
Introduction
Graphite is a graphing library that allows you to visualize different kinds of data in a flexible and powerful way. It graphs data sent to it by other statistics collecting applications.
In previous guides, we discussed how to install and configure Graphite itself and how to install and configure collectd for compiling system and services statistics.
In this guide, we’ll discuss how to install and configure StatsD. StatsD is a lightweight statistics gathering daemon that can be used to collect arbitrary statistics.
StatsD flushes stats to Graphite in sync with Graphite’s configured write interval. To do this, it aggregates all of the data between flush intervals and creates single points for each statistic to send to Graphite.
In this way, StatsD lets applications work around the effective rate-limit for sending Graphite stats. It has many libraries written in different programming languages that make it trivial to build in stats tracking with your applications.
In this guide, we’ll install and configure StatsD. We will assume that you’ve followed the installation instructions from the previous guides and that you have both Graphite and collectd configured on your Ubuntu 14.04 server.
Install StatsD
The StatsD program is not available in the Ubuntu default repositories. However, it is available on GitHub and has the configuration files necessary to compile it into an Ubuntu package.
Acquire the Components
Before we install the actual program, we need to get a few packages from the repositories. We need git so that we can clone the repository. We also need node.js because StatsD is a node application.
We also need a few packages that will allow us to build an Ubuntu package. Let’s get all of those now:
sudo apt-get install git nodejs devscripts debhelper
We are going to create the package in our home directory. More specifically, we will create a directory called “build” in our home directory to complete this process.
Create the directory now:
mkdir ~/build
Now, we will clone the StatsD project into that directory. Move into the directory and then issue the clone command:
cd ~/build
git clone https://github.com/etsy/statsd.git
Build and Install the Package
Move into the new directory that contains our StatsD files:
cd statsd
Now, we can create the StatsD package by simply issuing this command:
dpkg-buildpackage
A .deb file will be created in ~/build directory. Let’s move back out into that directory.
cd ..
Before we install the package, we want to stop our Carbon service. The reason for this is that the StatsD service will immediately start sending information when it is installed and it is not yet configured properly.
Stop the Carbon service for the moment by issuing this command:
sudo service carbon-cache stop
We can then install the package into our system:
sudo dpkg -i statsd*.deb
As we said before, the Statsd process starts automatically. Let’s stop it for the moment and restart our Carbon service. This will allow us to configure StatsD while still leaving Carbon active for our other services:
sudo service statsd stop
sudo service carbon-cache start
The StatsD service is now installed on our server! However, we still need to configure all of our components to work correctly together.
Configure StatsD
The first thing that we should do is modify the StatsD configuration file.
Open the file with your text editor:
sudo nano /etc/statsd/localConfig.js
It should look like this:
<pre> { graphitePort: 2003 , graphiteHost: “localhost” , port: 8125 } </pre>
We only want to adjust one setting in this configuration. We want to turn off something called legacy namespacing.
StatsD uses this to organize its data in a different way. In more recent versions, however, it has standardized on a more intuitive structure. We want to use the new format.
To do this, we need to add the following lines:
<pre> { graphitePort: 2003 , graphiteHost: “localhost” , port: 8125 <span class=“highlight”>, graphite: {</span> <span class=“highlight”>legacyNamespace: false</span> <span class=“highlight”>}</span> } </pre>
This will let us use more sensible naming conventions. Save and close the file when you are finished.
Create a Storage Schema for StatsD
Next, we need to define some more storage-schemas.
Open the storage-schema file:
sudo nano /etc/carbon/storage-schemas.conf
We are going to use exactly the same retention policy that we defined for collectd. The only difference is the name and the matching pattern.
StatsD sends all of its data to Graphite with a stats prefix, so we can match on that pattern. Remember to put this above the default storage specification:
[statsd]
pattern = ^stats.*
retentions = 10s:1d,1m:7d,10m:1y
Save and close the file when you are finished.
Create a Data Aggregation Configuration
Let’s set up some aggregation specifications. StatsD sends data in a very specific way, so we can easily ensure that we are aggregating the data correctly by matching the correct patterns.
Open the file in your editor:
sudo nano /etc/carbon/storage-aggregation.conf
We need to configure our aggregation in a flexible manner to convert our values accurately. We will take some cues from the StatsD project on how best to aggregate the data.
Right now, the aggregation looks like this:
<pre> [min] pattern = .min$ xFilesFactor = 0.1 aggregationMethod = min
[max] pattern = .max$ xFilesFactor = 0.1 aggregationMethod = max
[sum] pattern = .count$ xFilesFactor = 0 aggregationMethod = sum
[default_average] pattern = .* xFilesFactor = 0.5 aggregationMethod = average </pre>
We want to match metrics that end with .sum or .count and add the values to aggregate them. We already have one of those defined (with the sum section), but it’s a bit mislabeled, so we’ll adjust that.
We also want to take the min and max values for metrics ending in .lower and .upper respectively. These metric names might have numbers after them as well since they can be used to indicate the upper value of a certain percentage ( upper_90 for instance).
Finally, we want to configure our gauges, which are basically just measuring the current value of something (like a speedometer). We want to set these to always send the last value we gave it. We wouldn’t want to use the average or any other calculated value in this case.
In the end, the file should look something like this:
<pre> [min] pattern = .min$ xFilesFactor = 0.1 aggregationMethod = min
[max] pattern = .max$ xFilesFactor = 0.1 aggregationMethod = max
<span class=“highlight”>[count]</span> pattern = .count$ xFilesFactor = 0 aggregationMethod = sum
<span class=“highlight”>[lower]</span> <span class=“highlight”>pattern = .lower(_\d+)?$</span> <span class=“highlight”>xFilesFactor = 0.1</span> <span class=“highlight”>aggregationMethod = min</span>
<span class=“highlight”>[upper]</span> <span class=“highlight”>pattern = .upper(_\d+)?$</span> <span class=“highlight”>xFilesFactor = 0.1</span> <span class=“highlight”>aggregationMethod = max</span>
<span class=“highlight”>[sum]</span> <span class=“highlight”>pattern = .sum$</span> <span class=“highlight”>xFilesFactor = 0</span> <span class=“highlight”>aggregationMethod = sum</span>
<span class=“highlight”>[gauges]</span> <span class=“highlight”>pattern = ^..gauges..</span> <span class=“highlight”>xFilesFactor = 0</span> <span class=“highlight”>aggregationMethod = last</span>
[default_average] pattern = .* xFilesFactor = 0.5 aggregationMethod = average </pre>
Save and close it when you are finished.
Start the Services
Now that you have everything configured, we can do some service management.
First, you’re going to want to restart Carbon to pick up the new settings that you just set. It is better to fully stop the service, wait a few seconds and then start it than just using the “restart” command:
sudo service carbon-cache stop ## wait a few seconds here
sudo service carbon-cache start
Now, you can also start your StatsD service, which will connect to Carbon:
sudo service statsd start
Just like Carbon itself, StatsD reports on its own stats as well. This means that you can immediately see some new information if you visit your Graphite page in your browser again. Refresh the page if you already had it running:
<pre> http://<span class=“highlight”>domain_name_or_ip</span> </pre>
As you can see, we have quite a few different pieces of information available, all of which pertain to StatsD itself:
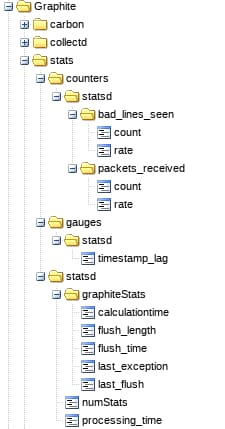
Let’s learn a little bit about how to feed StatsD data and how we can interact with it.
Anatomy of StatsD Data Metrics
The StatsD service connects to the Graphite service using a TCP connection. This allows for a reliable transfer of information.
However, StatsD itself listens for UDP packets. It collects all of the packets sent to it over a period of time (10 seconds by default). It then aggregates the packets it has received and flushes a single value for each metric to Carbon.
It is important to realize that the 10 second flush interval is exactly what we configured in our storage-schema as the shortest interval for storage. It is essential that these two configuration values match because it is what allows StatsD to get around the Carbon limitation of only accepting one value for each interval.
Because of the differences between these programs, we send data to StatsD in a slightly different way than when we send it straight to Graphite. If you recall, we send data to Graphite by specifying a metric name, a value, and a timestamp, like this:
<pre>
echo "<span class=“highlight”>metric_name metric_value</span> date +%s | nc -q0 127.0.0.1 2003
</pre>
This has some advantages, like allowing you to set the timestamp of the data you’re receiving, which can let you retroactively add data. For data sent to StatsD, we forego the use of the timestamp and instead replace it with the data type.
The syntax looks like this:
<pre> echo “<span class=“highlight”>metric_name</span>:<span class=“highlight”>metric_value</span>|<span class=“highlight”>type_specification</span>” | nc -u -w0 127.0.0.1 8125 </pre>
This will send a UDP packet to the port that StatsD is listening on.
Keep in mind that, just like with sending stats to Graphite directly, this is still not the way that stats are usually sent. The nc method is just for the purposes of demonstration.
There are many great StatsD client libraries that make it easy to send statistics from the apps you are creating using whatever programming logic makes sense. We’ll demonstrate this momentarily.
The metric name and value are pretty self explanatory. Let’s go over what the possible metric types are and what they mean to StatsD:
- c: This indicates a “count”. Basically, it adds up all of the values that StatsD receives for a metric within the flush interval and sends the total value. This is similar to the “sum” aggregation method that Carbon uses, which is why we told Carbon to use that aggregation method when storing longer intervals of this kind of metric.
- g: This indicates a gauge. A gauge tells the current value of something, similar to a speedometer or a fuel gauge. In these situations, we are only interested in the most recent value. StatsD will continue sending Carbon the same value until it receives a different value. Carbon aggregates this data using the “last” method to maintain the meaning of the information.
- s: This marking means the values passed are a mathematical set. Sets in mathematics contain unique values. So we can throw a bunch of values of this type at StatsD and it will count the number of times it received unique values. This could be useful for tasks like calculating the number of unique users (assuming you have a unique id attribute associated with those).
- ms: This indicates that the value is a time span. StatsD takes the timing value and actually creates quite a few different pieces of information based on the data. It passes Carbon information about averages, percentiles, standard deviation, sum, etc. Each of these must be aggregated by Carbon correctly, which is why we added quite a few aggregation methods.
As you can see, StatsD does a lot to make our metrics easier to digest. It talks about stats in ways that make sense to most applications and it will do a lot of the heavy lifting in terms of getting the data into the correct format as long as you tell it what the data represents.
Exploring the Different Data Types
Gauges
Let’s send some data to StatsD to try this out. The easiest one is a gauge. This will set the current state a metric, so it will only pass in the last value it receives:
echo "sample.gauge:14|g" | nc -u -w0 127.0.0.1 8125
Now, if after ten seconds (the flush rate of StatsD) we refresh the Graphite interface, we should see the new stat (it will be under the stats > gauges > sample hierarchy).
Notice how the line is uninterrupted this time. We can refresh the graph and there will be a value for every interval. Previously, Graphite would have gaps in its data from not receiving values for certain metrics over a period of time. With a gauge, StatsD sends over the last available value each time it flushes. It assumes you will just tell it when that value should change.
To see the change, let’s send it another few values for the gauge:
echo "sample.gauge:10|g" | nc -u -w0 127.0.0.1 8125
Now wait at least ten seconds so that StatsD sends that value, and then send:
echo "sample.gauge:18|g" | nc -u -w0 127.0.0.1 8125
You will see a graph that looks somewhat similar to this (we are looking at an 8 minute time frame):
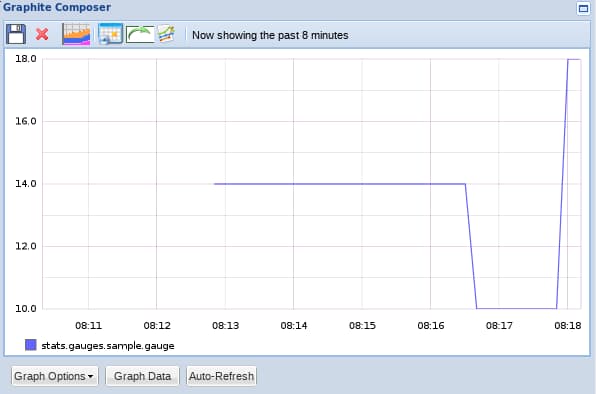
As you can see, this is very similar to the way that Graphite functions already, in that it only records one value for every ten second interval. The difference is that StatsD makes sure that the last known value is used for each interval.
Counts
Let’s contrast this a bit by configuring a count metric.
StatsD will collect all of the data it receives during its ten second flush interval and add them together to send a single value for that time frame. This more closely replicates the data that we want to record for most metrics.
For instance, we can fire a count metric to StatsD many times in a row:
echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
Now, assuming that these were all sent in the same interval (some of the values might have fallen on either side of an interval demarcation), we should see one value for the count when we refresh the interface. Make sure to adjust the interface to display only the past 5 to 15 minutes.
There are actually two metrics created. The count metric tells us the number of occurrences within our flush interval, and the rate metric divides that number by ten to arrive at the number of occurrences per second. These two would look like this:
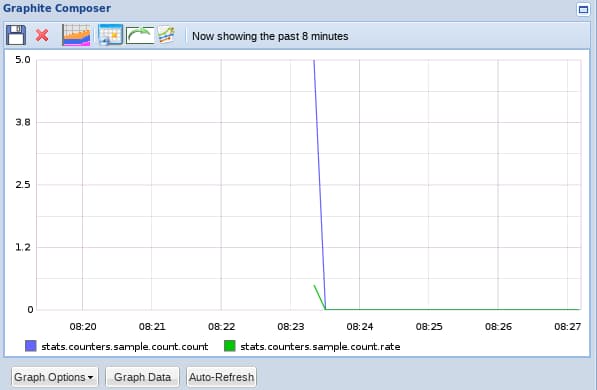
As you can see, unlike the gauge metrics, count metrics do not keep their value between flushes. This is what the metric means. If you are counting the number of times a user hits a button, just because he hits it twice in ten seconds does not mean that the next ten seconds the number is going to be two as well.
Sets
Let’s try a set now.
Remember, sets record the number of unique values that were passed to a metric. So we can send it five records, but if four of them have the same value, then the number recorded will be two, because that is the number of unique values:
echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
echo "sample.set:11|s" | nc -u -w0 127.0.0.1 8125
You can see in the following picture that my values originally straddled a flush interval, so only one number was recorded. I had to try again to get the sequence a second time:
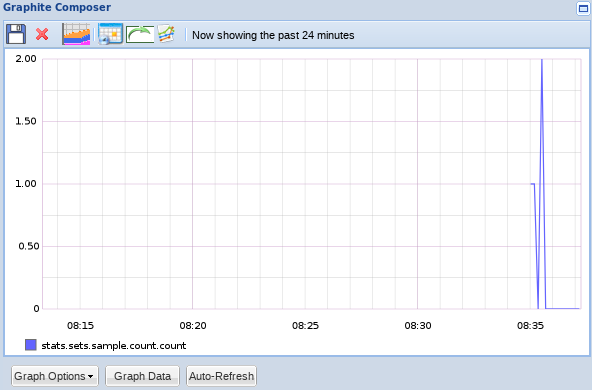
As you can see, the actual value that we pass is insignificant in a set. We only care about how many unique values were passed.
Timers
Timers are perhaps the most interesting metric.
StatsD does the most work in calculating data for timers. It sends Carbon many different metrics:
echo "sample.timer:512|ms" | nc -u -w0 127.0.0.1 8125
If we send it multiple values over the course of a few minutes, we can see many different pieces of information, like the average execution time, a count metric, the upper and lower values, etc.
It may look something like this:
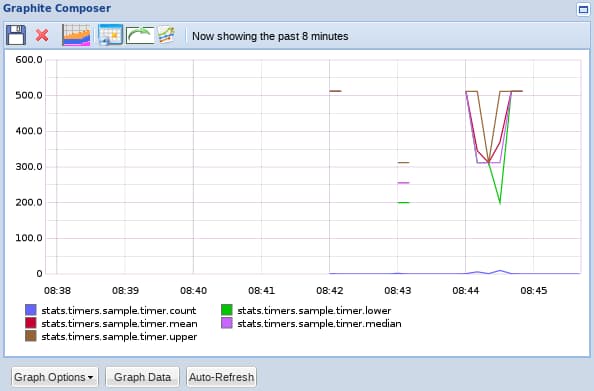
This is a great metric for feeding information about how programs you are creating are executing. It can tell you if changes you are making are slowing down your application.
Feeding StatsD Metrics
Now that you have an understanding of how the packets are structured, let’s briefly take a look at one of the StatsD libraries that we can use to send data within our program. Any language that has the capabilities of sending UDP packets can create StatsD metrics, but libraries can make this especially simple.
Since Graphite uses Django, let’s stay in that environment and check out a Python library.
First, install pip, a Python package manager:
sudo apt-get install python-pip
Now, we can tell it to install the latest version of the python-statsd package by typing:
sudo pip install python-statsd
This is a very simple StatsD client.
Start up a Python interactive session to load the library:
python
Now, we can import the library by typing:
import statsd
From here, the usage is really simple. We can create objects that represent our various metrics and then adjust them as we wish.
For instance, we can create a gauge object and then set it to 15 by typing:
gauge = statsd.Gauge('Python_metric')
gauge.send('some_value', 15)
We can then use the gauge.send to send whatever values we want to StatsD. The library has similar functionality with the other metric types. You can learn about them by looking at the project’s page.
You should have a pretty good idea of how to build tracking into your applications. The ability to send arbitrary metrics to StatsD for tracking and analysis makes tracking stats so easy that there’s little reason not to collect the data.
Conclusion
At this point, you should have Graphite installed and configured. By running through this tutorial and the last one, you have also configured collectd to collect metrics on your system performance, and StatsD to collect arbitrary data about your own development projects.
By learning to take advantage of these tools, you can begin to craft intricate and reliable stats tracking that can help you make informed decisions about every part of your environment. The advantages of making data-driven decisions are enormous, so start integrating metrics collection into your infrastructure sooner rather than later.
<div class=“author”>By Justin Ellingwood</div>
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Introduction to Tracking Statistics on Servers
Collecting and analyzing statistics on your servers and infrastructure becomes increasingly valuable as the complexity of your systems increase. In this series, we will introduce you to some battle-tested statistics gathering and rendering tools. We will go over some basic concepts and then show you how to install and set up each component to effectively monitor your servers and processes.
About the author
Former Senior Technical Writer at DigitalOcean, specializing in DevOps topics across multiple Linux distributions, including Ubuntu 18.04, 20.04, 22.04, as well as Debian 10 and 11.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Thanks for this great tutorials on Graphite, collectD, statsD . I’ve this following doubt. Now collectD lastest version comes with a statsD plugin. Does that mean using collectD with statsD plugin will do the work of both collectD and statsD? or collectD with statsD plugin acts as a bridge between collectD and statsD?
Thank you
snmalleswararao.chinta:
The collectd plugin implements the protocol, but is not nearly as light weight. So it might not be the best choice for all users. I set up all of them in the articles to demonstrate the functionality, but they do have a bit of overlap.
Another reason you may wish to use them separately is that it lets you swap out components easier. There are collectd alternatives that may suit your needs better, and having a separate StatsD instance running would allow you to easily make the transition to a new tool.
But really, its a matter of preference and your specific setup.
I have a problem with sending Raw data to graphite. Every other type of data works great for me, and I thank you for that, great guide! I tried sending raw data with both the python implementation of Statsd, and the command line “echo” to send Graphite data directly, both of which, send the data. However, carbon does not handle the data correctly…I have tried doing this guide twice, in case I missed something, but I have not.
With Python, it returns “True”, because the data is sent, and received, which is clear in the graphite cache.log file. However, this is the response. Request-Cache miss [eea16869e132ac38b986567144ab0080] I am assuming somewhere in the carbon—>whisper process something goes wrong. Does anyone have this problem too? Or have any idea what may be wrong? Maybe the aggregation/schemas file?
This will allow us to configure StatsD while still leaving Carbon active for our other services:
sudo service statsd stop —> sudo service carbon-cach start
Please change carbon-cach to carbon-cache
Great write up once again Justin
I seem to be having an issue starting the statsd service. Followed all the instructions to the letter, everything else is working okay but whenever I run sudo service statsd start, it will say it started and give it a process ID, but when I run a sudo service statsd status command it shows the status statsd stop/waiting. Anyone else had the same issue and know how I might be able to resolve it?
Same problem as vaanderal. The log (/var/log/upstart/statsd.log) displays the following error:
module.js:340
throw err;
^
Error: Cannot find module './servers/udp'
at Function.Module._resolveFilename (module.js:338:15)
at Function.Module._load (module.js:280:25)
at Module.require (module.js:364:17)
at require (module.js:380:17)
at startServer (/usr/share/statsd/stats.js:54:19)
at /usr/share/statsd/stats.js:190:20
at null.<anonymous> (/usr/share/statsd/lib/config.js:40:5)
at EventEmitter.emit (events.js:95:17)
at /usr/share/statsd/lib/config.js:20:12
at fs.js:268:14
Note that ~/build/statsd/servers/udp.js is not missing.
Solution to the question above
It seems that the command
sudo dpkg -i statsd*.deb
does not copy the “servers” folder in our system installation. I do not know if this is the best way to do things in nodejs but the following command solved the problem for me:
just after
sudo dpkg -i statsd*.deb
type
sudo cp -r ~/build/statsd/servers /usr/share/statsd
In Ubuntu trusty 14.04, python-statsd version 2.0.1-1 has a bug,
>>> import statsd
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.7/dist-packages/statsd/__init__.py", line 20, in <module>
host = getattr(settings, 'STATSD_HOST', 'localhost')
File "/usr/lib/python2.7/dist-packages/django/conf/__init__.py", line 54, in __getattr__
self._setup(name)
File "/usr/lib/python2.7/dist-packages/django/conf/__init__.py", line 47, in _setup
% (desc, ENVIRONMENT_VARIABLE))
django.core.exceptions.ImproperlyConfigured: Requested setting STATSD_HOST, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.
fixed by installing 3.0.1-1 from debian : http://pkgs.org/debian-sid/debian-main-i386/python-statsd_3.0.1-1_all.deb.html re: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=772936
The example “statsd.Gauge” doesn’t work, as they have refactored API it seems, but I prefer python-* packages over pip, so its a start.
This comment has been deleted
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
