AI Technical Writer

Introduction
Retrieval-Augmented Generation (RAG) is widely used to improve AI responses by combining large language models with external knowledge sources such as documents, databases, and PDFs. In theory, RAG should help AI systems give accurate, up-to-date, and context-aware answers.
However, many developers find that their RAG systems do not work as expected. Instead of producing useful answers, the system may generate irrelevant information, hallucinations, incomplete responses, or outdated content. This often leads to frustration and confusion, especially when the setup seems technically correct.
The truth is that RAG failures usually do not happen because of one single mistake. They happen due to multiple small issues across data preparation, embedding quality, retrieval logic, prompt design, and system integration. Understanding these weak points is essential for building a reliable RAG system.
Key Takeaways
- RAG fails mostly due to poor data quality and weak document preprocessing.
- Incorrect chunking and low-quality embeddings reduce retrieval accuracy.
- A weak retrieval strategy leads to irrelevant context being sent to the model.
- Poor prompt design prevents the model from using retrieved data properly.
- Lack of evaluation and monitoring makes problems harder to detect.
- Simple optimizations can greatly improve RAG performance.
Understanding How RAG Works
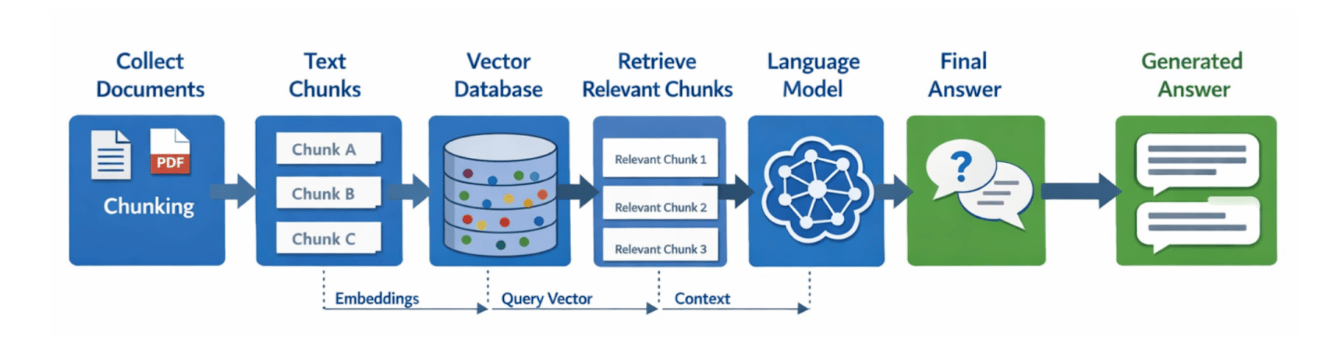
Before understanding why RAG fails, it is important to know how it works. A typical RAG pipeline first collects documents and converts them into smaller chunks. These chunks are then transformed into numerical vectors using embedding models. The vectors are stored in a vector database. When a user asks a question, the system converts the query into a vector and searches for similar vectors in the database. The most relevant chunks are retrieved and added to the prompt sent to the language model. The model then generates an answer based on both the question and the retrieved context.
If any step in this pipeline is weak, the final output will also be weak.
Understanding When RAG Works Better Than Fine-Tuning
LLMs are powerful systems, but they have limitations: they hallucinate. This means that they can confidently generate answers that are incorrect. This happens because these models do not truly understand everything. They are pattern-matching machines that generate responses based on what they learned during training. Now, suppose you have private data, documents, or internal knowledge, and those are not part of that training, the model has no direct access to them. As a result, it starts guessing instead of answering accurately. One way to fix this is fine-tuning.
Fine-tuning means retraining the model using your own data so that it learns your content directly. While this approach can improve accuracy, it is extremely difficult to manage in real-world systems. It requires expensive GPUs, long training time, and careful handling of model checkpoints. Every time your data changes, the model may need to be retrained. Over time, maintaining multiple versions of the model becomes complex and costly. Although fine-tuning removes the need to constantly provide context, it is painful to scale and maintain.
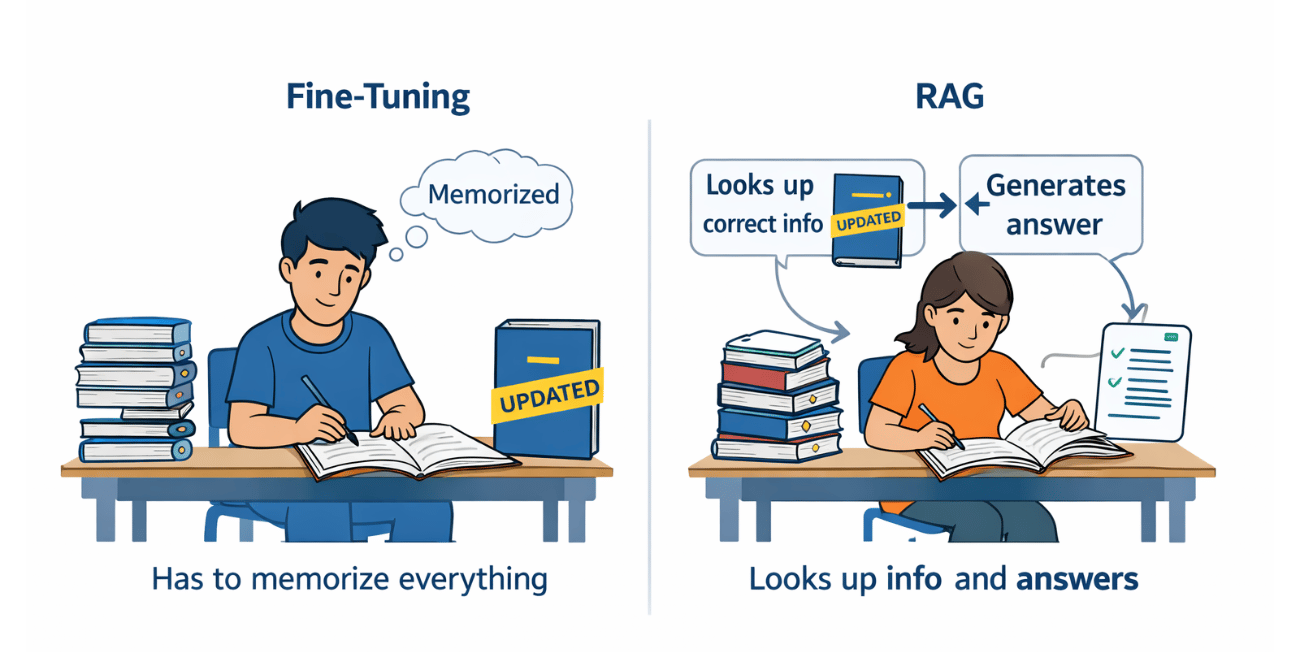
Another option could be Retrieval-Augmented Generation, or RAG, which takes a smarter and simpler approach. Instead of changing the model, RAG changes the way information is provided to the model. The model itself remains untouched. Rather than forcing the model to memorize everything, RAG allows it to look up the required information whenever it needs to answer a question. In this way, the model does not rely only on its internal knowledge. It relies on real, up-to-date data.
A simple way to understand RAG is through the example of an open-book exam. Imagine one student who tries to memorize the entire textbook. If the book is updated, the student must study again. This student represents fine-tuning. Now imagine another student who is allowed to carry the book into the exam. When a question appears, the student finds the relevant page, reads it, and writes the answer in their own words. This student represents RAG. The model first looks up the correct information and then generates a response based on it. It does not guess. It reads first and answers later.
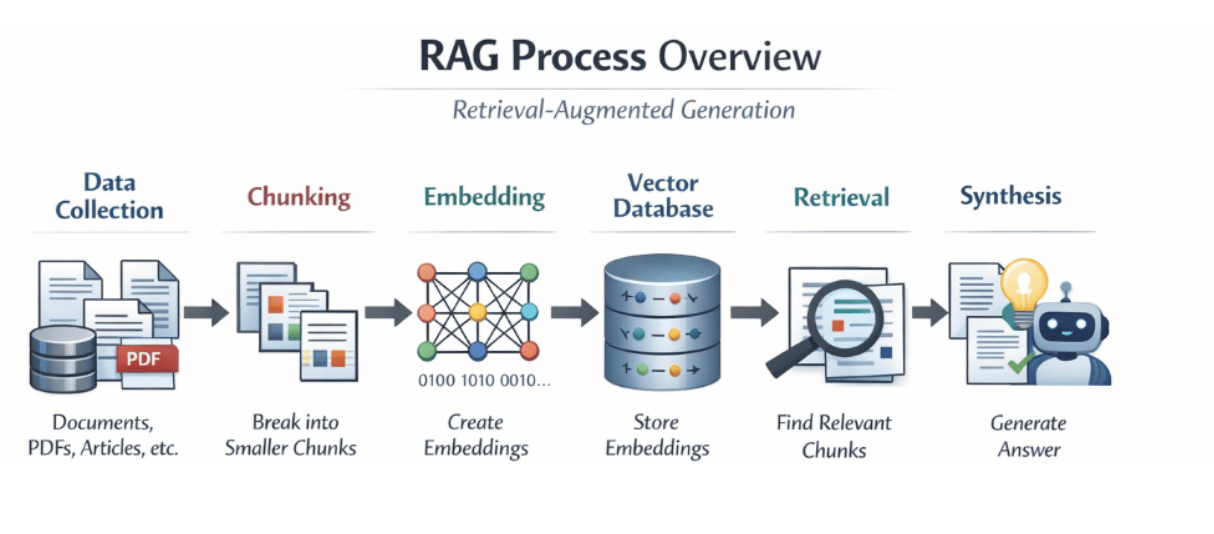
Understanding RAG Pipeline Step by Step
- The RAG process begins with collecting data. This includes documents, PDFs, manuals, articles, databases, and any other knowledge source that is important for your system. All of this information forms a private knowledge base.
- Since large documents are difficult for models to process at once, the next step is chunking. Chunking means breaking big documents into smaller sections. Each chunk contains one clear idea or topic, making it easier for the system to work with.
- After chunking, each section is converted into a numerical representation called an embedding. An embedding captures the meaning of the text in mathematical form. Texts with similar meaning produce similar embeddings. For example, “training models on GPUs” and “GPU-based model training” will have embeddings that are close to each other.
- These embeddings are then stored in a vector database. This database is specially designed to search by meaning instead of exact words, allowing it to quickly find relevant content. When a user asks a question, the system first converts that question into an embedding.
- It then searches the vector database to find the most relevant chunks based on similarity. This process is called retrieval. Instead of matching keywords, the system matches ideas and intent.
- The retrieved chunks are then added to the model’s input. This step is known as synthesis. The model now sees both the question and the supporting information. Using this context, it generates an answer grounded in real data rather than assumptions.
- Many RAG systems also include guardrails. Guardrails are rules that guide how the model responds. They can prevent the model from answering questions that are not supported by the retrieved content. For example, if the information is missing, the system can instruct the model to say “I don’t know” instead of guessing. This makes RAG-based systems more reliable and trustworthy.
RAG works well because it solves multiple problems at once. It does not require retraining the model, so new data can be added instantly. When documents are updated, only the database needs to be refreshed. There is no need to retrain or redeploy large models. This makes RAG much cheaper than fine-tuning because it avoids heavy GPU usage. It also allows teams to experiment and improve their systems quickly, leading to faster development cycles. Most importantly, by grounding answers in real documents, RAG significantly reduces hallucinations.
Another helpful analogy is the difference between memorizing roads and using GPS.
Fine-tuning is like memorizing every street in a city. When a new road is built, your knowledge becomes outdated. RAG is like using GPS. It checks the latest map every time and guides you accurately. This is why modern AI systems increasingly rely on RAG. It keeps models accurate, flexible, and up to date without the burden of constant retraining.
RAG vs Fine Tuning vs Prompt Engineering
To understand the difference between RAG, fine-tuning, and prompt engineering, imagine you are working with a very smart student who has a good general education but does not know everything.
Prompt Engineering: Giving Better Instructions
Prompt engineering is like learning how to ask the student better questions.
If you ask,
“Tell me about climate change.” You may get a generic answer.
But if you ask,
“Explain climate change in simple terms with recent examples.”
You will get a clearer and more useful response.
The student’s knowledge does not change. You are only improving how you communicate. In simple terms, prompt engineering means carefully designing the inputs so the model understands exactly what you want. It is fast, low-cost, and easy to try, but it cannot add new knowledge to the model.
Fine-Tuning: Sending the Student to Special Training
Fine-tuning is like enrolling the student in a specialized course. After training, the student becomes very good at one subject, such as medical terms, legal writing, or customer support. Now, whenever you ask related questions, the student performs better because the knowledge is built into them. However, if any new subject appears, the student must be retrained again. This takes time, money, and effort. In AI systems, fine-tuning means retraining the model on custom data to improve performance in a specific domain. It improves style and behavior, but updating knowledge is expensive.
RAG: Giving the Student Access to a Library
RAG is like giving the student access to a well-organized library during the exam. Instead of relying only on memory, the student can quickly look up the latest books and notes before answering. So even if the information changes, the student can still give accurate answers. In AI terms, RAG connects the model to external documents, databases, or knowledge bases. Before generating a response, the system retrieves relevant information and uses it as a reference. This makes RAG ideal for handling dynamic, large, and frequently updated data.
When to Use Fine-Tuning vs When to Use RAG
Choosing between fine-tuning and Retrieval-Augmented Generation (RAG) is one of the most important decisions when building an AI system. Both approaches improve model performance, but they solve different problems. Understanding when to use each helps you build systems that are accurate, scalable, and cost-effective.
When to Use Fine-Tuning
Fine-tuning is best used when you want to change how the model behaves, rather than what the model knows. It works by training the model on your own data so it learns your preferred writing style, tone, format, or domain-specific patterns.
Use Fine-Tuning When:
You should consider fine-tuning if:
- You need a consistent tone and branding
- You want structured outputs (JSON, reports, templates)
- You work in a specialized domain with stable knowledge
- You want predictable responses
- Your data does not change frequently
In fine-tuning, you take a model like Llama or Mistral and retrain the model using your own dataset. In this way, you are reproducing the neural network with updated weights based on your own dataset. This will produce the answer based on your custom data that is expected.
Example: Customer Support Chatbot
Problem
A company runs a customer support chatbot. The bot answers correctly, but the tone of the chatbot is inconsistent; some replies sound robotic, brand guidelines are not followed, and responses vary between agents.
Solution: Fine-Tuning
The company collects past high-quality support conversations and trains the model on them. After fine-tuning the replies to follow company style, the tone is polite and friendly, also the chatbot answers using the standard templates. Hence, the bot behaves like a trained support agent. Here, RAG is less useful because the main goal is consistent behavior, not dynamic knowledge.
When to Use RAG (Retrieval-Augmented Generation)
RAG is best used when your system depends on external, changing, or private information. Instead of storing knowledge inside the model, RAG fetches it from databases, files, or APIs in real time. In simple terms, RAG is about giving the model access to information.
Use RAG When:
You should use RAG if:
- Your data changes often
- You use internal documents
- You work with large datasets
- You need traceable sources
- You want up-to-date answers
- You cannot retrain frequently
RAG keeps knowledge outside the model and updates it independently.
Example: Internal Knowledge Assistant
A company wants an AI assistant for employees that answers questions about:
- HR policies
- Leave rules
- Project documentation
- Technical manuals
These documents are updated every month.
If they fine-tune the model, then every time there is a new update, there will be a need to retrain the model frequently. Thus leading to high cost and delay, also old policies remain in memory. Thus, in this case, the solution is RAG. All documents are stored in a vector database.
When an employee asks:
“What is the current work-from-home policy?”
The system:
- Searches HR documents
- Retrieves the latest policy
- Sends it to the LLM
- Generates the answer
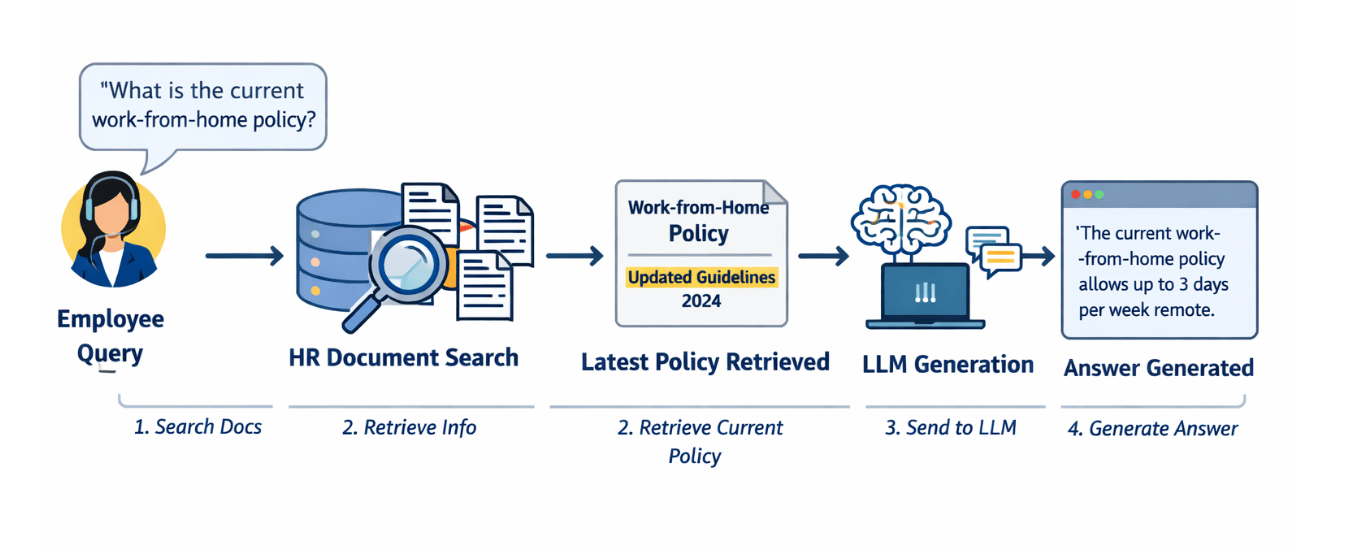
Result
Answers are always up to date without retraining.
A simple rule of thumb:
Use fine-tuning to control how the model responds. Use RAG to control what the model knows.
If your main problem is behavior, choose fine-tuning. If your main problem is knowledge, choose RAG. If you need both, combine them.
Common Reasons Your RAG System Underperforms
Many developers assume that adding documents to a vector database is enough to build a good RAG system. In practice, much more is required. A high-performing RAG pipeline depends on how well documents are prepared, how accurately they are retrieved, and how effectively relevant context is passed to the language model. Without proper chunking, ranking, evaluation, and monitoring, even the most powerful models can produce unreliable results. Understanding these hidden challenges is essential for building systems that work consistently in real-world scenarios.
Poor Data Quality and Incomplete Knowledge Base
One of the most common reasons RAG does not work well is poor input data. If the documents are outdated, incomplete, unstructured, or full of noise, the system will retrieve low-quality information. The language model cannot generate accurate answers if the source material itself is unreliable. Many developers also forget to update their knowledge base regularly. Over time, this leads to stale information being used in responses. In some cases, documents are copied directly from websites or PDFs without cleaning, resulting in broken formatting, repeated headers, and irrelevant metadata. These elements reduce retrieval accuracy.
When the data is weak, even the best model cannot compensate for it.
Ineffective Document Chunking Strategy
Chunking refers to breaking large documents into smaller pieces before embedding. If chunking is done incorrectly, retrieval performance drops significantly. When chunks are too large, they contain multiple topics, making it difficult for the system to match queries accurately. When chunks are too small, they lose context and become meaningless fragments. Both cases confuse the retrieval system. Another common mistake is splitting text without respecting sentence boundaries or logical sections. This produces unnatural chunks that reduce semantic clarity. Without proper chunking, relevant information may never be retrieved, even if it exists in the database.
Low-Quality or Mismatched Embeddings
Embeddings are responsible for converting text into numerical representations. If the embedding model does not match the domain of your data, similarity search becomes unreliable. For example, using a general-purpose embedding model for medical, legal, or technical documents often produces weak representations. This results in poor semantic matching between user queries and stored content. Additionally, mixing different embedding models within the same database creates inconsistencies. The system may fail to retrieve relevant documents because vectors are not comparable in a meaningful way. Embedding quality directly determines retrieval accuracy.
Weak Retrieval and Ranking Mechanism
Retrieval is not only about finding similar vectors. It is also about ranking them properly. Many RAG systems rely only on basic similarity scores, which is often not enough. Sometimes, the system retrieves documents that are only partially relevant. Other times, it misses important context because the top-k results are poorly ranked. Without re-ranking, filtering, or hybrid search techniques, retrieval becomes unreliable. Another issue is retrieving too many or too few documents. Too many documents overload the prompt and confuse the model. Too few documents reduce context and increase hallucinations. Balanced retrieval is essential for good RAG performance.
Poor Prompt Engineering and Context Formatting
Even if retrieval works well, the model may still fail if the prompt is poorly designed. The language model needs clear instructions on how to use the retrieved content. If the prompt does not clearly separate context from the question, the model may ignore important information. If the instructions are vague, the model may rely on its internal knowledge instead of the provided documents. Another problem is prompt overload. When too much text is added, important details get buried. The model struggles to identify what matters most. Effective prompt design is a critical part of RAG success.
Model Limitations and Context Window Issues
Every language model has a limited context window. If the combined prompt, retrieved documents, and instructions exceed this limit, some information is truncated. This results in incomplete or incorrect answers. Smaller models also struggle with reasoning over long contexts. Even when relevant documents are present, the model may fail to connect them logically. Using an underpowered model for complex RAG tasks often leads to disappointing results.
Lack of Evaluation and Continuous Improvement
Many teams build RAG systems and never evaluate them properly. Without benchmarks, feedback loops, and testing datasets, it becomes impossible to understand what is going wrong. Errors are often noticed only when users complain. By then, identifying the root cause becomes difficult. Without monitoring retrieval accuracy, hallucination rates, and response quality, optimization becomes guesswork. RAG systems require continuous tuning, not a one-time setup.
RAG Strategies to Improve RAG Performance
Building a high-quality Retrieval-Augmented Generation (RAG) system is not just about connecting a database to an LLM. To deliver accurate, reliable, and context-aware answers, modern RAG pipelines use multiple advanced strategies. These techniques improve how documents are retrieved, ranked, processed, and evaluated before they reach the language model.
Re-ranking for Better Precision
In most RAG systems, the first retrieval step focuses on speed rather than accuracy. This means the top results may not always be the most relevant. Re-ranking solves this problem by using a more powerful model to re-evaluate the retrieved chunks and reorder them based on relevance. This ensures that the best information appears first in the context, improving answer quality and reducing hallucinations. Although re-ranking requires more computation, it is essential for applications where precision is critical.
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank(query, chunks, top_k=5):
pairs = [(query, chunk) for chunk in chunks]
scores = reranker.predict(pairs)
ranked = sorted(
zip(chunks, scores),
key=lambda x: x[1],
reverse=True
)
return [chunk for chunk, _ in ranked[:top_k]]
Agentic RAG for Intelligent Retrieval
Agentic RAG allows the system to behave like an intelligent assistant that decides how to retrieve information. Instead of using a fixed search method, an agent analyzes the query and selects the best tools, such as vector search, keyword search, web search, or database lookup.
This approach is useful when user queries are complex or unpredictable. The system can adapt its strategy dynamically, but it also requires more sophisticated logic.
Knowledge Graphs for Relationship-Based Reasoning
Some domains, such as finance, medicine, or research, depend heavily on relationships between entities. Knowledge graphs store information as connected nodes and edges, allowing the RAG system to understand how concepts are related.
Instead of retrieving isolated chunks, the system retrieves connected facts, which leads to deeper reasoning. However, building and maintaining a knowledge graph requires significant infrastructure.
# Pseudocode
entities = extract_entities(query)
nodes = graph.find_nodes(entities)
neighbors = graph.expand(nodes)
context = collect_text(neighbors)
answer = llm.generate(query, context)
Query Expansion for Ambiguous Questions
Users often ask short or unclear questions. Query expansion improves retrieval by generating multiple versions of the original query. These variations help the system search from different perspectives. This method improves recall but requires additional LLM calls.
def expand_query(query, llm):
prompt = f"Generate 3 search queries for: {query}"
variants = llm.generate(prompt).split("\n")
return variants
def expanded_search(query):
queries = expand_query(query, llm)
docs = []
for q in queries:
docs.extend(vector_search(q))
return docs
Contextual Retrieval for High-Value Documents
Contextual retrieval improves accuracy by enriching each chunk with additional metadata, summaries, or surrounding context during ingestion. This makes each chunk more meaningful when retrieved. Although this method increases processing cost during indexing, it significantly improves retrieval quality, especially for important documents.
def contextual_chunk(doc):
summary = summarize(doc)
chunks = split(doc)
enriched = [
f"Summary: {summary}\nContent: {c}"
for c in chunks
]
return enriched
Context-Aware Chunking
Instead of splitting documents based on fixed length, context-aware chunking respects paragraph boundaries, headings, and semantic structure. This keeps ideas intact and improves comprehension. Slightly slower ingestion is the trade-off for higher-quality chunks.
import nltk
def semantic_chunk(text):
paragraphs = text.split("\n\n")
chunks = []
for p in paragraphs:
if len(p) > 500:
chunks.extend(nltk.sent_tokenize(p))
else:
chunks.append(p)
return chunks
Self-Improving RAG
Self-Improving or Self-reflective RAG allows the model to evaluate its own answers. After generating a response, it checks for errors, missing information, or weak evidence and regenerates if needed.
This is especially useful for research and analytical tasks, though it increases latency.
def self_reflective_rag(query, context):
answer = llm.generate(query, context)
review = llm.generate(
f"Check this answer for errors:\n{answer}"
)
if "incorrect" in review.lower():
answer = llm.generate(query, context)
return answer
FAQs
Is RAG better than fine-tuning?
RAG and fine-tuning serve different purposes. RAG is better for dynamic, changing information, while fine-tuning is better for learning specific styles or behaviors. Many systems use both together.
Why does my RAG system still hallucinate?
Hallucinations usually happen when the retrieved context is weak, irrelevant, or missing. Poor prompts and insufficient retrieval are common causes.
How many documents should I retrieve per query?
There is no fixed number, but usually between 3 and 8 high-quality chunks work well. The focus should be on relevance, not volume.
Do I need a vector database for RAG?
Most production RAG systems use vector databases for scalability and speed. However, small systems can use in-memory search during prototyping.
Can RAG work offline?
Yes, if your documents are stored locally and the model runs on-premise. However, updates and scaling become harder.
What are the common reasons RAG systems fail?
1. Outdated Knowledge When documents are updated, the system may still rely on old information. Solution: Track document changes and refresh the index automatically.
2. Declining Search Accuracy As more data is added, relevant results become harder to find. Solution: Use a mix of keyword-based and semantic search to improve retrieval.
3. Low-Quality Context Input Poorly structured chunks can overload the model with unnecessary content, reducing accuracy. Solution: Create meaningful chunks, filter weak matches, and summarize before generation.
4. Missing Performance Monitoring Without proper measurement, errors go unnoticed in real-world use. Solution: Continuously evaluate responses using quality and reliability metrics.
How often should I update my knowledge base?
It depends on your use case. For fast-changing domains, weekly or daily updates may be needed. For static content, monthly updates may be enough.
Conclusion
RAG is a powerful technique, but it is not a magic solution. When it fails, the problem usually lies in data quality, chunking strategy, embedding choice, retrieval logic, prompt design, or system monitoring. Most RAG systems underperform not because of bad models, but because of weak pipelines.
By treating RAG as an end-to-end system rather than a simple plug-and-play feature, developers can significantly improve reliability and accuracy. Regular evaluation, thoughtful design, and continuous optimization are essential for success.
When built carefully, RAG can transform AI applications into trustworthy, knowledge-aware systems. But when built carelessly, it becomes another source of frustration. Understanding why RAG is not working is the first step toward making it work properly.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
