AI Technical Writer

Introduction
In the world of Natural Language Processing (NLP), comparing and understanding the similarity between two strings is a fundamental task. Whether it’s correcting typos, detecting plagiarism, matching names, or evaluating machine-generated text, the ability to measure how “close” two strings are can significantly improve the performance of language-based applications.
One of the most well-known and widely used string similarity metrics is the Levenshtein Edit Distance. This algorithm identifies how similar two strings are. Often referred to as edit distance, this operation is widely used in NLP, spell checkers, search engines, and fuzzy string matching tasks. In this article, we will deep dive into implementing Levenshtein Distance in Python, comparing libraries, exploring performance, and examining its integration with modern NLP and LLMs.
Key Takeaways
- Levenshtein Distance is a fundamental string similarity metric that calculates the minimum number of single-character edits (insertions, deletions, substitutions) required to transform one string into another.
- It is widely used in spell checkers, fuzzy search, autocorrect, plagiarism detection, and bioinformatics.
- The algorithm uses dynamic programming, typically implemented with a matrix, offering deterministic and precise results.
- Python libraries like
Levenshtein,fuzzywuzzy, anddistancesimplify implementation for real-world tasks. - While powerful, Levenshtein Distance is computationally expensive and doesn’t capture semantic meaning, making it less ideal for deep NLP tasks involving full-text comparison.
- Other similarity metrics like Jaro-Winkler, Damerau-Levenshtein, Jaccard, and Cosine Similarity offer different strengths depending on the context (e.g., name matching, token comparison, semantic similarity).
How Levenshtein Distance Works
Levenshtein Distance measures the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one string into another. Let us take a simple yet complete explanation of Levenshtein Edit Distance using a matrix example and an easy-to-understand explanation:
“book” → “back”
Let:
String 1, s1 = "book"(length = 4)String 2, s2 = "back"(length = 4)
Step 1: Initialize the Matrix
To represent the strings in a matrix, we will create a 5 X 5 matrix and to also include the empty string (“ ”) at index 0.
Empty Matrix Initialization:
| b | a | c | k | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| b | 1 | ||||
| o | 2 | ||||
| o | 3 | ||||
| k | 4 |
Step 2: Fill in the Matrix
The Levenshtein distance between two strings i, j (of length | i | and | j | respectively) is given by D ( i, j ) where:

Let’s fill a few key cells:
Cell (1,1): Compare ‘b’ and ‘b’ → Match
D(1,1)=D(0,0)=0
Cell (2,2): Compare ‘o’ and ‘a’ → No match
D(1,2)= 1 (deletion)D(2,1)= 2 (insertion)D(1,1)= 0 (substitution)
D(2,2)=1+min(1,2,0)=1
Cell (3,3): Compare ‘o’ and ‘c’ → No match
D(2,3)= 2D(3,2)= 2D(2,2)= 1
D(3,3)=1+min(2,2,1)=2 Continue this process…
Step 3: Final Matrix
| b | a | c | k | ||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| b | 1 | 0 | 1 | 2 | 3 |
| o | 2 | 1 | 1 | 2 | 3 |
| o | 3 | 2 | 2 | 2 | 3 |
| k | 4 | 3 | 3 | 3 | 2 |
Step 4: Final Result
Levenshtein Distance D(4,4) = 2
So, it takes 2 operations to turn “book” → “back”:
- Substitute ‘o’ → ‘a’
- Substitute ‘o’ → ‘c’
We calculated the edit distance and constructed a matrix incrementally in the example above. The Levenshtein Distance is determined by considering insertions, deletions, and substitutions at each step, with the final result located in the matrix’s bottom-right cell.
Implementing Levenshtein Distance in Python (Without Libraries)
Here’s the Python code to compute and print the Levenshtein distance with the matrix.
def levenshtein_distance(s1, s2):
m, n = len(s1), len(s2)
dp = [[0 for _ in range(n+1)] for _ in range(m+1)]
# Initialize base cases
for i in range(m+1):
dp[i][0] = i
for j in range(n+1):
dp[0][j] = j
# Fill the matrix
for i in range(1, m+1):
for j in range(1, n+1):
if s1[i-1] == s2[j-1]:
cost = 0
else:
cost = 1
dp[i][j] = min(
dp[i-1][j] + 1, # deletion
dp[i][j-1] + 1, # insertion
dp[i-1][j-1] + cost # substitution
)
# Print the matrix
print("Levenshtein Distance Matrix:")
print(" ", " ".join([" "] + list(s2)))
for i in range(m+1):
row = [s1[i-1] if i > 0 else " "]
for j in range(n+1):
row.append(str(dp[i][j]))
print(" ".join(row))
return dp[m][n]
# Example: "book" to "back"
s1 = "book"
s2 = "back"
distance = levenshtein_distance(s1, s2)
print(f"\nLevenshtein distance between '{s1}' and '{s2}' is {distance}")
**Levenshtein Distance Matrix:**
**b a c k**
**0 1 2 3 4**
**b 1 0 1 2 3**
**o 2 1 1 2 3**
**o 3 2 2 2 3**
**k 4 3 3 3 2**
Levenshtein distance between ‘book’ and ‘back’ is 2
Using Python Libraries for Levenshtein Distance
1. Using python-Levenshtein
!pip install python-Levenshtein
import Levenshtein
s1 = "book"
s2 = "back"
distance = Levenshtein.distance(s1, s2)
print(f"Levenshtein distance: {distance}")
2. Using fuzzywuzzy (for fuzzy matching)
!pip install fuzzywuzzy python-Levenshtein
from fuzzywuzzy import fuzz
s1 = "book"
s2 = "back"
# Fuzzy match ratio based on Levenshtein distance
ratio = fuzz.ratio(s1, s2)
print(f"Fuzzy match ratio: {ratio}%")
Note: fuzz.ratio() returns a percentage similarity, not the distance itself.
3. Using rapidfuzz (lightweight and fast)
!pip install rapidfuzz
from rapidfuzz.distance import Levenshtein
s1 = "book"
s2 = "back"
distance = Levenshtein.distance(s1, s2)
print(f"Levenshtein distance: {distance}")
4. Using distance (simple and pure Python)
!pip install distance
import distance
s1 = "book"
s2 = "back"
distance_val = distance.levenshtein(s1, s2)
print(f"Levenshtein distance: {distance_val}")
5. Using textdistance (flexible and supports many algorithms)
!pip install textdistance
import textdistance
s1 = "book"
s2 = "back"
distance = textdistance.levenshtein(s1, s2)
print(f"Levenshtein distance: {distance}")
Complete Python Performance Benchmark
The Python benchmarking script provided below compares Levenshtein Distance performance across the libraries: rapidfuzz, python-Levenshtein, textdistance, and distance.
First, install dependencies if not already:
pip install matplotlib rapidfuzz python-Levenshtein textdistance distance
import time
import matplotlib.pyplot as plt
import Levenshtein
import textdistance
import distance as dist
from rapidfuzz.distance import Levenshtein as r_lev
# Strings to compare
s1 = "book"
s2 = "back"
N = 100_000
# Store results
results = {}
# Benchmark function
def benchmark(name, func):
start = time.time()
for _ in range(N):
func(s1, s2)
end = time.time()
duration = end - start
avg_time_us = duration / N * 1e6
results[name] = (duration, avg_time_us)
print(f"{name:<25}: {duration:.4f} sec (Avg: {avg_time_us:.2f} µs)")
print("Benchmarking Levenshtein Distance (100,000 repetitions):\n")
# Run benchmarks
benchmark("rapidfuzz", lambda a, b: r_lev.distance(a, b))
benchmark("python-Levenshtein", lambda a, b: Levenshtein.distance(a, b))
benchmark("textdistance", lambda a, b: textdistance.levenshtein(a, b))
benchmark("distance (pure Python)", lambda a, b: dist.levenshtein(a, b))
# Plotting the results
libraries = list(results.keys())
total_times = [results[lib][0] for lib in libraries]
avg_times = [results[lib][1] for lib in libraries]
plt.figure(figsize=(10, 5))
bars = plt.bar(libraries, avg_times, color=['#66c2a5', '#fc8d62', '#8da0cb', '#e78ac3'])
plt.title("Levenshtein Distance Avg Time per Call (µs)")
plt.ylabel("Average Time (µs)")
plt.xlabel("Python Library")
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
# Annotate bars with actual times
for bar, avg in zip(bars, avg_times):
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval + 0.5, f"{avg:.2f}", ha='center', va='bottom', fontsize=9)
plt.show()
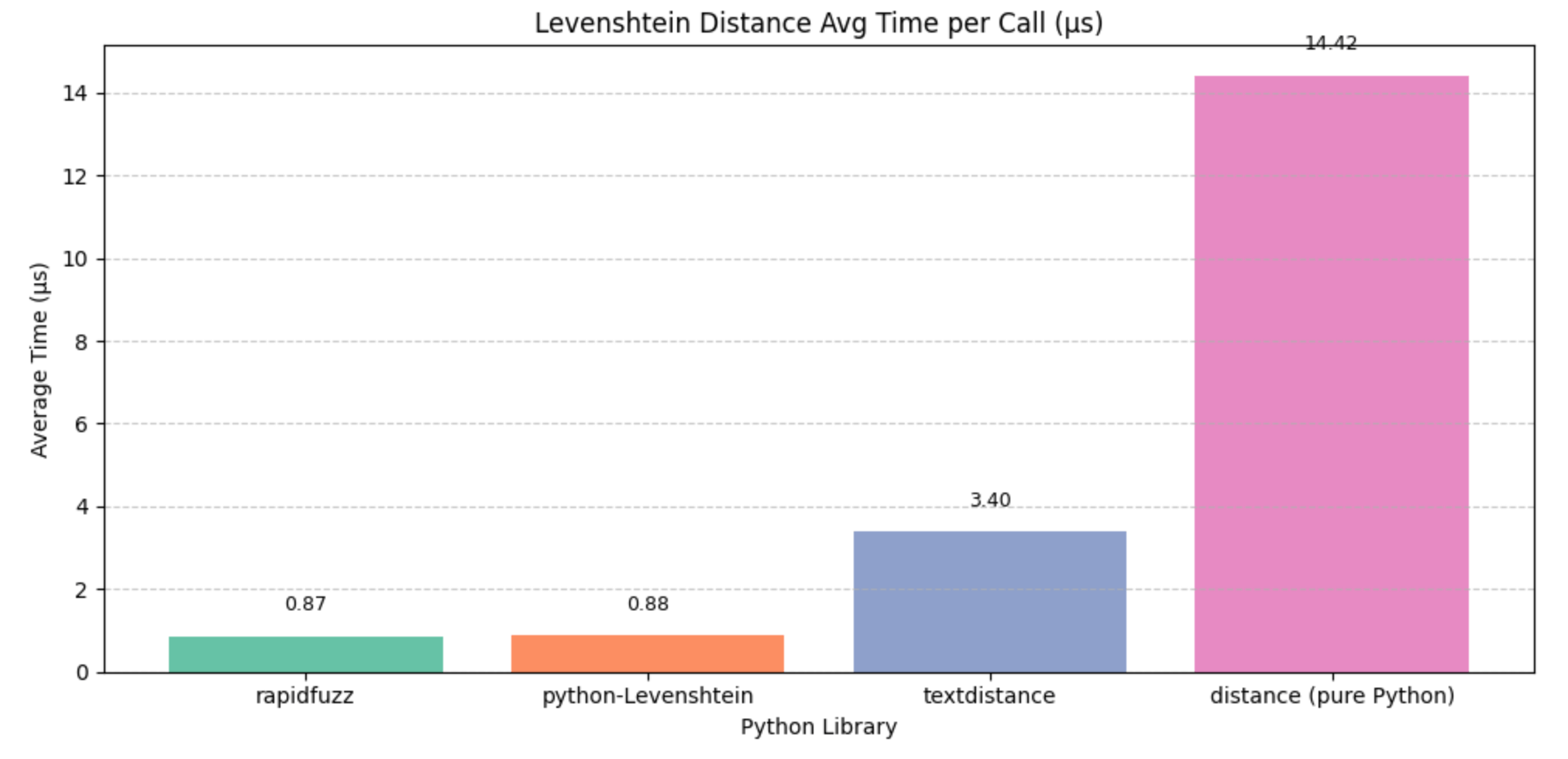
Benchmarking Levenshtein Distance (100,000 repetitions):
rapidfuzz : 0.0866 sec (Avg: 0.87 µs)
python-Levenshtein : 0.0881 sec (Avg: 0.88 µs)
textdistance : 0.3400 sec (Avg: 3.40 µs)
distance (pure Python) : 1.4420 sec (Avg: 14.42 µs)
Comparison with Other String Similarity Metrics
String similarity matrices is a process where a structured representation of strings are used to quantify how similar or dissimilar the words are to each other. This is done by capturing character-level or token-level differences in a tabular form. These matrices are central to algorithms like Levenshtein, Damerau-Levenshtein, and others, where each cell in the matrix denotes the “cost” or “distance” required to convert one substring into another through a sequence of operations such as insertion, deletion, substitution, or transposition.
The matrix is typically initialized with incremental values along its first row and column, representing the cost of converting an empty string to the characters of the other string.
As the matrix is filled row by row and column by column, each cell is computed based on a recurrence relation that compares the current characters and derives the minimum cost from previous cells. This process creates a dynamic programming grid where the bottom-right cell holds the final similarity score or distance between the full strings. String similarity matrices serve as the foundation for advanced NLP tasks like spell-checking, fuzzy matching, and data deduplication.
Different metrics have different goals, and they may emphasize edit distance, token similarity, or phonetic sound.
| Metric | Type | What it Measures | Range | Notes |
|---|---|---|---|---|
| Levenshtein Distance | Edit Distance | Minimum insertions, deletions, substitutions | 0 to ∞ | Penalizes each character-level change equally |
| Damerau-Levenshtein | Edit Distance | Like Levenshtein but also considers transpositions | 0 to ∞ | More realistic for typos (e.g. “acress” → “caress”) |
| Hamming Distance | Edit Distance | Number of different positions (only for equal length) | 0 to n | Fast, but less flexible |
| Jaro / Jaro-Winkler | Similarity | Measures character agreement and transpositions | 0.0–1.0 | Good for short strings and names |
| Jaccard Similarity | Set-Based | Intersection over union of sets/tokens | 0.0–1.0 | Good for longer texts or token-based comparison |
| Cosine Similarity | Vector-Based | Angle between TF-IDF or word vector representations | -1.0–1.0 | Used in NLP pipelines; needs vectorization |
| Sorensen-Dice | Set-Based | 2 * | A ∩ B | This metric assesses the similarity between a computer-segmented image and its corresponding ground truth (the correct answer). |
| Soundex / Metaphone | Phonetic | Encodes strings by pronunciation | Match/No match | Best for names or pronunciation-based matching (e.g., in genealogy) |
Let us consider the “book” and “back” example again:
| Metric | Value | Interpretation |
|---|---|---|
| Levenshtein | 2 | 2 character edits needed |
| Damerau-Levenshtein | 2 | Same as Levenshtein (no transposition here) |
| Hamming | 2 | Only valid because lengths are equal |
| Jaro-Winkler | ~0.83 | Fairly similar short strings |
| Jaccard (character set) | 0.5 | {‘b’,‘o’,‘k’} ∩ {‘b’,‘a’,‘c’,‘k’} |
| Cosine (TF-IDF) | Depends on corpus | Needs vectorization |
While Levenshtein distance is excellent for general-purpose, character-level string comparisons, more specialized metrics offer improved performance for specific use cases. Jaro-Winkler and Damerau-Levenshtein are particularly effective for handling name matching and typographical errors, as they give higher similarity to strings with common prefixes or transposed characters.
In contrast, set-based metrics such as Jaccard and Dice coefficient are better suited for comparing strings at the word or token level, making them ideal for document or phrase similarity tasks.
For capturing meaning beyond surface-level characters, vector-based metrics like cosine similarity, which operate on TF-IDF or embedding vectors, are powerful tools for semantic comparisons in full-text or NLP applications. Each of these metrics offers a unique perspective on similarity, and the choice depends on the granularity and context of the comparison.
Applications in NLP and LLMs
Levenshtein edit distance is considered the base tool in natural language processing tasks. Its ability to quantify how different two strings are by calculating the minimum number of insertions, deletions, or substitutions makes it ideal for handling noisy or user-generated text. In modern NLP pipelines and large language models (LLMs), Levenshtein distance often plays a supporting role, whether in preprocessing tasks like data cleaning, spell correction, or evaluation tasks such as comparing generated outputs with reference answers. Here are a few of the key applications of Levenshtein edit distance:
- Spell Checking and Auto-correction Identify and correct typos by finding the closest dictionary word using minimum edit distance.
- Fuzzy String Matching Match misspelled or approximately similar strings in applications like search, autocomplete, and OCR.
- Text Normalization Preprocess noisy or user-generated text before feeding it into NLP pipelines.
- Named Entity Matching Improve entity resolution in tasks like deduplication and linking names with minor differences.
- Evaluation of Text Generation Compare model-generated answers with ground truth in tasks like summarization or translation.
- Intent Recognition in Chatbots Help match user queries to predefined intents despite spelling errors or variants.
- Data Deduplication Detect near-duplicate records in datasets, especially in databases with inconsistent entries.
Pros of Levenshtein Distance
Levenshtein edit distance is easy to understand and fairly easy to calculate, as discussed in this article. It requires measuring the minimum number of single-character edits required to transform one string to another. This simplicity makes it a go-to solution for many basic string comparison tasks. Further, the operation is language-agnostic as it operates purely at the character level. Levenshtein distance does not require any language-specific rules, making it applicable across different languages and character sets. The distance it calculates is exact and deterministic, offering a well-defined and reproducible measure of difference between strings.
Cons of Levenshtein Distance
- Calculating the Levenshtein Distance can be computationally expensive as its time complexity is O(m × n) (where m and n are the lengths of the input strings), which can be slow for long strings or when comparing large datasets.
- Levenshtein Distance is insensitive to Context and Meaning as it only measures character-level differences and doesn’t account for semantic meaning. For example, “cat” and “feline” have a high edit distance but are semantically similar.
- Basic Levenshtein distance does not handle transposed characters well. For example, “form” and “from” are similar in meaning and appearance but have a distance of 2. Damerau-Levenshtein handles this better.
- Levenshtein distance treats insertions, deletions, and substitutions with equal weight. In real applications, some edits (e.g., substituting similar-looking characters) might be more likely or less costly than others.
- Since Levenshtein distance focuses on individual characters, it’s less effective for tasks that require token- or phrase-level similarity, such as semantic matching or text classification.
FAQs
How to calculate Levenshtein distance in Python?
You can use the python-Levenshtein, rapidfuzz, or write a custom dynamic programming solution.
How do you calculate Levenshtein Distance in Python without a library? Use a nested loop and a dynamic programming table as shown in the code example above.
What is the time complexity of Levenshtein Distance? O(m*n), where m and n are the lengths of the two strings.
What’s the difference between Levenshtein Distance and Hamming Distance? Hamming only works for equal-length strings and counts character mismatches; Levenshtein handles insertions and deletions too.
Which Python library is fastest for Levenshtein Distance?
rapidfuzz is generally the fastest and most efficient for production use.
Is Levenshtein Distance used in machine learning or LLMs? Yes. It’s used in preprocessing, deduplication, and postprocessing. It also complements semantic matching techniques in LLM pipelines.
Conclusion
Levenshtein Distance remains a foundational algorithm for string similarity in Python. While newer semantic models have expanded what’s possible in NLP, Levenshtein still plays a key role in tasks requiring literal string comparison. With powerful libraries like rapidfuzz and hybrid approaches combining edit distance with embeddings, Python developers have more tools than ever to tackle fuzzy string matching.
Ready to experiment? Try integrating Levenshtein matching into your next NLP or chatbot project using Python and DigitalOcean GPU Droplets for scalable compute.
Related Resources
- https://www.digitalocean.com/resources/articles/machine-learning-vs-natural-language-processing
- https://www.digitalocean.com/community/tutorials/nlp-models-using-backtracking
- https://www.digitalocean.com/resources/articles/nlp-vs-nlu
- https://www.digitalocean.com/community/tutorials/prompt-based-learning-in-natural-language-processing
- https://www.digitalocean.com/community/tutorials/enhancing-nlp-models-against-adversarial-attacks
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
