
Einführung
Wenn Sie eine Anwendung aktiv entwickeln, kann Docker den Workflow und den Prozess der Bereitstellung der Anwendung in der Produktion vereinfachen. Die Arbeit mit Containern im Entwicklungsbereich bietet folgende Vorteile:
- Die Umgebungen sind konsistent, was bedeutet, dass Sie die Sprachen und Abhängigkeiten für Ihr Projekt wählen können, ohne dass es zu Systemkonflikten kommt.
- Die Umgebungen werden isoliert, wodurch Probleme leichter behoben und die neuen Teammitglieder schneller eingearbeitet werden können.
- Die Umgebungen sind tragbar, sodass Sie den Code verpacken und mit anderen teilen können.
Dieses Tutorial zeigt Ihnen, wie Sie eine Entwicklungsumgebung für eine Ruby on Rails-Anwendung mit Docker einrichten. Sie erstellen mehrere Container – für die Anwendung selbst, die PostgreSQL Datenbank, Redis und einen Sidekiq Dienst – mit Docker Compose. Das Setup bewirkt Folgendes:
- Synchronisieren des Anwendungscodes im Host mit dem Code im Container, um Änderungen während der Entwicklung zu ermöglichen.
- Beibehaltung der Anwendungsdaten zwischen Container-Neustarts.
- Konfiguration von Sidekiq-Workern, um die Vorgänge wie erwartet zu verarbeiten.
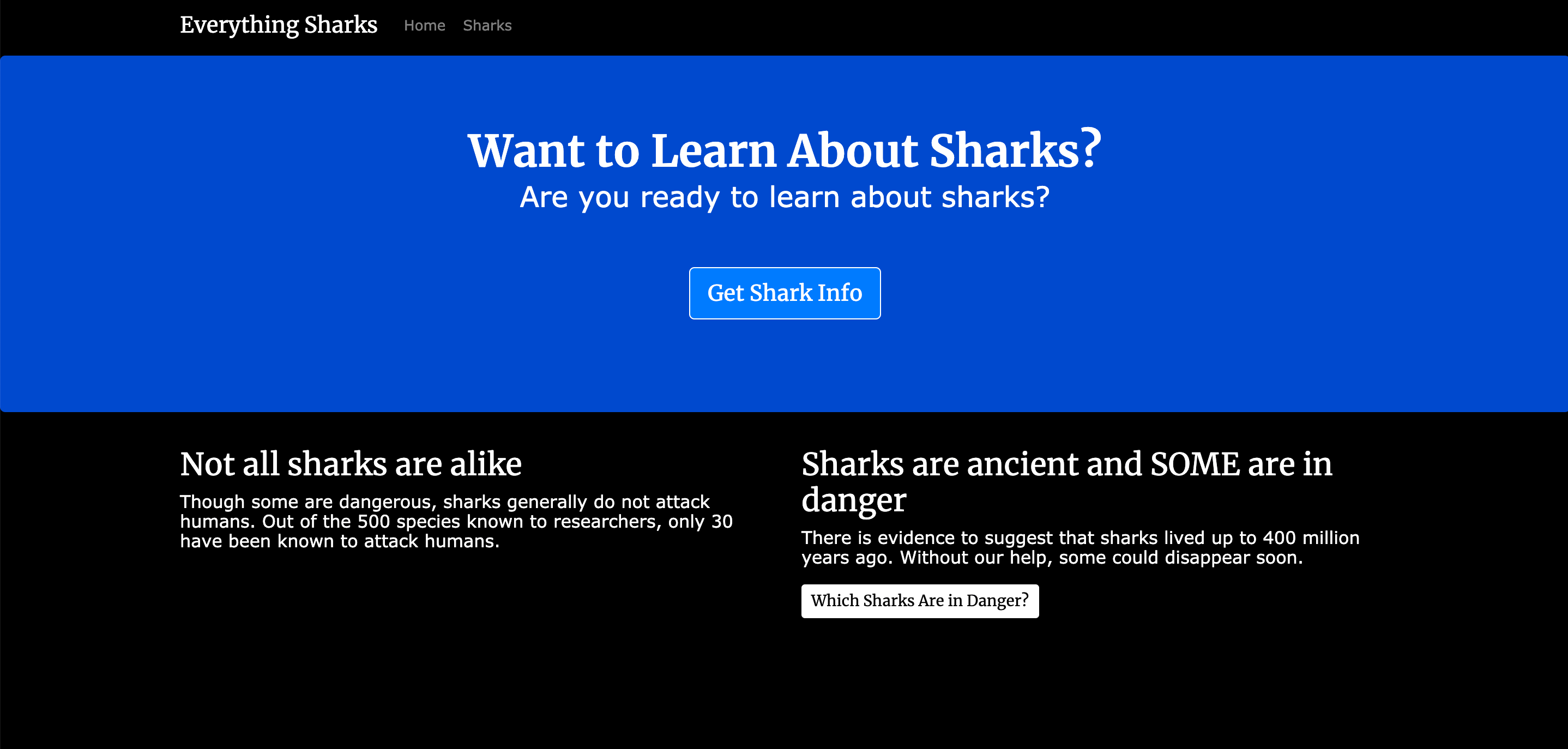
Am Ende dieses Tutorials haben Sie eine funktionierende Anwendung mit Informationen zu Haien, die auf Docker Containern ausgeführt wird:
Voraussetzungen
Um dieser Anleitung zu folgen, benötigen Sie:
- Einen lokalen Entwicklungsrechner oder einen Server, auf dem Ubuntu 18.04 ausgeführt wird, zusammen mit einem Benutzer ohne Rootberechtigung mit
sudo-Privilegien und einer aktiven Firewall. Eine Anleitung für das Setup finden Sie im Leitfaden für die Ersteinrichtung des Servers. - Docker muss auf Ihrem lokalen Rechner oder Server installiert sein. Folgen Sie dazu Schritt 1 und 2 in So installieren und verwenden Sie Docker unter Ubuntu 18.04.
- Docker Compose muss auf Ihrem lokalen Rechner oder Server installiert sein. Folgen Sie dazu Schritt 1 in So installieren Sie Docker Compose unter Ubuntu 18.04.
Schritt 1 – Klonen des Projekts und Hinzufügen von Abhängigkeiten
Unser erster Schritt besteht darin, das Repository rails-sidekiq aus dem DigitalOcean Community GitHub-Konto zu klonen. Dieses Repository enthält den Code aus dem Setup, das in So fügen Sie Sidekiq und Redis zu einer Ruby-on-Rails-Anwendung hinzu beschrieben wird. Dort wird erklärt, wie Sie einem bestehenden Rails 5-Projekt Sidekiq hinzufügen.
Klonen Sie das Repository in ein Verzeichnis namens rails-docker:
- git clone https://github.com/do-community/rails-sidekiq.git rails-docker
Navigieren Sie zum Verzeichnis rails-docker:
- cd rails-docker
In diesem Tutorial verwenden wir PostgreSQL als Datenbank. Um mit PostgreSQL anstelle von SQLite 3 zu arbeiten, müssen Sie das pg gem zu den Abhängigkeiten des Projekts hinzufügen, die in seiner Gemfile aufgelistet sind. Öffnen Sie diese Datei, um sie in nano oder Ihrem bevorzugten Texteditor zu bearbeiten:
- nano Gemfile
Fügen Sie das Gem an beliebiger Stelle in die Abhängigkeiten des Hauptprojekts ein (oberhalb der Entwicklungsabhängigkeiten):
. . .
# Reduces boot times through caching; required in config/boot.rb
gem 'bootsnap', '>= 1.1.0', require: false
gem 'sidekiq', '~>6.0.0'
gem 'pg', '~>1.1.3'
group :development, :test do
. . .
Auch können wir den sqlite Gem auskommentieren, da wir ihn nicht mehr brauchen:
. . .
# Use sqlite3 as the database for Active Record
# gem 'sqlite3'
. . .
Kommentieren Sie schließlich das spring-watcher-listen Gem unter development aus:
. . .
gem 'spring'
# gem 'spring-watcher-listen', '~> 2.0.0'
. . .
Wird dieses Gem nicht deaktiviert, erhalten wir beim Zugriff auf die Rails-Konsole ständig Fehlermeldungen. Diese Fehlermeldungen ergeben sich aus der Tatsache, dass dieses Gem Rails veranlasst, mit listen auf Änderungen in „development“ zu achten, statt das Dateisystem nach Änderungen abzufragen. Da dieses Gem die Root des Projekts überwacht, einschließlich des Verzeichnisses node_modules, wirft es Fehlermeldungen über beobachtete Verzeichnisse aus, die die Konsole überladen. Wenn Sie allerdings Bedenken bezüglich der Einsparung von CPU-Ressourcen haben, ist die Deaktivierung dieses Gem für Sie wahrscheinlich ungeeignet. In dem Fall kann es sinnvoll sein, Ihre Rails-Anwendung auf Rails 6 zu aktualisieren.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Sobald Ihr Projekt-Repository vorhanden ist, das Gem pg der Gemfile hinzugefügt und das Gem spring-watcher-listen auskommentiert wurde, können Sie Ihre Anwendung so konfigurieren, dass sie mit PostgreSQL funktioniert.
Schritt 2 – Konfiguration der Anwendung zur Verwendung mit PostgreSQL und Redis
Um mit PostgreSQL und Redis in der Entwicklung zu arbeiten, gehen Sie wie folgt vor:
- Konfigurieren Sie die Anwendung so, dass sie mit PostgreSQL als Standardadapter arbeitet.
- Fügen sie dem Projekt eine
.env-Datei mit unserem Datenbankbenutzernamen und Passwort und Redis-Host hinzu. - Erstellen Sie ein
init.sql-Skript, um den Benutzersammyfür die Datenbank zu erstellen. - Fügen Sie einen initializer für Sidekiq hinzu, damit er mit unserem containerisierten
redis-Dienst zusammenarbeiten kann. - Fügen Sie die
.env-Datei und andere relevante Dateien dengitignore- unddockerignore-Dateien des Projekts hinzu. - Erstellen Sie Datenbank-Einträge (Seeds), damit unsere Anwendung einige Datensätze zur Bearbeitung hat, wenn wir sie in Betrieb nehmen.
Öffnen Sie zunächst Ihre Datenbank-Konfigurationsdatei, die sich in config/database.yml befindet:
- nano config/database.yml
Derzeit enthält die Datei die folgenden Standardeinstellungen, die anstelle anderer, noch nicht festgelegter Einstellungen verwendet werden:
default: &default
adapter: sqlite3
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
Diese müssen geändert werden, um anzuzeigen, dass wir den postgresql-Adapter verwenden, da wir einen PostgreSQL-Dienst mit Docker Compose einrichten, um die Anwendungsdaten beizubehalten.
Löschen Sie den Code, der SQLite als Adapter festlegt, und ersetzen Sie ihn durch die folgenden Einstellungen, mit denen der Adapter und die anderen, zur Verbindung benötigten Variablen passend festgelegt werden:
default: &default
adapter: postgresql
encoding: unicode
database: <%= ENV['DATABASE_NAME'] %>
username: <%= ENV['DATABASE_USER'] %>
password: <%= ENV['DATABASE_PASSWORD'] %>
port: <%= ENV['DATABASE_PORT'] || '5432' %>
host: <%= ENV['DATABASE_HOST'] %>
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
. . .
Als Nächstes ändern wir die Einstellung für die Entwicklungsumgebung, da dies die Umgebung ist, die wir bei diesem Setup verwenden.
Löschen Sie die bestehende SQLite-Datenbankkonfiguration, damit der Abschnitt so aussieht:
. . .
development:
<<: *default
. . .
Löschen Sie schließlich auch die Datenbankeinstellungen für die Produktions- und Testumgebungen:
. . .
test:
<<: *default
production:
<<: *default
. . .
Durch diese Änderungen an den standardmäßigen Datenbankeinstellungen können wir unsere Datenbankinformationen dynamisch anhand von Umgebungsvariablen festlegen, die in .env-Dateien definiert sind, die nicht der Versionskontrolle unterstehen.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Beachten Sie, dass Sie bei Neuerstellung eines Rails-Projekts ohne Vorlage den Adapter mit dem Befehl rails new festlegen können, wie in Schritt 3 unter So verwenden Sie PostgreSQL mit der Ruby-on-Rails-Anwendung unter Ubuntu 18.04 beschrieben. Damit wird Ihr Adapter in config/database.yml festgelegt und das Gem pg dem Projekt automatisch hinzugefügt.
Da wir nun auf unsere Umgebungsvariablen verwiesen haben, können wir mit den bevorzugten Einstellungen eine Datei für sie einrichten. Die Konfigurationseinstellungen auf diese Weise zu extrahieren ist Teil des 12-Faktoren-Ansatzes der Anwendungsentwicklung, mit dem bewährte Praktiken für die Anwendungsbeständigkeit in verteilten Umgebungen definiert werden. Wenn wir dann in Zukunft Produktiv- und Testumgebungen einrichten, beinhaltet die Konfiguration unserer Datenbankeinstellungen die Erstellung zusätzlicher .env-Dateien und den Verweis auf die entsprechende Datei in den Docker Compose-Dateien.
Öffnen Sie eine .env-Datei:
- nano .env
Fügen Sie der Datei folgende Werte hinzu:
DATABASE_NAME=rails_development
DATABASE_USER=sammy
DATABASE_PASSWORD=shark
DATABASE_HOST=database
REDIS_HOST=redis
Neben der Einstellung des Datenbanknamens, des Benutzers und des Passworts haben wir auch für den DATABASE_HOST einen Wert festgelegt. Der Wert database verweist auf den PostgreSQL-Datenbank-Dienst, den wir mit Docker Compose erstellen. Auch haben wir einen REDIS_HOST festgelegt, um unseren redis-Dienst anzugeben.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Um den Datenbankbenutzer sammy zu erstellen, können wir ein init.sql-Skript schreiben, das wir dann beim Start an den Datenbank-Container anhängen können.
Öffnen Sie die Skript-Datei:
- nano init.sql
Fügen Sie folgenden Code hinzu, um einen Benutzer sammy mit administrativen Zugriffsberechtigungen einzurichten:
CREATE USER sammy;
ALTER USER sammy WITH SUPERUSER;
Dieses Skript erstellt den entsprechenden Benutzer in der Datenbank und erteilt ihm administrative Berechtigungen.
Legen Sie entsprechende Berechtigungen im Skript fest:
- chmod +x init.sql
Als Nächstes konfigurieren wir Sidekiq so, dass er mit unserem containerisierten redis-Dienst arbeitet. Wir können dem Verzeichnis config/initializers einen Initialisator hinzufügen. In diesem Verzeichnis sucht Rails nach Konfigurationseinstellungen, sobald Frameworks und Plugins geladen sind, womit ein Wert für einen Redis-Host festgelegt wird.
Öffnen Sie die Datei sidekiq.rb, um diese Einstellungen vorzunehmen:
- nano config/initializers/sidekiq.rb
Fügen Sie der Datei folgenden Code hinzu, um Werte für REDIS_HOST und REDIS_PORT anzugeben:
Sidekiq.configure_server do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Sidekiq.configure_client do |config|
config.redis = {
host: ENV['REDIS_HOST'],
port: ENV['REDIS_PORT'] || '6379'
}
end
Ähnlich wie die Datenbank-Konfigurationseinstellungen geben diese Einstellungen uns die Möglichkeit, unsere Host- und Portparameter dynamisch einzustellen, damit wir die entsprechenden Werte zur Laufzeit ersetzen können, ohne den Anwendungscode selbst zu ändern. Neben REDIS_HOST gibt es einen Standardwert für REDIS_PORT, falls er nicht anderweitig festgelegt wurde.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Um zu gewährleisten, dass die sensiblen Anwendungsdaten nicht in die Versionskontrolle kopiert werden, fügen wir der Datei .gitignore unseres Projekts .env hinzu, was Git mitteilt, welche Dateien im Projekt ignoriert werden können. Öffnen Sie die Datei zur Bearbeitung:
- nano .gitignore
Fügen Sie unten in der Datei einen Eintrag für .env hinzu:
yarn-debug.log*
.yarn-integrity
.env
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Als Nächstes erstellen wir eine .dockerignore-Datei, um festzulegen, was nicht in die Container kopiert werden soll. Öffnen Sie die Datei zur Bearbeitung:
- .dockerignore
Fügen Sie der Datei folgenden Code hinzu, der Docker anweist, bestimmte Dinge zu ignorieren, die nicht in die Container kopiert werden brauchen:
.DS_Store
.bin
.git
.gitignore
.bundleignore
.bundle
.byebug_history
.rspec
tmp
log
test
config/deploy
public/packs
public/packs-test
node_modules
yarn-error.log
coverage/
Fügen Sie auch in dieser Datei unten .env hinzu:
. . .
yarn-error.log
coverage/
.env
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Der letzte Schritt ist die Erstellung von Seed-Daten, damit die Anwendung ein paar Einträge hat, wenn wir sie starten.
Öffnen Sie eine Datei für die Seed-Daten im Verzeichnis db:
- nano db/seeds.rb
Fügen Sie der Datei folgenden Code hinzu, um vier Demo-Haie und ein Beispiel-Posting zu erstellen:
# Adding demo sharks
sharks = Shark.create([{ name: 'Great White', facts: 'Scary' }, { name: 'Megalodon', facts: 'Ancient' }, { name: 'Hammerhead', facts: 'Hammer-like' }, { name: 'Speartooth', facts: 'Endangered' }])
Post.create(body: 'These sharks are misunderstood', shark: sharks.first)
Diese Seed-Daten erstellen vier Haie und ein Posting, das mit dem ersten Hai verbunden ist.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Da Sie Ihre Anwendung so konfiguriert haben, dass sie mit PostgreSQL und Ihren Umgebungsvariablen funktioniert, können Sie nun die Dockerfile-Anwendung schreiben.
Schritt 3 – Dockerfile und Entrypoint-Skripts schreiben
Ihr Dockerfile gibt an, was im Anwendungs-Container nach der Erstellung enthalten sein soll. Durch den Einsatz eines Dockerfiles können Sie Ihre Container-Umgebung definieren und Diskrepanzen mit Abhängigkeiten oder Laufzeitversionen vermeiden.
Anhand dieser Richtlinien zum Aufbau von optimierten Containern werden wir unser Image so effizient wie möglich gestalten, indem wir eine Alpine-Basis verwenden und versuchen, die Image-Ebenen allgemein zu minimieren.
Öffnen Sie ein Dockerfile in Ihrem aktuellen Verzeichnis:
- nano Dockerfile
Die Docker-Images werden aus einer Folge von Image-Ebenen erstellt, die aufeinander aufbauen. Unser erster Schritt besteht darin, das Basisimage für die Anwendung hinzuzufügen, das den Ausgangspunkt der Anwendung bildet.
Fügen Sie der Datei folgenden Code hinzu, um das Ruby alpine-Image als Basis aufzunehmen:
FROM ruby:2.5.1-alpine
Das alpine-Image stammt aus dem Alpine Linux-Projekt und unterstützt eine kleinere Image-Größe. Weitere Informationen, ob das alpine-Image die richtige Wahl für Ihr Projekt ist, finden Sie in der Diskussion im Abschnitt Image-Varianten auf der Docker Hub Ruby-Image-Seite.
Bedenken Sie bei Gebrauch von alpine in der Entwicklung Folgendes:
- Das Minimieren der Image-Größe verringert die Ladezeit von Seiten und Ressourcen, insbesondere wenn Sie auch die Volumes auf ein Mindestmaß beschränken. Damit wird während der Entwicklung das Benutzererlebnis zügig und annähernd so gehalten, wie es wäre, wenn Sie lokal in einer nicht-containerisierten Umgebung arbeiten.
- Parität zwischen Entwicklungs- und Produktions-Images erleichtert eine erfolgreiche Bereitstellung. Da Teams sich in der Produktion häufig aus Geschwindigkeitsgründen für Alpine-Images entscheiden, trägt die Entwicklung unter Einsatz einer Alpine-Basis dazu bei, Probleme beim Wechsel in die Produktion zu verringern.
Geben Sie als Nächstes eine Umgebungsvariable ein, um die Bundler-Version anzugeben:
. . .
ENV BUNDLER_VERSION=2.0.2
Das ist einer der Schritte, die wir durchführen, um Versionskonflikte zwischen der standardmäßigen bundler-Version, die in unserer Umgebung verfügbar ist, und dem Anwendungscode zu vermeiden, der Bundler 2.0.2 erfordert.
Fügen Sie als Nächstes dem Dockerfile die Pakete hinzu, die mit der Anwendung zusammenarbeiten sollen:
. . .
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
Diese Pakete umfassen u. a. nodejs und yarn. Da die Anwendung Ressourcen mit webpack bedient, müssen wir Node.js und Yarn einbeziehen, damit die Anwendung wie erwartet läuft.
Denken Sie daran, dass das alpine-Image äußerst minimal ist: die Liste der hier aufgeführten Pakete enthält nicht alles, was Sie bei der Entwicklung eventuell brauchen, wenn Sie die eigene Anwendung containerisieren.
Installieren Sie als Nächstes die entsprechende bundler-Version:
. . .
RUN gem install bundler -v 2.0.2
Durch diesen Schritt wird die Parität zwischen der containerisierten Umgebung und den Spezifikationen der Gemfile.lock-Datei dieses Projekts gewährleistet.
Richten Sie jetzt das Arbeitsverzeichnis für die Anwendung im Container ein:
. . .
WORKDIR /app
Kopieren Sie Gemfile und Gemfile.lock:
. . .
COPY Gemfile Gemfile.lock ./
Der separate Schritt des Kopierens dieser Dateien, gefolgt vom bundle install, bewirkt, dass die Projekt-Gems nicht nach jeder Änderung des Anwendungscodes neu gebaut werden müssen. Dies funktioniert in Verbindung mit dem gem-Volume, das wir in unsere Compose-Datei aufnehmen werden. Dadurch werden Gems in den Fällen in Ihren Anwendungs-Container eingebunden, in denen der Dienst neu erstellt wurde, aber die Projekt-Gems gleich bleiben.
Legen Sie als Nächstes die Konfigurationsoptionen für den Gem-Build nokogiri fest:
. . .
RUN bundle config build.nokogiri --use-system-libraries
. . .
Dieser Schritt baut nokigiri mit den Bibliotheksversionen libxml2 und libxslt, die wir im oben stehenden Schritt RUN apk add... dem Anwendungs-Container hinzugefügt haben.
Installieren Sie als Nächstes die Projekt-Gems:
. . .
RUN bundle check || bundle install
Diese Anweisung überprüft vor der Installation, ob die Gems bereits installiert sind.
Als Nächstes wiederholen wir das gleiche Verfahren, das wir mit Gems mit den JavaScript-Paketen und Abhängigkeiten verwendet haben. Zuerst kopieren wir die Paket-Metadaten, dann installieren wir Abhängigkeiten und kopieren schließlich den Anwendungscode in das Container-Image.
Starten Sie mit dem Javascript-Abschnitt unseres Dockerfiles, indem Sie package.json und yarn.lock aus dem aktuellen Projektverzeichnis auf dem Host in den Container kopieren:
. . .
COPY package.json yarn.lock ./
Installieren Sie dann die erforderlichen Pakete mit yarn install:
. . .
RUN yarn install --check-files
Diese Anweisung enthält das Flag --check-files mit dem Befehl yarn, eine Funktion, die sicherstellt, dass zuvor installierte Dateien nicht entfernt wurden. Wie bei den Gems verwalten wir die Persistenz der Pakete im Verzeichnis node_modules mit dem Volume, wenn wir die Compose-Datei schreiben.
Kopieren Sie schließlich den Rest des Anwendungscodes und starten Sie die Anwendung mit einem Entrypoint-Skript (Einstiegspunkt-Skript):
. . .
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
Mit dem Entrypoint-Skript können wir den Container als exe-Datei ausführen.
Das endgültige Dockerfile sieht ungefähr so aus:
FROM ruby:2.5.1-alpine
ENV BUNDLER_VERSION=2.0.2
RUN apk add --update --no-cache \
binutils-gold \
build-base \
curl \
file \
g++ \
gcc \
git \
less \
libstdc++ \
libffi-dev \
libc-dev \
linux-headers \
libxml2-dev \
libxslt-dev \
libgcrypt-dev \
make \
netcat-openbsd \
nodejs \
openssl \
pkgconfig \
postgresql-dev \
python \
tzdata \
yarn
RUN gem install bundler -v 2.0.2
WORKDIR /app
COPY Gemfile Gemfile.lock ./
RUN bundle config build.nokogiri --use-system-libraries
RUN bundle check || bundle install
COPY package.json yarn.lock ./
RUN yarn install --check-files
COPY . ./
ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Erstellen Sie als Nächstes ein Verzeichnis entrypoints für die Entrypoint-Skripts:
- mkdir entrypoints
Dieses Verzeichnis enthält unser Haupt-entrypoint-Skript und ein Skript für den Sidekiq-Dienst.
Öffnen Sie die Datei für das Entrypoint-Skript der Anwendung:
- nano entrypoints/docker-entrypoint.sh
Fügen Sie den folgenden Code zur Datei hinzu:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec rails s -b 0.0.0.0
Die erste wichtige Zeile ist set -e, die das skriptausführende Shell /bin/sh anweist, schnell ein „fail“ auszugeben, wenn weiter unten im Skript Probleme auftauchen. Als Nächstes prüft das Skript, dass kein tmp/pids/server.pid vorhanden ist, um sicherzugehen, dass es beim Start der Anwendung keine Serverkonflikte geben wird. Schließlich startet das Skript den Rails-Server mit dem Befehl bundle exec rails s. Mit diesem Befehl verwenden wir die Option -b, um den Server an alle IP-Adressen anstatt an den Standard localhost zu binden. Diese Invokation bewirkt, dass der Rails-Server eingehende Anfragen an die Container-IP anstatt an den standardmäßigen localhost leitet.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Machen Sie das Skript ausführbar:
- chmod +x entrypoints/docker-entrypoint.sh
Als Nächstes erstellen wir ein Skript, das unseren sidekiq-Dienst startet, der die Sidekiq-Aufträge verarbeitet. Weitere Informationen darüber, wie die Anwendung Sidekiq einsetzt, finden Sie unter So fügen Sie Sidekiq und Redis einer Ruby-on-Rails-Anwendung hinzu.
Öffnen Sie eine Datei für das Sidekiq-Entrypoint-Skript:
- nano entrypoints/sidekiq-entrypoint.sh
Fügen Sie der Datei folgenden Code hinzu, um Sidekiq zu starten:
#!/bin/sh
set -e
if [ -f tmp/pids/server.pid ]; then
rm tmp/pids/server.pid
fi
bundle exec sidekiq
Dieses Skript startet Sidekiq im Kontext unseres Anwendungspakets.
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei. Machen Sie sie ausführbar:
- chmod +x entrypoints/sidekiq-entrypoint.sh
Mit den vorhandenen Entrypoint-Skripts und dem Dockerfile können Sie jetzt Ihre Dienste in der Compose-Datei definieren.
Schritt 4 – Dienste mit Docker Compose definieren
Mit Docker Compose können wir die verschiedenen, für das Setup erforderlichen Container ausführen. Wir definieren unsere Compose-Dienste in der Hauptdatei docker-compose.yml. Ein Dienst in Compose ist ein laufender Container und die Dienstdefinitionen, die Sie der Datei docker-compose.yml hinzufügen, enthalten Informationen darüber, wie das jeweilige Container-Image ausgeführt wird. Das Compose-Tool ermöglicht es, mehrere Dienste für den Aufbau von Multi-Container-Anwendungen zu definieren.
Unser Anwendungs-Setup enthält folgende Dienste:
- Die Anwendung selbst
- Die PostgreSQL-Datenbank
- Redis
- Sidekiq
Wir nehmen auch eine bind-Bereitstellung in unser Setup auf, damit alle Codeänderungen, die wir bei der Entwicklung vornehmen, sofort mit den Containern synchronisiert werden, die Zugriff auf diesen Code benötigen.
Beachten Sie, dass wir keinen test-Dienst definieren, da die Tests außerhalb des Bereichs dieses Tutorials und der Serie liegen, aber Sie können dies mithilfe des Präzedenzfalls tun, den wir hier für den sidekiq-Dienst verwenden.
Öffnen Sie die Datei docker-compose.yml:
- nano docker-compose.yml
Fügen Sie zunächst die Definition des Anwendungsdienstes hinzu:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
Die app-Dienstdefinition enthält die folgenden Optionen:
build: Dies definiert die Konfigurationsoptionen, einschließlichKontextunddockerfile, die verwendet werden, wenn Compose das Anwendungsimage baut. Wenn Sie ein bestehendes Image aus einer Registry wie Docker Hub verwenden möchten, können Sie stattdessen die Anweisungimageverwenden, die Informationen über Ihren Benutzernamen, das Repository und das Image-Tag enthält.context: Dieser definiert den build-Kontext für den Imageaufbau – in diesem Fall das aktuelle Projektverzeichnis.dockerfile: Dies gibt dasDockerfileaus dem aktuellen Projektverzeichnis als die von Compose verwendete Datei zum Bau des Anwendungsimages an.depends_on: Dies erstellt zunächst dieDatenbank- undredis-Container, damit sie vorappausgeführt werden.ports: Damit wird Port3000auf dem Host dem Port3000auf dem Container zugeordnet.volumes: Wir nehmen hier zwei Arten von Bereitstellungen auf:- Die erste ist eine bind-Bereitstellung, die unseren Anwendungscode auf dem Host in das Verzeichnis
/appauf dem Container einbindet. Dies erleichtert die schnelle Entwicklung, da Änderungen, die Sie am Host-Code vornehmen, sofort im Container gefüllt werden. - Die zweite ist ein benanntes Volume
gem_cache. Wenn die Anweisungbundle installim Container ausgeführt wird, werden die Projekt-Gems installiert. Das Hinzufügen dieses Volumes bewirkt, dass, wenn Sie den Container neu erstellen, die Gems in den neuen Container eingebunden werden. Bei dieser Bereitstellung wird davon ausgegangen, dass es keine Änderungen am Projekt gegeben hat. Wenn Sie also Änderungen an den Projekt-Gems in der Entwicklung vornehmen, müssen Sie daran denken, dieses Volume zu löschen, bevor Sie den Anwendungsdienst neu erstellen. - Das dritte Volume ist ein benanntes Volume für das Verzeichnis
node_modules. Anstattnode_modulesauf dem Host bereitzustellen, was zu Diskrepanzen und Berechtigungskonflikten in der Entwicklung führen kann, sorgt dieses Volume dafür, dass die Pakete in diesem Verzeichnis persistent gespeichert werden und den aktuellen Zustand des Projekts widerspiegeln. Auch hier gilt: Wenn Sie die Node-Abhängigkeiten des Projekts ändern, müssen Sie dieses Volume entfernen und neu erstellen.
- Die erste ist eine bind-Bereitstellung, die unseren Anwendungscode auf dem Host in das Verzeichnis
env_file: Dies teilt Compose mit, dass wir Umgebungsvariablen aus einer Datei namens.envhinzufügen möchten, die sich im build-Kontext befindet.environment: Mit dieser Option können wir eine nicht empfindliche Umgebungsvariable einrichten, die Informationen über die Rails-Umgebung an den Container überträgt.
Fügen Sie als Nächstes unterhalb der app-Dienstdefinition den folgenden Code hinzu, um Ihren Datenbank-Dienst festzulegen:
. . .
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
Anders als der app-Dienst ruft der Datenbank-Dienst ein postgres-Image direkt aus dem Docker-Hub ab. Beachten Sie, dass wir die Version hier auch anheften, anstatt sie auf die aktuellste zu setzen oder nicht anzugeben (wodurch standardmäßig die aktuellste festgelegt wird). Auf diese Weise können wir sicherstellen, dass dieses Setup mit den hier angegebenen Versionen funktioniert und unerwartete Überraschungen durch fehlschlagende Codeänderungen am Image vermieden werden.
Auch beziehen wir das Volume db_data ein, das die Anwendungsdaten zwischen Container-Starts persistent speichert. Zusätzlich haben wir unser Startskript init.sql auf dem entsprechenden Verzeichnis docker-entrypoint-initdb.d/ im Container bereitgestellt, um den Datenbankbenutzer sammy zu erstellen. Nachdem der Image-Entrypoint den standardmäßigen postgres-Benutzer und die Datenbank erstellt, werden alle im Verzeichnis docker-entrypoint-initdb.d/ gefundenen Skripts ausgeführt, die Sie für notwendige Initialisierungsaufgaben benötigen. Weitere Informationen finden Sie im Abschnitt Initialisierungskripts der PostgreSQL Image-Dokumentation.
Fügen Sie als Nächstes die redis-Dienstdefinition hinzu:
. . .
redis:
image: redis:5.0.7
Wie der Datenbank-Dienst, verwendet der redis-Dienst ein Image von Docker Hub. In diesem Fall bleibt der Sidekiq Auftrags-Cache nicht persistent gespeichert.
Fügen Sie schließlich die sidekiq-Dienstdefinition hinzu:
. . .
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
Unser sidekiq-Dienst gleicht unserem app-Dienst in wenigen Punkten: er verwendet denselben Build-Kontext, dasselbe Image, dieselben Umgebungsvariablen und Volumes. Allerdings ist er von den app-, redis- und den Datenbank-Diensten abhängig und startet somit zuletzt. Außerdem verwendet er einen entrypoint, der den im Dockerfile festgelegten Entrypoint außer Kraft setzt. Diese entrypoint-Einstellung verweist auf entrypoints/sidekiq-entrypoint.sh, die den entsprechenden Befehl enthält, um den sidekiq-Dienst zu starten.
Fügen Sie als letzten Schritt die Volume-Definitionen unterhalb der sidekiq-Dienstdefinition hinzu:
. . .
volumes:
gem_cache:
db_data:
node_modules:
Unsere Volumes auf oberster Ebene definieren die Volumes gem_cache, db_data und node_modules. Wenn Docker Volumes erstellt, werden die Inhalte des Volumes in einem Teil des Host-Dateisystems, nämlich /var/lib/docker/volumes, gespeichert, das von Docker verwaltet wird. Die Inhalte jedes Volumes werden in einem Verzeichnis unter /var/lib/docker/volumes/ gespeichert und in jedem Container bereitgestellt, der das Volume verwendet. Auf diese Weise werden die Info-Daten zu Haien, die unsere Benutzer erstellen, im Volumen db_data persistent gespeichert, selbst wenn wir den Datenbank-Dienst entfernen und neu erstellen.
Die fertige Datei sieht ungefähr so aus:
version: '3.4'
services:
app:
build:
context: .
dockerfile: Dockerfile
depends_on:
- database
- redis
ports:
- "3000:3000"
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
database:
image: postgres:12.1
volumes:
- db_data:/var/lib/postgresql/data
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
redis:
image: redis:5.0.7
sidekiq:
build:
context: .
dockerfile: Dockerfile
depends_on:
- app
- database
- redis
volumes:
- .:/app
- gem_cache:/usr/local/bundle/gems
- node_modules:/app/node_modules
env_file: .env
environment:
RAILS_ENV: development
entrypoint: ./entrypoints/sidekiq-entrypoint.sh
volumes:
gem_cache:
db_data:
node_modules:
Wenn die Bearbeitung abgeschlossen wurde, speichern und schließen Sie die Datei.
Mit den fertiggestellten Dienstdefinitionen können Sie die Anwendung starten.
Schritt 5 – Testen der Anwendung
Mit der vorhandenen docker-compose.yml-Datei können Sie Ihre Dienste mit dem Befehl docker-compose up erstellen und für die Datenbank ein Seeding durchführen. Sie können auch testen, ob die Daten persistent gespeichert werden, indem Sie die Container mit docker-compose down entfernen und neu erstellen.
Erstellen Sie zunächst die Container-Images und dann die Dienste, indem Sie docker-compose up mit dem Flag -d ausführen, das die Container im Hintergrund ausführt:
- docker-compose up -d
Sie sehen die von Ihren Dienste erstellte Ausgabe:
OutputCreating rails-docker_database_1 ... done
Creating rails-docker_redis_1 ... done
Creating rails-docker_app_1 ... done
Creating rails-docker_sidekiq_1 ... done
Sie können auch ausführlichere Informationen über die Startprozesse erhalten, indem Sie die Protokolle der Dienste anzeigen:
- docker-compose logs
Wenn alles richtig gestartet wurde, sieht dies in etwa wie folgt aus:
Outputsidekiq_1 | 2019-12-19T15:05:26.365Z pid=6 tid=grk7r6xly INFO: Booting Sidekiq 6.0.3 with redis options {:host=>"redis", :port=>"6379", :id=>"Sidekiq-server-PID-6", :url=>nil}
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Running in ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux-musl]
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: See LICENSE and the LGPL-3.0 for licensing details.
sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Upgrade to Sidekiq Pro for more features and support: http://sidekiq.org
app_1 | => Booting Puma
app_1 | => Rails 5.2.3 application starting in development
app_1 | => Run `rails server -h` for more startup options
app_1 | Puma starting in single mode...
app_1 | * Version 3.12.1 (ruby 2.5.1-p57), codename: Llamas in Pajamas
app_1 | * Min threads: 5, max threads: 5
app_1 | * Environment: development
app_1 | * Listening on tcp://0.0.0.0:3000
app_1 | Use Ctrl-C to stop
. . .
database_1 | PostgreSQL init process complete; ready for start up.
database_1 |
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: starting PostgreSQL 12.1 (Debian 12.1-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv6 address "::", port 5432
database_1 | 2019-12-19 15:05:20.163 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
database_1 | 2019-12-19 15:05:20.182 UTC [63] LOG: database system was shut down at 2019-12-19 15:05:20 UTC
database_1 | 2019-12-19 15:05:20.187 UTC [1] LOG: database system is ready to accept connections
. . .
redis_1 | 1:M 19 Dec 2019 15:05:18.822 * Ready to accept connections
Sie können auch den Status Ihrer Container mit docker-compose ps überprüfen:
- docker-compose ps
Die Ausgabe zeigt an, dass die Container ausgeführt werden:
Output Name Command State Ports
-----------------------------------------------------------------------------------------
rails-docker_app_1 ./entrypoints/docker-resta ... Up 0.0.0.0:3000->3000/tcp
rails-docker_database_1 docker-entrypoint.sh postgres Up 5432/tcp
rails-docker_redis_1 docker-entrypoint.sh redis ... Up 6379/tcp
rails-docker_sidekiq_1 ./entrypoints/sidekiq-entr ... Up
Erstellen Sie als Nächstes die Datenbank und führen Sie ein Seeding durch. Führen Sie dann mit dem folgenden docker-compose exec-Befehl darin Migrationen aus:
- docker-compose exec app bundle exec rake db:setup db:migrate
Der Befehl docker-compose exec ermöglicht es Ihnen, Befehle in Ihren Diensten auszuführen; wir verwenden ihn hier, um rake db:setup und db:migrate im Kontext unseres Anwendungspakets auszuführen, um die Datenbank zu erstellen, ein Seeding und Migrationen durchzuführen. In der Entwicklung wird sich docker-compose exec für Sie als nützlich erweisen, wenn Sie Migrationen gegen die Entwicklungsdatenbank ausführen möchten.
Nach Durchführung des Befehls sehen Sie die folgende Ausgabe:
OutputCreated database 'rails_development'
Database 'rails_development' already exists
-- enable_extension("plpgsql")
-> 0.0140s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0097s
-- create_table("posts", {:force=>:cascade})
-> 0.0108s
-- create_table("sharks", {:force=>:cascade})
-> 0.0050s
-- enable_extension("plpgsql")
-> 0.0173s
-- create_table("endangereds", {:force=>:cascade})
-> 0.0088s
-- create_table("posts", {:force=>:cascade})
-> 0.0128s
-- create_table("sharks", {:force=>:cascade})
-> 0.0072s
Bei laufenden Diensten können Sie localhost:3000 oder http://your_server_ip:3000 im Browser aufrufen. Die Startseite wird in etwa so aussehen:
Jetzt können Sie die Datenpersistenz testen. Erstellen Sie einen neuen Hai, indem Sie auf die Schaltfläche Get Shark Info klicken, welche die Route shark/index aufruft:
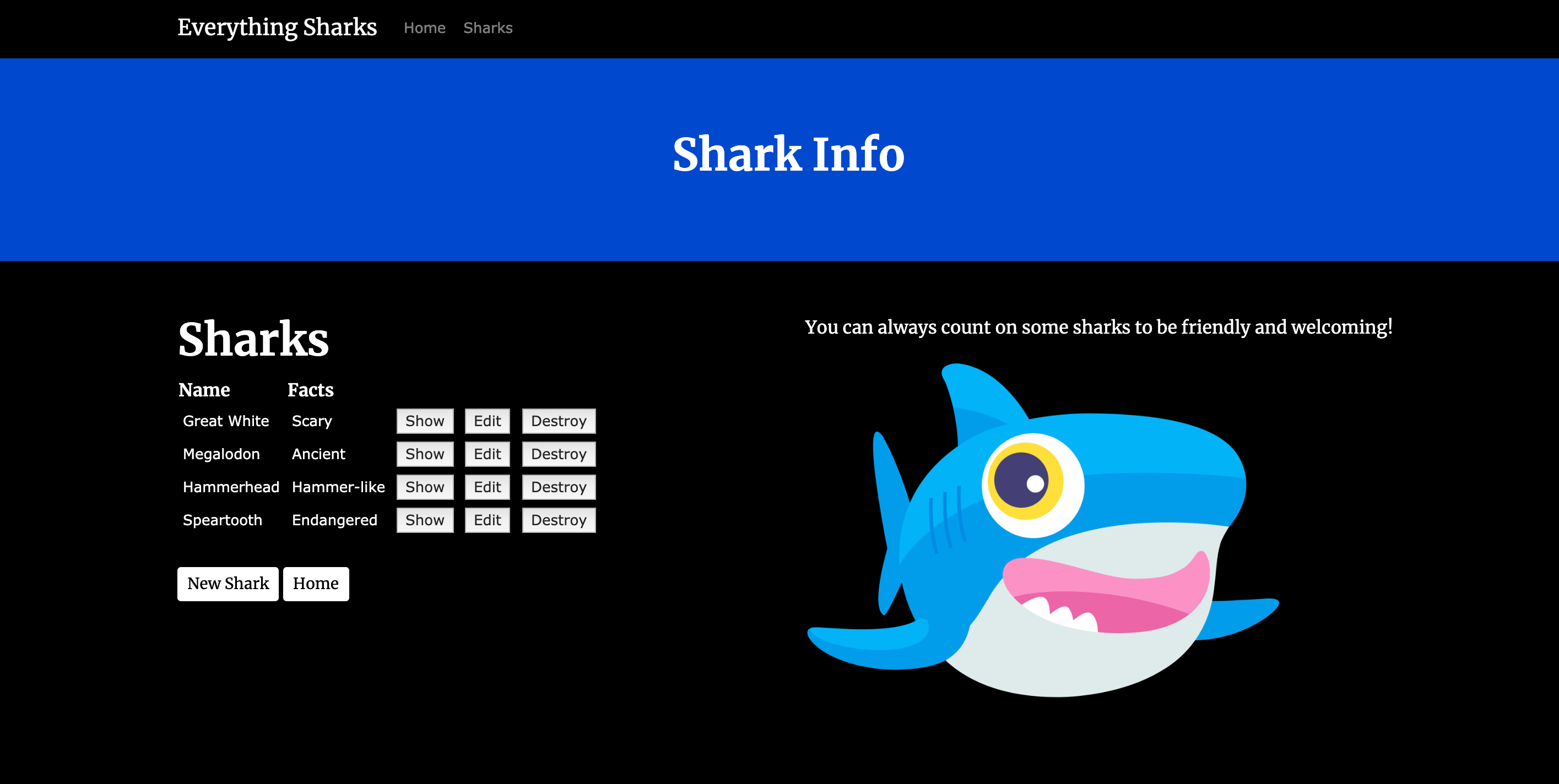
Um zu verifizieren, dass die Anwendung funktioniert, können wir ihr einige Demo-Informationen hinzufügen. Klicken Sie auf New Shark. Dank der Authentifizierungseinstellungen des Projekts werden Sie zur Eingabe des Benutzernamens (sammy) und Passworts (shark) aufgefordert.
Geben Sie auf der Seite New Shark unter Name „Mako“ und unter Facts „Fast“ ein.
Klicken Sie auf die Schaltfläche Create Shark, um den Hai zu erstellen. Wenn Sie den Hai erstellt haben, klicken Sie in der Navigationsleiste der Site auf Home, um zur Startseite der Anwendung zurückzukehren. Jetzt können wir testen, ob Sidekiq funktioniert.
Klicken Sie auf die Schaltfläche Which Sharks Are in Danger? . Da Sie keine gefährdeten Haie hochgeladen haben, wird Ihnen die Ansicht des gefährdeten Index gezeigt:

Klicken Sie auf Import Endangered Sharks, um die gefährdeten Haie zu importieren. Eine Statusmeldung teilt Ihnen mit, dass die Haie importiert wurden:

Sie sehen auch den Beginn des Imports. Aktualisieren Sie die Seite, um die gesamte Tabelle zu sehen:

Dank Sidekiq ist unser umfangreiches Batch-Upload der gefährdeten Haie gelungen, ohne den Browser zu blockieren oder die Funktionsweise anderer Anwendungen zu beeinträchtigen.
Klicken Sie auf die Schaltfläche Home unten auf der Seite, die Sie zur Hauptseite der Anwendung zurückbringen wird:
Klicken Sie hier erneut auf Which Sharks Are in Danger? . Sie sehen dann erneut die hochgeladenen Haie.
Da wir jetzt wissen, dass die Anwendung richtig funktioniert, können wir die Datenpersistenz testen.
Geben Sie am Terminal den folgenden Befehl ein, um die Container zu stoppen und zu entfernen:
- docker-compose down
Beachten Sie, dass die Option --volumes darin nicht enthalten ist; daher wird unser db_data-Volume nicht entfernt.
Die folgende Ausgabe bestätigt, dass die Container und das Netzwerk entfernt wurden:
OutputStopping rails-docker_sidekiq_1 ... done
Stopping rails-docker_app_1 ... done
Stopping rails-docker_database_1 ... done
Stopping rails-docker_redis_1 ... done
Removing rails-docker_sidekiq_1 ... done
Removing rails-docker_app_1 ... done
Removing rails-docker_database_1 ... done
Removing rails-docker_redis_1 ... done
Removing network rails-docker_default
Erstellen Sie die Container neu:
- docker-compose up -d
Öffnen Sie die Rails-Konsole im Container app mit docker-compose exec und bundle exec rails console:
- docker-compose exec app bundle exec rails console
Untersuchen Sie an der Eingabeaufforderung den letzten Hai-Datensatz in der Datenbank:
- Shark.last.inspect
Sie sehen den Datensatz, den Sie gerade erstellt haben:
IRB session Shark Load (1.0ms) SELECT "sharks".* FROM "sharks" ORDER BY "sharks"."id" DESC LIMIT $1 [["LIMIT", 1]]
=> "#<Shark id: 5, name: \"Mako\", facts: \"Fast\", created_at: \"2019-12-20 14:03:28\", updated_at: \"2019-12-20 14:03:28\">"
Hier können Sie prüfen, ob die gefährdeten Haie (Endangered) mit dem folgenden Befehl persistent gespeichert wurden:
- Endangered.all.count
IRB session (0.8ms) SELECT COUNT(*) FROM "endangereds"
=> 73
Ihr db_data-Volume wurde im neu eingerichteten Datenbank-Dienst erfolgreich bereitgestellt, damit Sie über den app-Dienst auf die gespeicherten Daten zugreifen können. Wenn Sie direkt zur index shark-Seite navigieren, indem Sie localhost:3000/sharks oder http://your_server_ip:3000/sharks aufrufen, wird Ihnen auch so der Datensatz angezeigt:

Die gefährdeten Haie finden Sie auch in der Ansicht auf localhost:3000/endangered/data oder http://your_server_ip:3000/endangered/data:
Die Anwendung wird jetzt in Docker Containern mit aktivierter Datenpersistenz und Codesynchronisierung ausgeführt. Sie können die lokalen Codeänderungen auf dem Host ausprobieren, die dank der bind-Bereitstellung, die wir im Rahmen des app-Dienstes festgelegt haben, mit dem Container synchronisiert werden.
Zusammenfassung
In diesem Tutorial haben Sie ein Entwicklungs-Setup für die Rails-Anwendung mit Docker Containern erstellt. Sie haben Ihr Projekt modularer und portabler gemacht, indem Sie sensible Informationen extrahiert und den Zustand der Anwendung vom Code entkoppelt haben. Sie haben auch eine docker-compose.yml-Standarddatei konfiguriert, die Sie je nach Ihren Entwicklungsbedürfnissen und -anforderungen ändern können.
Bei der Entwicklungsarbeit können Sie sich bei Interesse näher über das Konzipieren von Anwendungen für containerisierte und Cloud Native Workflows informieren. Weitere Informationen zu diesen Themen finden Sie in Anwendungen aufbauen für Kubernetes und Modernisierung von Anwendungen für Kubernetes. Wenn Sie in eine Fortbildung zu Kubernetes investieren möchten, sehen Sie sich den Leitfaden Kubernetes for Full-Stack Developers an.
Weitere Informationen über den Anwendungscode selbst entnehmen Sie den Tutorials der Reihe:
- So erstellen Sie eine Ruby-on-Rails-Anwendung
- So erstellen Sie verschachtelte Ressourcen für eine Ruby-on-Rails-Anwendung
- So fügen Sie einer Ruby-on-Rails-Anwendung Impulse hinzu
- So fügen Sie einer Ruby-on-Rails-Anwendung Bootstrap hinzu
- So fügen Sie einer Ruby-on-Rails-Anwendung Sidekiq und Redis hinzu
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Developer at DigitalOcean community. Expertise in areas including Ubuntu, Docker, Ruby on Rails, Debian, and more.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
