By Adrien Payong and Shaoni Mukherjee

Introduction
LLMs are most valuable when they’re used with the right approach for solving a problem. At a high level, there are 2 patterns you will gravitate towards: Retrieval-Augmented Generation and the Model Context Protocol. RAG is all about grounding answers in existing documents, knowledge bases, or manuals. MCP, on the other hand, is all about providing a model with the capabilities to retrieve live data or take action through tools, APIs, and workflows.
If your goal is traceable answers from structured knowledge, RAG is the response. If your application requires the latest data or systems interaction, MCP is the logical extension. However, the reality of real-world applications is often hybrid, where you use the two: RAG to give context and justification, MCP to take action, and RAG again to format an explanation back to the user.
This guide provides insights and decision-making guidelines for determining when to use each approach, along with known potential pitfalls. You’ll also see how RAG → MCP → RAG workflows are the backbone for production systems.
Key Takeaways
- Two complementary patterns: Interacting with LLMs tends to fall into one of two general patterns: retrieving knowledge (RAG) or making actions with tools (MCP).
- RAG excels at lookup tasks: Use RAG for static or semi-static knowledge bases where answers require grounding, citations, and explicit fact-traceability.
- MCP powers live actions: MCP is a better fit when a task involves working with APIs, databases, or workflows that require real-time data and state changes.
- Both have pitfalls: RAG has well-known challenges using stale content, chunking mismatches, or prompt overload. MCP is riskier when tools are poorly specified, tool calls risk getting stuck in loops, or tool side-effects are potentially unsafe.
- Many production scenarios blend both—retrieving knowledge with RAG, then acting with MCP, and returning to RAG for explanation and justification.
- Many production scenarios use a hybrid flow that mixes both — retrieval with RAG, followed by action with MCP, and returns to RAG for explain-and-justify.
Prerequisites
- Familiar with LLMs: Understand what large language models are and how they process inputs/outputs.
- Comfortable with APIs and Databases: Understand the role of APIs, tool calls, structured data sources, etc.
- Awareness of retrieval concepts: A working understanding of search, indexing, embeddings, TF-IDF, or at least the jargon, will help you follow the sections on RAG.
- Programming literate (Python): Since we have some example code (dataclasses, tool registries, retrievers) in Python, it’s helpful to be able to understand scripts.
- Systems-minded: Expect to think about trade-offs, failure modes, and hybrid flows when building real-world AI applications.
Understanding RAG and MCP (Quick Definitions)
We will clarify the meaning of each term before discussing how to choose between them.
- Retrieval-Augmented Generation (RAG): This involves wrapping an LLM with a retrieval step (search or a vector database). You index the content (split documents into chunks, get embeddings, and store them in an index). When a query comes in, the system retrieves the most relevant chunks from the index and augments the input to the LLM. The model then generates an answer based on the retrieved information.
- Model Context Protocol (MCP): This is a formal contract design to integrate external data sources and tools into the model. A MCP-based setup will typically have a set of tools registered (functions, APIs, database queries, …) with their interfaces (name and JSON schema for the input/output). The model can, when presented with a task, choose to invoke one of those tools by outputting a structured call (i.e., a JSON with parameters filled in). A host environment monitors these calls, then triggers the related function/API call, and sends the result back to the model.
Identify Scenarios Best Suited for RAG
In general, RAG should be your default solution in any situation where the information you’re trying to find is already documented or relatively static. You should consider RAG if:
- The answer is somewhere in your static or semi-static body of knowledge: policy documents, product specifications, runbooks, academic papers, etc.
- You require traceability and fact-based answers. With RAG, you can always have the model cite sources or show you exactly which document and section provided the information.
- Ultra-low latency isn’t a strict requirement (within reason). If your domain can handle a little bit of latency and doesn’t need to invoke external APIs in real-time for each query, RAG is a good fit.
Identify Scenarios Best Suited for MCP
MCP excels when static documents are not enough. You would want to choose an MCP (tool-using) approach if:
- You want to include up-to-date or dynamic data not contained in the documents. When the data you need lives behind an API or database and is likely to change over time (such as product stock levels, weather, user account information, and more), the model uses a tool to access the latest version of that data.
- You’d like the model to take an action rather than simply provide an answer. Actions can be like “Create a support ticket for this issue”, “Send a welcome email to the new user”, or “Order 50 more units of product X”.
- Perform complex, multi-step workflows. With MCP, the model can plan and execute sequences of tool calls. For example, using data obtained from one API call as part of the decision to call another.
Recognize Potential Failure Modes
Both RAG and MCP have failure modes. Knowing them in advance lets you build a more robust system. Here are some common failure modes to be aware of:
RAG Failure Modes:
- Stale/Missing Content: If your document corpus is out-of-date or does not actually contain the answer, retrieval won’t produce it out of thin air.
- Chunking or Recall Problems*:* RAG systems often split documents into smaller parts for indexing. If the relevant fact is split across chunks or the query uses different wording/synonyms than the stored text, the retriever may not select the correct passage.
- Overloaded Context*:* Drowning your prompt in too many retrieved chunks (i.e., beyond the model’s context window size or too much irrelevant text) can hurt model performance.
MCP Failure Modes:
- Poor Tool Definitions*:* If the tools made available to the model have unclear names, poorly worded descriptions, or inputs/outputs with badly specified schemas, the model may not use them correctly.
- Planning Loops or Tool Misuse*:* An unbounded model can enter an infinite loop or keep calling tools in cycles when it’s uncertain how to solve a problem (especially if the tool calls do not provide the necessary answer, and there is no guardrail to prevent further attempts).
- Security and Side-Effects*:* Allowing a model to take actions also requires us to consider the potential side effects. For example, if a tool is called without authorization, it may be abused (e.g., a tool that reads arbitrary information may be misused to read private or restricted information).
Awareness of these failure modes would shape the corresponding safeguards. For instance, you need to curate a high-quality knowledge base for RAG, with good retrieval strategies, provide well-defined tool schemas and usage policies for MCP, and set guardrails for actions.
Choosing RAG vs MCP – Quick Rules
Below are some simple guidelines that can be applied to determine which approach to start with for a given query or feature:
- If the question can be answered by simply reading some existing text, use RAG. Ask: “Is the information already written down somewhere that the system has access to?” If so, chances are it’s a retrieval problem.
- If the task is a query against live data or an action, use MCP (tools). If a human would solve the request by looking something up in a database or clicking a button in a system, that’s a very strong hint that the assistant should use a tool.
- If both knowledge and action are required by the user’s request, consider a hybrid approach. Some real-world problems will require both. First, some knowledge needs to be retrieved, such as a policy or rule; then, action will be taken; and then the result of that action must be explained. The RAG → MCP → RAG pattern is a very common recipe.
RAG vs MCP Demo: Bookstore Ops Assistant
This demo illustrates two modes for answering user questions about how a bookstore operates. On the RAG side, the answer is retrieved from a static “handbook” of policies. On the MCP-style tools side, the answer is returned by calling a live function to fetch inventory status or take an action. In this code, RAG is implemented as a small TF-IDF retriever over some static policy texts. The “MCP-style” tools are simulated by simple Python functions (note that no actual LLM is being used).
Setup & Imports
"""
Run locally:
python -m pip install --upgrade pip
pip install gradio scikit-learn numpy pandas
python RAG_vs_MCP_Demo_App.py
"""
from __future__ import annotations
import re
import json
from dataclasses import dataclass, asdict
from typing import Any, Callable, Dict, List, Tuple, Optional
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import gradio as gr
Static Handbook Retrieval (RAG)
The RAG component views the policy “handbook” as a small knowledge base. The code saves 4 policy documents (returns, shipping, membership, gift cards) to DOCS. It fits a TfidfVectorizer(stop_words=“english”) on these texts to create a term-document matrix.
TF-IDF (Term Frequency–Inverse Document Frequency) is a numerical statistic that weighs a word based on how important it is to a document within a corpus. The user query is vectorized with the same TF-IDF model, and cosine similarity is computed between the query and document vectors.
# ------------------------------
# 1) Tiny knowledge base (handbook) for RAG
# ------------------------------
DOCS = [
{
"id": "policy_returns",
"title": "Returns & Refunds Policy",
"text": (
"Customers can return most new, unopened items within 30 days of delivery for a full refund. "
"Items must be in their original condition with receipt. Refunds are processed to the original payment method. "
"Defective or damaged items are eligible for free return shipping."
),
},
{
"id": "policy_shipping",
"title": "Shipping Policy",
"text": (
"Standard shipping typically takes 3 to 5 business days. Expedited shipping options are available at checkout. "
"International orders may take 7 to 14 business days depending on destination and customs."
),
},
{
"id": "policy_membership",
"title": "Membership Benefits",
"text": (
"Members earn 2 points per dollar spent, get early access to new releases, and receive a monthly newsletter with curated picks. "
"Points can be redeemed for discounts at checkout."
),
},
{
"id": "policy_giftcards",
"title": "Gift Cards",
"text": (
"Gift cards are available in denominations from $10 to $200 and are redeemable online or in-store. "
"They do not expire and cannot be redeemed for cash except where required by law."
),
},
]
# Fit a very small TF‑IDF retriever at startup
VECTORIZER = TfidfVectorizer(stop_words="english")
KB_TEXTS = [d["text"] for d in DOCS]
KB_MATRIX = VECTORIZER.fit_transform(KB_TEXTS)
def rag_retrieve(query: str, k: int = 3) -> List[Dict[str, Any]]:
"""Return top-k documents as {id,title,text,score}."""
if not query.strip():
return []
q_vec = VECTORIZER.transform([query])
sims = cosine_similarity(q_vec, KB_MATRIX)[0]
idxs = np.argsort(-sims)[:k]
results = []
for i in idxs:
results.append({
"id": DOCS[i]["id"],
"title": DOCS[i]["title"],
"text": DOCS[i]["text"],
"score": float(sims[i]),
})
return results
def rag_answer(query: str, k: int = 3) -> Tuple[str, List[Dict[str, Any]]]:
"""Simple, template-y answer based on top-k docs."""
hits = rag_retrieve(query, k=k)
if not hits:
return ("I couldn't find anything relevant in the handbook.", [])
# Compose a short grounded answer using snippets
bullets = []
for h in hits:
# Take the first sentence as a snippet
first_sentence = h["text"].split(".")[0].strip()
if first_sentence:
bullets.append(f"- **{h['title']}**: {first_sentence}.")
answer = (
"**Handbook says:**\n" + "\n".join(bullets) +
"\n\n(Answer generated from retrieved policy snippets; no LLM used.)"
)
return answer, hits
The RAG retrieval works as follows:
- Index Policy Texts: Transform each paragraph of the handbook into a TF-IDF vector.
- Embed Query: Vectorize the user’s question into a TF-IDF vector using the same vectorizer.
- Compute Similarity: Calculate a cosine similarity score between each policy document and the query.
- Retrieve Top Docs: Select the top k documents with the highest similarity scores as relevant hits.
This is a toy substitute for a more complete RAG pipeline that would use neural embeddings. After identifying the top policy hits, rag_answer() is used to compose a short answer. For each hit, it extracts the first sentence of the policy text and formats it as a bullet point with the policy title.
MCP-Style Tools (Live Inventory)
The “MCP” part of the demo code represents how an assistant would call functions to manipulate real-time inventory data.
# ------------------------------
# 2) MCP-style tool registry + client executor
# ------------------------------
@dataclass
class ToolParam:
name: str
type: str # e.g., "string", "number", "integer"
description: str
required: bool = True
@dataclass
class ToolSpec:
name: str
description: str
params: List[ToolParam]
@dataclass
class ToolCall:
tool_name: str
args: Dict[str, Any]
@dataclass
class ToolResult:
tool_name: str
args: Dict[str, Any]
result: Any
ok: bool
error: Optional[str] = None
# In-memory "live" inventory
INVENTORY: Dict[str, Dict[str, Any]] = {
"Dune": {"stock": 7, "price": 19.99},
"Clean Code": {"stock": 2, "price": 25.99},
"The Pragmatic Programmer": {"stock": 5, "price": 31.50},
"Deep Learning": {"stock": 1, "price": 64.00},
}
# Define actual tool functions
def tool_get_inventory(title: str) -> Dict[str, Any]:
rec = INVENTORY.get(title)
if not rec:
return {"title": title, "found": False, "message": f"'{title}' not in inventory."}
return {"title": title, "found": True, **rec}
def tool_set_price(title: str, new_price: float) -> Dict[str, Any]:
rec = INVENTORY.get(title)
if not rec:
return {"title": title, "updated": False, "message": f"'{title}' not in inventory."}
rec["price"] = float(new_price)
return {"title": title, "updated": True, **rec}
def tool_place_order(title: str, quantity: int) -> Dict[str, Any]:
rec = INVENTORY.get(title)
if not rec:
return {"title": title, "ordered": False, "message": f"'{title}' not in inventory."}
if quantity <= 0:
return {"title": title, "ordered": False, "message": "Quantity must be positive."}
rec["stock"] += int(quantity)
return {"title": title, "ordered": True, "added": int(quantity), **rec}
# Registry of specs (like MCP manifests)
TOOL_SPECS: Dict[str, ToolSpec] = {
"get_inventory": ToolSpec(
name="get_inventory",
description="Get stock and price for a given book title.",
params=[
ToolParam("title", "string", "Exact book title"),
],
),
"set_price": ToolSpec(
name="set_price",
description="Update the price for a book title.",
params=[
ToolParam("title", "string", "Exact book title"),
ToolParam("new_price", "number", "New price in dollars"),
],
),
"place_order": ToolSpec(
name="place_order",
description="Increase stock by ordering more copies.",
params=[
ToolParam("title", "string", "Exact book title"),
ToolParam("quantity", "integer", "How many copies to add"),
],
),
}
# Mapping tool names to callables
TOOL_IMPLS: Dict[str, Callable[..., Any]] = {
"get_inventory": tool_get_inventory,
"set_price": tool_set_price,
"place_order": tool_place_order,
}
def validate_and_call(call: ToolCall) -> ToolResult:
spec = TOOL_SPECS.get(call.tool_name)
if not spec:
return ToolResult(tool_name=call.tool_name, args=call.args, result=None, ok=False, error="Unknown tool")
# minimal validation
for p in spec.params:
if p.required and p.name not in call.args:
return ToolResult(tool_name=call.tool_name, args=call.args, result=None, ok=False, error=f"Missing param: {p.name}")
try:
fn = TOOL_IMPLS[call.tool_name]
result = fn(**call.args)
return ToolResult(tool_name=call.tool_name, args=call.args, result=result, ok=True)
except Exception as e:
return ToolResult(tool_name=call.tool_name, args=call.args, result=None, ok=False, error=str(e))
The code itself defines an in-memory list of books, with each book having an associated stock count and price. It also defines 3 tool functions for inspecting/updating that inventory:
- get_inventory(title: str): Look up a book by title and return its stock and price, or a not-found message.
- set_price(title: str, new_price: float): Update the book’s price to the given value.
- place_order(title: str, quantity: int): Increase the stock of the book by the given quantity (simulating an order for more copies).
These are all registered in a simple in-memory tool registry. The ToolSpec for each tool contains its name, description, and parameter schema (name, type, description). This is similar to how MCP or function-calling frameworks would define tools with structured input schemas. A real LLM API would similarly expose these tools with JSON schemas for their title and price parameters.
MCP “standardizes how tools are defined, hosted, and exposed to LLMs” and makes it easy for a model to discover and use. Our Python code leverages simple dataclasses (ToolParam, ToolSpec, etc) to capture those schemas.
A function validate_and_call() takes a proposed ToolCall (tool name + args) and calls the Python function it represents, returning a ToolResult (output or error). This is analogous to a backend receiving the model’s function-call request and running that API call in a deployed LLM system.
Routing Queries: RAG vs Tools vs Both
The app can launch in either Auto, RAG only, or Tools only mode. When using Auto mode, the app uses basic heuristics to determine how to route each query.
- If the query has a policy keyword, it enables RAG retrieval.
- If it contains a keyword like “in stock”, “price”, or “order” and a quoted title, it will trigger a tool call.
- If both types of needs are present (e.g., “Dune…return policy”), the code sets the route to both so it will perform a retrieval and call a tool.
- Otherwise, it defaults to one or the other mode…
This reflects the general idea that RAG is for static knowledge lookup while function calls are for dynamic data or actions.
# ------------------------------
# 3) Simple planner/router: choose RAG vs Tools (MCP-style) vs Both
# ------------------------------
TOOL_KEYWORDS = {
"get_inventory": ["in stock", "stock", "available", "availability", "have", "inventory"],
"set_price": ["change price", "set price", "update price", "price to", "discount", "mark down"],
"place_order": ["order", "restock", "add", "increase stock"],
}
BOOK_TITLE_PATTERN = r"'([^']+)'|\"([^\"]+)\"" # capture 'Title' or "Title"
def extract_titles(text: str) -> List[str]:
titles = []
for m in re.finditer(BOOK_TITLE_PATTERN, text):
titles.append(m.group(1) or m.group(2))
return titles
def decide_tools(query: str) -> Optional[ToolCall]:
q = query.lower()
titles = extract_titles(query)
# get_inventory
if any(kw in q for kw in TOOL_KEYWORDS["get_inventory"]):
if titles:
return ToolCall(tool_name="get_inventory", args={"title": titles[0]})
# set_price (look for a number)
if any(kw in q for kw in TOOL_KEYWORDS["set_price"]):
price_match = re.search(r"(\d+\.?\d*)", q)
if titles and price_match:
return ToolCall(tool_name="set_price", args={"title": titles[0], "new_price": float(price_match.group(1))})
# place_order (look for an integer quantity)
if any(kw in q for kw in TOOL_KEYWORDS["place_order"]):
qty_match = re.search(r"(\d+)", q)
if titles and qty_match:
return ToolCall(tool_name="place_order", args={"title": titles[0], "quantity": int(qty_match.group(1))})
return None
def route_query(query: str, mode: str = "Auto") -> str:
if mode == "RAG only":
return "rag"
if mode == "Tools only":
return "tools"
# Auto: detect whether we need tools, rag, or both
# If a single sentence includes both a policy question + inventory check, we'll call it "both".
needs_tool = decide_tools(query) is not None
needs_rag = any(ch in query.lower() for ch in ["policy", "return", "refund", "shipping", "membership", "gift card", "gift cards", "benefits"])
if needs_tool and needs_rag:
return "both"
if needs_tool:
return "tools"
return "rag"
In this example demo,
- a question like “What is our returns policy?” contains the word “returns,” → which triggers RAG.
- “Do we have ‘Dune’ in stock?” question contains “in stock” and a quoted title → which triggers the get_inventory tool.
- If a user combines those two, “Do we have ‘Dune’ in stock, and what is our return policy?” then both routes would be triggered. The answer would therefore include a part from the handbook and a part from the live inventory.
Handling the Query and Composing the Answer
The handle_query(q, mode, show_trace) function below performs the above routing and produces the final answer.
# ------------------------------
# 4) Orchestrator: build a human-friendly answer + trace
# ------------------------------
def handle_query(query: str, mode: str = "Auto", show_trace: bool = True) -> Tuple[str, str, pd.DataFrame]:
route = route_query(query, mode=mode)
tool_trace: List[Dict[str, Any]] = []
rag_hits: List[Dict[str, Any]] = []
parts: List[str] = []
if route in ("rag", "both"):
rag_ans, rag_hits = rag_answer(query)
parts.append(rag_ans)
if route in ("tools", "both"):
call = decide_tools(query)
if call:
res = validate_and_call(call)
tool_trace.append(asdict(call))
tool_trace[-1]["result"] = res.result
tool_trace[-1]["ok"] = res.ok
if res.error:
tool_trace[-1]["error"] = res.error
# Compose a user-friendly tool result string
if res.ok and isinstance(res.result, dict):
if call.tool_name == "get_inventory":
if res.result.get("found"):
parts.append(
f"**Inventory:** '{res.result['title']}' -- stock: {res.result['stock']}, price: ${res.result['price']:.2f}"
)
else:
parts.append(f"**Inventory:** {res.result.get('message','Not found')}" )
elif call.tool_name == "set_price":
if res.result.get("updated"):
parts.append(
f"**Price updated:** '{res.result['title']}' is now ${res.result['price']:.2f}"
)
else:
parts.append(f"**Set price failed:** {res.result.get('message','Error')}" )
elif call.tool_name == "place_order":
if res.result.get("ordered"):
parts.append(
f"**Order placed:** Added {res.result['added']} copies of '{res.result['title']}'. New stock: {res.result['stock']}"
)
else:
parts.append(f"**Order failed:** {res.result.get('message','Error')}" )
else:
parts.append("Tool call failed.")
else:
parts.append("No suitable tool call inferred from your request.")
# Prepare trace artifacts
trace = {
"route": route,
"tool_calls": tool_trace,
"retrieved_docs": rag_hits,
}
# DataFrame for retrieved docs (for a quick visual)
df = pd.DataFrame([
{
"id": h["id"],
"title": h["title"],
"score": round(h["score"], 3),
"snippet": h["text"][:140] + ("..." if len(h["text"])>140 else ""),
}
for h in rag_hits
])
answer_md = "\n\n".join(parts) if parts else "(No answer composed.)"
trace_json = json.dumps(trace, indent=2)
return answer_md, trace_json, df
It does roughly the following:
- RAG part: For the RAG process, we call rag_answer(q). This returns a Markdown string and the retrieved docs.
- Tool part: If we need to run a tool, then we call decide_tools(q) to get a ToolCall. validate_and_call() executes the tool and returns a result.
- Combine answers: The RAG snippet-answer and the tool-answer string are concatenated with newlines in between. If the route was “both”, then both parts will be present. If only one is used, then the other part is simply omitted.
User Interface (Gradio Demo)
In Gradio, the UI (gr.Blocks) includes a title and instructions, a textbox for the user’s request, a dropdown to select the mode (Auto, RAG only, Tools only), and a “Run” button. Below the inputs, it displays the Answer (Markdown), the Trace (JSON), and a table of retrieved docs.
With Gradio managing the web server and rendering, the code is focused on the logic. When the user clicks “Run”, it invokes the handle_query() function with the inputs. The interface then displays the composed answer and the underlying trace. Running the script will start a local web page where one can type queries and see the live results.
# ------------------------------
# 5) Gradio UI
# ------------------------------
with gr.Blocks(title="RAG vs MCP Demo: Bookstore Ops Assistant") as demo:
gr.Markdown(
"# RAG vs MCP Demo: Bookstore Ops Assistant\n"
"Use this sandbox to feel the difference between RAG (lookup from a handbook) and MCP-style tools (act on live data).\n\n"
"**Tips**: Put book titles in quotes, e.g., 'Dune' or \"Clean Code\"."
)
with gr.Row():
query = gr.Textbox(label="Your request", placeholder="e.g., Do we have 'Dune' in stock? Or: What is our returns policy?", lines=2)
with gr.Row():
mode = gr.Dropdown(["Auto", "RAG only", "Tools only"], value="Auto", label="Routing mode")
show_trace = gr.Checkbox(True, label="Show trace")
submit = gr.Button("Run", variant="primary")
answer = gr.Markdown(label="Answer")
trace = gr.JSON(label="Trace (route, tool calls, retrieved docs)")
table = gr.Dataframe(headers=["id", "title", "score", "snippet"], label="Retrieved docs (RAG)")
def _run(q, m, t):
ans, tr, df = handle_query(q or "", mode=m or "Auto", show_trace=bool(t))
return ans, json.loads(tr), df
submit.click(_run, inputs=[query, mode, show_trace], outputs=[answer, trace, table])
if __name__ == "__main__":
demo.launch()
Output:
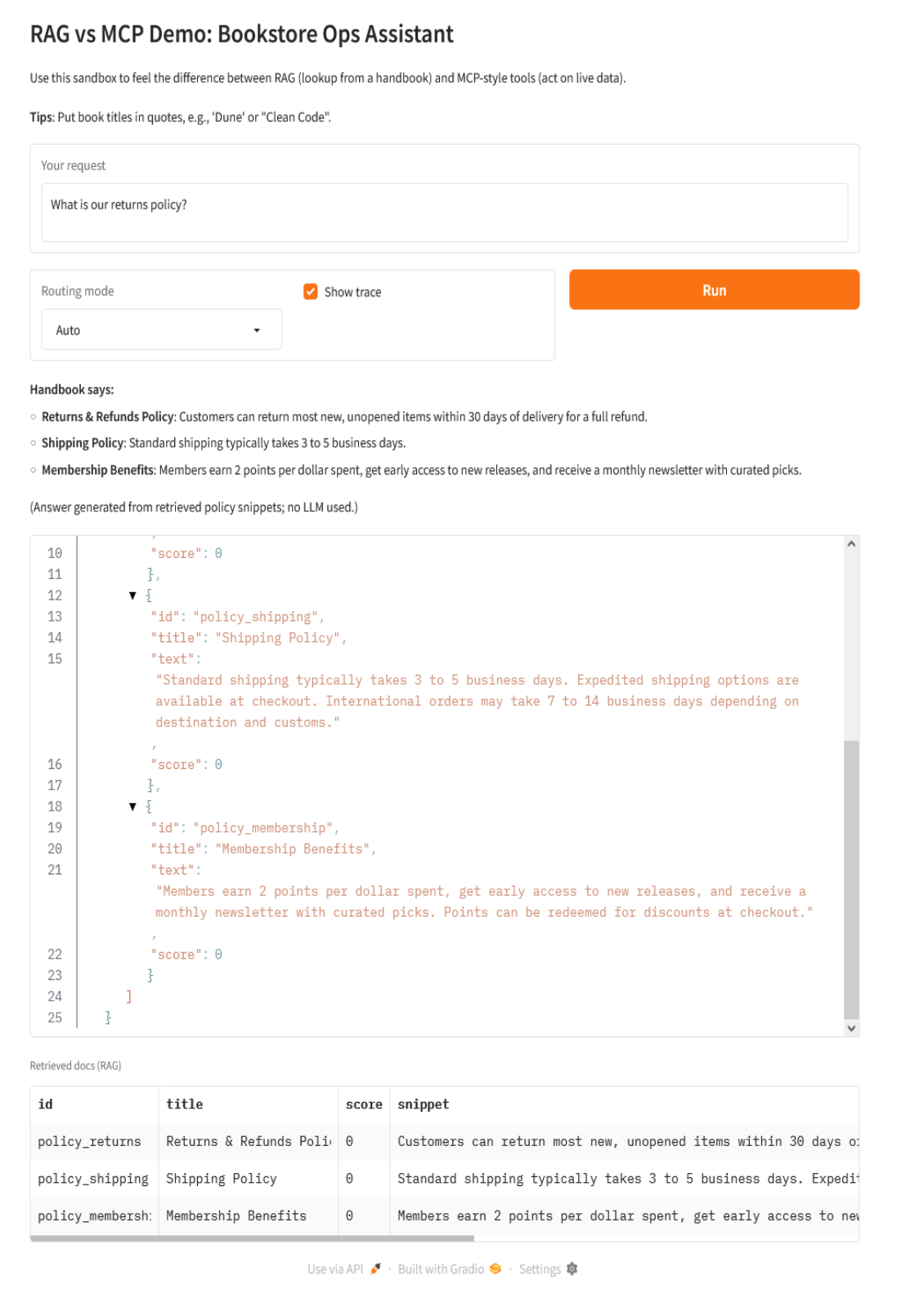
You can try the following queries:
- “What is our returns policy?”
- “How long does standard shipping take?”
- “Do we have ‘Dune’ in stock?”
- “Order 3 copies of ‘The Pragmatic Programmer’”
- “Change the price of ‘Clean Code’ to 29.99”
- “Do we have ‘Dune’ in stock, and what is our return policy?”
These examples will illustrate RAG with static FAQ-style information and tools operating on live data. In practice, many modern AI systems are hybrid. For example, a customer support chatbot could pull an account’s data through API calls, and also reference product documentation stored in a knowledge base.
FAQ SECTION
1. When should I use RAG instead of MCP?
Answer questions for which the answer already exists in a documented knowledge base, whether in the form of policies, specs, manuals, or FAQs. The RAG approach is best for questions that need fact-based responses or when real-time updates aren’t critical.
2. When is MCP the better choice?
Choose MCP if you need to use or work with live data. You can also choose it if the query relies on APIs, databases, or if the model must execute an action (create a ticket, send an email, etc. ).
3. What are the main risks of each approach?
- RAG risks*:* Outdated or missing documents, poor retrieval due to chunking/synonym mismatch, and overloading the model with irrelevant chunks.
- MCP risks*:* Poorly defined tools (unknown schemas or tool names), the model gets stuck in loops or misuses tools, and potential security implications if tools allow unintended actions.
4. Can I combine RAG and MCP in a single workflow?
Yes. In fact, many real cases will need both. For example, the assistant might first fetch the warranty policy via RAG, then place the order for a replacement device with MCP, and finally confirm the action by citing the relevant policy. The “RAG → MCP → RAG” flow is very common in production systems.
5. How do I decide quickly between RAG and MCP for a new query?
A simple rule:
- If a human were to “look it up in a document,” use RAG.
- If a human would “click a button or query a database,” use MCP.
Conclusion
Think of RAG as how you read what you know, and MCP as how you do things (and access live data). In practice, you probably start with RAG when answers are already in the docs and citations are required. Reach for MCP when a task involves APIs, databases, or a workflow of any kind. Once both are well-architected, combine them to create end-to-end flows (RAG → MCP → RAG) that both justify decisions and take action.
If you actually want an out-of-the-box MCP server to manage your infrastructure, DigitalOcean ships an open-source MCP server that interfaces with MCP-compatible clients (Claude Desktop/Code, Cursor, etc.). You supply a DO API token, register the server, and then natural-language prompts such as “deploy this repo to App Platform” or “show logs for service X” can be transformed into API calls. It’s a nice way to hook up the “action” half of your stack without writing your own glue code.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
