By Mark Drake
Manager, Developer Education

Introdução
Os sistemas de gerenciamento de banco de dados (SGDB, no inglês DMBS) são programas de computador que permitem que usuários interajam com um banco de dados. Um DBMS permite que os usuários controlem o acesso a um banco de dados, gravem dados, executem consultas e façam outras tarefas relacionadas ao gerenciamento de banco de dados.
No entanto, para realizar qualquer uma dessas tarefas, o DBMS deve possuir algum modelo subjacente que defina como os dados são organizados. O modelo relacional é uma abordagem para organizar dados que vem sendo bastante usada em softwares de banco de dados desde que foram criados no final dos anos 60. Tanto é que, no momento em que este artigo está sendo escrito, quatro dos cinco DBMS mais populares são relacionais.
Este artigo conceitual descreve o histórico do modelo relacional, como os bancos de dados relacionais organizam dados e como são usados hoje.
História do modelo relacional
Os bancos de dados são clusters de informações logicamente modelados, ou dados. Qualquer coleção de dados é um banco de dados, independentemente de como ou onde é armazenada. Mesmo um armário de arquivos que contém informações de folha de pagamento é um banco de dados, assim como uma pilha de formulários hospitalares ou uma coleção de informações de cliente de uma empresa espalhada em vários locais. Antes do armazenamento e gerenciamento de dados com computadores ser uma prática comum, bancos de dados físicos como esses eram os únicos disponíveis para as organizações governamentais e empresariais que precisavam armazenar informações.
Em meados do século XX, pesquisas na área da ciência da computação levaram à criação de máquinas com maior poder de processamento, bem como maior capacidade de armazenamento local e externo. Esses avanços levaram os cientistas da computação a começar a reconhecer o potencial que essas máquinas tinham para armazenar e gerenciar quantidades cada vez maiores de dados.
No entanto, não havia nenhuma teoria para explicar como os computadores poderiam organizar os dados de maneiras lógicas e significativas. Uma coisa é armazenar dados não ordenados em uma máquina, e outra, muito mais complicada, é projetar sistemas que permitam adicionar, recuperar, classificar e gerenciar os dados de maneira consistente e prática. A necessidade de uma estrutura lógica para armazenar e organizar dados levou a uma série de propostas sobre como tirar proveito dos computadores para gerenciar dados.
Um modelo de banco de dados inicial foi o modelo hierárquico, no qual os dados são organizados em uma estrutura que se assemelha a uma árvore, semelhante aos sistemas de arquivos modernos. O exemplo a seguir mostra como o layout de parte de um banco de dados hierárquico usado para categorizar animais se pareceria:
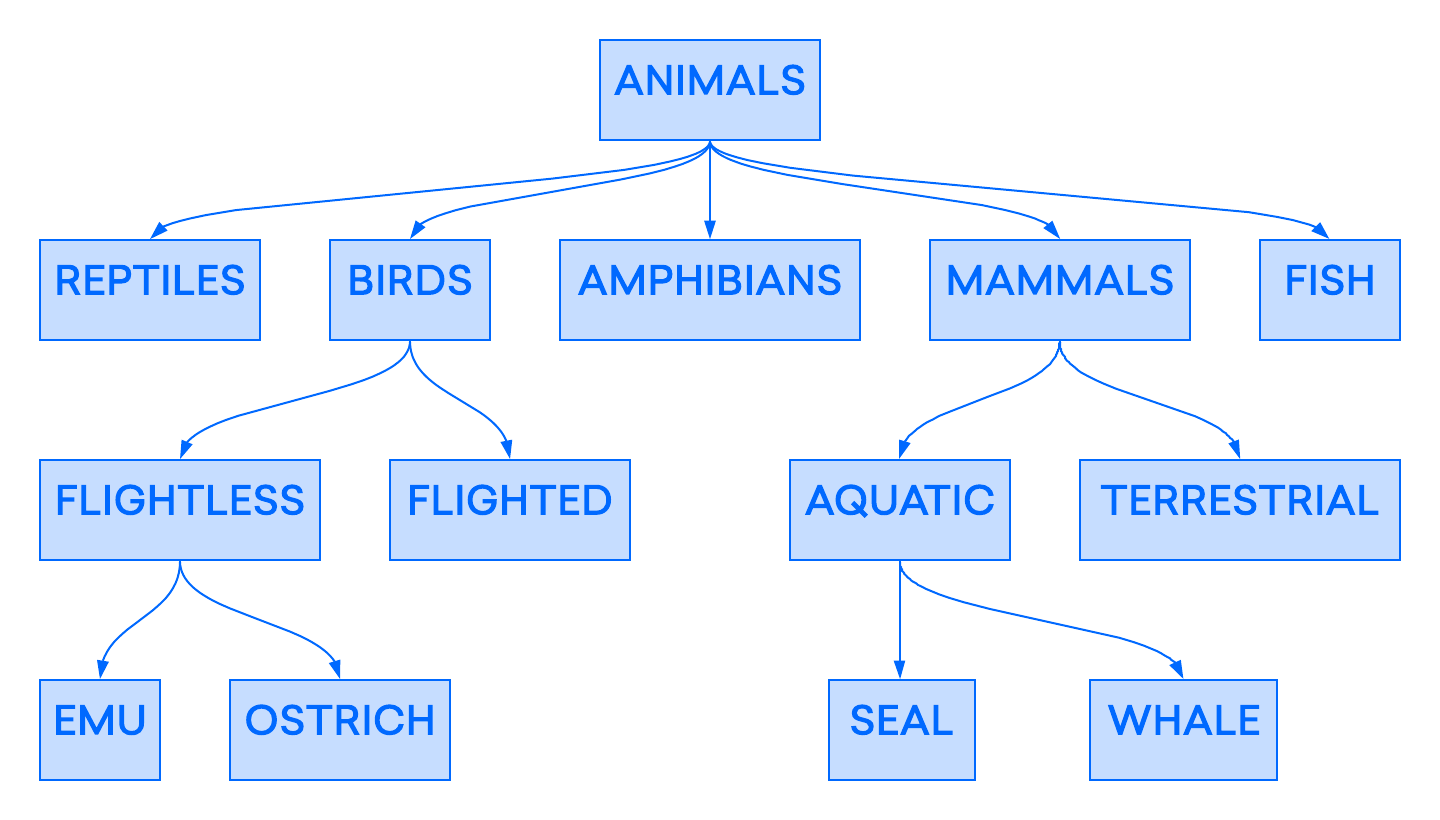
O modelo hierárquico foi amplamente implementado nos primeiros sistemas de gerenciamento banco de dados, mas também se mostrou um pouco inflexível. Neste modelo, mesmo que os registros individuais possam ter vários “filhos”, cada registro só pode ter um “pai” na hierarquia. Por conta disso, esses primeiros bancos de dados hierárquicos ficavam limitados a representar apenas relações “um a um” e “um para muitos”. Essa falta de relações"muitos para muitos" poderia levar a problemas quando se estivesse trabalhando com pontos de dados que você gostaria de associar a mais de um pai.
No final dos anos 60, Edgar F. Codd, um cientista da computação que trabalhava na IBM, criou o modelo relacional de gerenciamento de banco de dados. O modelo relacional de Codd permitiu que registros individuais fossem associados a mais de uma tabela, permitindo assim relações “muitos para muitos” entre pontos de dados, além de relacionamentos “um para muitos”. Isso proporcionou maior flexibilidade do que outros modelos existentes no que diz respeito ao projeto de banco de dados. Isso fez com que os sistemas de gerenciamento de banco de dados relacionais (RDBMSs) pudessem atender a uma gama muito maior de necessidades de negócios.
Codd propôs uma linguagem para gerenciar dados relacionais, conhecida como Alpha, que influenciou o desenvolvimento de linguagens de banco de dados posteriores. Dois dos colegas de Codd na IBM, Donald Chamberlin e Raymond Boyce, criaram uma dessas linguagens inspirada no Alpha. Eles deram a ela o nome de SEQUEL, abreviação de Structured English Query Language. No entanto, por causa de uma marca registrada existente, eles reduziram o nome de sua linguagem para SQL (conhecida mais formalmente como Structured Query Language).
Devido às restrições de hardware, os primeiros bancos de dados relacionais ainda eram proibitivamente lentos, e foi necessário algum tempo até que a tecnologia se tornasse difundida. Mas em meados dos anos 80, o modelo relacional de Codd já havia sido implementado em diversos produtos de gerenciamento de banco de dados comercial tanto da IBM quando de seus concorrentes. Esses fornecedores também seguiram a iniciativa da IBM desenvolvendo e implementando seus próprios dialetos de SQL. Em 1987, tanto o American National Standards Institute quanto a International Organization for Standardization haviam ratificado e publicado padrões para SQL, solidificando seu status como a linguagem aceita para gerenciar RDBMSs.
O uso difundido do modelo relacional em várias indústrias fez com que ele se tornasse reconhecido como o modelo padrão para o gerenciamento de dados. Mesmo com o surgimento de vários bancos de dados NoSQL nos últimos anos, os bancos de dados relacionais continuam sendo as ferramentas dominantes para armazenar e organizar dados.
Como os bancos de dados relacionais organizam os dados
Agora que você compreende de maneira geral a história do modelo relacional, vamos dar uma olhada mais de perto em como o modelo organiza os dados.
Os elementos mais fundamentais no modelo relacional são as relações, que os usuários e RDBMS modernos reconhecem como tabelas. Uma relação é um conjunto de tuplas, ou linhas em uma tabela, com cada tupla compartilhando um conjunto de atributos, ou colunas:
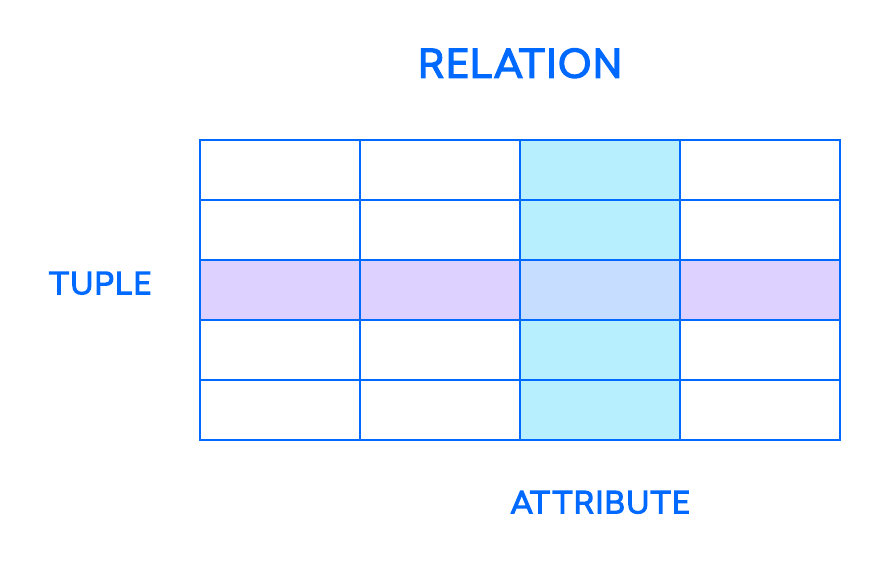
Uma coluna é a menor estrutura organizacional de um banco de dados relacional e representa as diversas facetas que definem os registros na tabela. Daí seu nome mais formal, atributos. Você pode pensar em cada tupla como sendo uma instância única de qualquer tipo de pessoas, objetos, eventos ou associações que a tabela possua. Essas instâncias podem representar coisas como funcionários em uma empresa, vendas de um negócio on-line ou resultados de testes de laboratório. Por exemplo, em uma tabela que contenha registros de funcionário de professores em uma escola, as tuplas podem possuir atributos como name (nome), subjects (disciplinas), start_date (data de início), e assim por diante.
Ao criar colunas, você especifica um tipo de dados que dita qual o tipo das entradas que são permitidas nessa coluna. Os RDBMSs muitas vezes implementam seus próprios tipos de dados únicos, que podem não ser diretamente intercambiáveis com tipos de dados semelhantes de outros sistemas. Alguns tipos de dados comuns incluem datas, strings, inteiros e booleanos.
No modelo relacional, cada tabela contém pelo menos uma coluna que pode ser usada para identificar de maneira única cada linha, chamada de chave primária. Isso é importante, pois significa que os usuários não precisam saber onde seus dados ficam fisicamente armazenados em uma máquina. Em vez disso, seu DBMS pode manter o controle de cada registro e retorná-los conforme necessário. Por sua vez, isso significa que os registros não possuem ordem lógica definida, e os usuários têm a capacidade de retornar seus dados em qualquer ordem ou sob o efeito do filtro que quiserem.
Se você tiver duas tabelas que gostaria de se associar uma com a outra, uma maneira de fazer isso é com uma chave estrangeira. Uma chave estrangeira é essencialmente uma cópia da chave primária de uma tabela (a tabela “pai”) inserida em uma coluna em outra tabela (o “filho”). O exemplo a seguir destaca a relação entre duas tabelas. Uma é usada para registrar informações sobre funcionários em uma empresa e a outra é usada para acompanhar as vendas dela. Neste exemplo, a chave primária da tabela EMPLOYEES (funcionários) é usada como a chave estrangeira na tabela SALES (vendas):
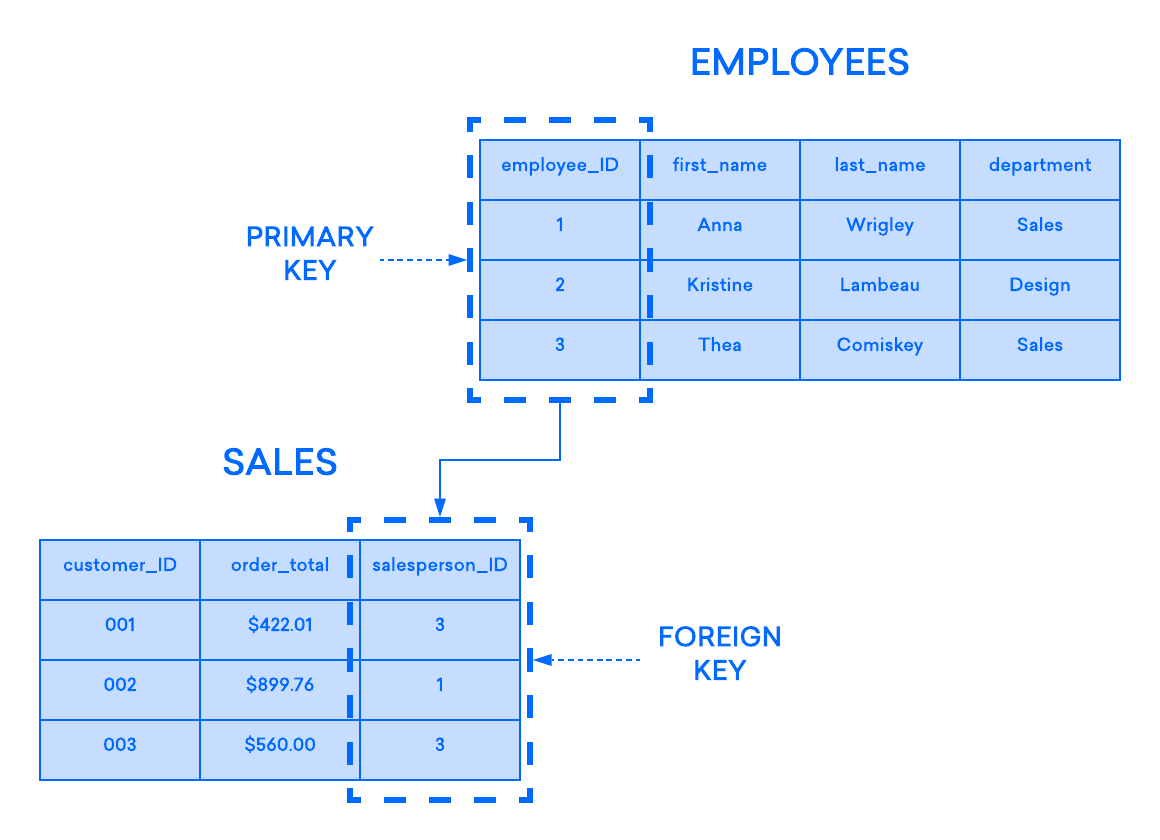
Se você tentar adicionar um registro à tabela filho e o valor inserido na coluna de chaves estrangeiras não existir na chave primária da tabela de origem, a declaração de inserção será inválida. Isso ajuda a manter a integridade de nível de relação, já que as linhas em ambas as tabelas sempre estarão relacionadas corretamente.
Os elementos estruturais do modelo relacional ajudam a manter os dados armazenados de forma organizada, mas o armazenamento de dados só é útil se for possível recuperá-los. Para recuperar informações de um RDBMS, é possível emitir uma consulta, ou uma solicitação estruturada para um conjunto de informações. Como mencionado anteriormente, a maioria dos bancos de dados relacionais usa SQL para gerenciar e consultar dados. O SQL permite que você filtre e manipule os resultados da consulta com uma variedade de cláusulas, predicados e expressões, dando-lhe um controle fino sobre quais dados aparecerão no conjunto de resultados.
Vantagens e limitações dos bancos de dados relacionais
Com a estrutura organizacional subjacente de bancos de dados relacionais em mente, vamos considerar algumas de suas vantagens e desvantagens.
Hoje em dia, tanto o SQL quanto os bancos de dados que o implementam se desviam do modelo relacional de Codd de várias maneiras. Por exemplo, o modelo de Codd determina que cada linha em uma tabela deve ser única, enquanto que, por razões de praticidade, a maioria dos bancos de dados relacionais modernos permite linhas duplicadas. Existem algumas pessoas que não consideram os bancos de dados SQL como verdadeiros bancos de dados relacionais se não conseguem aderir às especificações de Codd para o modelo relacional. No entanto, em termos práticos, qualquer DBMS que use SQL e de certa forma acate ao modelo relacional de dados provavelmente será referido como um sistema de gerenciamento de banco de dados relacional.
Embora os bancos de dados relacionais tenham rapidamente crescido em popularidade, algumas das desvantagens do modelo relacional começaram a se tornar aparentes à medida que os dados se tornaram mais valiosos e as empresas começaram a armazenar uma maior quantidade deles. Por exemplo, pode ser difícil dimensionar um banco de dados relacional horizontalmente. O dimensionamento horizontal, ou ampliamento, é a prática de adicionar mais máquinas a uma pilha existente para espalhar a carga e permitir um maior tráfego e processamento mais rápido. Isso é muitas vezes contrastado com o dimensionamento vertical, que envolve atualizar o hardware de um servidor existente, geralmente adicionando mais RAM ou CPU.
A razão pela qual é difícil dimensionar um banco de dados relacional de dados horizontalmente tem a ver com o fato de que o modelo relacional foi projetado para garantir a consistência, ou seja, clientes que consultarem o mesmo banco de dados sempre receberão os mesmos dados. Se você fosse dimensionar um banco de dados relacional horizontalmente em várias máquinas, tornaria-se difícil garantir a consistência, pois os clientes poderiam escrever dados em um nó mas não nos outros. Provavelmente haveria um atraso entre a gravação inicial e o momento em que os outros nós fossem atualizados para refletir as alterações, resultando em inconsistências entre eles.
Outra limitação apresentada pelos RDBMSs é que o modelo relacional foi projetado para gerenciar dados estruturados, ou dados que se alinhem a um tipo de dados pré-definido ou que pelo menos estejam organizados de alguma forma pré-determinada, tornando-os facilmente categorizáveis e pesquisáveis. No entanto, com a propagação da computação pessoal e o aumento da internet no início dos anos 90, dados não estruturados — como mensagens de e-mail, fotos, vídeos, etc — se tornaram mais comuns.
Nada disso é para dizer que os bancos de dados relacionais não são úteis. Muito pelo contrário, o modelo relacional ainda é a estrutura dominante para o gerenciamento de dados após mais de 40 anos. Sua prevalência e longevidade significam que os bancos de dados relacionais são uma tecnologia madura, que por si só é uma de suas principais vantagens. Existem muitos aplicativos projetados para trabalhar com o modelo relacional, bem como muitos profissionais administradores de banco de dados que são especialistas no assunto. Também há uma grande variedade de recursos disponíveis on-line e em livros para aqueles que querem começar com bancos de dados relacionais.
Outra vantagem dos bancos de dados relacionais é que quase todos os RDBMS suportam transações. Uma transação consiste em uma ou mais declarações SQL individuais realizadas em sequência como uma única unidade de trabalho. As transações apresentam uma abordagem tudo ou nada, o que significa que cada declaração SQL na transação deve ser válida; caso contrário, toda a transação falhará. Isso é muito útil para garantir a integridade dos dados ao fazer alterações em várias linhas ou tabelas.
Por fim, os bancos de dados relacionais são extremamente flexíveis. Eles foram usados para construir uma grande variedade de aplicativos diferentes e continuam funcionando de maneira eficiente, mesmo com grandes quantidades de dados. O SQL também é extremamente poderoso, permitindo adicionar e alterar os dados em tempo real, bem como alterar a estrutura de esquemas e tabelas do banco de dados sem afetar os dados existentes.
Conclusão
Graças à sua flexibilidade e design para a integridade dos dados, os bancos de dados relacionais ainda representam a principal maneira de os dados serem gerenciados e armazenados mais de cinquenta anos após terem sido concebidos pela primeira vez. Mesmo com o surgimento de diversos bancos de dados NoSQL nos últimos anos, compreender o modelo relacional e como trabalhar com RDBMSs é muito importante para quem quiser construir aplicativos que tirem proveito do poder dos dados.
Para aprender mais sobre alguns RDBMSs populares de código aberto, recomendamos que você consulte nossa comparação entre vários bancos de dados SQL relacionais de código aberto. Se tiver interesse em aprender mais sobre bancos de dados de maneira geral, recomendamos que verifique nossa biblioteca completa de conteúdos relacionados a banco de dados.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
