By Erin Glass
Senior Manager, DevEd
 en Ubuntu 20.04")
Introducción
Elastic Stack, previamente conocida como la pila ELK, es una colección de software de código abierto producido por Elastic que le permite buscar, analizar, y visualizar registros generados desde cualquier fuente y en cualquier formato, una práctica conocida como registro centralizado. El registro centralizado puede ser muy útil al intentar identificar problemas en sus servidores o aplicaciones, ya que le permite realizar búsquedas en todos sus registros desde un solo sitio. También es útil porque le permite identificar problemas que abarcan varios servidores vinculando sus registros durante un período de tiempo específico.
Elastic Stack cuenta con cuatro componentes principales:
- Elasticsearch: motor de búsqueda de RESTfuldistribuido que almacena todos los datos recopilados.
- Logstash: componente de procesamiento de datos de Elastic Stack que envía datos entrantes a Elasticsearch.
- Kibana: interfaz web para buscar y visualizar registros.
- Beats: transportadores de datos ligeros de uso único que pueden enviar datos de cientos o miles de máquinas a Logstash o Elasticsearch.
A través de este tutorial, instalará Elastic Stack en un servidor de Ubuntu 20.04. Aprenderá a instalar todos los componentes de Elastic Stack, incluido Filebeat, un Beat que se usa para reenviar y centralizar registros y archivos, y los configurará para recopilar y visualizar registros del sistema. Además, debido a que Kibana normalmente está solo disponible en el localhost, usaremos Nginx para hacer un proxy de modo que el acceso sea posible a través de un navegador web. Instalaremos todos estos componentes en un único servidor al que nos referiremos como nuestro servidor de pila de Elastic.
Nota: Al instalar Elastic Stack, debe usar la misma versión en toda la pila. En este tutorial, instalaremos las últimas versiones de toda la pila que, al redactarse el presente artículo, eran Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 y Filebeat 7.7.1.
Requisitos previos
Para completar este tutorial, necesitará lo siguiente:
-
Un servidor de Ubuntu 20.04, con 4 GB de RAM y 2 CPU configuradas con un usuario sudo no root. Puede hacerlo siguiendo la Configuración inicial de servidores para Ubuntu 20.04. En este tutorial, trabajaremos con la cantidad mínima de CPU y RAM requerida para ejecutar Elasticsearch. Tenga en cuenta que la cantidad de CPU, RAM y almacenamiento que su servidor de Elasticsearch requiera dependerá del volumen de registros que prevé.
-
OpenJDK 11 instalado. Consulte la sección Instalación de JRE y del JDK predeterminados en nuestra guía Cómo instalar Java con Apt en Ubuntu 20.04 para configurarlo.
-
Nginx instalado en su servidor, que configuraremos más adelante en esta guía como proxy inverso para Kibana. Para configurarlo, siga nuestra guía Cómo instalar Nginx en Ubuntu 20.04.
Además, debido a que Elastic Stack se usa para acceder a información valiosa sobre su servidor a la que no quiere que accedan usuarios no autorizados, es importante que mantenga su servidor protegido instalando un certificado TLS o SSL. Esto es opcional, pero se recomienda enfáticamente.
Sin embargo, ya que eventualmente realizará cambios en su bloque de servidor de Nginx a lo largo de esta guía, es probable que tenga más sentido completar la guía de Let´s Encrypt sobre Ubuntu 20.04 al final del segundo paso de este tutorial. Teniendo eso en cuenta, si planea configurar Let´s Encrypt en su servidor, necesitará lo siguiente antes de hacerlo:
-
Un nombre de dominio totalmente apto (FQDN). Para este tutorial, se utilizará
your_domainen todo momento. Puede adquirir un nombre de dominio en Namecheap, obtener uno gratuito en Freenom o utilizar un registrador de dominios de su elección. -
Los dos registros DNS que se indican a continuación se han configurado para su servidor. Puede utilizar esta introducción al DNS de DigitalOcean para obtener más información sobre cómo agregarlos.
- Un registro A con
your_domainorientado a la dirección IP pública de su servidor. - Un registro A con
www.your_domainorientado a la dirección IP pública de su servidor.
- Un registro A con
Paso 1: Instalar y configurar Elasticsearch
Los componentes de Elasticsearch no están disponibles en los repositorios de paquetes predeterminados de Ubuntu. Sin embargo, pueden instalarse con APT una vez que agregue la lista de fuentes de paquetes de Elastic.
Todos los paquetes de Elasticsearch están firmados con la clave de firma de Elasticsearch para proteger su sistema contra la suplantación de paquetes. Su administrador de paquetes considerará confiables los paquetes autenticados con la clave. En este paso, importará la clave GPG pública de Elasticsearch y agregará la lista de fuentes de paquetes de Elastic para instalar Elasticsearch.
Para comenzar, utilice cURL, la herramienta de línea de comandos para transferir datos con URL, para importar la clave GPG pública de Elasticsearch a APT. Tenga en cuenta que estamos usando los argumentos -fsSL para silenciar todos los progresos y posibles errores (excepto los de errores del servidor) y para permitir a cURL hacer una solicitud en una ubicación nueva si se redirige. Canalice el resultado del comando cURL al programa apt-key, que añade la clave GPG pública a APT.
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
A continuación, agregue la lista de fuentes de Elastic al directorio sources.list.d, donde APT buscará nuevas fuentes:
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
A continuación, actualice sus listas de paquetes para que APT lea la nueva fuente de Elastic:
- sudo apt update
Luego, instale Elasticsearch con este comando:
- sudo apt install elasticsearch
Ahora, Elasticsearch está instalada y lista para usarse. Utilice su editor de texto preferido para editar el archivo de configuración principal de Elasticsearch, elasticsearch.yml. En este caso, utilizaremos nano:
- sudo nano /etc/elasticsearch/elasticsearch.yml
Nota: El archivo de configuración de Elasticsearch se encuentra en formato YAML, lo que significa que debemos mantener el formato de sangrías. Asegúrese de no añadir espacios adicionales al editar este archivo.
El archivo elasticsearch.yml ofrece opciones de configuración para su clúster, nodo, rutas, memoria, red, detección y puerta de enlace. La mayoría de estas opciones están preconfiguradas en el archivo, pero las puede cambiar según sus necesidades. Para los fines de nuestra demostración de una configuración de un solo servidor, modificaremos únicamente la configuración del host de red.
Elasticsearch escucha el tráfico de todos los lugares en el puerto 9200. Es conveniente restringir el acceso externo a su instancia de Elasticsearch para evitar que terceros lean sus datos o cierren su clúster de Elasticsearch a través de su [API REST] (https://en.wikipedia.org/wiki/Representational_state_transfer). Para restringir el acceso y, por lo tanto, aumentar la seguridad, busque la línea que especifica network.host, elimine los comentarios y reemplace su valor por localhost para que tenga el siguiente aspecto:
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Hemos especificado localhost para que Elasticsearch escuche en todas las interfaces y las IP vinculadas. Si desea que escuche únicamente en una interfaz específica, puede especificar su IP en lugar de localhost. Guarde y cierre elasticsearch.yml. Si utiliza nano, puede hacerlo pulsando CTRL+X, seguido de Y y, luego, ENTER.
Estos son los ajustes mínimos con los que puede comenzar para usar Elasticsearch. Ahora, puede iniciar Elasticsearch por primera vez.
Inicie el servicio de Elasticsearch con systemctl. Elasticsearch tardará unos minutos en iniciarse. Espere, de lo contrario, es posible que reciba errores de que no se puede conectar.
- sudo systemctl start elasticsearch
Luego, ejecute el siguiente comando para permitir que Elasticsearch se cargue cada vez que su servidor se inicia:
- sudo systemctl enable elasticsearch
Puede comprobar si su servicio de Elasticsearch se está ejecutando enviando una solicitud HTTP:
- curl -X GET "localhost:9200"
Visualizará una respuesta que mostrará información básica sobre su nodo local, similar a la siguiente:
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Ahora que Elasticsearch está configurado y activo, instalaremos Kibana, el siguiente componente de Elastic Stack.
Paso 2: Instalar y configurar el panel de Kibana
De acuerdo con la documentación oficial, deberá instalar Kibana solo después de instalar Elasticsearch. La instalación en este orden garantiza que los componentes de los que depende cada producto estén correctamente implementados.
Debido a que ya agregó la fuente de paquetes de Elastic en el paso anterior, puede instalar los componentes restantes de Elastic Stack usando apt:
- sudo apt install kibana
A continuación, habilite e inicie el servicio de Kibana:
- sudo systemctl enable kibana
- sudo systemctl start kibana
Debido a que Kibana está configurado para escuchar solo en localhost, debemos configurar un proxy inverso para permitir el acceso externo a este. Utilizaremos Nginx para este propósito, que ya debería estar instalado en su servidor.
Primero, utilice el comando openssl para crear un usuario administrativo de Kibana que usará para acceder a la interfaz web de Kibana. Como ejemplo, nombraremos esta cuenta kibanaadmin, pero, para garantizar una mayor seguridad, le recomendamos elegir un nombre no estándar para su usuario que sea difícil de adivinar.
Con el siguiente comando se crearán el usuario y la contraseña administrativa de Kibana, y se almacenarán en el archivo htpasswd.users. Configurará Nginx para que requiera este nombre de usuario y contraseña, y lea este archivo de manera momentánea:
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
Introduzca y confirme una contraseña cuando se le solicite. Recuerde este dato de inicio de sesión o tome nota de él, ya que lo necesitará para acceder a la interfaz web de Kibana.
A continuación, crearemos un archivo de bloque de servidor de Nginx. Como ejemplo, nos referiremos a este archivo como your_domain, aunque podría resultarle más útil darle al suyo un nombre más descriptivo. Por ejemplo, si tiene un FQDN y registros de DNS configurados para este servidor, podría darle a este archivo el nombre de su FQDN.
Cree el archivo de bloque de servidor de Nginx usando nano o su editor de texto preferido:
- sudo nano /etc/nginx/sites-available/your_domain
Añada el siguiente bloque de código al archivo, y asegúrese de actualizar your_domain para que coincida con la FQDN o la dirección IP pública de su servidor. Con este código, se configura Nginx para dirigir el tráfico HTTP de su servidor a la aplicación de Kibana, que escucha en localhost:5601. También se configura Nginx para leer el archivo htpasswd.users y requerir la autenticación básica.
Tenga en cuenta que, si siguió todo el tutorial de los requisitos previos de Nginx, es posible que ya haya creado este archivo y lo haya completado con contenido. En ese caso, elimine todo el contenido existente en el archivo antes de añadir lo siguiente:
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Cuando termine, guarde y cierre el archivo.
A continuación, habilite la nueva configuración creando un enlace simbólico al directorio sites-enabled. Si ya creó un archivo de bloque de servidor con el mismo nombre en el requisito previo de Nginx, no necesitará ejecutar este comando:
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
A continuación, compruebe que no haya errores de sintaxis en la configuración:
- sudo nginx -t
Si se muestran errores en su resultado, regrese y verifique bien que el contenido que ingresó en su archivo de configuración se haya agregado correctamente. Una vez que vea syntax is ok en el resultado, reinicie el servicio de Nginx:
- sudo systemctl reload nginx
Si siguió la guía de configuración inicial para servidores, debería tener activado un firewall UFW. Para permitir las conexiones con Nginx, podemos ajustar las reglas escribiendo lo siguiente:
- sudo ufw allow 'Nginx Full'
Nota: Si siguió el tutorial de los requisitos previos de Nginx, es posible que haya creado una regla de UFW que admita el perfil Nginx HTTP en el firewall. Debido a que el perfil Nginx Full admite el paso del tráfico HTTP y HTTPS por el firewall, puede eliminar de forma segura la regla que creó en el tutorial de los requisitos previos. Hágalo con el siguiente comando:
- sudo ufw delete allow 'Nginx HTTP'
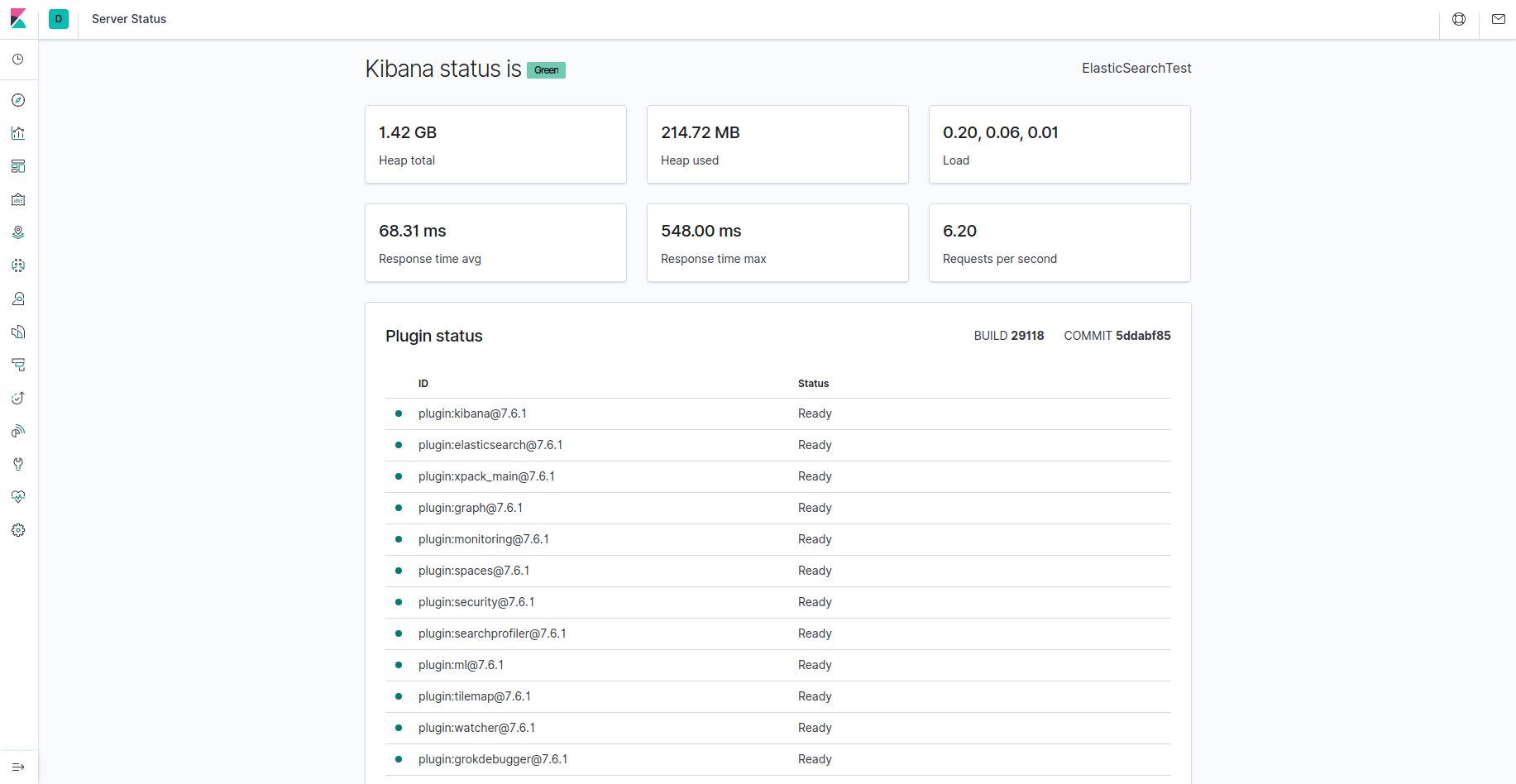
Con esto, el acceso a Kibana será posible a través de su FQDN o de la dirección IP pública de su servidor de Elastic Stack. Puede comprobar la página de estado del servidor de Kibana visitando la siguiente dirección e ingresando sus credenciales de inicio de sesión cuando se le soliciten:
http://your_domain/status
En esta página de estado, se muestra información sobre el uso de los recursos del servidor y se enumeran los complementos instalados.
Nota: Como se indica en la sección de requisitos previos, se le recomienda habilitar SSL o TLS en su servidor. Ahora, puede seguir la guía de Let’s Encrypt para obtener un certificado SSL gratuito para Nginx en Ubuntu 20.04. Una vez que obtenga sus certificados SSL y TLS, puede volver y completar este tutorial.
Ahora que el panel de Kibana está configurado, instalaremos el siguiente componente: Logstash.
Paso 3: Instalar y configurar Logstash
Aunque es posible que Beats envíe datos de manera directa a la base de datos de Elasticsearch, recomendamos usar Logstash para procesar los datos. Esto le permitirá, de forma más flexible, recopilar datos de diferentes fuentes, transformarlos en un formato común y exportarlos a otra base de datos.
Instale Logstash con este comando:
- sudo apt install logstash
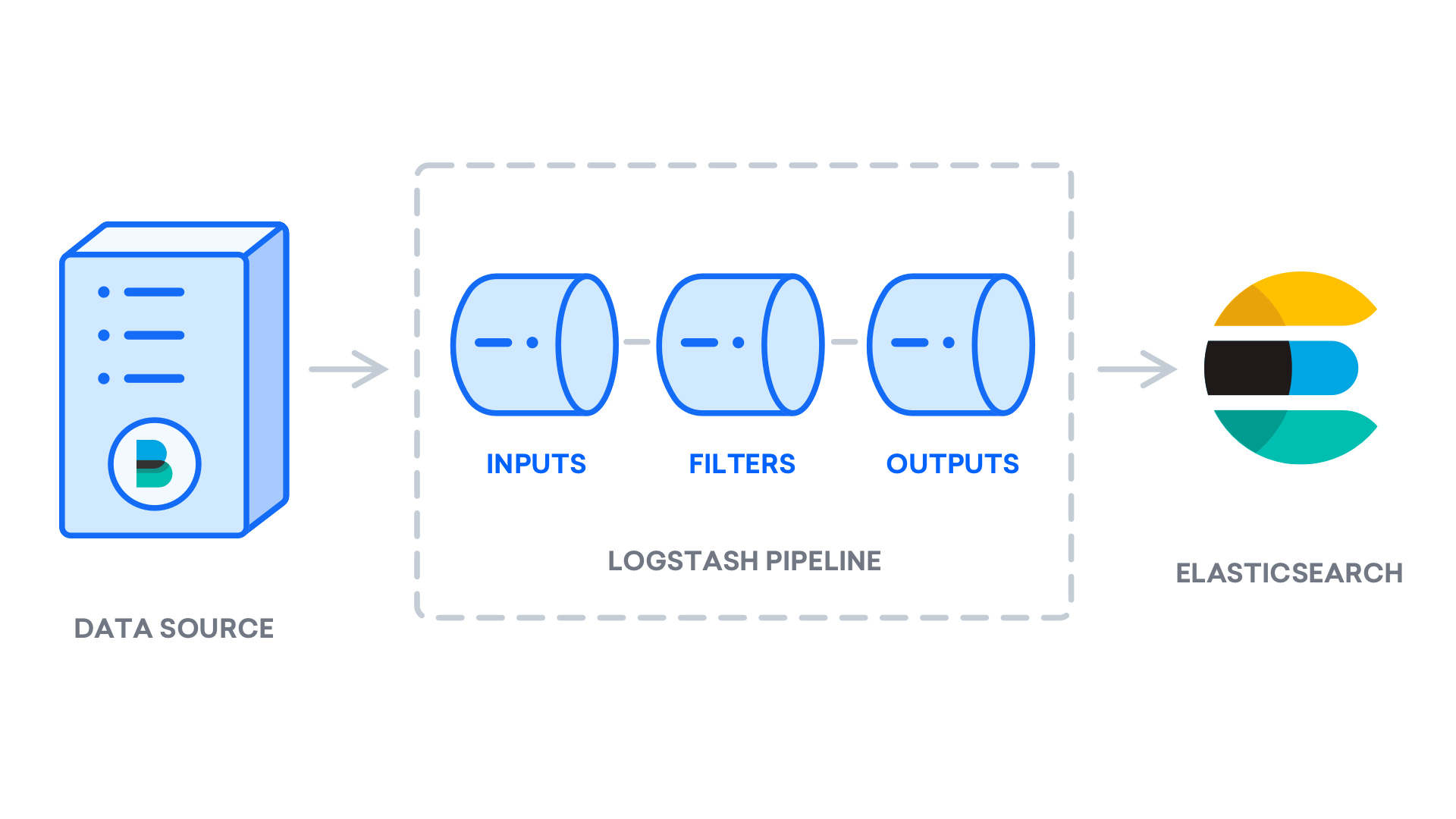
Después de instalar Logstash, puede seguir configurándolo. Los archivos de configuración de Logstash residen en el directorio /etc/logstash/conf.d. Para obtener más información sobre la sintaxis de configuración, puede consultar la referencia de configuración que proporciona Elastic. A medida que configura el archivo, le resultará útil pensar que Logstash es un proceso que toma datos en un extremo, los procesa de una u otra manera y los envía a su destino (en este caso, el destino es Elasticsearch). Un proceso de Logstash tiene dos elementos necesarios, input y output, y un elemento opcional, filter. Los complementos de entrada consumen datos de una fuente, los complementos del filtro procesan los datos, y los complementos de salida escriben los datos en un destino.
Cree un archivo de configuración llamado 02-beats-input.conf en el que establecerá su entrada de Filebeat:
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
Introduzca la siguiente configuración de input. Con esto, se especifica una entrada de beats que escuchará en el puerto TCP 5044.
input {
beats {
port => 5044
}
}
Guarde y cierre el archivo.
A continuación, cree un archivo de configuración llamado 30-elasticsearch-output.conf:
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Introduzca la siguiente configuración de output. Básicamente, con este resultado, se configura Logstash para almacenar los datos de Beats en Elasticsearch, que se ejecuta en localhost:9200, en un índice con el nombre del Beat utilizado. El Beat utilizado en este tutorial es Filebeat:
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
Guarde y cierre el archivo.
Pruebe su configuración de Logstash con el siguiente comando:
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Si no hay errores de sintaxis, su resultado mostrará Config Validation Result: OK. Existing Logstash después de unos segundos. Si no visualiza esto en su resultado, verifique cualquier error que aparezca en su resultado y actualice su configuración para corregirlo. Tenga en cuenta que recibirá advertencias de OpenJDK, pero no deberían causar ningún problema y pueden ignorarse.
Si su prueba de configuración tiene éxito, inicie y habilite Logstash para implementar los cambios de configuración:
- sudo systemctl start logstash
- sudo systemctl enable logstash
Ahora que Logstash se ejecuta de manera correcta y está totalmente configurado, instalaremos Filebeat.
Paso 4: Instalar y configurar Filebeat
La pila de Elastic utiliza varios transportadores de datos ligeros llamados Beats para recopilar datos de varias fuentes y transportarlos a Logstash o Elasticsearch. Aquí se muestran los Beats que ahora están disponibles en Elastic:
- Filebeat: recopila y envía archivos de registro.
- Metricbeat: recopila métricas de sus sistemas y servicios.
- Packetbeat: recopila y analiza datos de red.
- Winlogbeat: recopila registros de eventos de Windows.
- Auditbeat: recopila datos del marco de trabajo de auditoría de Linux y supervisa la integridad de los archivos.
- Heartbeat: supervisa la disponibilidad de los servicios con sondeo activo.
En este tutorial, usaremos Filebeat para reenviar registros locales a nuestra pila de Elastic.
Instale Filebeat usando apt:
- sudo apt install filebeat
A continuación, configure Filebeat para que se conecte a Logstash. Aquí, modificaremos el archivo de configuración de ejemplo que viene con Filebeat.
Abra el archivo de configuración de Filebeat:
- sudo nano /etc/filebeat/filebeat.yml
Nota: Al igual que con Elasticsearch, el archivo de configuración de Filebeat está en formato YAML. Esto significa que una correcta sangría es esencial. Por lo tanto, asegúrese de usar el mismo número de espacios que se indican en estas instrucciones.
Filebeat admite numerosas salidas, pero por lo general solo enviará eventos directamente a Elasticsearch o a Logstash para su procesamiento adicional. En este tutorial, usaremos Logstash para aplicar procesamiento adicional a los datos recopilados por Filebeat. Filebeat no tendrá que enviar datos de manera directa a Elasticsearch, por lo que desactivaremos esa salida. Para hacerlo, encuentre la sección output.elasticsearch y comente las siguientes líneas anteponiéndoles #:
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
A continuación, configure la sección output.logstash. Elimine el comentario de las líneas output.logstash: y hosts: ["localhost:5044"] quitando #. Con esto, se configurará Filebeat para establecer conexión con Logstash en su servidor de Elastic Stack en el puerto 5044, para el que especificamos una entrada de Logstash previamente:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
Guarde y cierre el archivo.
La funcionalidad de Filebeat puede ampliarse con módulos de Filebeat. En este tutorial usaremos el módulo de sistema, que recopila y analiza registros creados por el servicio de registro del sistema de distribuciones comunes de Linux.
Vamos a habilitarlo:
- sudo filebeat modules enable system
Puede ver una lista de módulos habilitados y desactivados ejecutando lo siguiente:
- sudo filebeat modules list
Verá una lista similar a la siguiente:
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...
Por defecto, Filebeat está configurado para usar rutas predeterminadas para los registros syslog y de autorización. En el caso de este tutorial, no necesita aplicar cambios en la configuración. Puede ver los parámetros del módulo en el archivo de configuración /etc/filebeat/modules.d/system.yml.
A continuación, debemos configurar los procesos de ingesta de Filebeat, que analizan los datos de registro antes de enviarlos a través de Logstash a Elasticsearch. Para cargar el proceso de ingesta para el módulo de sistema, introduzca el siguiente comando:
- sudo filebeat setup --pipelines --modules system
A continuación, cargue la plantilla de índice en Elasticsearch. Un índice de Elasticsearch es un conjunto de documentos que tienen características similares. Los índices se identifican con un nombre, que se utiliza para referirse al índice cuando se realizan varias operaciones dentro de este. La plantilla de índice se aplicará de forma automática al crear un nuevo índice.
Para cargar la plantilla, utilice el siguiente comando:
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
Filebeat incluye paneles de muestra de Kibana que le permiten visualizar datos de Filebeat en Kibana. Para poder usar los paneles, deberá crear el patrón de índice y cargar los paneles en Kibana.
Al cargarse los paneles, Filebeat se conecta a Elasticsearch para verificar la información de la versión. Para cargar paneles cuando se habilite Logstash, deberá desactivar el resultado de Logstash y habilitar el de Elasticsearch:
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Debería recibir un resultado similar a este:
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Ahora podrá iniciar y habilitar Filebeat:
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Si configuró su pila de Elastic de manera correcta, Filebeat iniciará el envío de sus registros syslog y de autorización a Logstash, que a su vez cargará esos datos en Elasticsearch.
Para verificar que Elasticsearch realmente reciba estos datos, consulte el índice de Filebeat con este comando:
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Debería recibir un resultado similar a este:
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
Si su resultado no muestra coincidencias, Elasticsearch no está cargando ningún registro bajo el índice que buscó, y deberá verificar su configuración en busca de errores. Si obtuvo el resultado esperado, continúe con el siguiente paso, en el que veremos la manera de explorar algunos de los paneles de Kibana.
Paso 5: Explorar los paneles de Kibana
Volvamos a la interfaz web de Kibana que instalamos antes.
En un navegador web, diríjase al FQDN o a la dirección IP pública de su servidor de Elastic Stack. Si su sesión se ha interrumpido, deberá volver a introducir las credenciales que definió en el paso 2. Una vez que haya iniciado sesión, debería recibir la página de inicio de Kibana:
Haga clic en el enlace Descubrir de la barra de navegación a la izquierda (puede tener que hacer clic en el icono Expandir de la parte inferior izquierda para ver los elementos del menú de navegación). En la página Discover, seleccione el patrón de índice predeterminado de filebeat-* para ver datos de Filebeat. Por defecto, esto le mostrará todos los datos de registro de los últimos 15 minutos. Visualizará un histograma con eventos de registro y algunos mensajes de registro a continuación:
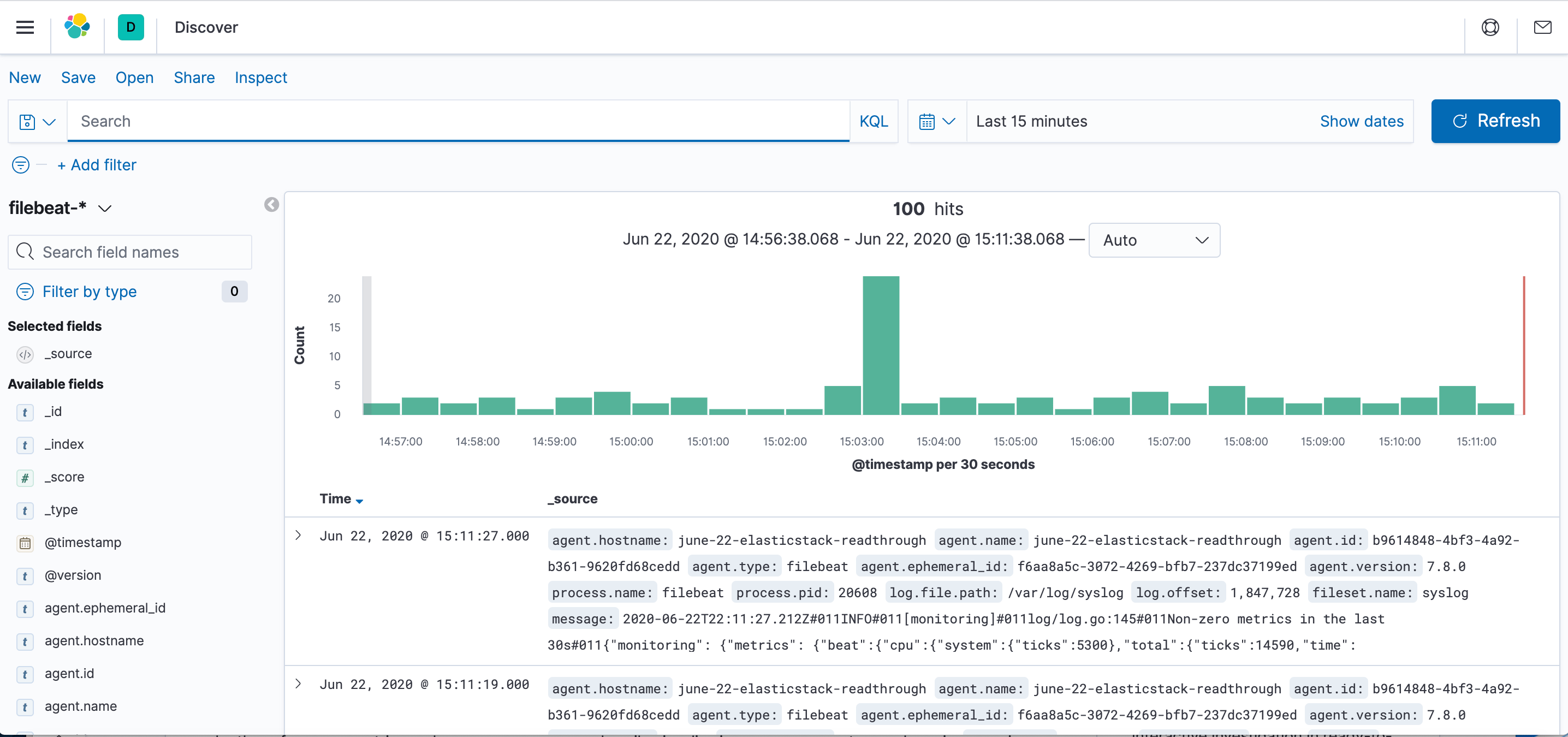
Aquí puede buscar y explorar sus registros y también personalizar su panel. Sin embargo, en este punto, no habrá muchos registros porque solo recopila syslogs de su servidor de Elastic Stack.
Utilice el panel del lado izquierdo para acceder a la página Dashboard y buscar los paneles de Filebeat System. Ahí puede seleccionar los paneles de muestra que vienen con el módulo system de Filebeat.
Por ejemplo, puede ver estadísticas detalladas basadas en sus mensajes de syslog:
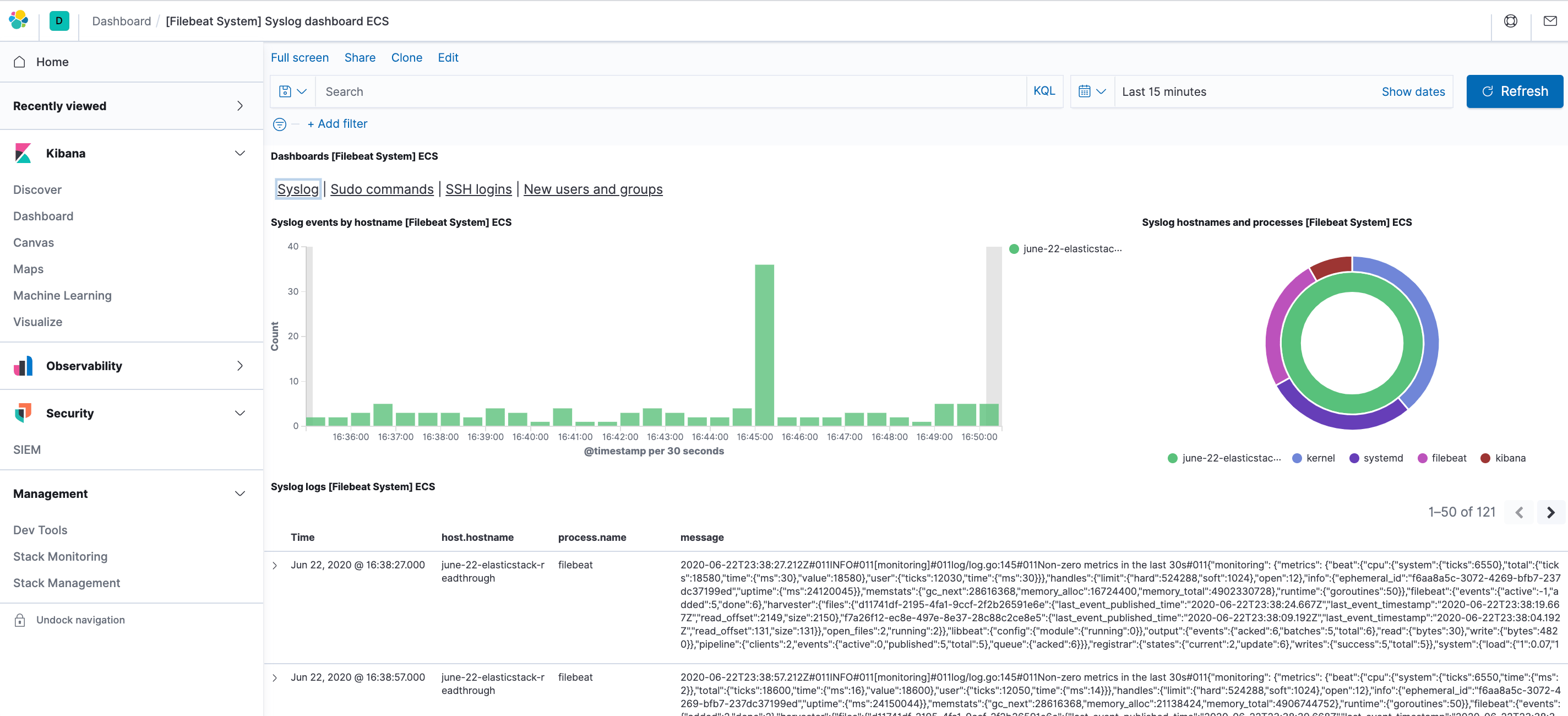
También puede ver los usuarios que utilizaron el comando sudo y el momento en que lo hicieron:
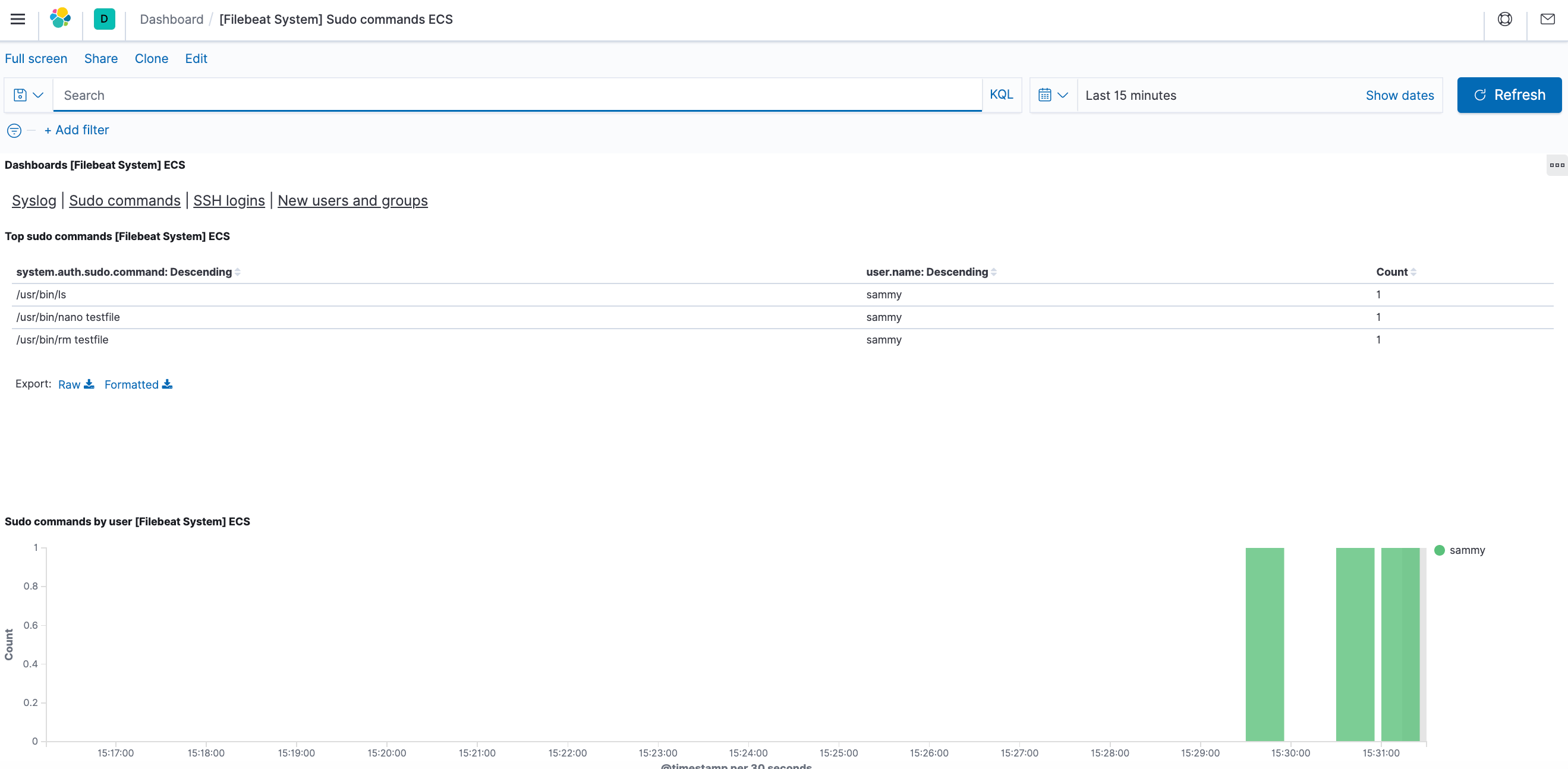
Kibana tiene muchas otras características, como graficar y filtrar. No dude en explorarlas.
Conclusión
A través de este tutorial, aprendió a instalar y configurar Elastic Stack para recopilar y analizar registros del sistema. Recuerde que puede enviar casi cualquier tipo de datos de registro o de índice a Logstash usando Beats, pero los datos se vuelven aún más útiles si se analizan y estructuran con un filtro de Logstash, ya que transforma los datos en un formato uniforme que Elasticsearch puede leer de forma sencilla.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Open source advocate and lover of education, culture, and community.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
