By Andrew Dugan
Senior AI Technical Content Creator II

Introduction
When calling a large language model with questions about recent or scheduled events, answers can often be incorrect because the models only have access to data they were trained on in the past. For example, if you ask any LLM trained before the last presidential election who the president is, without giving it access to the web, it will either respond with the previous president or it will make up an answer for you. An example of a query to Llama 3.3 70B is below, where the training knowledge cutoff was December 2023.
response = call_llm("Who is the current president?")
print(f"Response: {response}")
OutputResponse: As of my knowledge cutoff in 2023, Joe Biden is the President of the United States. However, please note that my information may not be up-to-date, and I recommend checking with a reliable news source for the most current information.
Most LLM APIs solve this problem by “grounding” your request in a web search. Web grounding is a process similar to retrieval augmented generation where the workflow determines whether or not the user’s input requires current information from the web, performs a web search, adds the search results as context to the final prompt, and returns the response to the user.
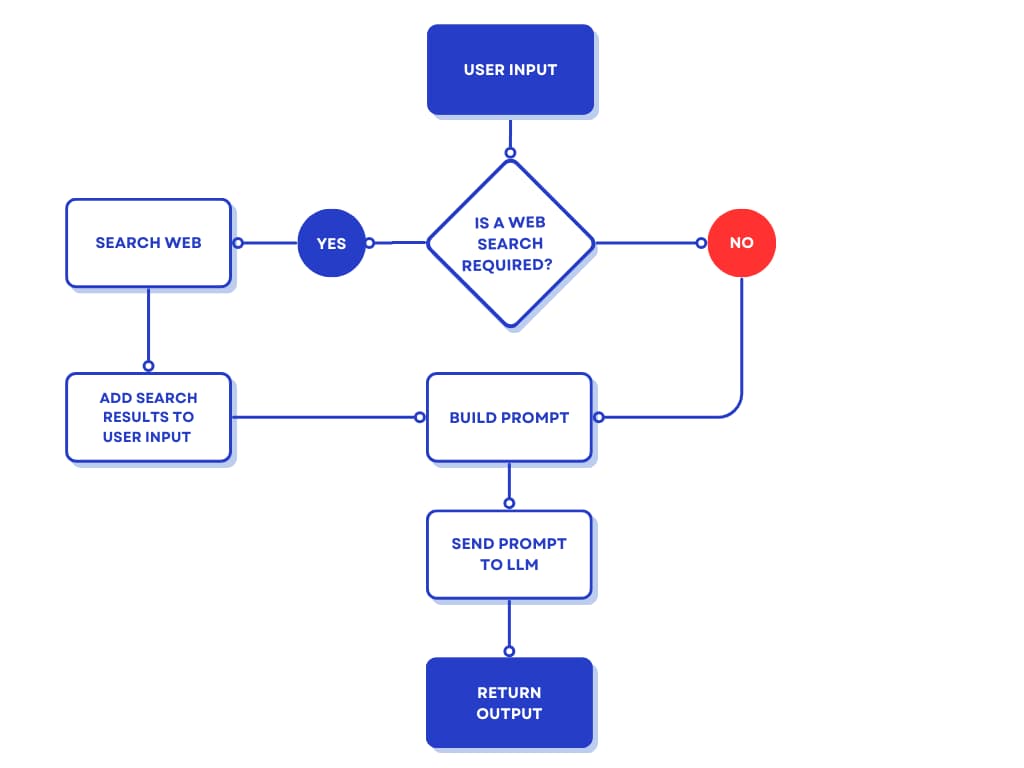
If you choose to use an open source model instead of an LLM API with built-in web grounding, you may need to implement this flow yourself. In this tutorial, you will implement a workflow using Python that employs web grounding to increase the accuracy of your model’s responses.
Key Takeaways
-
LLMs only have information up to the date they were trained. Web grounding uses real-time web searches to provide the LLM prompts access to current information.
-
Web grounding is a type of retrieval augmented generation, where the workflow finds and provides additional context to the user’s prompt when calling the LLM. It determines what additional information is required in order to respond to a prompt, searches the web for it, and includes the web search details in the prompt context.
-
Many closed-source models from OpenAI and Google have web grounding built-in, but for other models, users need to implement their own web grounding workflow with some Python logic and access to a web search API.
Step 1 — Getting Your API Keys
You will need a tool that can search the web and return responses. Many search services, including Google and Bing, have recently retired their search APIs in favor of their own proprietary web grounding services that require users to either use their models or use their agent ecosystems. In this tutorial, you will use Duck Duck Go searches through a limited free plan with Serp API. Any search API can work, as long as you have access to the title, snippet, and date of web search results.
To create a free account with Serp Api and get an API key, go to their website and create an account with their free plan.
You will also need access to an LLM. This tutorial uses Llama 3.3 70B through Serverless Inference on the DigitalOcean AI Platform. You will need to get a model access key to use Serverless Inference on the DigitalOcean AI Platform.
Step 2 — Setting Up Your Environment
If you do not already have Python, you will need to download and install it from their website.
Create a Python script called web_grounding_tutorial.py. In the script, import the requests library. Add your Serp API key. Replace the highlighted your_api_key placeholder value with the the API key from your free Serp API account. To find your API key with Serp API, login to their website, go to the API key section on your dashboard.
Then add the DigitalOcean inference URL with the headers for inference requests. Replace the highlighted your_model_access_key placeholder value with the access key you get from the DigitalOcean AI Platform console.
import requests
SERP_API_KEY = "your_api_key"
llm_url = "https://inference.do-ai.run/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer your_model_access_key"
}
The headers for the request to the LLM URL have been specified to define the JSON content type and the model access key for authorization. Now you need to define a function for calling your LLM. This function will make an HTTP request to the DigitalOcean Serverless Inference endpoint.
def call_llm(prompt):
data = {
"model": "llama3.3-70b-instruct",
"messages": [
{
"role": "user",
"content": prompt
}
],
"max_tokens": 500
}
response = requests.post(llm_url, headers=headers, json=data)
message = response.json()['choices'][0]['message']['content']
return message
The call_llm function takes a prompt, makes a call to the model using an HTTP request, and returns the response text.
Step 3 — Identifying if a Prompt Needs Grounding
Not all requests need to be grounded in a web search. For example, if you are asking for a soup recipe, you may want the LLM to provide one without a web search. Your web search API may have rate limits or costs that you want to reduce. The web searches may also add additional latency, so it’s best if your LLM is only making queries when necessary.
To check if a web search is necessary, you need a function that calls an LLM to ask if the user’s input should be augmented with results from a web search.
def needs_web_grounding(query):
prompt = f"Does the following prompt need information more recent than December 2023 to answer correctly?. Answer only YES or NO.\nQuestion: {query}\nAnswer:"
judgement = call_llm(prompt)
return judgement.strip().upper().startswith("YES")
The needs_web_grounding function asks the model if the user’s prompt needs information more recent than the December 2023 knowledge cutoff date of the Llama 3.3 70B model we are using. If the response from the LLM is ‘YES’, the function will return a True boolean object. Otherwise, it will return a False object. We will use the response from this function to determine whether or not to conduct a web search.
If you call the needs_web_grounding function on the query “Who is the current president?”, it will return “YES” (True), and if you call it on “Why is the sky blue?”, it will return “NO” (False).
The prompt in the needs_web_grounding function will not be able to accurately identify whether or not a prompt will need a web search every time. For example, if a country changes its capital city, the model may think countries don’t change their capital city very often and could return a ‘NO’. There are many similar examples that make accurately identifying the need for a web search a complex problem with many layers of depth. The simple prompt used above will work well enough for the purpose of this tutorial. In a production environment, you should tune this prompt to match the level of error that is acceptable for your application.
Step 4 — Implementing the Web Search
Now, you need to create the web searching function that will take a search query and return the top three results from the search query.
def search_web(search_query):
params = {
'engine': 'duckduckgo_light',
'q': search_query,
'api_key': SERP_API_KEY,
}
response = requests.get('https://serpapi.com/search', params=params)
data = response.json()
return data["organic_results"][:3]
The search_web function takes the user’s input and uses the SERP_API_KEY that was defined in step 2 to make a Duck Duck Go web search with the user’s input through the Serp API. It then returns the details from the top three search results. You will take the returned results and add them to the user’s prompt before having the LLM process a response.
Step 5 — Writing the Workflow Logic
Now, you need to write a function that will call all of the other functions that you have written. It will need to take the user’s input, call the needs_web_grounding function to determine if a web search is necessary, then either search the web and add the context to the prompt or call the LLM without the additional context.
def answer_with_web_grounding(user_input):
if needs_web_grounding(user_input):
print("Web search needed; fetching info...")
search_results = search_web(user_input)
prompt = f"Please respond to the user's query: {user_input}\n\nYou may use the following web search results as context in your answer: {search_results}"
else:
print("Web search NOT needed; answering from LLM knowledge.")
prompt = user_input
answer = call_llm(prompt)
return answer
If the needs_web_grounding function returns a True boolean response, it will write a prompt that asks the LLM to use the web search results as context in its answer. Otherwise, it will only use the user’s input as the prompt.
Now, when you run the following code:
answer_with_web_grounding("Who is the current president?")
You will get a response similar to the one below.
OutputThe current president of the United States is Donald J. Trump. He was sworn in as the 47th president on January 20, 2025, and his current term is set to end on January 20, 2029.
Not only are these results current, the sworn in date and term ending date show a level of detail that may not have been correctly returned if you had only used the model alone.
Improving your Web Grounding Workflow
To improve this LLM workflow for your application, the next step would be to update the method of determining whether or not the prompt needs a web search based on your application’s needs. If your application is only meant to find upcoming concert information, you may need a web search every time. Otherwise, if it’s only to catch a percentage of outdated responses, continue with the flow that you wrote in this tutorial. The prompt in the needs_web_grounding function can be tuned for this purpose.
Next, cleaning the output of the search results can reduce the number of tokens used and increase the accuracy of the response. The search_web function currently returns a JSON object that looks like this:
[
{
"position": 1,
"title": "President Donald J. Trump - The White House",
"link": "https://www.whitehouse.gov/administration/donald-j-trump/",
"displayed_link": "www.whitehouse.gov/administration/donald-j-trump/",
"snippet": "President Trump built on his success in private life when he entered into politics and public service. He remarkably won the Presidency in his first ever run for any political office.",
"favicon": "https://external-content.duckduckgo.com/ip3/www.whitehouse.gov.ico"
},
{
"position": 2,
"title": "Donald Trump Sworn In as 47th President in Capitol Ceremony ... - Yahoo",
...
}
]
Many of these fields, including “position”, “link”, “displayed_link”, etc. may not be necessary. Check the format of the results your search API is returning, and write a function that removes unnecessary fields in order to reduce the amount of information you are including in your context. It may also be advantageous to encode the JSON into a TOON format in order to reduce the number of tokens used.
You may find that the answers to many questions are not included in the snippets from the search results. For example, if you ask for the time of the next Seahawks game, it might know the day but not the time without access to the content from the link’s actual page.
answer_with_web_grounding("What time is the next Seahawks game?")
OutputThe next Seahawks game is today, Sunday, December 28, 2025, against the Panthers. However, the exact time of the game is not specified in the provided search results. I recommend checking the official Seattle Seahawks website...
One way to fix this is to add an additional step where the workflow uses a Python library such as Beautiful Soup to get the content from the web page and include its context in the query. After adding that additional functionality, context from the official Seahawks schedule page is included, and the model is able to tell that the game today is already over and the exact day and time for the next one is still not scheduled.
OutputThe next Seahawks game is scheduled for Week 18, but the date, time, and location are still "TBD" (to be determined) as it is against the 49ers at Levi's Stadium.
For security best practices, remove the hardcoded API keys and URLs from your code. One option is to save them as environmental variables and import them into the scripts.
Lastly, all LLM workflows should have sufficient error handling built into their code in order to account for the non-deterministic and unpredictable nature that is inherent in AI applications.
FAQ
Can I have web grounding activate in conversations rather than just a single prompt?
Yes, if you would like to have a conversational format where the user can ask followup questions, you can include the context in the conversation itself. If this adds too many tokens into the conversation context, consider removing past conversation entries to shorten the number of tokens if your application allows for it.
Adding web grounding is increasing the latency because the web search takes time. Are there ways to speed it up?
Yes, you can run your LLM calls asynchronously by sending the user’s prompt to the LLM without search results in the context at the same time that you send the call asking the LLM if the user’s prompt should be grounded in a web search. After the results are returned, if the web search is necessary, you can conduct the web search, and call the LLM again with the context from the web search. This will allow you to reduce the latency for LLM calls that do not need a web search. It will cost additional tokens though because you will be discarding the first LLM response if a web search is needed.
The web searching is costing me too many tokens. Is there a way to reduce the number of tokens spent for all of these calls?
Yes, one way is to use a smaller model in your needs_web_grounding function. You might find that you don’t need a 70B parameter model to determine whether or not an answer needs a web search. If you use a smaller model, you might find it to be cheaper and faster.
Conclusion
Web grounding is a powerful tool that can improve the accuracy of your AI applications and can be integrated directly into any other retrieval augmented generation workflow you have set up. It allows you to get accurate and current results from older models or smaller ones that may have been trained on less current information.
In this tutorial, you used a Serp API endpoint to make web searches through Duck Duck Go and augmented your prompt with the context from the search results. The next steps are to customize the implementation for your application.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Andrew is an NLP Scientist with 8 years of experience designing and deploying enterprise AI applications and language processing systems.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
