By Mark Drake
Manager, Developer Education

Introducción
Los sistemas de administración de bases de datos (DBMS) son programas que permiten a los usuarios interactuar con una base de datos. Les permiten controlar el acceso a una base de datos, escribir datos, ejecutar consultas y realizar otras tareas relacionadas con la administración de bases de datos.
Sin embargo, para realizar cualquiera de estas tareas, los DBMS deben tener algún tipo de modelo subyacente que defina la organización de los datos. El modelo relacional es un enfoque para la organización de datos que se ha utilizado ampliamente en programas de software de bases de datos desde su concepción a fines de la década de 1960; a tal grado que, a la fecha de redacción de este artículo, cuatro de los cinco DBMS más populares son relacionales.
Este artículo conceptual describe la historia del modelo relacional, la manera en que se organizan los datos en las bases de datos relacionales y cómo se utilizan hoy en día.
Historia del modelo relacional
Las bases de datos son conjuntos de información, o datos, modelados de forma lógica. Cualquier recopilación de datos es una base de datos, independientemente de cómo o dónde se almacene. Incluso un gabinete de archivos con información sobre nómina es una base de datos, al igual que una pila de formularios de pacientes hospitalizados o la recopilación de información sobre clientes de una empresa repartida en varias ubicaciones. Antes de que almacenar y administrar datos con computadoras se convirtiera en una práctica común, las bases de datos físicas como estas eran lo único con lo que contaban las organizaciones gubernamentales y empresariales que necesitaban almacenar información.
A mediados del siglo XX, los desarrollos en las ciencias de la computación dieron lugar a máquinas con mayor capacidad de procesamiento y almacenamiento, tanto local como externo. Estos avances hicieron que los especialistas en ciencias de la computación comenzaran a reconocer el potencial que tenían estas máquinas para almacenar y administrar cantidades de datos cada vez más grandes.
Sin embargo, no había teorías sobre cómo las computadoras podían organizar datos de manera significativa y lógica. Una cosa es almacenar datos no ordenados en una máquina, pero es mucho más complicado diseñar sistemas que permitan agregar, recuperar, clasificar y administrar esos datos de forma sistemática y práctica. La necesidad de contar con un marco de trabajo lógico para almacenar y organizar datos dio lugar a varias propuestas sobre cómo utilizar las computadoras para administrar datos.
Uno de los primeros modelos de bases de datos fue el modelo jerárquico, en el que los datos se organizan con una estructura de árbol similar a la de los sistemas de archivos modernos. El siguiente ejemplo muestra el aspecto que podría tener el diseño de una parte de una base de datos jerárquica utilizada para categorizar animales:
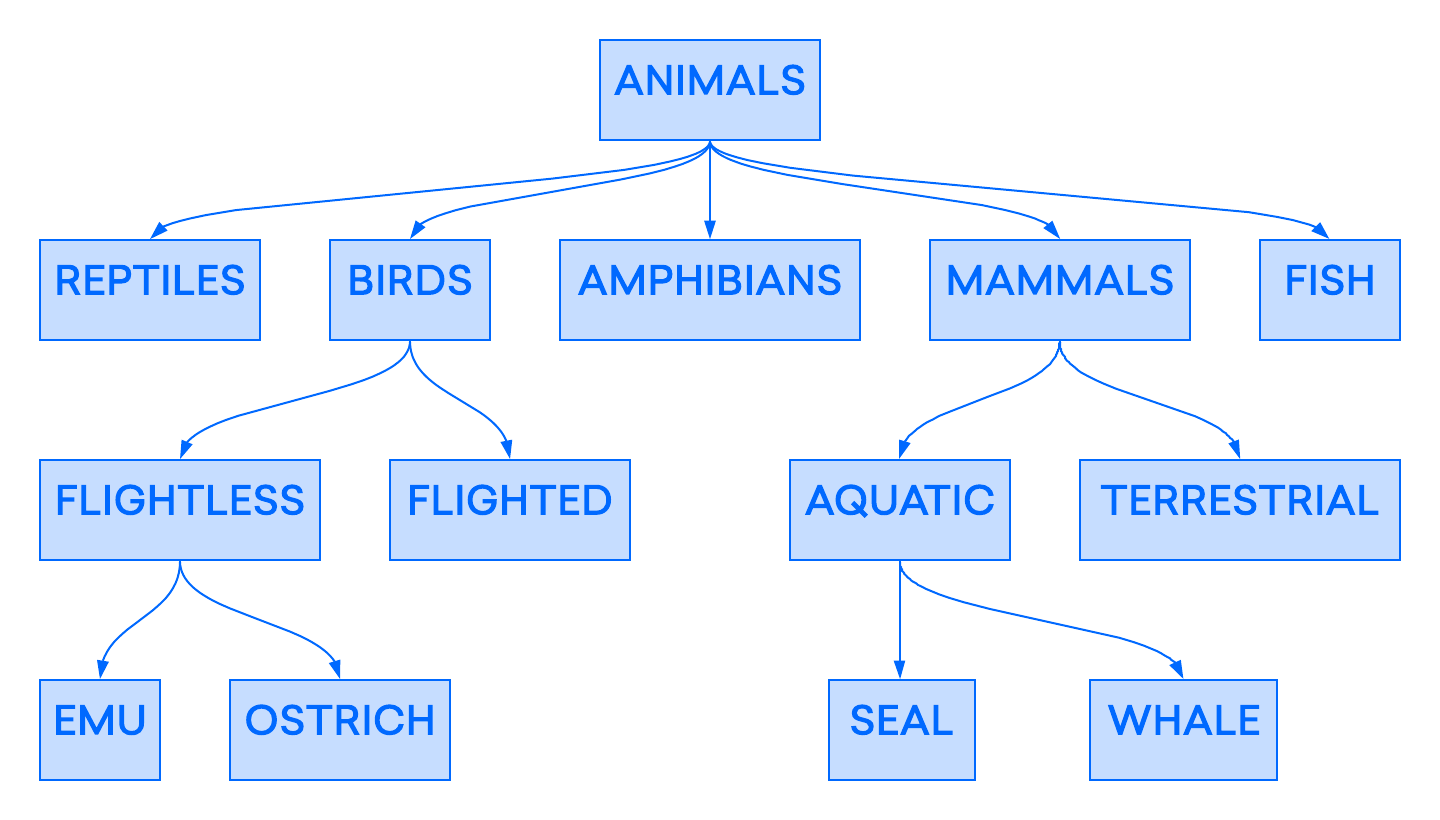
El modelo jerárquico se implementó ampliamente en los primeros sistemas de administración de bases de datos, pero resultaba poco flexible. En este modelo, a pesar de que los registros individuales pueden tener varios “elementos secundarios”, cada uno puede tener un solo “elemento primario” en la jerarquía. Es por eso que estas primeras bases de datos jerárquicas se limitaban a representar relaciones “uno a uno” y “uno a varios”. Esta carencia de relaciones “varios a varios” podía provocar problemas al trabajar con puntos de datos que se deseaba asociar a más de un elemento primario.
A fines de los años 60, Edgar F. Codd, un especialista en ciencias de la computación que trabajaba en IBM, diseñó el modelo relacional de administración de bases de datos. El modelo relacional de Codd permitía que los registros individuales se relacionaran con más de una tabla y, de esta manera, posibilitaba las relaciones “varios a varios” entre los puntos de datos además de las relaciones “uno a varios”. Esto proporcionó más flexibilidad que los demás modelos existentes a la hora de diseñar estructuras de base de datos y permitió que los sistemas de gestión de bases de datos relacionales (RDBMS) pudieran satisfacer una gama mucho más amplia de necesidades empresariales.
Codd propuso un lenguaje para la administración de datos relacionales, conocido como Alfa, que influyó en el desarrollo de los lenguajes de bases de datos posteriores. Dos colegas de Codd en IBM, Donald Chamberlin y Raymond Boyce, crearon un lenguaje similar inspirado en Alpha. Lo llamaron SEQUEL, abreviatura de Structured English Query Language (Lenguaje de consulta estructurado en inglés), pero debido a una marca comercial existente, lo abreviaron a SQL (conocido formalmente como* Lenguaje de consulta estructurado*).
Debido a las limitaciones de hardware, las primeras bases de datos relacionales eran prohibitivamente lentas y el uso de la tecnología tardó un tiempo en generalizarse. Pero a mediados de los años ochenta, el modelo relacional de Codd se había implementado en varios productos comerciales de administración de bases de datos, tanto de IBM como de sus competidores. Estos proveedores también siguieron el liderazgo de IBM al desarrollar e implementar sus propios dialectos de SQL. Para 1987, tanto el Instituto Nacional Estadounidense de Estándares (American National Standards Institute) como la Organización Internacional de Normalización (International Organization for Standardization) habían ratificado y publicado normas para SQL, lo que consolidó su estado como el lenguaje aceptado para la administración de RDBMS.
Gracias al uso extendido del modelo relacional en varias industrias, se lo comenzó a reconocer como el modelo estándar para la administración de datos. Incluso con el surgimiento de varias bases de datos NoSQL en los últimos años, las bases de datos relacionales siguen siendo las herramientas predominantes para almacenar y organizar datos.
Cómo organizan los datos las bases de datos relacionales
Ahora que tiene una idea general de la historia del modelo relacional, vamos a analizar en detalle cómo organiza los datos.
Los elementos más fundamentales del modelo relacional son las relaciones, que los usuarios y los RDBMS modernos reconocen como tablas. Una relación es un conjunto de tuplas, o filas de una tabla, en el que cada una de ellas comparte un conjunto de atributos o columnas:
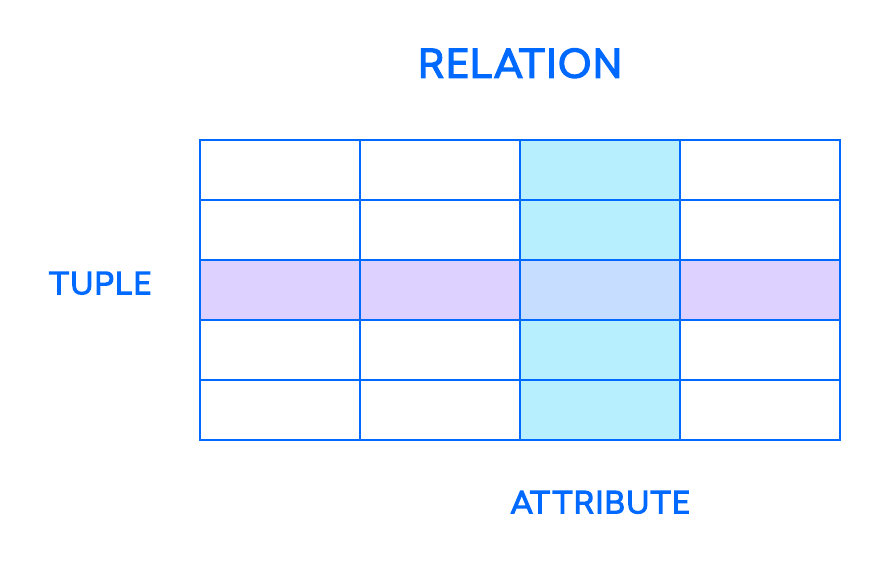
Una columna es la estructura de organización más pequeña de una base de datos relacional y representa las distintas facetas que definen los registros en la tabla. De ahí proviene su nombre más formal: atributos. Se puede pensar que cada tupla es como una instancia única de cualquier tipo de personas, objetos, eventos o asociaciones que contenga la tabla. Estas instancias pueden ser desde empleados de una empresa y ventas de un negocio en línea hasta resultados de pruebas de laboratorio. Por ejemplo, en una tabla que contiene registros de los maestros de una escuela, las tuplas pueden tener atributos como name, subjects, start_date, etc.
Al crear una columna, especificamos un* tipo de datos *que determina el tipo de entradas que se permiten en esa columna. Los sistemas de administración de bases de datos relacionales (RDBMS) suelen implementar sus propios tipos de datos únicos, que pueden no ser directamente intercambiables con tipos de datos similares de otros sistemas. Algunos tipos de datos frecuentes son fechas, cadenas, enteros y booleanos.
En el modelo relacional, cada tabla contiene, por lo menos, una columna que puede utilizarse para identificar de forma única cada fila, lo que se denomina clave primaria. Esto es importante, dado que significa que los usuarios no necesitan saber dónde se almacenan físicamente los datos en una máquina; en su lugar, sus DBMS pueden realizar un seguimiento de cada registro y devolverlo según corresponda. A su vez, significa que los registros no tienen un orden lógico definido y que los usuarios tienen la capacidad de devolver sus datos en cualquier orden y a través de los filtros que deseen.
Si tiene dos tablas que desea asociar, una manera de hacerlo es con una clave externa. Una clave externa es, básicamente, una copia de la clave primaria de una tabla (la tabla “primaria”) insertada en una columna de otra tabla (la “secundaria”). El siguiente ejemplo destaca la relación entre dos tablas: una se utiliza para registrar información sobre los empleados de una empresa y la otra, para realizar un seguimiento de las ventas de la empresa. En este ejemplo, la clave primaria de la tabla EMPLOYEES se utiliza como clave externa de la tabla SALES:
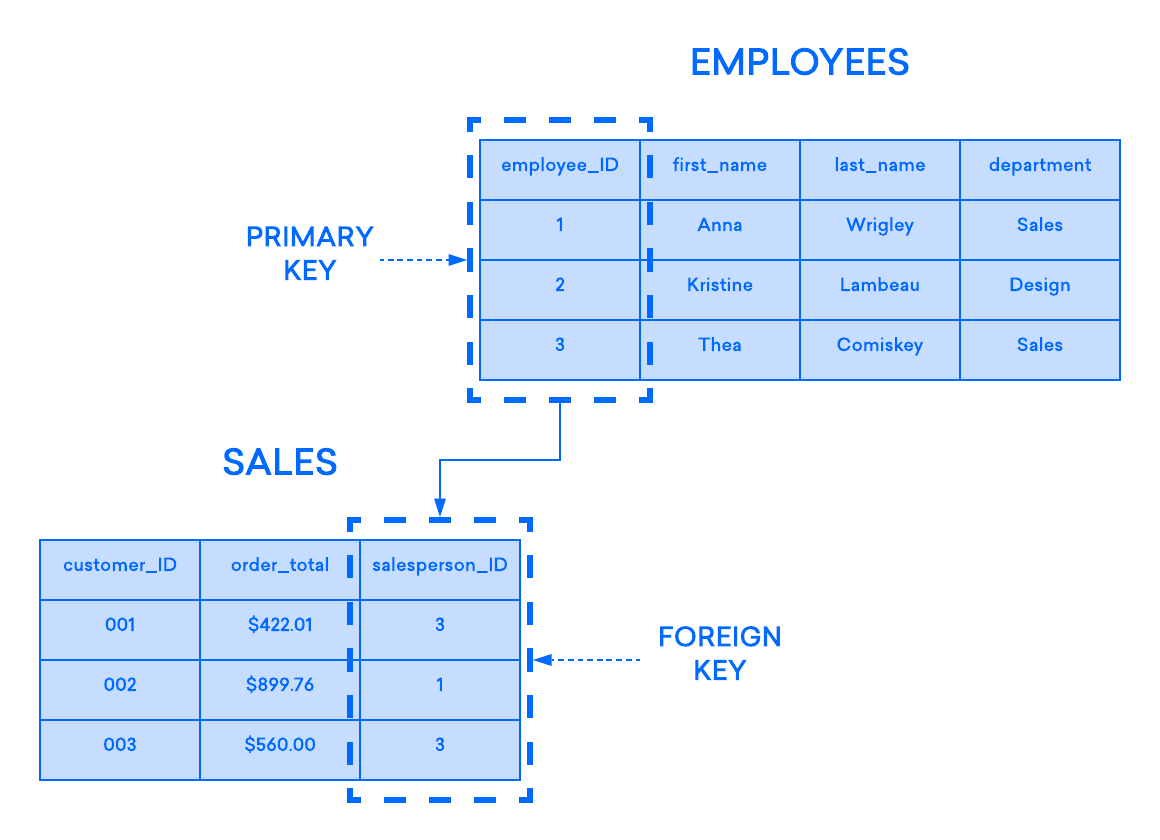
Si intenta agregar un registro a la tabla secundaria y el valor ingresado en la columna de la clave externa no existe en la clave primaria de la tabla primaria, la instrucción de inserción no será válida. Esto ayuda a mantener la integridad del nivel de las relaciones, dado que las filas de ambas tablas siempre se relacionarán correctamente.
Los elementos estructurales del modelo relacional ayudan a mantener los datos almacenados de forma organizada, pero el almacenamiento de datos solo es útil si se pueden recuperar. Para obtener información de un RDBMS, puede emitir una consulta o una solicitud estructurada de un conjunto de información. Como se mencionó anteriormente, la mayoría de las bases de datos relacionales utilizan SQL para administrar y consultar datos. SQL permite filtrar y manipular los resultados de las consultas con una variedad de cláusulas, predicados y expresiones, lo que, a su vez, permite controlar correctamente qué datos se mostrarán en el conjunto de resultados.
Ventajas y limitaciones de las bases de datos relacionales
Teniendo en cuenta la estructura organizativa subyacente de las bases de datos relacionales, consideremos algunas de sus ventajas y desventajas.
Hoy en día, tanto SQL como las bases de datos que lo implementan se desvían del modelo relacional de Codd de diversas maneras. Por ejemplo, el modelo de Codd determina que cada fila de una tabla debe ser única, mientras que, por cuestiones de practicidad, la mayoría de las bases de datos relacionales modernas permiten la duplicación de filas. Algunas personas no consideran que las bases de datos SQL sean verdaderas bases de datos relacionales a menos que cumplan con las especificaciones de Codd del modelo relacional. Sin embargo, en términos prácticos, es probable que cualquier DBMS que utilice SQL y, por lo menos, se adhiera en cierta medida al modelo relacional se denomine “sistema de administración de bases de datos relacionales”.
A pesar de que las bases de datos relacionales ganaron popularidad rápidamente, algunas de las deficiencias del modelo relacional comenzaron a hacerse evidentes a medida que los datos se volvieron más valiosos y las empresas comenzaron a almacenar más de ellos. Entre otras cosas, puede ser difícil escalar una base de datos relacional de forma horizontal. Los términos escalado horizontal o escala horizontal se refieren a la práctica de agregar más máquinas a una pila existente para extender la carga y permitir un mayor tráfico y un procesamiento más rápido. Se suele contrastar con el escalado vertical, que implica la actualización del hardware de un servidor existente, generalmente, añadiendo más RAM o CPU.
El motivo por el cual es difícil escalar una base de datos relacional de forma horizontal está relacionado con el hecho de que el modelo relacional se diseñó para garantizar coherencia, lo que significa que los clientes que realizan consultas en la misma base de datos siempre obtendrán los mismos datos. Al querer escalar una base de datos relacional de forma horizontal en varias máquinas, resulta difícil asegurar la coherencia, dado que los clientes pueden escribir datos en un nodo pero no en otros. Es probable que haya un retraso entre la escritura inicial y el momento en que se actualicen los demás nodos para reflejar los cambios, lo que daría lugar a inconsistencias entre ellos.
Otra limitación que presentan los RDBMS es que el modelo relacional se diseñó para administrar datos estructurados o alineados con un tipo de datos predeterminado o, por lo menos, organizado de una manera predeterminada para que se puedan ordenar o buscar de forma más sencilla. Sin embargo, con la difusión de los equipos informáticos personales y el auge de Internet a principios de la década de 1990, los datos no estructurados, como los mensajes de correo electrónico, las fotos, los videos, etc., se volvieron más comunes.
Nada de esto significa que las bases de datos relacionales no sean útiles. Al contrario, después de más de 40 años, el modelo relacional sigue siendo el marco dominante para la administración de datos. Su prevalencia y longevidad indican que las bases de datos relacionales son una tecnología madura, lo que constituye una de sus principales ventajas. Hay muchas aplicaciones diseñadas para trabajar con el modelo relacional, así como muchos administradores de bases de datos profesionales expertos en bases de datos relacionales. También hay una amplia variedad de recursos disponibles en formato impreso y digital para quienes desean comenzar a utilizar bases de datos relacionales.
Otra ventaja de las bases de datos relacionales es que casi todos los RDBMS admiten transacciones. Las transacciones constan de una o más instrucciones SQL individuales que se ejecutan en secuencia como una unidad de trabajo única. Las transacciones tienen un enfoque de todo o nada, lo que significa que todas las instrucciones SQL de una transacción deben ser válidas; de lo contrario, falla en su totalidad. Esto es muy útil para garantizar la integridad de los datos al realizar cambios en varias filas o tablas.
Por último, las bases de datos relacionales son sumamente flexibles. Se han utilizado para crear una amplia variedad de aplicaciones distintas y siguen funcionando de forma eficiente incluso con grandes cantidades de datos. SQL también es sumamente potente y permite agregar y cambiar datos sobre la marcha, así como alterar la estructura de los esquemas y las tablas de las bases de datos sin afectar a los datos existentes.
Conclusión
Gracias a su flexibilidad y diseño para la integridad de los datos, más de cincuenta años después de su concepción inicial, las bases de datos relacionales siguen siendo la principal forma de administrar y almacenar datos. A pesar del surgimiento de diversas bases de datos NoSQL en los últimos años, la comprensión del modelo relacional y la manera de trabajar con RDBMS es fundamental para cualquier persona que desee crear aplicaciones que aprovechen el poder de los datos.
Para obtener más información sobre RDBMS populares de código abierto, le recomendamos consultar nuestra comparación de diversas bases de datos relacionales SQL de código abierto. Si desea obtener más información sobre las bases de datos en general, le recomendamos consultar nuestra biblioteca completa de contenidos relacionados con bases de datos.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
