By Adrien Payong and Shaoni Mukherjee

Introduction
Large Language Models workflows have evolved from a ‘nice‑to‑have’ to a must‑have requirement for modern agentic AI systems. Agents must be able to read, act, and reason across multiple web services. OpenAI’s Agents SDK provides a flexible framework for building such agents, but falls short of defining how to integrate external tools. That’s where Model Context Protocol comes in.
MCP is an emerging open standard for exposing tools and contextual data to LLMs through a consistent interface. In this comprehensive article, we’ll cover what MCP is, why it matters, and how to use MCP with the OpenAI Agents SDK. We’ll dive into the protocol’s architecture, setup instructions, best practices, and security considerations. We’ll also look at real‑world examples of agents using MCP and discuss the future of agentic integration.
Key Takeaways
- MCP = standard bridge: one protocol (using JSON-RPC) that allows agents to discover and invoke tools, and read/write data without building custom integrations.
- Plug-in power for OpenAI Agents: Attach MCP servers (GitHub, DBs, Slack, fetch, filesystem), and your agent instantly gains access to those tools.
- Scales and simplifies: Avoid N×M glue code with a standardized interface. Add capabilities by wiring in new MCP servers without modifying client code.
- Safer, traceable operations: Typed schemas + structured tool calls allow auditing, debugging, and enterprise guardrails.
- Future-ready stack: Backed by major vendors, MCP is trending toward the default for interoperable, multi-agent workflows.
What is the Model Context Protocol?
Model Context Protocol is an open standard for integrating AI apps with external systems. It specifies a uniform interface for AI agents (e.g., ChatGPT, Claude, etc) to discover and call upon “tools” or access data from a standard API. It is a language (over JSON-RPC) that decouples an AI model from the proprietary API of each individual tool or service. Anthropic first published the MCP standard in late 2024, and it has since rapidly emerged as “the new API for AI” integrations.
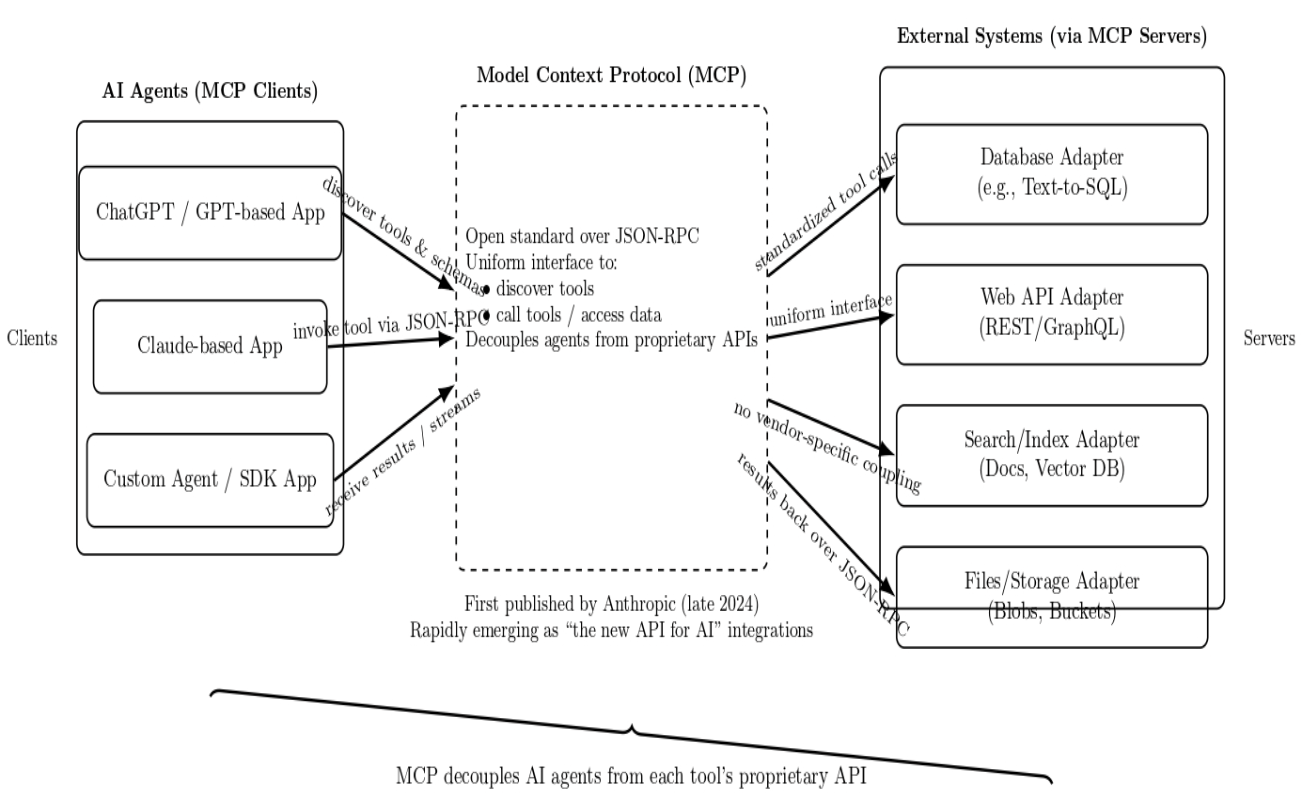
In the diagram above:
- On the left, one or more AI agents (clients) can discover tools using MCP, invoke tools, and receive tool results.
- In the middle, MCP provides a universal interface, built on the JSON-RPC standard. Agents can invoke tools or query data without having to know any proprietary tool APIs. MCP standardizes the interface between an agent and external systems.
- On the right, MCP servers can expose tools and data sources (e.g., databases, web APIs, search or vector databases, file storage, etc.) through a consistent schema.
MCP: The “USB-C” Port for AI Agents
This diagram below describes an AI agent with a single MCP client “port”, connected by a standard JSON-RPC “cable” to multiple MCP servers. Each cable adapts real resources to a common interface: one port, many swappable tools.
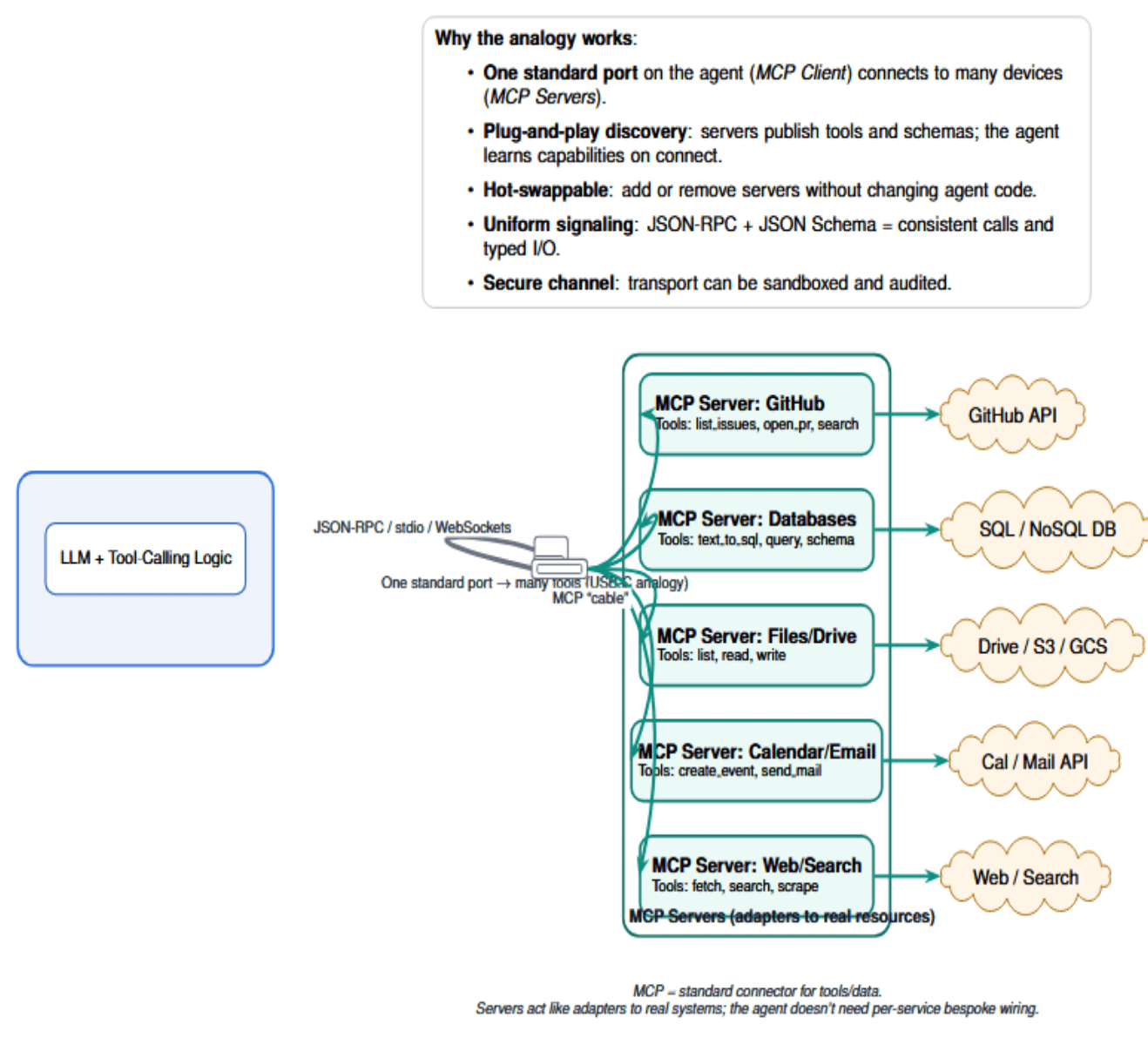
Key components of MCP include:
MCP Server: This is a program that exposes tools, data, or functions to an AI agent in a standard format. Each server is usually associated with a specific backend – for instance, a GitHub MCP server that allows an agent to list issues or PRs by calling GitHub’s API. It also communicates to the agent what tools are available to it (name, description, input/output schema), typically in a discovery step.
MCP Client: A component running as part of the AI host app (i.e., the agent or assistant). The client application is connected to an MCP server, manages the conversation (sending requests and receiving responses), and displays the results back to the AI model.
Tools (and Schema): In MCP, each available action is referred to as a tool. A tool has a name and a description of what it performs, but also a JSON Schema for its input parameters, and (optionally) output format. The schema allows the language model to recognize how to correctly call the tool and what result it should expect. For instance, a get_weather tool might take in a location string field as input and then return structured data on the weather. Tools are discovered by the agent through a standardized tools/list call; the server returns a list of tool definitions in JSON. For example, a tool list for an MCP server could look like:
{
"name": "get_weather",
"title": "Weather Information Provider",
"description": "Get current weather information for a location",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or zip code"
}
},
"required": ["location"]
},
"outputSchema": { ... }
}
This JSON snippet represents a simple tool definition for a weather API. The agent understands that it can call “get_weather” using a location parameter to get weather information.
Resources and Prompts: In addition to tools, MCP servers can also expose resources (pieces of data or documents that the model can retrieve) and prompts (predefined prompt templates). For instance, a server could offer a resource such as the content of a specific file or a prompt template for code generation.
Why does MCP matter?
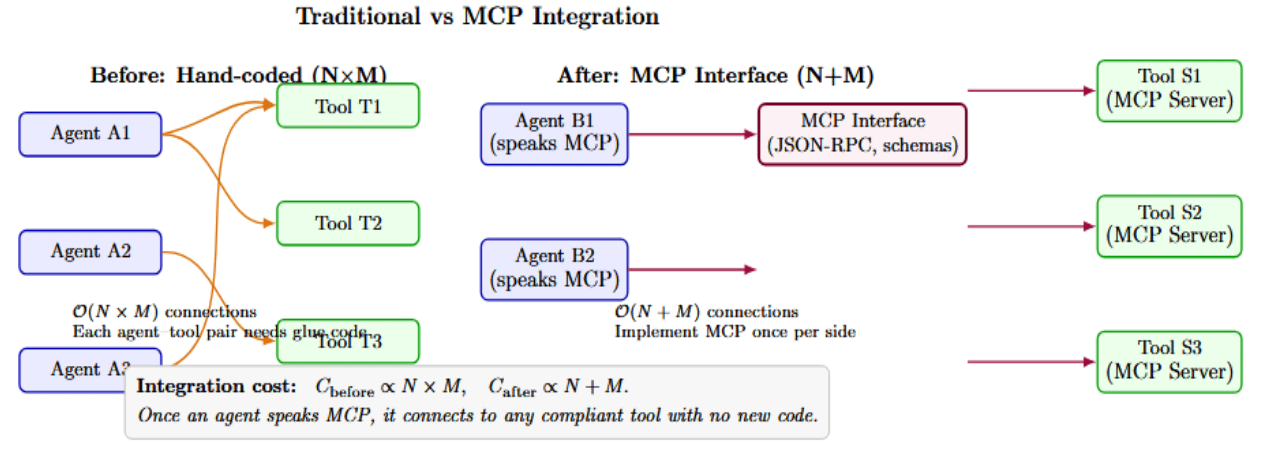
In traditional setups, adding a new capability involved hand-coding a new API’s interface with the AI assistant, custom prompts, and parsing. It doesn’t scale – it’s the “N×M integration problem”, where each new tool–agent combination requires a glue code. MCP provides a standard interface: once an agent speaks MCP, it can be connected to any MCP-compliant tool service with no new code. The diagram below contrasts two integration architectures.
What are OpenAI Agents and How Do They Work?
OpenAI Agents (from the OpenAI Agents SDK) are a framework for building LLM-powered agents that can plan and use tools in a structured way. The Agents SDK offers a high-level mechanism to define such agents, with features like:
- Tools & Function Calls: An agent can be provided a list of tools (Python functions, API calls, or even external skills) that it is permitted to use. The agent’s LLM will figure out when to invoke a tool in response to a user request. Under the hood, OpenAI’s own models use the Chat Completions API with function calling (or the newer Responses API) to support this tool.
- Planning and Multi-step Reasoning: The OpenAI Agents SDK also supports multi-step workflows, branching, and calling other agents (via “handoffs”). An agent could be set up, for example, to first decide to call a calculator tool, then a search tool, and formulate an answer – all as part of one atomic task.
- Provider-agnostic and Multi-LLM: It is provider-agnostic. It supports OpenAI’s own APIs (both the newer Responses API and the older, “classic” Chat Completions) and integration packages for other LLM providers.
- Built-in Guardrails and Tracing: The SDK includes safety(input/output guardrails), tracing (automatic logging of all decisions and tool calls by the agent), and debugging. In fact, OpenAI even provides a trace viewer you can use to see each step the agent took, which tool it called, how long it waited for that tool to respond, etc.
OpenAI Agents standardizes the approach to tool-using AI that was popularized by LangChain or AutoGPT. There’s no need to hand-code loops or write prompt chains. The Agents SDK offers a simple and Pythonic interface. For example, a very basic agent can be written as:
from agents import Agent, Runner
agent = Agent(
name="Assistant",
instructions="You are a helpful assistant that can use tools."
# (tools can be added here)
)
result = Runner.run_sync(agent, "Who won the World Cup in the year I graduated high school?")
print(result.final_output)
An agent like this could, if provided with a tool (e.g., a web search tool or knowledge base), independently decide to use it to retrieve the World Cup information. The developer doesn’t have to plan out those steps; you define the tools and the high-level goal.
How do Agents and MCP relate?
An agent can connect to one or more MCP servers and automatically gain access to all the tools those servers provide. Rather than implementing custom Python functions for each desired API, you can simply run or connect to an MCP server that exposes those APIs. As a result, the agent will enumerate those tools and call them when needed, as if they were built-in functions.
This effectively unlocks far more capabilities. The agent can access live data (company databases, cloud services, and more) instead of being limited to its training data and a few hard-coded tools you may have provided. It also enables more workflow automation – the agent can chain together multiple MCP-provided tools (even from different servers) to do a complex job.
Why Integrate MCP with OpenAI Agents?
What do you gain by combining MCP with your OpenAI agent? There are several key benefits:
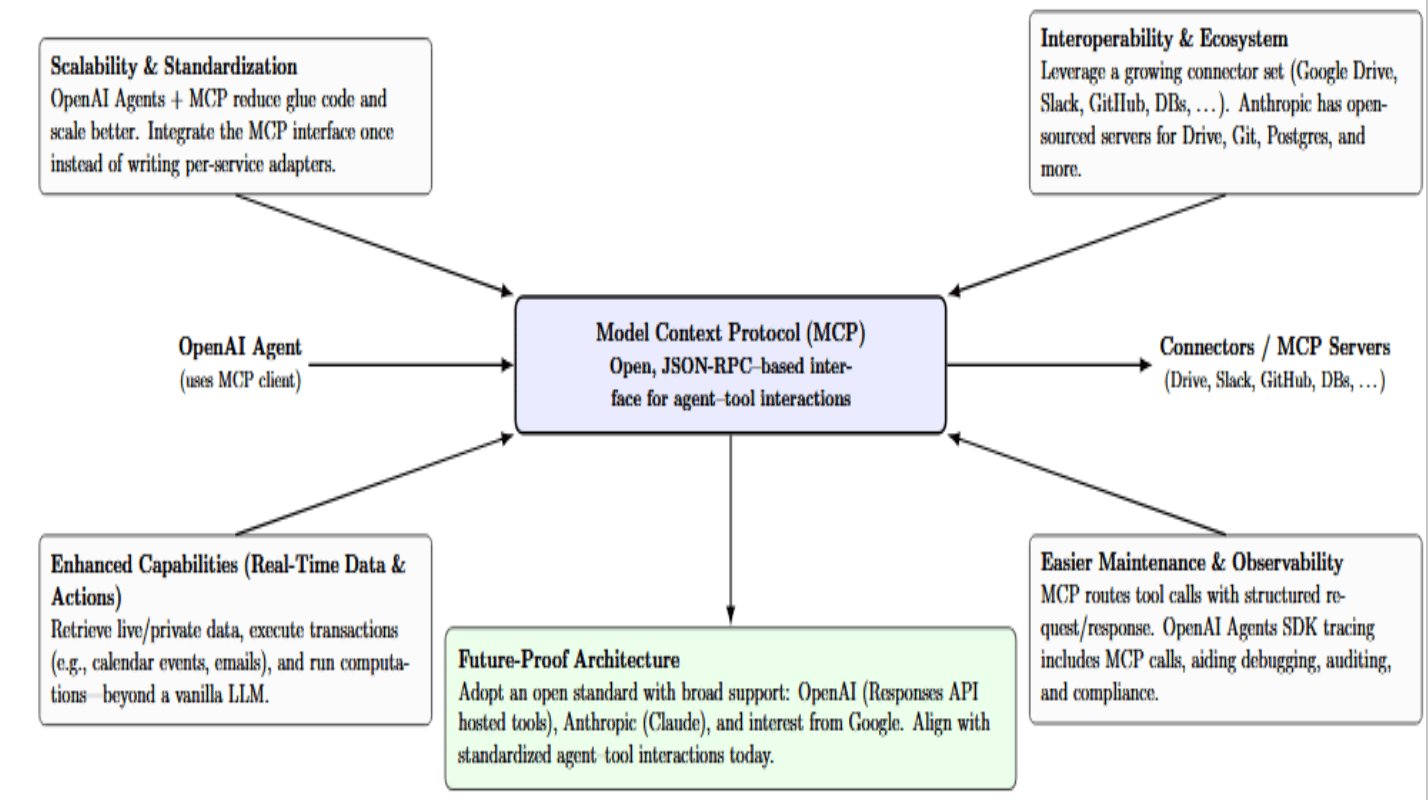
- Scalability & Standardization: OpenAI Agents + MCP result in less glue code and a more scalable architecture. Instead of writing custom integration code for each external service, you integrate the MCP interface once.
- Interoperability and Ecosystem: You can think of popular connectors like Google Drive, Slack, GitHub, databases, and more. By using MCP, the OpenAI agent can leverage this growing ecosystem of connectors. For example, Anthropic has already open-sourced their servers for Google Drive, Git, Postgres, and more.
- Enhanced Capabilities (Real-Time Data & Actions): An agent with MCP can do things that a vanilla LLM cannot. It can retrieve real-time or private data, perform transactions (e.g., create a calendar event, send an email, and more), or even execute computations on your behalf.
- Easier Maintenance & Observability: Routing tool usage through MCP provides a consistent way to log and monitor what your agent is doing. The OpenAI Agents SDKs tracing will automatically include MCP tool calls and their results. When something fails, you can introspect whether the agent misinterpreted a tool schema or whether the server failed to return a valid result. Observability is also improved because each tool call is a structured event (with request/response) that you can audit. This can be critical in an enterprise setting, for debugging and also compliance.
- Future-Proof Architecture: By using MCP, you are investing in an open standard with broad support. OpenAI’s platform itself has adopted MCP (e.g., the hosted tools in the Responses API), Anthropic’s Claude also supports MCP, and even Google has written about it as a promising approach. By connecting your agent to MCP today, you are aligning yourself with a trend towards standardized agent-tool interactions.
How to Set Up MCP with OpenAI Agents — Step by Step
Now, let’s get hands-on. In this section, we’ll walk through how to enable MCP in your OpenAI Agents setup. We’ll cover prerequisites, setting up an MCP server, configuring your agent to use it, and provide a simple example.
Prerequisites
Before integrating MCP, make sure you have the following environment ready:
- Python 3.9+ installed. The OpenAI Agents SDK is written in Python, so you’ll need a recent Python 3 environment.
- OpenAI API Key. You must get a valid API key with access to the OpenAI models you want to use with your agent. Set this key as an environment variable (OPENAI_API_KEY) or in a .env file. If you are using a .env file to store secrets (such as OpenAI key or tool tokens), you can also load it via python-dotenv or similar. The agent’s SDK will load OPENAI_API_KEY from the environment by default.
- OpenAI Agents SDK installed. This can be done via pip: pip install --upgrade openai-agents
- Node.js 18+ and npm (optional, but recommended). Having Node.js and npm lets you easily run those server packages. Ensure that you can run npx from the command line.
- MCP SDK or extension (if needed). The OpenAI Agents SDK (as of 2025) ships with built-in MCP support. Older versions of the SDK may require an extension library to add MCP support. For example, LastMile AI offers an openai-agents-mcp Python package, which patches MCP support into earlier Agents SDK versions. (pip install openai-agents-mcp and then import Agent from agents_mcp would, in this case, enable the mcp_servers feature.) On the current SDK, you can use agents.mcp directly.
- One note on MCPServerStdio: on the latest OpenAI Agents SDK, MCPServerStdio can be directly imported with “from agents.mcp import MCPServerStdio”.This class manages the lifecycle of an MCP server using stdio and is intended for use in local development/testing. If you have this in your SDK, you do not need the extension package.
- Tool/server access credentials. Depending on which MCP servers you want to use, you will likely require access tokens or API keys for those services.
Development environment: You can build a dedicated project directory and use a Python virtual environment. Additionally, the system must be able to execute asynchronous code (because we are likely to be using asyncio for the agent and MCP usage). It’s often necessary to use an async-compatible environment or write an asyncio.run(main()) to make non-blocking connections to MCP servers.
Configuring an MCP Server
The first step is to have an MCP server available for connection. You can leverage an existing MCP server implementation (for a common tool/data source) or implement your own MCP server (for a custom system). For this tutorial, we will be using existing servers to illustrate the process.
Choosing an MCP server: Anthropic’s MCP repository, as well as community contributions, provides servers for: a filesystem (file access), fetch for web content, Slack, GitHub, databases (Postgres), and more. Let’s assume we want our agent to be able to access the local filesystem and fetch web content. We can use the filesystem MCP server and the fetch MCP server provided by the MCP community. They are available as Node.js packages (@modelcontextprotocol/server-filesystem and @modelcontextprotocol/server-fetch).
Server configuration: The OpenAI Agents SDK can launch MCP server processes for you, providing the configuration. This is normally defined in a YAML config file called mcp_agent.config.yaml. The following is an example config that sets up two servers, “fetch” and “filesystem.”
mcp:
servers:
fetch:
command: npx
args: ["-y", "@modelcontextprotocol/server-fetch"]
filesystem:
command: npx
args: ["-y", "@modelcontextprotocol/server-filesystem", "."]
In this YAML:
- We define an MCP server called “fetch”. The command is npx (a way to run an npm package easily), and the args indicate that we are running the
@modelcontextprotocol/server-fetchpackage. This is a tool to fetch web URLs (an HTTP GET tool, etc. ). - Define an MCP server called “filesystem”. Its command is also
npx. However, this time it runs@modelcontextprotocol/server-filesystemwith “.” as an argument (which means it should serve the current directory). The filesystem server probably supplies tools such as list_files, read_file, etc., to interact with files within the allowed directory.
When you start your agent (in a step we’ll see below), the SDK will be able to use this config to start those two servers as subprocesses automatically. Note: -y flag in npx auto-confirms an installation if required.
An alternative to the above config-driven auto-spawning approach is to run an MCP server manually in another process or terminal. For example, to manually run the filesystem server in a command line, you might execute npx @modelcontextprotocol/server-filesystem in your project directory.
Configuring the Agent to Use MCP
Having an MCP server, configuring your OpenAI Agent to use it is a simple task. The idea is that you initialize the agent with an mcp_servers parameter, in addition to any normal tools you would provide. This mcp_servers parameter can either take the names of servers (if you’re using the YAML config style) or the server connection objects themselves (if you’re managing your servers in code).
Continuing with the above config, we will use our fetch and filesystem servers. Using the LastMile extension (or a recent Agents SDK release), we can do:
from agents_mcp import Agent # use agents_mcp extension if needed; otherwise from agents import Agent
agent = Agent(
name="MCP Agent",
instructions="You are a helpful assistant with access to both local tools and MCP-provided tools.",
tools=[ /* any native tools, e.g. get_current_weather function */ ],
mcp_servers=["fetch", "filesystem"] # names as defined in mcp_agent.config.yaml
)
When you supply mcp_servers=[“fetch”,“filesystem”], the SDK will look those names up in the config file and start each server. Internally, it starts the npx … server-fetch process and the server-filesystem process, and waits for those to be ready. It then calls each server’s tool-discovery and aggregates those tools into the agent’s list of tools, and the agent is good to go with a set of actions.
If you prefer to control things in code (using the official SDK’s classes), you could do something similar manually:
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
# Set up an MCP server for filesystem
fs_server = MCPServerStdio(
name="FS MCP Server",
params={
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "."]
}
)
# Set up an MCP server for fetch
fetch_server = MCPServerStdio(
name="Fetch MCP Server",
params={
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-fetch"]
}
)
async with fs_server as fs, fetch_server as fetch:
agent = Agent(
name="OpenAI Agent w/ MCP",
instructions="Use the tools to access files and web content as needed.",
mcp_servers=[fs, fetch] # pass the server instances directly
)
result = await Runner.run(agent, "Find a file named 'data.txt' and summarize its contents.")
In this snippet, we created two MCPServerStdio objects manually (they handle the process launch and stdio communication). We use async here to ensure these server processes indeed start and will get cleaned up after. We pass fs and fetch objects directly into mcp_servers, which gives the agent immediate access to them. Internally, the agent will get the list of tool definitions and then combine them with any native tools we provided. From the agent’s perspective, it now has a unified list of tools that contains, for example, read_file from the filesystem server and fetch_url from the fetch server (tool names are illustrative).
Tool discovery: Once set up, the agent’s planning loop will include the MCP tools. For example, if the user asks a question that requires external information (say, “summarize the contents of data.txt”), the agent can decide to call the read_file tool (belonging to the filesystem MCP server) to obtain the file contents and then process them further.
Multiple MCP servers: You can attach multiple servers to an agent. For instance, it would be possible to connect a filesystem server, a Slack server, and a database server all at once if your use case requires it.All the tools from all sources will be concurrently available to the agent.
At this stage, if all goes well, you have an instance of an OpenAI Agent that is MCP-enabled. In the following section, we will run an example.
Example: Using MCP in an Agent
To drive all that home, let’s go through a simple scenario. Imagine we want to have an agent that can search a local knowledge base (i.e., local files) and answer questions about it. We’d use the filesystem MCP server to let the agent read files.
Step 1: Prepare some data –Let’s assume we have a directory docs/ with some text files (such as .txt or .md files with content). For example, it could be docs/ProjectPlan.txt with some content in it.
Step 2: Run the filesystem MCP server – We only want the agent to be able to read from the docs/ directory. We can start the filesystem server with the path set to that location. Using our config, that would be: args: ["-y", "@modelcontextprotocol/server-filesystem", "docs"]. Alternatively, in code:
fs_server = MCPServerStdio(
name="FS",
params={"command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", "docs"]}
)
Step 3: Create and run the agent – The agent will connect to this server and then answer a user query. Here’s a self-contained code example (combining the above steps):
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
async def main():
# Launch the filesystem MCP server (serving the ./docs folder)
async with MCPServerStdio(
name="FS",
params={"command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", "docs"]}
) as fs:
# Instantiate the agent with the MCP server
agent = Agent(
name="DocAssistant",
instructions="You are an assistant who can access a document repository via tools.",
mcp_servers=[fs]
)
# Ask the agent a question that requires using the file-reading tool
query = "What does the project plan say about our launch date?"
result = await Runner.run(agent, query)
print(result.final_output)
# Run the async main
asyncio.run(main())
In the code above, the call Runner.run(agent, query) causes the agent to receive a user query “What does the project plan say about our launch date?”. The agent is aware (looking at its tool list) that it has some tools from the FS server, and probably a function such as read_file(file_path) or search_files(keyword), depending on the server’s implementation. Since the query provides a specific reference to a document name, “project plan”, the agent may choose to call a file search tool or attempt to read ProjectPlan.txt directly. The MCP server will perform the requested action (read the file) and return the file’s text to the agent. The agent (the LLM) then has the content and can construct an answer about the launch date in the project plan. Finally, result.final_output contains the answer, which is printed.
Example output: if our ProjectPlan.txt contained the line “The launch is expected in Q4 2025, approximately October,” the agent’s response could be: “As stated in the project plan, our expected launch date is during the fourth quarter of 2025, around October.” – and all of that created by the agent after reading the file with MCP.
Running & Testing
To run the agent, execute your Python script (or Jupyter notebook, etc.). The first time, you’ll notice it can take a while for the MCP servers to boot (particularly if there are packages to download). The agent can also emit logs on connection. E.g., it may print “FS MCP server started” or a list of available tools. It’s good practice to verify connectivity by explicitly listing tools after the connection. You can do “tools = await fs.list_tools()” (if using the low-level API) to see what’s being offered by the server.
Testing tool calls
Experiment with queries that use the tools. For our example, you could ask “List all files in the repository.” The agent might use the list_files tool from the filesystem server and return the list. You can see which tools are being called by watching the console or logs. The Agents SDK can log the tool invocation steps (particularly if you enable debugging logs. The statement logging.getLogger(“openai.agents”).setLevel(logging.DEBUG) will enable debug-level logging in the OpenAI Agents SDK for Python.
Tracing and debugging
The OpenAI platform also has a trace viewer for agent runs. You can get a URL in your code to view a run on the OpenAI platform by generating a trace ID and wrapping this run in the trace context manager. For example:
from agents import gen_trace_id, trace
trace_id = gen_trace_id()
print(f"View trace: https://platform.openai.com/traces/{trace_id}")
with trace(workflow_name="MCP Demo Workflow", trace_id=trace_id):
result = await Runner.run(agent, query)
This would log the entire conversation with tool calls to the OpenAI platform. This way, you can visually step through it. This is super helpful for debugging complex agent logic.
Best Practices & Pitfalls
While using MCP with agents is powerful, there are some best practices to follow and pitfalls to avoid. Here are important tips:
| Principle | Why it matters | What to do |
|---|---|---|
| Use typed schemas for tools & resources for clarity. | The LLM calls tools correctly only if the inputs/outputs are unambiguous. | Define strict JSON Schemas (required fields, enums, formats); include examples; validate at runtime. |
| Secure your MCP server: authentication, role-based access, guarding against prompt/tool abuse. | Prevents unauthorized access and tool misuse. | Enforce OAuth/tokens; least-privilege roles; rate limits; sanitize inputs; allowlist tools/servers. |
| Monitor performance/latency (multi-step workflows). | Tool calls add network/exec delay; bottlenecks hurt UX and cost. | Trace each call; log timings; batch operations; set timeouts/retries; cache safe results. |
| Maintain separation of concerns: agent logic vs tool logic. | Improves reliability and testability. | Keep planning/summarization in the agent; keep deterministic work in tools; unit-test tools; scenario-test agents. |
| Version your MCP schema and manage backward compatibility. | Avoids breaking agents when tools change. | Pin server versions; use semver; deprecate gradually; add contract tests; stage before prod. |
Real-World Use Cases
This is an executable map of agent use cases → specific examples → how the MCP pieces actually work. The left column names the scenario. The middle column shows the example. The right column deconstructs that process: which MCP servers the agent connects to, which tools it invokes (in sequence), and what’s done with results, errors, or approvals.
| Use case | What it enables (concise example) | MCP servers & key tools — how the process works |
|---|---|---|
| Internal Knowledge Base Assistant | Turn internal docs into a Q&A bot. Example: “How do I deploy on Kubernetes?” → agent searches repo docs → reads relevant files → summarizes. | Filesystem MCP (list_files, read_file) → Agent lists files or targets a known path; reads candidate docs. Enterprise Search MCP (search_files, semantic_search) → Agent issues a query; server returns ranked file paths/snippets. The agent then read_file on top hits, synthesizes an answer, and cites locations. |
| Data-Driven Decision Assistant | Natural-language insights over company data. Example: “Top-selling products last quarter?” → agent crafts SQL → fetches results → summarizes trends. | Postgres/DB MCP (execute_query, parameterized_query) → Agent constructs safe parameterized SQL; server executes, returns rows. Analytics MCP (get_sales_summary, timeseries_aggregate) → Agent issues higher-level aggregation calls to avoid N×1 queries; merges results, adds context (seasonality, outliers), returns a chart or bullets. |
| Multi-Tool Productivity Assistant | Orchestrate calendar, tasks, and messaging in one flow. Example: fetch deadline from Notion → create calendar event → notify team on Slack. | Notion/Asana MCP (get_page, create_task, update_task) → Agent fetches the deadline/metadata. **Calendar MCP (**create_event, list_events) → Agent creates meetings with attendees + reminders. Slack MCP (send_message, post_to_channel) → Agent posts confirmation and at-mentions the team. Tools can be chained in a single run; if any fail, we retry or ask the user. |
| DevOps & Code Agents | Automate PR reviews, deployments, and continuous integration steps. Example: “Deploy v1.2 to staging” → fetch config → deploy → report status. | Git/GitHub MCP (fetch_repo_file, open_pull_request, comment_on_pr) → Agent can read infra manifests/workflow files; can open/comment PRs with changes. Kubernetes MCP (deploy, get_pod_status, rollout_status) → Agent can apply manifests, or trigger rollout/poll status and surface logs/errors. Optional CI MCP triggers (run_pipeline, get_run_status) to coordinate build/test steps. |
| Interactive Voice / Chatbots with Dynamic Knowledge | Voice/chat assistants that query live backends. Example: “What’s my order status?” → query Orders DB → respond with details. | DB MCP (select, insert, update) → Agent queries Orders table with user/ID to retrieve status, ETA, etc**. Order/Inventory MCP** (get_order_status, get_inventory) → Domain tools abstract business logic. HTTP/Fetch MCP (fetch_url) → Agent calls REST endpoints for which there is no direct server. Result is sanitized, summarized and returned via TTS/Chat; sensitive actions may require to be confirmed by the user. |
Security & Governance Considerations
Below is a practical security & governance checklist for MCP-enabled agents. This checklist is a distillation of what to look for, why it matters, how to handle it - plus actionable example controls that you copy into your own environment.
| Consideration (exact wording) | Why it matters | Action checklist |
|---|---|---|
| Mention the emerging risk surface with MCP: exfiltration, tool misuse, and identity fragmentation. TechRadar | MCP expands what agents can access and do; weak guardrails can leak data, trigger unsafe actions, or spread secrets across many services. | Enforce least-privilege scopes. Isolate servers per team/tenant Rotate/expire credentials. Add human approvals for sensitive tools. Monitor unusual tool sequences. |
| Audit your MCP tool definitions, enforce minimal permissions, and log usage. | Misconfigured tools are the #1 failure point; audits prevent overbroad access and make incidents traceable. | Review schemas and auth scopes regularly. Pin MCP server versions (semver). Immutable, redacted audit logs of tool calls. Automated config drift checks in continuous integration. |
| Maintain agent traceability and explainability (which tool was called, why). | Clear traces enable debugging, incident response, user trust, and regulatory evidence of due process. | Per-run trace IDs and step logs. Capture tool name, args (redacted), timing, result status. Store “reason for call” summaries. Alert on anomaly patterns. |
| Compliance considerations for enterprise data. | Agents may handle PII/PHI/financial records; mishandling violates GDPR/HIPAA/SOX and internal policies. | Data classification & access tiers. data loss prevention/redaction on tool inputs/outputs. Residency controls & audit retention. DPIAs and vendor assessments |
Future of MCP + Agents
The table below contains a simplified view of the future direction of MCP and AI agents. It identifies key areas such as wider platform usage, emerging agent-to-agent patterns, an expanding marketplace of MCP servers, agents becoming first-class workflow components, and cross-vendor cooperation.
| Theme | What it means | Implications / Notes |
|---|---|---|
| Wider Adoption Across Platforms | MCP is being adopted by major players (OpenAI, Anthropic, Google DeepMind), with Microsoft Copilot and AWS Bedrock integrating MCP-style access. | Skills/tools built around MCP become portable; expect MCP to be as ubiquitous for tool-integration as HTTP. Official SDKs span Python, Java, Go, C#, etc. |
| Agent-to-Agent Communication (A2A) | Beyond agent→tool, agents coordinate with each other. One agent’s actions could be exposed as an MCP server callable by another. | Emerging orchestration patterns (delegation, shared memory, task queues) and projects like OpenAI Swarm point the way; MCP can provide the shared context layer. |
| Ecosystem of Tools (Marketplace) | A marketplace/directory of MCP servers (“plugins”) for everything from CRM to design tools. | Faster enterprise adoption via ready-made connectors; governance likely includes ratings, security/reliability vetting. |
| Agents as First-Class Workflow Components | Agents embedded throughout software (e.g., ERP UIs) executing real transactions via MCP-connected services. | “Agentic enterprise software” with AI woven into microservices; frameworks like Temporal/LangChain using Agents SDK + MCP for reliable hooks. (ref: temporal.io) |
| Collaboration & Standard Unity | MCP is open, community-driven; vendors may propose enhancements that ideally converge. | Watch the MCP community (GitHub, mailing lists). Real-world feedback will shape practical features and keep alternatives interoperable. |
Frequently Asked Questions
What is the Model Context Protocol (MCP)?
MCP is an open standard for connecting AI applications to external data sources, tools, and workflows. It uses a client–host–server architecture and JSON‑RPC to let agents discover and call tools dynamically.
How does MCP differ from the OpenAI Agents SDK’s built‑in tool‑calling?
The Agents SDK allows you to register Python functions as tools. MCP extends this by letting agents discover tools at runtime from remote or local servers via a standard protocol.
Can I use MCP with models other than OpenAI’s?
Yes. MCP is model‑agnostic; any model or framework that implements an MCP client can interact with MCP servers. Anthropic’s Claude and Google DeepMind’s Gemini also support MCP.
What are the main components of an MCP architecture?
An MCP deployment has a host that manages clients and enforces security, clients that maintain sessions with servers, and servers that expose tools, prompts, and resources.
What security risks exist when using MCP?
Major risks include prompt injection (malicious instructions in external content), tool poisoning (malicious tool metadata), OAuth vulnerabilities, and remote code execution. Supply‑chain attacks and insecure server configurations are also concerns. Follow strong authentication, input validation, least privilege, and monitoring practices to mitigate these risks.
How do I debug tool calls when using MCP with agents?
The OpenAI Agents SDK provides tracing utilities that are very handy. By using trace context managers or enabling debug logging, you can see step-by-step what tools were selected, what inputs were sent, and what outputs were returned. You can also manually call list_tools() on an MCP connection to see what the server offers, to verify it’s connected correctly.
What are the best practices for versioning MCP servers?
Use semantic versioning for your server and tool definitions. Advertise supported capabilities and versions in your metadata. When updating tools, change the version number or name and communicate changes to clients. Avoid caching tools when definitions change frequently; call invalidate_tools_cache() to refresh.
Conclusion
The Model Context Protocol is a core standard for the next generation of AI agents. It fills the crucial missing piece that unlocks the potential of LLMs. In addition, it allows us to transform large language models into practical, context-aware assistants that can be used to interface with real systems. If this sounds like something you want to get into, here are a few next steps:
- Try a simple demo: Follow along in this article to boot up a simple agent with an MCP server. Try a “hello world” where your agent uses MCP to read the contents of a local file.
- Browse some MCP servers: Visit the MCP documentation and community repository for any MCP servers that look interesting to you (databases, web services, SaaS apps, etc.), and give it a shot by adding one to your agent.
- Get involved in the community: Talk to people on the MCP GitHub, in chat, or in forums. The standard is evolving, and community feedback based on real-world usage is crucial. You’ll learn a ton from others’ experiences (common mistakes, smart applications, and so on).
- Look at your own use cases for MCP: What tool or data source could make your AI agent much more useful? Prototype an integration with that tool/data source over MCP and experience the value for yourself.
- Stay on top of security: Keep abreast of emerging best practices and consider implementing monitoring that’s MCP-aware (e.g., an alert if your agent suddenly calls a suspicious sequence of tools).
In adding MCP to your OpenAI Agents, you’re effectively endowing them with hands and feet with which to act in the digital world around us. The future of artificial intelligence is in AI agents that can safely access tools and data on our behalf, and MCP is a key enabler of that future.
Resources & Further Reading
- Official MCP Introduction – Anthropic Blog
- MCP Documentation and Specification
- LastMile AI’s openai-agents-mcp extension on GitHub-
- OpenAI Cookbook
- Connecting Agents to External Tools with MCP Servers
- The Model Context Protocol (MCP): A Game-Changer for Agentic AI
- Building Complex AI Workflows with OpenAI Agents SDK and MCP
- Extend LLMs with Amazon SageMaker using MCP
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
