
Status: Deprecated
This article covers a version of Ubuntu that is no longer supported. If you are currently operate a server running Ubuntu 12.04, we highly recommend upgrading or migrating to a supported version of Ubuntu:
- Upgrade to Ubuntu 14.04.
- Upgrade from Ubuntu 14.04 to Ubuntu 16.04
- Migrate the server data to a supported version
Reason: Ubuntu 12.04 reached end of life (EOL) on April 28, 2017 and no longer receives security patches or updates. This guide is no longer maintained.
See Instead: This guide might still be useful as a reference, but may not work on other Ubuntu releases. If available, we strongly recommend using a guide written for the version of Ubuntu you are using. You can use the search functionality at the top of the page to find a more recent version.
Introduction
A great number of applications require a database backend to store and efficiently query data. While traditionally, relational database management systems have been the most popular, non-relational models are gaining traction at a rapid rate.
One interesting non-SQL database that is focused on ease of use within a programming environment is RethinkDB. RethinkDB is an easy to configure JSON document storage database that can scale effortlessly.
One feature that makes RethinkDB simple to use with a programming language is that it supports robust client drivers. These allow you to interact with the database using much of the familiar syntax of your programming language.
In this guide, we will install and configure RethinkDB on an Ubuntu 12.04 VPS. We will interact with it using the Python client driver to demonstrate how its querying language can be accessed using native or near-native programming constructs.
Installation
There are two components that need to be installed to take complete advantage of the RethinkDB design. The first is the database itself. The second is the client driver that provides support for accessing the database from within your selected programming language.
We will cover both components here.
Install the RethinkDB Database Software
The RethinkDB software is not in the default repositories of Ubuntu 12.04. Fortunately, the project makes it easy to install by maintaining its own PPA (personal package archive).
To add a PPA to Ubuntu 12.04, we must first install the python-software properties package, which includes the commands we need. Update the package index and then install it:
sudo apt-get update
sudo apt-get install python-software-properties
Now that we have the software properties package installed, we can add the PPA of the RethinkDB project. Type the following to add this repository to our system:
sudo add-apt-repository ppa:rethinkdb/ppa
Now, we need to update our package index to gather information about the new packages we have available. After that, we can install the RethinkDB software:
sudo apt-get update
sudo apt-get install rethinkdb
We now have the database software available and can access its functionality.
Install the Python Client Driver
Although we have installed the database itself, we now should install the client driver for the database system. There are many options for client drivers depending on your programming language of choice.
The officially supported languages are JavaScript, Ruby, and Python. The community has also added support for many more languages including C, Clojure, Lisp, Erlang, Go, Haskell, Java, Perl, PHP, Scala, and more.
In this guide, we will be using the Python client driver due to the fact that Python is already installed on our system. We will install the client driver using pip, the Python package manager.
To conform to some suggested best practices when dealing with Python software, we’ll use virtualenv to isolate our Python environment. This package includes pip as a dependency.
sudo apt-get install python-virtualenv
Now that we have virtualenv and pip installed, we can create a directory in our home folder to install our virtual environment:
cd ~
mkdir rethink
Change into the directory and then use the virtualenv command to create the new virtual environment structure:
cd rethink
virtualenv venv
We can activate the environment by typing:
source venv/bin/activate
This will allow us to install components in an isolated environment without affecting our system’s programs. If we need to leave the environment (do not do this now, as we need the environment), type:
deactivate
Now that we have a virtual environment enabled, we can install the RethinkDB package by typing:
pip install rethinkdb
Our Python client driver is now installed and ready to use.
Starting RethinkDB and Explore the Web Interface
To begin exploring the RethinkDB system, we will start up a server and explore it using the built-in web interface.
From the command line, we can start a server instance using the following format:
rethinkdb --bind all
The --bind all parameter is necessary in order for your instance to be accessible from outside of the server itself. Since we are running from a remote VPS, this is a necessary addition.
If we visit our droplet’s IP address, followed by :8080, we will see the RethinkDB web interface:
<pre> <span class=“highlight”>your_server_ip_address</span>:8080 </pre>
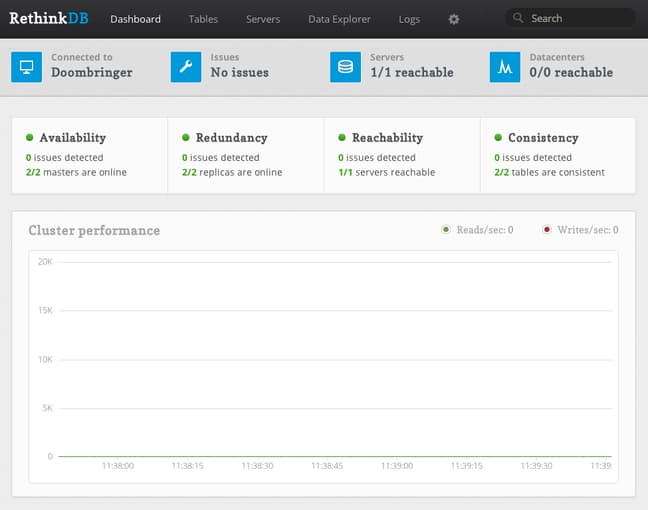
As you can see, we have a rich interface to our database server available.
We can see some standard health checks and some cluster performance metrics in the main view. Further down the page, the most recently logged activities are shown.
We also see some stats about our database. Next to the blue icons, the interface tells us the name of the database, and if any issues have been detected.
Furthermore, you can see that RethinkDB has a native understanding of servers and datacenters. This is because RethinkDB is built from the ground up to be easily scalable and distributable.
If we click on the “Tables” link at the top of the page, we can see any tables we have added to our database:
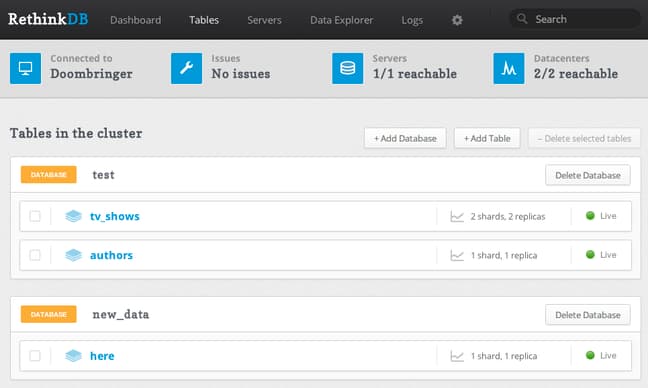
From here, we can see all the databases that we have in our server. Within each database, we can see tables that have been created. The overview also tells us about the sharding and replication that is configured for each component.
We can also add databases and tables from this view.
If we click on a single table, we can see an overview of the load, distribution, and document count:
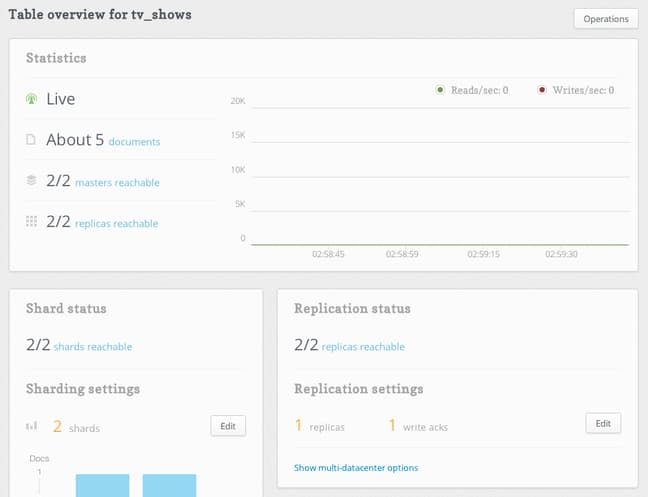
We can see more detailed information about the load and configuration of each table here. We can edit the sharding and replication settings and add indexes to query more efficiently.
Moving onto the next link across the top, we can see the servers that are available for our databases and tables.
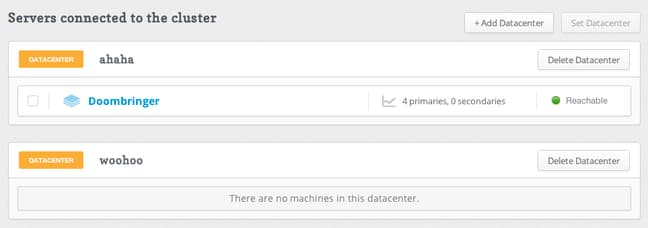
From here, we can manage and add databases, which are ways of grouping separate servers together. If you are deploying servers in different physical locations, this is an easy way of keeping track of where everything is. Changing the datacenter that a server is associated with is very easy as well.
Once again, you can click on an individual server to get an overview of its properties:
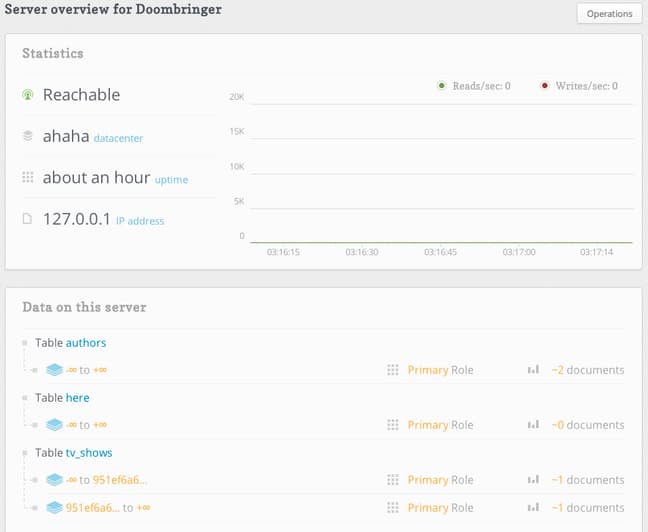
Moving on to the next link, titled “Data Explorer”, we are given an interface with which to interact with the server using the querying language:

We can create, delete, and modify tables and data from within this interface.
If we enter a query or a command, we can see the results below. We can view the information in a variety of formats and also do a query profile to see how the database decided to return the results that it did:
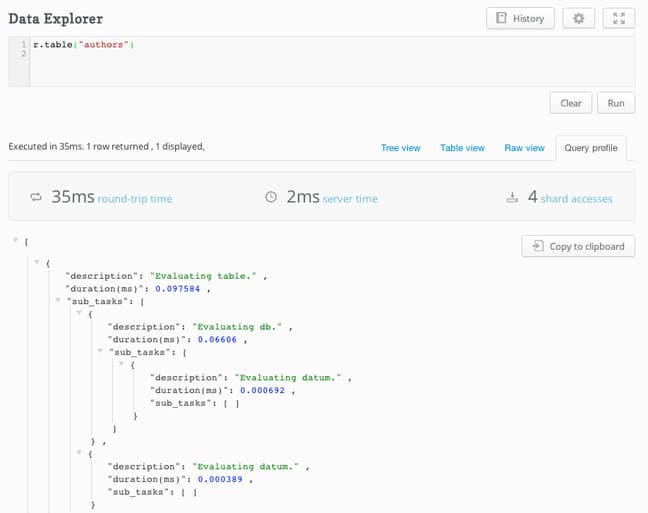
As you can see, we have a great tool for high level management of our databases and clusters.
Interacting with RethinkDB from within Python
Although the web interface is clean and easy to use, it probably is not the way that you will be interacting with the database in most cases. Most databases are used from within programs.
Start your Server in the Background
If you are unfamiliar with managing background processes, we will briefly explain how to start your server in the background to allow you to continue working in the terminal.
You can shutdown the server by pressing “Ctrl-C” in the terminal. You can then restart it in the background, so that you can access the terminal, by restarting it with:
rethinkdb --bind all &
The & starts the process in the background and allows you to continue working.
Another option is to not kill the initial server process and simply suspend the server and then resume it in the background. You can do this by instead typing “Ctrl-Z”.
Afterwards, resume the process in the background by typing:
bg
You can see the process at any time by typing:
jobs
[1]+ Running rethinkdb --bind all &
If you need to bring the task to the foreground again (perhaps to kill it when you are finished), you can type:
fg
The task will then be available in the foreground again. If you have multiple background processes, you may need to reference the job number by using this format:
<pre> fg %<span class=“highlight”>num</span> </pre>
Once your server is in the background, we can begin exploring the database through Python.
Exploring the RethinkDB System with Python
Start the Python interpreter so that we can begin to interact with the database:
python
From here, we simply need to import the client driver into the environment:
import rethinkdb as r
We can now connect with the local database by using the connect command:
r.connect("localhost", 28015).repl()
The .repl() at the end allows us to call commands on the connection that is formed without specifying the connection explicitly within the .run() call. This is used for convenience in testing situations like this.
Now, we have a connection to our server and we can begin working with the database immediately.
We can create a database to play around with by typing:
r.db_create("food").run()
We now have a database called “food”. The .run() command chained at the end is very important. RethinkDB commands look like local code, but they are actually translated by the RethinkDB client drivers to native database code and executed remotely on the server.
The run command is what sends this to the server. If we hadn’t added the .repl() command to the initial server connection, we would have to list the connection object in the run command like this:
conn = r.connect("localhost", 28015)
r.db_create("food").run(conn)
These first few commands give you a general idea of how command chaining works with RethinkDB. Complex commands can be created to do multiple operations at once. This allows you to make readable, sequential command chains that are all translated and sent to the database at once, instead of having multiple calls.
Now that we have a database, let’s make a table:
r.db("food").table_create("favorites").run()
We can then add some data to the table. RethinkDB uses a flexible schema design, so you can add any kinds of key-value pairs you would like. We will add some people and then add their favorite foods:
r.db("food").table("favorites").insert([
{ "person": "Randy", "Age": 26,
"fav_food": [
"banana",
"cereal",
"spaghetti"
]
},
{ "person": "Thomas", "Age": 8,
"fav_food": [
"cookies",
"apples",
"cake",
"sandwiches"
]
},
{ "person": "Martha", "Age": 52,
"fav_food": [
"grapes",
"pie",
"avocado"
]
}
]).run()
This will create three JSON documents in our “favorites” table. Each object defines a person, an age, and an array with the person’s favorite foods.
We can print out the documents by querying for them. To do this, we simply have to ask for the database and table, and the server will return an iterable object that we can then process with a loop.
The server will continuously give out data as the object, called a cursor, is processed. For instance, we can print everything by typing:
c = r.db("food").table("favorites")
for x in c:
print x
{u'person': u'Martha', u'Age': 52, u'fav_food': [u'grapes', u'pie', u'avocado'], u'id': u'b888ec64-f2c9-4f85-9db6-f8b8a66626c6'}
{u'person': u'Thomas', u'Age': 8, u'fav_food': [u'cookies', u'apples', u'cake', u'sandwiches'], u'id': u'3aa7ae68-85b0-48b6-9726-76e810ea4c55'}
{u'person': u'Randy', u'Age': 26, u'fav_food': [u'banana', u'cereal', u'spaghetti'], u'id': u'f027a270-d5ac-4c33-ad91-53a7541ace82'}
This prints each line in turn. The cursor object, represented by the variable “c” in our example, is given new data by the server as it is processed. This allows for quick execution of the code.
You may have noticed that each of the records that we added to the “favorites” table has been given an ID. This is done automatically and is used to index the contents of each table.
We can filter results by just adding another link in the command chain:
c = r.db("food").table("favorites").filter(r.row["fav_food"].count() > 3).run()
for x in c:
print x
{u'person': u'Thomas', u'Age': 8, u'fav_food': [u'cookies', u'apples', u'cake', u'sandwiches'], u'id': u'3aa7ae68-85b0-48b6-9726-76e810ea4c55'}
As you can see, we simply added a .filter() command. We used the r.row to reference the “fav_food” keys and then counted the number of entries for each row. We did a simple comparison to filter out those people who had 3 or fewer favorite foods.
Conclusion
As you can see, we can manipulate the data in our RethinkDB system easily and naturally. RethinkDB prides itself on being easy from a development standpoint without sacrificing the ability to scale easily and seamlessly.
This guide has only covered the basics in order to introduce you to some ways to work with RethinkDB. If you are considering using this in a production environment, it would probably be useful to explore the scaling and replication capabilities of the system and its database-aware networking capabilities.
<div class=“author”>By Justin Ellingwood</div>
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Senior Technical Writer at DigitalOcean, specializing in DevOps topics across multiple Linux distributions, including Ubuntu 18.04, 20.04, 22.04, as well as Debian 10 and 11.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
I don’t think it is a good idea to use --bind-all on a public server! That would mean anyone could go to example.com:8080 and have full admin access!
The RethinkDB security tutorial, recommends not using bind all on a public machine. It recommends instead proxying through the machine to access the web console.
@sam.parkinson3: You could setup firewall rules to only allow a specific IP address to connect to the port. It would be something like:
iptables -I INPUT -p tcp -s your.ip.address --dport 8080 -j ACCEPT
iptables -I INPUT -p tcp -s 0.0.0.0/0 --dport 8080 -j DROP
I’m just wondering what is the difference in your approach of installing RethinkDB and the one on their site http://www.rethinkdb.com/docs/install/ubuntu/
Need Help! I need to download the whole **Rethinkdb Installation Package into a USB for Ubuntu 14.04 server’ FYI, my ubuntu server do not have internet.
People suggested me to download the repositories from: http://download.rethinkdb.com/apt/pool/
But here I see too many .deb files and I loose track when I am downloading them. I also do not know how to install them on my ubuntu server yet. Is there any command line for ubuntu to download all .deb at a time. I also need command line to to install them on my Ubuntu Server.
Or does anybody know how I can get rid of this situation?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
