By Erin Glass
Senior Manager, DevEd
 no Ubuntu 20.04")
Introdução
A Pilha Elastic — anteriormente conhecida como ELK Stack — é uma coleção de softwares de código aberto produzida pela Elastic que permite pesquisar, analisar e visualizar logs gerados a partir de qualquer fonte em qualquer formato. Esta é uma prática conhecida como centralização de logs. A centralização de logs pode ser útil ao tentar identificar problemas com seus servidores ou aplicações, uma vez que ela permite que você pesquise todos os seus logs em um único lugar. Também é útil porque ele lhe permite identificar problemas que abrangem vários servidores correlacionando seus logs durante um período de tempo específico.
A pilha Elastic tem quatro componentes principais:
- Elasticsearch: um mecanismo de busca RESTful distribuído que armazena todos os dados coletados.
- Logstash: o componente de processamento de dados da pilha Elastic que envia dados recebidos para o Elasticsearch.
- Kibana: uma interface Web para pesquisar e visualizar logs.
- Beats: transportadores de dados leves e de propósito único que podem enviar dados de centenas ou milhares de máquinas para o Logstash ou para o Elasticsearch.
Neste tutorial, você irá instalar a pilha Elastic em um servidor Ubuntu 20.04. Você irá aprender como instalar todos os componentes da pilha Elastic — incluindo o Filebeat, um Beat usado para encaminhar e centralizar logs e arquivos — e configurá-los para coletar e visualizar logs de sistema. Além disso, como o Kibana normalmente está disponível apenas no localhost, usaremos o Nginx para fazer proxy dele para que ele seja acessível via um navegador Web. Vamos instalar todos esses componentes em um único servidor, que vamos nos referir como nosso servidor da pilha Elastic.
Nota: ao instalar a pilha Elastic, você deve usar a mesma versão em toda a pilha. Neste tutorial, vamos instalar as versões mais recentes de toda a pilha que são, no momento da escrita deste artigo, o Elasticsearch 7.7.1, Kibana 7.7.1, Logstash 7.7.1 e Filebeat 7.7.1.
Pré-requisitos
Para concluir este tutorial, você precisará do seguinte:
-
Um servidor Ubuntu 20.04, com 4GB de RAM e 2 CPUs configuradas com um usuário sudo não root. Você pode conseguir isso seguindo o guia Initial Server Setup with Ubuntu 20.04. Para este tutorial, vamos trabalhar com a quantidade mínima necessária de CPU e RAM para executar o Elasticsearch. Observe que a quantidade de CPU, RAM e armazenamento que seu servidor Elasticsearch exigirá depende do volume de logs que você espera.
-
OpenJDK 11 instalado. Veja a seção Installing the Default JRE/JDK How To Install Java with Apt on Ubuntu 20.04 para configurar isto.
-
Nginx instalado em seu servidor, que vamos configurar mais tarde neste guia como um proxy reverso para o Kibana. Siga nosso guia How to Install Nginx on Ubuntu 20.04 para configurar isso.
Além disso, como a pilha Elastic é usada para acessar informações valiosas sobre seu servidor, que você não deseja que usuários não autorizados acessem, é importante que você mantenha seu servidor seguro instalando um certificado TLS/SSL. Isso é opcional, mas altamente recomendado.
No entanto, como você acabará por fazer alterações em seu bloco de servidor Nginx ao longo deste guia, provavelmente faria mais sentido para você completar o guia Let’s Encrypt on Ubuntu 20.04 no final do segundo passo deste tutorial. Com isso em mente, se você planeja configurar o Let’s Encrypt em seu servidor, você precisará ter o seguinte em mãos antes de fazer isso:
-
Um nome de domínio totalmente qualificado (FQDN). Este tutorial utilizará o
your_domaindurante todo o processo. Você pode comprar um nome de domínio em Namecheap, obter um gratuitamente em Freenom ou usar o registrado de domínios de sua escolha. -
Ambos os registros de DNS a seguir serão configurados para o seu servidor. Você pode seguir esta introdução para DNS DigitalOcean para mais detalhes sobre como adicioná-los.
- Um registro A com
your_domainapontando para o endereço IP público do seu servidor. - Um registro A com o
www.your_domainapontando para o endereço de IP público do seu servidor.
- Um registro A com
Passo 1 — Instalando e Configurando o Elasticsearch
Os componentes do Elasticsearch não estão disponíveis nos repositórios de pacotes padrão do Ubuntu. No entanto, eles podem ser instalados com o APT após adicionar a lista de origem de pacotes do Elastic.
Todos os pacotes são assinados com a chave de assinatura do Elasticsearch para proteger seu sistema de spoofing de pacotes. Os pacotes autenticados usando a chave serão considerados confiáveis pelo seu gerenciador de pacotes. Neste passo, você importará a chave GPG pública do Elasticsearch e adicionará a lista de origem de pacotes do Elastic para instalar o Elasticsearch.
Para começar utilize o cURL, a ferramenta de linha de comando para transferir dados com URLs, para importar a chave GPG pública do Elasticsearch para o APT. Observe que estamos usando os argumentos -fsSL para silenciar todo o progresso e possíveis erros (exceto para uma falha de servidor) e permitir que o cURL faça uma solicitação em um novo local se for redirecionado. Faça o pipe da saída do comando cURL no programa apt-key, que adiciona a chave pública GPG para o APT.
- curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Em seguida, adicione a lista de origem do Elastic ao diretório sources.list.d, onde o APT irá procurar por novas origens:
- echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Em seguida, atualize suas listas de pacotes para que o APT leia a nova origem do Elastic:
- sudo apt update
Em seguida, instale o Elasticsearch com este comando:
- sudo apt install elasticsearch
Agora, o Elasticsearch está instalado e pronto para ser configurado. Use seu editor de texto preferido para editar o arquivo de configuração principal do Elasticsearch, elasticsearch.yml. Aqui, usaremos o nano:
- sudo nano /etc/elasticsearch/elasticsearch.yml
Nota: o arquivo de configuração do Elasticsearch está no formato YAML, o que significa que precisamos manter o formato de indentação. Certifique-se de não adicionar nenhum espaço extra ao editar este arquivo.
O arquivo elasticsearch.yml fornece opções de configuração para seu cluster, node, paths, memória, rede, descoberta e gateway. A maioria destas opções estão pré-configuradas no arquivo, mas você pode alterá-las de acordo com suas necessidades. Para os fins de nossa demonstração de uma configuração de um único servidor, vamos ajustar apenas as configurações para o host de rede.
O Elasticsearch escuta o tráfego de todos os lugares na porta 9200. Você vai querer restringir o acesso externo à sua instância Elasticsearch para evitar que agentes externos leiam seus dados ou encerrem seu cluster Elasticsearch por meio da sua [API REST] (https://en.wikipedia.org/wiki/Representational_state_transfer). Para restringir o acesso e, portanto, aumentar a segurança, encontre a linha que especifica o network.host, descomente-a e substitua seu valor por localhost dessa forma:
. . .
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
. . .
Nós especificamos localhost para que o Elasticsearch escute em todas as interfaces e IPs ligados. Se você quiser que ele escute apenas em uma interface específica, você pode especificar o IP dela no lugar de localhost. Salve e feche o elasticsearch.yml. Se você estiver usando o nano, você pode fazer isso pressionando CTRL+X, seguido de Y e, depois, ENTER.
Essas são as configurações mínimas com as quais você começa para utilizar o Elasticsearch. Agora, inicie o Elasticsearch pela primeira vez.
Inicie o serviço Elasticsearch com o systemctl. Dê ao Elasticsearch alguns momentos para iniciar. Caso contrário, poderá haver erros quanto à indisponibilidade de conexão.
- sudo systemctl start elasticsearch
Em seguida, execute o seguinte comando para habilitar o Elasticsearch para iniciar sempre que seu servidor inicializar:
- sudo systemctl enable elasticsearch
Você pode testar se seu serviço Elasticsearch está em execução enviando uma requisição HTTP:
- curl -X GET "localhost:9200"
Você verá uma resposta mostrando algumas informações básicas sobre seu nó local, semelhantes a esta:
Output{
"name" : "Elasticsearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "qqhFHPigQ9e2lk-a7AvLNQ",
"version" : {
"number" : "7.7.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Agora que o Elasticsearch está funcionando, vamos instalar o Kibana, o próximo componente da pilha Elastic.
Passo 2 — Instalando e configurando o painel do Kibana
De acordo com a documentação oficial, você deve instalar o Kibana somente após instalar o Elasticsearch. A instalação nesta ordem garante que os componentes de que cada produto depende estejam corretamente instalados.
Como você já adicionou a fonte de pacotes Elastic no passo anterior, você pode apenas instalar os componentes restantes da pilha Elastic usando o apt:
- sudo apt install kibana
Em seguida, habilite e inicie o serviço Kibana:
- sudo systemctl enable kibana
- sudo systemctl start kibana
Como o Kibana está configurado para ouvir somente em localhost, devemos configurar um proxy reverso para permitir acesso externo a ele. Usaremos o Nginx para este fim, que já deve estar instalado em seu servidor.
Primeiro, use o comando openssl para criar um usuário administrativo do Kibana que você usará para acessar a interface Web do Kibana. Como exemplo, vamos nomear esta conta como kibanaadmin, mas para garantir maior segurança, recomendamos que você escolha um nome não padrão para seu usuário que seria difícil de adivinhar.
O comando a seguir irá criar o usuário administrativo e a senha do Kibana e armazená-los no arquivo htpasswd.users. Você irá configurar o Nginx para exigir esse nome de usuário e senha e ler este arquivo momentaneamente:
- echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
Digite e confirme uma senha no prompt. Lembre-se ou tome nota deste login, pois você precisará dele para acessar a interface Web do Kibana.
Em seguida, vamos criar um arquivo de bloco de servidor do Nginx. Como um exemplo, vamos nos referir a este arquivo como your_domain, embora você possa achar útil dar ao seu arquivo um nome mais descritivo. Por exemplo, se você tiver um registro FQDN e DNS configurado para este servidor, você pode nomear este arquivo após seu FQDN.
Usando o nano ou seu editor de texto preferido, crie o arquivo de bloco de servidor do Nginx:
- sudo nano /etc/nginx/sites-available/your_domain
Adicione o seguinte bloco de código ao arquivo, garantindo atualizar your_domain para corresponder ao FQDN do seu servidor ou endereço IP público. Este código configura o Nginx para direcionar o tráfego HTTP do seu servidor para a aplicação do Kibana, que está escutando em localhost:5601. Além disso, ele configura o Nginx para ler o arquivo htpasswd.users e requerer autenticação básica.
Observe que se você seguiu o tutorial de pré-requisitos do Nginx até o fim, você pode já ter criado este arquivo e o preenchido com algum conteúdo. Nesse caso, exclua todo o conteúdo existente no arquivo antes de adicionar o seguinte:
server {
listen 80;
server_name your_domain;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Quando você terminar, salve e feche o arquivo.
Em seguida, habilite a nova configuração criando um link simbólico para o diretório sites-enabled. Se você já criou um arquivo de bloco de servidor com o mesmo nome nos pré-requisitos do Nginx, você não precisa executar este comando:
- sudo ln -s /etc/nginx/sites-available/your_domain /etc/nginx/sites-enabled/your_domain
Em seguida, verifique a configuração para erros de sintaxe:
- sudo nginx -t
Se quaisquer erros forem relatados em sua saída, retorne e verifique se o conteúdo que você colocou em seu arquivo de configuração foi adicionado corretamente. Depois que você vir syntax is ok na saída, reinicie o serviço do Nginx:
- sudo systemctl reload nginx
Se você seguiu o guia de configuração inicial do servidor, você deverá ter um firewall UFW ativado. Para permitir conexões ao Nginx, podemos ajustar as regras digitando:
- sudo ufw allow 'Nginx Full'
Nota: se você seguiu o tutorial de pré-requisitos, do Nginx, você pode ter criado uma regra UFW permitindo o perfil Nginx HTTP através do firewall. Como o perfil Nginx Full permite tanto o tráfego HTTP quanto HTTPS através do firewall, você pode excluir com segurança a regra que você criou no tutorial de pré-requisitos. Faça isso com o seguinte comando:
- sudo ufw delete allow 'Nginx HTTP'
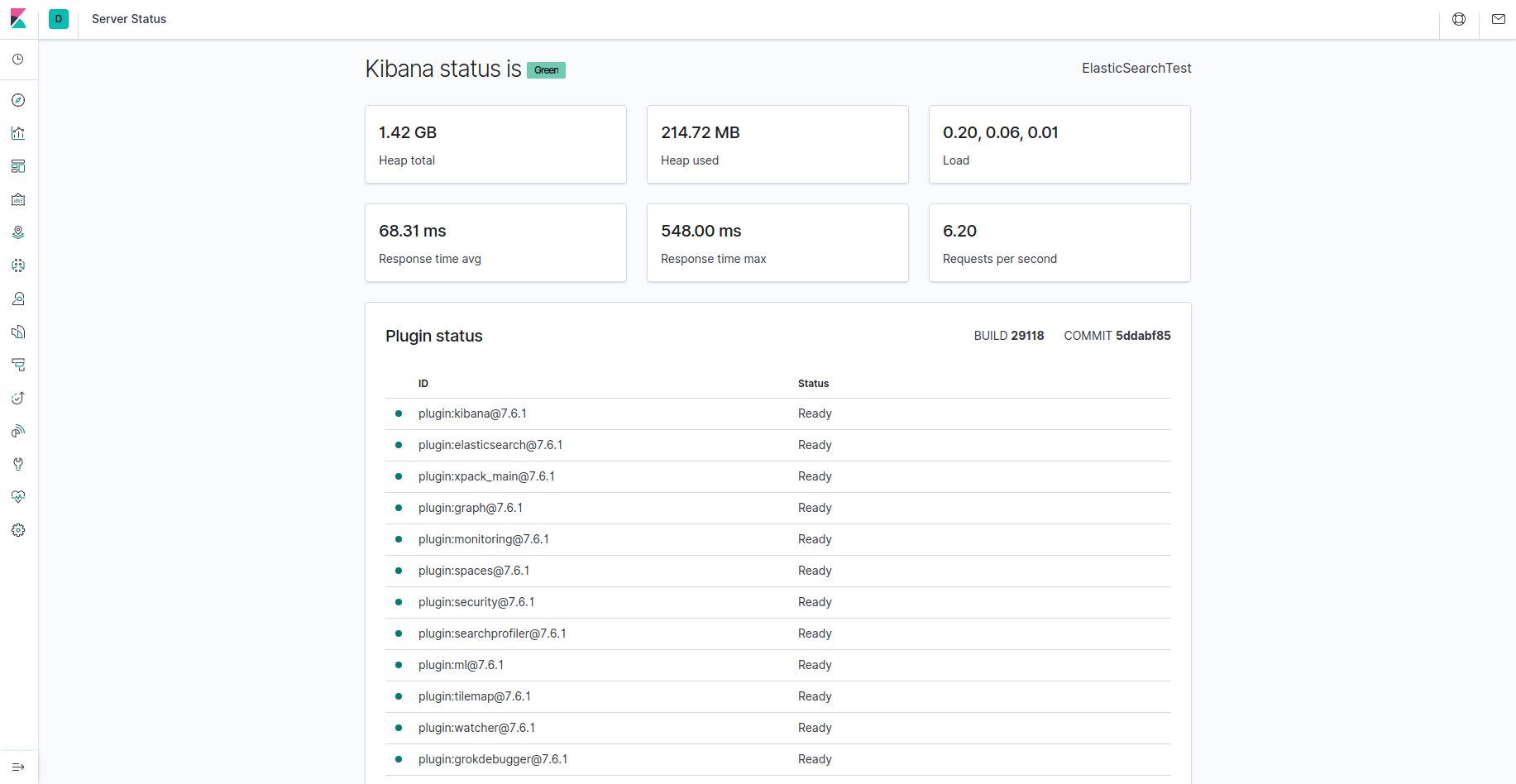
O Kibana agora está acessível através do seu FQDN ou do endereço IP público do seu servidor de pilha Elastic. Você pode verificar a página de status do servidor do Kibana navegando para o seguinte endereço e digitando suas credenciais de login quando solicitado:
http://your_domain/status
Esta página de status exibe informações sobre o uso de recursos do servidor e lista os plugins instalados.
Nota: conforme mencionado na seção de pré-requisitos, é recomendado que você habilite o SSL/TLS no seu servidor. Você pode seguir o guia do Let’s Encrypt agora para obter um certificado SSL gratuito para o Nginx no Ubuntu 20.04. Depois de obter seus certificados SSL/TLS, retorne para completar este tutorial.
Agora que o painel do Kibana está configurado, vamos instalar o próximo componente: Logstash.
Passo 3 — Instalando e configurando o Logstash
Embora seja possível para o Beats enviar dados diretamente para o banco de dados do Elasticsearch, é comum usar o Logstash para processar os dados. Isso lhe permitirá mais flexibilidade para coletar dados de diferentes fontes, transformá-los em um formato comum e exportá-los para outro banco de dados.
Instale o Logstash com este comando:
- sudo apt install logstash
Depois de instalar o Logstash, você pode seguir para configurá-lo. Os arquivos de configuração do Logstash residem no diretório /etc/logstash/conf.d. Para mais informações sobre a sintaxe de configuração, você pode conferir a referência de configuração que o Elastic fornece. À medida que você configura o arquivo, é útil pensar no Logstash como um pipeline que leva dados de uma extremidade, os processa de uma maneira ou de outra e os envia para seu destino (neste caso, o destino sendo o Elasticsearch). Um pipeline do Logstash tem dois elementos necessários, input e output, e um elemento opcional, filter. Os plugins input consomem dados de uma fonte, os plugins filter processam os dados e os plugins output gravam os dados para um destino.
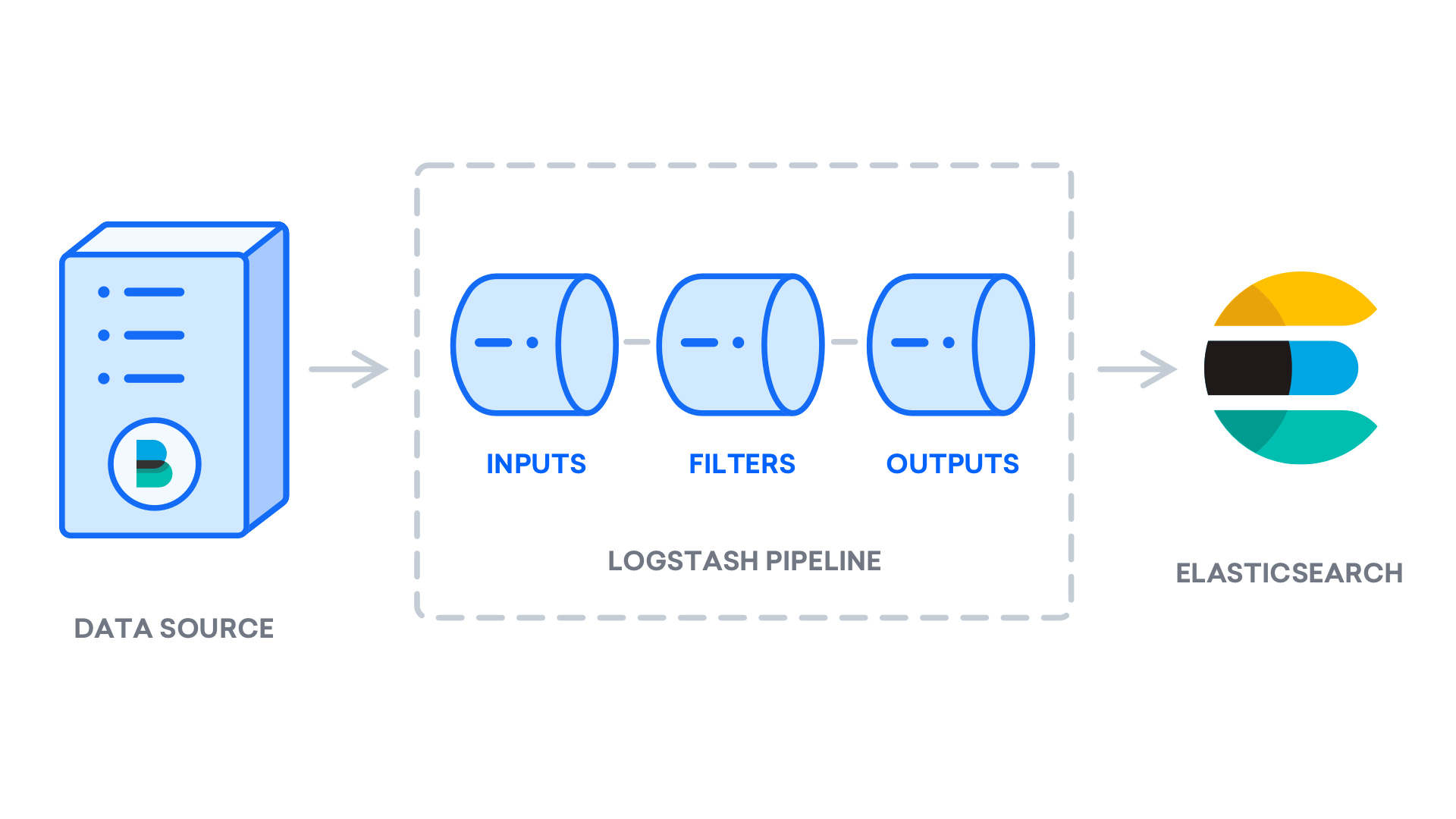
Crie um arquivo de configuração chamado 02-beats-input.conf onde você irá configurar sua entrada do Filebeat:
- sudo nano /etc/logstash/conf.d/02-beats-input.conf
Insira a seguinte configuração de input. Isso especifica uma entrada para o beats que irá ouvir na porta TCP 5044.
input {
beats {
port => 5044
}
}
Salve e feche o arquivo.
Em seguida, crie um arquivo de configuração chamado 30-elasticsearch-output.conf:
- sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf
Insira a seguinte configuração de output. Essencialmente, esta saída configura o Logstash para armazenar os dados do Beats no Elasticsearch, que está em execução em localhost:9200, em um índice com o nome do Beat usado. O Beat usado neste tutorial é o Filebeat:
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
}
Salve e feche o arquivo.
Teste sua configuração do Logstash com este comando:
- sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Se não houver erros de sintaxe, a saída irá exibir Config Validation Result: OK. Exiting Logstash após alguns segundos. Se você não vir isso em sua saída, verifique quaisquer erros na saída e atualize a configuração para corrigi-los. Observe que você receberá avisos do OpenJDK, mas eles não devem causar nenhum problema e podem ser ignorados.
Se seu teste de configuração for bem sucedido, inicie e habilite o Logstash para colocar as alterações de configuração em vigor:
- sudo systemctl start logstash
- sudo systemctl enable logstash
Agora que o Logstash está executando corretamente e está totalmente configurado, vamos instalar o Filebeat.
Passo 4 — Instalando e configurando o Filebeat
O Elastic Stack usa vários transportadores de dados leves chamados Beats para coletar dados de várias fontes e transportá-los para o Logstash ou para o Elasticsearch. Aqui estão os Beats que estão atualmente disponíveis na Elastic:
- Filebeat: coleta e despacha os arquivos de log.
- Metricbeat: coleta métricas de seus sistemas e serviços.
- Packetbeat: coleta e analisa dados de rede.
- Winlogbeat: coleta log de eventos do Windows.
- Auditbeat: coleta dados do framework de auditoria do Linux e monitora a integridade do arquivo.
- Heartbeat: monitora serviços para verificar sua disponibilidade com sonda ativa.
Neste tutorial, usaremos o Filebeat para encaminhar logs locais para nossa pilha Elastic.
Instale o Filebeat usando o apt:
- sudo apt install filebeat
Em seguida, configure o Filebeat para se conectar ao Logstash. Aqui, vamos modificar o arquivo de configuração de exemplo que vem com o Filebeat.
Abra o arquivo de configuração do Filebeat:
- sudo nano /etc/filebeat/filebeat.yml
Nota: assim como no Elasticsearch, o arquivo de configuração do Filebeat está em formato YAML. Isso significa que a indentação adequada é crucial, então certifique-se de usar o mesmo número de espaços que são indicados nessas instruções.
O Filebeat suporta inúmeras saídas, mas você geralmente apenas enviará eventos diretamente para o Elasticsearch ou para o Logstash para processamento adicional. Neste tutorial, usaremos o Logstash para realizar processamento adicional nos dados coletados pelo Filebeat. O Filebeat não precisará enviar quaisquer dados diretamente para o Elasticsearch, então vamos desativar essa saída. Para fazer isso, encontre a seção output.elasticsearch e comente as seguintes linhas precedendo-as com um #:
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
...
Então, configure a seção output.logstash. Descomente as linhas output.logstash: e hosts: ["localhost:5044"] removendo o #. Isso irá configurar o Filebeat para se conectar ao Logstash em seu servidor de pilha Elastic na porta 5044, a porta para a qual especificamos uma entrada do Logstash anteriormente:
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
Salve e feche o arquivo.
A funcionalidade do Filebeat pode ser estendida com módulos do Filebeat. Neste tutorial, usaremos o módulo system, que coleta e analisa logs criados pelo serviço de log de sistema das distribuições comuns do Linux.
Vamos habilitá-lo:
- sudo filebeat modules enable system
Você pode ver uma lista de módulos habilitados e desabilitados executando:
- sudo filebeat modules list
Você verá uma lista similar à seguinte:
OutputEnabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...
Por padrão, o Filebeat está configurado para usar caminhos padrão para o syslog e os logs de autorização. No caso deste tutorial, você não precisa alterar nada na configuração. Você pode ver os parâmetros do módulo no arquivo de configuração /etc/filebeat/modules.d/system.yml.
Em seguida, precisamos configurar os pipelines de ingestão do Filebeat, que analisa os dados de log antes de enviá-los através do logstash para o Elasticsearch. Para carregar o pipeline de ingestão para o módulo system, digite o seguinte comando:
- sudo filebeat setup --pipelines --modules system
Em seguida, carregue o modelo de índice no Elasticsearch. Um índice do Elasticsearch é uma coleção de documentos que têm características semelhantes. Os índices são identificados com um nome, que é usado para se referir ao índice ao realizar várias operações dentro dele. O modelo de índice será aplicado automaticamente quando um novo índice for criado.
Para carregar o modelo use o seguinte comando:
- sudo filebeat setup --index-management -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
OutputIndex setup finished.
O Filebeat vem empacotado com painéis de amostra do Kibana que lhe permitem visualizar dados do Filebeat no Kibana. Antes que você possa usar os painéis, você precisa criar o padrão de índice e carregar os painéis no Kibana.
Conforme os painéis carregam, o Filebeat se conecta ao Elasticsearch para verificar as informações da versão. Para carregar painéis quando o Logstash estiver habilitado, você precisa desativar a saída do Logstash e habilitar a saída do Elasticsearch:
- sudo filebeat setup -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Você deve receber um resultado similar a este:
OutputOverwriting ILM policy is disabled. Set `setup.ilm.overwrite:true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/elastic-stack-overview/current/xpack-ml.html
Loaded machine learning job configurations
Loaded Ingest pipelines
Agora, você pode iniciar e habilitar o Filebeat:
- sudo systemctl start filebeat
- sudo systemctl enable filebeat
Se você configurou sua pilha Elastic corretamente, o Filebeat começará a enviar seu syslog e logs de autorização para o Logstash, que então irá carregar esses dados no Elasticsearch.
Para verificar se o Elasticsearch está realmente recebendo esses dados, consulte o índice do Filebeat com este comando:
- curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Você deve receber um resultado similar a este:
Output...
{
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4040,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.7.1-2020.06.04",
"_type" : "_doc",
"_id" : "FiZLgXIB75I8Lxc9ewIH",
"_score" : 1.0,
"_source" : {
"cloud" : {
"provider" : "digitalocean",
"instance" : {
"id" : "194878454"
},
"region" : "nyc1"
},
"@timestamp" : "2020-06-04T21:45:03.995Z",
"agent" : {
"version" : "7.7.1",
"type" : "filebeat",
"ephemeral_id" : "cbcefb9a-8d15-4ce4-bad4-962a80371ec0",
"hostname" : "june-ubuntu-20-04-elasticstack",
"id" : "fbd5956f-12ab-4227-9782-f8f1a19b7f32"
},
...
Se sua saída mostrar 0 total hits, o Elasticsearch não está carregando nenhum log sob o índice que você pesquisou e você precisará revisar sua configuração por erros. Se você recebeu a saída esperada, continue até o próximo passo, no qual veremos como navegar por alguns painéis do Kibana.
Passo 5 — Explorando painéis do Kibana
Vamos retornar à interface Web do Kibana que instalamos anteriormente.
Em um navegador Web, vá até o FQDN ou endereço IP público do seu servidor de pilha Elastic. Se a sessão tiver sido interrompida, você precisará inserir novamente as credenciais que definiu no Passo 2. Depois de fazer login, você deve receber a página inicial do Kibana:
Clique no link Discover na barra de navegação à esquerda (você pode ter que clicar no ícone Expand no canto inferior esquerdo para ver os itens do menu de navegação). Na página Discover selecione o padrão de índice pré-definido filebeat-* para ver dados do Filebeat. Por padrão, isso irá lhe mostrar todos os dados de log dos últimos 15 minutos. Você verá um histograma com eventos de log e algumas mensagens de log abaixo:
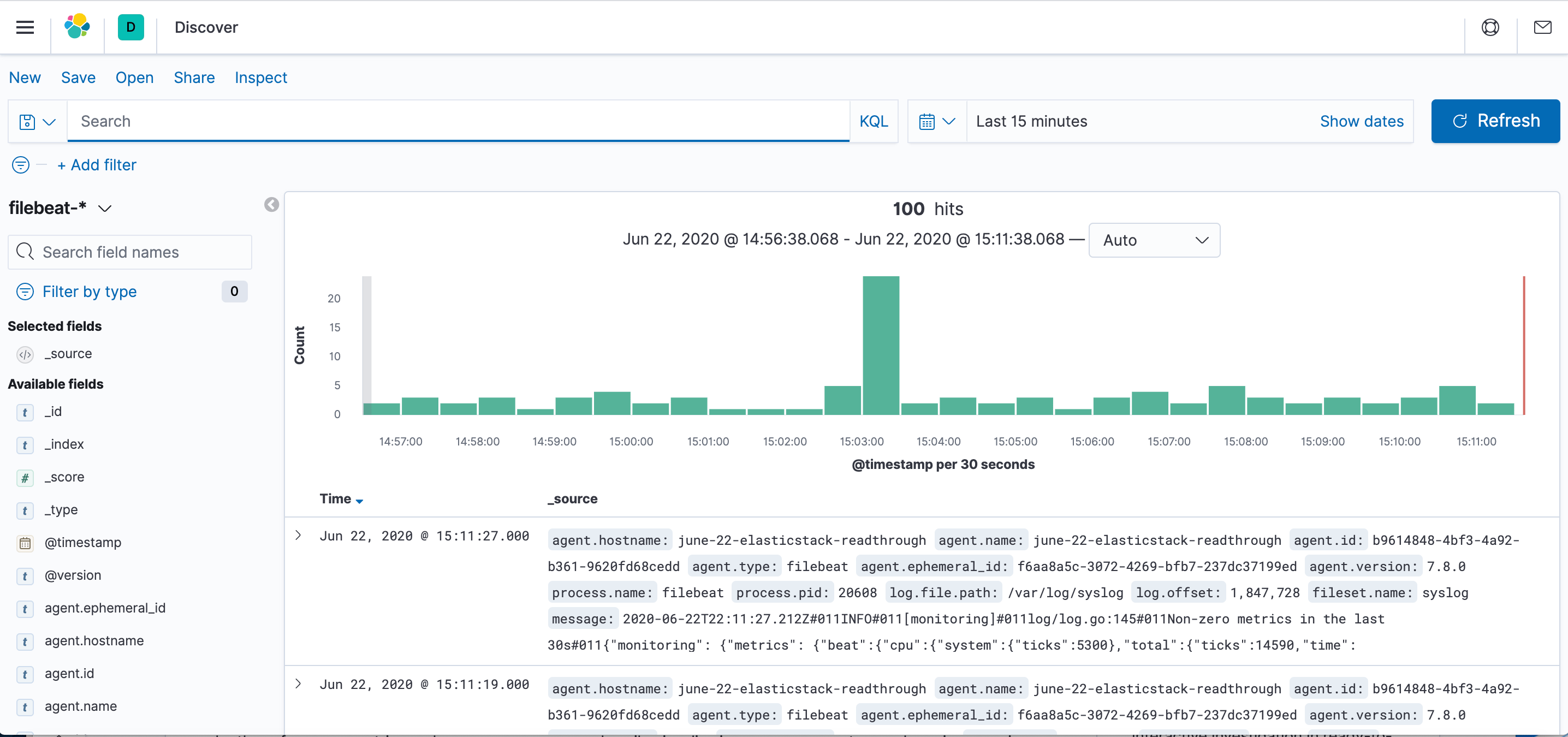
Aqui, você pode pesquisar e navegar pelos seus logs e também personalizar seu painel. Neste ponto, porém, não haverá muito lá porque você só está coletando syslogs do seu servidor de pilha Elastic.
Use o painel esquerdo para navegar até a página Dashboard e pesquise pelos painéis Filebeat System. Uma vez lá, você pode selecionar os painéis de amostra que vêm com o módulo system do Filebeat.
Por exemplo, você pode visualizar estatísticas detalhadas baseadas em suas mensagens syslog:
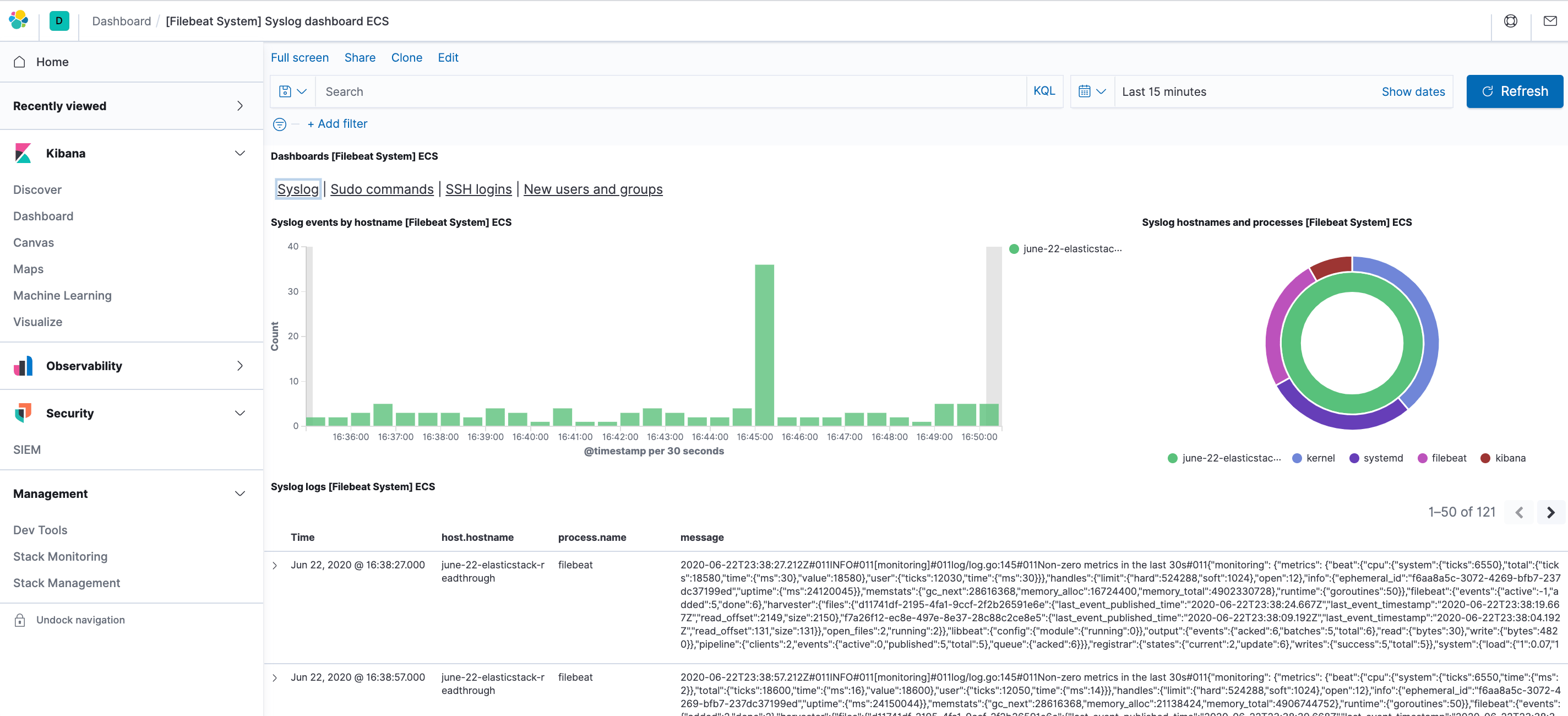
Você também pode visualizar quais usuários usaram o comando sudo e quando:
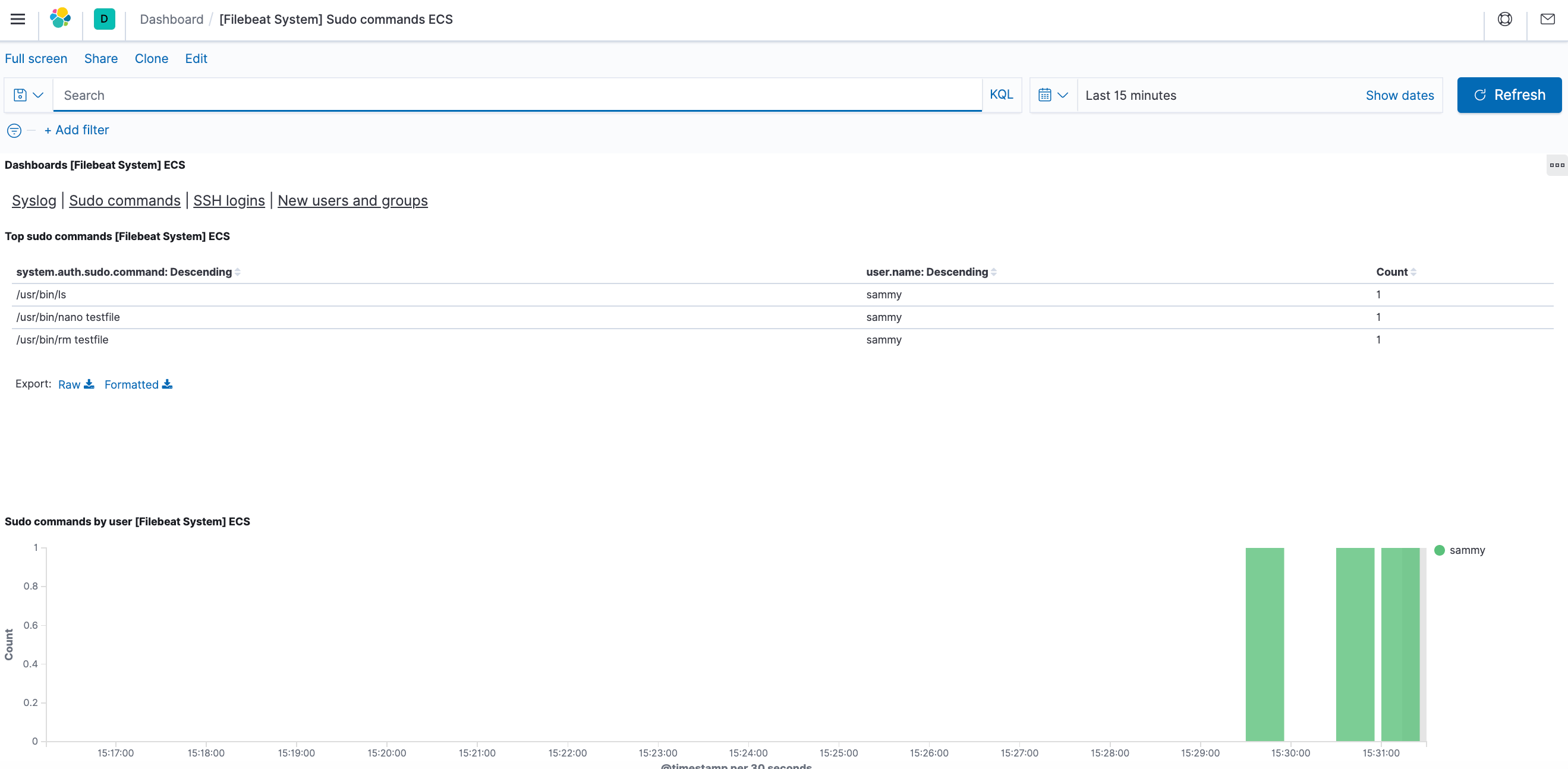
O Kibana tem muitos outros recursos, como gráficos e filtros, para você explorar.
Conclusão
Neste tutorial, você aprendeu como instalar e configurar a pilha Elastic para coletar e analisar logs de sistema. Lembre-se que você pode enviar praticamente qualquer tipo de log ou dados indexados para o Logstash usando o Beats, mas os dados tornam-se ainda mais úteis se eles forem analisados e estruturados com um filtro do Logstash, pois isso transforma os dados em um formato consistente que pode ser lido facilmente pelo Elasticsearch.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Open source advocate and lover of education, culture, and community.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
