By Adrien Payong and Shaoni Mukherjee

Introduction
Object detection is a key component in computer vision. Advanced object detection models such as YOLO (You Only Look Once), Faster R-CNN, RetinaNet, and their successors have achieved significant advances, driving applications across diverse fields including autonomous vehicles, robotics, surveillance systems, e-commerce platforms, and medical healthcare applications.
However, these systems cannot interpret natural language queries, answer scene-based questions, or explain their decision-making processes. The emergence of vision language models (VLMs) represents a significant advancement in the field. The combination of visual and linguistic representation learning allows VLMs to surpass the limitations of single-modality systems, granting machines human-like abilities to perceive and describe their environments.
This article explores their architectural frameworks, performance capabilities, practical applications, and their evolving place in the research landscape. We will provide code examples, comparative tables, and insights from academic research and commercial applications to understand this revolutionary field.
Prerequisites
- Foundational knowledge of machine learning techniques, including neural networks.
- Familiarity with essential computer vision tasks like image classification and object detection is expected.
- Knowledge of widely-used object detection models such as YOLO and Faster R-CNN, and datasets like COCO and PASCAL VOC.
- Basics of natural language processing techniques such as text embeddings and transformer models.
- Python coding knowledge and familiarity with either PyTorch or TensorFlow.
From Pixels to Concepts: The Evolution of Object Detection
Advancements in object detection moved from visual-only systems to advanced models that integrate both vision and language capabilities. This evolution has allowed AI systems to identify objects and understand context and meaning, setting the groundwork for multimodal intelligence.
The Traditional Paradigm
Traditional object detection systems use only visual features, transforming images to spatial feature maps before predicting bounding boxes and class labels for each identified object. Two major classes of detectors have shaped the field of object detection:
- One-Stage Detectors (e.g., YOLO, SSD): One-Stage Detector models resolve object detection as a regression task by mapping image pixels to bounding boxes and class probabilities in one single pass.
- Two-Stage Detectors (e.g., Faster R-CNN): Two-stage detection systems start by generating region proposals for potential object locations, then perform classification and refinement in the second stage, yielding superior accuracy at the cost of speed.
Both detection methods depend on extensively annotated datasets such as COCO and PASCAL VOC and operate within a fixed vocabulary of categories. Adding new object types to detection models or adapting them to handle open-world scenarios requires extensive re-labeling and re-training efforts. These models fail to grasp language or context because they can only interpret what they “see”, not what they “understand.”
The Multimodal Revolution
Vision-language models (VLMs) differ from traditional models because they simultaneously process image and text data. They work to align visual and linguistic concepts within a shared semantic space. Significant breakthroughs have propelled the development of VLMs:
- The emergence of large-scale vision-language datasets such as Conceptual Captions, LAION-400M, and COCO Captions includes millions of image–text pairs scraped from the web.
- The maturation of transformer architectures—first for language models like BERT, GPT, and T5, then expanding to vision models such as ViT and Swin Transformer, and eventually for cross-modal fusion.
- Self-supervised and contrastive learning objectives enable models to align images and text without explicit annotation.
Architectural Foundations of Vision Language Models
Vision Language Models are designed to integrate visual and textual understanding within a single, unified system. By using dedicated modules for image analysis, language comprehension, and cross-modal fusion, these models enable AI systems to interpret and reason across visual and textual data.
Multimodal Design: The Three Core Components
The multimodal architecture of vision language models consists of three primary components that perform distinct, specialized functions:
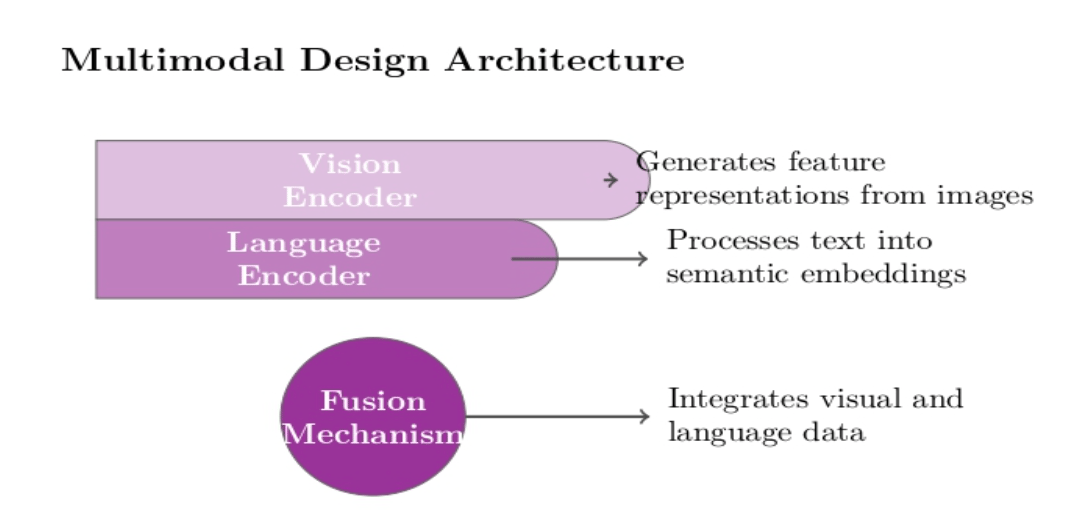
Vision Encoder
Typically, vision encoders are built on convolutional neural networks or, more recently, transformer-based models like vision transformers. These models process images to generate compact, high-dimensional feature representations that capture spatial details, semantic meaning, and contextual information from visual data.
Language Encoder
The language encoder takes in the text input, whether a simple label or a complex natural language query, and transforms it into a set of embeddings that capture the semantic meanings.
Fusion Mechanism
The fundamental component of VLMs is the fusion mechanism, enabling the alignment and integration of visual and language representations into a shared semantic space. Early VLMs used simple projection or concatenation layers to merge modalities, but recent innovations have brought about far more sophisticated approaches, such as:
-
Attention-Based Cross-Modal Alignment: Through cross-attention layers, models can focus selectively on relevant parts of an image that relate to language queries and vice versa, which enables detailed relational reasoning.
-
Token-Level Injection: Vision-Language Multimodal Transformer (VLMT) models integrate visual tokens into language sequences to fuse modalities at the earliest possible stage, which enables richer context sharing. This design removes the requirement for intermediate projection layers while optimizing information flow between different modalities.
Vision-Language Model Workflow
The VLM pipeline follows this typical sequence of steps:
- Image Input: The vision encoder processes an image to produce a grid of feature vectors(one for each patch or region).
- Text Input: The language encoder processes a textual prompt, yielding a semantic embedding.
- Fusion: The vision and language modalities are fused through embedding concatenation, cross-attention layers, or integrating tokens at the transformer input.
- Output: The model generates predictions for object locations as bounding boxes and/or object classes.
Notable Architectural Variations
The architectural landscape of current vision-language models is ruled by transformers, allowing models to capture complex, long-range dependencies across modalities. Pioneering examples include:
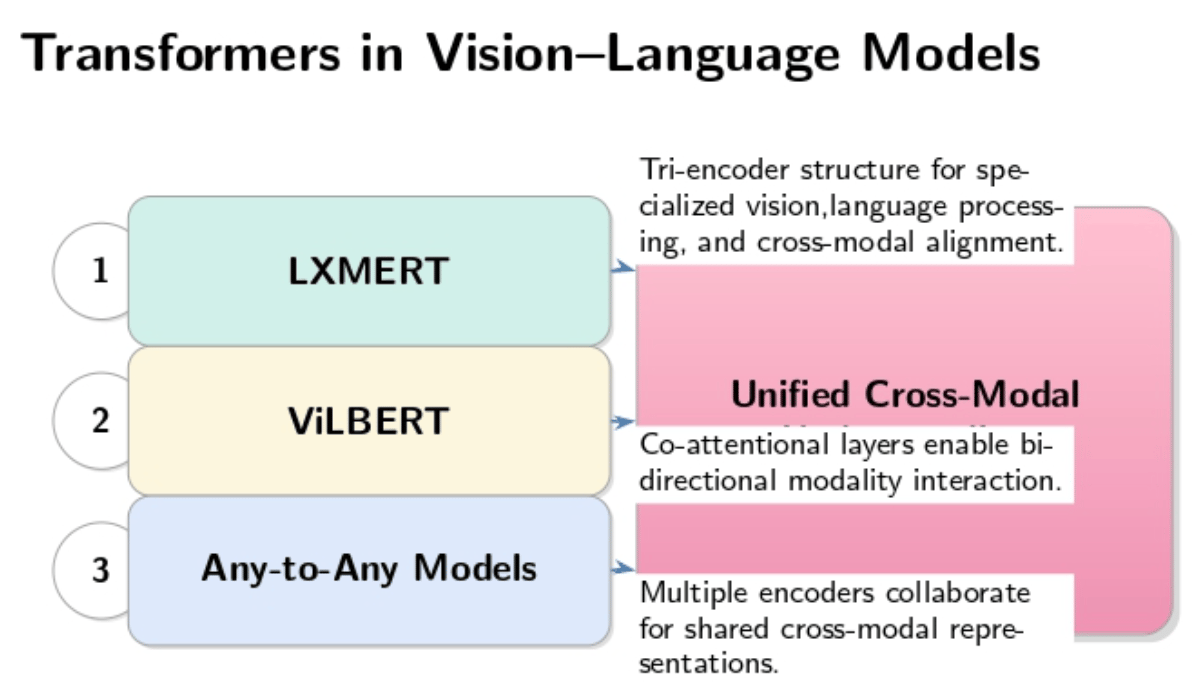
- **LXMERT (**Learning Cross-Modality Encoder Representations from Transformers): LXMERT uses a tri-encoder structure that includes three distinct encoders dedicated to vision processing, language understanding, and cross-modal alignment. This allows for rich interaction and specialized input processing.
- ViLBERT (Vision-and-Language BERT): Similar to LXMERT but uses co‐attentional layers to allow bi‐directional information flow between modalities.
- Any-to-Any Models: Any-to-any models represent a major step forward in architecture, allowing multiple encoders to collaborate across various modalities. These encoders create shared representations where inputs from one modality can be easily translated into another.
These models also feature multiple decoders that can generate outputs across various modalities, making them highly adaptable for a range of applications, such as object detection with natural language explanations.
Small Vision Language Models (sVLMs)
Researchers have developed lightweight visual language models that maintain multimodal capabilities with minimal computational overhead to support real-time and edge deployment. Techniques include:
- Knowledge Distillation: Training smaller “student” models to mimic the outputs of larger “teacher” models through Knowledge Distillation.
- Hybrid Designs: Researchers use lightweight transformers in combination with CNN backbones and alternative architectures such as Mamba.
- Sparse Attention, Early Fusion: Simplifying attention operations and performing early modality fusion helps to avoid unnecessary computational processes.
sVLMs enable advanced detection capabilities on devices with limited resources like drones, smartphones, and robotics.
Overview of Some Leading Vision Language Models
The table below compares some leading academic and commercial Visual Language Models by summarizing their architectural features, main tasks, and additional learning materials.
| Model | Year / Institution | Architecture Highlights | Main Tasks | Links |
|---|---|---|---|---|
| CLIP | 2021 / OpenAI | Dual encoder (ViT/CNN + Transformer); contrastive image-text pretraining | Zero-shot classification, retrieval, and detection | Code HuggingFace |
| BLIP | 2022 / Salesforce | Unified encoder-decoder, cross-attention for vision and language | Captioning, VQA, retrieval | Paper Code HuggingFace |
| BLIP-2 | 2023 / Salesforce | Frozen ViT + LLMs bridged by Q-Former adapter | Multimodal generation, VQA | Paper Code |
| Flamingo | 2022 / DeepMind | Frozen vision backbone, LLM, gated cross-attention adapters | Few-shot VQA, captioning, multimodal gen | Paper |
| OWL-ViT | 2022 / Google | ViT, image-text contrastive pretraining, open-vocabulary detection | Zero-shot detection, phrase localization | HuggingFace Code |
| GLIP | 2022 / Microsoft | Unified detection and phrase grounding with language-image pretraining | Open-vocabulary detection, phrase grounding | Paper Code |
| F-VLM | 2023 / Google | Frozen CLIP backbone, open-vocab detection via text-region similarity | Zero-shot object detection | Paper |
| GPT-4V | 2023 / OpenAI | Proprietary, LLM + vision encoder, multimodal transformer stack | Multimodal generation, VQA, analysis | Overview |
| Gemini | 2023 / Google | Native multimodal pretraining (text, image, audio, video); early fusion | Multimodal reasoning, analysis, and captioning | Blog Overview |
| LLaVA | 2023 / Multiple | LLM fine-tuned with visual instruction data | Multimodal chat, vision QA | Paper Code |
| MiniGPT-4 | 2023 / HKUST/CMU | Vicuna LLM + BLIP-2 vision encoder via Q-Former | Vision-language chat, multimodal generation | Paper Code |
The table highlights the diversity and progress occurring within the VLM ecosystem. This progression brings forth new models that stretch the limits of vision-language understanding. Researchers and practitioners who stay up-to-date with the latest VLMs can unlock new possibilities for innovative applications and multimodal AI advancements.
How VLMs Redefine Object Detection
The multimodal approach enables open-vocabulary, context-aware, and hierarchical detection capabilities that greatly extend the reach of traditional systems, providing more flexibility and depth in visual analysis.
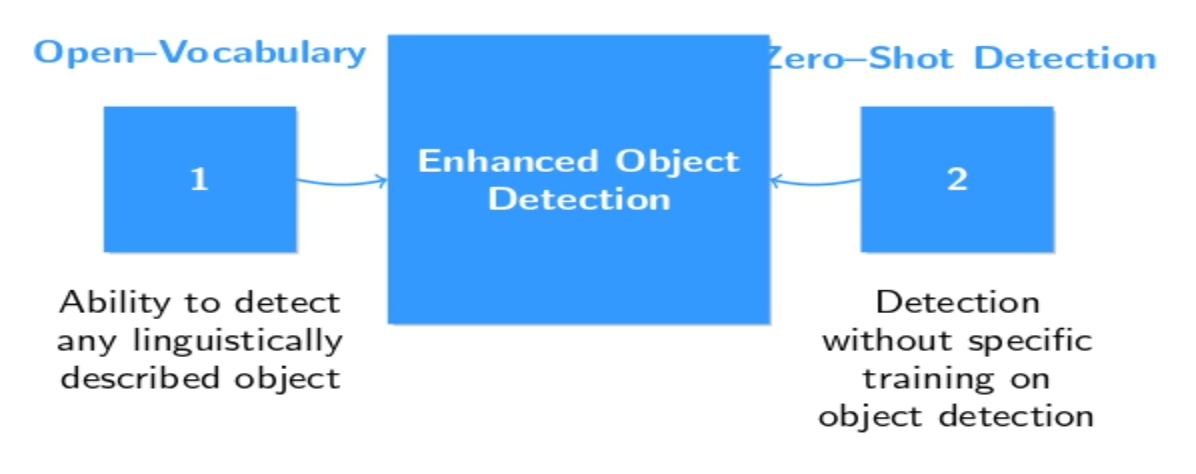
Open-Vocabulary and Zero-Shot Detection
VLMs provide the most significant improvement over traditional detectors through open-vocabulary support and zero-shot object detection capabilities.
-
Open-Vocabulary: The VLM detects and localizes any user-specified object categories at inference time, such as “yellow sports car,” “medical syringe,” or “person waving.” Traditional detection systems require all possible object classes to be labeled during the training period, whereas VLMs can detect and classify any object as long as it can be linguistically described.
-
Zero-Shot Detection: The extensive pre-training of VLMs using image–text pairs leads to a strong alignment between words and visual concepts. For example, CLIP(Contrastive Language-Image Pre-training) can enable users to input any text prompt(such as “a child playing with a dog”) to retrieve relevant areas in images by comparing embeddings, without supervised training on object detection.
Let’s consider a surveillance camera to detect “a person holding an umbrella.” Traditional detectors will need explicit training data for “person with an umbrella” to perform the task, while VLMs can process the query immediately if they have learned to ground similar concepts during pre-training.
Referring Expression and Hierarchical Detection
VLMs achieve successful results in complex contextual detection tasks that traditional object detectors fail to address:
- Referring Expression Detection: To identify objects from natural language descriptions such as “the blue bag next to the red chair,” systems must interpret the object classes and understand the surrounding relationships and context.
- Hierarchical Object Detection: VLMs demonstrate the ability to detect objects at various specificity levels through the hierarchical language structure they use. Once identified as a “vehicle,” the system can refine this detection to specify a “sports car” and then identify the exact make and model.
Explanatory and Temporal Detection
-
Explanatory Detection: The need for interpretability grows in importance within environments that require safety. VLMs can accompany their detections with natural language explanations: “Detected a person because the region contains facial features and matches the prompt ‘person walking.’”
-
Temporal Reasoning: Advanced VLMs that process video can track objects over time, understand actions, and provide scene-level descriptions (e.g., “a person picks up a bag and exits the frame”), enabling activity recognition and behavior analysis.
Comparison: Traditional Detectors vs. Vision Language Models
The development of object detection technology requires a thorough understanding of how traditional detectors like YOLO and Faster R-CNN differ from modern Vision Language Models. The following table provides a detailed comparison of these approaches across essential aspects like input types, generalization capabilities, interpretability, and more.
| Aspect | Traditional Detectors (YOLO, Faster R-CNN) | Vision Language Models |
|---|---|---|
| Input | Visual only | Visual + Natural Language |
| Vocabulary | Fixed, predefined classes | Open, user-defined (via text) |
| Training Data | Extensive labeled images | Image–text pairs may require less labeling |
| Generalization | Limited to trained categories | Zero-shot, few-shot, open-vocabulary |
| Contextual Reasoning | No | Yes, with spatial and relational context |
| Interpretability | Minimal | Can generate textual explanations |
| Efficiency | High (real-time possible) | Improving (sVLMs enable edge deployment) |
Let’s consider some performance trade-offs:
- Speed and Latency: YOLO and its variants deliver unparalleled performance in real-time applications by processing hundreds of frames per second. On the other hand, Visual Language Models are progressing, particularly due to the emergence of smaller, optimized architectures. However, they tend to be more computationally intensive.
- Flexibility and Adaptability: Visual language models surpass classic detectors in terms of flexibility. This is because they can process arbitrary queries and categories instantly.
- Scalability: Traditional models need retraining to deal with new categories or tasks, whereas VLMs require only a new text prompt.
Real-World Use Cases
The following table summarizes the real-world use cases for Vision Language Models:
| Domain | Challenge / Scenario | VLM Solution | Outcome / Impact |
|---|---|---|---|
| E-Commerce Visual Search | Retail catalogs contain thousands of niche products; manual labeling is costly. | GLIP-based pipelines tag user-uploaded images with long-tail categories (e.g., “vintage brass candlestick”) without new annotations. | Reduction in annotation cost; Faster product discovery. |
| Warehouse Robotics & Picking | Autonomous robots must pick items from unstructured bins. | Grounding DINO integrates with an industrial robot’s vision stack; human operators issue commands like “pick the blue spray bottle.” | Zero-shot grasp planning reduces downtime and retraining cycles. |
| Assistive AR for Accessibility | Visually impaired users need scene narration. | Microsoft Seeing AI uses Azure AI Vision’s promptable detection to narrate scenes for visually impaired users (e.g., “there is a stop sign ahead”). | Real-time audio descriptions improve situational awareness. |
| Digital Pathology | Pathologists search for rare cellular structures (e.g., mitotic figures) in whole-slide images. | PaLI-X fine-tuned on pathology data flags candidate regions via the prompt “find mitotic cells,” streamlining review workflows. | Enhanced diagnostic accuracy and efficiency in pathology workflows. |
| Quality Control in Manufacturing | Defect detection on PCB(printed circuit boards) requires identifying missing components or misalignments. | Gemini’s Vision API runs on-premise in Google Cloud Vertex AI, detecting anomalies like “missing 01005 resistor R17” based on dynamic prompt rules. | Automated, accurate defect detection improves manufacturing quality control. |
Vision Language Models improve efficiency and accuracy while delivering better user experiences across multiple sectors through visual and textual data understanding.
Practical Implementation: Zero-Shot Detection with Grounding DINO (Tiny)
Grounding DINO represents a specialized adaptation of the DINO (Detection with Interpolation‐Optimized anchors) framework that enables open‐set and zero-shot object detection.
DINO uses a DETR-based transformer encoder-decoder architecture for object localization while avoiding the need for hand-crafted anchor boxes. The Grounding DINO model builds upon this foundation by incorporating a language encoder with its visual backbone architecture. The model uses cross-modal attention to ground each textual query with relevant image regions based on the natural language prompt provided during inference. Grounding DINO performs object detection from textual descriptions without requiring further fine-tuning on task-specific classes.
The following example illustrates the application of the lightweight grounding-dino-tiny model for zero-shot object detection. The example looks for both “a cat” and “a remote control” within a single image.
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
model_id = "IDEA-Research/grounding-dino-tiny"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for cats and remote controls
text_labels = [["a cat", "a remote control"]]
inputs = processor(images=image, text=text_labels, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)
result = results[0]
for box, score, labels in zip(result["boxes"], result["scores"], result["labels"]):
box = [round(x, 2) for x in box.tolist()]
print(f"Detected {labels} with confidence {round(score.item(), 3)} at location {box}")
How It Works
- Imports: Requests retrieve images from URLs, torch manages tensor operations, and Hugging Face’s transformers package loads both processors(which handle image transforms and text tokenization) and the model.
- Model & Processor: AutoProcessor handles image and text input preparation, and AutoModelForZeroShotObjectDetection loads the grounding-dino-tiny checkpoint.
- Image Download: We retrieve the COCO image and then transform it into RGB format for subsequent processing.
- Text Prompts: When we pass [[“a cat”, “a remote control”]], the processor interprets these labels as a single collective prompt group.
- Inference: The processor(…) method produces tokenized text and normalized image tensors; the model(**inputs) carries out a forward pass without gradient computation.
- Post-Processing: The method post_process_grounded_object_detection filters detections using box_threshold=0.4 and text_threshold=0.3 to remove low-confidence results before rescaling normalized box coordinates into pixel values.
- Output: We loop through all detected boxes to display their label, confidence score, and rounded bounding-box coordinates for better readability.
Users can customize text_labels, modify threshold settings for precision/recall balance, or use a different image URL. The example shows that open-vocabulary and zero-shot detection can operate seamlessly with few lines of code.
FAQ SECTION
How do Vision Language Models (VLMs) differ from traditional object detection systems like YOLO or Faster R-CNN? Traditional object detection systems cannot process natural language queries and require retraining to adapt to new object categories. In contrast, vision Language Models combine image processing with natural language understanding. They can detect any object type and respond to complex scene-related queries through flexible text inputs.
What are the real-world benefits of Vision Language Models in commercial and industrial settings? Visual language models enhance multiple sectors by automating complex recognition tasks, supporting open-vocabulary queries, and delivering human-like explanations. E-commerce sectors take advantage of VLMs by reducing manual labeling costs while making product searches more intuitive. In manufacturing and robotics, natural language-driven commands enable VLMs to improve quality control and automate processes more efficiently. Healthcare benefits from VLMs that improve diagnostic accuracy by integrating visual analysis with medical expertise to deliver detailed insights beyond what traditional detectors provide.
Are Vision Language Models suitable for real-time or edge deployment, and what are the current limitations?
The latest improvements in model architecture and optimization have produced lightweight VLMs that operate efficiently on edge devices and support near-real-time applications.
The combination of knowledge distillation, sparse attention, and hybrid design approaches enables the practical use of these solutions in robotics and mobile or embedded systems.
Despite improvements, VLMs require more computational resources than classic detection systems such as YOLO and may exhibit higher latency.
Current research works to overcome these limitations and improve VLMs so they perform better in environments with limited resources and time constraints.
Conclusion
Vision Language Models (VLMs) introduce groundbreaking advances in the object detection field and multimodal artificial intelligence systems. Traditional detection systems such as YOLO and Faster R-CNN demonstrate high performance but remain limited by their dependence on annotated data and lack of language understanding.
On the other hand, by fusing visual data with language processing, VLMs deliver open-vocabulary and context-aware detection capabilities that enable immediate task adaptation through natural language prompts.
The current wave of models advances academic research while opening doors for real-world applications in multiple sectors like autonomous vehicles and healthcare. The ongoing refinement of VLM architectures and computational efficiency will establish them as the standard choice for intelligent and human-focused computer vision systems.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
