch „Viele-zu-Viele“-Beziehungen zwischen Datenpunkten möglich wurden. Dies bot mehr Flexibilität als andere existierende Modelle, wenn es um die Gestaltung von Datenbankstrukturen ging, und bedeutetet, dass relationale Datenbankmanagementsysteme (RDBMS) ein wesentlich breiteres Spektrum von Geschäftsanforderungen erfüllen können.
Codd schlug eine Sprache zur Verwaltung relationaler Daten vor, bekannt als Alpha, die die Entwicklung späterer Datenbanksprachen beeinflusste. Zwei Kollegen von Codd bei IBM, Donald Chamberlin und Raymond Boyce, schufen eine solche Sprache, die von Alpha inspiriert ist. Sie nannten ihre Sprache SEQUEL, kurz für Structured English Query Language, aber aufgrund eines bestehenden Warenzeichens kürzten sie den Namen ihrer Sprache auf SQL (formal eher als Structured Query Language bezeichnet).
Aufgrund von Hardware-Beschränkungen waren die frühen relationalen Datenbanken noch ungemein langsam, und es dauerte einige Zeit, bis die Technologie weit verbreitet war. Aber Mitte der 1980er Jahre war das relationale Modell von Codd bereits in einer Reihe kommerzieller Datenbankmanagementprodukte sowohl von IBM als auch seinen Konkurrenten implementiert worden. Diese Anbieter folgten ebenfalls dem IBM-Vorbild, indem sie ihre eigenen Dialekte von SQL entwickelten und implementierten. Bis 1987 hatten sowohl das American Standards Institute als auch die International Organization for Standardization Standards für SQL ratifiziert und veröffentlicht und damit den Status von SQL als akzeptierte Sprache für die Verwaltung von RDBMS gefestigt.
Die weite Verwendung des relationalen Modells in mehreren Branchen führte dazu, dass es als Standardmodell für das Datenmanagement anerkannt wurde. Selbst mit dem Aufkommen verschiedener NoSQL-Datenbanken in den letzten Jahren bleiben relationale Datenbanken die dominierenden Werkzeuge zur Speicherung und Organisation von Daten.
Wie relationale Datenbanken Daten organisieren
Nachdem Sie nun ein allgemeines Verständnis für die Geschichte des relationalen Modells haben, lassen Sie uns einen genaueren Blick darauf werfen, wie das Modell Daten organisiert.
Die grundlegendsten Elemente des relationalen Modells sind Beziehungen, die von Benutzern und modernen RDBMS als Tabellen erkannt werden. Eine Beziehung ist ein Satz von Tupeln oder Zeilen in einer Tabelle, wobei jedes Tupel einen Satz von Attributen oder Spalten gemeinsam hat:
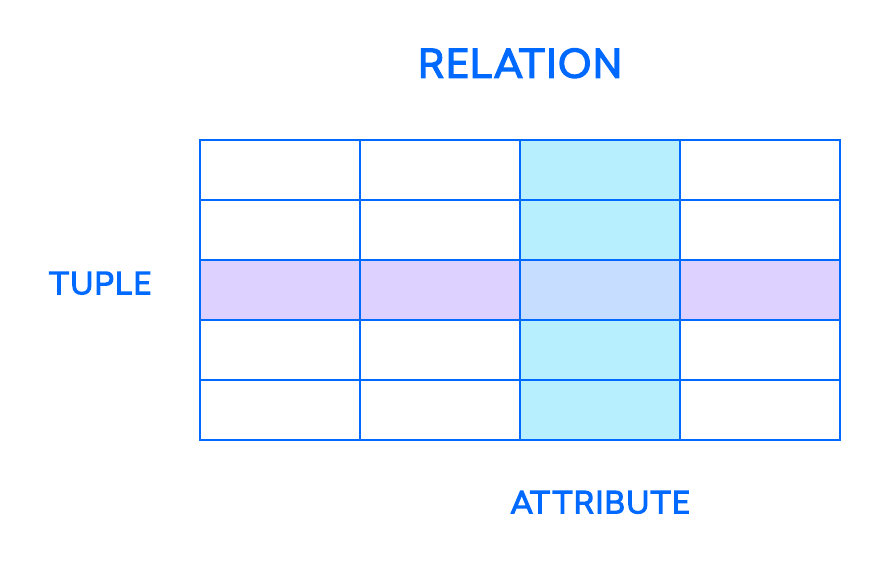
Eine Spalte ist die kleinste Organisationsstruktur einer relationalen Datenbank und stellt die verschiedenen Facetten dar, die die Datensätze in der Tabelle definieren. Daher ihr formellerer Name, Attribute. Sie können sich jedes Tupel als eine einzigartige Instanz jeder Art von Personen, Objekten, Ereignissen oder Assoziationen vorstellen, die die Tabelle enthält. Diese Instanzen können z. B. Mitarbeiter eines Unternehmens, Verkäufe aus einem Online-Geschäft oder Labor-Testergebnisse sein. In einer Tabelle, die beispielsweise Mitarbeiterdaten von Lehrern an einer Schule enthält, können die Tupel Attribute wie name, subjects, start_date usw. haben.
Bei der Erstellung von Spalten geben Sie einen Datentyp an, der festlegt, welche Art von Einträge in dieser Spalte zulässig sind. RDBMS implementieren oft ihre eigenen eindeutigen Datentypen, die möglicherweise nicht direkt mit ähnlichen Datentypen in anderen Systemen austauschbar sind. Einige gängige Datentypen umfassen Datumsangaben, Zeichenketten, Ganzzahlen und Boolesche.
Im relationalen Modell enthält jede Tabelle mindestens eine Spalte, die zur eindeutigen Identifizierung jeder Zeile verwendet werden kann, was als Primärschlüssel bezeichnet wird. Dies ist wichtig, da es bedeutet, dass Benutzer nicht wissen müssen, wo ihre Daten physisch auf einem Computer gespeichert sind; stattdessen können ihre DBMS jeden Datensatz verfolgen und ad hoc zurückgeben. Dies wiederum bedeutet, dass die Datensätze keine definierte logische Reihenfolge haben und die Benutzer die Möglichkeit haben, ihre Daten in beliebiger Reihenfolge oder durch beliebige Filter zurückgeben.
Wenn Sie zwei Tabellen haben, die Sie miteinander verknüpfen möchten, können Sie dies unter anderem mit einem Fremdschlüssel tun. Ein Fremdschlüssel ist im Wesentlichen eine Kopie des Primärschlüssels einer Tabelle (der „übergeordneten“ Tabelle), der in eine Spalte einer anderen Tabelle (der „untergeordneten“ Tabelle) eingefügt wird. Das folgende Beispiel verdeutlicht die Beziehung zwischen zwei Tabellen, von denen die eine zur Aufzeichnung von Informationen über die Mitarbeiter eines Unternehmens und die andere zur Verfolgung der Verkäufe des Unternehmens verwendet wird. In diesem Beispiel wird der Primärschlüssel der Tabelle EMPLOYEES als Fremdschlüssel der Tabelle SALES verwendet:
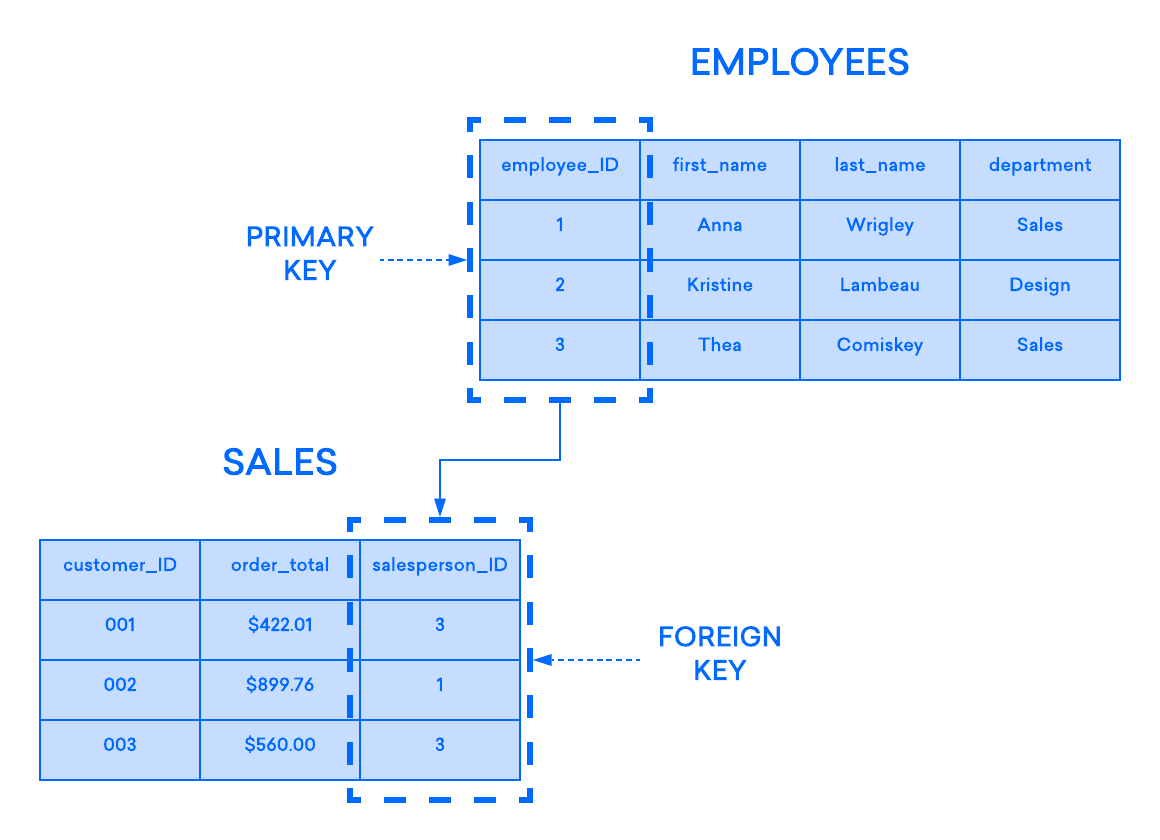
Wenn Sie versuchen, der untergeordneten Tabelle einen Datensatz hinzuzufügen, und der in die Fremdschlüsselspalte eingegebene Wert im Primärschlüssel der übergeordneten Tabelle nicht existiert, ist die Einfügeanweisung ungültig. Dies hilft, die Integrität der Beziehungsebene aufrechtzuerhalten, da die Zeilen in beiden Tabellen immer korrekt zueinander in Beziehung stehen werden.
Die Strukturelemente des relationalen Modells tragen dazu bei, die Daten auf organisierte Weise zu speichern, aber die Speicherung von Daten ist nur dann sinnvoll, wenn Sie diese auch abrufen können. Um Informationen aus einem RDBMS abzurufen, können Sie eine *Abfrage *oder eine strukturierte Anfrage nach einem Satz von Informationen stellen. Wie zuvor erwähnt, verwenden die meisten relationalen Datenbanken SQL zur Verwaltung und Abfrage von Daten. SQL ermöglicht es Ihnen, Abfrageergebnisse mit einer Vielzahl von Klauseln, Prädikaten und Ausdrücken zu filtern und zu manipulieren, wodurch Sie eine genaue Kontrolle darüber erhalten, welche Daten im Ergebnissatz angezeigt werden.
Vorteile und Grenzen relationaler Datenbanken
Lassen Sie uns mit Blick auf die zugrunde liegende Organisationsstruktur relationaler Datenbanken einige ihrer Vor- und Nachteile betrachten.
Heute weichen sowohl SQL als auch die Datenbanken, die es implementieren, in mehrfacher Hinsicht von Codds relationalem Modell ab. Beispielsweise schreibt das Modell von Codd vor, dass jede Zeile in einer Tabelle eindeutig sein sollte, während die meisten modernen relationalen Datenbanken aus Gründen der Praktikabilität duplizierte Zeilen zulassen. Es gibt einige, die SQL-Datenbanken nicht als echte relationale Datenbanken betrachten, wenn sich nicht an jede von Codds Spezifikationen für das relationale Modell halten. In der Praxis wird jedoch jedes DBMS, das SQL verwendet und sich zumindest teilweise an das relationale Modell hält, als relationales Datenbankmanagementsystem bezeichnet.
Obwohl relationale Datenbanken schnell an Popularität gewannen, wurden einige Unzulänglichkeiten des relationalen Modells offensichtlich, als Daten immer wertvoller wurden und Unternehmen begannen, mehr davon zu speichern. Zum einen kann es schwierig sein, eine relationale Datenbank horizontal zu skalieren. Horizontale Skalierung oder Herausskalieren ist die Praxis des Hinzufügens weiterer Computer zu einem bestehenden Stack, um die Last zu verteilen und mehr Datenverkehr und eine schnellere Verarbeitung zu ermöglichen. Dies steht oft im Gegensatz zur vertikalen Skalierung, bei der die Hardware eines vorhandenen Servers aufgerüstet wird, in der Regel durch Hinzufügen von mehr RAM oder CPU.
Der Grund dafür, dass die horizontale Skalierung einer relationalen Datenbank schwierig ist, hängt damit zusammen, dass das relationale Modell auf Konsistenz ausgelegt ist, d, h. Clients, die dieselbe Datenbank abfragen, werden immer dieselben Daten abrufen. Wenn Sie eine relationale Datenbank horizontal über mehrere Computer skalieren, wird es schwierig, die Konsistenz zu gewährleisten, da Clients Daten auf einen Knoten Schreiben können, aber nicht auf die anderen. Es gäbe wahrscheinlich eine Verzögerung zwischen dem anfänglichen Schreiben und dem Zeitpunkt, zu dem die anderen Knoten aktualisiert werden, um die Änderungen widerspiegeln, was zu Inkonsistenzen zwischen ihnen führen würde.
Eine weitere Einschränkung bei RDBMS besteht darin, dass das relationale Modell für die Verwaltung strukturierter Daten oder von Daten konzipiert wurde, die mit einem vordefinierten Datentyp übereinstimmen oder zumindest auf eine vorher festgelegte Weise organisiert sind, sodass sie leicht sortierbar und durchsuchbar sind. Mit der Verbreitung von Personal Computing und dem Aufkommen des Internets in den frühen 1990er Jahren wurden jedoch unstrukturierte Daten – wie E-Mail-Nachrichten, Fotos, Videos usw. – immer üblicher.
All dies bedeutet nicht, dass relationale Datenbanken nicht nützlich sind. Ganz im Gegenteil, das relationale Modell ist auch nach über 40 Jahren noch immer der dominierende Rahmen für das Datenmanagement. Ihre Verbreitung und Langlebigkeit bedeuten, das relationale Datenbanken eine ausgereifte Technologie darstellen, was wiederum einer ihrer wichtigsten Vorteile ist. Es gibt viele Anwendungen, die für die Arbeit mit dem relationalen Modell konzipiert wurden, sowie viele Datenbankadministratoren, die in ihrer Laufbahn Experten auf dem Gebiet der relationalen Datenbanken sind. Für diejenigen, die mit relationalen Datenbanken beginnen möchten, gibt es ein breites Angebot an Ressourcen, in gedruckter Form und online.
Ein weiterer Vorteil relationaler Datenbanken besteht darin, dass fast jedes RDBMS Transaktionen unterstützt. Eine Transaktion besteht aus einer oder mehreren einzelnen SQL-Anweisungen, die nacheinander als eine einzige Arbeitseinheit ausgeführt werden. Transaktionen stellen einen Alles-oder-Nichts-Ansatz dar, was bedeutet, dass jede SQL-Anweisung in der Transaktion gültig sein muss, da ansonsten die gesamte Transaktion fehlschlägt. Dies ist sehr hilfreich, um die Datenintegrität zu gewährleisten, wenn Änderungen an mehreren Zeilen oder Tabellen vorgenommen werden.
Und schließlich sind relationale Datenbanken äußerst flexibel. Sie wurden zum Aufbau einer Vielzahl unterschiedlicher Anwendungen verwendet und arbeiten auch bei sehr großen Datenmengen weiterhin effizient. SQL ist ebenfalls extrem leistungsfähig, sodass Sie im Handumdrehen Daten hinzufügen und ändern sowie die Struktur von Datenbankschemata und Tabellen ändern können, ohne die vorhandenen Daten zu beeinträchtigen.
Zusammenfassung
Dank ihrer Flexibilität und ihres Designs für Datenintegrität sind relationale Datenbanken auch mehr als fünfzig Jahre nach ihrer ersten Konzeption immer noch die wichtigste Art und Weise, wie Daten verwaltet und gespeichert werden. Selbst mit dem Aufkommen verschiedener NoSQL-Datenbanken in den letzten Jahren sind das Verständnis des relationalen Modells und die Arbeit mit RDBMS der Schlüssel für jeden, der Anwendungen entwickeln möchte, die die Datenleistung nutzen.
Um mehr über einige beliebte Open-Source-RDBMS zu erfahren, empfehlen wir Ihnen, sich unseren Vergleich verschiedener relationaler Open-Source-Datenbanken anzusehen. Wenn Sie mehr über Datenbanken im Allgemeinen erfahren möchten, empfehlen wir Ihnen, einen Blick in unsere vollständige Bibliothek datenbankbezogener Inhalte zu werfen.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
