AI Technical Writer

Introduction
Self-learning AI agents are systems that can recognize their environment, make decisions, take actions, and continuously improve their behavior based on feedback and experience. Unlike traditional rule-based software, these agents are not explicitly programmed for every possible scenario. Instead, they learn patterns, adapt to new situations, and refine their strategies over time. This ability to learn autonomously makes self-learning agents especially useful in complex and dynamic environments such as recommendation systems, robotics, autonomous navigation, finance, and intelligent assistants.
At their core, self-learning AI agents combine ideas from machine learning, reinforcement learning, decision theory, and large language models. The key idea is simple: the agent observes the conditions, chooses an action, receives feedback in the form of a reward or outcome, and updates its internal model or data to perform better in the future. Over repeated interactions, the agent gradually improves with time.
Key Takeaways
- Self-learning AI agents improve their behavior by interacting with an environment and learning from feedback.
- Reinforcement learning is one of the most common foundations for building self-learning agents.
- An agent consists of an environment, a policy, a reward signal, and a learning mechanism.
- Modern AI agents often combine classical reinforcement learning with neural networks and memory.
- Even simple self-learning agents can be built using Python and standard ML libraries.
- The same core principles scale from toy demos to real-world autonomous systems.
What Is a Self-Learning AI Agent?
A self-learning AI agent is an autonomous entity that makes decisions based on observations and learns from the consequences of those decisions. The agent does not rely solely on predefined rules. Instead, it updates its internal knowledge by evaluating how good or bad its actions were. This learning process allows the agent to adapt to changes and improve performance over time.
The defining characteristic of self-learning agents is the feedback loop. The agent observes the environment, selects an action, receives feedback, and then uses that feedback to adjust future actions. This loop continues indefinitely, allowing the agent to learn from both success and failure. The learning can be supervised, unsupervised, or reinforcement-based, but reinforcement learning is the most natural fit because it directly models interaction and reward.
How Self-Learning Happens
Self-learning occurs through repeated interaction and gradual updates. Initially, the agent may behave randomly or follow a naive strategy. As it collects experience, it stores information about states, actions, and rewards. Using this experience, the agent estimates which actions lead to better outcomes. Gradually, poor actions are avoided, and better actions are favored.
In reinforcement learning, this process is often formalized using value functions or policy gradients. The agent estimates the expected future reward for each action and adjusts its behavior accordingly. Neural networks are commonly used to approximate these value functions when the state space is large or continuous. This combination of learning from experience and function approximation is what allows modern AI agents to scale to complex tasks.
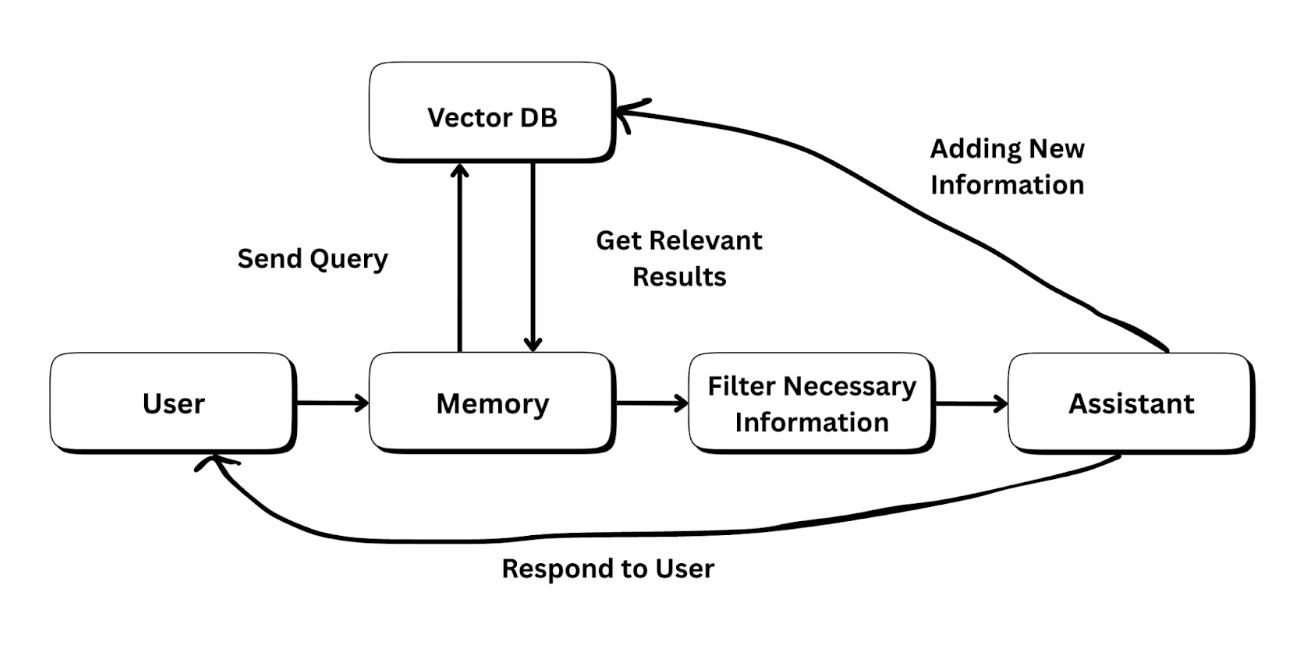
When a user asks a question, the query first goes into the memory layer instead of directly reaching the assistant. Memory represents everything the system knows from past interactions, such as previous conversations, user preferences, and learned corrections.
The memory then sends the query to a vector database, where the question is converted into embeddings and compared with stored knowledge to find the most relevant past information. The vector database returns these relevant results back to memory, allowing the system to recall similar questions or useful prior answers. Since not all retrieved information is needed, the memory passes the data through a filtering step that keeps only what is necessary and relevant for the current query. This filtered context is then sent to the assistant, which uses it to generate a more accurate and personalized response for the user.
After responding, the assistant adds new information, such as the latest answer, user feedback, or corrected details, back into the vector database. This closes the learning loop, ensuring the next response is better informed.
For example, imagine a user asking, “What is a self-learning AI agent?” The first time, the assistant generates an explanation and stores that response in the vector database. Later, if the same user asks, “Explain self-learning agents with a simple example,” the system retrieves the earlier explanation from memory, filters it, and improves it by adding an example before replying. Over time, the assistant becomes clearer and more helpful, not because the model is retrained, but because it remembers and learns from past interactions.
RAG vs Memories vs History
When building AI agents, terms like Retrieval-Augmented Generation (RAG), Memory, and History are often used interchangeably, but they serve very different purposes. Understanding the difference between them is essential for designing self-learning AI agents that are accurate, consistent, and capable of improving over time.
History is the simplest of the three. It refers to the raw conversation log between the user and the assistant. This includes everything said in the current session, usually passed to the model as recent messages. History helps the assistant maintain short-term context, such as understanding follow-up questions or pronouns like “this” or “that.” However, history is limited by context length, disappears when the session ends, and does not involve any learning. Once the conversation is gone, the assistant forgets everything that happened.
Memory goes a step further. Memory is curated, structured, and persistent information extracted from interactions. Instead of storing every message, memory stores meaningful summaries such as user preferences, corrections, decisions, or lessons learned. Memory is what enables an AI agent to improve its behavior over time. For example, if a user prefers short explanations or corrects the assistant once, that information can be saved in memory and reused in future interactions. Memory is selective, long-term, and designed to influence future reasoning, which makes it essential for self-learning agents.
Retrieval-Augmented Generation (RAG) is different from both history and memory. RAG focuses on grounding the model’s responses in external knowledge sources such as documents, PDFs, databases, or internal wikis. When a user asks a question, the system retrieves relevant chunks of information from a knowledge base using embeddings and then injects that information into the prompt before generating an answer. RAG does not remember users or learn from past behavior; its goal is accuracy and factual grounding, not adaptation.
The key difference lies in intent. History helps the model understand the current conversation, memory helps the agent learn and adapt over time, and RAG helps the model access reliable external knowledge. In practice, advanced AI agents use all three together. History maintains conversational flow, memory personalizes and improves responses, and RAG ensures answers are factually correct and up to date.
For example, consider a technical AI assistant. History allows it to understand that “this error” refers to a stack trace shared earlier. Memory allows it to remember that the user prefers Python examples and beginner-friendly explanations. RAG allows it to fetch the latest documentation or internal API references to answer accurately. Together, these components transform a simple chatbot into a robust, self-learning AI agent.
Memory
Memory stores manage a database where the agent can add, update, or delete records based on past conversations. These stored memories are then used by the LLM to generate responses. As a result, every time you interact with the agent, it remembers user preferences and contextual details from previous chats, allowing it to deliver highly personalized responses. This approach is especially powerful for email agents and use cases that require a continuously evolving, context-aware system.
Memory is a core component of a self-learning AI agent because it allows the system to retain and reuse knowledge across interactions instead of starting from scratch every time. The agent stores relevant information from past conversations, such as user preferences, decisions, corrections, and feedback, in a structured memory store or database. This memory can include short-term context (recent chats), long-term knowledge (user habits, recurring tasks, or rules), and learned outcomes from previous actions.
When a new request comes in, the agent retrieves the most relevant memories and injects them into the prompt or reasoning process of the LLM, enabling more accurate and personalized responses. Over time, as the agent continuously updates its memory by adding new insights, modifying outdated information, or removing irrelevant data, it effectively “learns” from experience. This feedback-driven memory loop allows the agent to improve its behavior, adapt to user needs, and evolve naturally, making it especially effective for applications like email assistants, workflow automation, and long-running AI systems that require consistency and personalization.
ChatGPT Self Learning Memory Updates
A very simple example from our day-to-day life is ChatGPT. ChatGPT updates its memory over time based on the user’s interactions. Now,imagine a user who regularly asks an AI assistant to help summarize meeting notes. Initially, the agent provides very general summaries, but after repeated interactions, it notices a pattern: the user always asks for action items first, prefers bullet-style summaries, and works in a remote-first team across different time zones. Instead of treating each request independently, the agent now updates its memory to store these preferences. The next time the user uploads meeting notes, the agent automatically generates a summary with action items at the top, highlights deadlines in the user’s local time zone, and keeps the language concise. This behavior feels like “learning,” not because the model has changed its parameters, but because the agent continuously updates and references its memory based on past interactions. Over time, the assistant becomes more personalized and efficient, demonstrating how self-learning AI agents evolve through memory updates rather than traditional retraining.
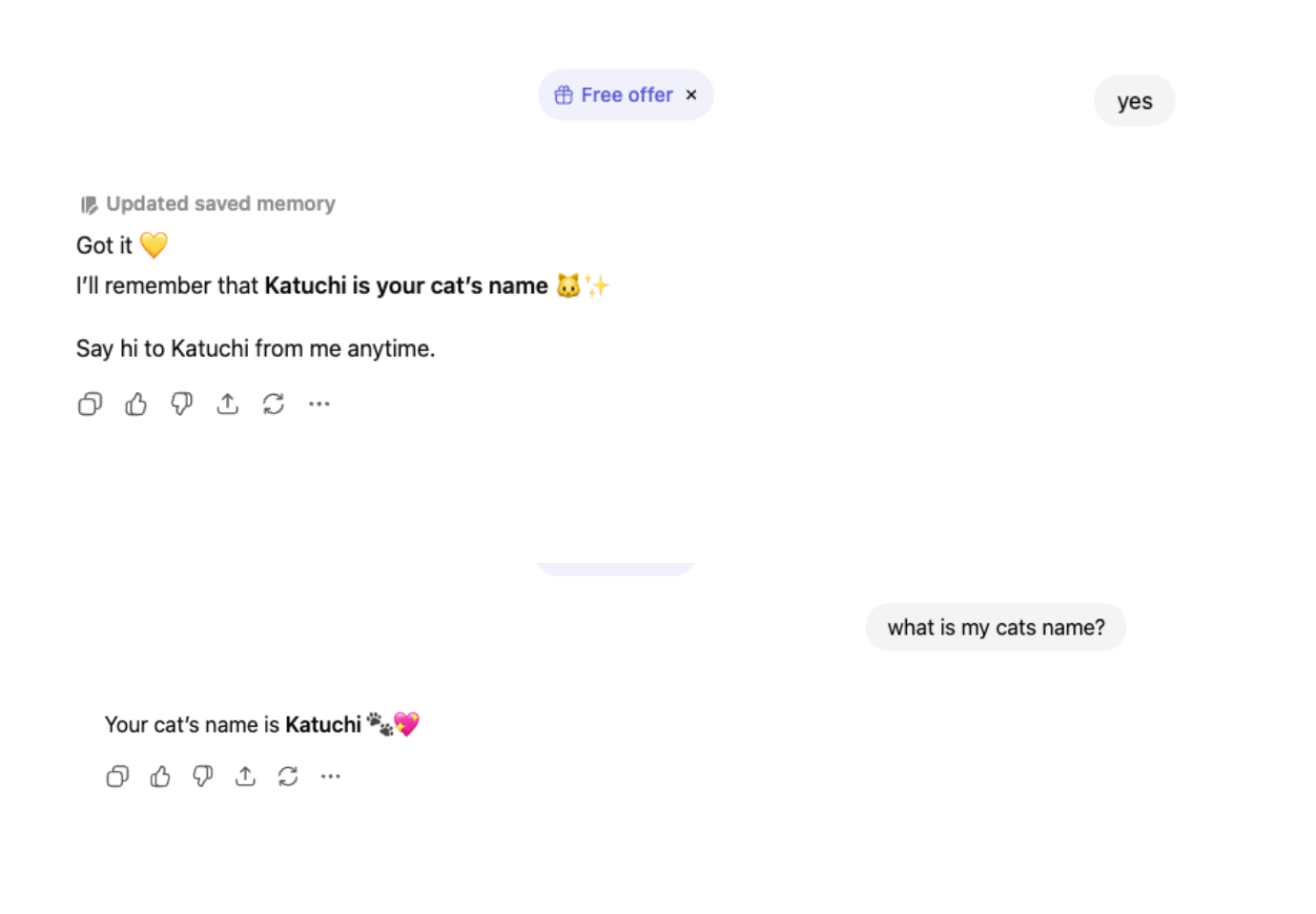
This is an example of how ChatGPT updates its memory, hence allowing it to remember my cat’s name when I ask it again in the future.
Tools to build Self Learning AI Agent
Building a self-learning AI agent requires more than just a language model. The agent needs supporting tools that help it store information, remember past interactions, prompt engineering, and update its behavior over time. Tools act as the base for continuous learning, memory management, and real-world automation. In this section, we explore the key tools that make it possible to build scalable and truly self-learning AI agents.
n8n
Now we all know by now that n8n is a powerful workflow automation platform that can be used to build self-learning AI agents without heavy backend engineering. Instead of writing complex code, n8n allows you to visually design the agent’s logic using nodes, thus making it ideal for building AI agents that think, act, remember, and improve over time. When combined with OpenAI models, databases, and feedback mechanisms, n8n becomes a practical framework for creating production-ready self-learning agents. A self-learning AI agent in n8n is essentially a continuous workflow that receives input, reasons using an LLM, performs actions via integrations, stores outcomes, and reuses past experiences. The learning happens through memory, feedback, and iteration rather than retraining the model.
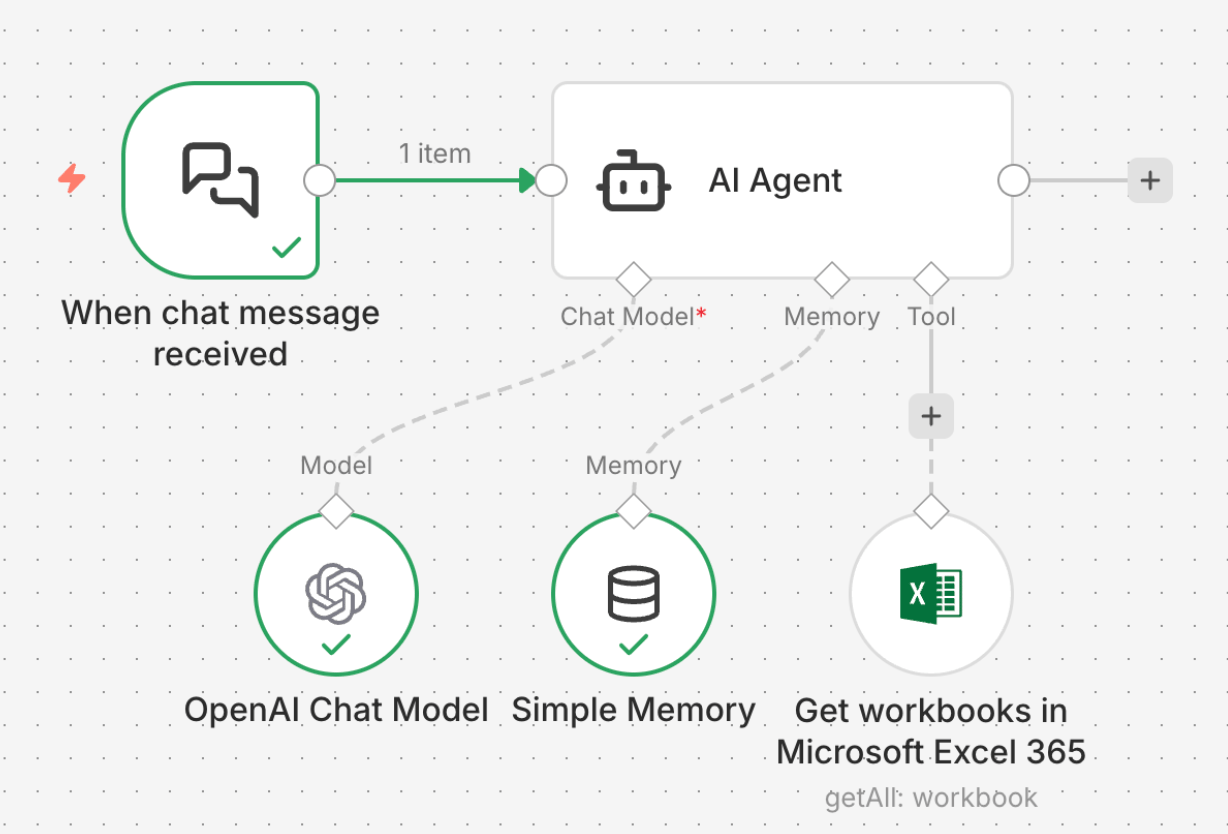
A self-learning AI agent in n8n allows users to design workflows that can observe user behavior, store useful information, and reuse it in future interactions. With n8n, users can connect the AI model with memory sources such as databases, knowledge bases, APIs, and even simple Excel or Google Sheets files. The AI model (for example, OpenAI via an API key) handles reasoning and language understanding, while n8n decides when to save information, where to save it, and how to retrieve it later. This separation makes the system flexible, explainable, and easy to extend.
To start, the user connects an LLM using an API key inside n8n. This allows the agent to process conversations or tasks. Next, n8n is configured with one or more memory stores. A database like PostgreSQL or MongoDB can be used for long-term structured memory, such as user preferences, habits, or past decisions. A vector database or document store can act as a knowledge base, storing embeddings of documents, FAQs, or notes that the agent can search when answering questions. For lighter use cases, even Excel or Google Sheets works surprisingly well. Each row can represent a user, a preference, or a learned fact, making it easy to read, update, and audit without deep technical knowledge.
The “self-learning” behavior comes from logic built into the workflow. For example, n8n can include a step that analyzes each user message and decides whether it contains a preference worth saving. If it does, the agent writes that information to the chosen memory store. On future interactions, the workflow first queries the database, knowledge base, or spreadsheet to retrieve relevant memories and injects them into the AI’s prompt. This allows the agent to respond differently based on what it has learned before, creating the illusion of continuous learning.
Consider a simple and relatable example. A user chats with a food recommendation agent and says, “I really like Italian food, especially pasta and risotto.” The n8n workflow detects this preference and stores it in a database or an Excel sheet under the user’s profile. The next time the user asks, “What should I eat for dinner tonight?”, the agent does not start from scratch. Before generating a response, n8n fetches the stored preference and passes it to the AI model. As a result, the agent replies with suggestions like mushroom risotto, creamy Alfredo pasta, or a light Italian salad. Over time, if the user also mentions avoiding spicy food or preferring vegetarian meals, those details are added to memory, making each future recommendation more personalized and accurate.
Large Language Model
A Large Language Model (LLM) can be considered as the brain of a self-learning AI agent. In simple terms, it is the part of the system that understands user input, makes decisions, and generates responses in human-like language. The LLM does not store long-term memory on its own, but it can analyze past information, reason over it, and decide what to learn or update.
In n8n, an LLM node can be used as a single node where user input, stored memory, and external data are passed together to generate intelligent responses or actions. This makes it easy to connect the model with databases, APIs, and automation workflows. The LLM is used because it allows the agent to think, adapt, and improve its behavior over time, acting as the decision-maker that turns stored knowledge into meaningful, context-aware responses.
Supabase
Supabase is an open-source backend platform that works like a ready-made database and API layer for your AI agent. In simple terms, it helps store information such as user preferences, past conversations, feedback, and learning updates in a structured way. For a self-learning AI agent, this is important because the agent needs a place to save what it learns over time instead of starting from scratch in every interaction. Supabase provides a fast PostgreSQL database, authentication, and real-time data access, making it easy for an AI agent to read and update its memory.
In n8n, Supabase can be used as a single node to insert, update, or fetch data, which keeps the workflow clean and easy to manage. For example, when a user says they like Italian food, the agent can store this preference in Supabase and retrieve it in future conversations to personalize responses. This is why Supabase is commonly used it acts as the long-term memory layer for self-learning AI agents, enabling continuous learning, personalization, and smarter behavior over time.
Prompt Engineering
Prompt engineering plays a critical role in how self-learning AI agents think, reason, and improve over time. Well-designed prompts help the agent clearly understand its goals, constraints, available tools, and expected output format. In self-learning systems, prompts guide how feedback, memory, and past experiences are interpreted and reused in future decisions.
Poorly written prompts can lead to confusion, hallucinations, or inconsistent behavior, while clear and structured prompts improve reliability, learning efficiency, and decision-making. As agents evolve, prompt engineering acts as a control layer that keeps the system aligned, focused, and adaptable without changing the underlying model.
OpenAI Agent Builder
OpenAI’s Agent Builder (via the OpenAI Agents SDK) is similar to n8n, also provides a structured way to build such agents by combining large language models with tools, memory, and feedback loops. Instead of writing complex orchestration logic from scratch, the agent builder allows you to define how an agent reasons, what tools it can use, and how it should learn from past interactions.
At its core, an OpenAI-based agent works in a continuous loop. The agent receives a task or user instruction, reasons about what needs to be done, decides whether to call a tool, executes that tool, observes the result, and then updates its internal state. This loop is what enables learning-like behavior, especially when feedback is stored and reused in future decisions.
Challenges and Limitations
Despite their capabilities, self-learning AI agents come with several challenges. Training can be unstable, especially when feedback is limited or when the environment keeps changing. If rewards are poorly designed, agents may learn unexpected or unwanted behaviors. These systems can also be hard to interpret, which makes debugging and building trust more difficult.
As agents grow in complexity, they often rely on many workflow nodes, memory stores, decision steps, API keys, and fallback logic. This added complexity can make the system harder to understand, maintain, and scale over time. Managing multiple API keys for language models, vector databases, and third-party services also introduces operational issues such as access control, key rotation, cost tracking, and security risks.
Ethical and safety concerns are equally important. Autonomous agents must be carefully constrained to prevent harmful outcomes, especially in sensitive areas like healthcare or finance. Human oversight, regular evaluation, and alignment techniques are critical for safe deployment. When an agent is given too many responsibilities at once, it can become confused, leading to hallucinations or incorrect outputs.
FAQs
What makes an AI agent self-learning? An AI agent is considered self-learning if it improves its behavior over time by learning from experience rather than relying solely on predefined rules.
Is reinforcement learning required for self-learning agents? Reinforcement learning is the most common approach, but self-learning can also involve supervised or unsupervised updates, especially in hybrid systems.
Can self-learning agents use large language models? Yes, modern agents often integrate large language models for reasoning, planning, and understanding natural language feedback.
Are self-learning agents safe to deploy? They can be safe if properly designed, tested, and monitored. Safety constraints and human oversight are critical.
How long does it take to train a self-learning agent? Training time depends on the complexity of the environment, the learning algorithm, and the amount of feedback available. Simple agents can learn quickly, while complex systems may require extensive training.
Conclusion
With AI moving forward so rapidly, things are changing at a lightning-fast pace, with agents now things are moved to self-learning AI agents to build intelligent systems. Unlike traditional systems that are built on fixed rules and need manual updates, these agents are designed in a way to improve themselves, remember their user interactions, and act intelligently. This ability is becoming essential because modern systems operate in environments that change frequently, where user needs, data, and context cannot be fully predicted in advance.
By learning from feedback, memory, and past behavior, self-learning AI agents can adapt to new situations without being retrained from scratch. This makes them more scalable, more personalized, and more efficient over time. Although challenges such as stability, safety, and transparency still exist, they can be managed through thoughtful architecture, human-in-the-loop oversight, and responsible deployment practices. Also, with the help of powerful tools like n8n, it has become extremely easy to build these agents.
When designed carefully, they allow AI systems to learn from real usage, adapt to change, and provide better results over time without constant reprogramming.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
